
基于双向LSTM和两阶段方法的触发词识别
2017-03-12 08:30何馨宇李丽双
中文信息学报 2017年6期
何馨宇,李丽双
(大连理工大学 计算机科学与技术学院,辽宁 大连 116023)
0 引言
近年来,网络与信息技术不断发展,生物研究者对医学领域持续关注,生物研究方向的相关文献呈指数级数量增长,这使得相关研究人员从海量的医学文献中快速获取有益的知识变得相当困难,因此生物医学信息抽取技术应运而生。
生物医学领域信息抽取的最终目的是将研究者感兴趣的非结构化数据以结构化的形式表示与呈现,方便研究。生物领域信息抽取经历了从生物医学命名实体识别到二元关系抽取,再到生物医学事件抽取的发展过程。其中,生物事件抽取属于复杂的关系抽取,是为描述更为复杂的、更为详细的分子变化的过程而提出的。一个生物事件由一个触发词和一个或者多个要素组成,如在句子片段“Prevented induction of 1L-10 production by gp41 in mo-nocytes”中,参与事件的蛋白质为IL-10和gp41,包含三个事件,分别为Gene_expression事件,Positive_regulation事件和Negative_regulation事件,该片段中存在的事件如图1所示,三个事件的事件结构如下:
事件1(Type:Gene_expression,Trigger:production,Theme:IL-10);
事件2(Type:Positive_regulation,Trigger:induction,Theme:事件1,Cause:gp41);
事件3(Type:Negative_regulation,Trigger:Prevented,Theme:事件2)。

图1 文本片段生物事件示例图
生物事件抽取方法主要分为两类: 分阶段的pipeline方法和联合事件抽取方法。其中分阶段的pipeline方法为目前较为主流的事件抽取方法,该方法将事件抽取分为触发词识别、要素识别和后处理三个阶段,即先识别触发词,再根据触发词识别结果进行要素识别,最后通过后处理将触发词和要素构成整个事件。由于触发词识别错误很有可能被传播到要素识别阶段,从而影响整个生物医学事件抽取的性能,所以在分阶段的事件抽取过程中,生物医学事件触发词识别起到了至关重要的作用。研究显示,有超过60%的抽取错误要归因于触发词识别阶段[1]。因此,本文将触发词识别任务作为研究重点。目前,触发词识别方法大体可以分成两大类。
一是基于浅层机器学习的方法。这类方法一般将触发词识别视为一个多分类任务。通常需要人工的总结、抽取特征,代价较大,且系统的泛化能力较差。[2]Bjorne[3]等使用SVM作为分类器,抽取了触发词的形态学特征、句子特征、词性、词干特征及依存链上的信息等,在BioNLP’09SharedTask取得了最好的结果。Pyysalo等[4]总结了上下文、依存关系等丰富特征,并通过SVM进行分类,在MLEE语料[4]上的F值为75.84%;Zhou等[5]使用了半监督的学习模型,通过引入未标注的语料和事件抽取中的隐藏话题来识别触发词,在MLEE语料上的F值为76.89%;Zhou等[6]将领域知识中学习到的特征与人工特征进行融合,通过SVM进行触发词分类,在MLEE语料上的F值为78.32%。
二是基于神经网络和词向量的方法。为了解决生物医学事件触发词提取过程中人工设计特征较为复杂以及缺乏语义信息等问题,基于词向量和神经网络的深度学习方法最近相继被提出。神经网络通常以词向量作为模型的输入,用于获取词与词之间的语义信息。同时,网络模型可以自动地学习一些抽象的特征,避免了机器学习模型人工设计复杂特征带来的问题。Wang等[7]通过词向量得到词之间的句法和语义功能信息,然后将生成的特征向量送到神经网络中进行分类。Nie等[8]将Skip-gram模型得到的词向量转化成特征矩阵,用于初始化神经网络的权重,以解决神经网络模型在训练时只得到局部最优解的问题。
上文提及的方法均为一阶段的触发词识别方法。该类方法直接对触发词进行分类,即一次性识别触发词类型和非触发词。一阶段方法训练代价较大,且对于生物医学领域语料中存在的常见问题——数据不平衡问题也没有得到很好的解决。因此,本文提出了一种基于两阶段的触发词识别方法: 将触发词识别分为识别和分类两个阶段。第一阶段,仅识别文本中的触发词正例,但不区分这些触发词的类型, 分类任务中涉及到的类型仅为正例和负例;第二阶段,仅针对第一阶段识别出的触发词正例进行分类,分类任务中涉及到的类型全部为正例,所以,两个阶段中均对类不平衡有所缓解。此外,两阶段方法可以有效地避免过多的负例对正例分类造成的干扰。同时,在训练时间上,两阶段方法所用时间也更短、更高效。
深度学习采用词向量作为输入,可以避免由于人工特征向量稀疏而造成的维度灾难问题[9],并且能够避免浅层机器学习方法中人工总结设计特征费时费力的不足。而深层神经网络能够对原始数据逐层进行表示优化,使得数据表示对分类更有利,从而提升系统性能。因此,本文在两个阶段的不同分类任务中均采用了目前较为流行的长短时记忆递归神经网络(LSTM)。此外,本文利用大规模的生物医学文献训练了一种基于依存关系的词向量,与传统的Skip-gram模型相比,基于依存关系的词向量可以获得更加丰富的语义信息,有助于提升触发词的识别性能。而双向LSTM和句子向量对于LSTM性能的提升也具有一定的作用,是本文触发词识别方法能够取得较好效果的关键因素。
1 方法
图2所示为本文触发词识别的整体框架,该框架主要由两部分构成: 数据的向量表示,基于双向LSTM和两阶段方法的触发词识别。在数据的向量表示部分,本文先按照预训练的依存词向量,通过查表的方式将原始文本转换为词向量作为输入。此外,在训练的过程中不断对预训练的词向量进行微调,得到微调后的词向量,再通过对两套词向量进行相关运算获得句子级的向量特征信息,对输入进行优化。在基于双向LSTM和两阶段方法的触发词识别部分,本文在深度学习框架Theano的基础上,分别通过双向LSTM神经网络构建了两阶段方法中的二分类和多分类模型对输入数据进行触发词类型预测,相关内容将在后文详细阐述。
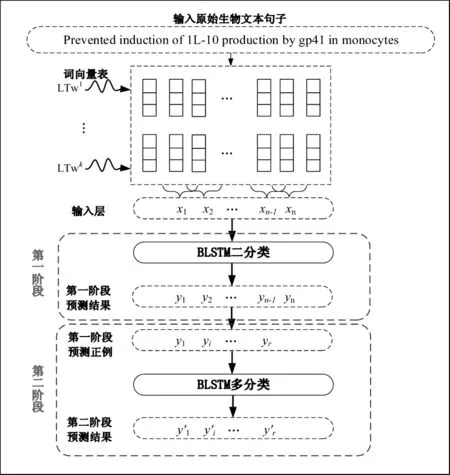
图2 基于两阶段方法的触发词识别框架
1.1 数据的向量表示
1.1.1 依存词向量
词向量也称为词嵌入或词表达,使用词向量替代传统的one-hot方式用于词汇表示,解决了one-hot表示带来的维数灾难问题。近年来,随着深度学习在文本挖掘领域的不断发展,词向量也得到了更为广泛的应用。将词向量作为额外特征或者直接作为学习算法的输入,已经对许多文本挖掘系统性能起到了提升作用。
目前较为常用的词向量训练工具是由Mikolov等于2013年发布的word2vec[10],Mikolov等提供了ContinuousBag-of-Word(CBOW)和Skip-gram两种常用的词向量训练模型,分别利用周围词预测目标词和利用目标词预测周围词。然而,与其他利用线性上下文信息来训练词向量的其他自然语言处理任务不同,生物医学触发词识别需要更多来自依存上下文的信息。为此,本文在word2vec的传统模型基础上,利用句子中词语的依存关系,通过依存上下文来代替传统word2vec模型中线性上下文训练得到依存词向量,使得触发词识别过程获得更多的语义信息支持。
在本文中,我们从PubMed数据库中下载了5.7GB的摘要内容,对摘要原文进行分句分词处理后,将其送至Gdep解析工具得到依存解析结果。最后,利用word2vecf[11]将得到的依存上下文信息用于训练所需要的依存词向量。Gdep是一个专门针对生物文本的依存句法分析工具,能够以较高的准确率对生物文本进行句法分析。如图3所示,依存上下文可以捕获使用小窗口线性上下文难以获得的长距离词间的关系,例如,在线性上下文中,当线性窗口大小为1和2时,“discovers”“star”和“telescope”的关系很难确定。因此,相较于线性上下文训练得到的词向量(例如Skip-gram、CBOW等模型),依存词向量可以获得更多的语义信息,从而提高触发词识别性能。
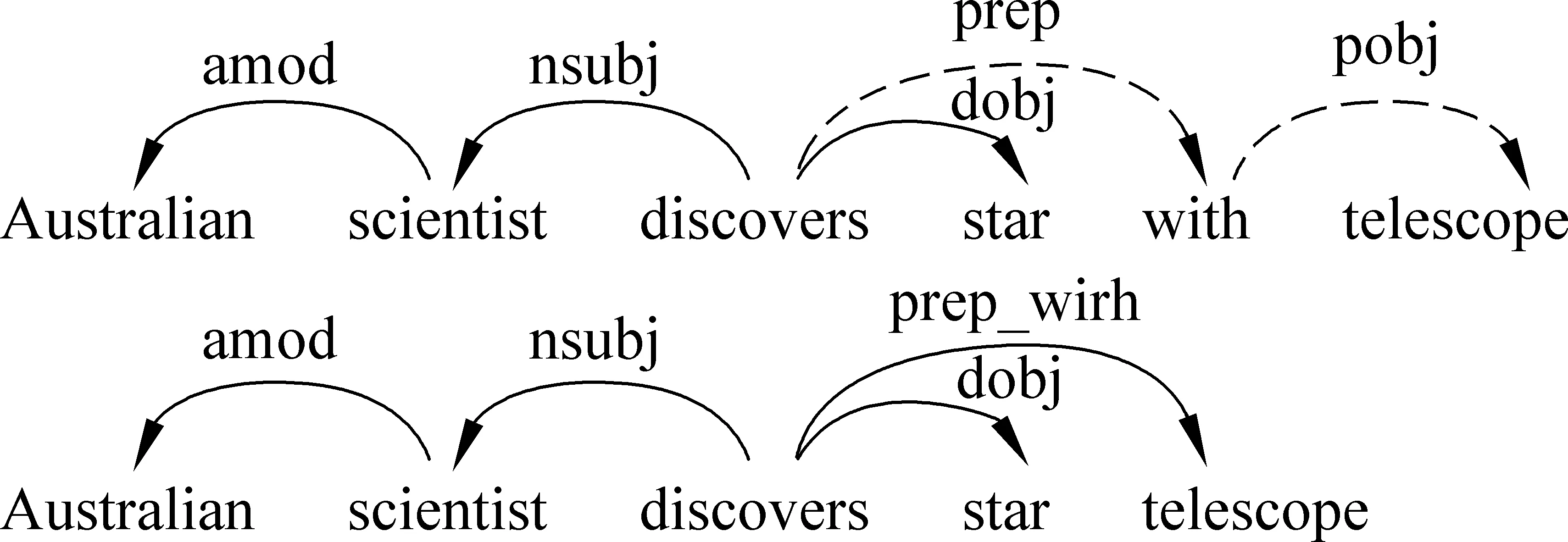
图3 依存关系示例
1.1.2 句子向量
在原始的LSTM框架中,所有的输入都是基于词级的向量特征信息,并且需要通过输入门控制其读入到记忆单元中。但是单纯的词级向量容易忽视句子本身潜在的特征信息,而把句子信息作为一种补充输入,有助于在隐层抽象出更加精确的特征表示。为了能够建立起单词与句子之间的潜在关系,本文在BLSTM框架中融入句子级的向量特征信息,从而将句子信息通过读入门输入到记忆单元中,获得更加丰富的文本信息。
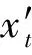
预训练的词向量包含了训练语料中无法捕捉到的特征信息,不断微调的词向量包含了更丰富、更具有针对性的文本信息,句子向量建立了单词与句子之间的潜在关系。实验证明,句子向量在生物触发词识别任务上也具有一定的提升性能。
1.2 基于双向LSTM和两阶段方法的触发词识别
1.2.1LSTM神经网络
传统的递归神经网络在有监督的训练过程中的误差传播会随着神经网络递归深度的增加而不断地减小或夸大,这种影响被称之为梯度弥散[13]。为了解决梯度弥散问题,20世纪90年代的研究人员进行了各种各样的尝试,目前Hochreiter和Schmidhuber[14]提出的长短时记忆(longshort-termmemory,LSTM)结构是目前最受研究者青睐也是最有效的用来解决递归神经网络梯度弥散问题的方法。LSTM的基本构成单位是一个记忆存储块,其主要包括一个记忆单元和三组具有自适应性的元素乘法门,即输入门、忘记门和输出门。这三个门是非线性的求和单元,旨在收集存储块内外的激活信息,并且通过乘法运算控制记忆单元中的激活值。正是这种有选择的读写上下文信息的优势极大地弥补了梯度弥散的缺陷。
双向LSTM神经网络[15]的基本思想是对每一句话分别采用顺序(从第一个词开始,从左往右递归)和逆序(从最后一个词开始,从右向左递归)递归神经网络计算得到两套不同的隐层表示,如图4所示。然后通过向量求和或拼接的方式计算得到最终的隐层表示。这样,文本序列中的每个单词的隐层都包含完整的前后上下文信息。相较于单向LSTM而言,双向LSTM可以提供更为全面的语义信息,从而提高系统性能。
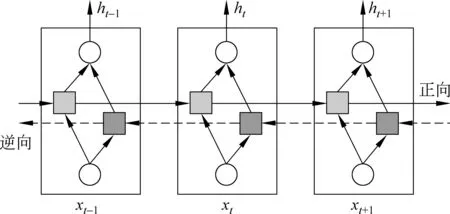
图4 双向递归神经网络的一般结构
1.2.2 两阶段方法
在本文中,我们采用了两阶段的触发词识别方法。将触发词的识别过程分为识别和分类两个阶段。
(1) 识别阶段
在这个阶段中,生物医学文献中的触发词和非触发词被区别开来,但不对识别出的触发词进行分类,即此阶段为触发词二分类任务。在此阶段,我们通过双向LSTM构建触发词二分类模型,并对预测出来的触发词正例进行筛选,作为第二阶段的输入。
(2) 分类阶段
在这个阶段中,为识別阶段得到的触发词确定其具体类型,此阶段为触发词的多分类任务。在此阶段,我们通过双向LSTM构建触发词多分类模型,并将第一阶段识别出来的正例按照预定义的19种触发词类型进行分类,之后在预测结果中加回第一阶段过滤掉的预测负例,从而得到MLEE语料测试集的完整预测结果。
为了更好地与一阶段方法比较,本文在触发词识别的两阶段实验中均采用了与一阶段方法相同的双向LSTM神经网络构建触发词二分类和多分类的模型,同时采用了依存词向量捕捉词语语义信息,增加了句子向量信息,建立词级特征和句子级特征之间的联系,丰富上下文信息,得到更加精确的隐层表示。
2 实验与分析
2.1 语料及评价方法
为了对本文提出的触发词识别方法进行评价,本文在生物信息抽取领域的通用语料——MLEE[7]语料上进行了触发词识别实验。MLEE语料由Pyysalo[4]组织标注,不仅抽取分子级别的事件,而且还面向细胞、组织、器官等更多的生物实体相关的事件,共包含了19种事件类型,涵盖了从分子到器官水平的大多数事件类型。这些事件类型按照功能可以被分为“Anatomical”“Molecular”“General”“Planned”四大类,具体类型包括“Cellproliferation”“Regulation”“Bloodvesseldevelopment”等。此外,MLEE语料为了丰富事件表示还引入了更加精确的事件描述。该数据集的数据静态分布如表1所示。
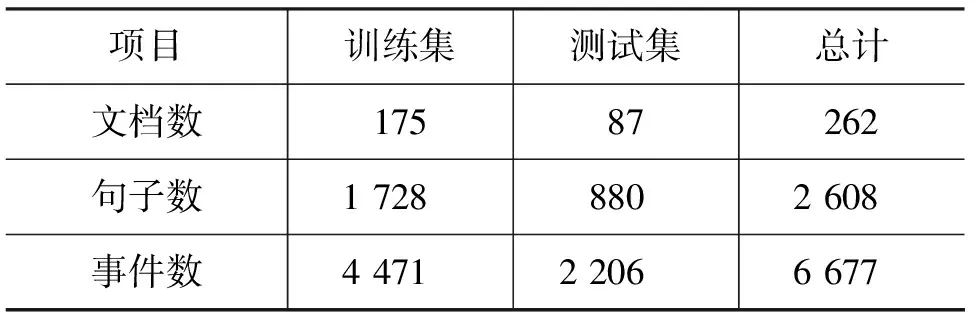
表1 MLEE数据集的统计数据
本文使用三个性能评价指标评价每类触发词的性能,分别是准确率Precision(P)、召回率Recall(R)和F值F-score(F)。其定义为公式:
其中TP(true positives)表示正例中判断正确的样本数,FP(false positives)表示负例中判断错误的样本数,FN(false negatives)表示正例中判断错误的样本数。
2.2 实验结果及分析
为了能够更好地比较不同神经网络结构之间触发词识别的性能差异,本文对所有实验采用了统一的参数标准。在一阶段方法和两阶段方法中的不同阶段训练模型时,梯度下降的学习率均设置为0.001,最大迭代次数设置为200次,隐层节点数为200,输入层的上下文窗口规定为 5。
2.2.1 依存词向量vs Skip-gram模型词向量
如1.1节所述,基于依存关系的词向量可以获得更多的语义信息,从而提高触发词识别性能。为了验证依存词向量对于触发词识别性能的影响,本文针对基于单向LSTM的一阶段触发词识别方法,分别采用了两种不同的词向量,即通过word2vec词向量训练工具,Skip-gram模型训练的普通词向量和使用word2vecf[11]词向量训练工具训练的基于依存关系的词向量,词向量维度均为200。触发词识别性能如表2所示(第1行&第2行),基于依存词向量的触发词识别F值较基于Skip-gram模型训练的词向量的触发词识别F值提高1.8%。
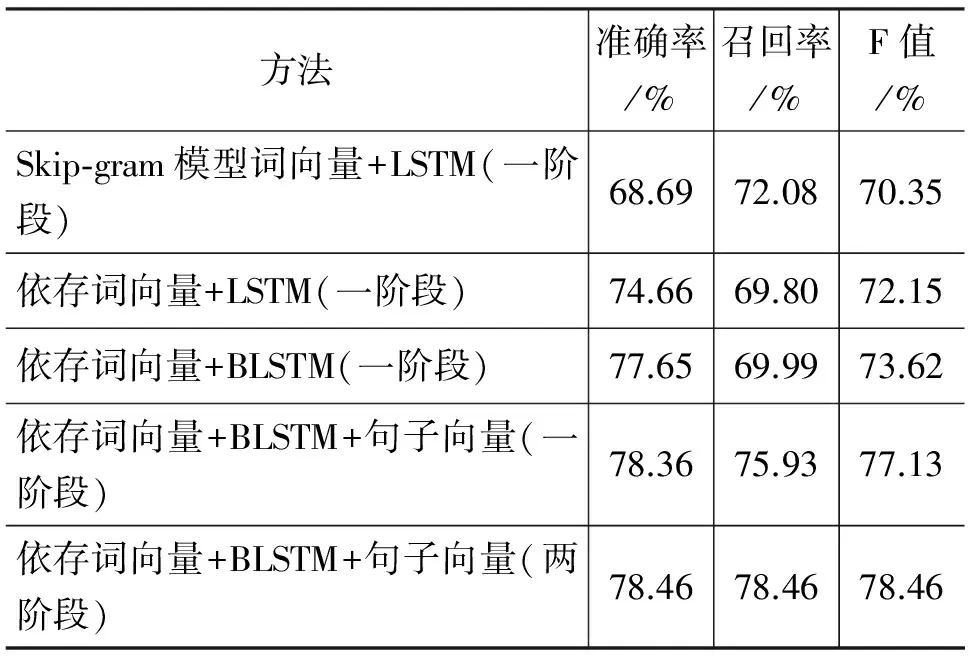
表2 不同方法的触发词识别性能对比
2.2.2 基于LSTM的触发词识别vs.基于BLSTM的触发词识别结果
为了能够在单向的基础上, 进一步探究双向递归神经网络的识别性能,实验采用了对正向和逆向LSTM的隐层相加的方式表示新的隐层,识别的F值为73.62%,比单向的LSTM提高了1.47%,如表2第2行&第3行所示。从性能上看,无论是召回率还是准确率,双向的LSTM递归神经网络明显优于单向的递归神经网络。这主要是因为双向的递归神经网络可以访问更加丰富的上下文信息。
2.2.3 句子向量对触发词识别性能的影响
为了验证句子向量对于双向LSTM性能的影响,本文在上述实验的基础上增加了句子向量。如前文所述,本文句子向量的计算采取的是句子中所有单词对应的预训练词向量和微调后词向量的差值加和求平均的方式。如表2所示,从性能上看,增加句子向量后的F值(第4行)较不加句子向量的F值(第3行)提升了3.51%,可见句子级的向量特征信息可以通过获取丰富的文本信息从而提升系统的识别性能。
2.2.4 一阶段方法的触发词识别vs.两阶段方法的触发词识别结果
在两阶段的触发词识别方法中,触发词识别被分为识别和分类两个阶段。在识别阶段,候选实例仅被识别为触发词和非触发词两类,语料中的类型数目比例为“所有正例总数: 负例总数”,而一阶段方法中类型的比例为“每个子类数目: 负例总数”。显然,对于两阶段方法中的第一阶段而言,这个比例将大于一阶段方法的相应比例,从而缓解了类不平衡的问题;在分类阶段,由于只对识别阶段筛选出来的预测正例进行分类,数据集中类的不平衡问题也得到了很好的缓解。此外,这种方式也可以有效地避免过多的负例对正例分类造成的干扰。同时,实验表明,在训练时间上,两阶段方法的训练时间也更短,更高效。综上,针对触发词识别任务而言,两阶段方法是一个比较有效的方法。为了验证两阶段方法的有效性,本文在基于依存词向量、双向LSTM和句子向量的实验基础上结合了两阶段方法,实验结果如表2(第5行)所示,两阶段方法的触发词识别相较于一阶段方法F值提高了1.33%。
2.2.5 本文系统与其他系统整体性能的比较
为了更好地评价本文提出方法的性能,我们选取了MLEE语料,将生物触发词识别的现有参考文献与本文进行了整体性能比较,结果如表3所示。本文所提出的方法在总体性能上,分别比Pyysalo等[4]基于丰富特征的SVM的分类方法F值高2.62%;比Zhou等[5]基于半监督的学习模型,通过引入未标注的语料和事件抽取中的隐藏话题来识别触发词的方法F值高1.57%;比Wang[7]基于依存关系的词向量的触发词识别的方法F值高1.36%;比Nie[8]等神经网络和词向量的方法F值高1.23%。此外,Zhou等人[6]将大规模语料中学习到的领域知识与人工总结的语义、句法等特征进行融合,然后通过SVM进行触发词分类,取得了目前MLEE语料上触发词识别的最好性能,本文方法F值比Zhou高0.14%。相较而言,本文方法通过深层神经网络自动学习特征,避免了抽取人工特征时的代价。
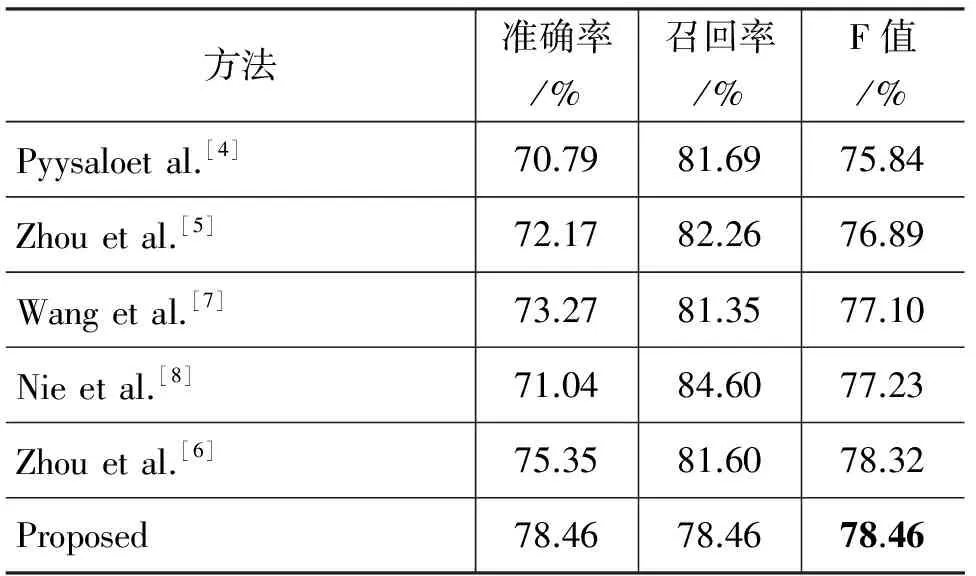
表3 本文系统与其他系统的性能比较* Nie et al.[8]原文中触发词识别结果为14类,本文按照19类对其进行了换算。
2.2.6 本文系统与其他系统在19个子类上的性能比较
MLEE语料上共有19种预定义事件类型,为了更好地分析本文所提出方法的触发词识别性能,我们分别在19个子类上与Pyysalo[9]、Zhou[11]、Nie[13]的触发词识别性能进行了比较,具体如表4所示。

表4 本文系统与其他系统在19个子类上的性能比较
可以看出,相较于Pyysalo提出的基于特征的SVM分类方法,本文提出的方法在八种类型的触发词识别性能上优于文献[4]的方法,例如在“Cell proliferation”,“Positive regulation”和“Binding”等类型上F值分别提升了6.06%、4.05%和0.39%。相较于Zhou等[6]的机器学习方法,本文提出的方法在六种类型的触发词识别性能上优于文献[6]的方法,例如在“Breakdown”,“Positive regulation”, “Regulation”和“Binding”等类型上F值分别提升了18.19%、1.89%、0.45%和0.76%。与Nie等[8]基于神经网络和触发词的方法相比,本文提出的方法有七种类型的触发词抽取结果好于文献[8]。其中“Positive regulation”和“Remodeling”等类型上F值分别提升了2.91%、50%。总体来看,本文方法在处理“Negative regulation”“Positive regulation”“Regulation”以及“Binding”等复杂事件类型时具有一定优势,而这些复杂事件触发词的抽取往往更需要语义信息的支持。
3 结论
本文针对生物触发词识别任务,提出了一种基于双向LSTM和两阶段方法的触发词识别模型,在生物事件抽取通用语料——MLEE语料上获得了较好的性能。主要结论如下:
首先,在生物触发词识别任务中,浅层的机器学习方法需要设计复杂的人工特征、丰富的专业领域知识,以及大量的实验选择特征。这一方面增加了系统的设计成本,另一方面也对系统的移植带来了困难。从而,本文采用了深层神经网络方式识别触发词。而LSTM神经网络可以学习长距离依赖的信息,避免了传统递归神经网络在处理长句子时产生的梯度弥散问题。因此,本文提出了基于双向LSTM的触发词识别模型。
其次,为了获取更好的数据表示,本文针对PubMed数据库中下载的大规模语料训练了基于依存关系的词向量,该词向量可以捕获长距离词间的关系,从而获得更加丰富的语义信息。此外,本文在预训练词向量的基础上扩展了一套随着训练过程不断微调的词向量,进而通过计算得到句子向量,句子向量信息可以建立起词级特征和句子级特征之间的联系,丰富上下文信息,得到更加精确的隐层表示。
最后,本文采用的两阶段方法可以缓解训练过程中存在的类不平衡问题。两阶段方法将触发词识别分成识别和分类两个阶段,通过将一次分类转换为两次分类,每个阶段数据不平衡的严重性低于一次分类,间接地缓解了数据不平衡问题。此外,在两阶段方法中,由于第二阶段只对预测的正例进行多分类,可以有效避免过多的负例对正例分类造成的干扰。同时,实验表明,在训练时间上,两阶段方法的训练时间也更短、更高效。综上,针对触发词识别任务而言,两阶段方法是一个比较有效的方法。
[1] Björne J. Biomedical event extraction with machine learning[J]. TUCS Dissertations, 2014(178): 1-121.
[2] Vlachos A. Two strong baselines for the BioNLP 2009 event extraction task[C]//Proceedings of the 2010 Workshop on Biomedical Natural Language Processing. Association for Computational Linguistics, 2010: 1-9.
[3] Bjorne J, Juho H, Filip G, et al. Extracting complex biological events with rich graph-based feature sets[C]//Proceedings of the Workshop on BioNLP: Shared Task, 2009: 10-18.
[4] Pyysalo S, Ohta T, Miwa M, et al. Event extraction across multiple levels of biological organization[J]. Bioinformatics, 2012, 28(18): i575-i581.
[5] Zhou D, Zhong D. A semi-supervised learning framework for biomedical event extraction based on hidden topics[J]. Artificial Intelligence in Medicine, 2015, 64(1): 51-58.
[6] Zhou D, Zhong D, He Y. Event trigger identification for biomedical events extraction using domain knowledge[J]. Bioinformatics, 2014, 30(11): 1587-1594.
[7] Wang J, Zhang J, Yuan A, et al. Biomedical event trigger detection by dependency-based word embedding[C]//Proceedings of IEEE International Conference on Bioinformatics and Biomedicine. IEEE, 2015: 429-432.
[8] Nie Y, Rong W, Zhang Y, et al. Embedding assisted prediction architecture for event trigger identification[J]. Journal of Bioinformatics & Computational Biology, 2015, 13(3): 575-577.
[9] Yoshua B, Rejean D, Pascal V, et al. A Neural Probabilistic Language Model[J]. Journal of Machine Learning Research (JMLR), 2003, 3: 1137-1155.
[10] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. 2013, arXiv preprint arXiv: 1301.3781.
[11] Levy O, Goldberg Y. Dependency-based word embeddings[C]//Proceedings of Meeting of the Association for Computational Linguistics, 2010: 302-308.
[12] Li L, Jin L, Jiang Y, et al. Recognizing biomedical named entities based on the sentence vector/twin word embeddings conditioned bidirectional LSTM[C]//Proceedings of China National Conference on Chinese Computational Linguistics. Springer International Publishing, 2016: 165-176.
[13] Kolen J, Kremer S. Gradient flow in recurrent nets: the difficulty of learning long-term dependencies[M]. Wiley-IEEE Press, 2007, 28(2): 237-243.
[14] Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780.
[15] Schuster M, Paliwal K. Bidirectional recurrent neural networks[J]. Signal Processing, 1997, 45(11): 2673-2681.
猜你喜欢
现代电力(2022年2期)2022-05-23
新高考·高一数学(2022年3期)2022-04-28
通信技术(2021年12期)2022-01-25
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
计算机应用与软件(2018年9期)2018-09-26
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
海军航空大学学报(2015年4期)2015-02-27
