
面向供应链挖掘“商品关系链”价值
——“大数据与智慧物流”连载之二
2017-03-14 02:34李嘉/文
物流技术与应用 2017年2期
李 嘉/文
面向供应链挖掘“商品关系链”价值
——“大数据与智慧物流”连载之二
李 嘉/文
中国有句俗语:人以群分,物以类聚。这句话蕴含朴素的大数据思维。本文以笔者亲自主导的一个仓储商品布局优化案例为切入点,深入探讨这种思想在电商供应链领域的价值。
一、物以“类”聚
评价电商仓储能力的核心KPI之一是在售SKU(Stock Keeping Unit)总量。不同种类的SKU,在码放标准、安保要求、生产流程、打包方式、温度控制等方方面面存在巨大差异。简单来说,在售SKU总量越多,电商的供应链能力越强。现行模式下一个SKU对应一个销售种类(例如32G Iphone7 金色手机,即为一个标准SKU);相应地,一个SKU默认为仓配体系中的一个最小作业单元(比如最小上架单位、最少补货单位、最少拣货单位等)。然而细思起来,这种模式存在一个巨大的“意识断层”,即:引入一个SKU的动作在采购端完成,其核心动机是根据市场需求拓展供给商品,根本目在于提升GMV;而仓配体系遵循的铁律是用最低的成本把商品送达用户,根本目标在于降低成本。两者分处销售与运营两端,目标不同,本质上没有任何理由支持“每一个销售基本单元必须 = 每一个运营最小作业单元” 这个等式的成立。
在跨越 “意识断层”方面,JD运营已经开始了探索。以2016年7月在华南某10万平方米仓储中心进行的科学仓储布局项目为例,见图1。布局前后效果见图2。
从图1看出,项目引入SKU簇作为库内的最小作业单元,同簇SKU在整个库房生命周期内,会被同时执行上架、补货、移库等操作,不可拆分。经实地测算,重布局后,减少拣货时无效移动59%。无效移动案例如下:
a.Case平库:拣货员穿越了一个巷道,但未拣选任何商品,记录为一次无效移动。
b.Case“货到人”库:一个移动货架有100件商品,类kiva机器人搬运一次后,拣货员拣选了其中1件。此情况中,其余99件商品分别记录一次无效移动。
具体实施步骤如下:
1. 利用大数据预测工具计算每2个SKU被同单购买的概率;将此概率作为个体距离,应用聚类算法,在SKU总量基础上生成若干SKU初始簇;
2. 根据簇内每一SKU的支持度,计算其在簇内的件数配比;
3. 根据待布局储区容积,寻找全局最优的簇实例组合。最优目标为:拣货时无效移动次数最少;
4. 根据待上架目标介质的实际容量,以及簇内配比,对初始簇进行裁剪(目标介质指以下中的一种:可移动货架、平库巷道、shuttle货格等)。一个初始簇会被切分为若干个簇实例。一个簇实例是一个具体到件数的存储/作业单元;
5. 按切分好的簇实例及其分布完成上架。簇实例示意图见图3。
该项目在算法实现层面存在以下难点,供读者应用时参考:
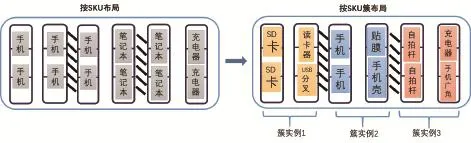
图1:某库房商品布局演进

图2:某库房商品布局前后效果图
1. 预测SKU合买概率难度较大,历史订单数据受季节因素、赠品绑定、促销等因素影响明显;

图3:簇实例示意图

图4:融合热销品近产线模型

图5:某热销品近产线效果的计算方法

图6:思维导图
2. 不同类型储区对簇实例裁剪要求各异,需兼顾以下维度思考:
(1)簇实例之间应保有关联度
(2)避免热销簇过度集中,导致局部拥堵
(3)避免簇实例的商品量过大,导致占用目标介质过多
(4)避免簇实例的商品量过小,导致拣货时SKU易被击穿
3. 如欲兼容热销品近产线模型,会引发计算复杂度指数级攀升,见图4。热销品近产线效果的计算方法见图5。
(1)按商品合买概率划分SKU簇
(2)以巷道为目标介质,生成簇实例,上架商品
(3)将销量最高的巷道移到黄金位置
(4)围绕01巷道,按簇间合买概率布局02、03巷道
(5)按销量排序后,03巷道中商品销量更高,交换02、03巷道中簇实例
(6)以02巷道为中心,迭代4-5步骤,直至整个储区规划完毕
JD运营从表象上看打破了按SKU管理库房的传统,实际上是还原了Stock Keeping Unit的本来含义。本文所述SKU簇,提供了定义仓配体系更高效的最小作业单元的新思路,其广泛应用将大幅削减管理复杂性,更贴近运营目标。运营中的最小作业单元不应仅是基本销售单元的影子。
二、 人以“群”分
每一件售出商品背后至少有三个人:生产商、销售商、用户。前文就类聚后的商品,在电商运营端的价值进行初步讨论,并未展开对商品背后人群的精准分析。未尽之言以一张思维导图作为概述,以求启迪读者更多思考。见图6。
作者为京东商城运营研发部大数据研发部负责人
猜你喜欢
山东冶金(2022年4期)2022-09-14
冶金设备(2020年2期)2020-12-28
电子制作(2019年20期)2019-12-04
山东冶金(2019年3期)2019-07-10
能源(2017年5期)2017-07-06
中国科技信息(2016年15期)2016-11-04
中国卫生(2015年2期)2015-11-12
创业家(2015年1期)2015-02-27
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
