
木棉和棉的自动识别
2017-03-13 07:58王荣武
东华大学学报(自然科学版) 2017年1期
高 亮, 王 旭, 王荣武, 3
(1. 东华大学 纺织学院,上海201620; 2. 新疆维吾尔自治区纤维检验局,新疆 乌鲁木齐 830000; 3. 西安工程大学 陕西省功能性服装面料重点实验室,陕西 西安 710048)
木棉和棉的自动识别
高 亮1, 王 旭2, 王荣武1, 3
(1. 东华大学 纺织学院,上海201620; 2. 新疆维吾尔自治区纤维检验局,新疆 乌鲁木齐 830000; 3. 西安工程大学 陕西省功能性服装面料重点实验室,陕西 西安 710048)
木棉和棉同属于纤维素纤维,化学性质非常相似,采用传统方法不能有效地鉴别. 通过光学显微镜获得的纤维纵向图像发现,木棉纤维纵向较为光滑,没有类似棉的天然转曲,因此可以利用图像处理的方法进行纤维识别.首先提出了一种纤维分离算法,通过轮廓和骨架的分离,从而有效地分离交叉纤维. 然后利用灰度分布特征和经典模式识别方法实现了木棉和棉的自动识别.
木棉; 棉; 数字图像处理; 交叉纤维; 纤维分离; 自动识别
木棉纤维属于天然纤维素纤维,中空率高达97%,是目前纺织用纤维中线密度最小、质量最轻、中空率最高、最具保暖效果的天然纤维材料,其被誉为“植物软黄金”,但它属于未被充分利用的小品种纤维.值得一提的是,木棉除了在纺织方面的独特优势外,还具有抗炎保肝作用以及很强的抗肿瘤药理作用.因此,研究木棉的应用颇具意义[1].
文献[2]利用硫酸溶解的方法对木棉和羊毛混纺产品进行定量分析,发现经硫酸完全溶解后,羊毛损伤很小,确定了溶解方法的可行性.而对于木棉和棉而言,它们的物理性质和化学性质均非常相似,因此常用的纤维鉴别方法无法进行定量分析,而采用显微镜观察法可以有效地进行鉴别[3].文献[4]使用红外光谱对木棉和棉进行定量分析,根据特征吸收峰面积与木棉含量的关系得出标准曲线,从而实现木棉含量的测定.利用图像处理方法进行纤维识别的过程中,纤维目标的分割是一大难点.国内外关于图像分割技术的研究[5-7]非常多,目前应用较为广泛的是基于交叉点处各分支斜率的分离.文献[8]提出的方法适用于两个纤维垂直交叉的情况下的分离,并没有提出其他诸如T字、并列、首尾相接等较为复杂交叉情况下的分离方法.文献[9-10]提出的方法没有对公共骨架段进行判断,认为交叉点间的骨架段是公共骨架段,由于纤维制片中,形态的复杂性和不确定性,此类方法不能全部识别出伪公共骨架段,仅适用于简单的两根纤维交叉的区分,对于一根或多根纤维复杂交叉的情况没有考虑在内.文献[11]提出对纤维提取边缘,根据斜率变化趋势去除纤维头,对剩下的不连续纵向边缘进行Hough变换拟合出纤维边缘直线,之后对边缘进行两次合并,合并后的边缘直线与其他提取的直线一起参与最终边缘配对,该方法适用于边缘接近直线的纤维,对于边缘非直线,如带有转曲的棉、卷曲的羊毛以及一些弯曲的纤维,该方法效率较低.文献[12]针对交叉纤维和分叉纤维图像在显微镜不同焦距下呈现的清晰度差异,利用同根纤维相邻部分像素点在z轴方向坐标范围基本一致,以及交叉点处不同纤维像素点z轴方向坐标差异较大这一原理,根据纤维的(x,y,z)三维特性实现纤维分离,该方法的分离准确度较高,但需要对同一目标采集多幅图层,系统效率低,速度慢,不适用于快速检测.
本文首先选择适合观察木棉和棉纵向形态的制片方法,然后利用配有自动载物台的光学显微镜进行采样[13],在对比分析现有的纤维识别算法的基础上,针对木棉和棉表观形态上的差异,探索合适的目标分割方法,提取最能反映两者区别的特征值,依据分类准则将纤维分类,结合纱线中纤维的密度进行混纺比计算,具体检测流程如图1所示.
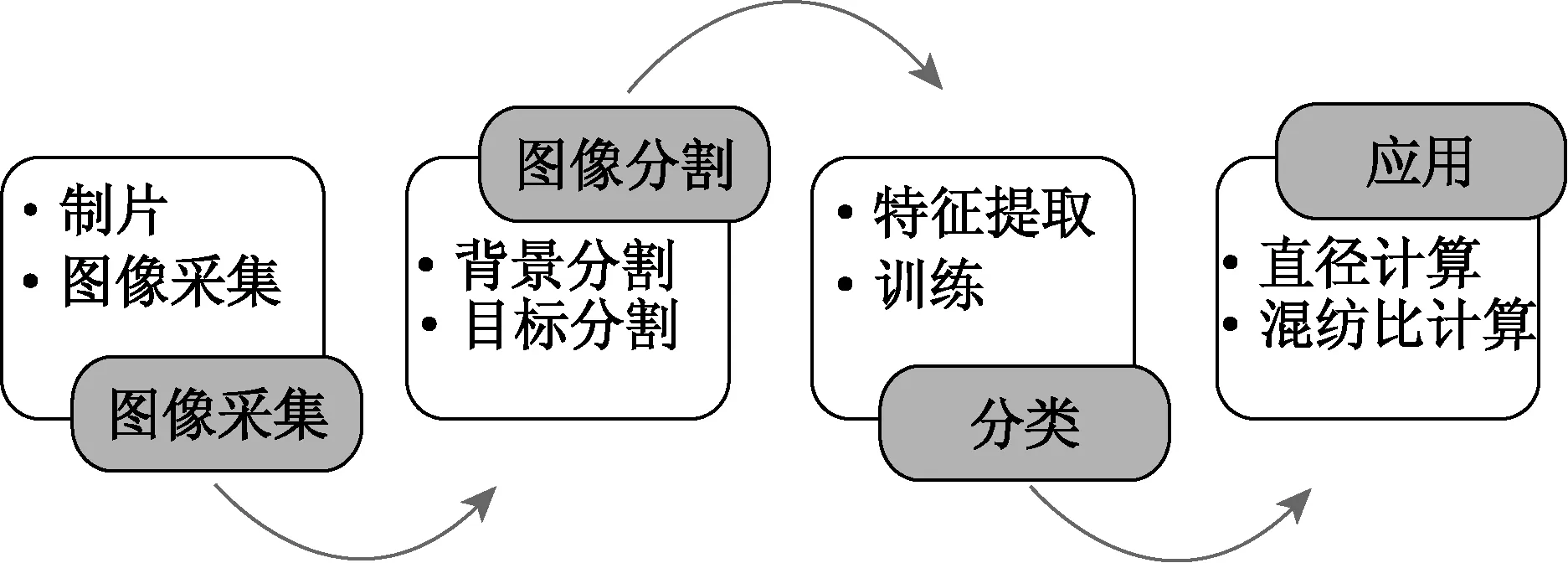
图1 木棉/棉检测流程Fig.1 Detecting process of kapok and cotton
1 算法介绍
根据目前常用的纤维种类识别制片方案进行纤维制样.首先,从制备好的木棉/棉非织造纤网中随机选取一小块,利用Y172型哈氏切片器将纤网切割,精密螺丝旋转10 格,即切取长度为200 μm[14].将切取下来的纤维放置在事先擦拭干净的载玻片上,用玻璃棒蘸取适量甘油滴在载玻片上的纤维上,顺着一个方向搅拌,搅拌的目的是为了能让纤维更好地分散,以便随后图像的观察,减小测试结果的误差,因此,尽可能对纤维进行长时间的搅拌以得到更好的分散效果. 搅拌完成后,将擦拭干净的盖玻片盖上,注意放置盖玻片时要先将盖玻片的一端与甘油接触,随后轻轻放下另一端,避免在放置盖玻片的过程中产生气泡,因为气泡会影响图像的采集质量,从而影响图像的分割结果.
将制好的试样放在北昂F6型纤维细度仪[15]的显微镜观察台上进行图像采集,通过调节焦距和亮度使木棉和棉的边界和纹理尽量清晰,该测试方法支持的图像分辨率为800像素×600像素,否则会导致纤维分离准确率下降. 通过对采集图像中纤维形态的观察,排除团聚的纤维后,纤维交叉形态大体可分为4类,即并列、十字交叉、T字交叉、头尾相接,如图2所示.
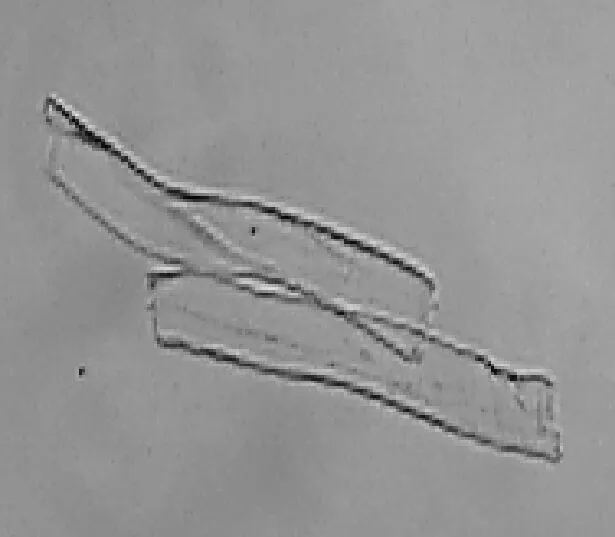
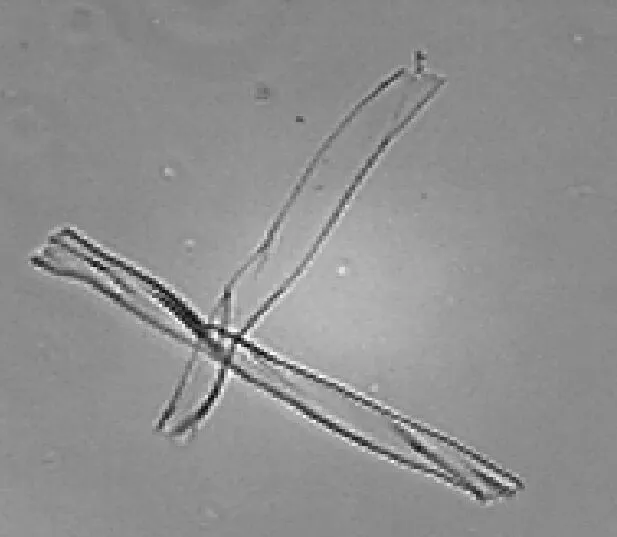
(a) 并列 (b) 十字交叉

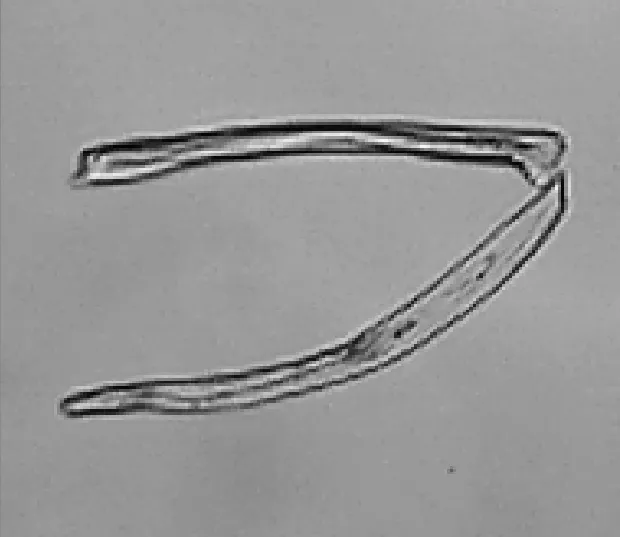
(c) T字交叉 (d) 头尾相接
由图2可知,对于并列纤维,根据外部轮廓凹凸性能够分离,而提取骨架会丢失相关的凹凸信息,因此在提取轮廓阶段进行分离.对于十字交叉、T字交叉、头尾相接的交叉情况,在轮廓图中分离相对较复杂,而提取骨架后根据骨架趋势能够实现有效的分离.十字交叉和T字交叉由于骨架图中同一根纤维骨架在交叉处的斜率差异性较小,可实现纤维分离;对于头尾相接的情况,根据骨架在粘连点处表现斜率突变的特性分离交叉点处的纤维.
1.1 预处理
通过对目标图像进行二值化、填充、联通区域标记等预处理操作去除图像中的噪音,保留感兴趣的纤维目标,为后续的分离做好准备.目标图像预处理后的效果图如图3所示.
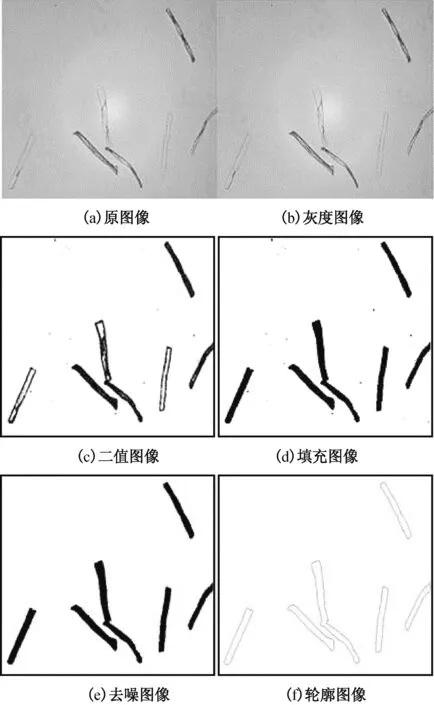
图3 预处理效果图Fig.3 Effect images of preprocessing
1.2 纤维分离算法
1.2.1 轮廓剪枝
由于纤维边缘的不平整导致了轮廓图中存在一些小分叉,如图4所示,AF为主骨架,BC和DE为短枝,需要进行剔除.首先采用8邻域关系图(如图5所示)将轮廓图像中目标像素分为端点、普通点、交叉点3类.

(a) 剪枝前的骨架 (b) 剪枝后的骨架
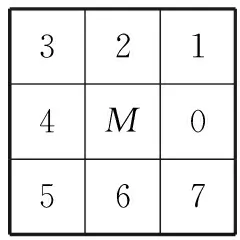
图4 剪枝Fig.4 Cutting branch
图5 8邻域关系图
Fig.5 Eight neighbourhood diagram
假如M为目标像素点,使用0~7共8个数字表示相邻像素点与M的方位关系.依次按0-7-0的顺序检测M的8邻域像素点的状态,如果M点8邻域中有且仅有一个目标像素,定义该目标点为端点;如果M点8邻域中有两个目标像素,定义该目标点为普通点;如果M点8邻域中检测到6次像素灰度级变化,则定义该中心像素点为交叉点.按照上述定义,A、B、E、F为端点,C、D为交叉点,其余像素点为普通点.观察发现短小分叉的特点为:分支两端的一端是端点,另一端是交叉点.根据这一特点可以剔除短小分叉.依次可以从端点开始跟踪骨架(具有一个端点和一个交叉点),长度小于20个像素的骨架作为短枝.在图4(a)中,BC、DE不满足长度阈值,被判断为短枝,短枝剔除后的主骨架如图4(b)所示.
1.2.2 根据轮廓分离并列纤维
根据角度法找出轮廓中的凹极值点[16],具体算法如下所述.
Step 1 遍历图像,搜索图像中的端点,将没有跟踪过的端点设为跟踪起点M,初始搜索方向为左下方,逆时针搜索.
Step 2 根据当前轮廓点的坐标P1,顺时针跟踪m个点到P0,逆时针跟踪m个点到P2.通过式(1)定义凹凸点,用P0P1与P1P2的夹角θ表示该点的凹凸程度,θ>0表示凹点,且θ值越小表示该点凹的程度越小,θ<0表示凸点,且θ值越大表示该点凸的程度越大.
(1)
Step 3 计算所有轮廓点的凹凸性,如图6所示,横坐标表示同一轮廓中所有轮廓点按逆时针的顺序编号,纵坐标表示该轮廓点的凹凸程度.如果轮廓点在顺时针和逆时针方向一定范围内θ均为最小,则该点作为符合要求的凹极值点.
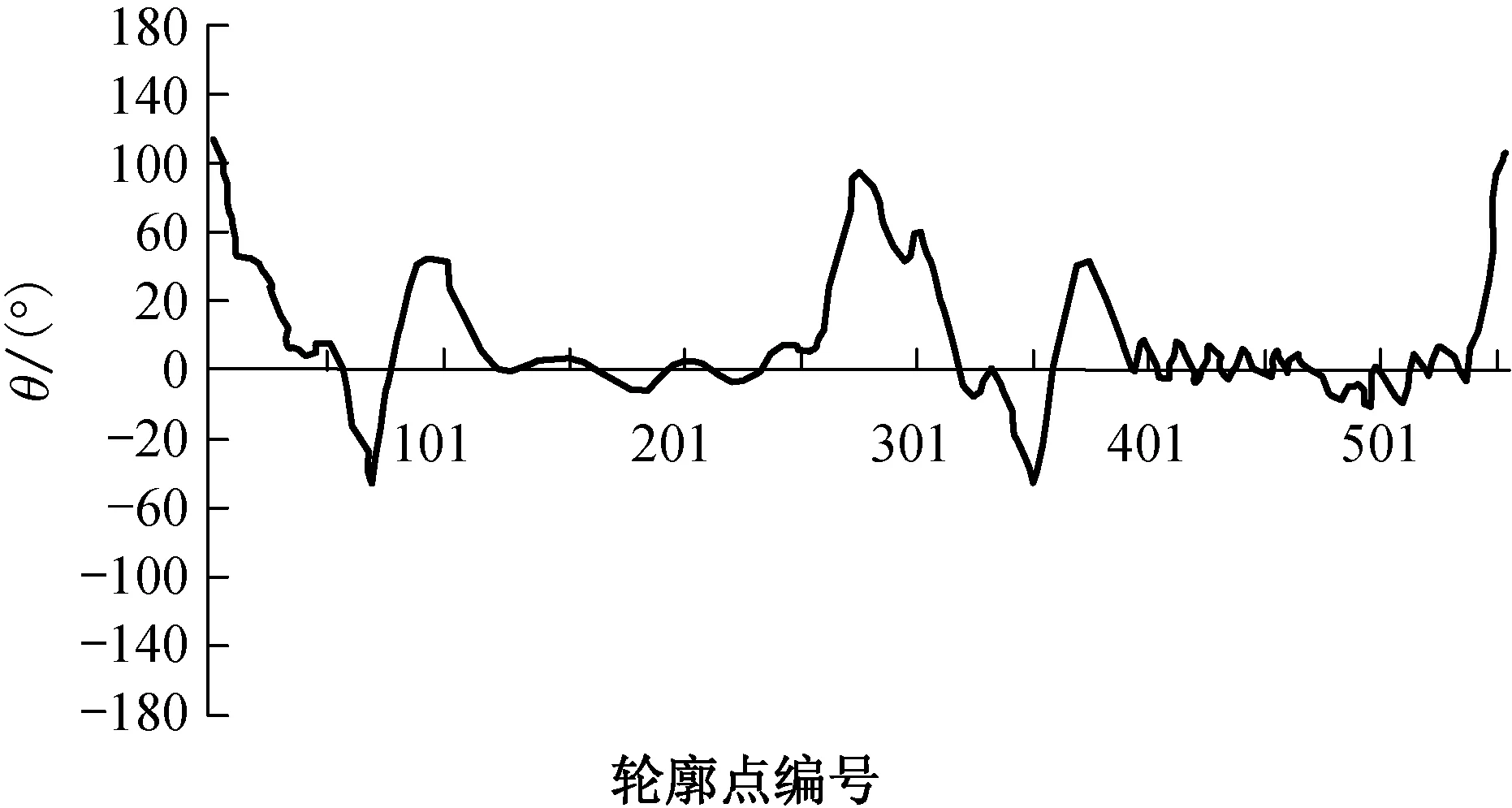
图6 纤维轮廓点位置-凹凸性的关系曲线Fig.6 Curve relation of contour point and convexity
Step 4 记录每个轮廓符合要求的凹极值点个数,如果个数为2,在二值化图像中连接对应的凹点,从而切断交叉纤维,否则不做处理.
对于典型并列的纤维可以实现分离,如图7所示.

(a) 原图 (b) 效果图
图7 并列纤维的分离
Fig.7 Separation of paralleling fibers
1.2.3 提取骨架并剪枝
利用快速查表法提取纤维骨架,并对骨架进行剪枝处理,剪枝操作与轮廓剪枝原理相似.骨架短小分叉的特点为:(1)分支两端一端是端点,另一端是交叉点;(2)分叉长度较短.根据这两个特点可以剔除短小分叉,从而为下一步分离十字交叉、T字交叉和头尾相接的交叉纤维做准备.

(a) 原纤维骨架 (b) 剪枝后纤维骨架
图8 纤维骨架剪枝
Fig.8 Cutting skeleton’s branch of fibers
1.2.4 根据骨架分离十字交叉、T字交叉、头尾相接纤维
对于十字交叉纤维,以图2(b)为例,经过预处理得到二值图像,利用快速查表法提取纤维的骨架,处理效果如图9所示.
图9 架剪枝图Fig.9 The image after cutting branch
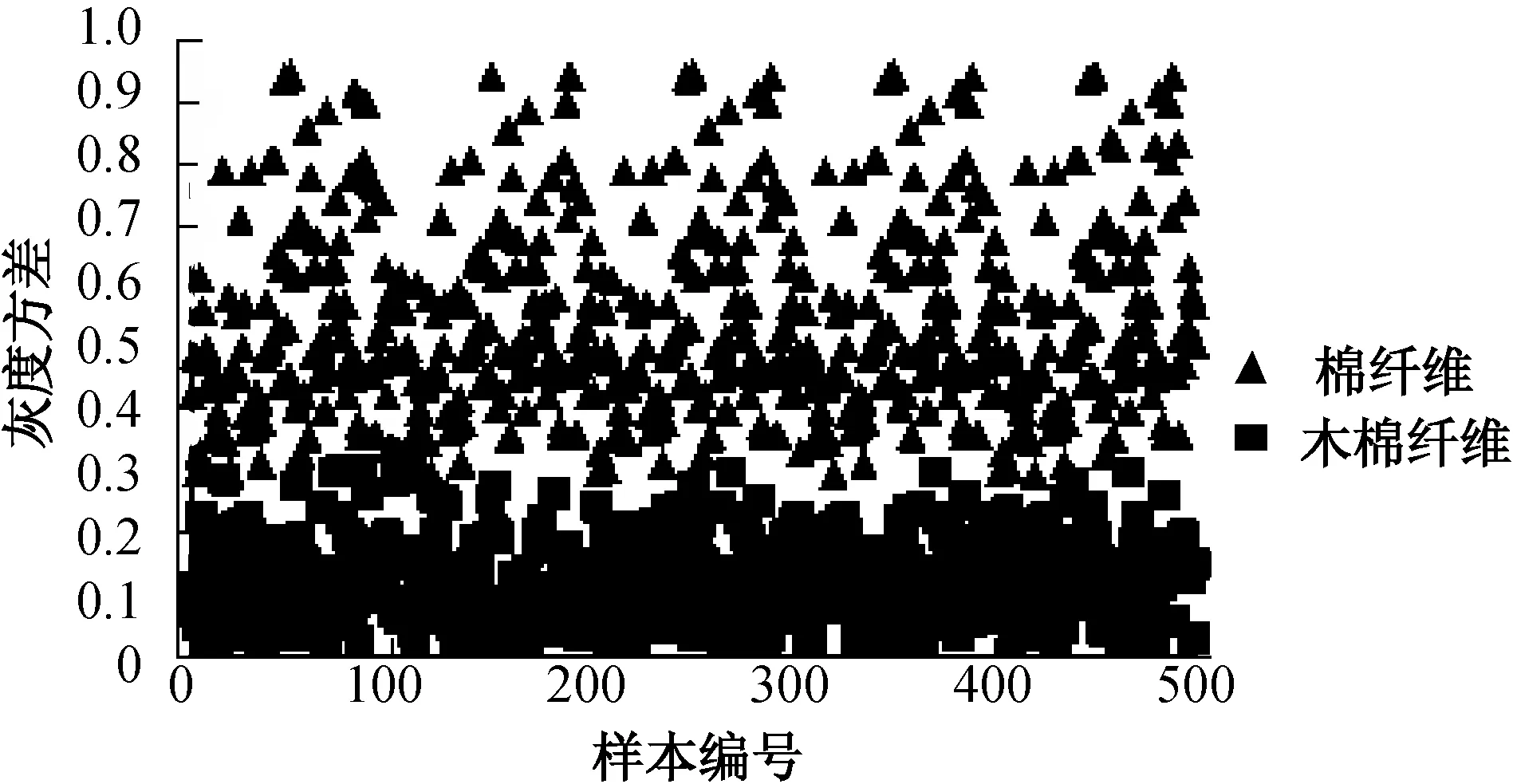
达到理想分离效果的原理:逐行扫描,从骨架的一个端点开始跟踪该骨架线段,直到跟踪到该线段的另一个端点,即分离成功.但要达到理想分离效果,需要解决一个问题,在骨架跟踪过程中,遇到交叉点应该如何继续跟踪.为解决这个问题,首先引入公共骨架线段的概念,将纤维进行分段处理,标记图像中所有的交叉点,去除交叉点后获得了各独立的纤维骨架线段.其中公共骨架线段定义需要满足两个条件:(1)骨架线段的两端均是交叉点;(2)骨架线段的长度在一个较短的特定范围内.满足条件(1)的骨架线段很多,因此条件(2)中长度范围的选择至关重要,有必要对公共线段骨架长度做动态的设定值. 通过观察发现,公共骨架的长度与两根交叉纤维的夹角有密切的关系,两根交叉纤维的夹角越接近90°,公用骨架的长度越小,夹角越接近0°,公共骨架的长度越大.对不同交叉角度的纤维的公共骨架长度进行测量可以得到骨架长度与交叉角度的关系. 本试验采用的试样的交叉角度与公用骨架长度的关系如图10所示.
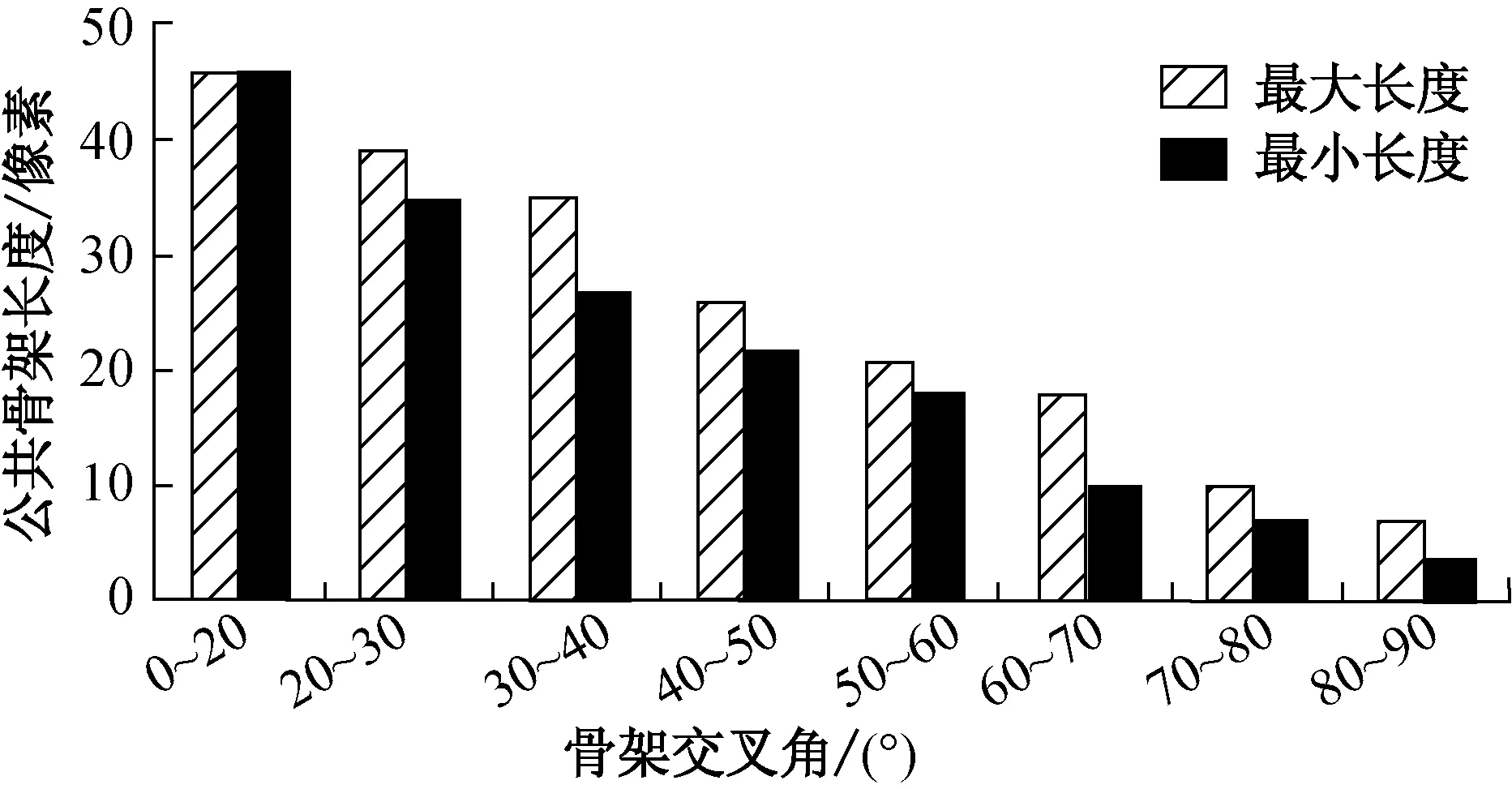
图10 交叉角度与公用骨架长度的关系Fig.10 The relation between crossed angle and public skeleton length
找到公共骨架线段后,对公共骨架点进行标记,然后依据8邻域的目标像素点个数进行分类,将目标像素点分为4类:端点、普通骨架点、分叉点、公共骨架点.骨架跟踪具体算法如下所述.
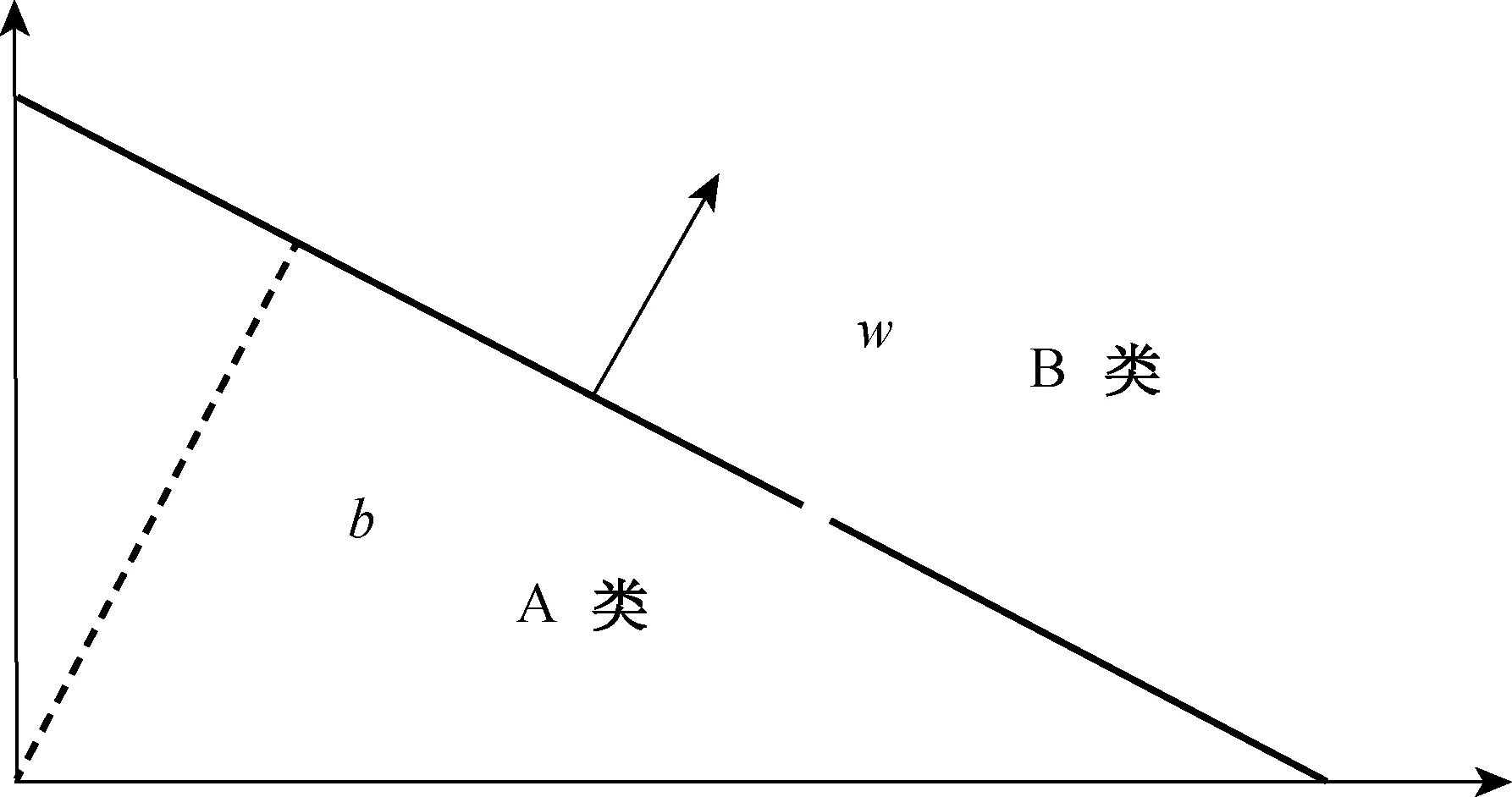
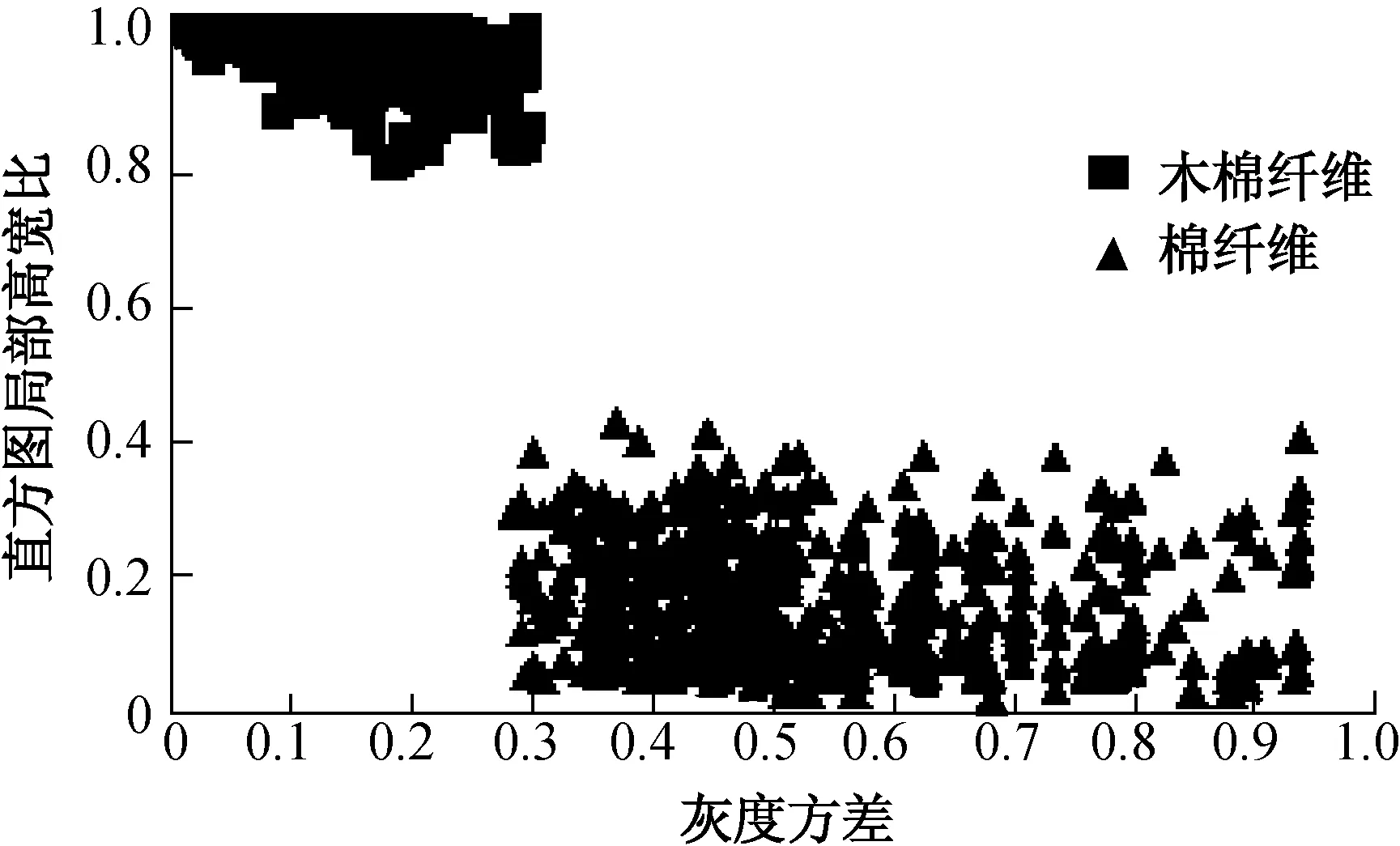
Step 1 确定公共骨架线段.从交叉点各个方向开始跟踪,直到搜索到交叉点或者端点后停止跟踪.如果终止条件为交叉点,则将该线段初步定为公共骨架,且记录该骨架长度为L,然后根据该交叉点另外两条非公共骨架线段所成角度,对照图10查出对应公共骨架长度的范围(Lmin,Lmax),如果Lmin Step 2 对公共骨架两端骨架进行配对,将公共骨架相连的4根骨架根据同根纤维交叉点处斜率差异最小原则进行两两编号配对. Step 3 端点开始跟踪骨架,当前目标点8邻域有交叉点时,搜索8邻域方向是否有公共骨架点,如果有,说明交叉纤维属于十字交叉,记录当前目标点的配对编号,沿公共骨架方向继续跟踪,再次遇到交叉点时,搜索交叉点8邻域的目标点的配对编号,其中与起始配对编号相同的目标点为下一个跟踪点,直到跟踪到端点.如果没有公共骨架,说明交叉纤维属于T字交叉,计算当前骨架方向与交叉点处的另两条骨架的夹角,夹角大的两者作为配对对象,继续沿配对骨架方向进行跟踪,直到跟踪到端点. Step 4 在完成十字交叉和T字交叉的纤维分离之后,对头尾相接的交叉纤维进行分离,这里头尾相接是指两根纤维的头端发生重叠,导致交叉区域具有明显拐点,在跟踪骨架过程中,如果发现斜率发生突变,则将突变区域剔除. 交叉纤维经过骨架分离后的效果图如图11所示. (a) 分离的十字交叉纤维 (b) 分离的T字交叉纤维 (c) 分离的头尾相接纤维 由图11可见,纤维骨架已经被完全正确地分离,每根纤维为独立的目标.但本方法不适用于多根纤维在很小的纤维段内多次重复交叉的情况. 1.3 纤维分离效果 经过对图像中交叉纤维的分离,得到独立的纤维个体,同时为了提取有效的特征参数,剔除纤维的头尾部分,各占纤维总长度的1/5,只保留纤维中段,对纤维中段用对应的原灰度值填充,得到效果图如图12所示. 图12 纤维分离效果图Fig.12 The effect image of separated fibers 2.1 特征参数提取 根据目标纤维灰度上的差异,经过对特征值筛选,选取各个目标直方图的局部高宽比、目标灰度方差两个参数作为特征参数.木棉和棉的灰度直方图如图13所示,其中,横坐标表示灰度级(0~255),纵坐标表示对应灰度级的像素个数.从图13找出最大峰值,该坐标对应的像素个数作为直方图高,以最大峰值作为中心线,取左右延伸一定范围作为直方图的宽,由此求得直方图的局部高宽比. (a) 木棉 (b) 棉 观察木棉和棉的外观特征发现,棉纤维表面纹理明显要比木棉粗糙,因此反映在图像中的纤维的灰度方差也不相同.灰度方差σ2的定义为 (2) (3) (4) 式中:b为像素的灰度值,取0~255的整数;n为数字图像中的总像素个数;n(b)为该窗口内灰度为b的像素个数. 以样本号作为横坐标,分别以归一化后的直方图局部高宽比和灰度方差两个参数作为纵坐标,分析单一特征参数的有效性,得到的识别效果图如图14和15所示. 图14 木棉和棉的灰度直方图局部高宽比Fig.14 Local aspect ratio of kapok and cotton’s histogram 图15 木棉和棉的灰度方差Fig.15 Variance of kapok and cotton 由图14和15可以得出:由于木棉中空率较大,纤维壁较薄,因此纤维内部灰度与背景相近,灰度均匀,纹理较平滑,直方图高宽比较大,灰度方差较小;棉由于存在天然转曲,纤维表面灰度分布不均匀,直方图高宽比较小,灰度方差较大.因此,使用灰度直方图高宽比度和灰度方差结合可以分离木棉和棉.由于特征值存在异常值,而剔除异常值可以提高纤维分离程度. 2.2 特征参数的相关性分析 对两个特征参数进行相关性分析,如果两个变量之间是线性的,则可用一个线性的方程实现纤维的识别公式;如果变量之间是线性无关的,可采用非线性的方程,或者一个近似的线性方程来实现纤维的识别公式.本文采用Spearman等级相关系数进行分析,其适用于度量定序变量之间的相关系数,其计算公式为 (5) 式中:di=(xi-yi),xi和yi分别为两个变量按大小(或优劣等)排位的等级(称为秩);n为样本的容量. Spearman等级相关系数的取值区间为:-1≤rs≤1.rs为正值时,存在正的等级相关;rs为负值时,存在负的等级相关.rs=1,表示两个变量等级完全相同,存在完全正相关;rs=-1,表明两个变量的等级完全相反,存在完全负相关.rs的绝对值越大表明相关性越强,若rs=0,表明两个变量不是线性相关. Spearman等级相关系数是根据一定的样本容量计算的.两个变量的总体是否存在显著的等级相关也需要检验.当样本容量大于20时,可利用t统计量(如式(6))进行等级相关系数的显著性检验. (6) 使用500组样本特征参数做Spearman等级相关系数的相关性分析,计算得出两个特征向量的Spearman等级相关系数rs为-0.573.经t统计量检验显著,证明两个特征值为线性相关的,因此可以建立相似的线性识别公式来实现纤维的分离. 2.3 木棉和棉自动识别公式的确立 对于一个样本集,如果存在一个线性分类器能把每个样本都正确分开,则称样本集为线性可分的,否则称为线性不可分的.反过来,如果样本集是可分的,则必然存在一个分类器能把每个样本正确分类.假设模式向量x是n维的,线性判别函数的一般形式为 (7) 式中:w为权重系数;a为偏置截距. 式(7)的几何意义为其定义的超平面将空间X分为两部分,如图16所示,超平面是位数为n-1的仿射子空间,它将空间X分为两部分对应输入的两类. 图16 Spearman几何表示Fig.16 Geometric representation of Spearman 图17 木棉和棉的特征参数Fig.17 The schematic diagram of kapok and cotton’s character formula 根据经典模式识别方法,结合如图17所示的木棉和棉特征参数的分布,本文采取类别均值的分离,训练样本集.木棉和棉的均值向量计算见式(8)和(9)所示. (8) (9) 式中:m1表示木棉的向量均值;X1i表示木棉中样本号位为i的特征向量;N1为木棉样本数;m2表示棉的向量均值;X2i表示棉中样本号位为i的特征向量;N2为棉样本数.将特征均值连线的方向确定为特征向量的投影方向,将中心点连接线段的中垂线确定的函数作为线性判别函数,如式(10)所示. (10) 利用识别式(10)对500组木棉和棉的自动识别,对于图像质量较好的试样,识别正确率达到90%以上. 根据上文中所述方法得到图像中纤维种类和根数之后,同时可计算出纤维直径,再结合已知的线密度,根据式(11)和(12)可以计算出木棉和棉的混纺比.由于木棉中空率较大,在制片过程中中腔会被压扁,如何对测得的木棉宽度进行直径折算将成为今后研究的重点. 100% (11) P2=100%-P1 (12) 式中:P1为木棉的质量百分比;n1为木棉的根数;K1为木棉的修正系数;ρ1为木棉的密度;D1为木棉的直径;P2为棉的质量百分比;n2为棉的根数;K2为棉的修正系数;ρ2为棉的密度;D2为棉的直径. 本文以木棉和棉纤维纵向形态作为研究对象,利用数字图像处理技术讨论了交叉纤维的分离,提出了一种新的分离算法,同时提取了直方图高宽比和灰度方差两个参数作为识别的特征值,取得了较好的试验结果. 经过测试,对于图像质量较好的样本,识别正确率在90%以上.在识别出纤维根数和种类之后,同时结合纤维的直径和已知的纤维线密度,可以进一步计算出纤维的混纺比. 后续的研究可在此基础之上开发出木棉/棉混纺比测试软件,能够在生产检测中得到推广应用. [1] 张振方,王梅珍,林玲,等.木棉纤维及其集合体研究进展[J].产业用纺织品,2015,33(8):30-34. [2] 刘艳,潘建君.羊毛木棉混纺产品定量分析方法的研究[J].针织工业,2014(12):65-67. [3] 朱军军,石东亮.木棉和棉纤维的鉴别方法探讨[J].中国纤检,2012(6):72-73. [4] 吴世荣.基于红外光谱的木棉与棉定量分析[J].中国纤检,2011(23):64-65. [5] ZHANG Y J. A review of recent evaluation methods for image segmentation[C]∥Isspa 2001: Sixth International Symposium On Signal Processing and its Applications, Vols 1 and 2, Proceedings. 2001:148-151. [6] HARALICK R M, SHAPIRO L G. Image segmentation techniques[J]. Computer Vision,Graphics and Image Processing, 2015,29(85):100-132.[7] PAL N R, PAL S K. A review on image segmentation techniques[J]. Pattern Recognition,1993,26(93):1277-1294. [8] 孟荣爱,周长剑,邱书波.纸浆纤维交叉分离的一种新型算法[J].纸和造纸,2011,30(8):67-69. [9] 解德义,徐新彬.基于数字图像处理的交叉纤维的分离方法[J].山东轻工业学院学报,2008(1):40-42. [10] 余承健.纤维检测中交叉图像的分离算法[J].电脑知识与技术,2006(20):142-144. [11] 贾立峰.重叠纤维的分离计数算法[J].纺织学报,2011,32(5):43-49. [12] 陈梦睿.交叉纤维分离算法的研究[D].上海:东华大学计算机科学与技术学院,2012:1-32. [13] 卜涛涛,卢超.图像分割算法研究[J].电脑知识与技术,2010,6(8):1944-1946. [14] 王君,王荣武,吴雄英,等.Lyocell/棉纵向切段制样方法及最佳切段长度的确定[J].中国纤检,2010(1):49-52. [15] 王荣武.基于图像处理技术的苎麻和棉纤维纵向全自动识别系统[D].上海:东华大学纺织学院,2007:35-37. [16] 宋晓眉,程昌秀,周成虎.简单多边形顶点凹凸性判断算法综述[J].国土资源遥感,2011(3):25-31. (责任编辑:刘园园) Automatic Recognition of Kapok and Cotton GAOLiang1,WANGXu2,WANGRongwu1,3 (1. College of Textiles, Donghua University, Shanghai 201620, China; 2. Xinjiang Uygur Autonomous Region Fiber Inspection Bureau,Urumqi 830000, China; 3. Shanxi Key Laboratory of Functionnal Fabrics, Xi’an Polytechnic University, Xi’an 710048, China) Kapok and cotton both belong to the cellulose fiber and their chemical properties are very similar,so using traditional methods can not recognize them efficetively. In fiber longitudinal images acquired through light microscope, kapok fiber’s longitudinal appearance is smooth, while cotton fiber has natural twist, so the digital image processing method can be used to recognize kapok and cotton. A new algorithm is proposed, which can separate crossing fiber effectively through the separation of the contour and skeleton. Then, gray level distribution and classic pattern recognition method are used to realize the automatic recognition of cotton and kapok. kapok; cotton; digital image processing; crossing fiber; fibers’ separation; automatic recognition 1671-0444(2017)01-0095-07 2015-09-22 陕西省教育厅科学研究计划资助项目(14JS039) 高 亮(1989—),男,河北保定人,硕士研究生,研究方向为数字图像处理. E-mail:18317131087@163.com 王荣武(联系人),男,教授,E-mail:nbwrw@163.com TS 117 A



2 纤维种类识别
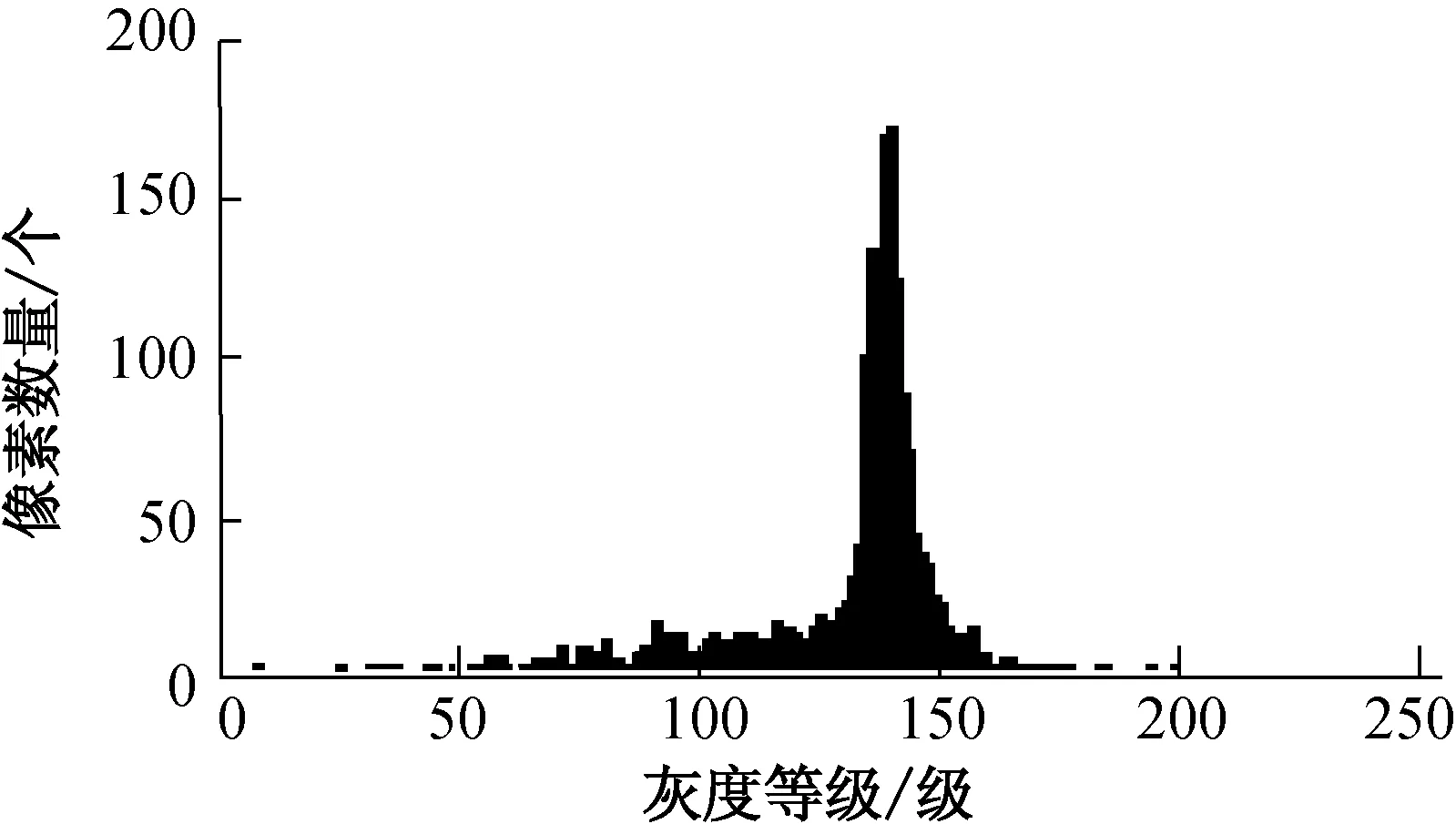
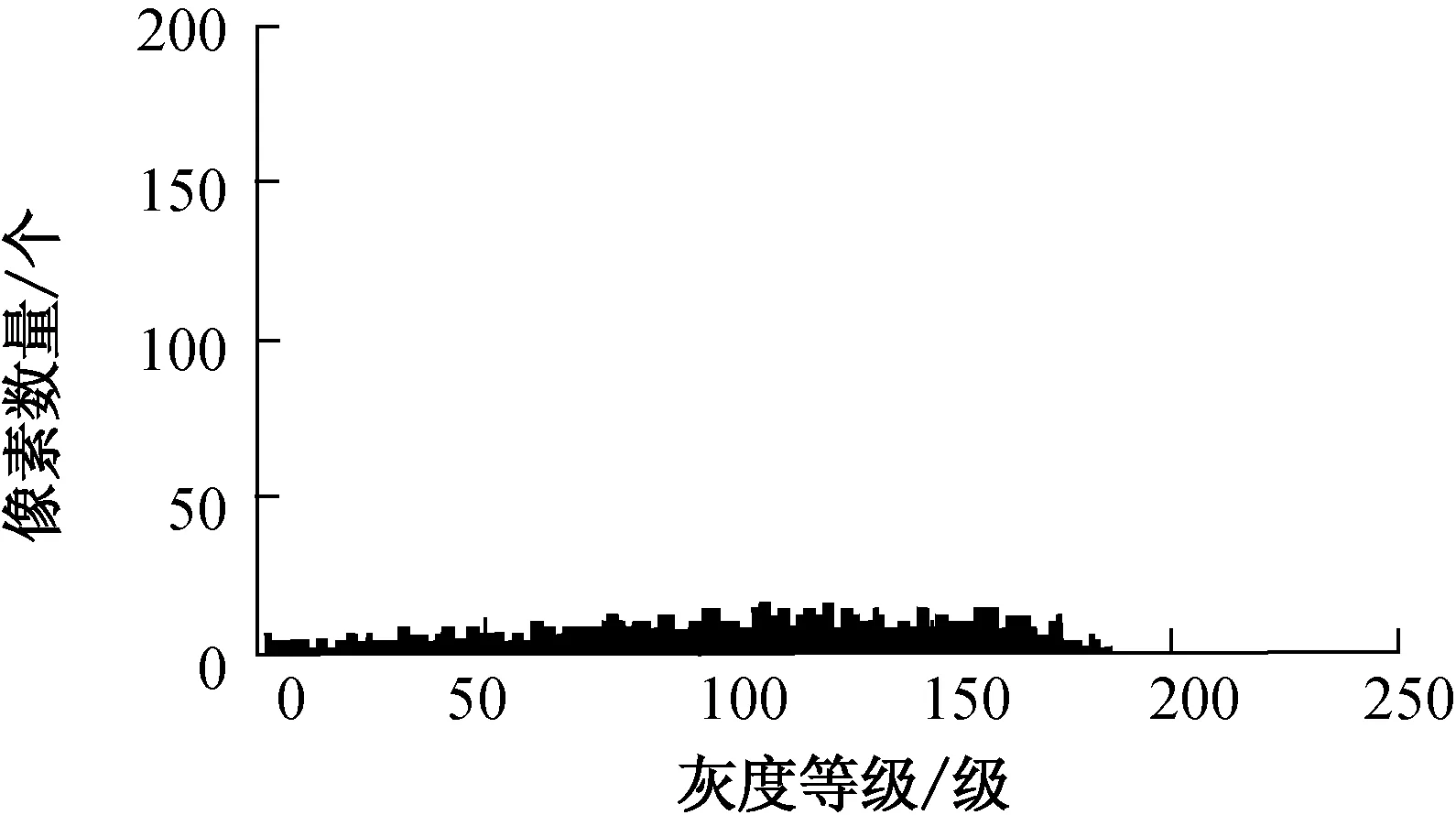
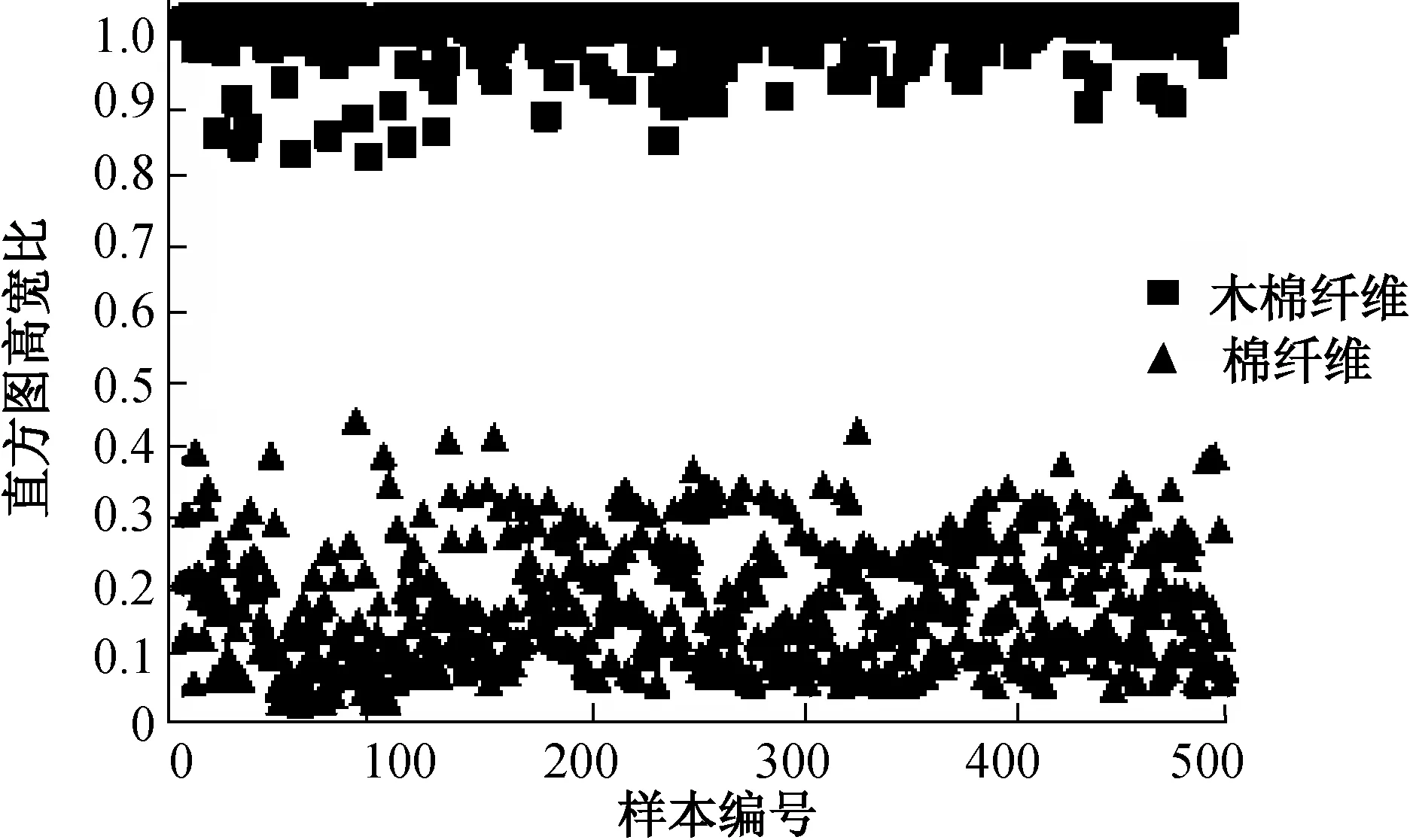
3 应用前景
4 结 语
猜你喜欢
吉林师范大学学报(自然科学版)(2022年4期)2022-12-09
数学物理学报(2022年2期)2022-04-26
歌海(2021年6期)2021-02-01
幼儿园(2020年15期)2020-11-24
World Journal of Psychiatry(2020年4期)2020-07-11
艺术家(2020年5期)2020-07-09
中学生数理化·教与学(2019年8期)2019-09-18
海峡姐妹(2019年5期)2019-06-18
小学生学习指导(中年级)(2019年3期)2019-04-10
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
