
基于交互式条件随机场的RGB-D图像语义分割
2017-04-14 00:47左向梅苟婷婷
计算机应用与软件 2017年3期
左向梅 赵 振 苟婷婷
(中国飞行试验研究院 陕西 西安 710089)
基于交互式条件随机场的RGB-D图像语义分割
左向梅 赵 振 苟婷婷
(中国飞行试验研究院 陕西 西安 710089)
RGB-D图像语义分割是场景识别与分析的基础步骤,基于条件随机场(CRF)的图像分割方法不能有效应用于复杂多变的现实场景,因此提出一种交互式条件随机场的RGB-D图像语义分割方法。首先利用中值滤波和形态重构方法对Kinect相机拍摄的RGB-D图像进行预处理,降低图像噪声及数据缺失;其次,利用基于条件随机场的分割方法对经过预处理的图像进行自动分割,得到粗略的分割结果;最后,用户通过交互平台,将代表正确场景信息的标签反应到条件随机场模型中并进行模型更新,改善分割结果。通过多组实验验证了该算法不仅满足用户对于复杂场景分割与识别的需求,而且用户交互简单、方便、直观。相较于传统的基于条件随机场分割方法,该方法得到较高的分割精度和较好的识别效果。
条件随机场 语义分割 交互式 RGB-D图像
0 引 言
随着科技的发展,Kinect深度相机的出现解决了在激光扫描设备和深度相机系统中存在的实际困难,简单、廉价、方便的特性使它成为计算机视觉领域的研究热点。Kinect相机获取的RGB-D图像[1]既包含了被拍摄物体的RGB图像,也包含了深度信息,因其丰富的数据特点使得其广泛应用于图像语义分析与理解的相关领域。
图像语义分割[2]包含了传统的图像分割和目标识别两个任务,其目的是将图像分割成多个具有语义信息的块,并识别出分割块的类别,最终得到一幅含有语义标注的图像。目前存在的语义分割方法一般是通过构建条件随机场模型来完成图像分割和识别两个任务。条件随机场模型[3]是一种基于无向图的概率模型,用来对序列数据进行标记,具有很强的概率推理能力。其优势在于充分考虑了图像中不同物体之间的位置关系,能够对物体类别有合理的推断。但是现实场景复杂,纯粹的依靠算法来完全自动实现分割和识别并不能满足要求。因此,用户干涉的图像分割技术成为新的研究热点。
目前广泛应用的主要有基于图割理论[4]、随机游走[5]、图匹配[6]等交互式分割方法。虽然它们理论依据不同,但是都具有相似的步骤思想。大体概括为:选取图像中的某些区域进行标记,用标记的像素根据制定的规则进行训练,得到相关分类模型后对其他像素进行标记,完成图像语义分割。这些算法相较于自动分割方法虽然效果有所提高,但是依旧存在一些不足:对用户输入要求较高,用户选择的位置和数量都会影响分割结果,并且要不断调整输入,交互量较大;由于算法的限制,现有分割方法大多用于单一目标分割中,对于多目标分割问题,很难快速得到准确的结果。
针对以上问题,本文提出了一种交互式RGB-D图像语义分割方法,巧妙地将手动操作融入到自动分割过程中,加入少量的人工交互操作,却很好地改善了分割精度,这是以前自动方法所达不到的。
1 方 法
本文方法主要分为三个步骤:首先对Kinect相机获得的RGB-D图像进行预处理,去除噪声并改善像素缺失状况;其次,利用基于条件随机场的图像分割方法对经过预处理的图像进行初始分割,得到大体的分割结果,这样有利于减少后续的交互工作量;最后,用户通过交互平台,将反应场景正确信息的标签传递到交互能量函数项中,并进行模型更新,得到改善后的分割结果。图1为本文方法流程图。
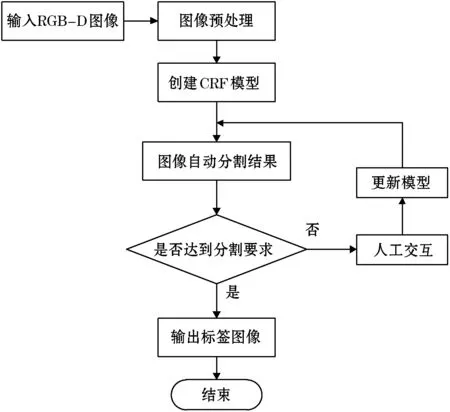
图1 基于交互式条件随机场的图像分割流程图
1.1 图像预处理
从Kinect得到的深度图含有大量的噪声,手动拍摄时Kinect轻微晃动以及场景中的光线干扰,都会增加图像噪声。而且深度估计算法还产生大量的稍纵即逝的人为干扰,尤其是靠近边缘的区域。所以在提取图像特征并进行识别之前,必须进行图像去噪。为此,使用中值滤波器[7]对图像进行去噪。
深度图像除了包含噪声外,还会出现数据缺失的部分,这些区域从彩色相机是可见的,但没有出现在深度图像上。比如对黑色吸光物体或镜面和低反射率表面,它们的深度没能被估计,出现了深度图上的孔。因此本文使用形态学重构方法[8]对其进行修补。
使用中值滤波去噪和形态学重构补洞后效果如图2所示。

图2 深度图像预处理
1.2 图像自动分割
图像进行预处理之后,在进行交互式分割之前,先使用基于条件随机场的方法进行自动分割,这样可以减少后续的交互工作量。条件随机场[3]是由Lafferty等提出的一个基于统计序列分割和标记的方法,是一个在给定输入节点的前提下,计算输出节点的条件概率的无向图模型。
本文中条件随机场能量函数E(y)测量了图像中每个像素i对应的可能标签yi的代价。yi可以取一组离散数据集{1,2,…,C},C代表类别数。能量函数由三项组成:(1)一元代价函数φ,依赖于像素位置i、局部描述符xi和学习的参数θ;(2)相邻像素i和j的标签势函数ψ(yi,yj);(3)相邻两像素点i和j之间的空间连续性η(i,j),它的形式依不同的图像而有所不同。能量函数定义如下:
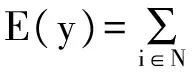
(1)
1.2.1 一元势函数
本文中一元势函数φ是由局部几何模型和位置先验概率这两部分组成:
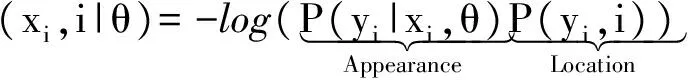
(2)
1) 几何模型
几何模型P(yi|xi,θ)是用一系列D维的局部描述符xi训练而成。几何模型的训练框架描述如下:
在给定从训练图片中提取出来的描述符集合:X={xi:i=1,2,…,N}情况下,我们用大小为H(1000)的单隐藏层和C维的最大软间隔输出层来训练一个神经网络,表示成P(yi|xi,θ)。它含有参数θ(大小为(D+1)×H和(H+1)×C的两个权重矩阵),通过使用反向传播和交叉熵损失函数学习而成。
经过训练后,神经网络模型生成了P(yi|xi,θ)和描述符xi之间的映射。在使用条件随机场模型之前,本文利用基于图割的分割方法产生超像素{s1,s2,…,sk}[9],计算两种不同的超像素点集合:仅用颜色图像得到的SRGB和利用颜色与深度图像共同生成的SRGBD。我们利用超像素来聚合一元势函数产生的初步预测结果。然后,对于图像的每个超像素sk,我们对所有落入该超像素的概率P(yi|xi,θ)求平均值,然后给在sk内的每个像素点赋予计算出的均值类概率。
2) 位置先验概率
位置先验概率P(yi,i)有两种不同的形式,第一种获得了目标的二维位置,类似于其他的语义分割方法。第二种是一种新颖的利用深度信息的三维位置先验概率。
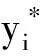


1.2.2 标签势函数
关于这一项我们选用相对简单的Potts 模型[10]:
(3)
使用简单的标签转换模型使得我们能够清楚地看到相对于条件随机场中的其他两个势函数、深度值的好处。在实验中我们将d的值设为3。
1.2.3 空间转换势函数
空间转换代价η(i,j)提供了一个机理来抑制或者鼓励每个位置的标签转换(独立于建议的标签类)。我们用下面的势函数形式表示:
η(i,j)=η0exp{-αmax(|I(i)-I(j)|-t,0)}
(4)
其中|I(i)-I(j)|表示在图像中相邻像素点i和j之间的梯度,t为一个阈值,而α和η0是尺度因子,η0=100。
1.3 交互式图像分割
对图像进行自动分割后,其分割结果并不是很好,因此,我们在上述模型中增加了交互能量函数项,将当前场景的正确信息反应到条件随机场模型中并进行模型更新,改善分割结果。我们的交互项是通过交互平台由用户对自动分割结果中错误的部分简单地画几笔实现的。模型更新能量函数如下所示:
(5)
这里E1(ci:xi)测量了像素i的在特征xi条件下标签为ci的概率,E2(ci:cj)测量了两个相连像素标签的一致性。通过使用图割方法[11]可以有效最小化模型更新能量函数。下面详细描述我们能量函数各组成部分的含义和作用。
1.3.1 交互能量函数
能量函数E1(ci:xi)依据像素i的特征评价了它属于某个物体标签的概率。它由两项组成,来自于深度相机的颜色和深度信息的局部外观和几何模型:
(6)
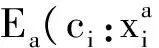
(7)

(8)
这里d(x,ci)是当前像素与对象类ci最近聚类中心的颜色值开方距离,ξ是一个比较小的数,为了避免分母为0,一般取10e-6。
(9)
• 高度hi:像素i在平面拟合面上的投影到地面的距离
• 尺寸si:覆盖该像素的平面拟合面的尺寸
• 方向θi:平面拟合面法向量与地面法向量夹角
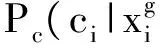
(10)
能量项E2(ci,cj)用来约束邻域像素标签的光滑性。我们用下式来计算该项:
E2(ci,cj)=δ[ci≠cj]sim(fi,fj)
(11)
这里,fi=[r,g,b,d]T为像素i的颜色值和深度值的串联。两个像素之间的相似性由式(12)计算:
(12)
其中σ是像素特征间的平均距离。
1.3.2 模型更新

2 系统实现及实验结果
2.1 系统实现
本文系统采用C++开发,所使用的开发环境是微软的VisualStudio2010,链接的库包括:微软基础类(MFC),开放图像库(OpenGL),开放计算机视觉库(OpenCV)等。
系统界面如图3所示,其中菜单栏包括文件、视图、运行、更新四项。左边子窗口为标签面板和参数设置面板,中间为图像显示区域,右边为渲染的深度数据显示区。其中文件项完成对文件的读取和保存;视图项调整界面显示内容;运行项包括对用户标签、分割标签、模型存储等操作;更新项可以重新加载数据。
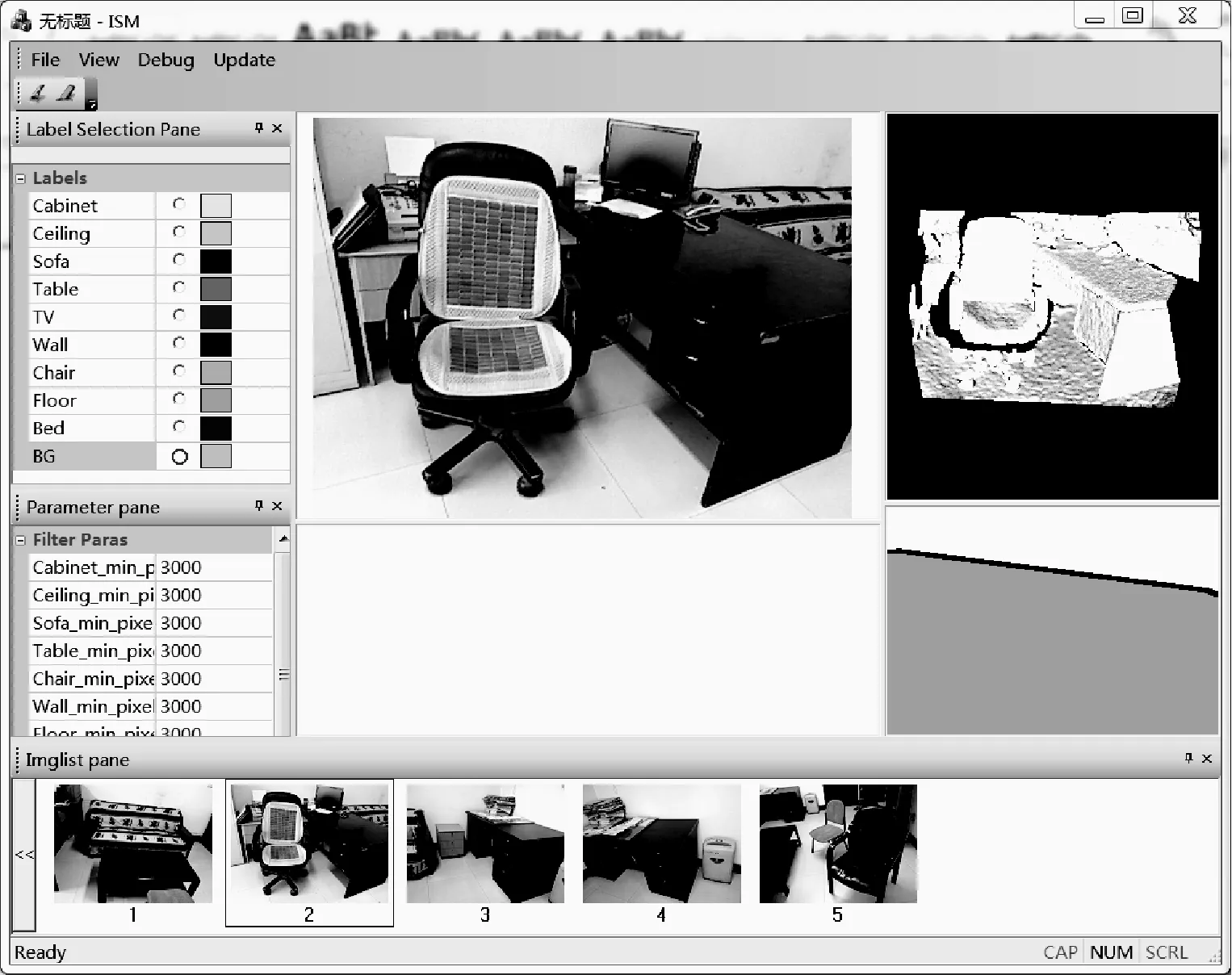
图3 系统软件界面
2.2 实验结果
图4展示了对我们拍摄的几个场景中的部分图像,使用交互式分割方法得到的结果,并与自动分割结果进行了对比。图4(a)中的灰度条代表了不同类别的物体标签;图4(b)-(g)为六组图像分割结果,每一组从左到右依次为RGB图像(包含人工交互笔画)、对应的深度图像、自动分割结果、交互式分割结果。从图中可以看出,使用自动分割方法虽然能达到大体分割结果,但对于一些物体还是出现了标签错误的情况。比如自动分割时图4(b)中椅子背部分被错分为沙发,图4(d)中桌子部分被错分为柜子,沙发部分被错分为桌子。
使用我们的交互式分割方法,增加少量的人工交互操作后,可以很大程度上改善分割效果,得到用户要求的分割精度。与其他交互式分割方法相比,不需要用户预先进行盲目的标记,大大减少了工作量,从图中可以看出每组图像的交互不超过6笔。而且我们不是简单地进行前景和背景单一分割,而是实现了多目标分割,识别了图像中多类物体。通过将自动分割结果及交互式分割结果与真实标签图像进行误差计算,如表1所示,可以看出,交互式分割结果准确率明显高于自动分割结果。

表1 自动分割与本文交互式分割准确率对比

图4 自动与交互式图像分割对比
除了对实验结果准确率的分析,我们还对图4中6组图像分割过程中交互的次数及时间进行了记录,见表2所示。运行该系统的计算机配置:Windows7 操作系统,至强3.2GHz处理器,16GB内存。从表2可以看出,每幅图像第一次交互所需的笔画数量最多,交互时间较长,随后只需要较少的交互量就可以在短时间内达到用户期望的分割结果,本文中所使用的实验图像最多只需要交互三次就能完成语义分割。
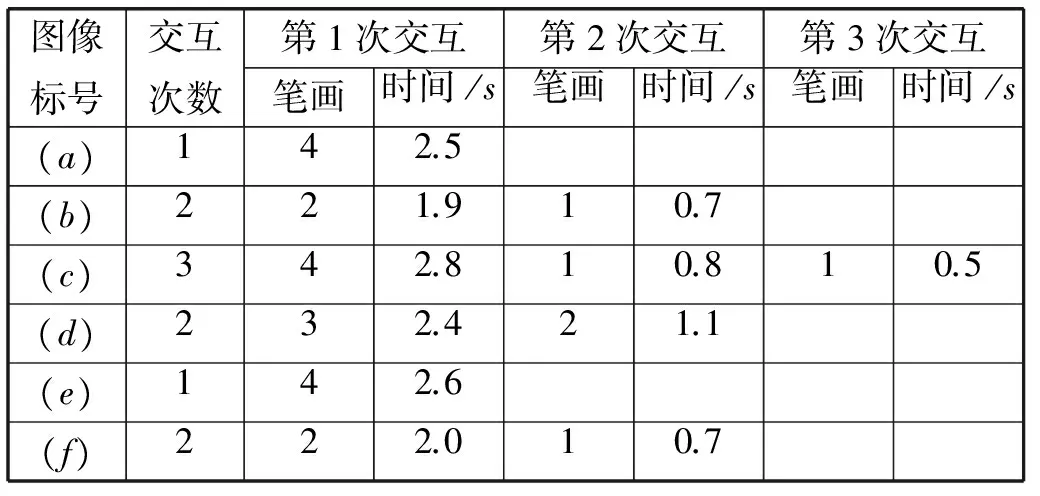
表2 本文交互式分割时间表
为了进一步验证本文系统的性能,将我们的方法与基于图割的交互式分割方法[14]及SIOX交互式分割方法[15]进行对比,分割结果见图5所示。图5(a)、(b)为两组实验图像及结果,其中第一列为RGB图像(包含人工交互笔画),第二列为基于图割的交互式分割结果,第三列为SIOX交互式分割结果,第四列为本文交互式分割结果。表3为图5(a)、(b)两组图像的分割准确率及时间。从图5及表3可以看出,相比于其他两种方法,在近似相同的时间消耗情况下,我们的方法能够得到更好的分割结果,从而达到用户对图像的分割需求。

图5 不同交互式分割方法对比结果
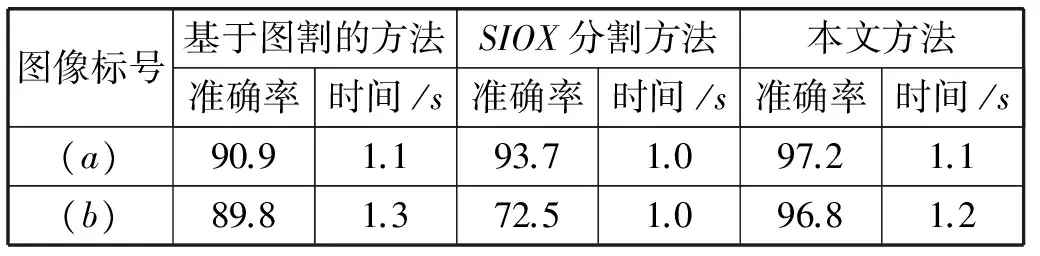
图像标号基于图割的方法SIOX分割方法本文方法准确率时间/s准确率时间/s准确率时间/s(a)90.91.193.71.097.21.1(b)89.81.372.51.096.81.2
上述实验是在假定人工交互给出的都是正确标签的情况下进行的,所以外观函数里的权重系数αp和几何函数里的系数αg设定为较大的值,从而增加人工交互对分割结果的影响。但在实际操作中,难免会存在错误的人工交互,通过减小权重系数αp和αg,可以降低人工交互对系统分割结果的影响。当人为引入错误的信息后,系统依然保留原有的判断,从而提高系统的鲁棒性。图6为两组实验结果,从图6中可以看出,当αp和αg设以较大的值(αp=0.6,αg=0.7),人工错误地操作将桌子标记为椅子,结果系统误将桌子显示为椅子,由此可以看出人工交互对系统的影响较大。考虑到人为错误信息的引入,适当降低αp和αg的值(αp=0.4,αg=0.5),图中可以看出,尽管人为将桌子错误标记为椅子,但是由于人工操作对系统影响降低,系统自身判断占据较大比重,所以依旧将桌子判断为桌子,从而提高了系统的鲁棒性。

图6 两组引入人工错误信息后的实验结果对比图
尽管通过降低权重系数αp和αg的值,可以减轻人为错误信息引入后对系统系统性能的负面影响,但这是以削弱人工对系统的影响为代价。有时候系统本身判断的确是错误的,人工就需要多次的操作才能纠正系统自身的判断失误,不免带来系统效率上的降低。因此,为了保证系统拥有较高的使用效率的同时,对人为错误信息拥有一定的处理能力,选取合适的权重系数αp和αg的值需要根据用户不同的需求来决定。
3 结 语
本文提出了一种交互式的图像分割和标签方法,提取RGB-D图像的语义区域。当对图像进行分割时,首先使用基于条件随机场模型的方法对图像进行初始分割,随后通过少量人工交互,动态地调整辨别型模型来反映当前场景的信息,从而改善分割结果。依据我们的实践,只需要简单的画几笔就能很好地提高分割精度,这对于自动分割方法来说是很难达到的。而且,当前的分割信息自动地集成到我们学习的条件随机场模型中,所以对于后续的图像也能改善分割精度。虽然我们提出的交互式图像分割方法能很好地提高分割精度,对用户交互操作量也比较少,但是交互操作会影响分割速度,所以后续工作需要进一步优化能量函数,在提高精度的同时不增加计算时间。
[1]ShaoL,HanJ,KohliP,etal.ComputervisionandmachinelearningwithRGB-Dsensors[M].Switzerland:SpringerInternationalPublishing, 2014: 3-26.
[2]KohliP,LadickL,TorrPH.Robusthigherorderpotentialsforenforcinglabelconsistency[J].InternationalJournalofComputerVision, 2009, 82(3): 302-324.
[3]LaffertyJD,McCallumA,PereiraFCN.Conditionalrandomfields:probabilisticmodelsforsegmentingandlabelingsequencedata[C]//ProceedingsoftheEighteenthInternationalConferenceonMachineLearning,Williamstown,MA,USA.SanFrancisco,CA,USA:MorganKaufmannPublishers, 2001: 282-289.
[4]BoykovYY,JollyMP.InteractivegraphcutsforoptimalboundaryandregionsegmentationofobjectsinN-Dimages[C]//ProceedingoftheEighthIEEEInternationalConferenceonComputerVision,Vancouver,BC,Canada, 2001: 105-112.
[5]GradyL.Randomwalksforimagesegmentation[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2006, 28(11): 1768-1783.
[6]NomaA,GracianoABV,JrRMC,etal.Interactiveimagesegmentationbymatchingattributedrelationalgraphs[J].PatternRecognition, 2012, 45(3): 1159-1179.
[7]HwangH,HaddadRA.Adaptivemedianfilters:newalgorithmandresults[J].IEEETransactionsonImageProcessing, 1995, 4(4): 499-502.
[8] 文华. 基于数学形态学的图像处理算法的研究[D]. 哈尔滨:哈尔滨工程大学, 2007.
[9]BoykovY,Funka-LeaG.GraphcutsandefficientN-Dimagesegmentation[J].InternationalJournalofComputerVision, 2006, 70(2): 109-131.
[10]YuanJ,BaeE,TaiXC,etal.Acontinuousmax-flowapproachtoPottsmodel[C]//11thEuropeanConferenceonComputerVision,Heraklion,Crete,Greece.Springer, 2010: 379-392.
[11]BoykovY,VekslerO,ZabihR.Fastapproximateenergyminimizationviagraphcuts[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2001, 23(11): 1222-1239.
[12]LiY,SunJ,TangCK,etal.Lazysnapping[J].ACMTransactionsonGraphics, 2004, 23(3): 303-308.
[13]ChumO,MatasJ.RandomizedRANSACwithT(d,d)test[C]//Proceedingsofthe13thBritishMachineVisionConference,Cardiff,UK, 2002: 448-457.
[14]RotherC,KolmogorovV,BlakeA. “GrabCut”:Interactiveforegroundextractionusingiteratedgraphcuts[J].ACMTransactionsonGraphics, 2004, 23(3): 309-314.
[15]FriedlandG,JantzK,RojasR.SIOX:simpleinteractiveobjectextractioninstillimages[C]//Proceedingsofthe2005IEEEInternationalSymposiumonMultimedia,Irvine,CA,USA, 2005: 253-260.
RGB-D IMAGE SEMANTIC SEGMENTATION METHOD BASED ONINTERACTIVE CONDITIONAL RANDOM FIELDS
Zuo Xiangmei Zhao Zhen Gou Tingting
(ChineseFlightTestEstablishment,Xi’an710089,Shaanxi,China)
RGB-D image semantic segmentation is the primary step of scene recognition and analysis, and the image segmentation method based on conditional random fields (CRF) cannot be applied in complex and volatile scenes, therefore an RGB-D image semantic segmentation method with interactive conditional random fields is proposed. Firstly, preprocess the depth and color images generated from Kinect with median filter and morphology reconstruction method, reducing the image noise and missing data. Secondly, automatically segment the preprocessed images with conditional random fields to obtain the rough segmentation. Finally, user takes the correct labels into the conditional random fields’ model to update the model through an interactive platform, which can improve the segmentation results. Compared with the traditional segmentation method based on conditional random fields, the proposed method can achieve better performance in scene understanding and analysis.
Conditional random fields Semantic segmentation Interactive RGB-D image
2015-07-09。左向梅,工程师,主研领域:模式识别与图像处理。赵振,工程师。苟婷婷,硕士生。
TP391.41
A
10.3969/j.issn.1000-386x.2017.03.032
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小哥白尼(军事科学)(2022年2期)2022-05-25
红领巾·萌芽(2019年8期)2019-08-27
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
长江学术(2016年4期)2016-03-11
CHIP新电脑(2016年3期)2016-03-10
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
人间(2015年21期)2015-03-11
