
精准医学研究相关信息资源的发现与汇聚
2017-03-21 08:44:02,,,,
中华医学图书情报杂志 2017年11期
, , , ,
精准医学研究从疾病预防、诊断、治疗等方面改变传统医学的研究模式,基因组学、药物组学、转录组、蛋白质组等各类数据也随着各项精准医学研究的开展和推进逐渐丰富。发现与汇聚精准医学信息资源,探讨适合的知识服务模式与结构,实现已有资源、成果的有效存储、流通和再利用,满足医生、科研人员、产业发展等多方面的需求,是精准医学研究的重要组成部分。
继2015年美国提出精准医学研究计划和英国持续投入资金推动其“10万人基因组计划”后,我国于 2016年公布了“精准医学”相关的重大科研计划和政策举措,并将其列为国家重点研发计划之一。
本文围绕国家科技创新和医药卫生事业发展的需求,借助数据仓储、数据过滤与解析等异构资源整合技术,开展精准医学相关资源的采集、存储、加工、组织与分析。围绕国际精准医学计划,发现精准医学领域科学数据,整合其前沿资讯、研究进展、企业动态等,为医药卫生领域科研人员提供集成性、综合性、有效性和多元化的[1]数据资源和科研支撑与知识服务,促进科技创新和健康产业发展。
1 精准医学相关信息资源的发现
本文重点对美国和英国的精准医学项目产生的精准医学科学数据进行扫描。
1.1 精准医学研究计划及其相关资讯资源
1.1.1 美国All of Us /Precision Medicine Initiative
2015年1月30日,美国政府宣布了其精准医学计划(Precision Medicine Initiative,PMI)[2],即通过分析100万名志愿者的基因信息,更好地了解疾病形成机理,为开发相应药物、实现“个性化医疗”“个性化用药”奠定基础。
2015年9月,美国国立卫生研究院(National Institutes of Health,NIH)组织专家成立了精准医学专业咨询委员会,并对精准医学计划的实施进行了详细解读[3]。
2016年,美国联邦政府从财政预算中为精准医学计划划拨2.15亿美元经费。2017年2月,NIH将项目名称改名为“All of Us”[4],同时拨出500万美元用于社区和卫生保健部门招募志愿者,以准确、全面地绘制美国人群基因地图。该项目的资源类型有公告/报告、新闻、会议、研究进展等,每日更新。
1.1.2 英国Precision Medicine Catapult
2012年末,英国启动10万人基因组计划(The 100,000 Genomes Project)(https://www.genomicsengland.co.uk/the-100000-genomes-project/),计划于2017年前对包含癌症和罕见病在内的10万人进行基因组测序,使英国的生命科学研究处于全球现代医学的前沿。
2015年4月,由英国技术战略委员会(Innovate UK)资助的Precision Medicine Catapult (PMC)项目启动,该项目旨在连接政府、企业、研究机构以及领域学者,共同发展英国精准医学研究,推动精准医学相关产业的发展。该项目的资源类型有新闻、博客,每日更新。
1.2 精准医学科学数据
精准医学领域涉及的数据类型众多,疾病、药物、基因、通路等均属于精准医学领域范畴。为了更好地实现资源扫描和精准医学异构数据整合,为精准医学知识服务奠定基础,本文调研了DrugBank、CTD、TTD等几个有代表性的精准医学数据库。
1.2.1 DrugBank
DrugBank(https://www.DrugBank.ca/)是2006年加拿大卫生研究院(Canadian Institutes of Health Research)、阿尔伯塔省创新健康研究计划(Alberta Innovates -Health Solutions)和代谢组学创新中心(The Metabolomics Innovation Centre,TMIC)共同资助创建的。数据库整合了药物的化学结构、药理作用、作用蛋白靶点、作用的生理通路、药物间相互作用等信息,包含了6 432类药物、2 350类靶标物质及它们之间12 715条相互作用关系的信息。
1.2.2 CTD
CTD(Comparative Toxicogenomics Database,http://ctdbase.org/)是2002年由北卡州立大学(North Carolina State University,NCSU)开发的,主要描述化合物、基因、疾病及其相互关系,同时还包涵了基因本体(Gene Ontology,GO)、通路和暴露组等相关内容。
1.2.3 TTD
TTD(Therapeutic Target Database,http://bidd.nus.edu.sg/BIDD-Databases/TTD/TTD.asp)是2002年新加坡国立大学(National University of Singapore)生物信息学和药物创新团队(Bioinformatics and Drug Design Group)创建的,提供已知或正在探索的可用作治疗的蛋白质靶点和核苷酸靶点的信息及其对应的靶疾病、靶通路和相应的药物/配体信息,同时包括这些靶点在其他数据库中的相关链接,如靶点的功能、序列、3D结构、配体结合性质、酶的命名以及相关文献等信息的链接。
1.2.4 Pathway Commons
Pathway Commons(http://www.pathwaycommons.org)是由多伦多大学(University of Toronto)创建的,并与计算生物信息中心(cBio Center for Information Biology)、哈佛医学院(Harvard Medical School)、俄勒冈健康与科学大学(Oregon Health & Science University)共同参与维护。该数据库整合了来自22个数据资源的化学通路信息,包括生物体内一系列生物化学分子(如基因,基因产物以及化合物等)通过各种生化级联反应来完成某一具体的生物学过程所涉及的蛋白质、DNA、RNA、生物小分子等多种物质。数据库收录了4.2万条通路信息,135万条相互作用关系[5]。
1.2.5 COSMIC
COSMIC(Catalogue of somatic mutations in cancer,COSMIC,http://cancer.sanger.ac.uk/cosmic)是创建于2004年的人类癌症相关体细胞突变数据库,是世界上最大的癌症体细胞突变数据库,由Wellcome Trust Sanger Institute开发和维护。该数据库收录专家审编数据和全基因组数据,截至2016年9月,数据库收录了123万肿瘤样本、2.8万全基因组数据、400万突变数据等[6]。
2 精准医学信息资源汇聚与整合
精准医学知识服务是在资源扫描的基础上,完成资源的采集、分析和重组,帮助用户获取多来源的领域知识,更有效地支持相关工作人员的知识应用和知识创新。为了实现不同系统间的信息资源共享,需要整合各种分布杂乱的资源。实现信息资源整合的关键在于遵循标准化的规范体系[7]。根据上文对精准医学资讯和科学数据的扫描,我们构建了统一的元数据标准,将多来源的异构数据存储到本地,并以知识服务的形式提供资源的共享和再利用。精准医学异构资源发现与整合的方案见图1。
2.1 资源发现与采集
对美国All of Us计划和英国Precision Medicine Catapult进行精准医学资源扫描,发现了精准医学领域的研究进展、项目动态、会议报道、人员招募等资讯类数据。这两个项目资源类型及分布见表1。同时整合了国际先进的精准医学科学数据集,数据内容涵盖药物、疾病、基因、通路等多种类型,为用户提供精准医学科学数据服务。数据采集情况见表2。
2.2 元数据标准描述
针对资讯类和科学数据两类资源的特性,分别设计了通用的资源元数据标准(表3、表4),为实现异构精准医学资源的整合奠定基础。为了优化用户对资源的检索,系统利用MeSH医学主题词表对所有资源进行了知识标注,支持用户根据自己的需要选择搜索路径,同时为实现资源间的语义关联做好铺垫。

表1 美英两国精准医学资源类型及采集数量
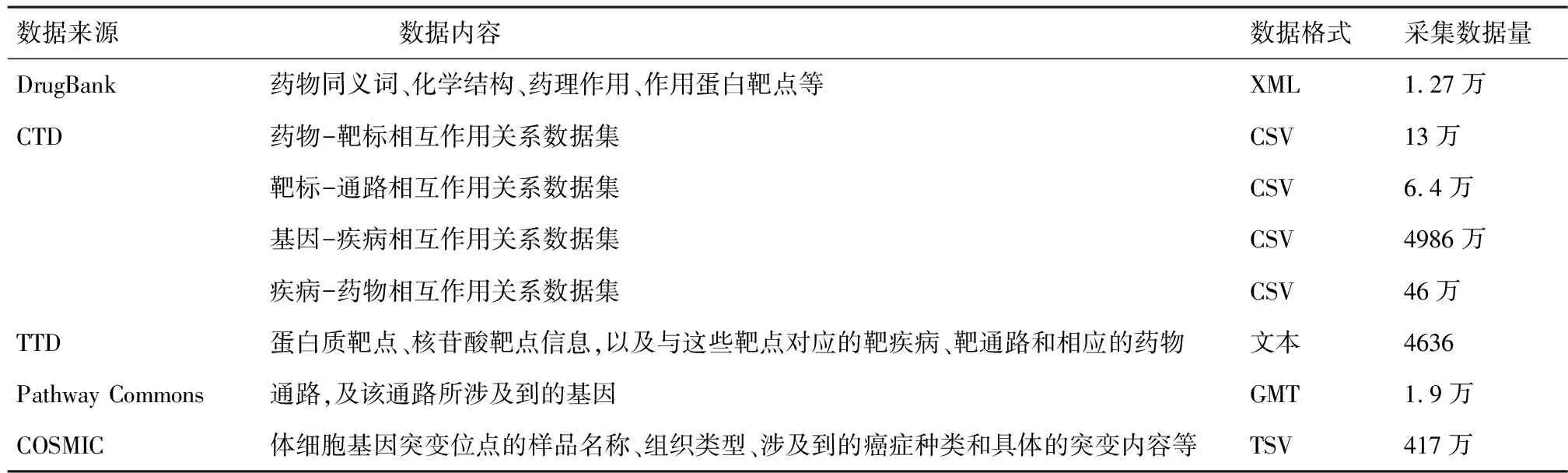
表2 精准医学科学数据采集

表3 资讯类数据的元数据标准
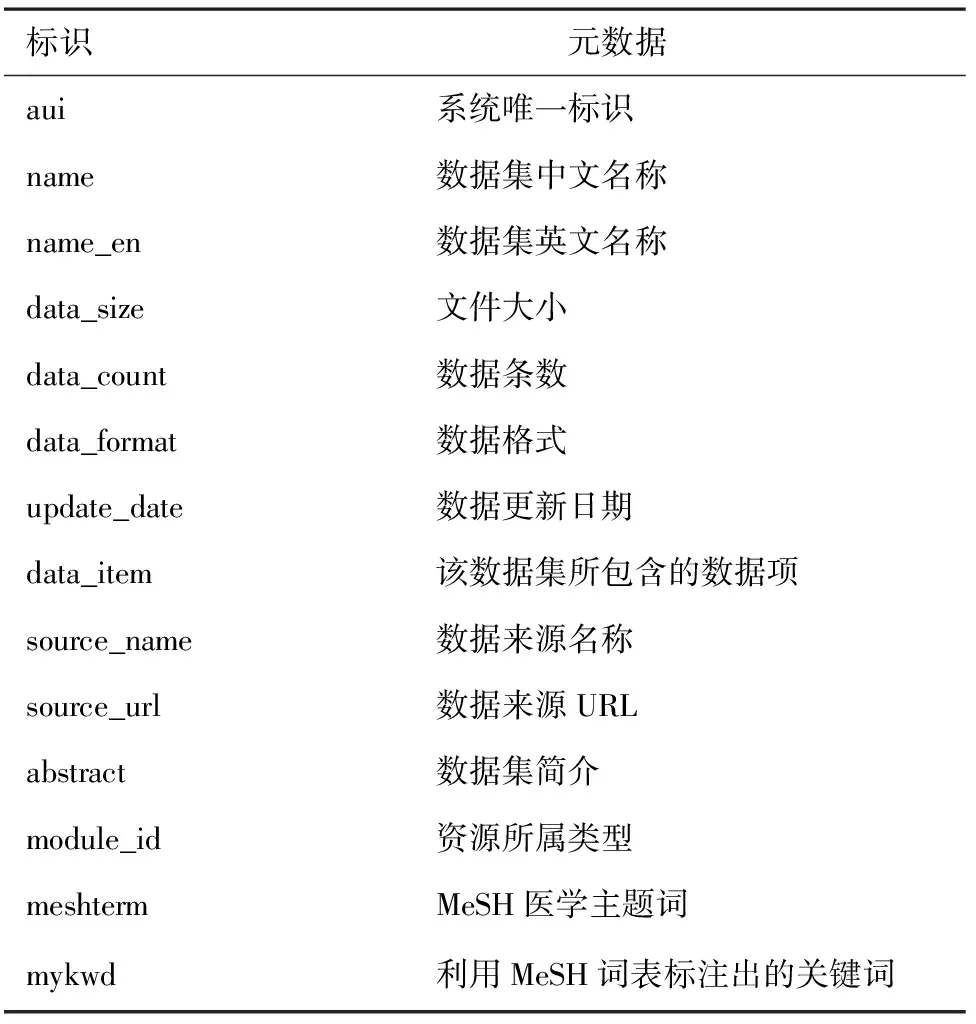
表4 科学数据的元数据标准
2.3 资源解析与整合
常见的异构资源整合方式包括模式集成和数据复制。模式集成是指在数字资源整合过程中将来源于不同数据库的数据视图集成为全局模式,以帮助用户无限制地访问各数据库的数字资源[8];数据复制则是通过对各数据库的异构数据进行数字资源的整合,为用户提供一站式服务,满足用户的信息需求,提升用户浏览和获取信息资源的体验[9],其代表技术是数据仓库技术(Extract-Transform-Load,ETL)。比较以上两种模式的特点,数据复制能够将异构数据本地化,为用户提供集成化的数据服务,用户只需要进行一次身份验证便可以无障碍地检索和获取众多数据库中的资源[9],可大大提升访问效率和用户体验。
在资源分类和对应元数据标准的基础上,本文采用了数据复制的异构资源整合方式,以满足用户对数据集成服务的需求。对于资讯类数据,通过网络爬虫工具对资源相关内容的文章列表页面进行爬取、解析,获得文章内容页面的URL列表;然后对文章内容页面进行爬取,通过正则表达式工具解析页面内容,根据设计的元数据标准获取相应字段项的内容,存储到本地数据库中;最终获取项目的实施方案、最新动态、研究进展及报告等类型资源。对于资源本身带有的附件如PDF等,我们将其下载到本地,通过唯一ID关联到资源本身,再呈现在知识服务系统中。对于可开放获取的精准医学科学数据,根据药物、基因、疾病等类型分别下载,然后依据科学数据元数据标准解析出相关数据项和对数据集的MeSH主题归类进行标注。
在此基础上,继续开展数据过滤、解析及整合工作。采用数据仓库技术(Extract-Transform-Load,ETL),完成对精准医学异构数据的提取、数据类型与正规性检查、数据的清洗、数据的解析和准备[10]等工作。根据两类资源元数据标准,规范数据格式,实现异构数据之间的转换,最终加载到精准医学数据仓库中。借助数据整合系统的反馈层,完成对数据整合流程的反馈控制、资源调度和系统优化,不断增强数据整合层的运行效率。同时设计基础管理模块,对用户日志、数据访问以及系统使用过程中的缓存和异常等问题进行管理。
3 精准医学知识服务及资源利用效果评估
随着互联网、云计算等信息技术的快速发展,医学知识服务已从传统的文献检索向围绕数据资源、科学数据等展开的新型知识服务模式转变。在知识服务模式转变的初期,产生并积累了大量的医学数据资源,形成了诸如DrugBank、OMIM、Disease Ontology等一系列的医学数据库。这些资源的结构、存储方式、组织方式、管理方式等各不相同,并且处于分散和无序的状态,利用效率不高[11]。通过信息整合,将原本分散、异构和分布的资源组织成一个整体,才能支撑知识服务的开展。由此可见,资源的汇聚与整合在知识服务中起着极为重要的作用。
为了促进知识共享,国内外医学情报机构积极探索医学领域集成化的知识服务。高东平等构建的重大疾病临床样本生命组学数据库,集成不同来源、不同尺度、不同维度、不同粒度、不同质量的临床数据和组学数据,实现了临床样本生命组学大数据共享与利用服务[12];林炜炜等在采集医院阿尔兹海默症病理基本信息、临床信息、影像信息等的基础上,连接生物标本组学(基因组学、代谢组学、表观遗传组学等)数据库,构建了医疗数据及生物样本数据平台、随访数据平台及健康数据平台[13];Linda Huang等人设计并构建了癌症基因组学的Precision Medicine Knowledge Base(PMKB),对COSMIC数据库中的癌症相关基因变异和注释信息进行结构化整合,并允许用户对知识库的条目进行编辑[14]。综上所述,目前国内外对医学领域的数据共享和知识服务还仅限于科学数据的集成服务,围绕科学数据并继续整合相应领域的前沿资讯、最新研究进展、科学文献等的服务还相对较少。
本文在设计完成精准医学资讯和科学数据元数据标准的基础上,围绕领域热点构建了精准医学专题知识服务。通过对美英等国精准医学资源的扫描,获取国外精准医学领域的前沿资讯、研究报告、最新研究进展,实现信息汇聚;基于DrugBank、CTD、TTD等发布的数据资源,实现对疾病、药物、基因等知识的提取,完成数据资源的采集、整合、存储、加工,并对外提供科学数据的公开浏览和下载;汇集华大基因、诺禾致源等国内精准医学相关的企业动态,实现全面的精准医学知识服务。
该项知识服务已经在中国工程科技知识中心医药卫生专业知识服务系统中上线并投入使用。通过对平台访问日志进行后分析发现,自精准医学专题知识服务模块上线以后,有20%的用户关注并浏览过该模块相关内容。用户较为关注(访问次数较多)的内容包括前沿资讯中关于政府推动精准医学研究的相关举措、精准医学研究重点研发计划的实施和推动过程,科学数据中DrugBank、CTD相应的数据集,下载量约为3人次/天。此外,有8%的用户在访问并下载了科学数据之后,继续在最新研究进展中查询利用科学数据开展的相关精准医学科学研究。精准医学专题知识服务面向精准医学领域科技人员,提供多维度的科研支撑服务,为领域决策者制定精准医学研究的宏观策略提供全面、开放、智能的知识资源和战略决策服务。该服务汇聚、整合精准医学领域的前沿资讯、研究进展、科学数据、企业动态等资源,提供精准医学资源的集成化服务,不但可以满足用户对精准医学相关资讯获取、信息查询和数据下载的一站式集成式服务需求,还能提高用户工作效率。
4 结论与展望
本文扫描与汇聚精准医学领域数据资源,借助数据仓储、数据过滤与解析等技术,设计了异构资源发现与整合框架,可实现不同来源、不同类型数据之间的整合与共享,构建不同类型科学数据的知识服务,为精准医学领域相关人员提供最新资讯、研究报告、会议动态、科学数据等数据资源和多维度的科研支撑服务。
为了进一步达到辅助知识创新的目的,下一步我们将围绕精准医学的资源主题开展关联数据、语义技术等技术的应用与深入探索,从语义层面上实现信息资源的组织和聚合[15],构建一个资源组织和深度聚合的整体框架体系,实现真正意义上的从资源发现到知识发现[16]。具体工作包括开展精准医学科学数据与科技文献及中国工程科技知识中心医药卫生知识服务系统中其他领域各类异构资源的深度关联,构建领域知识图谱,开展对已有资源和数据的深度标注,提升资源的揭示粒度,为平台的知识发现关联提供技术支持。
猜你喜欢
小学教学研究(2022年5期)2022-04-28 21:29:36
当代陕西(2020年21期)2020-12-14 08:14:36
动漫星空(兴趣百科)(2020年12期)2020-12-12 05:31:42
祝您健康(2020年4期)2020-05-20 15:04:20
NBA特刊(2018年11期)2018-08-13 09:29:22
民生周刊(2017年19期)2017-10-25 16:48:02
岷峨诗稿(2017年4期)2017-04-20 06:26:26
电信科学(2016年11期)2016-11-23 05:07:56
通信电源技术(2016年6期)2016-04-20 06:21:36
新校长(2016年5期)2016-02-26 09:29:01
