
基于关联特征的贝叶斯Android恶意程序检测技术
2017-03-01 04:26张仁斌
计算机应用与软件 2017年1期
王 聪 张仁斌 李 钢
(合肥工业大学计算机与信息学院 安徽 合肥 230009)
基于关联特征的贝叶斯Android恶意程序检测技术
王 聪 张仁斌 李 钢
(合肥工业大学计算机与信息学院 安徽 合肥 230009)
Android应用恶意性和它所申请的权限关系密切,针对目前恶意程序检测技术检出率不高,存在误报,缺乏对未知恶意程序检测等不足,为实现对Android平台恶意程序进行有效检测,提出了一种基于关联权限特征的静态检测方法。首先对获取的应用权限特征进行预处理,通过频繁模式挖掘算法构造关联特征集,然后采用冗余关联特征剔除算法对冗余关联特征进行精简,最后通过计算互信息来进行特征筛选,获得最具分类能力的独立特征空间,利用贝叶斯分类算法进行恶意程序的检测。实验结果证明,在贝叶斯分类之前对特征进行处理具有较强的有效性和可靠性,能够使Android恶意程序检出率稳定在92.1%,误报率为8.3%,检测准确率为93.7%。
贝叶斯分类 安卓 恶意检测 关联特征 特征选择
0 引 言
面对Android平台上层出不穷的恶意应用,为了有效改善智能终端缺少有效安全检测平台的现状,国内外研究人员进行了一系列的工作。现阶段Android平台恶意软件的主流分析技术包括静态分析[1]和动态分析[2]两个方面。Enck等[3]提出了Kirin 工具,该工具会对可能进行恶意行为的权限组合作出提示。然而,Enck的工作没有对权限组合与程序的恶意性之间的关系进行实验验证,Kirin工具所预设权限组合的可靠性存在问题。Zhou等[4]提出了一种Android恶意代码检测方法DroidRanger,对恶意家族相关的敏感权限进行统计,从而识别恶意应用。但是由于缺少统一的权限过滤规则和大量样本的实验验证,该方法也存在其局限性。检测工具Androguard[5]采用基于特征码方法,因为特征码涉及到特征库的更新问题,不能及时地识别未知恶意程序。张玉清等[6]对Android系统安全作了综述,从系统和应用两个层次进行阐述,特别对基于权限机制的改进在安全加固方面的应用作了说明。Google在Android4.2系统之后加入了应用验证服务(Application Verification Service),对恶意软件进行扫描来防御潜在威胁,Jiang[7]对其进行了全面测试,检测率只有15.32%。蔡泽廷[8]提出了一种基于机器学习的Android恶意软件检测模型,训练静态指纹匹配库和动态行为签名库,能在一定程度上检测未知恶意程序,但是训练数据量太少,精度不高。张思琪[9]提出了一种基于改进贝叶斯分类的Android恶意软件检测方法,利用移动设备应用程序获取的多种行为特征值,应用机器学习技术检测Android恶意软件。该方法只选取短信、GPS等六种行为特征集合,恶意行为的涉及范围小。诸姣等[10]通过从应用市场获取的应用数据,采用信息检索和语义分析等技术对应用程序功能与权限的语义关系进行了描述,并建立了关系模型。秦中元等[11]提出一种利用危险权限对比,根据提取消息摘要的md5进行匹配的检测方法,该方法没有对过度申请的特征进行去干扰,并且没有特征处理,检测不够精确。
除此,还有一些动态的检测方法。Shabtai[12]实现了一个基于主机的Android恶意程序检测系统,通过动态监控设备运行的特征及事件,比如CPU使用、运行的进程数量、电量等,运用机器学习算法进行分类,但是由于缺乏真实的恶意软件,检测能力不易评估。Enck等[13]实现了一种自动监控的方法,通过在Linux底层中插入代码,利用发送和存储的数据信息情况自动监控应用程序,但是该方法对系统的资源消耗严重,会导致系统运行不稳定甚至崩溃。徐冰泉等[14]提出了GrantDIoid,一种支持Android权限即时授予的方法。 通过拦截应用对所有权限的使用,采用一套恶意程序权限使用特征对正常使用进行过滤,当存在威胁权限请求时,提醒用户对该权限进行实时授权。
权限机制是Android安全机制的核心,应用程序的权限与系统提供的API之间存在对应关系。Felt等[15]提出了一个STOWAWAY工具,并使用其对940个Android应用进行分析统计,发现30%以上的应用存在权限过度申请但未使用的情况。Au等[16]提出了PScout工具,该工具完成了Android系统API与权限的映射关系集合,可以利用该映射集判断应用是否存在权限过度申请。而针对多应用多权限间接提权攻击的检测技术,也有些研究人员进行了一些探索。文献[17]将Android系统应用层权限扩展导致的攻击分为混淆代理人攻击(Confused Deputy Attack)和共谋攻击(Collusion Attack)。文献[18]提出了一种用户实时授权的安全框架,使授权粒度得到了细化,但是无法对权限提升导致的共谋攻击进行检测。
为了解决当前基于权限的检测方案中权限存在过度申请,以及特征独立性处理的不完善等问题,本文使用基于关联权限特征的静态分析方法。最后,设计了多组实验进行对比,相比之前基于权限的静态方法[1]以及基于动态的检测技术[2],本方法在检测精度和处理方法上都有明显优势。
1 基于关联权限特征的贝叶斯恶意检测方案
1.1 整体框架
Android系统采用了权限分离的机制,通过赋予不同的权限来对应用程序的行为进行控制。基于关联权限特征的贝叶斯检测方案,充分利用了贝叶斯分类对特征独立性的要求。传统的机器学习分类方法忽略了Android恶意程序的恶意性与权限组合之间的关系,认为各个特征的分类能力是一样的,由此进行机器学习产生的训练集会产生误判。
这种进行关联特征挖掘从而进行关联去冗余的特征处理方法,通过挖掘将关联的特征组合进行绑定,真正实现了特征之间的独立性,同时满足了贝叶斯分类的要求。该方案包含三个部分,特征提取、特征选择、机器学习和分类,整个检测框架图1所示。
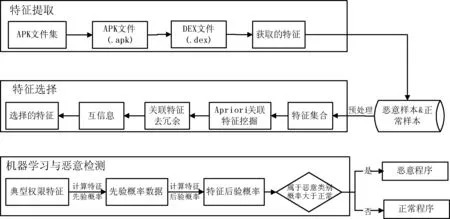
图1 基于关联特征及贝叶斯恶意程序检测框架
1.2 特征获取及预处理
为了确保安全性和可靠性,Android应用程序在进行权限申请时应该满足最小特权原则,但大部分应用都存在权限过度申请的现象,给用户带来安全隐患,也给本文的特征选择造成了干扰。
针对该问题,本文采取了一种通过对Android应用安装文件APK进行分析和修改,建立API权限映射表,使其满足最小特权原则的方法。通过设置一个权限匹配阈值,判断该应用程序是否存在权限过度声明。也就是首先通过解压APK文件提取出程序所调用的所有系统API,并在预先准备好的API权限映射表中查找该API对用的系统权限,得到应用程序真正使用到的最少权限表。然后统计该权限列表的权限数量,计算其占该应用程序所申请权限得比例。如果比例值小于等于阈值,则保留获取的全部权限信息;如果比例值大于阈值,则只保留匹配成功的权限信息,从而达到了对过度申请的权限剔除的目的。文件预处理过程如图2所示,其中设定阈值为3/4。
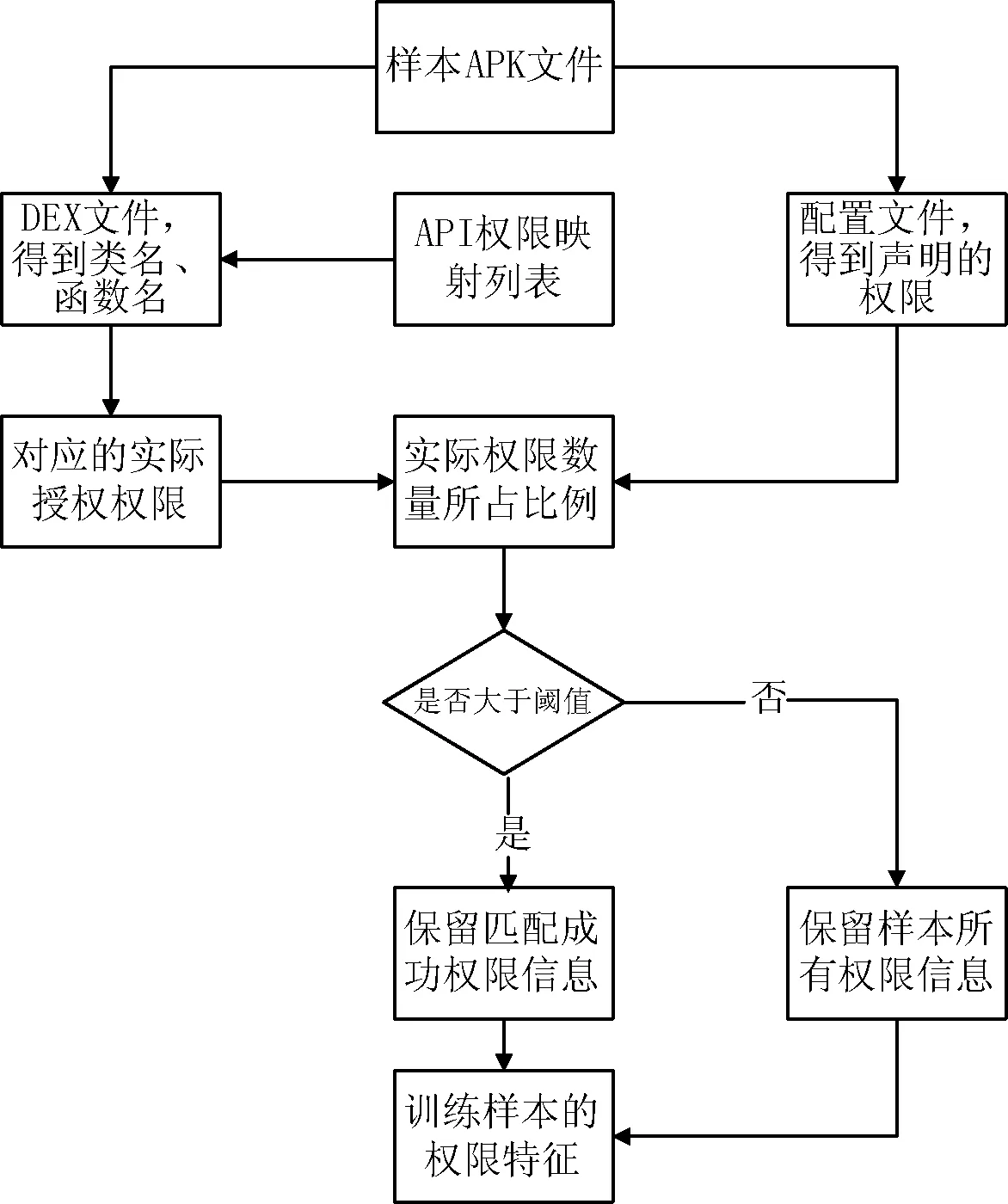
图2 文件预处理
1.3 关联特征挖掘及去冗余
1.3.1 Apriori算法挖掘关联特征
采用挖掘关联规则的Apriori算法来挖掘同类型应用申请的权限之间的关联性,构建权限关系特征库。为了解决对高频率事件的有效性挖掘,减少对数据库的扫描次数和候选数据集的数量,在经典的Apriori算法基础上提出一个改进的Apriori算法。基本思路是,用迭代的方法产生频繁集,产生可以满足最小置信度规则的规则集和输出。 在这里用到的Apriori算法是建立在Android权限这一相关概念的基础之上的。Apriori算法就是为了挖掘权限频繁项集,挖掘Android应用申请的权限之间的关联性,以构建权限关联特征库。
本文对随机选择的1000个恶意样本所申请的权限进行提取,形成权限特征数据库,并删除其他无关数据。然后,删除掉大部分恶意程序很少使用的权限特征。最后利用Apriori算法来对这个权限特征数据库进行处理,以产生极大频繁权限特征项集。
Apriori算法有两个主要性质:连接和剪枝,也是产生频繁项集的两个步骤。该算法最后输出为极大频繁权限项集数据库,整个流程如下:
(1)Lappend=ext_post_append(Dpi),提取所有恶意样本都声明过的权限项集;
(2)Dmi=del_post(Dpi),删除所有恶意样本都包含的权限项集;
(3)Di=del_pre(Dmi),删除所有恶意样本很少使用的权限项集;
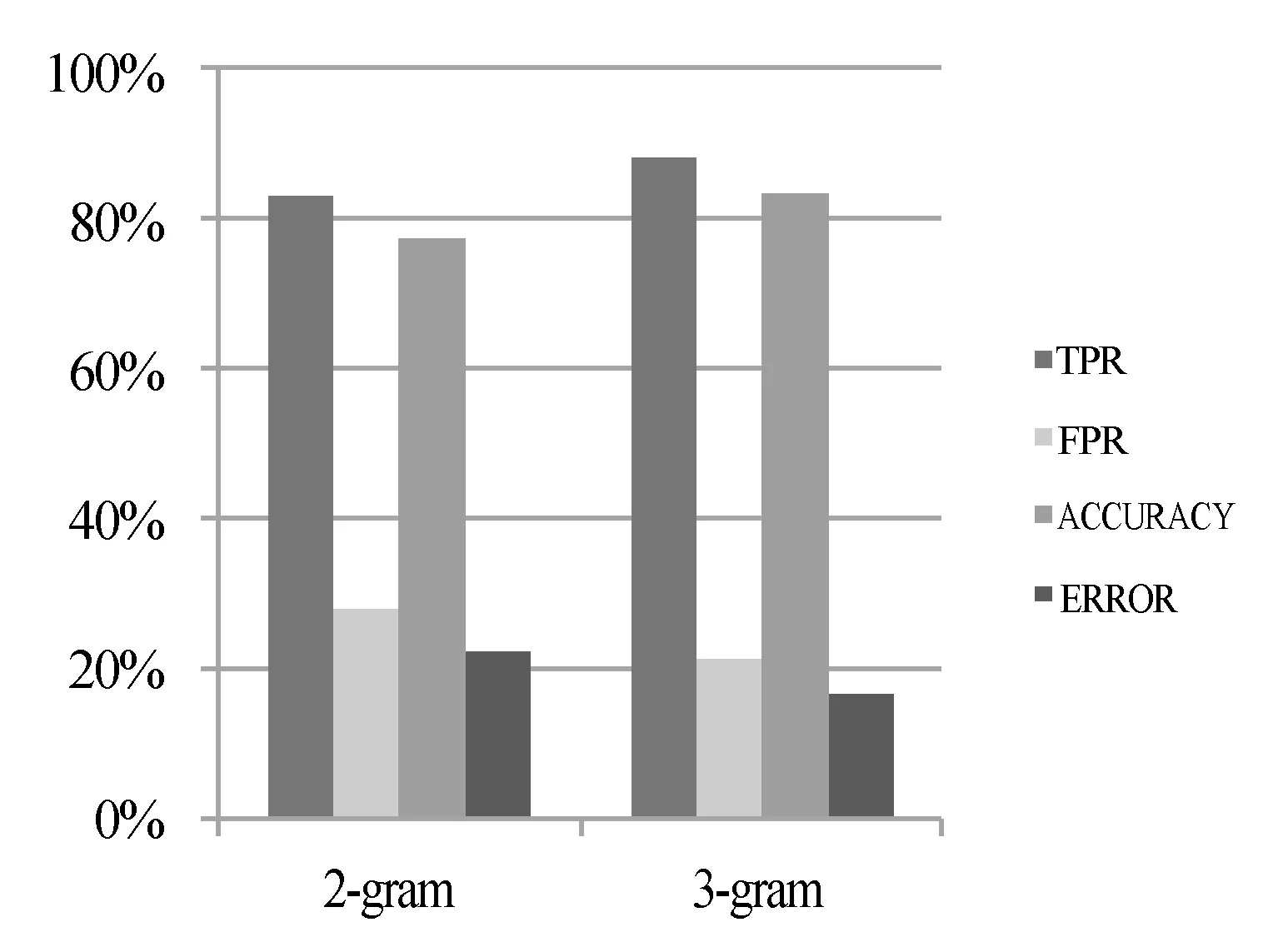
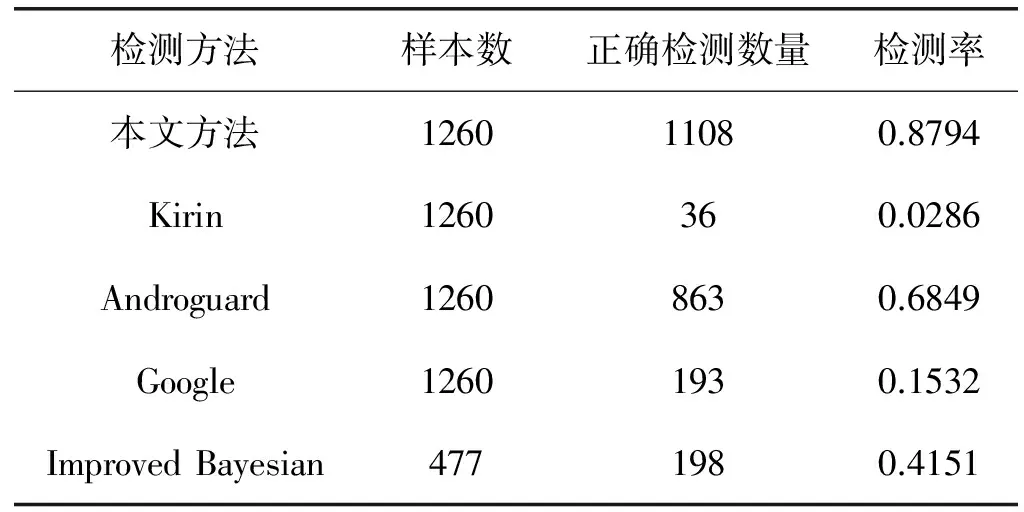
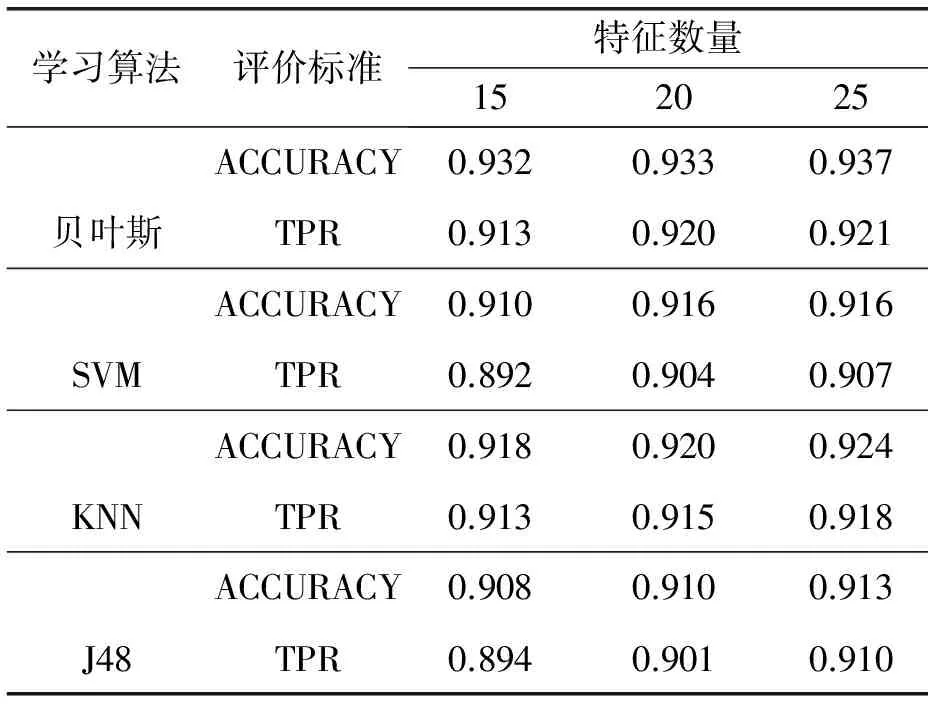
(4)Lk=max_permission(Di,min_support),Lk=append(Lappend),将所有恶意样本的权限项集合并到极大项集;
(5) 连接:设l1和l2是Lk-1中的项集,通过Lk-1与自身连接产生k-项集的集合,候选集的集合为Ck。那么执行Lk-1连接,且Lk-1是可连接的,若(l1[1]=l2[1])∧(l1[2]=l2[2])∧…∧(l1[k-2]=l2[k-2])∧(l1[k-1] (6) 剪枝:Ck是Lk的超集,也即Ck的成员可以是不频繁集,但频繁k-项集一定是Ck的子集。Ck可能较大,根据Apriori的性质:若(k-1)-项集不是频繁的,那么它就一定不是k-项集的子集。所以,如果一个候选k-项集的(k-1)-子集不在Lk-1中,那么该候选项集也不是频繁的,可从Ck中删除,通过此种方式,可以迅速建立频繁项集。 1.3.2 去冗余 观察一些恶意样本申请的权限特征,发现存在较强的关联性,在恶意样本中几乎同时出现,如果认为它们对分类能力的贡献是同等的,把它们作为独立的权限特征来处理,显然会对分类形成误判。所以为了提高权限特征在分类中的有效性,需要去除在前面获得的权限特征集合中的冗余特征。整个方法步骤如图3所示。 图3 去冗余算法 1.4 贝叶斯分类模型处理过程 本文中的贝叶斯分类器由学习和检测两个阶段组成。学习阶段用到的训练集包括已知的恶意程序样本和非恶意的Android程序,所有这些统称为样本集。所有的权限特征都是来自于这些样本,经过前面的特征提取,关联特征挖掘和特征去冗余,特征集的空间大大减小。训练函数也会计算每个应用分别属于正常和恶意类别的先验概率。贝叶斯分类的基本思路是利用训练样本得到先验概率,然后进行学习训练通过后验概率,最后把样本归类于恶意或正常中概率最大的那个类别。 1.4.1 特征选择 从应用软件安装文件APK文件获取权限特征,设为ti,每一个权限特征都用一个随机变量Ti来表示: (1) 为了筛选最有分类能力的权限特征,必须确保选择出关联性最强的那些权限特征,通过采用计算特征之间互信息MI(MutualInformation)的方法来对特征进行排序。在这里,假设C为一个随机变量,它代表的是Android程序的类别,恶意或正常。 C∈{malicious,benign} (2) (3) 在计算完每个特征的互信息之后,特征集中每个特征就会按照互信息值的大小从大到小进行排序,最大限度地表示出了特征变量和类别之间的测度。那些互信息值较大的特征将被采用,以改善分类器的分类性能。 1.4.2 贝叶斯分类 P(C=c|T=t) (4) 式中P(Ti=ti|C=c)和P(C=cj)都是在训练集选定后计算的先验概率,n是分类中用到的特征数目,c0和c1分别代表分类类别正常程序和恶意程序。 (5) 1.4.3 评价标准 为了衡量一个分类器的准确性,在本文的实验中,用TPR(True Positive Rate)代表命中率,表示被分类出来恶意样本与总的恶意样本数量之比。FPR(False Positive Rate)代表误报率,表示正常样本被误检为恶意样本与总正常样本数量之比。ACCURACY代表准确率,ERROR代表错误率。于是有以下定义: 定义1 命中率,即: (6) 定义2 误报率,即: (7) 定义3 正确率,即: (8) 定义4 错误率,即: (9) 在上面公式中,TP表示恶意样本被正确分类的数量,TN表示正常样本被正确分类的数量,FN表示恶意样本被错误分类为正常样本的数量,FP表示正常样本被错误分类为恶意样本的数量。 从VirusShare[19]和Google Play、Android正规应用市场等获得了2 000个样本,1 000个恶意样本和1 000个正常样本。然后提取样本中的权限特征,依次对其进行预处理,关联特征挖掘,去冗余和利用互信息进行特征筛选。那1 000个正常样本由十分广泛的Android应用组成,包括娱乐、工具、体育、健康、新闻、音乐等类别。将每个样本申请的权限与Android系统中全部的134种权限[20]进行对比,其实有多种权限,在恶意样本或正常样本都没有用到。 针对上述问题的研究,本文一共设计了三组实验,分别针对预处理的必要性、关联特征挖掘及去冗余的必要性、以及基于互信息的特征筛选进行验证。正常样本和恶意样本各选择1 000个,分别选取其中的800样本作为训练集,一共是1 600个,其余400个作为测试样本。 在此实验中,正常样本和恶意样本各选择1 000个,采用分层10折交叉方法进行验证,也就是选取1 600个样本作为训练集,选取剩下400个样本作为测试集。迭代10次,每次随机选取测试集计算分类器的TPR、FPR、ACCURACY、ERROR,取平均值。同时利用Androguard[5]工具对相同的样本进行检测,对比结果如图4所示。 图4 基于原始权限特征的分类结果对比 本实验是针对提取出的特征利用贝叶斯直接进行训练分类的结果,虽然效果离预期的还有一定距离,但是在特征处理之前对权限特征做了预处理,使得提取的特征具有较强的可靠性和有效性,所以依然比Androguard等检测工具的准确率和命中率高,且误报率下降。特别是比目前直接根据权限进行分类的方法的检测精度要高,证明对特征的预处理是十分必要且有效的。 (2) 前面提到每一个恶意样本恶意行为的出现,是多个权限特征组合作用的结果,因此有些权限的出现必然伴随着另外一个或几个权限的出现,就是关联特征,这种特征之间的关联性与贝叶斯分类要求的特征独立性假设相矛盾。 在分类研究领域,对特征空间扩展的研究[21]中,提到可以用n-gram方法,就是在一系列字符串、特征中,由n个连续项目所组成的序列来扩展特征空间。例如对于字符串“ANDBKLSFGTUIESRXI”,做n=3的n-gram,产生结果为“AND”、“NDB”、“DBK”、…、“SRX”、“RXI”的n-gram。使用n-gram存在的一个问题就是特征项数量问题,当采用n元n-gram模型,意味着Mn个特征项,这里M代表特征数量。随着n的增大,采用该特征模型的计算量和复杂度会大大增加。在此通过对关联特征进行统计,然后对前n种不同长度的特征空间进行统计,发现n=3的特征空间组数比较多,因此按照n=3对经过预处理的权限特征向量进行分割,就强制性地形成了一些“伪”关联特征,并且每一个串都自动形成了一个去冗余的独立特征了。 分别针对n=2和n=3进行了验证实验,结果如图5所示。本实验基于n-gram模型,进行了特征空间的一个扩展,扩展的结果和统计能在一定程度上能反映关联特征的组合规律和数量。贝叶斯分类虽然要求特征之间相互独立,但是大量研究表明贝叶斯分类器的分类性能依然可以通过一些方法提高。其中一种是构建新的样本特征集,期待在新的特征空间中特征彼此之间存在较好的独立性。从图5可以看出,本实验刚好利用这一点,验证了n-gram模型对特征扩展的有效性。实验也对不同n值进行了对比,表明大量关联特征是以3个权限组合的形式存在的,为后面的特征筛选提供了依据。 图5 基于n-gram模型的检测结果 (3) 以上实验虽然针对特征进行了一定的处理,比如根据出现的频繁程度排序、特征扩展等,但是依然没有真正地对冗余关联特征进行剔除。特别没有对互信息这一与类别有重大关系的影响因素进行考虑。因此在上面实验基础上,计算独立特征空间的各特征互信息,并根据互信息排序,挑选若干与类别关系大的特征进行样本训练,然后进行样本测试。 本实验分别选取了互信息排名在前5、前10、前15、前20、前25、后5的的特征空间进行验证,结果如图6所示。从图中曲线可以看出,选取互信息最高和最低的特征实验结果差别较大,而在利用的特征在15个以上时,结果则非常接近,这也表示15至20个互信息排名靠前的特征足以满足精确检测的需要。利用互信息排名最高的5个特征的正确率达到85%以上,最后稳定在94%左右。而排名最低的5个特征的正确率则在68%左右。表明互信息对分类器的影响要大于特征数量的影响。 图6 基于关联特征贝叶斯分类结果 本文在引言部分,提到了近年恶意检测相关的一些工作,主要有Enck等提出的基于权限组合的Kirin工具[3];基于特征码的开源检测工具Androguard[5];Google的恶意程序防御服务Application Verification Service,Jiang对其进行了详细测试[7];还有张思琪的改进贝叶斯方法[9],都具备一定的恶意程序检测能力。Zhou等发起了Android Malware Genome Project,包含流行的1 260个Android恶意样本,Kirin、Androguard、Application Verification Service均对这个恶意样本库[22]进行过实验验证,利用本文方法再次对此样本进行测试,对比结果如表1所示。 表1 本文方法与Kirin、Androguard等检测结果对比 Kirin工具基于9条权限规则对1260个样本进行检测,检测出36个恶意程序,误报率7.7%。利用最新Androguard版本对相同的样本测试,检测出863个恶意程序,由于特征库不能及时更新,新版本的分析功能也不能提高检测率。Google的Application Verification Service只是采用程序SHA1(Secure Hash Algorithm)值进行识别,检测率不高。改进贝叶斯没有针对原始特征进行预处理,并且没有细粒度的特征筛选,也没有获得较高的检测率。很明显,利用本文方法对应用程序的权限特征进行处理,获取最适合贝叶斯训练的特征空间,最后挑选分类能力最强的特征进行检测,检测率高,误报率低,说明本文方法在特征处理上的优越性,以及在检测精度上的有效性。 机器学习中,还有支持向量机(SVM),K最近邻(KNN),J48等优秀的分类算法,他们对分类的特征有着不同的要求,在此特地选取互信息排名在前15、前20、前25的特征进行贝叶斯分类,并且选取出现频率排在前15、前20、前25的特征分别用SVM、KNN、J48三种分类算法对相同的特征集进行验证,结果对比如表2所示。从对照表格可以看出,在分类之前对特征进行筛选处理,再利用贝叶斯分类的正确率和命中率都接近94%。而其他三种算法,都利用出现频率较高的特征直接进行训练,检测正确率和命中率都要低于贝叶斯分类器,其中KNN算法的结果较SVM和J48要好,这与样本数量较大有关。 表2 不同机器学习算法恶意检测结果的精度对比 通过两组实验对比,分别是本文方法与近几年流行的检测方法或工具的结果对比,以及基于贝叶斯分类与其他机器学习方法的对比。结果表明,实际测试结果与理论分析结果一致,表明本文方法的有效性和可靠性,尤其适用于未知恶意程序的检测。 本文提出了一种基于关联权限特征的贝叶斯恶意程序检测方案,解决了目前恶意程序检测技术检出率不高、误报、不能对未知恶意程序进行检测等问题。方案对Android应用恶意行为和权限之间的关系进行分析,建立权限特征和恶意行为模式的关联。特别是实现了对特征之间隐含关联性的挖掘,并且选取了对分类贡献大的独立性特征,最后通过贝叶斯分类模型对这些特征进行处理,取得了良好的分类效果。不仅检测正确率和命中率都高于其他分类器,特征处理也十分有效,而且能对未知恶意程序进行有效的检测。 对Android平台恶意程序的识别中取得了一定的效果,但是还存在可以进一步完善之处:1)收集更大数量、更具代表性的恶意样本,使得机器学习获得的特征可以及时的更新,在最短的时间内发现恶意软件,减少安全隐患;2)本文只考虑了单应用的恶意检测,还需要对多应用间通过间接权限提升导致的共谋攻击进行研究,从静态和动态两方面来检测此类恶意行为;3)本文中用到的算法,比如频繁模式挖掘算法,分类算法等的效率如何提升,也需要进一步研究,以完善此类基于关联特征的静态检测方法。这些都是有待进一步研究的工作。 [1] Feng Y, Anand S, Dillig I, et al. Apposcopy: semantics-based detection of Android malware through static analysis[C]//Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering. ACM, 2014: 576-587. [2] Petsas T, Voyatzis G, Athanasopoulos E, et al. Rage against the virtual machine: hindering dynamic analysis of Android malware[C]//Proceedings of the Seventh European Workshop on System Security. ACM, 2014: 1-6. [3] Enck W, Ongtang M, McDaniel P. On lightweight mobile phone application certification[C]//Proceedings of the 16th ACM Conference on Computer and Communications Security. ACM, 2009: 235-245. [4] Zhou Y, Wang Z, Zhou W, et al. Hey, you, get off of my market: detecting malicious apps in official and alternative Android markets[C]//Proceedings of the 19th Annual Network and Distributed System Security Symposium, 2012: 5-8. [5] Androguard[DB/OL]. http://code.google.com/p/androguard/. [6] 张玉清, 王凯, 杨欢, 等. Android安全综述[J]. 计算机研究与发展, 2015, 51(7): 1385-1396. [7] Jiang X. An evaluation of the application (“App”) verification service in Android 4.2[R].Raleigh, North Carolina, USA: North Carolina State University, 2012. [8] 蔡泽廷. 基于机器学习的Android恶意软件检测模型研究[D]. 青岛:青岛理工大学, 2013. [9] 张思琪. 基于改进贝叶斯分类的Android恶意软件检测[J]. 无线电通信技术, 2014, 40(6): 73-76. [10] 诸姣, 李宏伟, 彭鑫, 等. 安卓应用系统的功能与权限相关性研究[J]. 计算机应用与软件, 2014, 31(10):27-33. [11] 秦中元, 徐毓青, 梁彪, 等. 一种Android平台恶意软件静态检测方法[J]. 东南大学学报(自然科学版), 2013, 43(6):1162-1167. [12] Shabtai A. Malware detection on mobile devices[C]//2010 Eleventh International Conference on Mobile Data Management. IEEE, 2010: 289-290. [13] Enck W, Gilbert P, Han S, et al. TaintDroid: an information-flow tracking system for realtime privacy monitoring on smartphones[J]. ACM Transactions on Computer Systems (TOCS), 2014, 32(2): 393-407. [14] 徐冰泉, 张源, 杨珉. GrantDroid:一种支持Android权限即时授予的方法[J]. 计算机应用与软件, 2014, 31(8): 232-236,284. [15] Felt A P, Chin E, Hanna S, et al. Android permissions demystified[C]//Proceedings of the 18th ACM Conference on Computer and Communications Security. ACM, 2011: 627-638. [16] Au K W Y, Zhou Y F, Huang Z, et al. PScout: analyzing the Android permission specification[C]//Proceedings of the 2012 ACM Conference on Computer and Communications Security. ACM, 2012: 217-228. [17] Enck W. Defending users against smartphone apps: techniques and future directions[C]//7th International Conference on Information Systems Security. Springer, 2011: 49-70. [18] Nauman M, Khan S, Zhang X. Apex: extending Android permission model and enforcement with user-defined runtime constraints[C]//Proceedings of the 5th ACM Symposium on Information, Computer and Communications Security. New York, NY, USA: ACM, 2010:328-332. [19] VirusShare. Because sharing is caring[DB/OL]. [2013-10-21]. http://virusshare.com/torrents.4n6. [20] Manifest.permission[EB/OL]. http://api.apkbus.com/reference/android/Manifest.permission.html. [21] Yano Y, Hashiyama T, Ichino J, et al. Behavior extraction from tweets using character N-gram models[C]//Fuzzy Systems (FUZZ-IEEE), 2014 IEEE International Conference on. IEEE, 2014: 1273-1280. [22] Zhou Y, Jiang X. Dissecting Android malware: characterization and evolution[C]//Security and Privacy (SP), 2012 IEEE Symposium on. IEEE, 2012: 95-109. BAYESIAN ANDROID MALWARE DETECTION TECHNOLOGY BASED ON THE FEATURES OF ASSOCIATION Wang Cong Zhang Renbin Li Gang (SchoolofComputerandInformation,HefeiUniversityofTechnology,Hefei230009,Anhui,China) There is a close relationship between the Android malware and the application’s permissions, in view of the detection rate is not high of current detection technology, the existence of false positives, and lack of detection of unknown malicious. A static detection method based on the characteristics of associated permissions is proposed to realize the effective detection of Android malware. First of all, the characteristics of the application permissions are preprocessed, and the permissions association dataset is constructed by the frequent pattern mining algorithm, then the redundancy feature selection algorithm is designed to simplify the redundancy, finally the feature selection is carried out by Mutual information, independent feature spaces with the most ability to classify. The experimental results show that dealing with features has a better validity and reliability before Bayesian classification, the detection rate can be stable in 92.1%, the false positive rate is 8.3%, the detection accuracy rate is 93.7%. Bayesian classification Android Malware detection Associate features Feature selection 2015-12-16。国家自然科学基金项目(61273237)。王聪,硕士生,主研领域:计算机网络安全。张仁斌,副教授。李钢,教授。 TP3 A 10.3969/j.issn.1000-386x.2017.01.052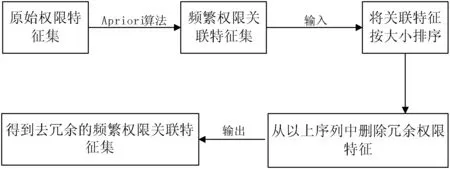
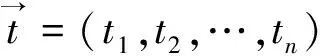
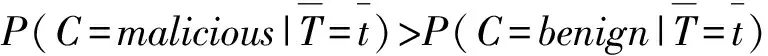
2 实验结果与分析


3 结 语
猜你喜欢
法律方法(2021年4期)2021-03-16
中国生物医学工程学报(2019年6期)2019-07-16
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
计算机技术与发展(2017年8期)2017-09-01
计算机应用(2016年10期)2017-05-12
电脑知识与技术(2016年1期)2016-03-22
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
弹箭与制导学报(2015年1期)2015-03-11
郑州大学学报(理学版)(2014年2期)2014-03-01
