
基于局部密度的无监督作文跑题检测方法
2017-03-12 08:47温启帆
中文信息学报 2017年6期
李 霞,温启帆
(1. 广东外语外贸大学 语言工程与计算实验室,广东 广州 510006;2. 广东外语外贸大学 信息科学与技术学院,广东 广州 510006)
0 引言
对于机器评分系统,当应试者通过拷贝、背诵、堆砌词汇等方式输入一篇与作文题目无关的“优秀”作文时,系统如果不做跑题检测,则可能会给该作文评出较高的分数,从而影响机器评分系统的公平性和准确性。因此,作文跑题检测对于作文自动评分系统的公平性、鲁棒性和准确性具有重要的意义。
作文跑题是指作文偏离题目所要求的主题并写成其他无关的主题作文。例如题目要求学生就“全球淡水资源短缺问题”写一篇议论文,而所写的作文却是有关“对假冒伪劣商品的看法”或“对社会实践的重要性的讨论”等与淡水资源短缺无关的主题时,则该作文将被认定为跑题作文。目前作文跑题检测方法主要包括有监督作文跑题检测方法和无监督作文跑题检测方法,前者需要事先对已经标注好的大规模跑题作文进行训练,使用机器学习方法中的分类等方法实现跑题作文的检测。然而,在很多实际教学场景中,当英语教师给出一个新的作文题目时,往往事先并没有标注好的跑题作文数据,此时有监督跑题检测方法便无法适用。因此,针对事先没有作文训练集,通过作文题目的描述信息来自动检测作文是否跑题的无监督作文跑题检测研究成为近年来有关作文跑题检测的主要研究内容。
作文跑题检测的核心问题是判断作文的主题是否偏离作文题目给定的主题。通常,一篇作文为了论证作者的思想或观点,往往会通过几个子观点来论证其核心观点,因此一篇作文可能会包含多个子主题,而这些子主题中有些在语义层面与题目的相关度较低,这使得单纯通过抽取特征词来向量化作文和题目并基于此来计算相似度,有可能因为不相关的子主题词导致作文和题目相似度的不准确,从而影响到跑题检测的最终结果。
基于以上问题,本文提出一种不同于现有的作文内容向量表示的方法,通过使用LDA主题生成模型对待测作文生成作文所包含的主题集合,并依据主题概率所占的权重按一定比例抽取作文主题中的关键词组合作为作文最终的主题信息,并基于这些核心主题词信息和作文题目信息之间的语义相似程度来判断作文是否跑题,进而避免了传统方法中使用作文特征词来判断作文是否跑题时所引入的噪声特征词问题。在此基础上,本文还提出了有效的作文和题目的相似度计算方法和基于局部密度的阈值抽取方法,最终实现了一种无需作文训练集和主题无关的无监督作文跑题检测系统。
1 相关工作
现有研究中,Higgins等[1-3]以tf*idf抽取作文的内容词,并将作文和题目表示为包含作文内容的空间向量,使用余弦相似度来计算作文和题目之间的相关程度。与传统方法所不同的是,Higgins等在工作中引入了参考题目,即与作文的目标题目不同的题目集合,通过计算待测作文与目标题目及给定参考题目之间的相似度,并对这些相似度进行排序,判断待测作文与目标题目之间的相似度占整个排序集合中的排名比例来判断待测作文是否跑题,例如,认为与目标题目相似度排名在前10%时认为是切题作文,否则认为是跑题作文。Persing和Ng[4]基于作文的丰富特征和人工事先标注好的与主题相关的句子分值,通过建立线性回归方程来构建作文与主题的一致性分值计算方法。该方法由于需要针对不同的作文主题训练得到不同的评分模型,属于有监督的主题一致性计算方法。Cummins等[5]分别使用分布式语义和信息检索中的伪相关反馈方法对作文题目进行扩充,提高了作文主题相关性的计算结果,同时系统还将该主题相关性模型纳入到一个有监督的评分系统中,结果表明该方法可以有效提升系统对作文的综合评分性能。Rei和Cummins[6]在句子级别的主题相关性判别领域做了一定的研究,其使用Word2Vec词向量按词语权重叠加的方式表示句子向量,结合tf*idf特征权值,以余弦相似度计算句子和主题的相关程度,实验结果表明该方法具有较强的鲁棒性。
陈志鹏等[7]将文本中的单词采用词向量表示,并基于分布式表示扩展与其语义上相近的词,基于此提升作文和题目的相似度计算。在其后续研究中[8]提出了一种基于文档发散度的概念,通过大规模作文回归模型训练得到发散度与跑题阈值的关系模型,从而实现对不同题目动态选取不同跑题阈值的方法。该方法需要事先具有大规模来自不同主题下已经标注好的作文训练数据,通过训练才能得到回归参数,所以本质上还是属于有监督的作文跑题检测方法。李晓亚[9]针对不同的应用场景分别提出了几个跑题检测模型,其中基于题目排序的跑题检测方法属于无监督跑题检测方法,该方法延续使用了空间向量模型方法并基于WordNet进行了词扩展来提升作文和题目的相似度比较。范弘屹等[10-11]也分别研究了基于HowNet或WordNet来计算和提升词语的语义相似度问题。梁茂成等[12-13]的工作中也涉及了作文内容分析和相似度的计算,但均需要事先标注好的作文训练语料,并采用回归或分类方法实现作文的特征抽取和向量表示等工作,属于有监督的方法。
已有的无监督作文跑题检测方法从不同层面改进了作文与题目的语义相似度计算,进而提升作文跑题检测的结果,但是这些方法是将作文表示为内容向量,并采用tf*idf特征词抽取方法来表示作文,依然存在非主题词被选入所导致的噪声问题。同时,已有的无监督方法中Higgins明确给出了作文跑题的阈值判断方法,该方法通过判断作文与参考题目和目标题目之间的相似度差异来检测作文是否为跑题作文。
针对现有方法的不足,本文提出一种基于作文主题词抽取和局部密度阈值选择的无监督作文跑题检测方法,主要贡献包括: ①基于LDA主题生成模型预测待测作文的主题分布,并根据主题分布概率抽取更为准确的作文主题词信息;②提出面向作文跑题检测的有效相似度计算方法;③根据作文切题度分布密度实现对跑题阈值的自动抽取。
实验结果表明本文提出的作文跑题检测方法能有效识别跑题作文。
2 基于局部密度的无监督作文跑题检测方法
2.1 作文关键词抽取
通常,一篇作文为了论证作者的思想或观点,往往会通过几个子观点来论证其核心观点,因此一篇作文可能会包含多个子主题,例如一篇描写关于“大学生活”的作文,作者可能从学习和娱乐两个方面阐述其大学生活,并在作文中着重于学习方面的描写。因此,针对跑题检测,既要抽取出作文中有关学习方法的子主题,也要抽取其有关娱乐方面的子主题,并能够依据作文的侧重点对不同主题分别对待。基于这样一个思想,本文提出使用LDA主题生成模型[14]对作文进行主题抽取,利用LDA主题模型去“理解”作文的主题分布,并根据各个主题分布概率作为权重在各个主题下提取不同数量的关键词。
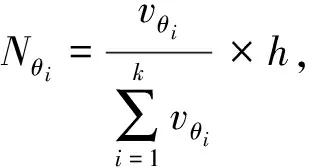
表1分别给出了GlobalShortageofFreshWater、TheEffectsComputershaveonPeople和TheFeaturesoftheSettingAffecttheCyclist三个题目作文中某一篇待测作文提取的关键词及其概率值,表中的主题1~主题5是按照主题概率排序后的前5个主题,参数中设置的抽取主题词个数为h=30。从表1可以看出,在作文的不同子主题下抽取出了不同数量的作文主题词,从而能更为真实地反映作文的内容主题。
2.2 作文题目主题词扩展
词的分布式表示是指将词表中的词映射为一个稠密的、低维的实值向量,每一维表示词的一个潜在特征,可以反映词与词之间的语义关系,通过单词的词向量形式可以找出与其语义相近的词。Word2vec[15-16]是Google在2013年开源的词向量工具包,可以实现将词语表示成具有语义的词向量,通过词向量的余弦相似度可以测量出词语间的语义距离,从而用于获取语义相近的词语。
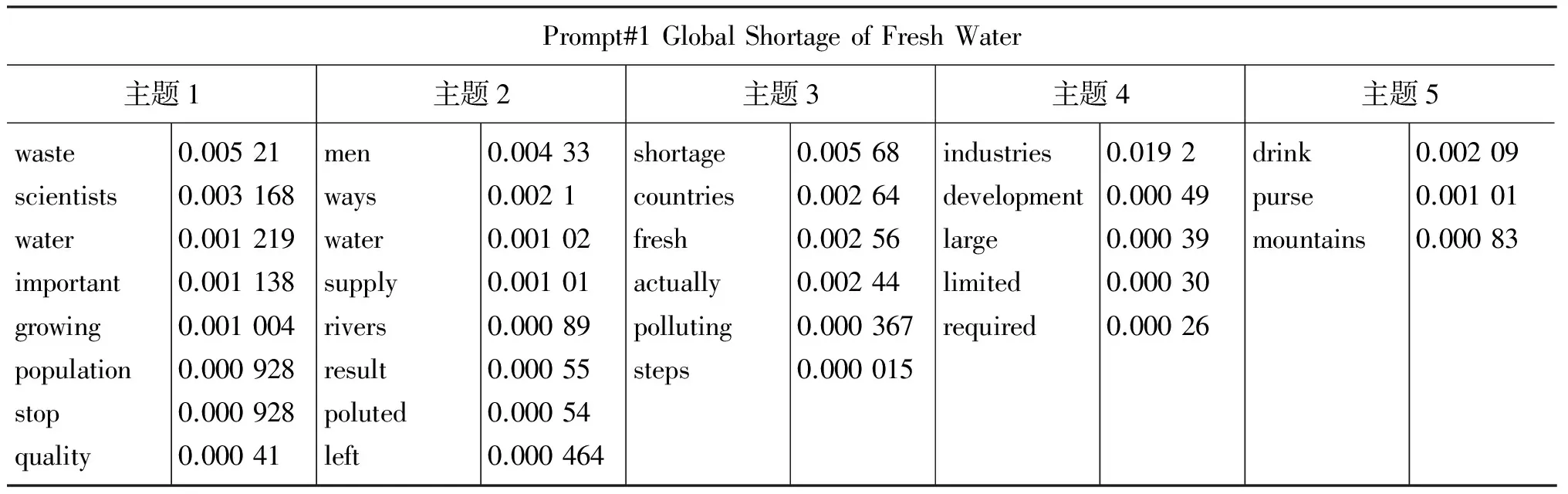
表1 本文方法在3个主题中各选取一篇待测作文抽取的特征词列表
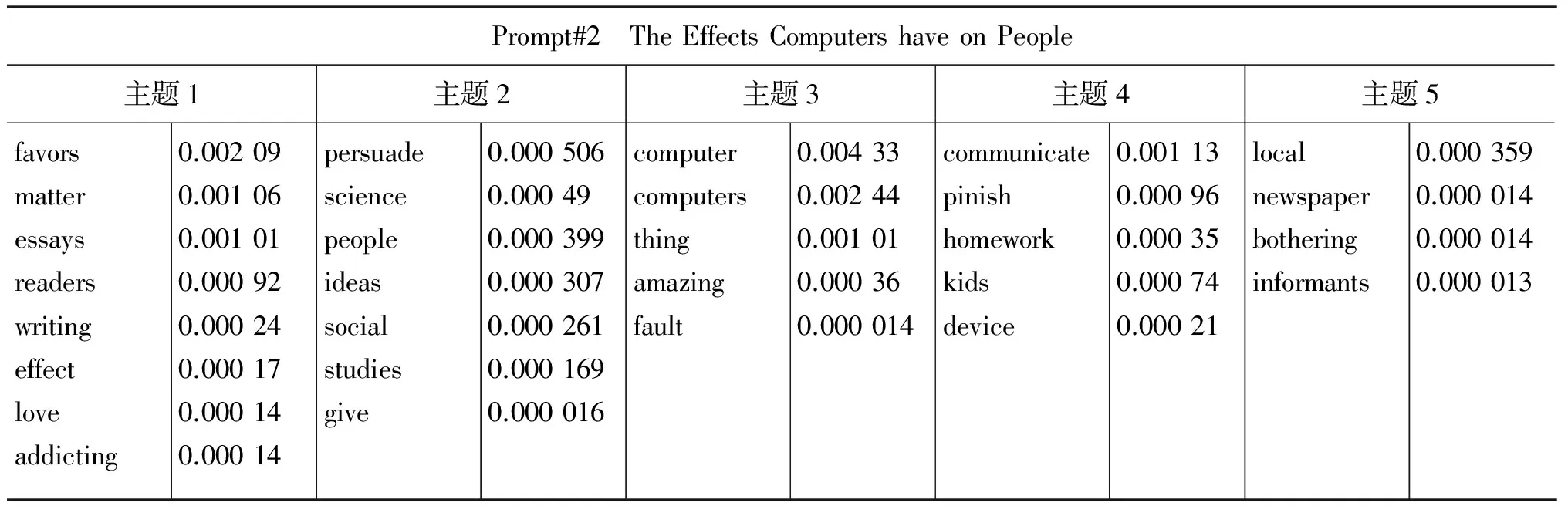
续表
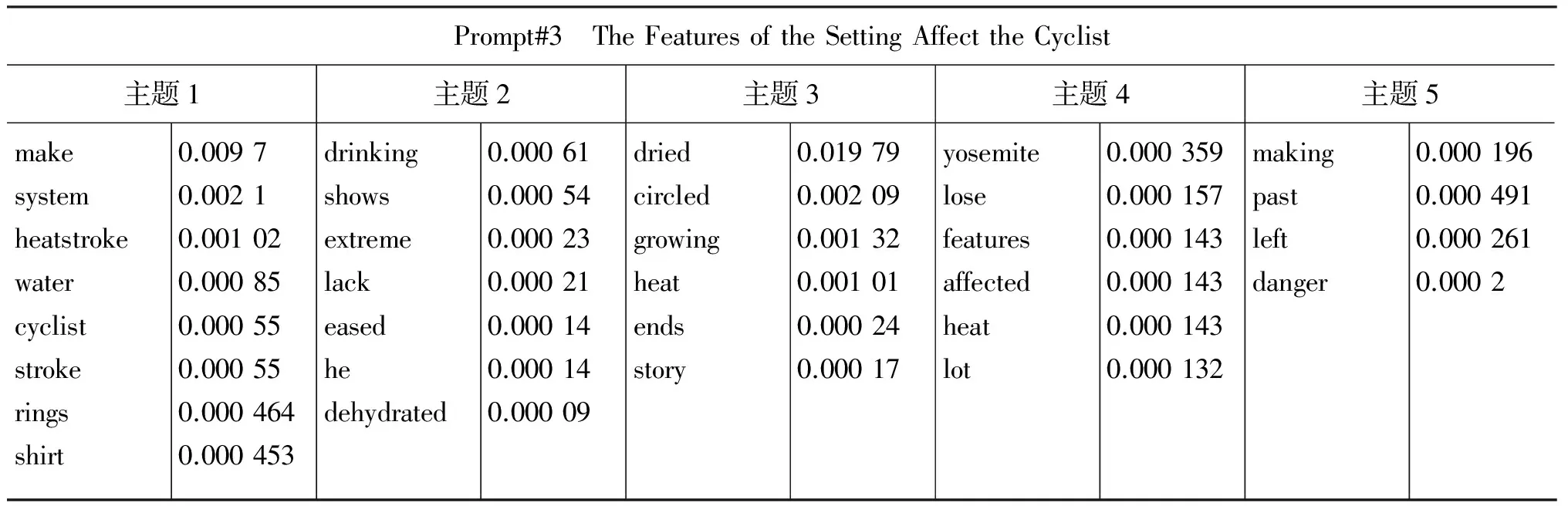
Prompt#3 TheFeaturesoftheSettingAffecttheCyclist主题1主题2主题3主题4主题5makesystemheatstrokewatercycliststrokeringsshirt0.00970.00210.001020.000850.000550.000550.0004640.000453drinkingshowsextremelackeasedhedehydrated0.000610.000540.000230.000210.000140.000140.00009driedcircledgrowingheatendsstory0.019790.002090.001320.001010.000240.00017yosemitelosefeaturesaffectedheatlot0.0003590.0001570.0001430.0001430.0001430.000132makingpastleftdanger0.0001960.0004910.0002610.0002
本文首先对题目进行分词和去停用词等预处理,假定题目预处理后的特征词列表为T=(t1,t2,...,tn),对该列表中的每个特征词ti,首先基于训练好的分布式词向量模型表示该特征词为一个向量,然后计算出和特征词ti在分布式向量上余弦相似度较高的单词作为其扩展词。本文中,我们对题目的每一个特征词选取了前10个相似度最大的词作为扩展词,分布式表示词向量训练和采用的是50维词向量模型。
2.3 作文切题度的定义和计算
针对本文的研究,我们将作文切题度定义为作文与题目之间在主题内容上的相似程度,通过判断作文与题目之间的切题度来划分该作文属于切题作文还是跑题作文。首先通过2.1节对待测作文进行主题词抽取,然后使用2.2节介绍的方法对作文题目基于语义上下文信息进行扩展,然后计算两者之间的相似度。
考虑到作文的不同子主题具有不同的重要程度,本文的相似度计算方法是针对题目扩展后的每个主题词,分别计算其与作文每个主题词的相似度,并使用最大相似度值作为当前主题词与作文主题词之间的相似度,以此类推计算下一个题目主题词与作文主题词的最大相似度,最后以题目主题词的最大相似度的平均值作为作文的最终切题度分值,详细分值计算如式(1)所示。
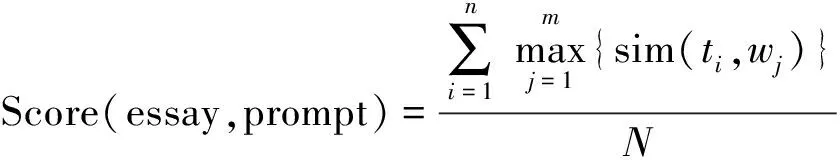
(1)
其中essay表示待测作文文本,(w1,w2,...,wm)为从作文essay中抽取出的主题词,prompt为作文的题目,(t1,t2,...,tn)为作文题目经过扩展后的全部主题词。sim(ti,wj)为题目主题词ti和作文主题词wj转换为词向量后的余弦相似度,N为题目扩展后的特征词的总数。
2.4 基于局部密度的阈值选择
跑题检测的最终目标是将待测作文划分成跑题和切题两个类别,理论上如果能够找到某一个维度或多个维度指标,使得切题作文和跑题作文各自聚集成独立的两个簇,则可以比较好地找到两个簇的边界阈值,从而划分作文为切题簇或跑题簇,达到跑题检测的目的。我们发现,虽然跑题作文本身的内容主题差异较大,但在实际作文数据中,由于跑题作文与作文题目无关,内容差异大,因此跑题作文之间切题度的差值会大于切题作文之间切题度的差值,因此我们认为作文的局部密度可以有效划分开跑题作文和切题作文。基于此,本文提出了一种基于局部密度的阈值选择策略,具体算法描述如下:

基于局部密度的阈值选择算法
3 实验设置与结果分析
3.1 实验数据
为了验证本文所提方法的有效性,分别选取了以英语为母语的学习者和以英语为二语的中国英语学习者所写的两个不同类型的作文语料库,选取了其中的八个作文主题下共9 381篇作文进行测试,文中将这八个作文主题分别标号Prompt#1~Prompt#8,其中Prompt#1~Prompt#4来自Kaggle的作文评分比赛数据集*https://www.kaggle.com/c/asap-aes/data。,Prompt#5~ Prompt#8来自中国英语学习者语料库CLEC作文数据集[17],CLEC(Chinese learner English corpus)是由桂诗春和杨慧中老师主编的中国学习者英语语料库,该语料库包含了大学英语四级和大学英语六级等不同级别考试的作文,并对所有作文进行了手工错误标注和分数归类,实验中,我们对所测试的作文的错误标注信息进行了清除,使其尽量保持原始作文状态。
数据集中的跑题作文主要包括两个来源,一是从原始作文集中抽取并经过人工判定为跑题的低分作文,另一部分是从其他题目下随机抽取的不同主题的作文。其中,Prompt #1从原始作文集中提取最低分为0分并经人工判断为跑题的作文28篇,从Kaggle数据集中其他三个不同题目下分别随机抽取100篇,共300篇,合计为328篇跑题作文。Prompt #2从最低评分为5分的作文中人工判断筛选出跑题作文31篇,从Kaggle数据集其他三个不同题目下分别随机抽取90篇,共270篇,合计为301篇跑题作文。Prompt #3从原始作文集中提取最低分为0分并经过人工判断为跑题的作文三篇,从Kaggle数据集其他三个不同题目下分别随机抽取91篇,共273篇,合计为276篇跑题作文。Prompt #4从最低评分为1分的作文中人工判断筛选出跑题作文43篇,从Kaggle数据集其他三个不同题目下分别随机抽取50篇,共150,合计193篇跑题作文。Prompt #5、Prompt #6、Prompt #7和Prompt #8分别从CLEC语料库其他四个不同题目中随机抽取44篇、50篇、20篇和30篇跑题作文。整个实验数据集的详细描述如表2所示。
3.2 评价指标
采用信息检索中常用的检索正确率P(precision)、召回率R(recall)和F1度量值作为本文算法的评测指标。

表2 本文作文数据集描述
同时也参考了Higgins[1-3]中使用的FP(False Positive)和FN(False Negative)两个指标作为辅助评价指标,相应的五个指标计算公式描述如下:

(2)

(3)
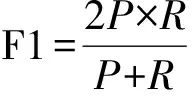
(4)

(5)

(6)
3.3 实验参数和比较的基准方法
将传统基于作文内容向量表示的方法作为本文的基准比较方法(文中以tf*idf方法来命名),同时参考了Higgins[2]工作中提到的使用拼写纠错和词形还原等预处理步骤,分别使用这两个预处理步骤加入到本文方法进行比较。实验还对Higgins提到的基于参考作文题目的阈值划分方法与本文的局部密度阈值划分方法进行了比较和分析。
实验中LDA主题-词概率分布矩阵所使用的训练语料采用了路透社语料库10 788个新闻文档共计130万字和90个主题,分布式词向量采用11GB大小的维基百科数据源进行训练,LDA关键词提取方法中参数k选取为5,提取的关键词数量为30,超参数α为0.1,超参数β为0.1,最大迭代次数为5 000。
3.4 实验结果与分析
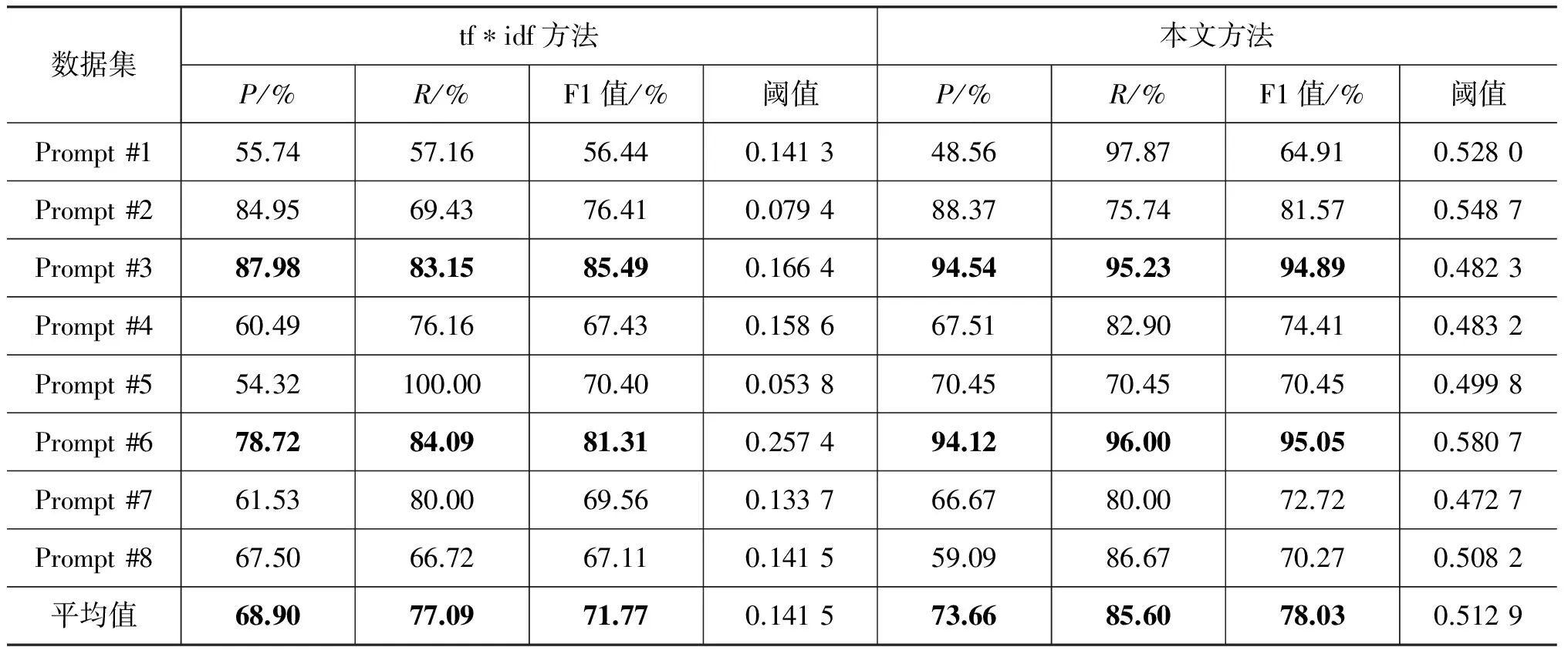
表3 tf*idf方法和本文方法在八个数据集上的实验结果对比
首先我们对传统基于作文内容向量表示的方法和本文方法进行了比较, 实验结果如表3所示。实验结果表明,本文方法相比传统的基于tf*idf权重的向量表示方法在八个作文数据集上F1值均有不同程度的提高,其中tf*idf方法最好的结果在数据集Prompt #3上,在该数据集上tf*idf方法的精度、召回率和F1度量值分别为87.98%、83.15%和85.49%,而本文方法在该数据集上的精度、召回率和F1度量值则分别为94.54%、95.23%和94.89%,分别提升了6.56%、12.08%和9.4%。在数据集Prompt #5上,tf*idf方法的F1度量值为81.31%,而本文方法在该数据集上的F1度量值则为95.05%,提升了13.74%。在所有八个作文数据集上,两种方法整体的平均F1度量值分别为71.77%和78.03%,提升了6.26%,整体效果提升显著。
为了进一步测试本文的方法,我们将为本文方法加入拼写纠错和词形还原两个预处理方法,并在八个数据集上进行实验,结果如表4所示。从表4可以看出,经过拼写检查预处理后,本文方法整体结果确实有所提升,在8个数据集上本文方法的平均准确率、平均召回率和平均F1值相比预处理前的结果分别提升了1.96%、1.17%和1.61%,同时本文方法相比传统tf*idf方法,经过拼写检查预处理后,平均F1值提升7.87%。表4还表明,词形还原对改善跑题检测的最终实验结果没有太大提升。
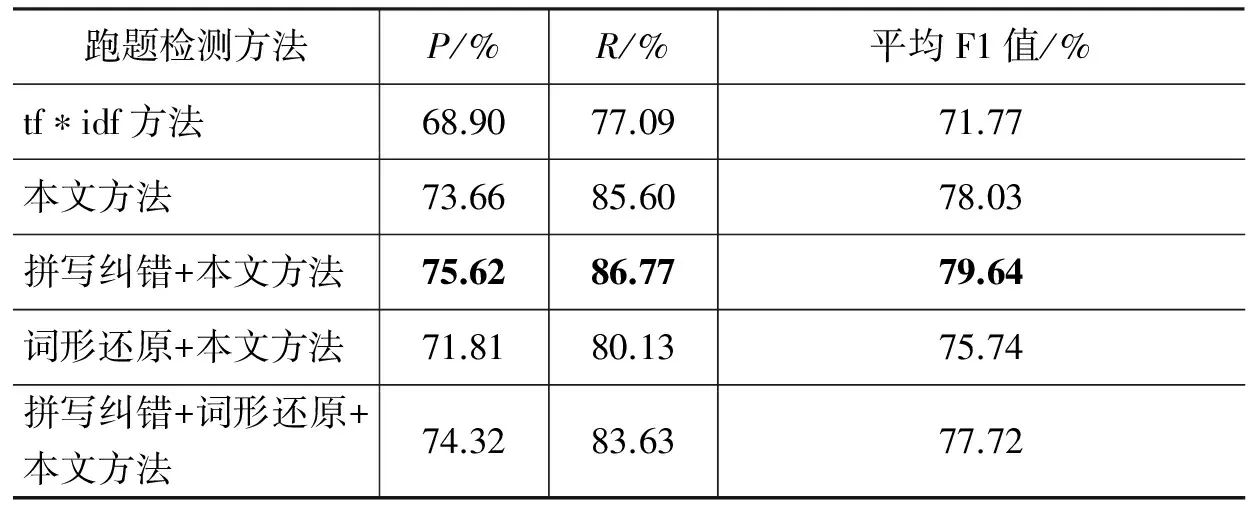
表4 各方法在八个数据集上实验结果对比
我们还对另外两个指标FN(False Negative)和FP(False Positive)值进行了实验对比,由于本文的数据集来源于两个类别,一个是以英语为母语学习者的作文数据集,作文数量较多,平均每个数据集在2 000篇以上,另一个是以英语为二语的中国英语学习者语料库,作文数量较少,平均为300篇左右。我们分别计算母语学习者和二语学习者数据集上几个跑题方法的效果,结果如表5所示。从表5可以看出,本文方法相比基准tf*idf方法在平均F1值和平均FN值、平均FP值上,均有所提升。同时从表5还可以看出,增加拼写检错预处理后,在二语学习者的数据集上本文方法平均F1值提升了2.04%,而在母语学习者数据集上提升了1.29%,这说明,增加拼写检查后,虽然两个指标都有所提升,但是针对二语学习者的作文数据,由于作文的语法错误相对比母语学习者多,因此经过纠错后,整体提升的效果更大。
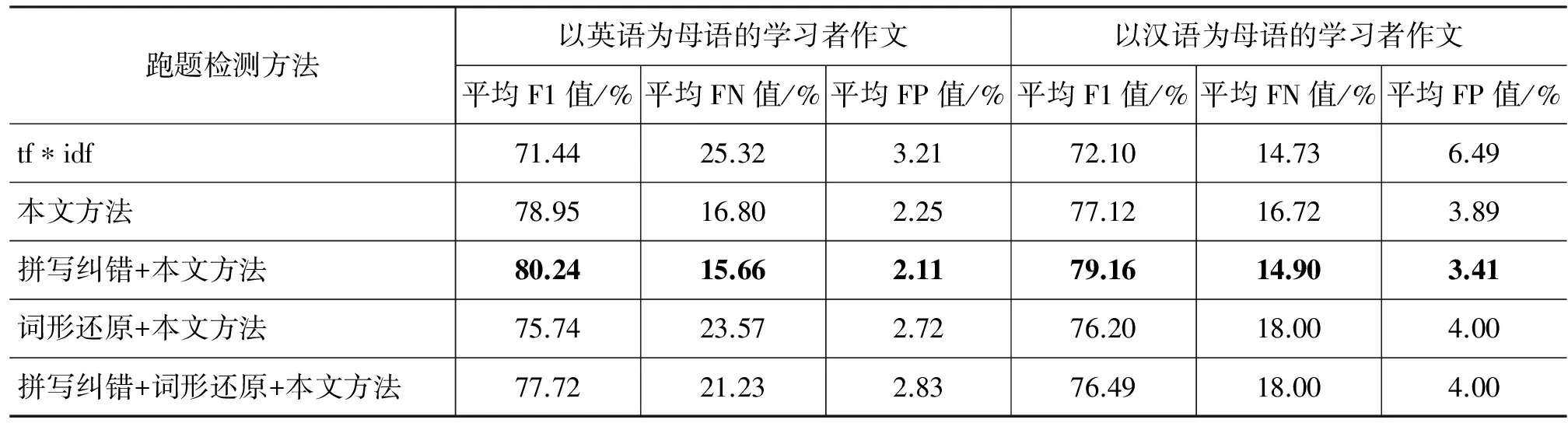
表5 各方法在不同语言学习者作文上的平均FN和平均FP值的实验结果对比
为了能够更为清晰地比较本文的局部密度划分和Higgins提到的基于参考作文题目的阈值划分方法的差异,本文对所有作文数据均采用本文的主题词抽取和题目扩展,并基于本文的相似度计算方法,但在划分跑题和切题作文上,分别采用本文的局部密度方法和Higgins的基于参考作文题目的方法,其中基于参考作文题目的方法以排序后是否排在前25%作为判断是否跑题的标准。实验中参考题目选取了来自高考、雅思和中学作文三个领域,各取三个参考题目共九个参考题目,这九个参考作文题目的详细描述如表6所示,实验比较结果如表7所示。实验结果表明,本文提出的基于局部密度的阈值划分方法优于基于参考题目的方法,在八个作文数据集上的平均F1值要高出6.52%。同时我们发现,Higgins的基于参考题目的方法总体召回率较低,我们认为这是因为跑题作文的主题具有不确定性,对不同的参考题目,其相关度排名有可能高,也有可能低,这是导致召回率较低的原因。

表6 参考题目描述
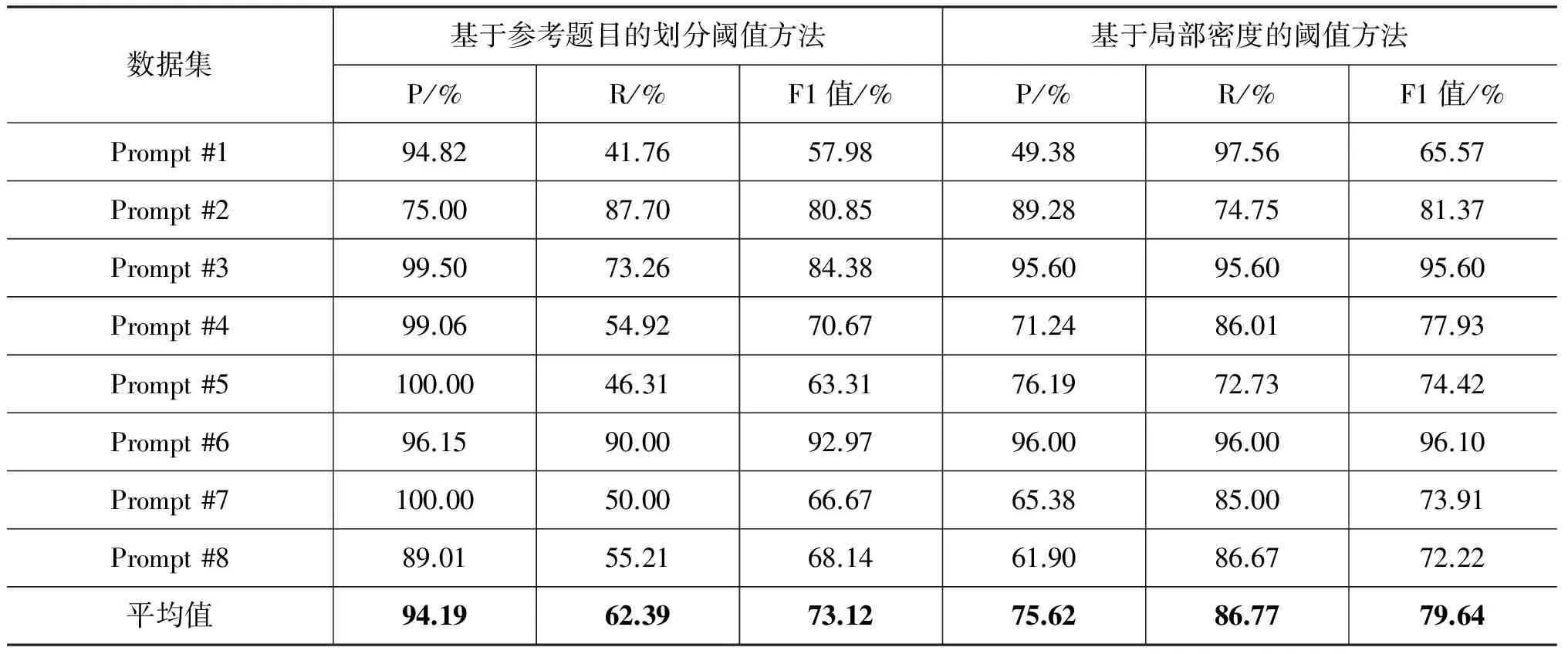
表7 基于参考题目和本文局部密度划分阈值实验结果对比
4 总结
本文提出了一种基于作文主题词抽取和基于局部密度阈值选择的无监督作文跑题检测方法,该方法的创新之处在于根据待测作文的主题分布提取作文的主题关键词,并研究出一种基于作文切题度局部密度的阈值抽取方法动态选取跑题阈值,该方法无需事先标注好的作文训练集,并可以适应不同的作文主题,具有很好的通用性。在多个真实数据集上的实验结果表明,该方法跑题检测性能优于传统的tf*idf向量表示方法。
实验中我们发现在部分数据集上效果不佳,如在数据集Prompt #1上的F1度量值只有64.91%,我们分别计算八个作文数据集的作文切题度方差,发现Prompt#1的作文切题度方差在所有数据集中值最大,为0.015,其他七个作文数据集的切题度分别为0.008、0.010、0.001、0.005、0.006、0.008和0.006,这说明Prompt #1的作文主题发散性较大。同时本文在原始作文数据集中抽取离题作文时是针对分数最低的作文进行人工判断和抽取的,有可能那些分数不为0分或者分数不是最低分的作文也是离题作文,这也可能导致本文算法的结果降低。针对发散性很高的作文集合,如何更有效地采用无监督阈值抽取方法并检测跑题作文是未来本文进一步需要研究和改进的方向。
[1] Burstein J, Higgins D. Advanced capabilities for evaluating student writing: Detecting off-topic essays without topic-specific training[C]//Proceedings of the 12th International Conference on Artificial Intelligence in Education, Nether Austerdam, July 2005: 112-119.
[2] Higgins D, Burstein J, Attali Y. Identifying off-topic student essays without topic-specific training data[J]. Natural Language Engineering, 2006, 12(02): 145-159.
[3] Louis A, Higgins D. Off-topic essay detection using short prompt texts[C]//Proceedings of NAACL HLT 2010 Fifth Workshop on Innovative Use of NLP for Building Educational Applications, 2010: 92-95.
[4] Persing I, Ng V. Modeling prompt adherence in student essays[C]//Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics (ACL 2014), MD: Baltimore, June 2014: 1534-1543.
[5] Cummins R, Yannakoudakis H, Briscoe T. Unsupervised modeling of topical relevance in L2 learner text[C]//Proceedings of 11th Workshop on Innovative Use of NLP for Building Educational Applications, California: San Diego, June 2016: 95-104.
[6] Rei M, Cummins R. Sentence similarity measures for fine-grained estimation of topical relevance in learner essays[C]//Proceedings of the arXiv, June 2016: 1606.03144.
[7] 陈志鹏,陈文亮,朱幕华. 利用词的分布式表示改进作文跑题检测[J].中文信息学报, 2015,29(5),PP: 178-184.
[8] 陈志鹏,陈文亮. 基于文档发散度的作文跑题检测[J]. 中文信息学报,2017, 31(1): 23-30.
[9] 李晓亚,中国大学生英语作文跑题检测系统的研究与设计[D]. 合肥: 中国科学技术大学硕士学位论文, 2016.
[10] 范弘屹,张仰森. 一种基于HowNet的词语语义相似度计算方法[J].北京信息科技大学学报,2014, 26(4):42-45.
[11] 颜伟. 基于WordNet的英语词语相似度计算[C]. 全国学生计算语言学研讨会,2004.
[12] 梁茂成. 中国学生英语作文自动评分模型构建[M], 北京: 外语教学与研究出版社,2011.
[13] 李霞,刘建达. 适用于中国外语学习者的英文作文全自动集成评分算法[J].中文信息学报, 2013, 27(5):100-106.
[14] David M B, Andrewy N, Michael I J. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003,3: 993-1022.
[15] Tomas Mikolov, Kai Chen, Greg Corrado,et al. Efficient estimation of word representations in vector space[C]//Proceedings of the arXiv, 2013:1301.3781.
[16] Tomas Mikolov, Ilya Sutskever, Kai Chen, et al. Distributed representations of words and phrases and their compositionality[C]//Proceedings of the arXiv, 2013: 1310.4546.
[17] 桂诗春,杨惠中. 中国英语学习者英语语料库[M]. 上海: 上海外语教育出版社,2003.
猜你喜欢
实用医药杂志(2021年4期)2021-01-11
中国医学计算机成像杂志(2020年6期)2020-03-14
艺术评论(2018年5期)2018-07-23
情感读本·道德篇(2017年6期)2017-07-04
课堂内外·创新作文小学版(2016年6期)2016-07-04
档案管理(2014年6期)2014-10-30
小猕猴学习画刊(2013年2期)2013-03-19
对联(2011年18期)2011-09-19
对联(2011年8期)2011-09-18
对联(2011年4期)2011-09-14
