
可拓分类知识挖掘系统的设计与实现
2017-03-01 04:32:00叶广仔李卫华刘晓蔚
计算机应用与软件 2017年1期
叶广仔 李卫华 刘晓蔚
1(东莞职业技术学院计算机工程系 广东 东莞 523808)2(广东工业大学计算机学院 广东 广州 510006)3(东莞职业技术学院管理科学系 广东 东莞 523808)
可拓分类知识挖掘系统的设计与实现
叶广仔1李卫华2刘晓蔚3
1(东莞职业技术学院计算机工程系 广东 东莞 523808)2(广东工业大学计算机学院 广东 广州 510006)3(东莞职业技术学院管理科学系 广东 东莞 523808)
针对决策者处理矛盾问题时需要动态分类知识作为参考依据的需求,研制可拓分类知识挖掘系统。系统采用B/S结构,利用jQuery技术实现Web前端开发,通过MVC框架模式实现后台开发。此外,系统增强了数据预处理能力,提出且实现了挖掘八类可拓分类知识以及动态生成信息元库和知识库。并给出系统在教师科研考核评价中的具体应用,为科研管理者找出适合促进教师科研工作的策略提供科学的依据。
可拓分类 知识挖掘 科研考核 jQuery技术
0 引 言
在实际工作中,处理矛盾问题时,决策者往往希望知道对象具有某种性质或符合某些要求的程度,在某些变换下是否会从具有变为不具有这些性质、从符合变为不符合这些要求,或反之。这样的一种动态分类知识,对作出更合适的决策具有重要的价值。但是,单靠人力去挖掘动态分类知识效率低且难以普及,因此,提出利用计算机技术协助人们完成这个任务。可拓分类知识挖掘系统是结合可拓数据挖掘技术[1]、数据库技术、可视化技术而形成的人工智能系统,可挖掘动态的分类知识。
自2004年提出,经过十年的研究和探索,可拓数据挖掘[2]逐步明确了其研究对象和目标,并初步形成一套挖掘可拓知识的基本理论以及基本方法[3-4]。近几年关于可拓数据挖掘的应用及其计算机实现开始被涉及,如文献[5]以CPI指数的变换对产品销售数据的影响为例来研究传导知识的挖掘,文献[6]研究了成品油税费改革对股票市场影响的传导知识挖掘,文献[7]进行了客户价值可拓知识挖掘软件研究。本文实现的可拓分类知识挖掘系统在系统设计及功能实现方面做出以下改进及优化:
(1) 系统设计方面:系统采用B/S结构,降低了客户端运行环境的软硬件要求;系统的Web前端采用jQuery技术[8],提升了系统与用户交互能力;系统后台使用MVC框架模式[9-10],加强了系统模块化,提高系统的重用性及降低维护成本。
(2) 系统功能方面:系统根据可拓知识挖掘需要,对原始数据库进行预处理,把空缺数据记录进行清除;系统可挖掘出八类可拓分类知识,为决策者提供更全面的参考依据;系统可根据不同的原始数据库,动态生成“基础信息元库”、“评价信息元库”以及“可拓分类知识库”,从而提高系统的灵活性及通用性。
此外,本文以某学院出台的新规定对教师科研工作影响程度进行定“量”和定“性”分析作为应用案例[11],介绍了可拓分类知识挖掘系统进行可拓分类知识挖掘的过程。
1 可拓分类知识挖掘相关概念
1.1 简单关联函数
设取值范围为有限区间(a,b],其中正域为X=(a1,b],a1≥a,且最优点为b,建立简单关联函数[12]:
(1)
1.2 关联差和关联积
(2)
为变换φ下信息元Ii关于评价特征d的关联差[12];称:
(3)
为变换φ下信息元Ii关于评价特征d的关联积[12]。
1.3 支持度和可信度
数据挖掘得到的规则知识是从一批数据中获取的,可通过支持度和可信度来衡量其重要程度和准确程度,通常用:l=(支持度,可信度)=(support,confidence)表示,即知识式表示为:A⟹(l)B。
设|U|表示论域中所有对象的个数,|E-|表示负域中对象的个数,|E0|表示零界中对象的个数,|E+|表示正域中对象的个数,|E+(T)|表示发生正质变的对象个数。
根据文献[12]中描述,正质变知识支持度和可信度的计算公式如下:
(4)
2 可拓分类知识挖掘系统的设计
如图1所示,可拓分类知识挖掘系统首先对数据库或数据仓库中已有的原始数据进行预处理,并利用基元和复合元从形式化的角度对信息进行表示,建立变换前后评价信息元库;其次选取关联函数建立分类模型,计算变换前后评价信息元的综合关联度、关联差、关联积;然后根据可拓分类标准,把变换后的评价信息元划分为正质变域、负质变域、拓界、正量变增效变换域、正量变减效变换域、负量变增效变换域、负量变减效变换域和零效变换域等八个域;最后对可拓分类信息元库进行支持度和可信度计算,从而生成可拓分类知识。
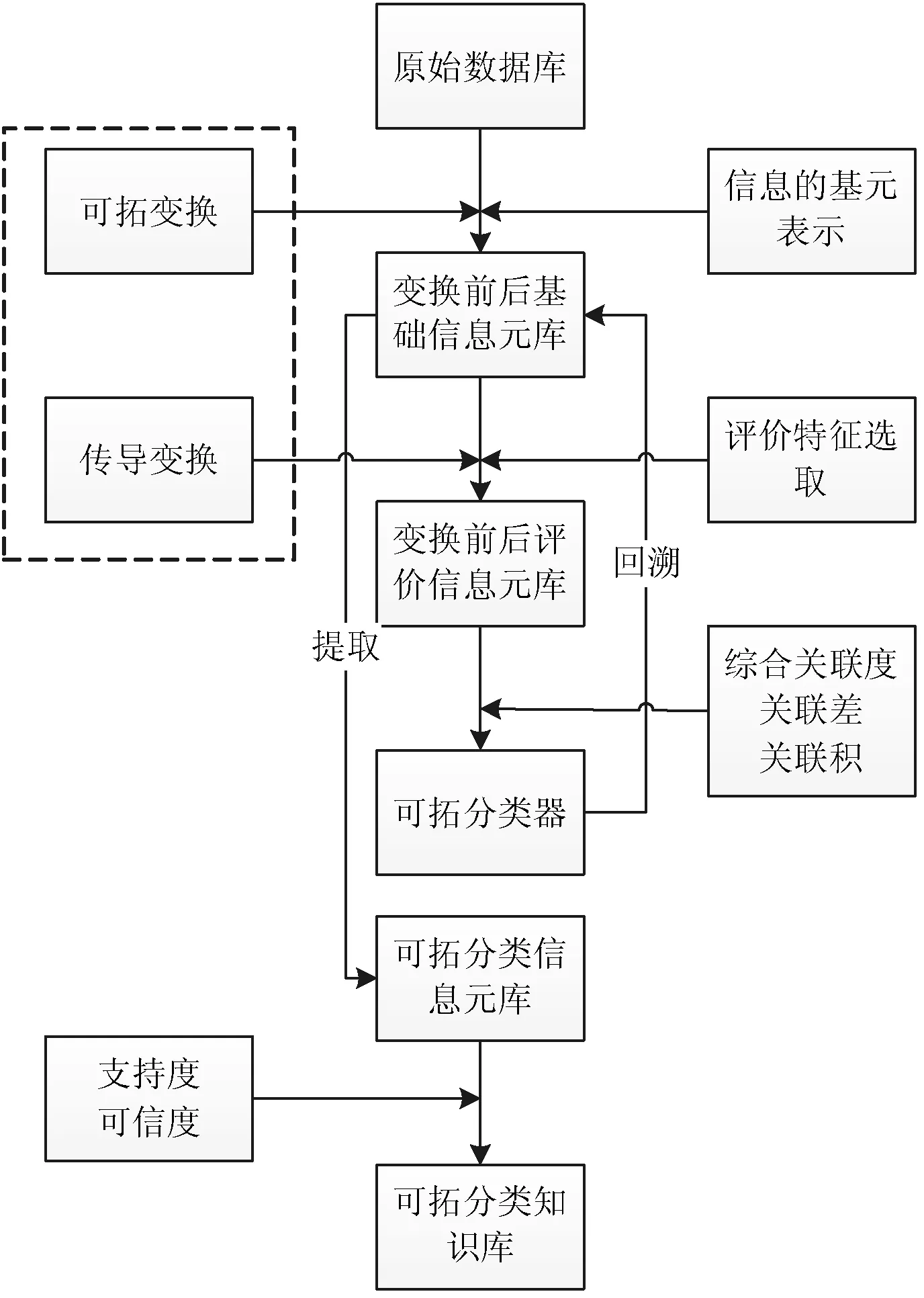
图1 可拓分类知识挖掘系统框图
根据上述可拓分类知识挖掘流程,可拓分类知识挖掘系统针对数据库、用户界面以及业务逻辑等方面进行设计,以确定系统的数据库结构、功能要求以及业务逻辑模块。
2.1 系统的数据库设计
本系统使用SQL Server 2008 R2作为数据库管理系统,其数据主要划分为三类:
(1) 变换前后基础信息元库:用于存储数据挖掘前的原始数据,其字段的个数、名称及类型由原始数据表决定,结构固定,如图2所示。
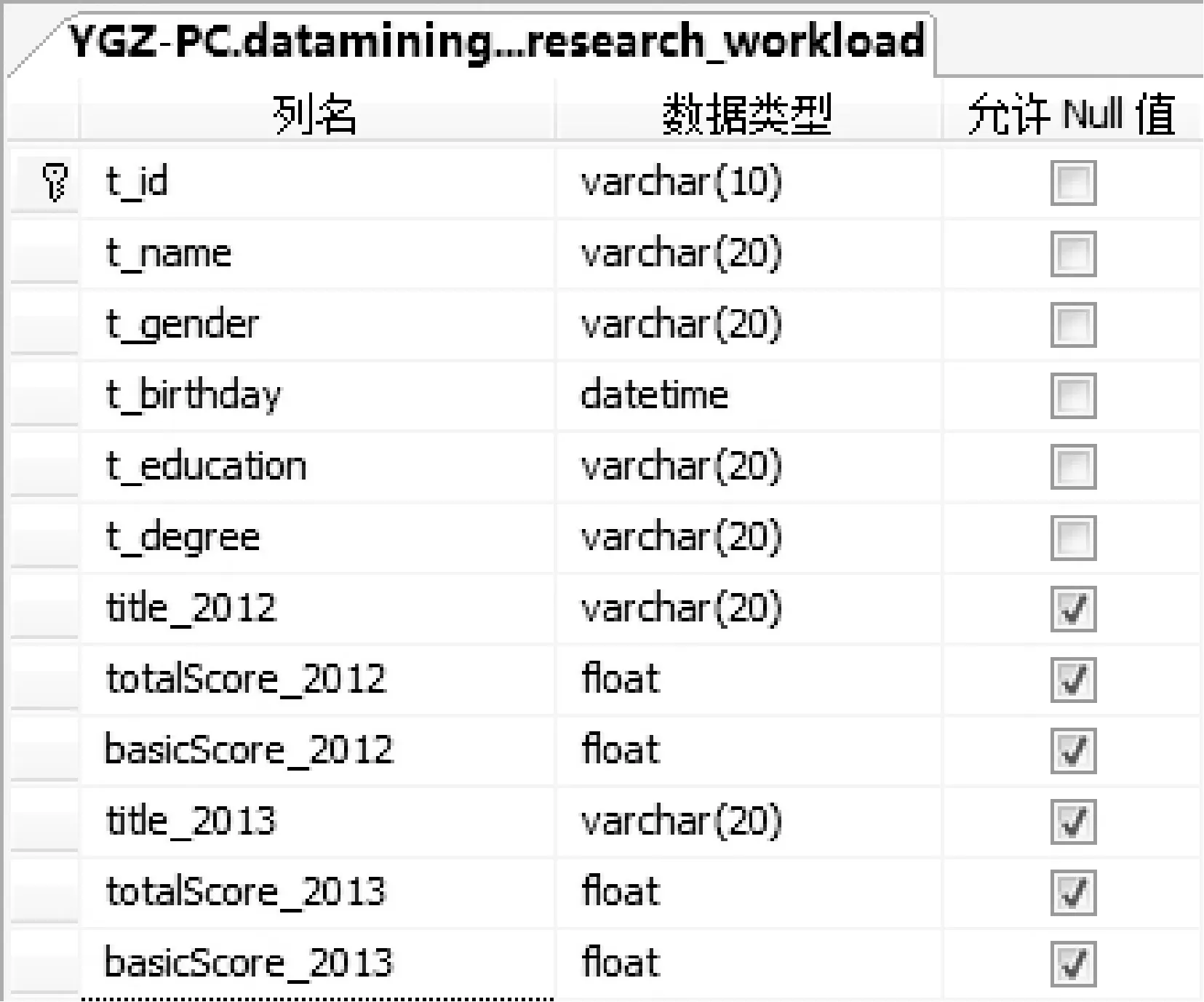
图2 变换前后基础信息元库设计图
(2) 变换前后评价信息元库:用于存储数据挖掘过程中产生的中间数据,字段的个数、名称及类型基于原始数据表,但受数据挖掘过程中的操作影响,结构不固定,如图 3所示。
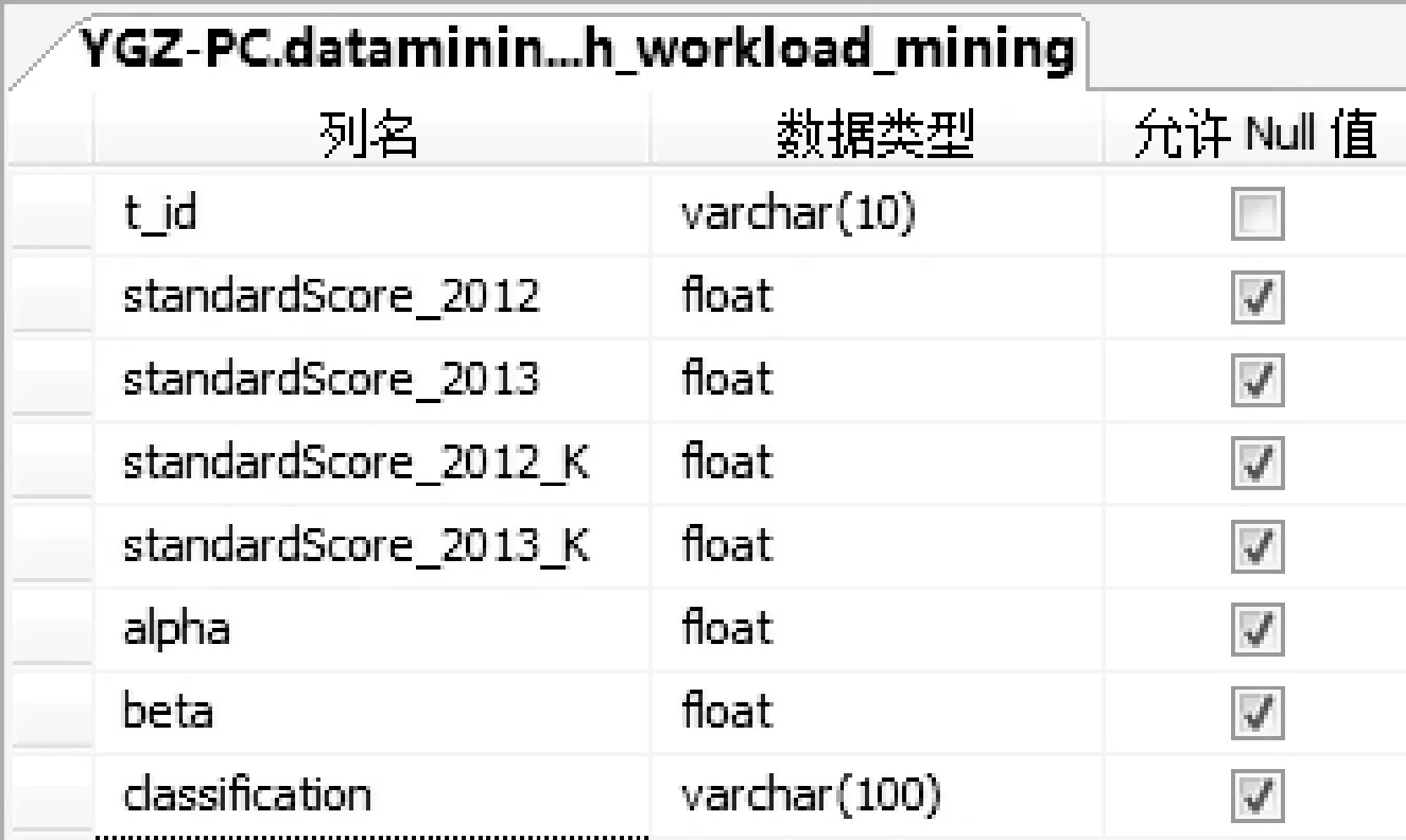
图3 变换前后评价信息元库设计图
(3) 可拓分类知识库:用于存储数据挖掘后生成的分类知识,主要包括分类、数量、支持度以及可信度等四个字段,结构固定,如图4所示。

图4 可拓分类知识库设计图
其中,“变换前后评价信息元库”和“可拓分类知识库”的数据基于“变换前后基础信息元库”,并通过可拓分类知识挖掘过程产生。
2.2 系统的用户界面设计
本系统主要使用jQuery技术进行用户界面设计,同时使用CSS[13]进行样式设计,具体设计如下:
(1) 用户界面布局:系统利用jQuery EasyUI中的Tabs选项卡、Accordion 折叠面板以及Layout布局等插件实现界面的整体布局。
(2) 界面动态效果:系统采用jQuery中的隐藏/显示、淡入淡出、滑动技术和jQuery EasyUI中的Draggable 可拖动、Droppable 可放置插件,以及jqChart插件实现用户界面丰富的动态效果。
(3) 数据交互方式:系统通过jQuery EasyUI中的Form 表单、Dialog 对话框插件实现数据的提交,利用Datagrid 数据网格、Pagination 分页插件实现数据的显示,使用jQuery AJAX技术[14]实现前台与服务器间的数据交互,以JSON文本作为数据传输格式,如图5所示。

图5 系统前后台数据格式变换过程
2.3 系统的业务逻辑设计
本系统通过MVC框架模式划分为模型层、视图层、控制层,将业务逻辑聚集到一个部件中,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑,从而提高系统的通用性及可维护性。下面以计算关联度的业务逻辑为例,介绍功能模块及层次的划分。
如图6所示,index.jsp页面为视图层模块,主要负责用户与系统的数据交互,具有输入和显示数据功能;CalculateKbySCFuncServlet类为控制层模块,主要负责接受视图层模块提交的数据及请求,并根据请求调用模型层的模块进行处理,然后把处理结果返回到视图层;SRWMiningImpl类为模型层模块,主要负责应用程序数据逻辑部分的处理,实现在数据库中存取数据。
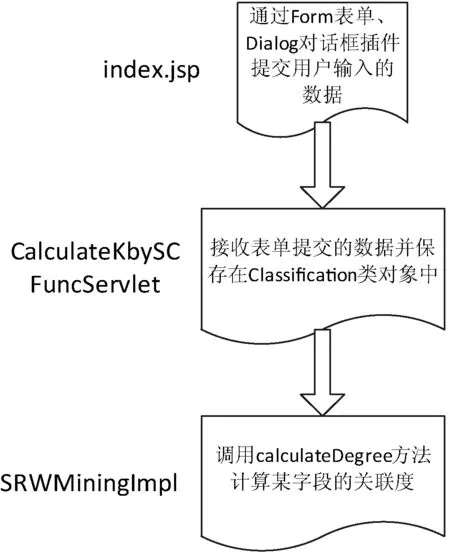
图6 功能模块层次结构图
3 可拓分类知识挖掘系统的案例实现
下面根据上述的可拓分类知识挖掘系统设计,以某学院计算机系教师科研考核为案例,对学院出台的“学院科研工作考核及奖励办法”这一策略,即可拓变换φ,对教师科研工作的影响程度进行定“量”和定“性”的分析,实现对应的可拓分类知识挖掘。
3.1 数据预处理
在进行数据分类知识挖掘前,需要对原始数据进行预处理,把存在的空缺数据记录进行清除,以避免对知识提取的影响。本系统将去除策略出台后才引进,即字段“title_2012”为null的教师记录;以及去除策略出台前后科研工作量都为0,即字段“totalScore_2012”和“totalScore_2013”同时为0的教师记录。
如图7所示,在界面右侧窗格中选择字段名称及字段值,点击“process”按钮,便可删除一个或多个字段为选定值的教师记录,从而形成“变换前后基础信息元库”。
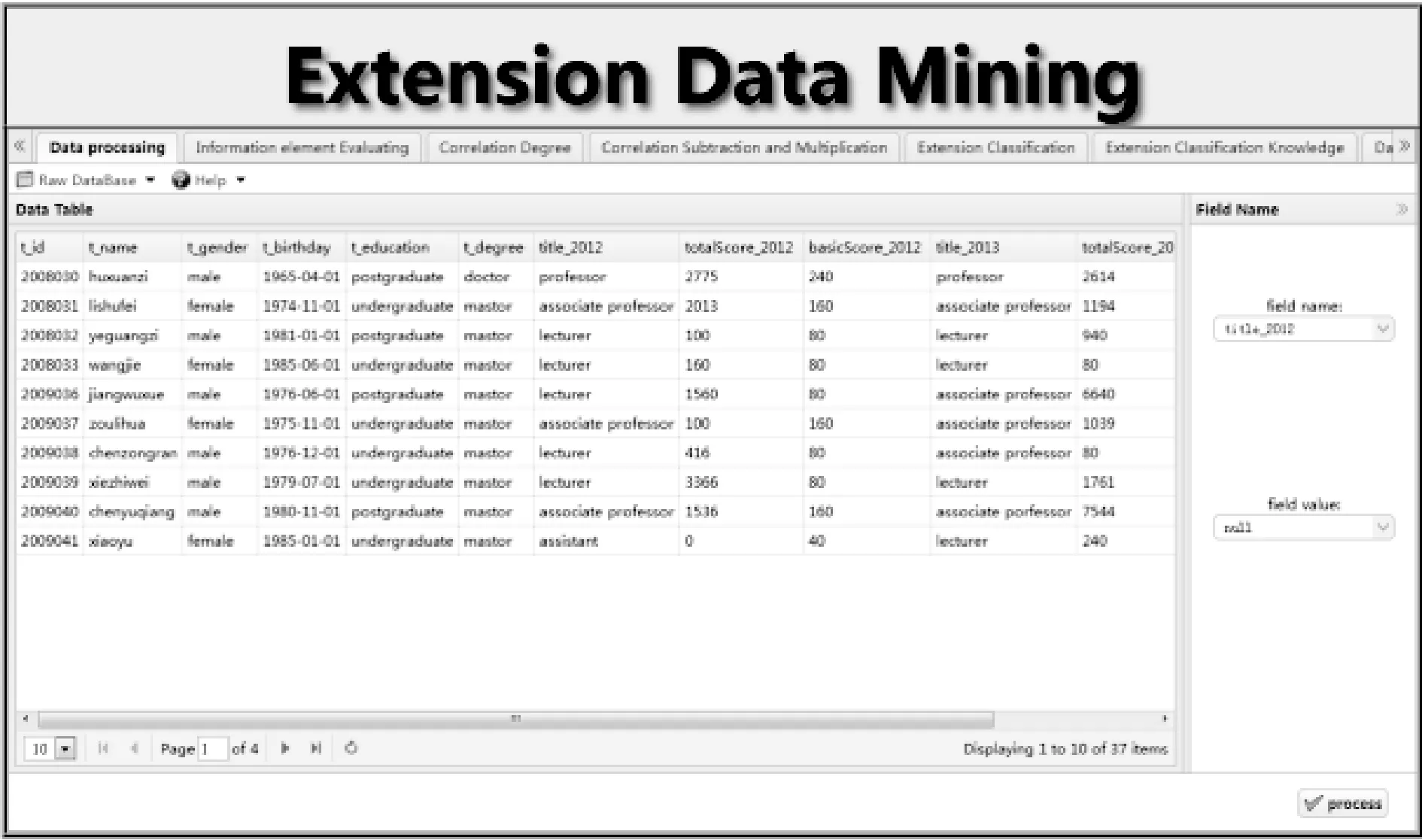
图7 数据预处理界面
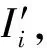
3.2 选取评价特征
在“变换前后基础信息元库”中,教师信息元有9个特征,为了分析教师的科研工作情况,选取达标值作为评价特征。其中,教师“科研年度达标值”等于“年度总得分”减去“年度标准分”,即:standardScore=totalScore-basicScore。
如图8所示,选取了教工号“t_id”、2012年度达标值“standardScore_2012”、2013年度达标值“standardScore_2013”作为“变换前后评价信息元库”中的三个字段。其中:
standardScore_2012=totalScore_2012-basicScore_2012
standardScore_2013=totalScore_2013-basicScore_2013
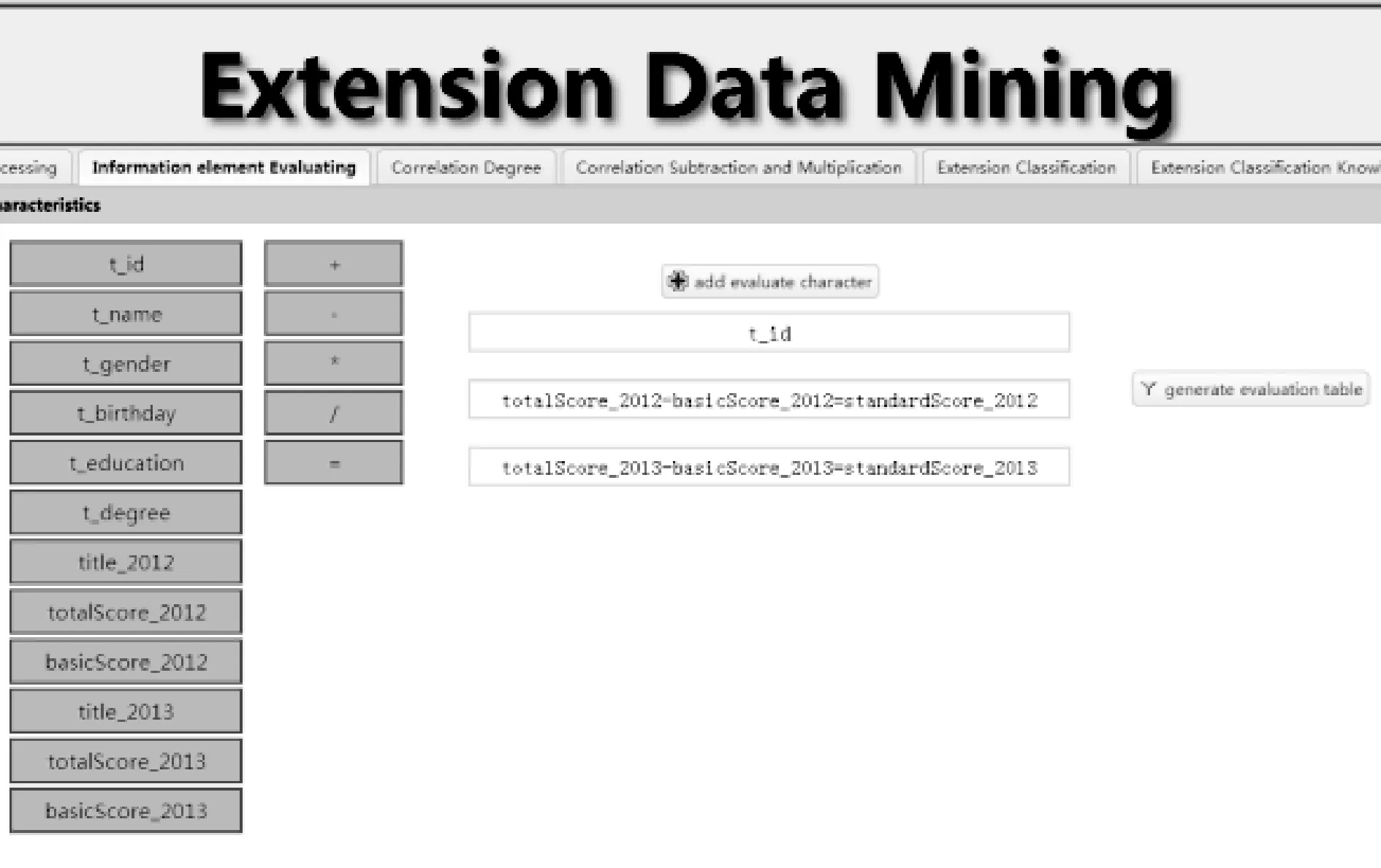
图8 评价特征选取界面
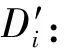
3.3 计算评价信息元关联度
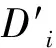

图9 简单关联函数参数设置界面
3.4 计算关联差和关联积
为了实现可拓分类,并对教师科研工作的受影响程度进行定“量”和定“性”的分析,需要对变换前后评价特征进行关联差和关联积计算。如图10所示,根据式(2),在变换T下Di关于评价特征standardScore的关联差:
=standardScore_2013_K- standardScore_2012_K
根据式(3),其关联积:
=standardScore_2013_K× standardScore_2012_K
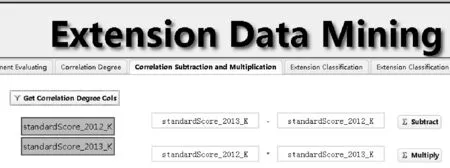
图10 关联差与关联积计算界面
3.5 可拓分类处理
基于评价特征变换前的关联度“K_before”、变换后的关联度“K_after”、关联差“Alpha”以及关联积“Beta”等4个字段的取值范围对评价信息元进行分类。如图11所示,把“变换前后评价信息元库”中字段“standardScore_2012_K”设置为“K_before”,把字段“standardScore_2013_K”设置为“K_after”,把字段“alpha”设置为“Alpha”,把“beta”设置为“Beta”。
图11 分类标准设置界面
根据上述4个字段的取值范围,参照表1所示的分类标准,对评价信息元进行可拓分类,从而得出“变换前后评价信息元库”的评价信息元分类情况,如图12所示。

表1 评价信息元分类标准表
基于实际情况,此处不考虑零界,把关联度大于等于0的情况归类为正域,小于0归类为负域,因此只有七种分类。
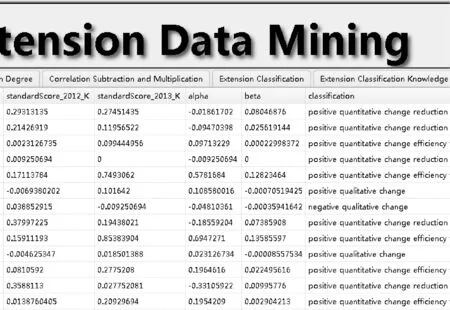
图12 变换前后评价信息元库
3.6 获取可拓分类知识
根据“变换前后评价信息元库”统计出正质变、负质变、正量变增效变换、正量变减效变换、负量变增效变换和零效变换等六种分类的数量,并通过相关计算公式,如利用式(4)计算正质变知识的支持度和可信度,求出各分类的支持度和可信度,从而得出可拓分类知识库,如图13所示。本例由于不考虑零界,因此不存在拓界情况。此外由于原始数据记录数有限,负量变减效变换情况并没有出现。
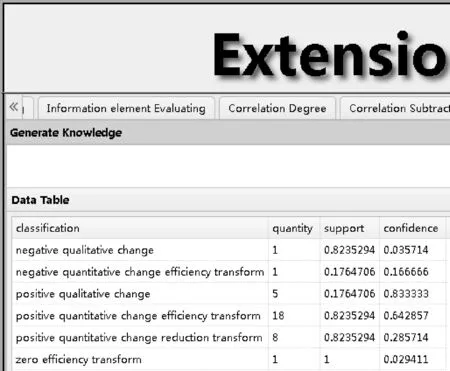
图13 可拓分类知识库
如图14所示,正质变情况的支持度和可信度为l1=(17.65%,83.33%)。同理可得:
正量变增效变换情况的支持度和可信度为l2=(82.35%,64.28%);
正量变减效变换情况的支持度和可信度为l3=(82.35%,28.57%);
负质变情况的支持度和可信度为l4=(82.35%,3.57%);
负量变增效变换情况的支持度和可信度为l5=(17.65%,16.67%);
零效变换情况的支持度和可信度为l6=(100%,2.94%)。
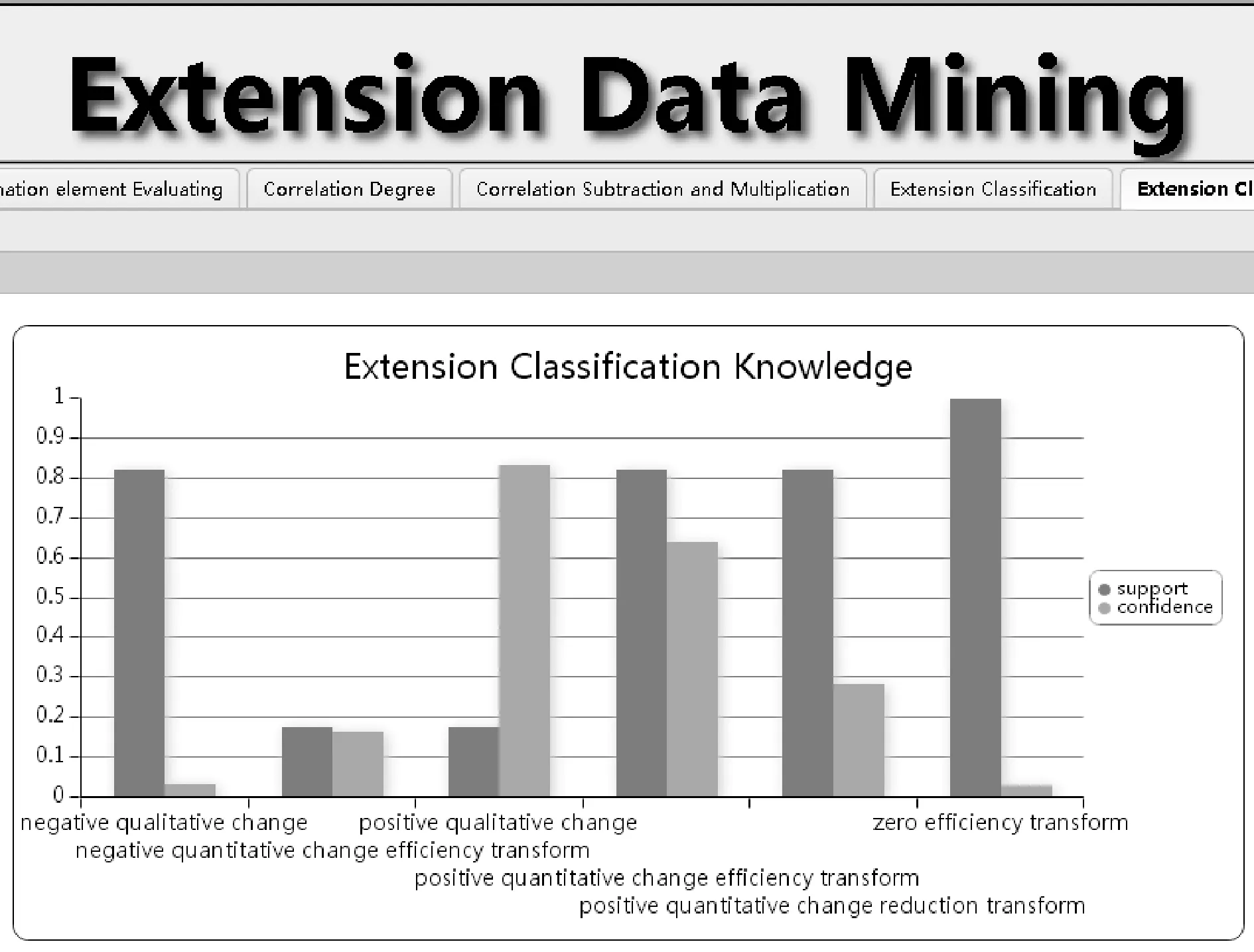
图14 可拓分类知识的支持度和可信度
综合上述六种可拓分类知识,负质变知识和零效变换知识的可信度分别为3.57%和2.94%,而正质变知识和正量变增效变换知识可信度分别为83.33%和64.28%。可见学院推出的奖励策略对教师的科研工作具有较好的促进作用,能较好调动教师科研工作的积极性。
4 结 语
本文设计及实现的可拓分类知识挖掘系统能协助人们挖掘动态分类知识。在系统设计上,引入jQuery技术在前台页面创造出丰富的交互元素和动态效果,利用MVC框架模式把系统划分为模型层、视图层、控制层,用一种业务逻辑、数据、界面显示分离的方法组织代码,提高系统的通用性和可维护性。在系统功能上,增强了数据预处理能力,提出了八类可拓分类知识的挖掘,以及信息元库和知识库的动态生成对系统的通用性有很大的提高。总的来说,在系统的性能及功能上比以往的可拓数据挖掘软件有了一定的优化及改进。
本文实现的案例说明,可拓分类知识挖掘系统能为科研管理者对策略执行前后的数据进行分析,挖掘出有助于衡量策略执行效果的知识。它将可拓分类方法应用到高校教师科研考核评价中,从量上分析该策略对教师的科研情况产生正面或负面影响的程度,在各种策略中找出更适合院校促进教师科研工作的策略,从而解决教师科研工作量不足的矛盾问题。
本系统的研究仍处于初级阶段,下一步将针对基于数据库的传导知识挖掘、可拓聚类知识挖掘等问题进行深入研究,从而完善其可拓数据挖掘的功能。
[1] 蔡文,杨春燕,陈文伟,等.可拓集与可拓数据挖掘[M].北京:科学出版社,2008.
[2] 李立希,李铧汶,杨春燕.可拓学在数据挖掘中的应用初探[J].中国工程科学,2004,6(7):53-59.
[3] 杨春燕,蔡文.基于可拓集的可拓分类知识获取研究[J].数学的实践与认识,2008,38(16):184-191.
[4] 杨春燕,蔡文.可拓数据挖掘研究进展[J].数学的实践与认识,2009,39(4):134-141.
[5] 李小妹.CPI指数变换对产品销售影响的可拓数据挖掘[J].数学的实践与认识,2009,39 (4):178-183.
[6] 李小妹,杨春燕,李卫华.成品油税费改革对股票市场影响的传导知识挖掘[J].计算机应用研究,2010,27(8):2865-2868.
[7] 朱伶俐,李卫华,李小妹.客户价值可拓知识挖掘软件研究[J].广东工业大学学报,2012,29(4):7-13.
[8] 蓝健.轻松玩转jQuery[M].北京:人民邮电出版社,2012.
[9] 赵俊峰,姜宁,焦学理,等.Java Web应用开发案例教程——基于MVC模式的JSP+Servlet+JDBC和AJAX[M].北京:清华大学出版社,2012.
[10] 叶广仔,李卫华,李淑飞.可拓策略生成系统的构件化设计与实现[J] .智能系统学报,2010,5(4):366-371.
[11] 叶广仔,李卫华.可拓数据挖掘在教师科研考核评价中的应用[J].数学的实践与认识,2015,45(12):53-59.
[12] 杨春燕,李小妹,陈文伟,等.可拓数据挖掘方法及其计算机实现[M].广州:广东高等教育出版社,2010.
[13] 刘增杰,臧顺娟,何楚斌.精通HTML5+CSS3+JavaScript网页设计[M].北京:清华大学出版社,2012.
[14] Bear Bibeault,Yehuda Katz.jQuery实战[M].三生石上,译.2版.北京:人民邮电出版社,2012.
[15] 杨春燕,蔡文.可拓工程[M].北京:科学出版社,2007.
[16] 杨春燕,蔡文.可拓学[M].北京:科学出版社,2014.
DESIGN AND IMPLEMENTATION OF EXTENSION CLASSIFICATION KNOWLEDGE MINING SYSTEM
Ye Guangzai1Li Weihua2Liu Xiaowei3
1(DepartmentofComputerEngineering,DongguanPolytechnic,Dongguan523808,Guangdong,China)2(SchoolofComputerScienceandTechnology,GuangdongUniversityofTechnology,Guangzhou510006,Guangdong,China)3(DepartmentofManagementScience,DongguanPolytechnic,Dongguan523808,Guangdong,China)
According to the demand of policy makers’ need for dynamic classification knowledge as reference to deal with contradictory issues, an extension classification knowledge mining system is developed. The system is enhanced by B/S structure, using the jQuery technology to implement Web front-end development and the framework of MVC model to implement background development. Besides, this system enhances the ability of data preprocessing, and it is able to mine eight kinds of extension classification knowledge and dynamic generate information database and knowledge database. This system is applied into faculty scientific research evaluation, which provides references for scientific research managers to find appropriate strategy to promote teachers’ scientific research.
Extension classification Knowledge mining Scientific research evaluation jQuery technology
2015-08-12。广东省自然科学基金项目(1015009001000044);广东省省级科技计划项目(2014A010103002)。叶广仔,讲师,主研领域:智能系统软件。李卫华,教授。刘晓蔚,实验师。
TP30
A
10.3969/j.issn.1000-386x.2017.01.059
猜你喜欢
江苏科技信息(2022年16期)2022-07-17 09:07:36
大众投资指南(2021年35期)2021-02-16 01:06:26
当代陕西(2019年15期)2019-09-02 01:52:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
电力与能源(2017年6期)2017-05-14 06:19:37
读者(2017年5期)2017-02-15 18:04:18
信息通信技术(2015年6期)2015-12-26 01:16:46
图书馆建设(2015年10期)2015-02-13 03:48:27
新世纪图书馆(2014年7期)2014-09-19 12:20:40
电子设计工程(2014年18期)2014-02-27 12:00:13
