
研究前沿识别方法比较与应用
2017-03-21 08:44:04,,
中华医学图书情报杂志 2017年11期
, ,
随着学科的交叉融合,新的研究方向不断涌现,从中识别关键方向对于科研人员了解学科发展趋势、国家在激烈的国际科技竞争中获得优势都至关重要。研究前沿代表科学发展的热点及趋势,指引科学发展的方向,决定技术创新的路径、各国政府的科技政策制定、科技资源配置与科研方向的选择。
1 研究前沿的概念与定义
研究前沿的概念自Price 1965年提出后,不断被其他学者修订和丰富。Price认为,研究前沿具有时效性[1]。研究前沿随着时间发生变化,就一个学科领域来说,研究前沿的变化过程基本代表了这个学科的发展过程。与研究前沿相关的概念很多,例如热点主题、新兴研究领域、新兴主题、新兴趋势、潜在知识等。研究前沿的识别方法大体分为定性和定量方法两类,前者已经比较成熟,后者仍在不断发展和完善。
Research frontier和Research front都被翻译为“研究前沿”,但是这两者的意义却存在着区别[2],前者是指专家根据自己个人的科研经验判断得出的研究前沿,后者是指由定量指标分析计算得出的研究前沿。
研究前沿的定义大致分为3类:将被引文献定义为研究前沿,将施引文献定义为研究前沿,将突发词或热点主题定义为研究前沿。研究前沿的概念及演进过程如表1所示。
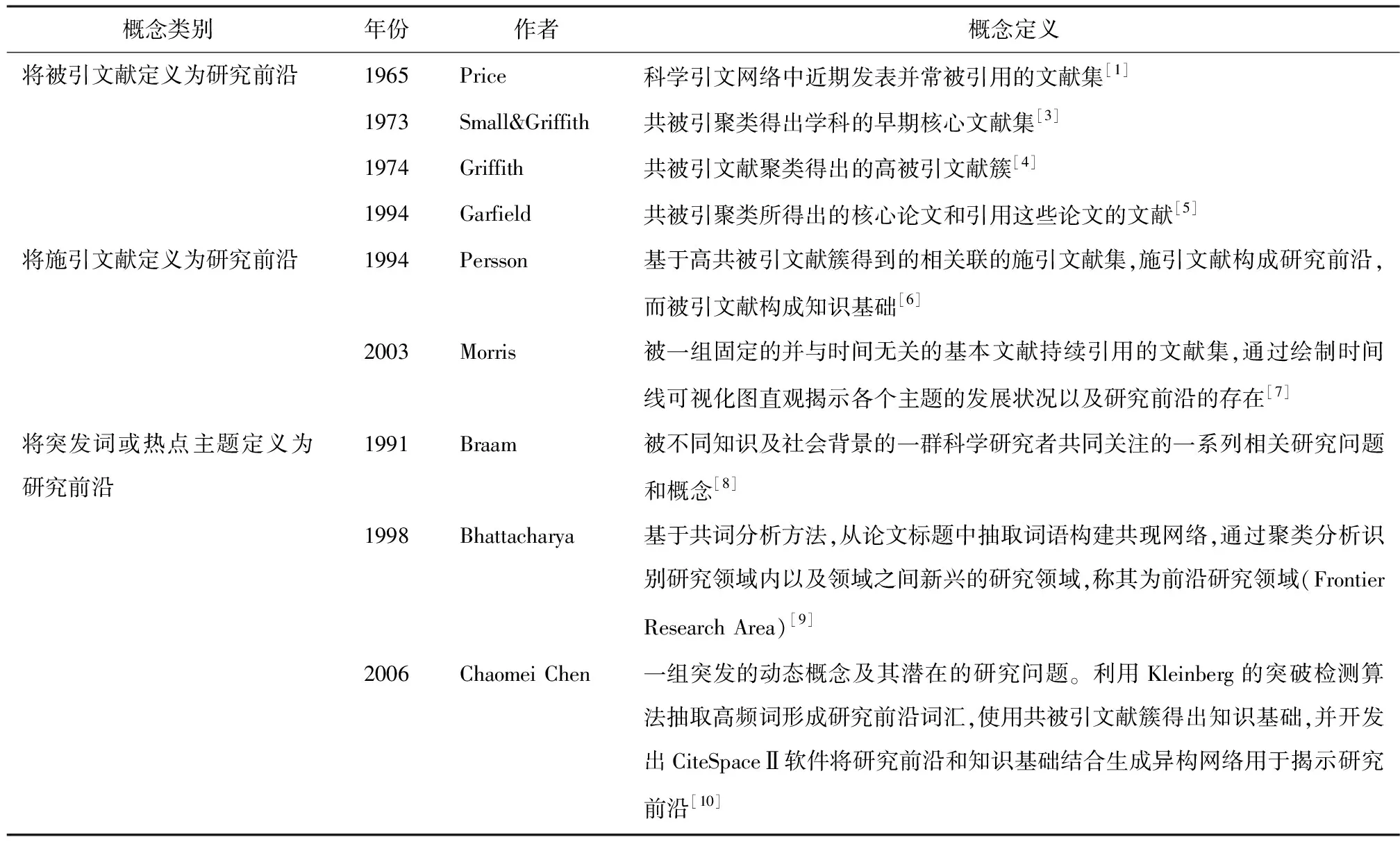
表1 研究前沿的概念及演进
信息科学领域存在着很多与“研究前沿”相似的概念,如新兴研究领域(Emerging Research Domains,Emerging Knowledge Domains,Emerging Fields,Emerging Research Area)、潜在知识(Latent Knowledge)、新兴主题(Emerging Topics)、新兴技术(Emerging Technology)、新兴趋势(Emerging Trend)、研究热点等。新兴趋势(Emerging Trend)的概念是2003年Apirl Kontostathis提出的,是指随着时间推移逐渐引起人们兴趣并得到越来越多的研究者讨论的主题领域[11];新兴主题是Naohiro 2002年提出的,是指在某个特定科学研究领域中的由多个关键词或者词组表示的一组新兴的主题领域,代表科学研究领域中最具发展潜力的研究方向或趋势[12];新兴技术是正在出现的并具有较大发展趋势和商业潜能而且可能对行业经济以及产业结构产生重大影响的技术[13-14]。它既可以是以前从未出现过的技术,也可以是已有技术经过一段平原期后,最近在原有的研究基础之上掀起的技术热潮[15]。研究热点虽然还没有明确的定义,但已经被广泛使用,例如Web of Science将发表于过去两年并被大量文献引用且被引频次位居其学术领域前0.1%的文献集称为热点论文。
与研究前沿相关的概念很多,本文借鉴相关概念的研究,探讨研究前沿识别方法。
2 研究前沿识别方法
2.1 定性分析法
定性分析是根据研究需要,广泛收集专家的意见,结合获取的资料对学科发展进程以及现状进行概括,最终形成对课题或专题研究的前沿预测和技术预见等。定性分析主要有德尔菲法、内容分析法、科技政策分析、比较分析法、社会调查法、专家咨询法、情景分析法等,有的研究综合采用几种方法[16]。基于专家意见的定性分析方法被广泛应用,其中德尔菲法、专家咨询法和文献综述法是比较常用的分析方法。
基于德尔菲法的前沿预测方法较为成熟、权威,在国家科技发展战略制定中起着至关重要的作用。例如美国成立专门的利益非攸关战略专家委员会,负责对美国当前的技术水平与影响力、世界科技发展态势、产业结构性变化进行分析、评估和预见,形成咨询报告;再依据战略规划,成立科技发展优先领域专门委员会,通过广泛调研,择优筛选,制定关键技术选择标准,委托世界技术评估中心等咨询机构进行社会经济需求分析和国内外相关技术调研的此基础上形成报告[17]。欧盟2014 年实施 “地平线 2020”计划,其中欧盟科技计划的咨询工作,主要依靠各行业各领域的专家。科技战略规划、政策效果评价、项目评审评估等都需要组建相应专家组或专家委员会提供咨询服务。其基本原则:欧盟委员会及有关部门可根据工作需求成立专家组,专家组至少由 6 人组成且至少召开两次专家组会议,作为咨询实体的专家组主要在立法建议、政策倡议、战略规划与举措的实施等诸多方面为欧盟委员会或有关部门提供专业咨询服务支持[18]。欧盟于2007年成立了欧洲研究理事会(ERC),为欧盟国家的前沿学科提供科研经费,通过竞争机制择优资助前沿学科和交叉学科的研究以及新技术和新兴领域的开拓性探索,并使用风险性、适用性、跨学科性、创新性4个文献计量指标进行评估,评估结果由ECR同行评审小组判断裁决,经过计量经济学决策模型决策,选择资助前沿项目。基于定性分析的前沿识别方法汇集了专家的智慧和经验,但其对专家的水平要求较高,并受专业知识面、专家主观认识以及专家时间精力等不确定性因素影响,比较耗时,成本较高。
2.2 定量分析法
20世纪60年代文献计量学快速发展,有关研究前沿的研究随着SCI 引文数据库的建立逐渐兴起,以文献计量学为基础的定量分析法受到关注。目前用于识别研究前沿的定量分析法主要有基于引文的前沿监测研究方法和基于内容的前沿监测研究方法。
2.2.1 基于引文的前沿识别研究
2.2.1.1 共被引分析
自1973年Small提出“共引”(Co-citation)的概念[3]后,Garfield和Persson也提出了共被引分析方法[4-5]。共被引分析能够根据论文共同被引用的频次和论文之间共同被引用产生的密切程度,聚类得出某领域内的研究前沿,在前沿研究中比较常用。基本方法是:首先收集某一主题相关的文献及其参考文献字段并建立被引文献索引;然后选择被引用次数在一定阈值内的论文(高被引论文)作为研究对象,计算一对被引用文献的共被引频率;采用单链聚类方法对被引用文献进行聚类分析,先随机选择一篇文献,然后搜索所有与其相关的文献单元,进而形成共被引的文献簇;根据聚类结果和前面统计出的共被引频率,用多维尺度分析绘制出研究前沿的结构图。多维尺度分析通过低维空间(通常是二维)揭示文献间的联系,并利用平面距离来反映文献之间的相似程度;然后使用该文献簇中的文献题目中经常出现的词语或短语为研究前沿命名;最后在该领域专家的帮助下就可以比较准确地揭示该学科领域中的研究前沿[19]。
ESI Research Fronts是ESI数据库的组成部分之一,在近5年高被引论文的基础之上,使用共被引分析和聚类分析得到各学科领域的ESI研究前沿,科睿唯安从2013年起将该方法应用于ESI每年定期发布的“研究前沿”报告[20]。ESI 研究前沿以ESI高被引论文(论文的被引频次在同出版年、同学科论文中位居前1%的论文)为起点,基于共被引分析方法用单链接聚类算法聚类识别得出。他们认为,ESI研究前沿与科学研究前沿存在着很大程度上的重合关系(见图1),并且ESI研究前沿是洞悉科学研究前沿的重要起点。在聚类构建研究前沿时,按照ESI研究前沿的共被引强度阈值判断两篇文章A和B是否构成一个共被引对的计算方式如下:
其中cocitation frequency是论文A和B的共被引频次,Citation A是论文A的被引频次,Citation B是论文B的被引频次。
当cosine similarity≥0.1时,说明两篇文章可以组成共被引对。如果共被引对(A,B)中的一篇文献和共被引对(C,D)中的一篇文献具有较强的共被引关系,则 (A,B)和(C,D)将形成更大的聚类。当组成某一研究前沿的核心论文数过高(>50)时,则调高阈值,但须保证一个ESI研究前沿最少有2篇核心论文。最终从组成ESI研究前沿的核心论文的题目中提取关键词,组成ESI研究前沿名称[21]。有学者通过作者共被引分析,发现使用多种类型的数据源识别研究前沿的效果要好于使用单一的论文数据[22]。在聚类方法的选择中,除了单链聚类方法以外,双聚类方法能够对高被引文献和引用文献进行双向聚类,可以反映共被引分析过程中被引文献与引用文献的对应关系,因此也被广泛使用。例如杨颖、崔雷参考Persson对研究前沿的定义,在共被引分析方法中应用双聚类方法得到了护理学领域的研究前沿和知识基础[23]。
共被引方法的有效性已经得到广泛验证,然而论文从发表到被引用需要一定的时间,因此共被引分析法具有一定的滞后性,并且共被引强度阈值的设定以及聚类的大小都需要人工干预,结果在一定程度上会受到人为因素的影响。
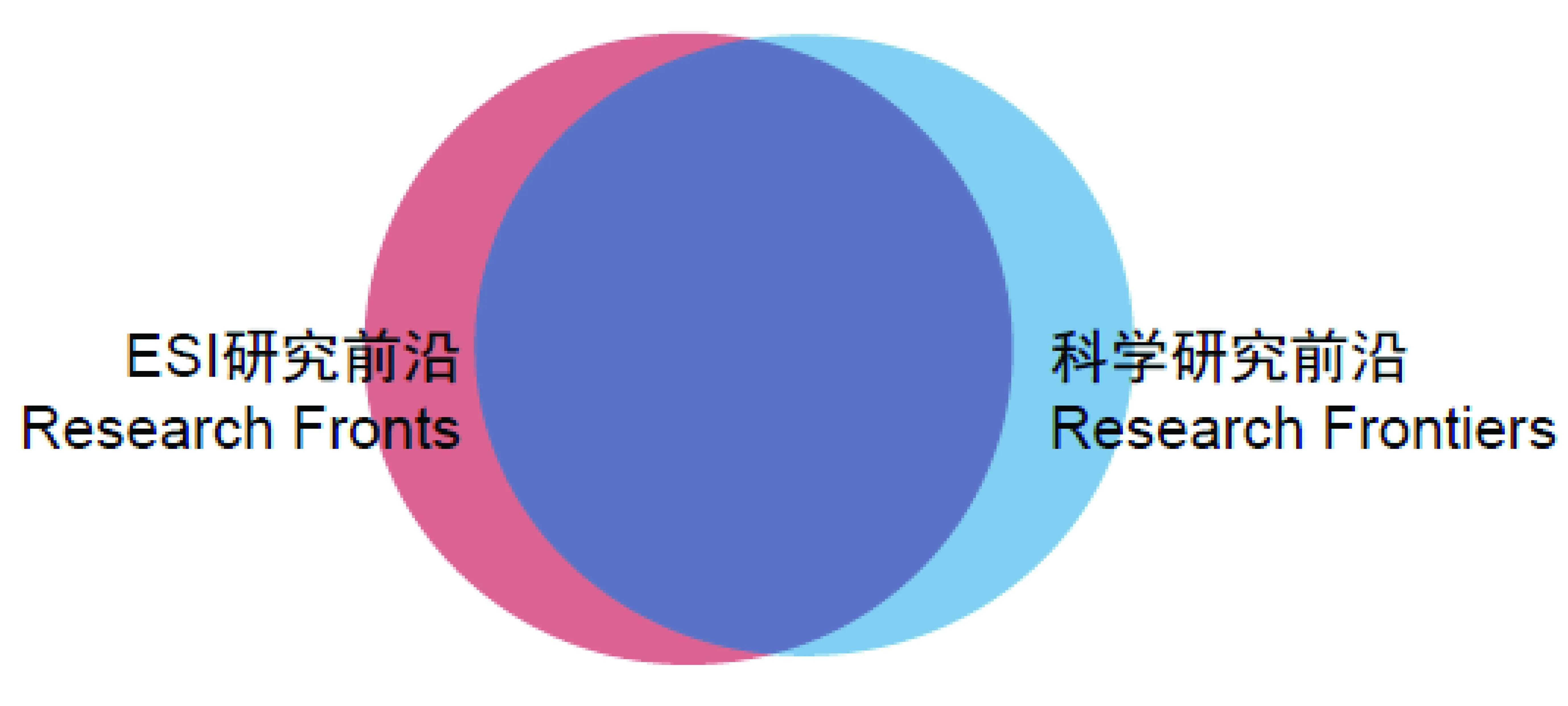
图1 ESI研究前沿与科学研究前沿关系图
2.1.1.2 文献耦合分析
1963年Kessle教授提出了“文献耦合”(Bibliographic Coupling)这一术语[24]。无论是文献耦合还是共被引,都是对文献相关性的一种测量。文献耦合和共被引在概念上存在着严格的对偶关系,但文献耦合是静态的,而共被引聚类分析随着时间推移和新的文献加入到引用网络中而变化。
1974年Weinberg对文献耦合进行了较为全面的研究,并将它应用于科学学研究中[25]。
此后,更多的学者进一步发展了文献耦合的分析方法[5-6]。
采用文献耦合识别研究前沿的步骤为:首先对某一主题相关的文献及其参考文献字段建立引文索引,之后排除没有达到一定耦合频率阈值的文献并建立引用矩阵并求得两个文献的耦合频率;使用谱系聚类方法对文献单元样本进行聚类分析。谱系聚类方法会产生一个二叉树,二叉树的‘叶’可以将文献簇形象地表示为线性序列,就可以进一步分析得到研究前沿的结构;将二叉树产生的结果定为纵轴Y,加入时间轴X就可以得到研究前沿的时间演化图。最后提取、使用在该文献簇的文献题目中经常出现的词语或短语对研究前沿的命名,并在该领域专家的帮助下,对各研究前沿进行比较准确的描述[19]。
2005年BoJarneving指出,需要更多详细的定性研究来比较共被引分析和文献耦合分析识别研究前沿的效果[26],并于2007年使用文献耦合聚类分析方法识别出核心文献和领域研究前沿[27]。
2012年Schiehd借鉴Persson的定义,提出可以从基于文献耦合聚类的文献簇中识别研究前沿,从共被引文献簇中识别知识基础,并提出了模仿地理地图的二维和三维图像探测研究前沿和研究基础的可视化方法[28]。
还有不少学者使用专利文献识别研究前沿,如Huang MH[29]、Boyack KW等[30]认为文献耦合聚类方法的识别效果优于共被引聚类方法,因此李蓓、陈向东[31]用基于专利引用耦合聚类的方法识别纳米领域的新兴技术。由于发明专利文献能够反映技术的价值和新颖性,因此专利文献分析是研究前沿识别方法中的一种新思路。
基于文献耦合的分析方法虽可在一定程度上弥补共被引分析方法的时滞性,但仍存在不足。因为1篇论文发表后,其参考文献不会再有改变,文献耦合分析的数据集不会像共被引分析那样随时间发生变化,所以基于文献耦合的方法在研究前沿主题演化上受限。此外,虽然两篇文献同时引用了1篇文献,但有可能引用了文献的不同部分,引用目的也可能不同。此外,不论是文献耦合分析还是共被引分析,均不能自动描述筛选获得论文的主题,而需要通过人工筛选出论文标题、关键词进行标识,或是通过专家判断解读。
2.1.1.3 直接引用分析
自2004年Garfield采用直接引用网络的方法得出一个知识领域文献的历史演化图谱(Historiography Mapping)[32]后,基于直接引文的方法已取得初步进展。
2006年,Klavans和Boyack[33]在比较基于直接引用方法和共被引方法的聚类结果时,发现直接引用更适用于相似文献的聚类分析。
2010年,Klavans 和Boyack指出,直接引用分析可以更早、更直接地揭示引文网络所代表的研究领域结构特征以及发展趋势,但在精确性方面文献耦合及其复合方法略优于共引分析,而直接引用方法最不准确[30]。
日本东京大学的Shibata,Kajikawa,Matsushima和Sakata等学者组成的研究团队推动了基于直接引文探测研究前沿方法的发展[34]并在2009年分别构建了氮化镓(Gallium Nitride)、复杂网络(Complex Network)、碳纳米管(Carbon Nanotuhe)3个领域的3种引文网络。他们通过使用Newman[35]用2004年提出的拓扑聚类算法将引文网络聚类得到各个领域的文献簇探测研究前沿,通过对比文献簇的可见性(标准化后簇的大小)、速度(平均出版年)、拓扑相关性(密度)3个指标判断基于直接引用、共被引、文献耦合3种引文网络方法在识别研究前沿上的效果。结果表明基于直接引用的方法可以识别到更大更早的新兴簇,在识别研究前沿方面表现最好,文献耦合次之,共被引则表现最差。此外,基于直接引用方法得出的论文的内容相似度最高。由于最大范围地包含了核心论文,因此缺失研究前沿的风险性最小[36]。同年,该团队利用直接引用分析,并使用Newman的拓扑聚类方法得到每个簇内链接密度高的紧密文献群,采用A.T.Adai等开发的LGL模型绘制成动态可视化大型网络以更加直观地理解文献簇,描述了太阳能电池研究的技术趋势,对能源和太阳能电池的研究结构进行可视化分析,有效预测了新兴的研究领域[37]。2011年,他们用同样方法探测再生医学领域研究前沿并得到专家证实,预测了成人干细胞和成体干细胞方向的研究前沿[38]。他们还采用直接引用方法,通过对比太阳能电池相关论文与专利2种数据源的文献聚类结果,识别更具商业价值的潜在技术前沿[39]。
研究表明,基于引文分析的研究前沿识别方法中,共被引和文献耦合方法较为常见;而基于直接引用的方法识别效果最好,很有可能成为未来研究前沿识别的趋势。
为获得最好的研究效果,多数分析人员会综合运用上述引文分析方法。基于引文的研究前沿识别方法存在引用滞后性及分析对象间接性的问题,因此从能够更直接体现研究前沿的论文研究内容入手进行前沿探测受到很多学者关注。
2.2.2 基于内容的前沿识别研究
2.2.2.1 词频分析
词频分析是文献计量学中传统和具有代表性的一种内容分析方法,其基本原理是通过词出现的频次来确定研究热点及其变化趋势[40]。词频分析能够通过给定阈值的关键词反映某研究领域热点,词频越高,表示研究人员对该研究领域关注度越高。对文献的主题内容进行研究,既可揭示其研究热点,又可结合词频出现的年份揭示研究主题的时间分布,进而识别学科研究热点及趋势[41]。
2002年Kleinberg提出的突发词检测算法(Burst Detection Algorithm),可用于检测某学科领域内研究兴趣的突然增长[42]。这个算法原本是用来检测单个词的突然出现,但也适用于时间序列的多词专业术语和引文分析[43]。
在实际应用过程中,基于词频来识别研究前沿的方法过于单薄,因此大都结合其他方法使用。如Mane以1982-2001年Proceedings of the National Academy of Science of the United States of America(PNAS)中的论文为数据集,用Kleinberg突发词检测算法抽取高频词,然后利用共词方法识别PNAS中的主要研究主题和新兴趋势并绘制出可视化图谱,通过咨询领域专家验证词频分析在识别研究前沿以及主要趋势的合理性及实践价值[44]。
2006年,陈超美开发出基于主题词分析的CiteSpaceⅡ可视化软件[9],利用突发词检测算法,从题目、叙词、摘要以及文献记录的标识符中抽取出数量上发生突变的专业术语(Burst Terms)来识别新兴的学科前沿。经过对大量来源文献动态分析后可以得出数量变化趋势,对突发词进行检测并发现聚类来识别和表示研究前沿,再从含有突发词的文献的引文中得到知识基础[45]。
2017年,Xiaorong He等使用突发词检测算法分析关键词和参考文献,得到有序加权平均(OWA)算子研究的新兴趋势[46]。
词频分析方法的不足在于词频阈值的确定存在较强的主观性,目前学者大多将高频词汇阈值设定为Top50,但是只筛选高频词汇进行分析会忽略可能代表研究热点或新研究趋势的低频词汇。
2.2.2.2 共词分析
Callon 1983年提出的共词分析技术,是一种根据文本信息项之间的关联强度进行有效可视化的内容分析技术[47]。共词分析法对文献内容的挖掘更加深入准确,最大程度发挥了词频分析的优势,因此越来越多的研究者采用共词分析方法来识别研究前沿。随着研究的深入,共词分析方法不断改进,分析词从索引词、关键词发展到自由词,从单个词语、双词短语再到多词短语,词语共现范围可被限定在同一句子之内、数十个词之内、同一段落之内或者同一篇论文之内等[48]。
1984年Rip等采用共词分析方法对10年内生物技术领域的论文进行分析揭示了该领域的现状和研究前沿,指出识别研究前沿要结合科学计量方法(ScientometricMethod)和专家认知分析(Cognitive Analysis)[49]。
1993年Kostoff提出了数据库内容结构分析法(Database Tomography,DT),在持续改进的同时先后进行了技术竞争情报和高技术领域研究前沿分析等应用[50]。
1998年,Bhattacharya抽取论文标题中的词语构建共现网络,通过聚类分析来识别凝聚态物理研究领域内和领域间的新兴研究领域,并指出这种方法能比基于引文的方法更好地探测科学领域的研究活动[9]。
在前沿识别研究中,许多学者会综合应用多种方法。如2017年Carlos Olmeda-Gómez等使用基于关键词共现方法和基于共被引网络并结合突发词检测算法2种分析技术,从知识基础中识别研究前沿,最终得出西班牙图书馆和信息科学产出的主题背景和前沿[51]。
由于词语在不同的语境下含义会有所不同,单个词语并不能表达具体的意思,只有出现在句子中才会有意义。因此仅共词分析方法不足以揭示研究前沿。
2.2.2.3 文本挖掘
基于文本挖掘的前沿监测方法主要包括新兴趋势探测(Emerging Trend Detection,ETD)方法、非相关知识发现方法和基于概率主题模型方法。A.Kontostathis等2003年提出的新兴趋势探测(ETD)概念,是指监测某个领域中热点信息的动态趋势,当探测到最新发展态势时给以提示[11],因此从本质上讲ETD也是一种研究前沿探测研究[52]。
1986年,D.R Swanson首次提出“基于非相关文献的知识发现法”,从表面没有任何联系的文献内容中识别出新颖的、潜在有效的并且最终可理解的知识的信息研究方法[53]。非相关知识发现方法摒弃了传统的引文分析方法,利用自然语言处理技术对科技文献内容进行深入分析,从中发现相关知识点,进而发现潜在的知识关联[54]。
D.M.Blei等于2003年提出了LDA模型,并对文本进行“隐性语义分析”(LSA)[55];于2006年又提出动态主题模型[56],主要研究如何扩展LDA模型,让动态LDA模型可以处理具有时间戳的文档数据集,实现动态主题的探测与追踪。LDA 模型理论完备、参数比较容易设置并且有良好的泛化能力,能以词组的形式表示主题词-主题-文档之间的语义关系,改善了共词分析不能有效表达词汇间语义关系的缺陷,使分析结果更加准确、可靠、成熟。
3 研究前沿识别方法的应用
研究前沿的识别和选择对于政府制定科技发展战略或者企业制定指导性的发展规划都具有支撑决策的重要意义。
3.1 研究前沿识别方法在政府决策中的应用
日本技术预见工作始于20世纪70年代。1970年,日本科技厅采用德尔菲法进行关键技术和通用技术的选择[57],进行第一个预见分析。日本为了成为全球科学技术的领导者并保持其科技强国的地位,从第三期《科学技术基本计划》(2006-2010)开始将研究前沿作为首要研究课题,确定生命科学、信息通信、环境、纳米材料等 8 个重点领域作为日本 2006-2010 年科研攻关的重点,又从中遴选确定了 273 个重要研发课题。这些课题是通过技术预测、国际比较、公民调查等多种方法挑选出来的,其设定的目标大多是采用定性与定量相结合的方式确立的[58]。
韩国自1993年起,每5年进行一次技术预见工作,截至2011年,共进行了4次技术预见。其中前两次技术预见运用了德尔菲法,第三次则增加了未来社会与社会需求展望、未来社会情景描述等预测方法。2009年,韩国采用文本挖掘、论文网络分析等方法,进行了为期两年的“第四次技术预见”,以便更好地把握社会和科技发展的态势。国家科学技术审议会负责审议和批准技术预见的结果,其下设的技术预见综合委员会,由来自科技领域和人文社会领域的20位专家构成,负责技术预见工作的总体协调与组织。技术预见综合委员会下设未来技术评估委员会、未来展望委员会和技术预见学科委员会3个委员会,由各领域专家组成,分别负责对上一次技术预见结果进行评估、对未来社会进行展望和分析、以未来社会展望为基础遴选未来技术[59]。
加拿大创新基金会(CFI)通过研究技术的可发展性、创新能力、对国家的有益性三个重要标准来评估所有提案,根据满足审查标准的程度,选择最优的提案,由研究人员、研究管理人员和私营部门管理人员组成的审查人员审查后向CFI提供资助建议。
3.2 研究前沿识别方法在企业中的应用
大型企业通常已经占据一个或多个领域的领军地位,为了谋求更长远的发展,它们通常会对有潜力的重要领域做出预测。几乎一半的美国“财富”1000强企业都使用技术预见方法进行企业战略规划。这些公司一般规模较大,通常都有自己的战略规划部门负责进行前瞻性和面向未来的研究。例如飞利浦、朗讯科技、西门子、戴姆勒-克莱斯勒以及壳牌等大型公司已经开发出自己的未来展望系统,并通常采用基于专利分析、文献分析、情景分析、调查的方法,或者使用德尔菲法和技术路线图进行决策。惠普、英特尔和谷歌等许多大公司对技术创新预见,都率先使用“预测性市场”,即通过一个虚拟的交易机制,从关于未来可能的技术发展方向上挖掘所有员工的知识和经验的方式来做出决策判断。这种方法类似而又不同于基于专家的预测方法,是一种比较新的方法[60]。
4 讨论
目前,对研究前沿还没有明确、统一的定义,也缺少一套客观公认的标准化指标体系。研究前沿的定性识别方法大多是基于专家预测,专家的主观意见占有很大比重,同时对专家的专业素养要求较高。虽然不少国家和大型企业借助专家的意见来辅助战略决策,但在实际应用中,这种方法费时费力,并不能及时满足研究前沿识别的需求。
共被引分析、文献耦合分析、直接引用分析以及共词分析等方法在探测研究前沿中应用广泛,可以根据使用情况及应用环境的不同选择适合的方法。共被引分析、文献耦合、共词分析大多使用单链接聚类算法等传统的聚类技术,存在主观设定阈值的问题,需要借助领域专家的经验以获得更好的聚类结果。复杂网络领域的社团结构探测算法可通过网络结构的特征直接获取最优化的聚类结果,不会存在阈值主观调整的问题,因此将来可能会有更多的社团结构探测算法应用于科学网络中。日本的Shibata团队证明,基于直接引用的方法识别研究前沿效果优于基于共被引、文献耦合的方法,有可能成为研究新趋势。基于引文分析的方法虽然应用广泛,但依赖于能够提供引文关系的数据库,而在现实中这样的数据库是相当有限的。从这个意义上来说,基于词的分析方法的应用空间更为广阔。基于文本挖掘的前沿监测方法直接通过对文本内容的分析,自动识别研究前沿,较为简便快捷,在前沿研究中会得到越来越多的重视和应用。
与期刊论文数据相比,专利、各国政府部门的科技规划、各国基金机构资助的重点领域的项目申请书和研究报告以及重要组织、学会、科研机构撰写的相关研究前沿的研究报告等多种数据更能及时反映科学研究前沿,会越来越多地应用于科学前沿识别。
猜你喜欢
数学物理学报(2022年2期)2022-04-26 14:08:28
电子测试(2017年15期)2017-12-18 07:19:27
智能系统学报(2015年4期)2015-12-27 09:38:39
大型铸锻件(2015年5期)2015-12-16 11:43:20
浙江大学学报(工学版)(2015年11期)2015-03-01 01:20:00
浙江大学学报(工学版)(2015年5期)2015-03-01 01:18:17
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:32
电子设计工程(2015年6期)2015-02-27 12:04:53
新闻前哨(2014年1期)2014-03-12 22:10:06
湖南理工学院学报(自然科学版)(2014年1期)2014-02-28 22:12:27
