
基于深度卷积网络的SAR图像目标检测识别
2017-03-23 08:29:05李君宝杨文慧许剑清
导航定位与授时 2017年1期
李君宝,杨文慧,许剑清,彭 宇
(哈尔滨工业大学自动化测试与控制系, 哈尔滨 150001)
基于深度卷积网络的SAR图像目标检测识别
李君宝,杨文慧,许剑清,彭 宇
(哈尔滨工业大学自动化测试与控制系, 哈尔滨 150001)
在SAR图像解译应用领域,目标的自动检测与识别一直是该领域的研究重点和热点,也是该领域的研究难点。针对SAR图像的目标检测与识别方法一般由滤波、分割、特征提取和目标识别等多个相互独立的步骤组成。复杂的流程不仅限制了SAR图像目标检测识别的效率,多步骤处理也使模型的整体优化难以进行,进而制约了目标检测识别的精度。采用近几年在计算机视觉领域表现突出的深度学习方法来处理SAR图像的目标检测识别问题,通过使用CNN、Fast RCNN以及Faster RCNN等模型对MSTAR SAR公开数据集进行目标识别及目标检测实验,验证了卷积神经网络在SAR图像目标识别领域的有效性及高效性,为后续该领域的进一步研究应用奠定了基础。
SAR;目标检测识别;CNN;Fast RCNN; Faster RCNN
0 引言
近年来,合成孔径雷达(Synthetic Aperture Radar,SAR)在军事及民用领域的广泛应用使得对高性能的SAR图像处理及解译技术的需要更加迫切[1],其中SAR图像的自动目标识别技术是众多技术中的关键,也是科研攻坚的难点。SAR图像与普通光学图像在成像机理、几何特征、辐射特征等方面有较大的不同。SAR所成图像对地物回波的强弱不敏感,层次感较差;雷达波反射的不均匀造成图像的分辨率较低,目标边缘模糊;此外,SAR图像中噪声较多,对目标检测的影响较大。鉴于SAR图像的上述特点,通常来说,SAR图像的自动目标识别一般由图像滤波预处理、提取感兴趣区域、特征提取及目标识别等步骤组成。在上述各步骤中,特征提取是重中之重,能否提取到具有较高识别力特征是后续整个识别过程的关键。一般来说,SAR图像的特征提取由主成分分析及其改进算法等机器学习方法实现[2]。
在传统的机器学习算法中,特征的提取规则往往是由人工设计的,或者当数据量较大时由计算机总结出来。实际应用中,当数据量过大且数据较复杂时,这种方式提取到的特征往往并不具有代表性,无法表示不同类别数据间的独特性,因此也就限制了识别精度。相较于传统的机器学习算法,深度学习在特征提取方面具有无可比拟的优越性。深层网络结构通过逐层的非线性变换,能够实现复杂函数的逼近,由低层到高层,特征的表示越来越抽象,越能对原始数据进行更本质地刻画。优秀的特征自学习能力使深度学习受到了学术界及工业界的广泛关注,在短短不到10年的时间里,深度神经网络已在图像、语音、自然语言处理等方面显示出了优越的性能,引发了诸多领域的革命性变革。在图像识别及目标检测领域,卷积神经网络(Convolutional Neural Network,CNN)表现出色,在世界各大计算机视觉挑战赛中取得了优异的成绩。
2006年,Geoffrey Hinton在科学杂志上发表的一篇论文给出了训练深度神经网络的一种可行性解决方案,由此开启了深度学习的热潮[3]。在短短几年时间里,无论是深度网络的架构还是深度网络在人工智能(语音识别、图像识别等)领域的应用都取得了突破性的进展。2012年,Hinton领导的研究小组在ImageNet[4]图像分类比赛中拔得头筹。在这个包含1000类图像的分类挑战中,该小组的深度卷积网络模型的分类精度较之传统图像识别方法超出10%之多[5]。Hinton小组的成功是计算机视觉领域里程碑式的一步。自2012年之后,各挑战小组纷纷采用深度卷积神经网络来处理图像识别及目标检测问题,在此过程中,卷积神经网络的架构不断得到改进,分类精度也在逐步提高。
本文将卷积神经网络应用到SAR图像的目标检测识别任务中,针对MSTAR SAR公开数据集,使用CNN网络进行了目标识别实验,在此基础上,分别使用RCNN网络的扩展模型Fast RCNN和Faster RCNN进行了SAR图像目标检测实验。根据实验结果,分析了卷积神经网络应用于SAR图像目标检测识别的可行性,为后续该领域的相关研究提供了思路。
1 卷积神经网络(CNN)
卷积神经网络由Yann LeCun发明并首次应用于手写数字的识别[6],在该项任务中,CNN在20世纪90年代就达到了商用的程度。近几年,在计算机视觉领域,CNN也发挥了出色的性能,这主要得益于其适用于图像数据的特殊网络结构。在处理图像数据时,通常将图像表示为一维的像素向量,以手写数字识别为例,假设原始图像的大小为32×32,图1所示为使用传统神经网络处理时的示意图。

图1 普通神经网络用于手写数字识别Fig.1 Ordinary neural network for handwritten digit recognition
如图1所示,网络输入为32×32的一维像素向量,输出为从0到9共10类数字编号,中间隐含层的层数和每层的节点数可调整,神经网络各个网络层的神经元相互之间是全连接的。使用这种全连接网络来处理手写数字识别问题虽然可行但识别效果较差,主要原因在于对图像数据来说,图像的相邻像素之间是存在相关关系的,而这种全连接网络的处理方式无法捕捉像素之间的空间关系,也就丢失了图像中隐含的很重要的一部分特征。其次,同一类目标的大小、形状以及纹理信息在不同样本中表现不同,而这种普通的全连接网络对目标的形体变化或图像的场景变化不具备鲁棒性。
与传统的神经网络结构不同,卷积神经网络在处理图像数据方面具有独特的优势,图2所示为Yann LeCun发明的用于手写数字识别的卷积神经网络结构[6]示意图。如图2所示,卷积神经网络一般由卷积层、下采样层和全连接层组成。
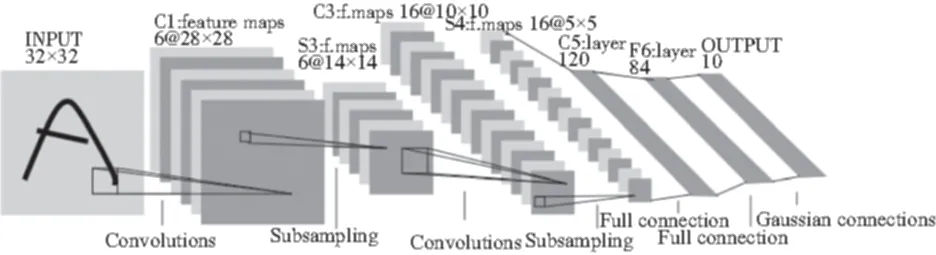
图2 卷积神经网络用于手写数字识别Fig.2 Convolutional neural network for handwritten digit recognition
卷积神经网络的输入为原始图像,卷积层的卷积核以一定的大小和步幅对原始图像进行卷积运算得到特征图,下采样层对特征图进行采样处理,抽取特征图一定区域内的最大值或平均值,经过多层卷积和下采样处理后,由全连接层整合特征并交由分类器进行分类处理。相较于传统的神经网络,卷积神经网络具有以下几方面特点:
1)局部感知:针对图像数据像素的局部联系较为紧密的特点,卷积神经网络的卷积层设置成局部连接的形式,如图3中右半部分所示,卷积核模拟生物的视觉感受野,每一次卷积只提取图像固定大小区域内的局部信息;
2)权值共享:局部感知使每一次卷积只提取到图像局部区域内的信息,因此,要想提取整幅图像的某类特征需要该类卷积核按照一定的步幅对整幅图像中所有局部区域进行特征提取,在整个过程中卷积核进行卷积计算时的权值系数不会因为这些区域在图像中的位置不同而发生变化,这是因为特征的提取方式与提取位置无关;
3)多核卷积:每一种卷积核只能提取到图像的某一类特征,因此,需要在卷积层设置多种卷积核,从而提取到更加全面的图像特征信息,如图3中局部连接部分所示,不同的颜色代表不同种类的卷积核,分别提取图像的不同特征;

图3 局部感知示意图Fig.3 Local sensing
4)下采样:在某些卷积层后通常会添加一个下采样层,抽取卷积得到的特征图中一定范围内的局部平均值或最大值,这样既降低了数据量,也提升了网络对输入图像中目标形变和场景变化的鲁棒性;
5)多层卷积:在一定范围内,网络层数越高,学习到的特征越抽象,越能表示图像的全局化信息,但在全连接网络中,网络层数的加深也带来了参数数量的指数型增长,这使得网络的学习过程非常困难,而在卷积神经网络中,得益于权值共享,深层网络的优势得到发挥,能够学习到更具辨识力的抽象特征。
综上所述,卷积神经网络的网络结构非常适用于图像数据的识别处理,自2012年卷积神经网络初次应用于ImageNet挑战赛以来,其出色的性能得到了学术界和工业界广泛的关注及认可,不断被应用于计算机视觉、语音识别等人工智能领域,在此过程中,卷积神经网络的架构不断得到改进,其性能也在逐步提高。
2 CNN及RCNN扩展模型
2.1 CNN模型
本文用于SAR图像目标识别的卷积神经网络参考AlexNet[5]模型,该模型来源于ImageNet挑战赛,由多伦多大学的Alex Krizhevsky等设计实现。2012年,AlexNet模型在图像分类任务中的首次应用便达到了85%的准确率。ImageNet数据集中包含1000类图像,所以AlexNet模型的输出层中包含1000个输出节点。根据本文所用数据集的类别数,将输出层的输出节点改为8,网络的整体架构如图4所示。

图4 卷积神经网络架构Fig.4 Convolutional neural network used in this paper
如图4所示,模型包含5个卷积层和3个全连接层(包括输出层),在第1、2、5个卷积计算后添加了下采样(Max-pooling)操作。网络的主要执行流程及具体参数信息如下。
1)输入层:原始图像,大小为3×224×224;
·卷积操作:96种大小为11×11的卷积核,卷积步幅为4;
2)卷积层1:96个大小为55×55的特征图;
·下采样操作:采样范围3×3,步幅为2;
·卷积操作:256种大小为5×5的卷积核,卷积步幅为1;
3)卷积层2:256个大小为27×27的特征图;
·下采样操作:采样范围3×3,步幅为2;
·卷积操作:384种大小为3×3的卷积核,卷积步幅为1;
4)卷积层3:384个大小为13×13的特征图;
·卷积操作:384种大小为3×3的卷积核,卷积步幅为1;
5)卷积层4:384个大小为13×13的特征图;
·卷积操作:256种大小为3×3的卷积核,卷积步幅为1;
6)卷积层5:256个大小为13×13的特征图;
·下采样操作:采样范围3×3,步幅为2;
7)全连接层6:4096个神经元节点;
8)全连接层7:4096个神经元节点;
9)输出层(全连接层8):8个神经元节点。
2.2 RCNN扩展模型
图像目标识别的结果给出了图像中可能存在的目标类别,而目标检测的结果则进一步明确指出了可能存在的目标类别在图像中的具体坐标位置。深度学习技术应用于目标检测领域以来,体系架构不断发展完善,从RCNN到Faster RCNN,检测准确率和检测效率都有了一定提升。目标检测由目标的定位和识别两部分组成,目标的识别由卷积神经网络实现,但对于目标的位置定位来说,有多种实现方式。RCNN(Regions with CNN features)[7]的检测算法是基于图像分割方法(如Selective Search[8])来找出一些可能是物体的区域;再把这些区域的尺寸缩放成卷积神经网络的输入尺寸,由卷积神经网络的识别结果判断该区域到底是不是物体,是哪个物体;最后对是物体的区域位置进行进一步的回归微调,使得目标的位置定位更加准确。RCNN虽然能够达到目标检测的目的,但是众多的可能区域都要经过卷积神经网络进行类别划分,如此大的计算量严重限制了目标检测的效率。此外,RCNN的整个检测识别流程过于复杂,很难进行整体优化。
RCNN的扩展模型Fast RCNN和Faster RCNN对RCNN的结构进行了优化改进,大幅度提高了目标检测效率。本文选取了MSTAR SAR数据集中的一类军事目标图像2S1,使用标注工具创建目标检测数据集,分别训练了Fast RCNN和Faster RCNN两种目标检测模型,验证两种模型针对SAR图像数据的有效性。
Fast RCNN[9]依然使用图像分割方法(Selective Search)提取感兴趣区域(Region of Interesting,RoI),不过与RCNN不同的是,Fast RCNN不再单独把每个RoI区域输入卷积神经网络,而是将原始图像输入卷积神经网络,只进行一次特征提取,从而有效地提高了计算效率,Fast RCNN的网络结构如图5所示。网络的输入为原始图像和RoI的坐标,原始图像经过多层卷积后得到最终的特征图,根据网络的计算规则将RoI的坐标映射到特征图上,得到卷积后的RoI区域,如图5中特征图内的红色框所示。由于每个RoI区域大小不一,而神经网络全连接层要求固定大小的输入,因此,坐标映射之后将RoI采样到固定尺度(6×6)。之后,通过全连接层将RoI连接成特征向量,交由分类器进行类别划分。由于图像分割方法给出的RoI的位置坐标与目标的真实坐标之间并不完全重合,所以当分类器判定RoI内包含目标时,还需进一步对RoI的坐标进行微调,使其更加接近目标的真实位置坐标。如图5所示,Fast RCNN架构将输出层分成了两部分,把目标分类和坐标回归的训练联合在了一起,对检测识别流程进行了整合。

图5 Fast RCNN结构示意图Fig.5 Schematic diagram of Fast RCNN
Faster RCNN[10]的基本结构仍然是卷积神经网络,但是它省去了图像分割方法提取图像内目标可能区域的步骤,通过在卷积神经网络最后一层特征图后添加一个叫做RPN(Region Proposal Network)的网络来实现该部分功能,RPN结构如图6所示。

图6 RPN结构图Fig.6 Diagram of Region Proposal Network
RPN网络以特征图上的每个点为中心,使用不同面积和长宽比的滑动窗口来采集特征图特定区域内的特征。Faster RCNN预设了9种滑动窗口,分别对应三种窗口面积1282、2562、5122和三种窗口长宽比1∶1、1∶2、2∶1的自由组合。为了解决网络的固定输入问题,将不同类型的窗口采集到的特征降维到固定维度。根据降维后的特征,分类层给出滑动窗口内包含目标的得分,得分高的窗口作为正样本,得分低的就认为没有物体,会被过滤掉。当分类层给出的结果认为窗口内有目标时,需要对目标的位置进行进一步的回归校正。此时,将特征图窗口内的区域映射回输入图像,如果输入图像内对应的区域与图像中目标的真实区域的重叠率大于某一设定值(预设值为0.7)时,则该区域的标签为1;若重叠率小于另一设定值(预设值为0.3)时,则该区域的标签为0;介于两个设定值之间的区域不参与训练。对于标签为1的区域,寻找映射回输入图像的坐标与图像中真实的目标坐标之间的映射关系,完成回归定位过程。
Faster RCNN的整体模型结构如图7所示,通过调整网络结构,经过分阶段的训练,Faster RCNN把整个目标检测识别流程全部整合到了神经网络中。模型的输入为原始图像,经过多层卷积得到特征图后,由RPN网络和全连接网络分别完成目标的检测和识别功能。模型的训练过程分为4步:
1)使用预训练的CNN模型初始化网络参数,训练RPN网络;
2)使用第一步中产生的RoI区域训练Fast RCNN分类网络;
3)固定卷积层参数,调整RPN参数;
4)固定卷积层参数,调整全连接层参数。

图7 Faster RCNN结构示意图Fig.7 Schematic diagram of Faster RCNN
3 SAR图像目标识别及目标检测实验结果
3.1 目标识别实验结果
本实验在MSTAR数据库上进行,MSTAR SAR是美国国防高级研究计划局和空间实验室的MSTAR项目提供的实测SAR地面静止军用目标数据集,目前国内外对SAR图像目标识别进行的研究也大多以该数据集作为实验数据。该数据集内的图像由X波段、HH极化方式、0.3m×0.3m高分辨率聚束式合成孔径雷达分别在1996年和1997年采集得到。经过前期处理,从原始SAR图像数据中提取出像素大小约为158×158的目标切片图像,这些目标切片图像数据大多是不同型号的坦克、装甲车在0~360°不同方位角下的静止切片图像。本文中SAR图像目标识别实验所用数据来自该数据集中8类军事目标图像,分别为2S1、BRDM_2、BTR60、D7、T62、T72、ZIL131、ZSU_23_4。图8所示为这些军事目标的SAR图像及其对应的真实场景下的可见光图像。

图8 8类SAR目标图像Fig.8 Eight targets of SAR image
本文中SAR图像目标识别实验的训练样本和验证样本是8类军事目标在俯仰角为15°时的成像数据,测试样本是各类军事目标在俯仰角为17°时的成像数据。对于常规方法来说,SAR图像实现自动目标识别需要经过4个步骤:图像预处理、特征提取、特征选择和目标分类,这4个步骤分别需要设计不同的算法来实现。本文利用卷积神经网络实现SAR图像的目标识别,无需人为设计上述各步骤,只需将原始图像去均值处理后缩放到固定大小输入神经网络即可,特征提取、特征选择和目标分类都由卷积神经网络一次性实现。本文中各类目标实验数据集的组成及识别结果如表1所示。

表1 实验数据集组成及识别结果
表1中的识别率是指对测试集样本的识别准确率。由表1可得,使用8层卷积神经网络对8类SAR军事目标图像的总体识别准确率为99.0%,就每一类的单项识别准确率来说,2S1类目标的准确率最低,BTR60类目标的准确率最高,达到了100%。与常规的SAR图像目标识别方法相比,使用卷积神经网络不仅简化了目标识别流程,大大提高了识别效率,就识别准确率来说也达到了当前最佳水平。
3.2 目标检测实验结果
本文选取了MSTAR SAR数据集中的一类军事目标图像2S1进行目标检测实验,首先需要使用目标标注工具创建目标检测数据集。实验数据集构成及实验结果如表2所示。

表2 数据集构成及实验结果
由实验结果可知,目标检测的准确率过高,这是因为实验所用数据集中的SAR图像场景过于单一,所有目标的位置坐标差别不大,网络存在严重的过拟合问题。该问题的解决需要国内外相关研究部门的协助,公开更多场景更加复杂的SAR图像数据集,以供研究所用。虽然实验结果缺乏通用性,但对于SAR图像的自动目标检测识别领域来说,本文所用的深度学习相关技术是一次有益的尝试,图9给出了Fast RCNN和Faster RCNN目标检测识别的图形化结果,相较于常规的SAR图像目标检测识别方法,本文所用方法简化了流程的同时也提高了识别准确率。

图9 实验结果Fig.9 The results of experiments
4 结论
本文研究了卷积神经网络在SAR图像目标检测识别中的应用,使用卷积神经网络及其拓展模型对MSTAR SAR图像数据分别进行了目标识别和目标检测实验。实验结果表明,卷积神经网络在SAR图像目标识别方面具有广阔的应用前景,对于目标检测任务,卷积神经网络的两种扩展模型Fast RCNN和Faster RCNN都能实现比较好的检测效果。在检测效率方面,由于整合了整个流程,Faster RCNN模型要远远优于Fast RCNN,具体的检测用时因硬件平台的不同而有所差异。虽然由于缺乏复杂场景的SAR图像数据集,本文所用实验数据过于单一,实验结果缺乏一定的通用性,但是本文内容为卷积神经网络在SAR图像目标检测识别领域的应用提供了思路,为后续该方向的进一步研究奠定了基础。
[1] 杨桄, 陈克雄, 周脉鱼, 等. SAR图像中目标的检测和识别研究进展[J]. 地球物理学进展, 2007, 22(2):617-621.
[2] 韩萍, 吴仁彪, 王兆华, 等. 基于KPCA准则的SAR目标特征提取与识别[J]. 电子与信息学报, 2003, 25(10):1297-1301.
[3] Hinton G E , Salakhutdinov R R . Reducing the dimensionality of data with neural networks [J]. Science (New York, N.Y.), 2006, 313 (5786) : 504-507.
[4] Deng J, Dong W, Socher R, et al. Imagenet: A large-scale hierarchical image database[C]//Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. IEEE, 2009: 248-255.
[5] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems, 2012: 1097-1105.
[6] Lécun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11):2278-2324.
[7] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2014:580-587.
[8] Uijlings J R R, Sande K E, Gevers T, et al. Selective search for object recognition[J]. International Journal of Computer Vision, 2013, 104(2):154-171.
[9] Girshick R. Fast R-CNN[C]// IEEE International Conference on Computer Vision. IEEE, 2015:1440-1448.
[10] Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]//Advances in Neural Information Processing Systems, 2015: 91-99.
Deep Convolutional Network Based SAR Image Object Detection and Recognition
LI Jun-bao, YANG Wen-hui, XU Jian-qing, PENG Yu
(Automatic Test and Control Institute, Harbin Institute of Technology, Harbin 150001, China)
Automatic target detection and recognition has been the focus in SAR image interpretation field. Generally, the target detection and recognition method of SAR image is divide into independent 4 steps, filtering, segmentation, feature extraction and target recognition. Complex process limits the efficiency of SAR image target detection and recognition. Too many steps make it difficult to optimize the whole model, so the accuracy of method is restricted. In recent years, deep learning has been the famous method in many important computer vision challenges. Deep learning has led to a revolutionary change in the field of computer vision. In this paper, we apply deep learning to SAR image automatic target detection and recognition task. And we verify the feasibility and efficiency of deep learning method through experiments on MSTAR SAR image sets.
SAR; Target detection and recognition; CNN; Fast RCNN; Faster RCNN
10.19306/j.cnki.2095-8110.2017.01.011
2016-04-24;
2016-07-16。
教育部新世纪人才计划(NCET-13-0168);国家自然基金(61371178)。
李君宝(1978-),男,博士,副教授,主要从事图像处理及模式识别方面的研究。E-mail:lijunbao@hit.edu.cn
V448.2
A
2095-8110(2017)01-0060-07
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
当代陕西(2019年10期)2019-06-03 10:12:04
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
