
基于多模型融合的汉语介词短语识别
2017-03-12 08:48黄德根
中文信息学报 2017年6期
刘 彤,黄德根,张 聪
(大连理工大学 计算机学院,辽宁 大连 116024)
0 引言
介词短语(preposition phrase,PP)作为一种重要的短语类型,在汉语中占有很大的比例。文献[1]曾对包含十万字、六万词的语料所包含的介词短语的句子进行过统计分析,结果表明,科技类文章含有介词短语的句子占57%,而政论类文章包含介词短语的句子占63%。介词短语大多作为句子状语和补语,正确识别介词短语能够提高句子结构的清晰度,降低句子的复杂度,为下一步句法分析提供有效信息。提升介词短语的识别精度对于信息检索及文本分类效果都有较大提升,对于浅层句法分析、机器翻译等研究具有极其重要的意义。
现有的介词短语识别研究主要集中在介词短语学习模型的选择和介词短语的层次关系分析两方面。在学习模型的选择方面,文献[2]提出了一种结合可信搭配关系和三元边界统计模型的识别方法,根据固定搭配制定两个搭配模板,利用模板获取可信搭配关系,根据其识别介词短语,结合三元模型和规则识别剩余的介词短语;文献[3]提出了基于最大熵模型的识别方法,首先对介词短语抽取标记介词短语的特征,然后利用最大熵模型识别语料中的介词短语,最后利用依存树库中的介词短语边界词的语法知识对识别结果进行校正;文献[4]提出了基于HMM模型的识别方法,先利用HMM模型识别语料中的介词短语,然后利用依存语法对识别结果进行校正。
在层次关系方面,文献[5]提出了基于双层CRF模型的识别方法,针对介词短语的特点选择双层CRF模型进行识别,并制定规则对结果进行校正;文献[6]在文献[5]基础上提出了基于多层CRF模型的介词短语识别方法,通过CRF模型利用多个有效特征及复合特征模板从后向前逐个识别语料中的介词短语,然后利用基于转换的驱动学习方法制定了规则转换集,并用其对识别结果进行校正。
另外,文献[7]提出了基于简单名词短语的介词短语识别方法,简单名词短语(simple noun phrase,SNP)是文献[8]提出的内部不包含复杂修饰成分的名词短语,先识别出介词短语中的SNP并进行融合,简化介词短语的内部结构,降低介词短语识别的复杂性,再进行介词短语识别,是目前发表的识别效果相对较好的方法。
通过对以往的研究进行分析发现,当前介词短语识别中认可度较高的模型是CRF模型,但在介词嵌套方面的研究还不够细致。文献[6-7]已经考虑过介词短语嵌套情况,但并未对介词短语的结构层次进行深入的分析。他们采取的是将句子介词短语从后向前依次识别的方法,不能很好地解决介词短语的嵌套、并列结构并存的情况。
本文提出多模型融合的介词短语识别方法,通过分词融合将语料中的简单名词短语信息融合以简化语料,并对其训练得到内层训练模型,使用该模型识别测试语料中的内层介词短语,规则校正后将初始语料中的内层介词短语进行融合并修改其标注信息,重新进行训练得到嵌套介词识别模型,再将测试语料识别出的内层介词短语融合修改标注信息后用嵌套模型进行识别,规则校正后得到最终结果。本文在介词短语识别时着重考虑介词短语层次特点,将同等层级的介词短语同时识别,降低某层识别错误给其他层次所带来的影响。
1 理论基础
1.1 序列标注
条件随机场(conditional random fields,CRFs)模型[9]能够充分利用词语的上下文信息特征,适用于序列标注工作。CRF通过学习训练数据获得使训练样本标注序列在标注序列集合中条件概率最大的特征集合和特征权重。
序列标注需要将语料进行分词及词性标注,经过分词及词性标注后的汉语句子S=W1/P1W2/P2W3/P3…Wi/Pi…WN/PN(Wi为第i个词,Pi为第i个词的词性,N为词的个数)。
简单名词短语识别使用BIO标记边界状态,其中,B表示简单名词短语的左边界,I表示内部词语或右边界,O表示不在短语内部的词语。即,对于输入的词语序列S=W1/P1W2/P2W3/P3…Wi/Pi…WN/PN,任务的目标为获得一个对应的标注序列T*=T1T2T3…TN,使得该序列在所有可能的标注序列中概率最大,其中Ti∈{B,I,O}。
介词短语自动识别的任务是标注出句子中所有介词短语,而不对介词短语的内部成分进行分析。首先,把句子S经过分词及词性标注处理为“word(1)/pos(1) word(2)/pos(2) …word(i)/pos(i)…word(n)/pos(n)”的格式(word(i)为第i个词,pos(i)为第i个词的词性)。然后,获得对应的标注序列T*=T1T2T3…TN,使该序列在所有可能的标注序列中概率最大,其中,Ti可能取值有B、I、E、O,“B”表示介词短语的首词,“I”表示介词短语的内部词,“E”表示介词短语的尾词,“O”表示介词短语的外部词语。最后,输出标注序列不为“O”的所有词。
1.2 分词融合
本文中分词融合是指根据已经识别出来的序列标注结果进行词语合并,并制定规则修改合并后的词的词性等特征。主要包括两个方面: SNP融合、内层介词短语融合。
SNP融合: 首先识别出语料中的简单名词短语,然后将相应的词语进行合并,并将融合后的短语词性标注为“COM-NOUN”。例如,短语“在嫌疑人家中”的处理过程如表1所示。
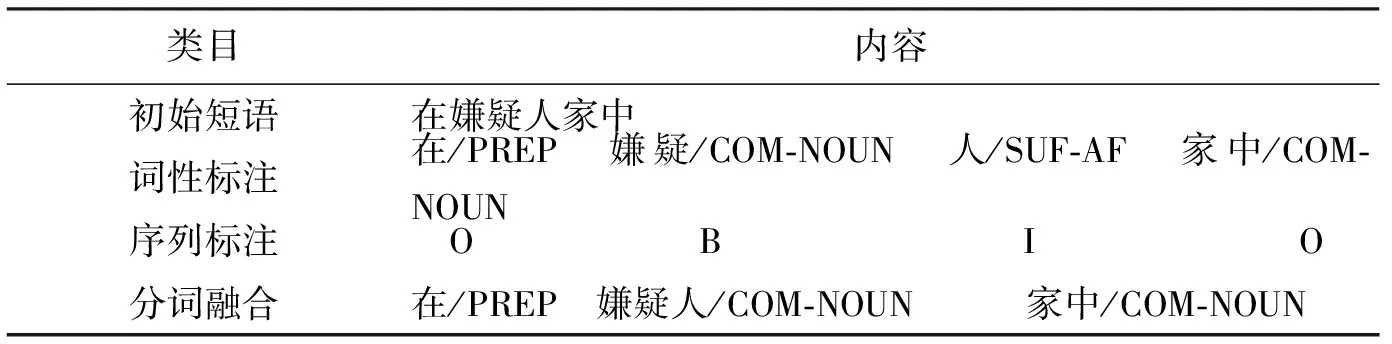
表 1 SNP分词融合示意表
介词短语融合应用在介词短语模板训练部分、介词短语识别模块。在介词短语模板训练部分,将训练语料内层介词短语融合,并将词性标注为PP,训练外层介词短语识别模板;在介词短语识别模块,将测试语料内层介词短语识别后,若介词短语无嵌套情况,识别后可进行去除,若有嵌套需将介词短语原语料中识别结果所对应的词语进行合并,并将合并后的介词短语词性标注为PP,简化语料以适应外层介词短语识别。例如,嵌套短语“本着对亲人负责的态度”处理过程如表2所示。
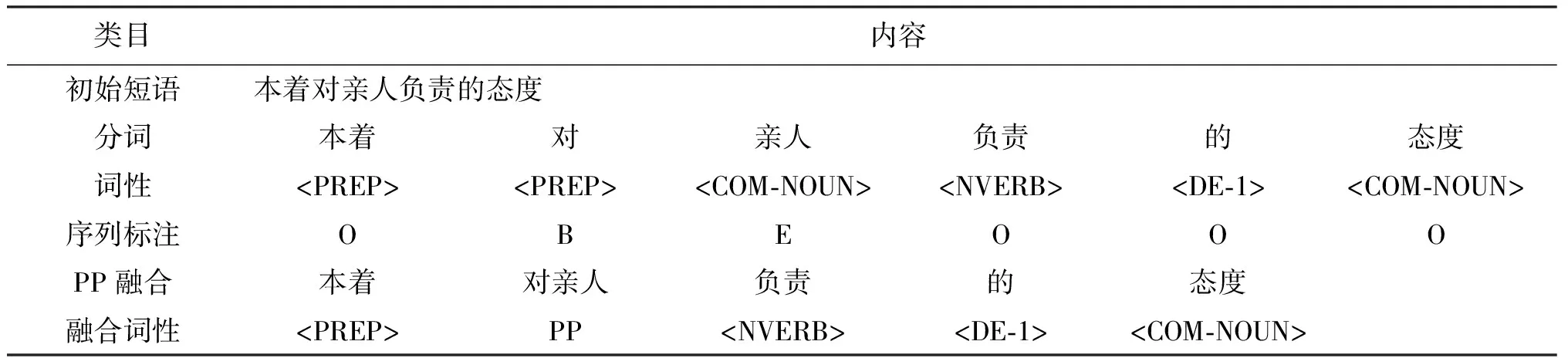
表 2 内层介词短语分词融合示意表
2 介词短语分层识别方法
具有嵌套并列结构的介词短语识别采用CRF模型,具体步骤如图1所示。
2.1 语料预处理
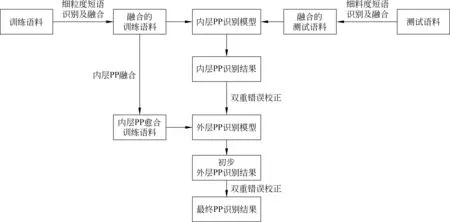
图1 分层识别流程图
本文首先使用CRF模型对语料中的简单名词短语进行识别,由于简单名词短语选取特征与介词短语不同,因此要将语料形式进行更改,只需要留下词和词性;然后针对PP内部短语的特性制定规则库,并将结果进行校正;最后依据识别校正后的简单名词短语将初始语料中相应的词语进行分词融合,使语料更加简洁,适合介词短语识别。
2.1.1 特征抽取及特征模板
本文识别简单名词短语使用的特征为词特征(word)、词性特征(pos),选取特征窗口大小为5,特征模板如表3所示,括号中的数字表示词的相对位置。

表 3 SNP特征模板特征描述及特征表示
2.1.2 规则库
依据介词短语内短语的特性制定规则库,修正简单名词短语识别结果,使其更适宜介词短语识别,部分规则如下:
① 若前词为程度副词,该程度副词修饰名词短语的第一个词,且第一个词为形容词时,则将程度副词合并到名词短语中。如“高层次”中“高”的前词为副词“更”,合并“更”到短语内得到“更高层次”。
② 若名词短语后界为“全部”等副词,则名词短语的后界为副词的前词。
③ 当名词短语前词为“沿”“依”时,若组成名词短语的前两个词为名词,且名词短语由三个或三个以上的词构成时,则其前界为名词的后词,否则标记不是名词短语。
④ 若后界为“你”等人称代词,将人称代词的前词标记为简单名词短语的后界。
2.2 介词短语分层识别
2.2.1 多模型训练
由于介词短语内部结构复杂,上下文联系密切,特征的选择对介词短语的识别效果有着重要影响。本文结合其他文献特征的选择,最终决定采用六个基本特征,具体如下:
① 词特征(word);
② 词性特征,即词性标注(pos);
③ 候选介词前界特征(CFB): 当前分句中该词之前是否存在候选介词;
④ 候选介词后界特征(CLB): 当前词是否可以作为介词短语后界,使用式(1)计算当前词可以作为后界的概率(阈值设置为0.05):
后界概率=当前词作为后界出现的次数/对应介词出现的总次数
(1)
⑤ 候选介词后词特征(CLW): 当前词是否可以作为介词短语后面的词,利用公式计算当前词可以作为后词的概率,阈值设置为0.05;
⑥ 词长特征(CL): 本文使用原子特征模板和复合特征模板,选择特征窗口大小为5进行实验。通过基本特征构成的集合作为CRF模型的原子特征模板,如表4所示。复合特征模板侧重特征间的搭配关系,提高了介词短语识别的精度,复合模板如表5所示,其中括号中的数字表示词的位置。

表 4 原子特征模板特征描述及特征表示

表 5 复合特征模板特征描述及特征表示
介词短语嵌套、并列现象的存在,使得介词短语识别难度加大,如句子“他们把对战士的爱、对边防的情一一送上哨卡”,包含并列结构“对战士的爱”“对边防的情”以及嵌套结构“把(对战士的爱)、(对边防的情)”。在文献[6]、文献[7]所采用的从右向左逐个介词短语识别的方法中,某个介词短语识别的错误会对其他介词短语的识别产生影响,如表6所示。逐个识别介词短语不能很好适用这种结构,本文将介词短语分层识别,从内层至外层逐层用CRF进行介词短语识别。另外,由于嵌套的内外层的上下文信息不同,本文提出需要训练不同的模型对不同层的介词短语进行识别的观点。
内层介词短语训练模板需将经过简单名词短语融合后的语料进行训练,外层介词短语训练模板需要将语料内层介词短语融合,并修改词性等相应的特征,重新训练生成。

表 6 从右向左逐个介词短语识别错误示例
2.2.2 分层识别
分层识别过程如下:
首先,将测试语料处理成适合内层介词短语识别的形式,修改前界、后界、后词等特征,同时修改人工标注结果以方便比对,修改方式为:
① 若有多层嵌套的介词短语,则只标注最内层介词短语。
② 若只有一层介词短语,则标注该层介词短语。
③ 去掉不含介词短语的句子,并用CRF识别内层介词短语。
如测试语料中的句子“他们本着对亲人、对家庭负责的态度”,经过分词、词性标注以及SNP识别融合后的结果是“他们/
随后,使用CRF工具利用训练好的介词短语内层识别模型识别出介词短语,并根据双重错误校正系统进行校正。然后,将识别校正后的内层介词短语进行融合并修改相关特征。如上例分词融合后结果为“他们/
最后,利用训练好的适合外层的模型对外层介词短语进行识别并进行双重错误校正。
2.2.3 转换规则集
本文在序列标注后规则处理时使用的转换规则集由两部分构成: 错误驱动学习(transformation-based error-driven learning, TBL)和语义分析得到的固定搭配。
TBL基本思想是通过错误驱动来修改识别结果,根据预先设计好的转换模板和目标函数寻找修正错误最多的转换规则,用生成的规则对标注结果进行修正,这部分规则由触发条件和转换规则组成。在进行结果校正时,若满足触发条件则进行修正。
例如,句子“统统记在参加保险者的名下。”满足触发条件的介词为“在”且其前词词性是动词,若分句中存在“的”,则标记“的”后面的词为“E”,介词后的词到“的”标记为“I”,结果如表7所示。

表 7 转换规则集示例
固定搭配是通过对介词短语进行语义分析得到的,本文参考分析国内的语言学家们对介词及介词短语的研究成果,包括范晓[10]的《介宾短语·复指短语·固定短语》,张斌[11]的《现代汉语虚词》,陈昌来[12]的《汉语“介词框架”研究》等,总结出一系列适用于本文语料的固定搭配,如“对……来说”“当……时”。当进行结果校正时,若当前分句满足固定搭配,则修改其标注结果。
3 实验设置及结果分析
3.1 实验设置
本实验语料选用《人民日报》2000年1月语料,包含7 037个介词短语信息。该语料经过分词工具[13]进行分词及词性标注,并进行了人工校正。此外,需将训练语料格式化,使其适合CRF训练,删除测试语料中不包含介词短语的句子,并对其同样进行格式化处理,再使用CRF工具进行序列标注。
实验方法方面,本文采取五倍交叉实验: 将语料平均分成五份,每份介词短语数目如表8所示。使用其中一份语料作为测试语料,其他四份作为训练语料,重复进行五次实验,取平均值作为最终结果。
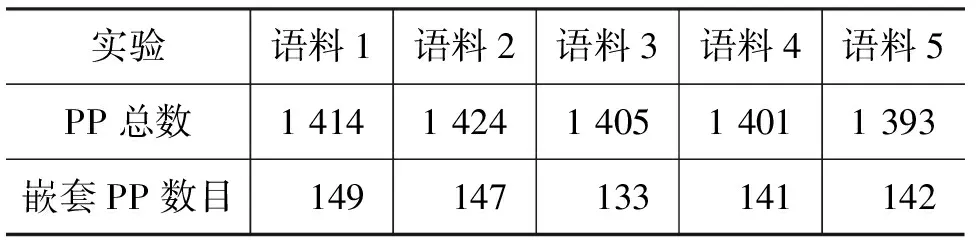
表 8 语料中介词短语数目统计
实验结果采用CoNLL2000评价标注,使用精确率(P)、召回率(R)和F值进行评价。精确率表示正确识别的介词短语所占识别出的介词短语百分比,反映了模型的识别能力。召回率表示正确识别的介词短语占语料中所有介词短语的百分比,反映了模型的查全能力。F值综合表征了精确率和召回率,体现了算法综合性能。P、R、F值的公式如下:
其中,Nc代表正确识别的介词短语数,Ni代表识别出的介词短语数,Ny代表语料中的介词短语总数。
3.2 实验结果及分析
本文进行了五个对比实验,实验1是融入简单名词短语的介词短语识别结果;实验2是在实验1的基础上对多层嵌套分层识别改进的结果,将从右向左逐个识别改为逐层识别;实验3对实验2进行了改进,对分层嵌套结构识别结果进行融合并对特征进行更新;实验4在实验3的基础上,外层介词短语识别时重新训练新的模型,识别后再加规则处理的结果。实验5是在实验4基础上,将外层介词短语识别完后更换规则得到的结果。实验结果如表9所示。
实验2的P、R、F值相比实验1分别提高了0.32%,0.33%,0.33%,说明在分层嵌套的情况下,以层为单位能够降低某个介词短语识别错误对其他介词短语造成的影响,这种方式更适合介词短语的识别;实验3每层识别后,不再去掉已经识别出来的介词短语,而是将其合并并修改标注信息,P、R、F值比实验2分别提高了0.47%,0.46%,0.46%,说明单纯去掉识别出来的介词短语会影响介词短语的上下文信息,可能会导致接下来的介词短语识别错误;实验4在不同层介词短语识别时采用不同的训练模型进行识别,P、R、F值比实验3分别提高了0.22%,0.21%,0.22%,说明不同层次的介词短语上下文信息也会不同,同一个训练模型不能很好地处理嵌套结构。实验5相比实验4 的P、R、F值分别提高了0.08%,0.07%,0.07%,说明不同层的介词短语由于结构不同所使用的校正规则信息也应不同。

表 9 实验结果统计
表10给出了本文方法和融合SNP方法(baseline)对嵌套并列结构介词短语识别的改进效果对比。

表 10 嵌套并列结构介词短语总数及识别错误数目
为了进一步说明本文方法的有效性,本文在同一语料上重现了相关的研究方法,表11为本文方法与其他方法的实验对比。

表11 与其他方法的结果比较
由表11的实验结果可见,与其他模型相比,CRF模型能够较好地利用上下文信息,并通过特征的重要性对其加权,识别结果精度较高;文献[7]的结果说明融入简单名词短语能够降低句子的复杂程度,提高识别精度;文献[6-7]采用的从右向左逐个介词短语的识别方法,某个介词短语识别错误会对接下来要识别的介词短语产生影响,本文对识别方法的改进,降低了复杂嵌套、并列结构介词短语的识别难度,不同层次采用不同的训练模型进行识别,能够更好地获得嵌套介词短语的特征信息,提高识别效果。
4 总结及展望
中文介词短语中,介词短语嵌套和并列现象是影响介词短语识别性能的重要问题之一。为此,本文提出了多模型融合的中文介词短语识别方法。实验结果表明:
① 介词短语具有嵌套、并列的复杂结构,从右向左识别介词短语的方法中,某个介词短语的识别错误会影响到后续的介词短语识别。分层识别方法不是每次只识别一个,而是将同一层次的介词短语同时进行识别,更适合存在嵌套、并列的介词短语。
② 内外层介词短语结构不同,上下文信息也不同,需要不同的训练模型进行识别,训练语料需要将标记的内层介词短语融合,并进行特征修改后训练嵌套模型,以适应外层介词短语识别。
③ 识别出的内层介词短语不再进行去除,而是根据识别结果将测试语料中相应的词语进行分词融合,并将相应特征进行修改,以适应外层介词短语识别。在外层识别时,重新训练新的模型使之适合当前层的识别,可提高识别效果。
在语料处理过程中,简单名词短语的识别错误可能会将介词短语的后界与后词合并在一起,导致识别介词短语错误。例如,句子“加大 对 大要案件 侦办力度”经过简单名词短语识别融合后结果为“加大 对 大要案件侦办力度”,介词短语识别结果为“对大要案件侦办力度”,而正确结果为“对大要案件”。因此后续的研究要改善简单名词短语的识别方法,使简单名词短语的粒度细化,以提高精确率和召回率。
[1] 吴云芳. 现代汉语介词结构的自动标注[D]. 北京: 北京语言文化大学硕士学位论文, 1998.
[2] 干俊伟, 黄德根. 汉语介词短语的自动识别[J]. 中文信息学报, 2005, 19(4):17-23.
[3] 卢朝华, 黄广君, 郭志兵. 基于最大熵的汉语介词短语识别研究[J]. 通信技术, 2010, 43(5):181-183.
[4] 奚建清, 罗强. 基于HMM的汉语介词短语自动识别研究[J]. 计算机工程, 2007, 33(3):172-173.
[5] 胡思磊. 基于CRF模型的汉语介词短语识别[D]. 大连: 大连理工大学硕士学位论文, 2008.
[6] 张杰. 基于多层CRFs的汉语介词短语识别研究[D]. 大连: 大连理工大学硕士学位论文, 2013.
[7] 桑乐园, 黄德根. 基于简单名词短语的汉语介词短语识别研究[J]. 中文信息学报, 2015, 29(6):8-12.
[8] 孙玉祥. 汉语简单名词短语自动识别的研究[D]. 大连: 大连理工大学硕士学位论文, 2014.
[9] Lafferty J D, Mccallum, et al. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[M]. Departmental Papers (CIS), 2001.
[10] 范晓. 介宾短语·复指短语·固定短语[M]. 北京: 人民教育出版社, 1990.
[11] 张斌. 现代汉语虚词[M]. 上海: 华东师范大学出版社, 2000.
[12] 陈昌来. 汉语“介词框架”研究[M]. 北京: 商务印书馆, 2014.
[13] Degen H, Deqin T. Context information and fragments based cross-domain word segmentation[J]. China Communications, 2012, 9(3):49-57.
猜你喜欢
通信技术(2021年12期)2022-01-25
疯狂英语·初中天地(2021年8期)2021-11-20
空军工程大学学报(2021年4期)2021-09-23
计算机应用与软件(2018年9期)2018-09-26
高中生·天天向上(2018年2期)2018-04-14
电影文学(2017年24期)2017-11-16
金融经济(2017年7期)2017-07-15
大众理财顾问(2016年9期)2016-10-11
外语教学理论与实践(2014年2期)2014-06-21
教学与管理(理论版)(2009年9期)2009-11-04
