
一种基于Docker容器的集群分段伸缩方法
2017-03-01 04:26苗立尧陈莉君
计算机应用与软件 2017年1期
苗立尧 陈莉君
(西安邮电大学计算机学院 陕西 西安 710061)
一种基于Docker容器的集群分段伸缩方法
苗立尧 陈莉君
(西安邮电大学计算机学院 陕西 西安 710061)
针对现有的虚拟机集群伸缩方法响应慢、开销大的问题,提出一种基于Docker容器技术的虚拟机集群伸缩方法。在检测实时工作负载同时通过自回归模型对未来工作负载进行预测,最后使用排队论模型计算所需伸缩量。首先从虚拟机自身进行资源重分配,然后依据工作负载变化率选择Docker容器级别的伸缩或虚拟机级别的伸缩,直到请求响应时间在用户可接受范围之内为止。实验结果证明,在面对不同的工作负载变化情况时,该方法可以提供更快的响应速度和更低的开销。
伸缩 虚拟机 Docker容器
0 引 言
随着网络的飞速发展,基于Web的应用在受到广泛关注的同时,其性能也面对着前所未有的挑战。Web应用的性能经常受制于动态的工作负载[1-2],而具有伸缩性的云计算环境为Web应用动态负载问题提供了解决方案。
目前,已有很多基于云计算环境下的集群伸缩性研究。这些集群的底层是由虚拟机搭建的,例如VMware、XEN等。文献[3]将云计算环境中现有的弹性应用自动伸缩技术这些技术分为两类:反应式伸缩和预测式伸缩。另外对于突发式的工作负载变化,由于虚拟机部署、启动时间比较长,一定程度上延长了伸缩调整时间。文献[4]介绍了对Web应用进行分层伸缩的原理。文献[5]指出蚁群算法、蜂群算法在负载均衡和伸缩算法里的应用。文献[6]提出了一种基于工作流模型的虚拟机动态分配、回收方法。但该方法并不能对未来的工作负载情况进行预测。文献[7]介绍了伸缩工具RightScale的伸缩算法原理。它是响应式伸缩,总是处于被动。
Docker是一个开源的引擎,可以轻松地为任何应用创建一个轻量级的、可移植的、自给自足的容器[8]。它并不是虚拟机,但它可在提供堪比虚拟机性能的同时,更快地部署。但因Docker容器的稳定性以及安全性还有待研究,目前很多企业并未将Docker容器大规模投入生产实践,它们的云环境仍建立在虚拟机构成的集群之上。基于此,本文提出了利用Docker容器来完成集群的快速伸缩。
针对文献[6-7]中仅依靠虚拟机伸缩响应慢、开销大,且不能进行预测的问题,故本文采用Docker容器技术来代替只使用虚拟机的伸缩方法。首先对多层Web应用进行数学建模以得到工作负载与资源数量间的关系,并综合利用预测式伸缩和响应式伸缩实现在Web应用面临变化的工作负载时,从三种粒度进行集群伸缩,以提高伸缩的响应速度并减少额外的开销。
1 分析与建模
1.1 Web应用的分层结构
现代的Web应用大多采用多层结构设计[9],应用主要分为表现层、业务层、数据层。每个应用都拥有一组特定的需求和限制,这是应用所有者制定的服务等级协议SLA(Service-Level Agreement)标准。
1.2 排队论建模
排队论是关于等待队列的一种数学研究方法。通过如图1所示的排队论模型,可以计算得到等待时间和队列长度,甚至所需的资源数量[10]。为了精确计算在负载变化时,每层应该伸缩多少资源,本文基于排队论模型里的G/G/1模型建立了多层应用的分析模型。本文提出的模型基于会话,每个会话包含多种交互操作。

图1 排队论示例
在G/G/1模型中,G/G/1分别表示请求到达间隔服从一般分布、服务时间服从一般分布、服务数量为1个,到达的服务请求按照先来先服务(FCFS)顺序处理。令
λ
i
表示到第
i
层的请求到达率,
R
i
表示第
i
层的平均响应时间,
S
i
表示该层的平均服务时间。由系统的监测数据计算可以得到到达间隔时间和服务时间的方差,分别使用
和
来表示,那么该模型可通过下式表示:
(1)

(2)
这里的βi为与该层有关的常量系数,T和τ由经验得出。
1.3Web应用开销分析
云服务提供商采用的收费策略是“pay-per-use”模型,即Web应用所有者只需按照他们使用的资源总额进行结算[12]。目前常见的一种云平台收费规则是计时收费:对于性能完全一样的一组服务器,按单位时间计费,不足一个单位时间的也取整数个。
本文提出的算法共采用了两种云基础设施作为底层,分别是虚拟机VMs和Docker容器。基于上文所述云平台收费规则由此本文提出如下计费公式:
(3)
其中,CTotal表示开销总额,CD表示Docker容器的使用单价,Dti表示第i个容器的使用时长。同样,CV表示虚拟机的使用单价,Vtj表示第j个虚拟机的使用时间,CExtra表示额外的开销。
2 基于Docker容器的伸缩方法
云计算的伸缩性指的是系统适应负载变化对资源进行调整的能力。从伸缩的方式看,伸缩有纵横之分[13],如图2所示。从伸缩的时机看,伸缩有预测式伸缩和响应式伸缩。

图2 纵向伸缩和横向伸缩
2.1 预测式伸缩
预测式伸缩的目的是通过对过去的历史数据的计算和分析,来完成对将来的预测。鉴于Web应用的工作负载情况可能随时间呈现一定的规律,故本文采用自回归模型AR(Auto-Regression)[14]来进行预测。模型函数用下式表示:x(n)+a1x(n-1)+a2x(n-2)+…+apx(n-p)=w(n)
(4)
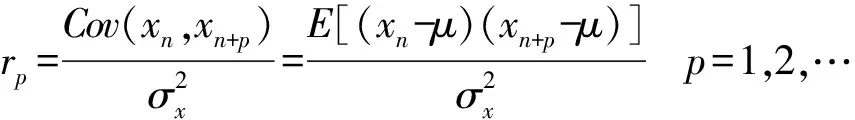
(5)
再根据Yule-Walker方程组可以解得系数:a1,a2,…,ap
(6)
代入式(1)即可得到一个用过去时刻数据预测将来时刻值的计算式[15]。
基于上述数学分析,本文首先假设一个固定的时间间隔v,记录时刻同时监控当时的工作负载值,并维持一个长度为T的历史数据表。将表内离当前时刻最近的p个数据代入上文所述的自回归模型,计算得到p个自相关系数r1,r2,…,rp,接着求解Yule-Walker方程组,解得系数a1,a2,…,ap,最终得到AR模型的方程,由此可以继续计算出下一时刻工作负载的预测值。
2.2 响应式伸缩
由于预测式伸缩不适用于突发式的工作负载。本文将采用响应式伸缩来弥补预测式伸缩的不足。
本文提出的方法首先要维持一张长度为L的近期负载表,表里记录了当前时间往前P时间内的负载变化情况。假定此刻监控得到的工作负载值为γo,将其与近期负载表里的工作负载值计算平均斜率得到此刻的负载变化率λ。如果λ大于上限λtu,说明此刻迎来突发的工作负载骤增,需要进行扩展。同理,当λ小于下限λtl,说明此刻迎来突发工作负载骤降,则需要进行收缩。
综上,预测式伸缩和响应式伸缩结合使用可以应对周期性工作负载变化和突发式的工作负载变化。
2.3 算法概述
本文通过t时刻的请求率γo(t)来反映当时的工作负载情况(后面用工作负载代替请求率),同时监控请求响应时间to。维持两张表:长度为T的历史负载表H和长度为L的近期负载表P。通过对H的数据代入AR模型可以对下个时刻的工作负载进行预测γp(t),同时对P的数据进行计算可得到工作负载的变化率λ。
本文提出的伸缩算法包括两部分:扩展算法和收缩算法。在扩展算法里,当监测到的γo(t)大于上限γtu时,如果此时工作负载变化率λ也大于上限λtu,此时部署Docker容器来完成扩展。如果此时λ介于上限λtu和下限λtl之间,部署虚拟机来扩展,或者预测的工作负载γp(t)大于请求率上限γtu时,直接部署虚拟机来扩展,收缩算法与扩展算法类似。
在伸缩调整时,先在虚拟机自身进行资源重新分配。如果调整后响应时间不能满足SLA要求,再判断部署虚拟机还是部署Docker容器。调整操作直到请求响应时间重新满足SLA为止。
在每次伸缩调整操作之后,会有一个短暂的冷却时间以防止频繁伸缩对系统性能带来的消耗。
表1列出本文提出的算法将会用到的各个变量及其含义。

表1 各个变量及其含义
算法的伪代码如下:
算法1 服务器调度算法
Input:s,γtu,γtl,λt
Output: Scaling Plan1. Begin
2. While(App is running)
3. Monitortoat a fixed interval
4. Maintain 2 tables: History TableH(LengthT) & Present TableP(Length L).
5. Calculateλ,γp(t)
6. Ifγo(t)>γtu||γp(t)>γtu,Then
7. Scaling-Up(S)
8. Else ifγo(t)<γtu,Then
9. Scaling-Down(S)
10. ColdDown(period)
11. End
2.3.1 扩展算法
扩展算法的目标是提高服务器的性能或增加服务器的数量以在面临高工作负载时仍能提供满足SLA的服务。算法伪代码如下:
算法2 扩展算法
Input:S
Output: updatedS
1. Begin
2. Ifγp(t) >γtu,then
3. Invoke VM Scaling Up
4. Monitorto
5. Whileto>ttu
6. Invoke Self Scaling Up
7. Calculateλ
8. Ifλ>λtu,then
9. Invoke Docker Scaling Up
10. Else ifλ<λtu,then
11. Invoke VM Scaling Up
12. Invoke Self Scaling Up
13. End
Self-Scaling属于纵向伸缩,算法通过对部署在同一台物理机h上的多台服务器之间进行资源重分配来提高服务器的性能。算法伪代码如下:
算法3 自调整算法
Input: pair(Sa,Sb)
Output: updated pair(Sa,Sb)1. Begin
2. Monitorto
3. Ifto>ttu,then
4. Whiles≠updated(s)
5. IfSa∉updated(s)&&sb∉updated(s)&&u(sa,ri)>utu(ri) &&u(sb,ri) 6. Remove one unit of resourcerifromsb, 7. Add one unit of resourceritosa 8. IncludeSaandSbtoupdated(s) 9. End Docker-Scaling和VM-Scaling算法属于横向伸缩。通过比较λ与上限λtu来确定是否属于突发式的工作负载,从而确定是增加Docker容器还是虚拟机。算法伪代码实现如下: 算法4 Docker容器扩展 Input:S Output: newS1. Begin 2. Monitorto 3. Calculateλ 3. Whileto>ttu&&λ>λtu 4. for each tier of m-tiers : 5. Using QueueTheoryModel to calculate the desirednServers at tieribased on the observed request rateγo(t) 6. DeploynDocker Containers as Servers to tieri 7. Include the new Servers to the list ofS 8. End 算法5 虚拟机扩展 Input:S Output: newS1. Begin 2. Monitorto 3. Whileto>ttu 4. for each tier of m-tiers : 5. Using QueueTheoryModel to calculate the desirednServers at tieribased on the observed request rateγo(t) 6. AddnVMs as Servers to tieri 7. Include the new Servers to the list ofS 8. End 2.3.2 收缩算法 收缩算法通过对请求率γ°(t)和响应时间t° 的监测,当γ°(t)低于上限γtu,若γ°(t)还低于下限γtl,则关闭虚拟机。否则关闭Docker容器。关闭的时候需要保持t°满足SLA。算法伪代码如下: 算法6 收缩算法 Input:S Output: newS1. Begin 2. Monitorto<γo(t)&&γo(t)<γtu 3. Whileto 4. Ifγo(t)<γtl,then 5. Exclude one VM fromS& Shut it down 6. Else 7. Exclude one Docker fromS& Shut it down 8. End 3.1 实验环境 本文的实验环境基于TPC Benchmark W(TPC-W)[16]。TPC-W是一款交互式的网络性能测试工具,它提供的工作负载模拟了常见电子商务的业务活动。本文基于此构建一个由4台虚拟机组成的云计算环境,并在之上搭建一个三层的电子商务平台,一台作为HTTP服务器,一台作为数据库服务器,剩余两台作为Web应用服务器。 3.2 实验设计及结果 在TPC-W的基础上,本文从负载变化维度列出了两种典型的工作负载变化情况:突发负载、周期负载。如图3所示。 (a) 突发负载 (b) 周期负载 本文在上述两种工作负载变化情况下,选取了3个实验对象见表2所示。 表2 实验对照 其中A和B、A和C分别构成对照组。它们分别运行各种工作负载变化,每种负载运行3次,每次运行2小时,计算它们的平均响应时间、平均开销,并加以比较。实验结果如图4、图5所示。 图4 突发负载下的比较 图5 周期负载下的比较 分析实验结果可知,在突发负载情况下,A、B、C的请求响应时间会随着负载变化产生波动,其中A的请求响应时间明显小于B、C是由于A在伸缩时的部署,启动时间小于B、C。在周期负载情况下,A、B、C的请求响应时间随着负载变化而波动,B和C在每个负载周期时的表现都几乎不变。A随着周期到来请求响应时间明显降低,是由于A的预测算法可以提前为周期负载做好准备。3个实验对象的平均开销如图6所示。 图6 平均开销的比较 图6中1、2分别表示2种工作负载变化情况。从图可以看出,本文提出的方法可以减少突发性工作负载和周期性工作负载下的伸缩开销。 实验结果表明,本文提出的算法可以使Web应用在面临不同工作负载的情况下满足SLA标准,在降低开销的同时加快伸缩响应速度。 本文通过建立自回归模型预测未来工作负载变化情况,并结合响应式伸缩协同做出伸缩调整决定。伸缩的资源数量由工作负载量在排队论模型里计算得到。该伸缩方法在自身、Docker容器、虚拟机三种粒度上对面临工作负载变化的虚拟机集群进行了调整。 通过实验可知,本文提出的方法可以有效完成在两种典型工作负载变化下对虚拟机集群的伸缩调整。在保证了Web应用的SLA标准的同时,相比只有虚拟机来完成伸缩的集群,伸缩调整速度得到了提升,在一定程度上节省了Web应用所有者的开销。 [1] Farokhi S,Jamshidi P,Brandic I,et al.Self-adaptation Challenges for Cloud-based Application s:A Control Theoretic Perspective[C/OL].(2015-02-18) [2015-06-29].http://www.infosys.tuwien.ac.at/staff/sfarokhi/soodeh/papers/Soodeh-Farokhi_CameraReady_FeedbackComp-2015.pdf. [2] 朱志祥,许辉辉,王雄.基于云计算的弹性负载均衡方案[J].西安邮电大学学报,2013,18(6):43-47. [3] Lorido-Botran T,Miguel-Alonso J,Lozano J A.A Review of Auto-scaling Techniques for Elastic Applications in Cloud Environments[J].Journal of Grid Computing,2014,12(4):559-592. [4]VaqueroLM,Rodero-MerinoL,BuyyaR.DynamicallyScalingApplicationsintheCloud[J].ACMSIGCOMMComputerCommunicationReview,2011,41(1):45-52. [5]KukadePP,KaleG.SurveyofLoadBalancingandScalingapproachesincloud[J].InternationalJournalofEmergingTrendsandTechnologyinComputerScience,2015,4(1):189-192. [6]MaoM,HumphreyM.Auto-ScalingtoMinimizeCostandMeetApplicationDeadlinesinCloudWorkflows[C]//2011InternationalConferenceforHighPerformanceComputing,Networking,StorageandAnalysis,2011:1-12. [7]RightScale.SetupAutoscalingusingVotingTags[EB/OL].(2012-12-14) [2015-06-29].http://support.rightscale.com/12-Guides/Dashboard_Users_Guide/Manage/Arrays/Actions/Set_up_Autoscaling_using_Voting_Tags/index.html. [8]Docker.WhatisDocker?[EB/OL].(2014-02-15) [2015-06-29].http://www.docker.org.cn/book/docker/16_what-is-docker.html. [9]UrgaonkarB,ShenoyP,ChandraA,elal.AgileDynamicProvisioningofMulti-TierInternetApplications[J].ACMTransactionsonAutonomousandAdaptiveSystems,2008,3(1):217-228. [10]Wikipedia.QueueingTheory[EB/OL].(2015-06-19) [2015-06-29].https://en.wikipedia.org/wiki/Queueing_theory. [11]Wikipedia.Little’slaw[EB/OL].(2015-06-24) [2015-06-29].https://en.wikipedia.org/wiki/Little%27s_law. [12]HanR,GhanemMM,GuoL,elal.Enablingcost-awareandadaptiveelasticityofmulti-tiercloudapplications[J].FutureGenerationComputerSystems,2014,32:82-98. [13] 龚强.云计算关键技术之弹性伸缩控制技术认知研究[J].信息技术,2014(1):1-2,6. [14]Wikipedia.Autoregressivemodel[EB/OL].(2015-06-24) [2015-06-29].https://en.wikipedia.org/wiki/Autoregressive_model. [15] 丁玉美,阔永红,高新波.数字信号处理-时域离散随机信号处理[M].西安:西安电子科技大学出版社,2002:152-153. [16]TPC-W.TPC-WSummary[EB/OL].(2005-04-28) [2015-06-29].http://www.tpc.org/tpcw/. A CLUSTER SCALING METHOD BASED ON DOCKER CONTAINER Miao Liyao Chen Lijun (SchoolofComputerScienceandTechnology,UniversityofPostsandTelecommunications,Xi’an710061,Shaanxi,China) A scaling method of cluster is proposed based on Docker container technology to solve the problems of present scaling method,such as slow response and heavy cost.It uses auto-regressive model to predict future workload while monitoring the real-time workload,and calculates the need of resource with one queue theory model.This method first relocates resources by itself,then it chooses the Docker scaling or VM scaling depending on the workload change rate until the response time is within an acceptable range of users.The experimental results show that this method can provide faster scaling response and less cost when dealing with fluctuating workloads. Scalability Virtual machine Docker container 2015-11-02。苗立尧,硕士生,主研领域:大数据与高性能计算。陈莉君,教授。 TP319 A 10.3969/j.issn.1000-386x.2017.01.0063 实验验证


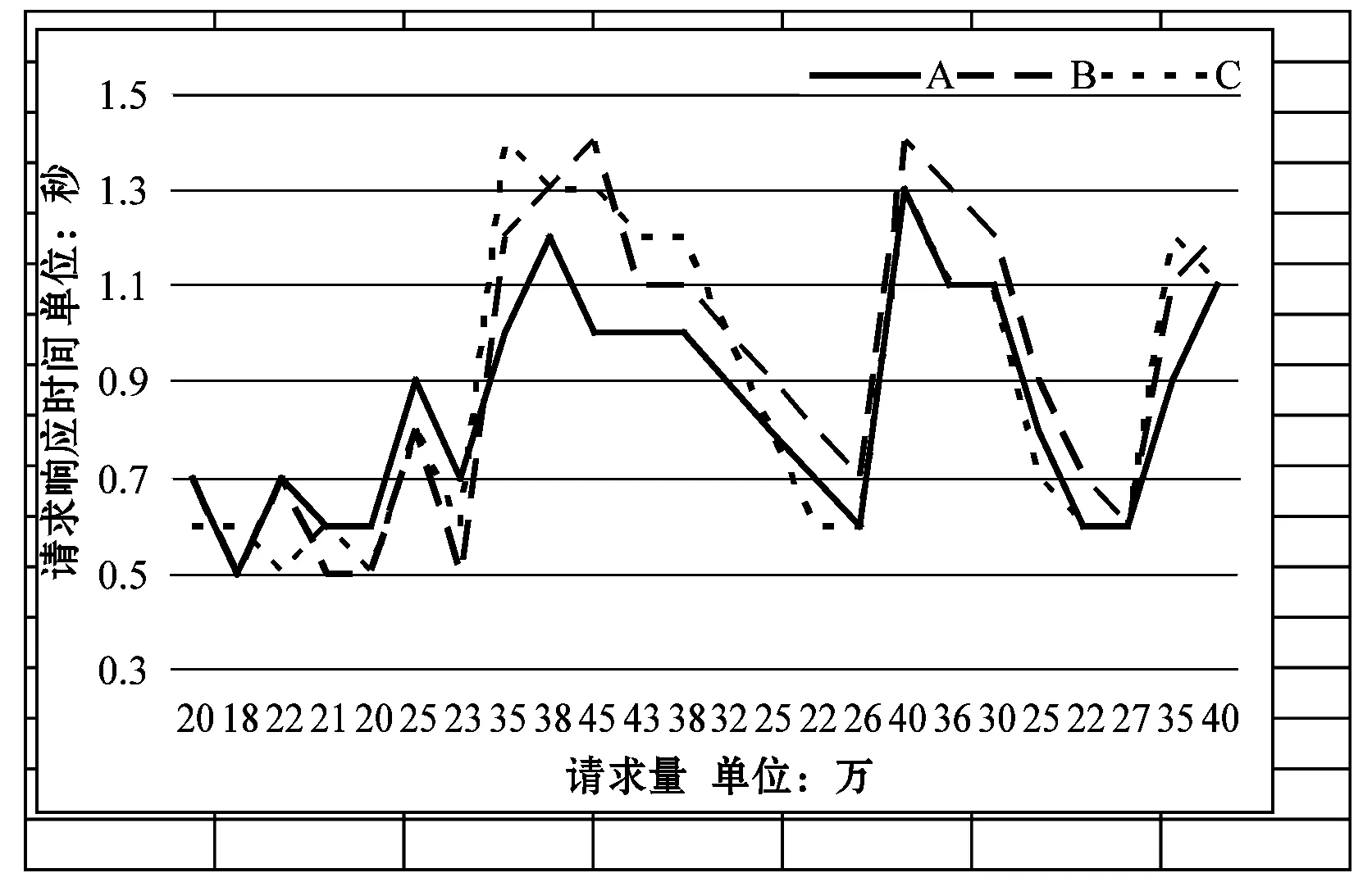

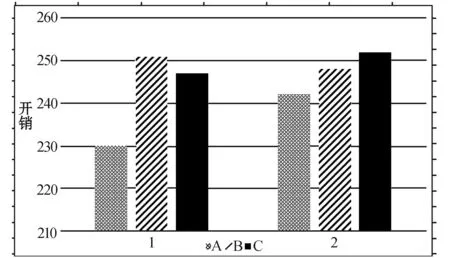
4 结 语
猜你喜欢
中学生数理化·八年级物理人教版(2022年4期)2022-04-26学生天地(2020年14期)2020-08-25读者·校园版(2019年24期)2019-12-10军事运筹与系统工程(2019年4期)2019-09-11特别文摘(2018年3期)2018-08-08电子制作(2018年11期)2018-08-04中国交通信息化(2017年3期)2017-06-08知识就是力量(2017年2期)2017-01-21小朋友·聪明学堂(2015年8期)2015-11-30诗选刊(2015年6期)2015-10-26
