
基于粒子群算法的基因表达谱聚类分析方法
2017-03-16 02:29陈佳瑜
重庆理工大学学报(自然科学) 2017年2期
李 梁,陈佳瑜
(重庆理工大学 计算机科学与工程学院,重庆 400054)
基于粒子群算法的基因表达谱聚类分析方法
李 梁,陈佳瑜
(重庆理工大学 计算机科学与工程学院,重庆 400054)
双向聚类算法可以发现基因表达谱中隐藏的信息。为了寻找规模较大的基因相似矩阵,结合粒子群算法强大的搜索能力,提出了GP-Cluster双向聚类算法。基于粒子群(PSO)算法,引入Sigmoid函数进行动态调整,并在粒子飞行过程中加入了遗传算法(GA)“优胜劣汰”的思想,增加粒子运动的多变性和随机性,避免算法陷入局部最优。实验结果证明:相比GA算法和PSO算法,改进后的混合粒子群算法GP-Cluster能找到质量更佳的双向聚类,取得更好的聚类效果。
数据挖掘;基因表达谱;双向聚类;粒子群算法;遗传算法
随着生物技术的迅速发展,出现了基因芯片和DNA微阵列等高通量检测技术,人们已经可以对某一特定状态下的组织或细胞进行基因表达谱的测序。而具有相似表达谱的基因之间很有可能存在某种联系,可以通过聚类的方法,将表达水平相近的基因聚在同一个类中,从而发现未知基因的功能和具有生物科学价值的基因信息。
目前,基因表达数据分析最常用的方法是聚类。但是传统的聚类方法在分析基因数据时会受到很大的限制,因为某些基因只在部分特定条件下才会表现出相似特性,而不是这些基因在所有条件下表现都相似。为了更好地寻找有价值的基因聚类,Cheng和Curch[1]于2000年提出了一种基于贪心策略的双向聚类算法(又称CC算法),第1次将双向聚类应用于基因表达谱的聚类上。该算法抛弃了传统聚类只从单方向上寻找相似特征的方法,而是同时从行和列两个方向进行聚类,这样可以找到隐藏在局部数据中的生物信息。其基本思想是通过删除或添加某些行和列减少基因矩阵在表达上的差异性,从而产生双向聚类。
本文针对基因表达谱聚类的复杂性和多变性,提出了一种基于粒子群算法(particle swarm optimization,PSO)和遗传算法(genetic algorithm,GA)的混合双向聚类算法,称为GP-Cluster算法。
1 双向聚类
CC算法在被提出时就给出了双向聚类(bicluster)的定义:
定义1 设X是基因集,Y是对应的表达条件集,aij是基因表达矩阵A中的元素。设I,J分别为X,Y的子集,则(I,J)对指定的子矩阵Aij具有以下平均平方残差:
(1)

双向聚类的目的就是从基因表达矩阵中找到满足条件的子矩阵,使子矩阵在表达波动上尽可能一致。目前应用比较广泛的双向聚类的模型有4种:等值模型、加法模型、乘法模型和信息共演变模型[2]。
2 粒子群算法和遗传算法
2.1 粒子群算法
相较于其他群体智能算法,粒子群优化算法具有概念简明、易于实现、收敛速度快、参数数量少等特点,是一种高效的搜索算法[3-5]。同时也存在一些缺点,PSO算法在求解复杂多峰问题[6]时速度较慢,容易陷入早熟,并且算法的收敛精度不高[7]。
在PSO算法中,每一个粒子(particle)都代表一个解,一系列的粒子组成群(swarm)。与其他群体智能算法不同,粒子群算法是将每个粒子个体看成解空间中的一个没有体积和质量的微粒,以一定的速度飞行寻找最优解,这个速度是根据粒子自身的飞行经验和其相邻粒子的飞行经验共同决定并进行动态调整的[8]。通常情况下,粒子追随当前的最优粒子活动,经过逐代搜索最后得到最优解。
标准粒子群算法的数学描述如下[9]:
设有D维搜索空间,总的粒子数为N。Xi=(xi1,xi2,…,xin)为第i个粒子的当前位置;Vi=(vi1,vi2,…,vin)为第i个粒子的当前飞行速度;第i个粒子在飞行过程中的最优位置为Pi=(pi1,pi2,…,pin),所有粒子的全局最优位置为Pg=(pg1,pg2,…,pgn)。每个粒子的位置变化公式为:
Vid(t+1)=wvid(t)+c1r1(pid(t)-
xid(t))+c2r2(pgd(t)-xid(t))
(2)
Xid(t+1)=xid(t)+vid(t+1)
1≤i≤n,1≤d≤D
(3)
其中:w为惯性权重,w较大时适合对解空间进行大范围的搜索,w较小时适合进行小范围的搜索;c1,c2是学习因子,为常数;r1,r2是[0,1]之间的随机数;vid=[-vmax,vmax],vmax是常数。
2.2 遗传算法
遗传算法是一种随机搜索算法,它借鉴了生物界的遗传选择机制,适合处理复杂的非线性优化问题。
遗传算法的基本思想是“优胜劣汰,适者生存”,模拟自然界的生物由低级向高级的演化过程,根据问题的目标函数构造一个适应度函数,问题的每一个解都对应1条染色体,对1个由多个解构成的种群进行初始化、变异、交叉,经过多代繁衍,将获得的适应值最好的个体作为问题的最优解。
遗传算法可以形式化地描述为
GA=(POP(t),N,l,s,g,p,f,t)
(4)
式(4)中:l表示染色体的二进制串的长度;s代表选择策略;g表示遗传算子;p表示遗传算子的操作概率;f表示适应度函数;t为终止条件。
遗传算法从初始给定的多个解开始,通过一定的规则逐步迭代产生新解。初始给定的多个解的集合被称为种群,它是问题的解空间里的一个子集,记为POP(t),其中t为迭代步,POP(t)中每一个个体的适应度为fi=fitness(POPi(t))。
相较于粒子群算法,遗传算法采用二进制编码,因此更适合求解离散型问题,特别是0-1非线性优化问题[10-11]。粒子群算法没有交叉和变异操作,而是根据自己的速度来决定搜索方向,并且每一个粒子都拥有记忆功能,能记住搜寻到的最佳位置。
3 混合粒子群算法模型
在本算法中,每一个粒子都看成是一个小的双向聚类。在粒子运动中,表达相似的粒子合在一起成为一个新的较大的双向聚类。算法以随机产生的解为初始解,通过二进制编码,以上一代粒子的平方残差值H为适应度函数,采取精英选择策略,保存较优的粒子进入下一次迭代。为了防止算法收敛过早,使粒子的运动陷入局部最优,在迭代寻优的过程中引入了遗传算法的交叉、变异的操作,使粒子的运动更随机多变。
3.1 惯性权重调整
在粒子群算法中,惯性权重平衡着粒子的全局和局部搜索能力[12],具体是指上一代粒子速度对当前代粒子速度的影响。权重较大时,算法的全局搜索能力较强;权重较小时,算法的局部搜索能力较强。本文粒子群算法的权重引入Sigmoid函数使其进行非线性递减[13]。实验结果表明:动态调整惯性权重可以得到较好的结果,并能提高问题的求解效率。
(5)
式(5)中w0和λ为常数。
3.2 编码方式
设A是一个M行N列的基因表达矩阵,M为实验条件数,N为基因个数。对任意一个基因或条件,只可能有2种情况:一种是在算法最终产生的双向聚类里面;一种是不在最后的双向聚类里面。所以,算法需要采用0-1二进制编码。每一个粒子都由一个0-1二进制串构成,这个二进制串的长度为N+M,即为基因数N和条件数M的和,前N位编码基因,后M位编码实验条件。若基因或条件在双聚类里面,则对应位置上的值为1;若不在,就设为0。设粒子种群规模为P,则粒子初始位置X就是一个P行的0-1向量组成的矩阵。
3.3 算法描述
GP-Cluster算法最后是要寻找均方残差值H越小越好的最优解,具体算法描述如下:
1) 初始化种群规模P、加速因子、权重因子、最大迭代次数等参数,产生初始粒子X和速度V。
2) 计算目标函数值,产生第1代粒子的均方残差值。
3) 初始化个体极值和群体极值:挑出第1代粒子中最好的个体,也就是均方残差值H最小的个体。
4) 迭代寻优:先要对每一代粒子都计算1次自适应的权值,更新粒子的速度和位置,对粒子进行交叉和变异的操作,然后计算目标函数值,更新个体最优和群体最优。
5) 当前迭代次数到达初始设定的最大迭代次数时,算法结束。
4 实验及结果分析
4.1 实验数据
急性白血病基因表达谱(leukaemia)数据集[14]共有38个急性白血病样本和7 129个基因,其中:27个被诊断为急性淋巴性白血病(ALL);11个被诊断为急性骨髓性白血病( AML)。乳腺癌基因表达谱(breast cancer)数据集[15]共有1 213个基因和98个样本,其中:34例在5年内癌细胞发生转移;44例表现正常;20例BRCA基因变异。
4.2 实验分析
双向聚类算法实验使用Matlab对数据进行分析和处理,采取Max-Min方法对数据进行归一化处理,如式(6)所示。其中:x是样本数据中的原始值;X是标准化后的值。
(6)
算法的结束条件,即最大迭代次数为200;种群规模为200;加速因子c1,c2为0.15。粒子的最大速度和最小速度不宜过大,否则容易收敛过早,陷入局部最优。本研究把最大速度设为0.1,最小速度设为-0.1,交叉率为0.8,变异率为0.2。
分别用粒子群算法、遗传算法和本文中提出的GP-Cluster算法对上述2个数据集进行测试。测试结果见表1~2和图1~4。
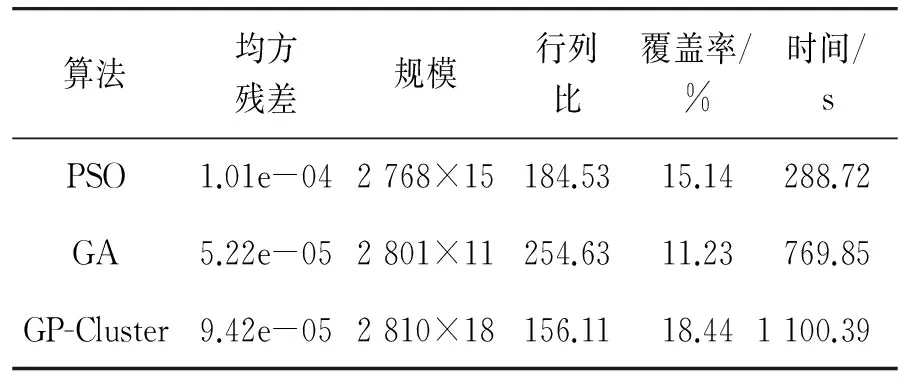
表1 急性白血病数据集实验结果比较

表2 乳腺癌基因表达数据实验结果比较
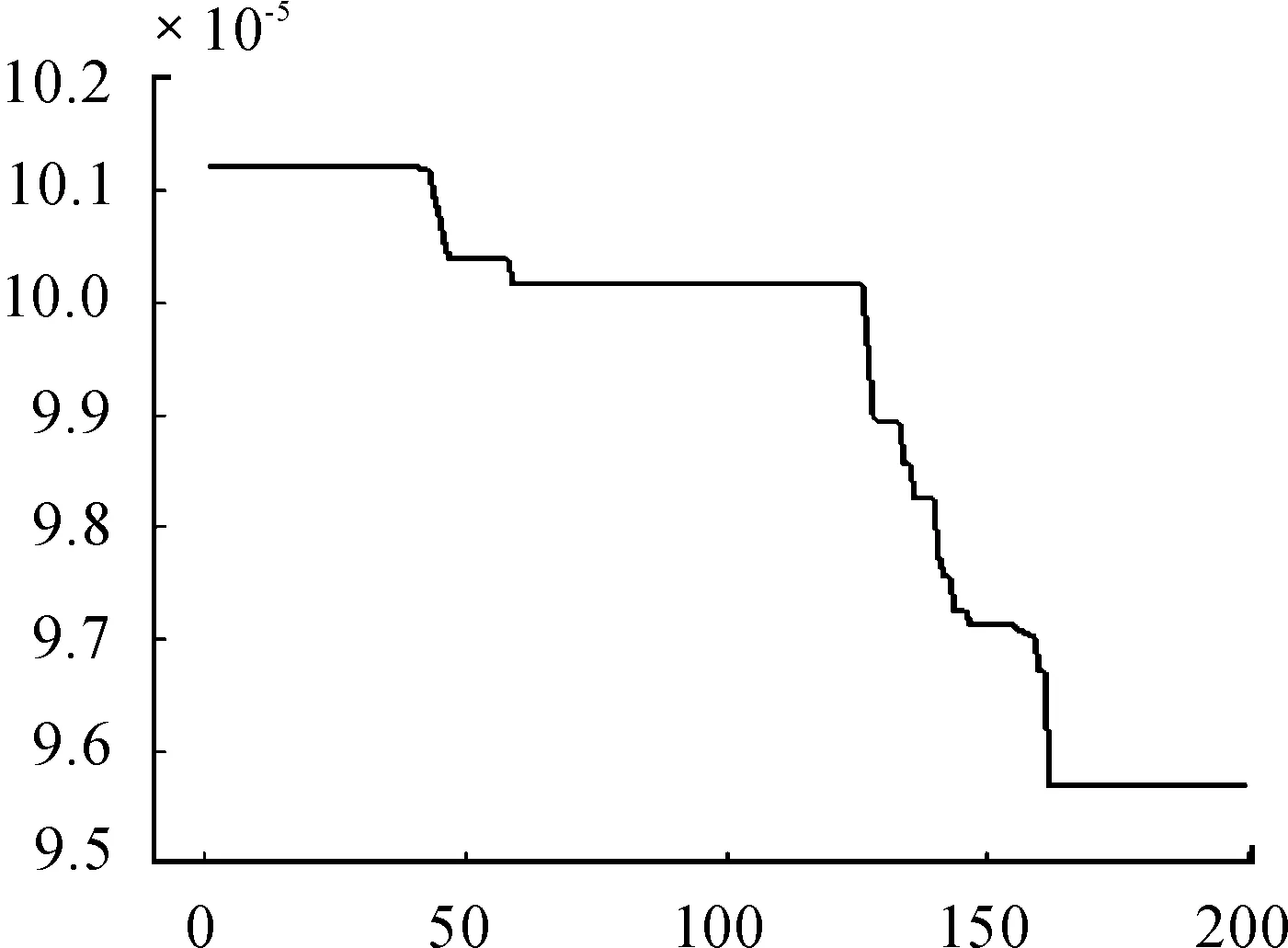
图1 GP-Cluster(急性白血病)迭代曲线
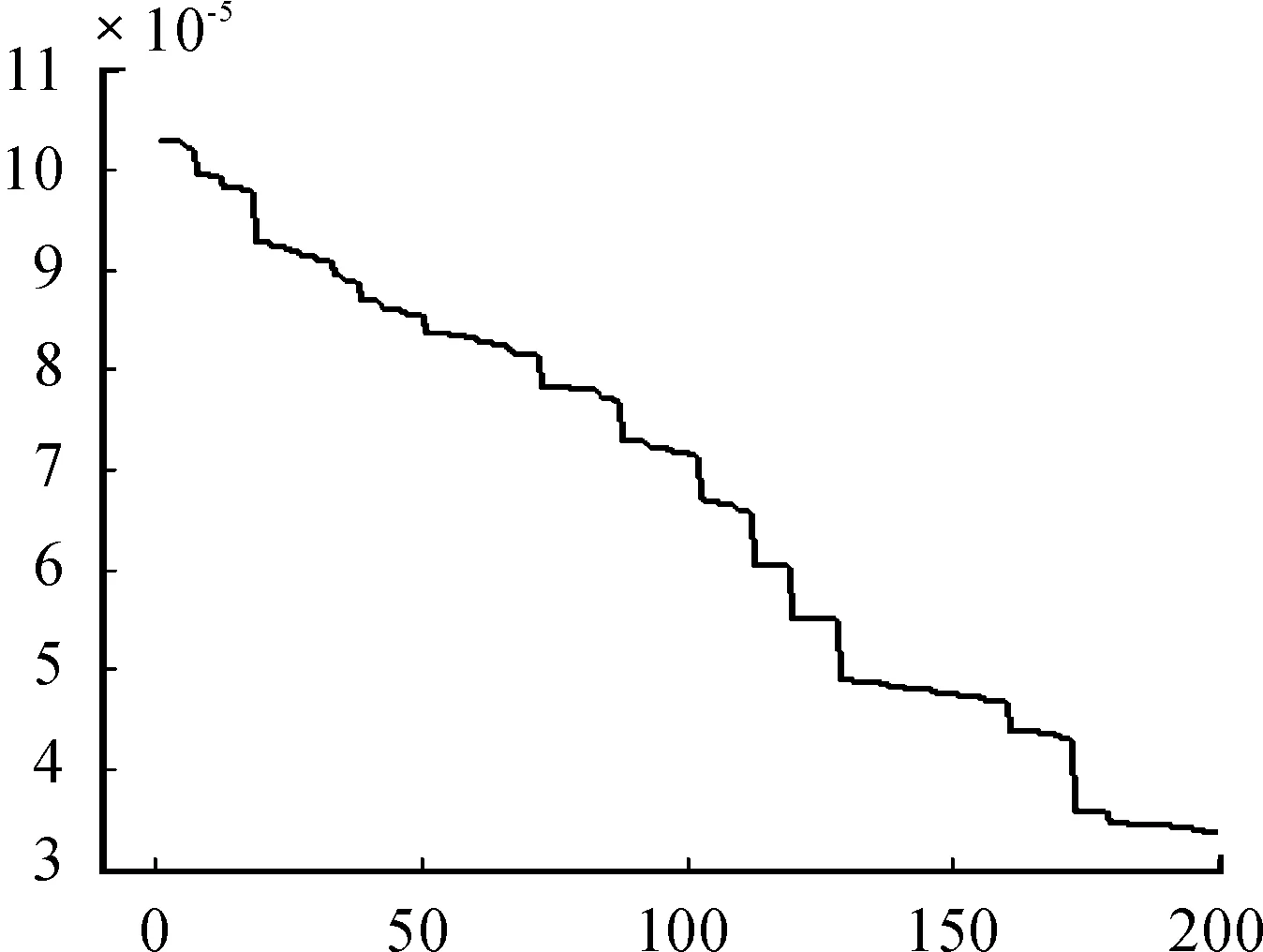
图2 GA(急性白血病)迭代曲线

图3 GP-Cluster(乳腺癌)迭代曲线Fig.3 Iterative curve of GP-Cluster(Breast cancer)
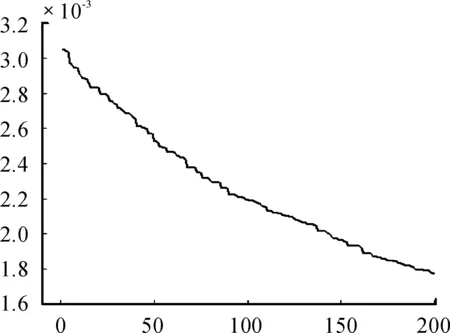
图4 GA(乳腺癌)迭代曲线
本文采用均方残差值、双聚类规模、基因数与条件数的比值、对原基因矩阵的覆盖率和算法运行时间这5个指标来评价聚类结果质量。其中:均方残差值为10次实验得到的所有均方残差值的平均值,越小越好;规模就是算法产生的基因聚类矩阵的大小,其值越大越好;行列比即基因聚类矩阵中基因数与条件数的比值,在均方残差值相同的情况下,这个值越小越好。
与粒子群算法相比,从表1、2中明显可以看出:改进后的GP-Cluster算法的均方残差值比粒子群算法的均方残差值减小了一个数量级,改进效果十分明显;从双向聚类的规模上看,GP-Cluster算法得到的聚类规模和覆盖率都比PSO算法要略大一些,尤其从行列分配上看,GP-Cluster算法的基因数和条件数的分布更加均匀。也就是说,GP-Cluster算法产生的双向聚类尽可能多地同时覆盖了原基因矩阵中的基因和条件。所以,GP-Cluster产生的双聚类质量要高于粒子群算法所产生的双聚类的质量。
遗传算法和GP-Cluster算法的均方残差相差不大,遗传算法的均方残差要略小一点,但是在双聚类的规模上GP-Cluster算法产生的双聚类的行数和列数都有所增加,尤其是在列数上增加明显,这样就导致了行列比比遗传算法的行列比小了近一半,对原基因矩阵的覆盖率也比遗传算法高了近1倍。因此,GP-Cluster算法产生的双聚类的质量优于遗传算法产生的双聚类的质量。从图1、2上可以看出:GP-Cluster算法在迭代150次时就达到了遗传算法170次左右的效果。从图3、4上可以看出:GP-Cluster算法迭代到50次时就达到了遗传算法迭代150次时的效果。由此可以说明:GP-Cluster收敛较快,比遗传算法效率更高。
虽然结合了遗传算法的混合粒子群优化算法找到的双聚类质量更佳,但是从算法运行所花费的时间上看,GP-Cluster算法消耗的时间明显增加。
5 结束语
分析基因表达数据具有重要的医学价值和生物研究意义。本文介绍了一种基于遗传算法和粒子群算法的双向聚类算法——GP-Cluster双向聚类算法。它将遗传算法中的“优胜劣汰”思想引入到了粒子群算法中,平衡了局部搜索和全局搜索的关系,大大改进了粒子群算法在解决双聚类问题上易陷入局部最优的不足。两组实验结果表明:改进后的混合优化算法对解决基因表达谱聚类问题表现出了较为理想的效果,能找到更优的基因相似矩阵。但GP-Cluster算法也存在不足,那就是计算量大,花费时间较多,有待继续改进。
[1] CHENG Y,CHURCH G M.Biclustering of Expression Data[C]//Proceeding of the 8th International Conference on Intelligent Systems for Molecular Biology.ACM Press.(ISMB’00).2000:93-103.
[2] 张敏,戈文航.双聚类的研究与进展[J].微型机与应用,2012,31(4):4-10.
ZHANG Min,GE Wenhang.Research and progress of double clustering[J].Micro computer and application,2012,31(4):4-10.
[3] 周康渠,赵慧真. 混合离散粒子群算法在混流装配线生产调度中的应用[J]. 重庆理工大学学报(自然科学),2015(3):58-64.
ZHOU Kangqu,ZHAO Hu-zhen. Application on Scheduling of Mixed Model Assembly Lines with Hybrid Distribution Particle Swarm Optimization Algorithm[J]. Journal of Chongqing University of Technology(Natural Science),2015(3):58-64.
[4] 刘敏,李智彪.基于粒子群优化脉冲耦合神经网络的红外图像分割[J].激光杂志,2016(2):50-53.
LIU Min,LI Zhi-biao.Infrared Image Segmentation Based on Particle Swarm Optimization Pulse Coupled Neural Network[J].Laser Journal,2016(2):50-53.
[5] 孙延维,彭智明,李健波.基于粒子群优化与模糊聚类的社区发现算法[J].重庆邮电大学学报(自然科学版),2015,27(5):660-666.
SUN Yanwei,PENG Zhiming,LI Jianbo.Community detection algorithm based on particle swarmoptimization and fuzzy clustering[J].Journal of Chongqing University of Posts and Telecommunications(Natural Science Edition),2015,27(5):660-666.
[6] 周文刚,赵宇.具有完全学习策略的量子行为粒子群癌症基因聚类算法[J].北京邮电大学学报,2014,37(4):59-63.
ZHOU Wengang,ZHAO Yu.A complete learning strategies quantum-behaved particle swarm cancer gene clustering algorithm[J].Journal of Beijing university of posts and telecommunications,2014 37(4):59-63.
[7] 梁军.粒子群算法在最优化问题中的研究[D].南宁:广西师范大学,2008.LIANG Jun.The particle swarm algorithm in the optimization research[D].Nanning:Guangxi normal university,2008.[8] 谢晓锋,文俊,杨之廉.微粒群算法综述[J].控制与决策,2003,18(2):129-142.
XIE Xiaofeng,WEN Jun,YANG Zhilian.Particle swarm algorithm[J].Control and decision,2003,19(2):129-142.
[9] SHI Y,EBERHART R C.Particle swarm optimization:developments,applications and resource[ C] // In:Proc of Congress onEvolutionary Computation.Seoul.Korea:IEEE Service Center.2001:81-86.
[10]林秀芳,陈淑梅,陈金兰.运用遗传算法的磁流变阻尼器减震的模糊控制[J] . 重庆理工大学学报(自然科学),2015(9):64-69.
LIN Xiufang, CHEN Shumei,CHEN Jin lan.Genetic Algorithm-Based Fuzzy Control Strategy for A Magnetorheological Damper[J].Journal of Chongqing University of Technology(Natural Science),2015(9):64-69.
[11]陈磊,霍永亮.利用改进的遗传算法求解约束优化问题[J].重庆工商大学学报(自然科学版),2014,31(9):63-67.
CHEN Lei,HUO Yongliang.The Solution to Constrained Optimization Problem by Improved Genetic Algorithm[J].Journal of Chongqing Technology and Business University(Natural Science Edition),2014,31(9):63-67.
[12]刘伟,周育人.一种改进惯性权重的PSO 算法[J].计算机工程与应用,2009,45(7):46-48.
LIU Wei,ZHOU Yuren.An improved inertia weight PSO algorithm[J].Computer engineering and application,2009,45(7):46-48.
[13]沈明明,毛力.融合K-调和均值的混沌粒子群聚类算法[J].计算机工程与应用,2011,47(27):144-151.
SHEN Mingming,MAO Li.Fusion K - harmonic mean of chaotic particle cluster algorithm[J].Computer engineering and application,2011,47(27):144-151.
[14]GOLUB T R,SLONIM D K,TAMAYO P,et al.Molecular classification of cancer:class discovery and class prediction by gene expression monitoring[J].Science,1999,286(15):531-537.
[15]van’t VEER L J,DAI H,van de VIJVER M J,et al.Gene expression profiling predicts clinical outcome of breast cancer[J].Nature,2002,415(6871):530-536.
(责任编辑 杨黎丽)
Gene Expression Profile Clustering Based on Improved Particle Swarm Algorithm
LI Liang, CHEN Jia-yu
(College of Computer Science and Engineering, Chongqing University of Technology, Chongqing 400054, China)
Bi-clustering algorithm can find the hidden information in the gene expression patterns. In order to find a larger genetic similarity matrix, combined with powerful search ability of particle swarm optimization, GP-Cluster algorithm was proposed. This algorithm was based on particle swarm algorithm (PSO), introducing the Sigmiod function to adjust the weights dynamically, and using the genetic algorithm(GA), the thought of “evolution”, to increase the variability and randomness of particle movements and to avoid algorithm falls into local optimum. The experimental results show that compared with GA algorithm and PSO algorithm, the improved hybrid particle swarm algorithm(GP-Cluster) can find a better quality of bi-clustering.
data mining; gene expression; bi-clustering; particle swarm algorithm; genetic algorithm
2016-08-15 基金项目:重庆市应用开发计划项目(CSTC2013yykf A40002).
李梁(1964—),男,重庆人,副教授,主要从事数据挖掘和数据仓库、数据库技术研究;陈佳瑜(1992—),女,湖北十堰人,硕士研究生,主要从事数据挖掘和数据仓库技术研究,E-mail:934415724@qq.com。
李梁,陈佳瑜.基于粒子群算法的基因表达谱聚类分析方法[J].重庆理工大学学报(自然科学),2017(2):89-94.
format:LI Liang, CHEN Jia-yu.Gene Expression Profile Clustering Based on Improved Particle Swarm Algorithm[J].Journal of Chongqing University of Technology(Natural Science),2017(2):89-94.
10.3969/j.issn.1674-8425(z).2017.02.016
TP301
A
1674-8425(2017)02-0089-06
猜你喜欢
出版人(2022年11期)2022-11-15
网络安全与数据管理(2022年3期)2022-05-23
今日农业(2021年19期)2021-11-27
数学小灵通(1-2年级)(2021年10期)2021-11-05
科技风(2021年19期)2021-09-07
北京航空航天大学学报(2020年10期)2020-11-14
今日中国·法文版(2020年7期)2020-07-04
自动化学报(2019年6期)2019-07-23
系统工程与电子技术(2016年4期)2016-08-24
通信电源技术(2016年5期)2016-03-22
