
超视距空战仿真中的策略识别
2017-03-08 11:12张立民张兵强
海军航空大学学报 2017年1期
方 君,张立民,徐 涛,张兵强
(海军航空工程学院信息融合研究所,山东烟台264001)
超视距空战仿真中的策略识别
方 君,张立民,徐 涛,张兵强
(海军航空工程学院信息融合研究所,山东烟台264001)
针对超视距空战仿真中敌机策略的识别问题,研究了一种基于案例的策略识别方法。该方法通过构建包含假定的对手任务目标、观测数据、策略等内容的案例库,采用相似度计算选择与新的观测相似的案例库子集,并计算策略概率分布来识别对手策略。实验证明,相比与常规的基于案例推理方法,在案例中增加敌机任务目标提高了策略识别准确率,并且在假定敌机目标不正确时,能修复错误假定并进行策略识别,改善了基于案例策略识别方法的性能。
超视距;空战仿真;策略识别;相似度
随着机载电子设备和武器装备性能的不断提高,超视距(Beyond Visual Range,BVR)空战已成为现代空战的主要形式。BVR空战仿真中,CGF(Computer Generated Force)在机动动作的仿真周期内有充足的时间来预测对手机动并规划应对策略,对对手行动和计划的准确识别将大大降低规划应对策略的复杂程度[1]。然而,对对手进行远距离空中观测往往受机载雷达所获得的测量数据的限制,使得准确识别对手的行动很困难[2]。因此,怎样从不完整的观测信息中识别出对手的策略是BVR空战仿真中CGF策略识别的关键问题之一。
计划、行动和意图的识别近几年成为了AI中比较活跃的研究领域[3]。文献[4]在缺少具体动作或有噪声的情况下使用动作序列图来执行基于案例的计划识别,文献[5]采用基于案例推理(Case-Based Reasoning,CBR)方法对人类驾驶汽车的控制动作以及技术水平进行建模,来降低汽车驾驶时的碰撞风险,该方法在给定当前环境状态时通过CBR系统来预测驾驶员的下一个动作。但以上系统在上一步计划识别出现错误的情况下均不能进行正确计划识别,且不能改进计划识别过程。
文献[6]致力于研究为获得更多的计划信息,agents何时进行交互最合适或必须,其系统执行符号化的计划识别,通过决策特征树来判断多agent想定中某个agent是否应该与其他agents进行交互。和BVR领域不同,该系统假定能获得其他agent的全部观测信息。文献[7]展示了一个应用于足球游戏中的学习团队计划的agent,该agent通过识别对手团队计划来修复策略。文献[8]同样研究了该领域的计划识别,系统使用识别后的计划来辅助进行基于案例的强化学习。文献[9]将人类行为认知应用于识别老年人的行为,以调整agent在协助老年人时能提供更多帮助。与BVR领域的agent不同,这些认知agents能够获得更加完善的信息。
单一agent的计划可扩展到多agent领域,但面临的难度将会更大[10]。通过将团队计划表示为加权最大满意度问题,文献[11]验证了多agent计划识别可应用于部分可观测系统。但其算法的运行时间与缺失的信息数量成比例,明显不适用于类似于BVR空战的实时作战领域。
观测信息的不完整或信息品质的不确定是通过观测进行学习的CBR系统要致力解决的问题[12-14]。这类系统通过观测专家完成任务的行为过程来学习怎样执行任务,与有无专家知识库无关。
本文针对BVR空战中观测信息可能不完整的问题展开研究,采用基于案例推理的策略识别方法(Case-Based Policy Recognition,CBPR)。
该方法在传统的基于案例推理方法基础上,在案例中增加任务目标,并综合观测和任务目标进行推理。仿真结果表明,与传统的基于案例推理方法相比,该方法的策略识别准确率有了明显提高,同时,在假定任务目标不准确的情况下,该方法能有效纠正目标来提高策略识别准确率。
1 BVR空战策略识别
与传统的CBR不同的是CBPR采用由3部分组成的案例结构来有效识别仿真中对手的策略。传统的CBR中案例分为:问题和解决方案[15-18],BVR空战仿真领域可理解为当前观测和对手策略,CBPR增加了第三部分,即对手的任务目标。典型的CBR循环包括4个步骤:检索(Retrieval)、重用(Reuse)、修复(Revision)、保留(Retain)[19-20],由于本文重点是研究任务目标对策略识别的影响,故CBPR方法仅执行检索和重用步骤。
1.1 案例描述
案例描述是对实际问题及解决方案的抽象化表示,是基于案例推理方法的基础和前提,案例描述是否合理将对推理的结果产生重大影响。本文涉及BVR空战领域,故案例描述是由经验丰富的飞行员的指导给出的。CBPR中每个案例由3部分组成,可表示为C=<G,O,Π>。
G表示任务目标,主要包括5类:
①全力攻击(HA):直接接近并开火;
②迂回攻击(IA):迂回接近并开火;
③安全攻击(SA):攻击距离内开火并撤离;
④跟踪观察(TO):迂回接近但不开火;
⑤保持安全(BS):不接近。
在CBPR中,目标G用agent的不同愿望加权表示,agent的愿望包括攻击姿态、安全和开火,具体如表1所示。
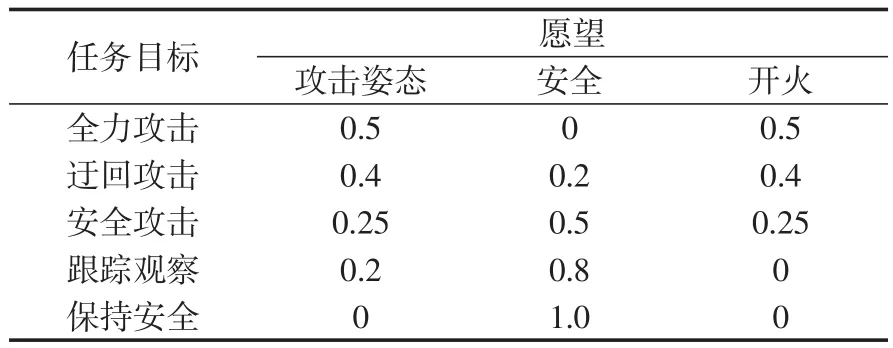
表1 任务目标加权愿望Tab.1 Weight of desires in mission goal
O表示实时观测,将记录对手agent的位置和方向信息。CBPR中观测被映射成不同的特征,如面向目标、目标距离等。每个特征均为0-1归一化值,体现了当前观测中该特征的表示程度。例如,当对手agent直接面向目标时,特征面向目标值为1,当面向目标90°时值为0.5。
BVR空战中的观测特征有如下几种:
①面向目标;
②目标距离;
③在目标武器攻击范围内;
④目标在武器攻击范围内;
⑤朝目标移动。
Π表示对手策略。策略是一系列动作的组合,超视距空战中主要包括两大类动作,即机动动作和武器发射动作。超视距空战机动动作主要包括以下4种:
①纯追踪:agent朝直接目标飞行;
②180°置尾:agent背离目标同向直线飞行;
③90°摆脱:agent保持与目标90°偏离角摆脱飞行;
④斜向机动:agent保持对目标雷达可探测最大方位角飞行。
发射武器分为发射武器、不发射武器2种。
组合机动和发射武器2类动作,策略Π共有8种组合。
1.2 案例检索
CBPR案例检索采用案例相似度判断方法。策略识别过程中,计算当前问题q的目标和观测与案例库CB中的每个案例c之间的相似度。
2个观测之间的相似度定义为每个特征之间的平均距离:
式(1)中:simo(q,c)表示当前问题q观测和案例c观测;σ(wf,qf,cf)表示特征f的两个值之间的加权距离;N是指特征个数。
2个目标之间的相似度定义为确定目标的加权愿望之间的距离:
2个案例之间的相似度定义为观测相似度和目标相似度的加权平均:
式(3)中,wo+wg=1。
采用以上公式计算案例相似度,CBPR将检索出一个案例子集Cq,案例子集中每个案例与问题q的相似度均大于给定的阈值参数τr。如果被检索的案例相似度均不超过阈值,策略被标记为未知,CBPR将根据新的观测信息继续重复检索过程。检索到Cq后,CBPR返回Cq中所有策略的归一化比例,可理解为策略的概率分布,其值与案例压缩过程中产生的案例权重有关。例如,策略p的比例为0.7,表示该策略有70%的可能是正在执行的策略。
1.3案例压缩
为控制案例库CB的大小,提高检索效率,在案例库中所有案例构建完成以后,需要对案例库案例进行压缩。
压缩算法首先合并策略相同、相似度超过给定阈值的案例,即2个策略相同的案例无论何时相似度超过给定的阈值τπ,则将案例合并同时在案例中增加关联计数器。
合并完成后,对案例库进行压缩。案例压缩主要针对策略相同相似度超过给定阈值τπ的案例。相似度计算采用1.2节中的式(3)。对于任一案例c∈CB,从案例集中检索出案例c′,其与c相似度超过给定阈值且策略相同,即sim(c,c′)>τπ且c⋅p=c′⋅p,则删除案例c′。
案例压缩完成后,将案例库中案例的关联计数器计数进行归一化处理,得到该案例的归一化策略分享权重。这种案例压缩方法能够避免出现大量相似案例,在检索时其对不常见案例具有压倒性的数量优势。最终的案例集比原始的规模要小很多,但保持了原始案例集中重要案例与非典型案例之间的差异。
1.4 CBPR应用于BVR想定
本文研究的CBPR算法目前主要针对BVR空战中1v1想定。在1v1想定运行前,假定红方CGF使用CBPR方法对目标策略进行识别,蓝方CGF每次仿真中执行固定的一个任务目标。首先提供想定的任务简报给红方CGF的CBPR组件,任务简报包含了期望的对手目标和案例集CB。仿真中,针对任务目标,CBPR按3种方式进行配置:①忽略任务目标,即只使用观测进行策略识别;②案例检索时考虑简报给定的任务目标,此时目标任务可能正确也可能不正确;③在案例检索过程中修复任务目标,
CBPR目标修复过程与策略搜索过程类似。对于一个新的观测q,CBPR检索案例集中所有观测相似度大于τr的案例子集Cq,并创建Cq中所有目标的概率分布。目标修复过程中,取平均概率最高的目标作为新的任务简报目标,用于检索对手将来的策略。
2 仿真验证
2.1 想定设置
为验证CBPR算法,本文创建了3种典型态势的1v1超视距空战想定,如图1所示,并对每个想定设置5种不同的对手任务目标,如1.1节所述。红机agent采用全力进攻策略,即在发现目标后直接朝目标飞行,并在蓝机进入武器射程时发射导弹。红机使用CBPR组件对蓝机进行策略识别。蓝机agent给定任务目标,假定对手采用固定策略,预测对手保持当前的速度和航向飞行。
为创建足够多的测试想定,本文对以上15对(想定、任务目标)均进行30次随机微调,共产生450种想定。想定微调指在一定的界限内独立修改每个agent的航向和位置,生成随机但有效的想定。这里有效是指红蓝双方最终会有一个agent进入另一个agent的雷达探测区域内。
2.2 仿真验证
本文采用k折交叉验证方法,将2.1节中描述的想定进行均分,其中k=10。每次提取一个测试集,其他作为训练集来生成案例集CB,并采用1.3节描述的案例压缩方法对案例集CB进行压缩。
为测试在CBPR算法中使用任务目标的效果,本文分别采用4种不同方法进行实验。
1)任务目标正确。即假定CBPR能获得正确的对手任务目标。仿真中对案例检索时目标相似度权重和观测相似度权重的分配进行了多次实验,结果表明目标权重设置在wq∈[ ] 15%,25%范围内时,对策略识别的结果影响很小,故分别设置wq=0.2、wq=0.8。
2)不考虑任务目标。该情况下,CBPR在进行策略识别时不使用任务目标,仅使用观测来识别策略,可理解为在案例检索过程中,目标相似度权重wq=0。
3)任务目标错误。此情况下除了给CBPR错误的任务目标外,其他与情况1)一致。
4)修复目标。这种情况下提供给CBPR一个错误的任务目标,但除了策略检索识别外,CBPR还运行一个仅使用观测的检索,该检索与策略检索不同,其返回的是任务目标而不是策略的概率分布。CBPR在想定运行中检查概率最大的任务目标是否与假定的任务目标,是否一致,如不一致,则返回目标差异判断,并用概率最大的任务目标修正假定的任务目标进行策略识别。
仿真实验结果如图2所示。图2给出了采用4种不同识别方法,对8种策略的平均识别准确率及总的平均值。可看出,当CBPR假定的对手任务目标正确时,其不同策略的识别准确率普遍优于CBPR不使用任务目标方法;当CBPR假定的对手任务目标不正确时,策略识别准确率极差;当CBPR假定的对手任务目标不正确,且CBPR执行目标修复算法时,策略识别准确率与CBPR假定的任务目标正确的情况基本相当。
3 结论
本文针对超视距空战仿真中敌机策略的识别问题,采用一种改进的基于案例策略识别方法,通过在案例中增加假定对手任务目标,综合任务目标及观测进行对手策略识别。实验表明,相比于传统的基于案例策略识别方法,该方法不仅在假定策略正确时能提高策略识别准确率,在假定目标策略错误时,该方法能够通过目标修复算法修正错误的任务目标,并提高对对手策略的识别准确率。
[1]CARBERRY S.Techniques for plan recognition[J].User Modeling and User-Adapted Interaction,2001,11(1):31-48.
[2]BORCK H,KARNEEB J,ALFORD R,et al.Case-based behavior recognition in beyond visual range air combat [C]//Proceedings of the Twenty-Eighth International Florida Artificial Intelligence Research Society Conference. Menlo Park:AAAI Press.2015:379-384.
[3]GEIB C,PYNADATH D.Plan,Activity,and Intent Recognition[J].Ai Magazine,2007,14(5):5505-5511.
[4]VATTAM S S,AHA D W,FLOYD M.Case-based plan recognition using action sequence graphs[C]//International Conference on Case-Based Reasoning.Heidelberg:Springer International Publishing.2014:495-510.
[5]ONTAÑÓN S,LEE Y C,SNODGRASS S,et al.Casebased prediction of teen driver behavior and skill[C]//International Conference on Case-Based Reasoning.Heidelberg:Springer International Publishing.2014:375-389.
[6]FAGUNDES M S,MENEGUZZI F,BORDINI R H,et al.Dealing with ambiguity in plan recognition under time constraints[C]//Proceedings of the 2014 International Conference on Autonomous Agents and Multi-agent Systems.New York:ACM Press.2014:389-396.
[7]LAVIERS K,SUKTHANKAR G.A real-time opponent modeling system for rush football[C]//Proceedings-International Joint Conference on Artificial Intelligence.Menlo Park:AAAI Press.2011:2476-2481.
[8]MOLINEAUX M,AHA D W,SUKTHANKAR G.Beating the defense:using plan recognition to inform learning agents[C]//Proceedings of the Twenty-Second International Florida Artificial Intelligence Research Society Conference.Menlo Park:AAAI Press.2009:337-343
[9]LEVINE S J,WILLIAMS B C.Concurrent plan recognition and execution for human-robot teams[C]//ICAPS. Menlo Park:ACM Press.2014:490-498.
[10]BANERJEE B,LYLE J,KRAEMER L.The complexity of multi-agent plan recognition[J].Autonomous Agents and Multi-Agent Systems,2015,29(1):40-72.
[11]ZHUO H H,LI L.Multi-agent plan recognition with partial team traces and plan libraries[C]//Proceedings of the International Joint Conference on Artificial Intelligence. Menlo Park:AAAI Press,2011:484-489.
[12]ONTAÑÓN S,MISHRA K,SUGANDH N,et al.Casebased planning and execution for real-time strategy games [C]//International Conference on Case-Based Reasoning. Berlin Heidelberg:Springer,2007:164-178.
[13]RUBIN J,WATSON I D.On combining decisions from multiple expert imitators for performance[C]//Proceedings of the Twenty-Second International Joint Conference.Menlo Park:AAAI Press,2011:344-349
[14]FLOYD M W,ESFANDIARI B,LAM K.A case-based reasoning approach to imitating robocup players[C]//Proceedings of the Twenty-First International Florida Artificial Intelligence Research Society Conference.Menlo Park:AAAI Press,2008:251-256.
[15]杨健,赵秦怡.基于案例的推理技术研究进展及应用[J].计算机工程与设计,2008,29(3):710-712. YANG JIAN,ZHAO QINYI.Research and application of CBR’s progression[J].Computer Engineering and Design,2008,29(3):710-712.(in Chinese)
[16]魏青,张世波.基于案例推理的研究综述[J].电脑知识与技术,2009,30(5):8518-8519. WEI QING,ZHANG SHIBO.The summary of casebased reasoning research[J].Computer Knowledge and Technology,2009,30(5):8518-8519.(in Chinese)
[17]罗忠良,王克运,康仁科,等.基于案例推理系统中案例检索算法的探索[J].计算机工程与应用,2005,41(25):230-232. LUO ZHONGLIANG,WANG KEYUN,KANG RENKE,et al.Study on a case retrieval algorithm in case-based reasoning system[J].Computer Engineering and Application,2005,41(25):230-232.(in Chinese)
[18]汤文宇.CBR的应用研究[D].南京:南京邮电大学,2007. TANG WENYU.The application Research of CBR[D]. Nanjing:Nanjing University of Posts and Telecomunications,2007.(in Chinese)
[19]蔡冬强,何钦铭.CBR技术在自动配色系统中的应用研究[J].浙江大学学报:工学版,2006,40(10):1692-1695. CAI DONGQIANG,HE QINMING.Research of CBR in colour-matching system[J].Journal of Zhejiang University:Engineering Science,2006,40(10):1692-1695.(in Chinese).
[20]王润生,贾希胜,王润泉.基于CBR的损伤评估系统研究[J].系统工程与电子技术,2005,27(10):1771-1775. WANG RUNSHENG,JIA XISHENG,WANG RUNQUAN.Research of the CBR-based damage assessment system[J].Systems Engineering and Electronics,2005,27(10):1771-1775.(in Chinese).
Policy Recognition in Beyond Visual Range Air Combat Simulation
FANG Jun,ZHANG Limin,XU Tao,ZHANG Bingqiang
(Research Institute of Information Fusion,NAAU,Yantai Shandong 264001,China)
To recognize the policy of adversary in beyond visual range air combat simulation,a case-based policy recogni⁃tion method was studied.In this method,a case base containing hypothetical mission goal,observations,and policy of ad⁃versarial aircraft was constructed.The similarity calculation was used to retrieval a subset of case base and calculate the probability distribution to recognize the adversary’s policy.Experiments showed that compared with the traditional casebased reasoning method,an adversary’s goal improved policy recognition.It also could recognize when its assumptions about the adversary agent’s goal were incorrect,and could correct these assumptions.
beyond visual range;air combat simulation;policy recognition;similarity
TP311
:A
1673-1522(2017)01-0116-05
10.7682/j.issn.1673-1522.2017.01.004
2016-12-06;
:2016-12-22
国家自然科学基金资助项目(91538201);泰山学者工程专项经费资助项目(ts201511020)
方 君(1979-),男,讲师,硕士。
猜你喜欢
中国毕业后医学教育(2022年4期)2022-11-29
宁夏大学学报(自然科学版)(2022年2期)2022-07-19
文史春秋(2022年4期)2022-06-16
宁夏大学学报(自然科学版)(2022年1期)2022-04-30
小哥白尼(军事科学)(2022年1期)2022-04-26
小哥白尼(军事科学)(2021年9期)2022-01-17
水上消防(2021年4期)2021-11-05
中国计算机报(2020年9期)2020-03-25
科技视界(2018年8期)2018-06-08
汽车与安全(2017年9期)2017-09-29
