
基于学术论文与新闻语料的教育信息化文本挖掘分析
2017-03-23 05:20陆伟
大学 2017年12期
陆 伟
目前,国内对于教育信息化、数字化学习等领域的研究主要从教育教学理论的创新发展、教育信息化的资源建设与应用现状、论文文献的文本解构与分析等方面展开。在教育信息化相关文本分析方面,部分学者基于期刊文献数据库,运用文献计量等方法分析了国内教育信息化领域的研究热点和与趋势,这些研究在量化描述教育信息化研究的特征的同时,也总结或预测了相关研究的主题或发展趋势。本文以现有的文本分析研究为基础进行了拓展。
采用网络爬虫抓取相关论文或新闻文本数据,并使用中文分词及关键词提取、词向量分析、文本聚类等技术方法,本文剖析和归纳了国内教育信息化相关研究及新闻报道的关注点。研究发现,慕课、翻转课堂、微课、智慧教育等近年来兴起的教学模式或教育理念引领了新一轮教育信息化相关研究的热潮,也是新闻报道的热点;同时,在文本挖掘中对比分析不同背景的语料资源也能够获得有价值的启发。在词向量与相关词分析中,在论文和新闻文本语境下,教育信息化及若干热点词汇的“含义”存在一定的差别,这些差异反映了学术论文和新闻报道在关注的问题上有不同的聚焦。
一、数据与研究设计
(一)数据简介
本研究使用的论文文本数据来自中国知网(CNKI)学术期刊数据库、博士学位论文数据库以及优秀硕士论文数据库。新闻文本数据则来自中国教育信息化网——“教育部教育管理信息中心主办的教育信息化资讯类综合门户网站”,该网站资讯频道下的“信息化动态”栏目汇集了国内各地教育信息化发展动态的相关报道。
本文利用网络爬虫抓取了数千篇论文文献以及万余篇新闻报道的文本信息,文本信息的检索和爬取时间为2016年9月。论文文献方面,我们以“教育信息化”为主题,在相关论文数据库中进行搜索并采集了2000年至2016年9月期间刊发的有效期刊文献5,347篇(其中核心期刊文献1,356篇);优秀硕士学位论文3,629篇,博士学位论文71篇。新闻语料方面,中国教育信息化网汇集的教育信息化动态报道主要集中在近三年,2010年之前的报道相对很少,我们采集了2010年1月至2016年9月期间发布的有效新闻资讯共10,288篇。
(二)基本描述性统计分析
图1-1展示了CNKI相关文献数据库中以“教育信息化”为研究主题的文献数量变化趋势;由于2016年的数据信息并不完整(截止当年9月),因此这一年度的数据量相比上一年均有所下降。在期刊类文献中,2013年后相关文献的数量有了明显的上升,非核心期刊上刊发的相关文献更是在此后的两年内增长了十多倍。在学位论文方面,硕士论文逐年增长,这一绝对数字的增长反映了教育信息化相关议题逐渐受到重视甚至追捧;另一方面,相关博士学位论文的数量很少,这可能与博士论文对理论创新性的要求较高有关。
需要说明的是,CNKI硕博学位论文数据库中收入的学位论文文献并不全面,个别重点院校相关重点学科的学位论文也不在收录范围;因此根据数据库中现有的学位论文对院校、专业、导师等信息进行排名比较很可能会出现偏差。但是本文认为,将现有的数据视为学位论文总体的“抽样”或学科相关研究趋势的代表,仅对论文的研究主题或内容进行分析,仍然不失可行性。
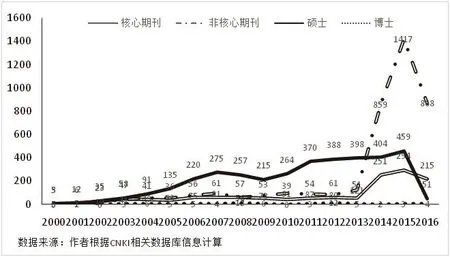
图1-1 以“教育信息化”为主题的研究文献数量
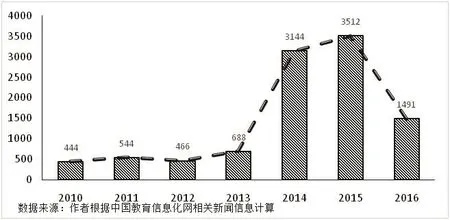
图1-2 教育信息化相关资讯报道量
图1-2显示的是中国教育信息化网站“信息化动态”栏目中近年来的相关资讯报道量;2016年的资讯信息截止到当年9月,因此相比2015年出现了明显下降。总体上看,相关资讯量在2013年后出现了爆发式的增长,这与期刊文献(尤其是非核心期刊文献)在2013年后出现的增长趋势十分相似。
(三)研究设计
1.关键词词频计算
本研究从关键词词频统计、词向量距离与相关词分析以及文本聚类三个方面对现有的文本数据进行挖掘分析。在进行关键词统计前,我们需要将文本资料按时期分类。参考已有的研究文献,并结合本研究所采用文本的时期范围和数量变迁特征,我们将教育信息化相关论文文本划分为三个时期:2000—2005年,2006—2013年,2014—2016年;对于新闻文本,则划分为2010—2013年,2014—2016年两个阶段。
本文首先采用Python版本的结巴(Jieba)分词包对新闻文本进行分词。在本文的研究语境下,对于“智慧教育”“三通两平台”“云计算”等专有名词,默认的分词模式可能会将其进一步切分,因此需要构建自定义词表,使相关的专业词汇能够被准确保留。对于期刊文献和学位论文文献,研究者已经在文献中提供了关键词,仅需对其按阶段分类统计即可;但新闻语料并不存在现成的关键词,对此,本文采用词频-逆文档率(Term Frequency- Inverse Document Frequency,以下简称TF-IDF)算法提取了每篇新闻文本的关键词。某词语i的TF-IDF值可表示为:
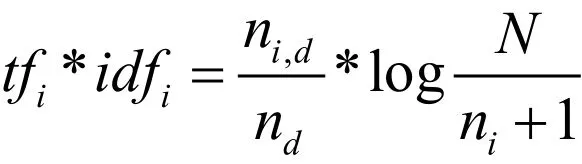
其中,ni,d是词i在文本d中出现的频数;nd是文本d中的总词频数;N为语料库中的文本总量;ni是词i在语料库中出现的总频数——为避免分母为0(即语料库中没有词i)而加1。TF-IDF值越大的词被认为对于文本越重要(能更好地代表文本);对关键词按TF-IDF值进行排序,排名靠前的词即可被选作为该本文的关键词。
2.词向量计算
Word2Vec是Google于2013年开源的一款将词表征为数值向量的学习工具,它能够胜任自然语言处理(NLP)领域的多种工作,例如,聚类、寻找近义词、情感分类、词性分析等。Word2Vec有多个开源版本,我们在Anaconda(一种用于科学计算的Python版本)环境下安装了Gensim模块进行词向量训练—— 基于Skip-gram模型。
以词向量(Distributed Representation)的方式将文本中的词汇进行数学化的表示最早由辛顿提出[1],其基本思想是通过训练将每个词映射到一个低维实数向量空间中(具体的向量维度可在模型系统中进行调整)。词向量中的每一维代表一个具有一定语义和语法解释的词语特征。通过词之间的距离(如余弦距离、欧式距离等)可以判断它们之间的语义相似性。这不仅避免了传统的“One Hot”向量表示法经常遭遇的“维数灾难”,同时也解决了“词汇鸿沟”问题,即词之间不再是孤立的,潜在语义及语法特征相似的词在距离上会更接近。对于两个n维空间中的词向量A(x11,x12,…,x1n)和B(x21,x22,…,xn2),其语义相似性可由夹角余弦值表示为:
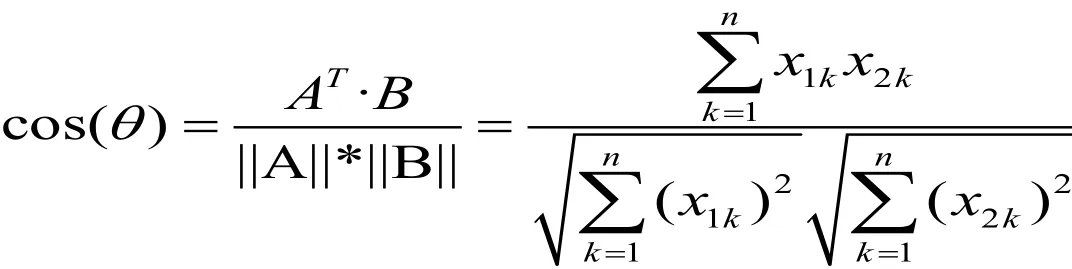
余弦值越接近1,两个词的语义关联度也越高。本研究使用的语料为经过分词处理后的论文文本(摘要)和新闻文本。借助Word2Vec深度学习工具包,我们尝试寻找“教育信息化”等热点词汇的相关词,并对不同的文本语料进行比较。
3.文本聚类
在机器学习领域,聚类是无监督学习(Unsupervised Learning)的一个例子,聚类试图将数据集中的样本划分为多个不相交的子集,每个子集称为一个簇(Cluster),从而在数据中发现某种潜在的结构。[2]事实上,以教育信息化为主题的研究或报道存在很多的子领域或子主题,统计高频关键词是揭示这一多样性的方式之一;而基于文本的聚类分析可以帮助我们更全面地了解相似主题——尤其是那些相对独立但不热门的主题——的研究或报道。
本研究尝试了对(核心)期刊文献及新闻文本进行聚类。参考西格兰提出的方法[3],我们根据一组指定词汇在期刊(摘要)及新闻文本中出现的频度来实现对相关文本的聚类。借助前述分析中使用的关键词词频表,我们在不同类型的文本中分别提取词频不少于十次的词,作为为该类型文本聚类时的公共词汇表。利用这些词汇列表和文献或新闻标题列表可以建立相应的文本文件(即一个大的矩阵),记录每篇文献或新闻中相关词汇的统计情况;同时,我们也对上述矩阵进行了转置,从而实现对文本关键词的聚类。在具体的聚类方式上,本文选择了(凝聚的)层级聚类。
凝聚层级聚类采用自底而上的策略不断合并两个最为相似的对象,从而形成一个逐渐增大的簇,当所有对象都在一个簇中或达到某个终止条件时,聚类结束。在研究的语境下,被合并的对象即为某篇文献或新闻。对象之间的相似性基于两者之间的距离或紧密程度。由于一些文献或新闻的(摘要)文本字数较多,这使得它们在总体上包含了更多的词汇,为了纠正这一潜在的问题,我们采用了皮尔逊距离度量对象之间的相似性。
二、研究结果及分析
(一)高频关键词分析
表2-1中显示的是不同时期内,核心期刊与非核心期刊文献以及硕博学位文献中频次排名前20的关键词。从关键词的分布来看,在2000—2005年和2006—2013年两个时期,期刊文献的研究关注点有较强的连续性,这一点与该时期内期刊文献的数量变化平缓相对应;2014年—2016年期间,以“教育信息化”为主题的研究不仅在数量上异军突起,关注点也发生了很大的变化:翻转课堂、慕课、微课、智慧教育等新兴名词是这一时期高频关键词的主要代表,它们为一线教学实践注入活力的同时,也改变了相关学术研究的方向和生态环境。
有趣的是,期刊论文与硕博学位论文的关键词有较大的风格差异。以2014—2016年期间的研究为例,期刊文献的关键词有较多宏观或抽象的概念,例如大数据、教学改革等;硕博学位论文的关键词则体现了较多微观的教学场景,例如电子书包、课堂教学、交互式电子白板等。另一方面,诸如ASP.NET,B/S模式、J2EE等词汇也频繁出现在了学位论文的关键词中。含有这类关键词的论文基本由计算机技术、软件工程等工科专业的学生撰写,论文通常从技术层面探讨相关的软件设计或系统部署,服务于教育信息化相关工程建设。即便是相同的主题,期刊论文与学位论文的研究视角或风格也可能存在差别,关键词选取策略的不同某种程度上正反映了这种差异。

表2-1 期刊论文与学位论文高频关键词
对于新闻文本,我们采用TF-IDF算法对每篇新闻进行关键词的提取及排序,选择前五位关键词为每篇新闻的关键词代表。在以关键词的TF-IDF值作为其权重值的情况下,我们统计了2014—2016年以及2010—2013年两个时期的新闻文本高频关键词(TOP20)。

表2-2 新闻文本高频关键词(TOP20)
从表2-2中的结果可知,两个时期的新闻文本共享了较多的高频关键词,例如培训、教学点、教育资源、数字化校园等。2014—2016年期间,与微课、慕课、翻转课堂、智慧教育等相关的新闻大量涌现,引领了这一时期的教育信息化相关报道。这部分解释了为何与教育信息化相关的新闻报道量在2013年后出现了井喷式的增长。“微课”“慕课”,“翻转课堂”等被认为具有革命性的教育模式于2012年前后在西方国家兴起,并于随后的一两年中风靡全球,在初等至高等教育的各阶段皆有应用。对这些“教育信息化”的热门概念或议题进行报道或研究可谓时势使然。
(二)词向量距离与相关词分析
词向量训练的效果很大程度上取决于对文本语料的数量。当有丰富大量的语料(句子)能够反映词语之间关系时,模型才可以充分学习句中的语义和语法关系。对于期刊和硕博论文,我们使用了论文的摘要文本,由于摘要篇幅相对较短,我们将期刊论文与硕博论文进行了合并,统一为论文文本;新闻文本仍然自成一类。事实上,我们也尝试区分对核心期刊、非核心期刊以及硕博论文的摘要文本,分别进行词向量训练,但是由于语料数量较少,分开训练的效果并不理想。使用Word2Vec进行词向量模型训练后,本文计算了部分热点词汇的相似词(表2-3)。
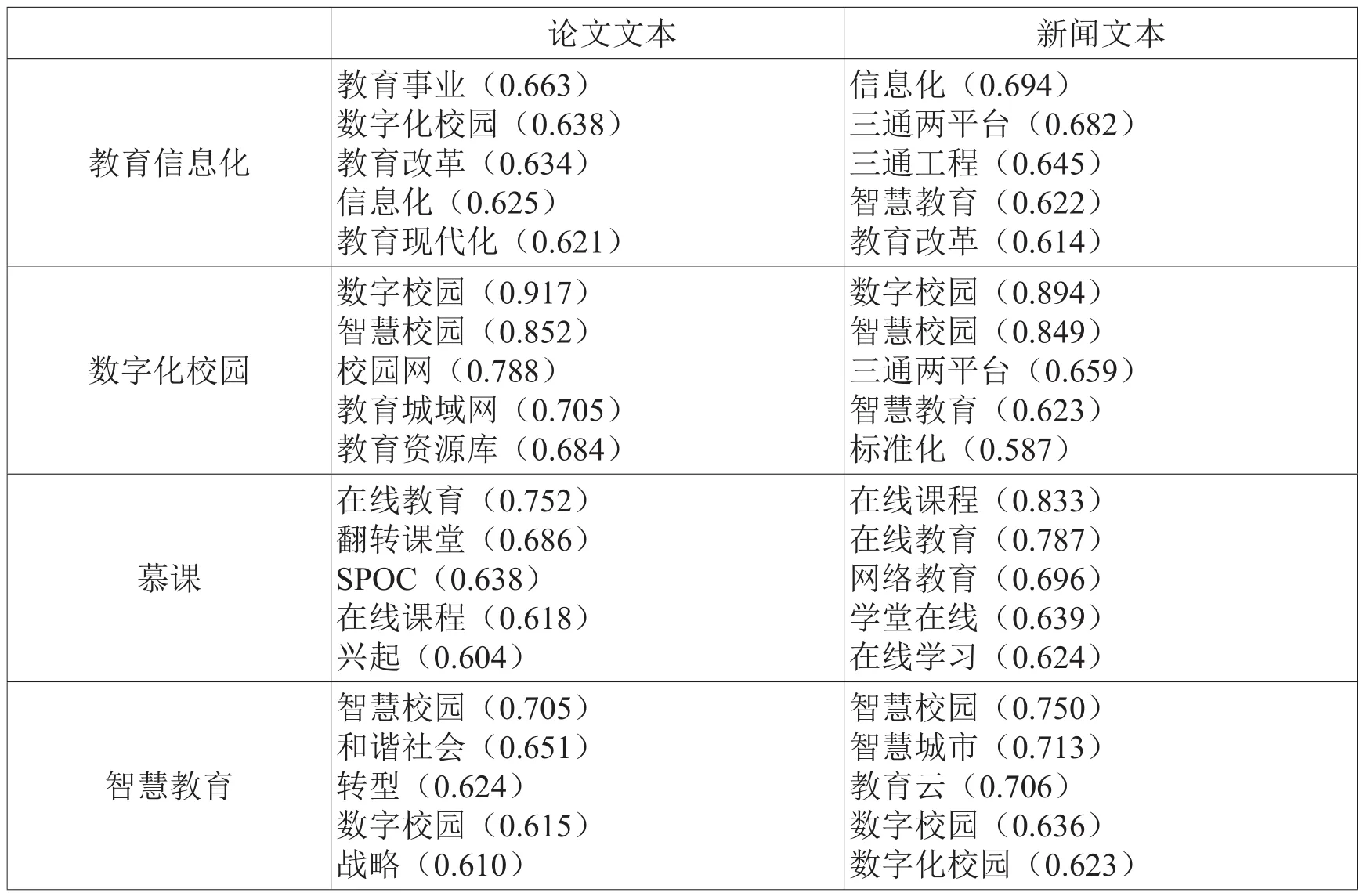
表2-3 教育信息化及部分热点词汇相关词
表2-3中显示的是教育信息化、数字化校园、慕课以及智慧教育的五个最相关词汇(以余弦距离衡量)。总体上看,热点词汇的相关词基本都符合我们的认知。在新闻文本中,“教育信息化”的相关词中出现了“三通两平台”和“三通工程”,这是全国各地十二五时期教育信息化建设的核心目标,几乎是同时期教育信息化事业的代名词。同时,相关词也与文本类型有一定联系。例如,在“慕课”的相关词中,论文文本下准确识别出了“SPOC”(Small Private Online Course),即小规模限制性在线课程,它被认为是“后慕课时代”的一种典型课程范式,能够更好实现慕课与传统课堂的融合,部分期刊文献和硕博论文均对此展开了专门讨论,但它在新闻语料中几乎没有出现。
不难看出,在论文文本下,“智慧教育”的相关词中出现了“和谐社会”“转型”“战略”等词,这一结果并不理想,其原因很可能在于期刊文献及硕博论文的摘要文本中关于“智慧教育”的语料并不丰富。另一方面,新闻文本在分词后全都纳入了词向量训练,相比论文摘要,新闻文本的词库量更大,句式也更为丰富多样,因此模型训练都取得了为较理想的结果,这再一次说明了语料数量对于词向量训练的重要性。
(三)文本聚类分析:以层级聚类为例
指定了一组固定词汇后,我们可以根据单词在文献摘要或新闻文本中出现的次数对相关文本进行聚类(按行聚类);该分析能够帮助我们发现研究或报道主题相近的文本。从基本的聚类格局来看,学期教育、基础教育、职业教育、高等教育、继续教育等不同教育阶段均有涉猎教育信息化的研究;且不同教育阶段的关注点存在一定差异。例如,基础教育阶段的教育信息化研究主题较为丰富,微课、翻转课堂等研究直指基础教育阶段的教学模式改革,以电子书包、平板电脑等为关注点的研究注重对教学应用、数字化校园建设等的考察;而在职业教育领域,大多数研究关注的是职业学校的数字教育资源建设以及借助信息化手段提升职业学校教师教学水平等主题。
在列上对数据进行聚类有助于进一步揭示结构化的信息。在本研究的语境下,列代表的都是论文文献或新闻文本中的关键词,在列上进行聚类则可以知晓哪些词经常会结合在一起出现。例如,在新闻文本中,和“调研”联系较为密切、时常一起出现的词有“电教馆”“电化教育”“会议”等;这反映了各地区电教馆较为频繁地参与了教育信息化调研工作的基本事实。
借助树状图(图2-1和图2-2),我们可以更直观地了解聚类结果。由于论文文献或新闻报道的聚类量很大,限于篇幅,我们仅展示了部分聚类结果。图中所有的子节点均由一个垂直线和两条水平线连接;一般来说,水平线的长度反映了聚类中的误差情况,水平线越短,两个类的相似度也就越高。垂直线和水平线的交错潜在地划分了文本的类型或主题,这即是层级聚类的直观意义。

图2-1 期刊文献聚类(部分)
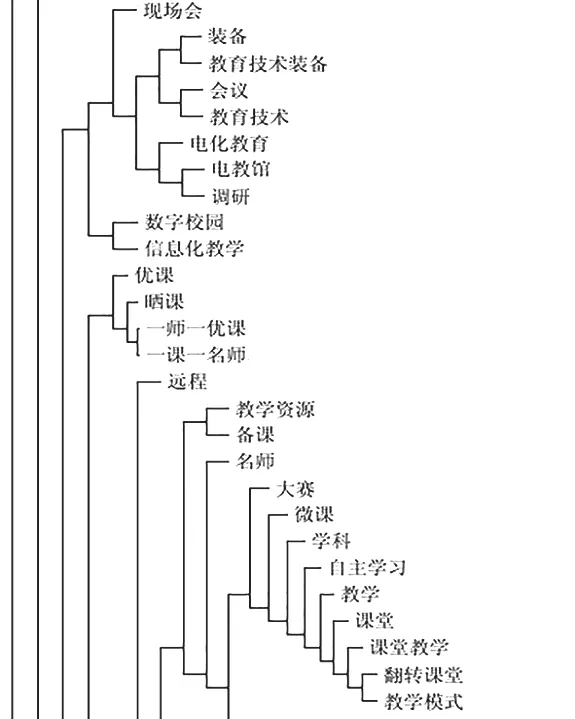
图2-2 新闻文本关键词聚类(部分)
三、总结
本研究发现慕课、翻转课堂、微课、智慧教育等近年来兴起的教学模式或教育理念为教育信息化相关研究注入了新的内涵,相关研究或报道不断涌现,是新时期教育信息化事业发展的核心关切。不同的文本语料从不同的角度描绘了教育信息化的相关研究或事业发展;进行教育信息化相关文本挖掘分析时,综合分析不同来源和背景的相关语料资源能够获得有价值的启发。本文拓展了“教育信息化”相关领域文本分析和挖掘研究的文献范畴,同时借鉴了较新的工具和方法,丰富了相关领域中文本挖掘分析的研究视角。
需要指出的是,本研究也存在一些缺点和不足,而这些缺陷可能会影响文本挖掘分析的效果。例如,与大多数该领域的文献或文本分析研究相似,本文以“教育信息化”为主题在CNIK中进行了相关文献的检索;但是较早时期的相关研究未必会采用“教育信息化”这类术语表述方式,这可能会直接影响文献检索的结果并限制研究的视野。另外,在文本聚类方面,本文对相关研究主题的划分尚不够清晰,层级聚类结果的呈现也有待优化,后续的研究可尝试更多样的聚类方法和可视化手段,后者包括高维度下的多维缩放,主题河(ThemeRiver)、数字景观(Landscapes)等等。
即便存在一些缺陷,借鉴深度学习、自然语言处理等领域的工具、技术和方法对有关文献或文本进行分析挖掘仍然能获得有趣的启发。当然,即使在“教育大数据”时代,研究者也不应忽略生活中的“小数据”;本文建议研究者将海量数据分析技术与实地调查相结合,以更好把脉各类教育事业的发展动态及其内在规律。
注释:
[1]Hinton, G.E.Learning Distributed Representations of Concepts [C].In Proc.Eighth Annual Conference of the Cognitive Science Society, 1986, (1): 1–12.
[2]周志华.机器学习[M].北京:清华大学出版社, 2016:197.
[3]西格兰著,莫映,王开福,译.集体编程智慧[M].北京:电子工业出版社,2009:29-53.
猜你喜欢
通信技术(2021年12期)2022-01-25
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
浙江大学学报(工学版)(2015年11期)2015-03-01
浙江大学学报(工学版)(2015年5期)2015-03-01
浙江大学学报(工学版)(2015年1期)2015-03-01
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
