
基于主题角色的文本情感分类方法
2017-03-01 04:26刘晨晨冯旭鹏刘利军黄青松段成香
计算机应用与软件 2017年1期
刘晨晨 冯旭鹏 胡 杨 刘利军 黄青松,3* 段成香
1(昆明理工大学信息工程与自动化学院 云南 昆明 650500)
基于主题角色的文本情感分类方法
刘晨晨1冯旭鹏2胡 杨1刘利军1黄青松1,3*段成香4
1(昆明理工大学信息工程与自动化学院 云南 昆明 650500)
2(昆明理工大学教育技术与网络中心 云南 昆明 650500)3(云南省计算机应用重点实验室 云南 昆明 650500)4(昆明迪时科技有限公司 云南 昆明 650000)
传统文本情感分类方法通常以词或短语等词汇信息作为文本向量模型特征,造成情感指向不明和隐藏观点遗漏的问题。针对此问题提出一种基于主题角色的文本情感分类方法。该方法首先提取出文本中的潜在评价对象形成评价对象集,评价对象作为情感句描述的主体能够很好地保存文本情感信息;然后使用LDA模型对评价对象集进行主题抽取,将抽取出的主题分裂成“正”“负”两种特征项,将这两种特征项记为正负主题角色用于保存文本情感信息;最后,计算主题角色在文本中的情感影响值并建立主题角色模型。实验结果表明,所提方法与传统方法相比可有效提高主观性文本情感分类的准确率。
文本情感分类 潜在评价对象 LDA 主题抽取 主题角色
0 引 言
文本情感分析又称意见挖掘,简单而言,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程[1]。情感信息的分类任务可大致分为两种:一种是主、客观信息的二元分类;另一种是主观信息的情感分类,包括最常见的褒贬二元分类以及更细致的多元分类[2]。随着互联网上各种带有情感色彩的主观性文本的出现,如微博、新闻评论、博客等,主观文本的情感分类日益受到研究者的关注。
主观文本倾向性分类是基于文本的情感特征的处理过程,主要有两种研究思路:基于语义和基于机器学习的方法。基于语义的方法通过将文本中的词汇倾向值进行统计求和[3],得到文本的情感倾向,主要借助已有的词典或自然语言知识库扩展情感倾向词典。Turney等[4]提出了一种无监督的学习方法,通过测试副词、名词等单词的语义倾向性,将文本分为积极和消极两类;随后Turney等[5]利用点互信息(PMI)和潜在语义分析(LSA)来推断一个词的语义倾向;朱嫣岚等[6]提出了两种基于HowNet词典的语义倾向性计算方法,用来计算词语与褒贬义基准词之间的相关性。基于语义的方法通过计算出词语与褒贬义基准词的距离得到了词语的情感值[6],但是这种方法并没有考虑词语本身的情感值对文本倾向性的影响。
基于机器学习的方法通过对训练集进行训练得到分类器,使用得到的分类器来对新文本进行情感分类。Pang等[7]首先采用朴素贝叶斯、最大熵分类和支持向量机三种机器学习的方法对电影评论数据进行文本倾向性分类;唐慧丰等[8]以不同词性的词作为文本表示特征,对KNN、SVM、中心向量法等文本分类方法,在不同特征数量和规模的训练集的情况下进行了比较研究;徐军等[9]将机器学习的方法用于新闻文本情感分类取得了不错的分类性能。基于机器学习的方法在文本情感分类的应用上已取得不错的效果,但是这种方法由于缺乏语义信息大大影响了其分类效果。有学者针对上述问题在机器学习的基础上加入语义的方法,提高了分类性能。徐琳宏等[3]通过计算词语与知网中标注的情感词的相似度获取特征词,用SVM分类器分析文本的褒贬性,并将副词对情感词倾向性的影响考虑了进来,得到了很好的分类效果。胡杨等[10]以向量空间模型为基础,通过建立情感角色模型,将情感角色对应的倾向值融入模型特征空间,进一步提高了分类的精度。但是无论是基于语义的还是基于机器学习的方法,通常都以词或短语等词汇信息作为文本向量模型特征,由于自然语言本身的灵活性和复杂性,单纯使用词汇信息无法准确表达文本的情感倾向[11]。此外,评价对象作为情感句描述的主体,若忽略其对文本情感分类的影响,也容易造成情感指向不明和隐藏观点遗漏的问题[12]。
针对上述问题,本文以向量空间模型为基础,提取文本中的潜在评价对象得到评价对象集,使用LDA主题模型对评价对象集进行建模,以评价对象作为特征词抽取出主题。将抽取出的主题分裂成“正”“负”两种并生成主题角色作为文本特征项,计算主题角色在文本中的情感影响值作为特征值的一部分,建立主题角色模型。实验表明,本文模型在篇章级文本情感分类中可有效提升分类效果。
1 基于主题角色的文本情感分类
评价对象是指某段评论中所讨论的主题,具体表现为评论文本中评价词语所修饰的对象[1],分析其在文本句中的情感倾向能够很好地保存文本情感特征。考虑到文本所表达的情感倾向必然针对特定的对象,一篇文本中可能存在多个评价对象,对评价对象集进行建模可以较为准确地抽取出与主题最相关的评价对象,方便在后文中对文本情感极性进行准确分析。
1.1 潜在评价对象抽取和主题挖掘
文本情感分类中通常将名词或名词短语作为候选评价对象。使用分词工具对文本进行预处理,包括分词、去除停用词和词性标注,抽取文本中的名词作为潜在评价对象,将从所有文本中抽取出的潜在评价对象合并得到评价对象集 ,使用LDA模型对评价对象集 进行主题挖掘。
LDA模型是由Blei等[13]在2003年提出的一种对自然语言进行建模的生成模型,可以用来挖掘大规模文档集或语料库中内蕴的主题信息。LDA模型如图1所示。
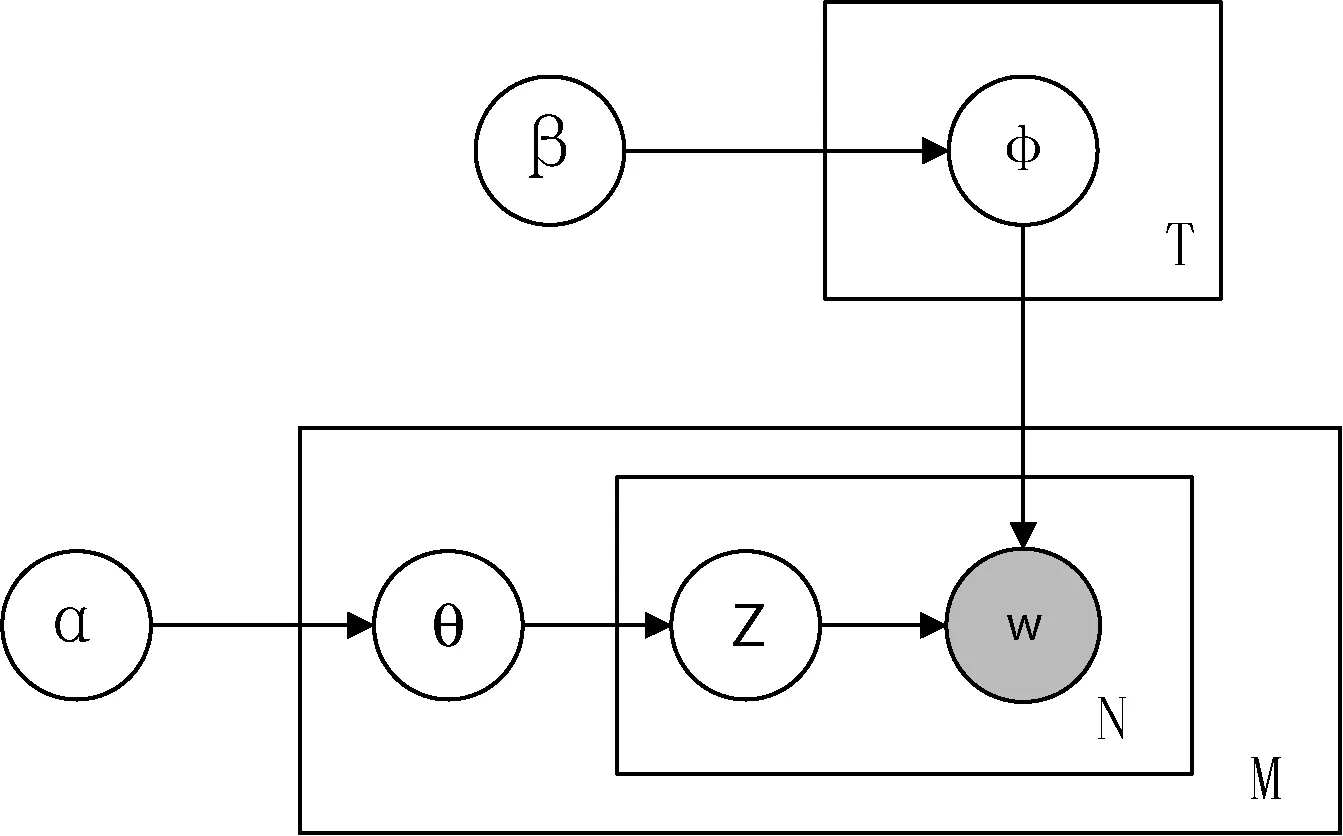
图1 LDA图模型
其中α为文本—主题概率分布θ的超参数,β为主题—特征词概率分布φ的超参数,M、T、N分别为文本数、主题数和一篇文本中的特征词数,w为观察到的文本中的特征词,z为特征词w的主题分配。通过对变量z进行Gibbs采样间接估计θ和φ:
(1)
(2)
主题抽取完成后,为每个主题都生成了一个主题—特征词分布,选取每个主题中概率分布排名前m的特征词作为主题最相关特征,并表示为所属各个主题的概率分布形式如式(3):
Tn=(w1∶φnl,w2∶φn2,…,wm∶φnm)
(3)
其中,wm为与主题Tn最相关的前m个特征词,φnm为主题Tn下词wm的概率分布,用式(2)计算。
1.2 主题角色生成和情感值计算

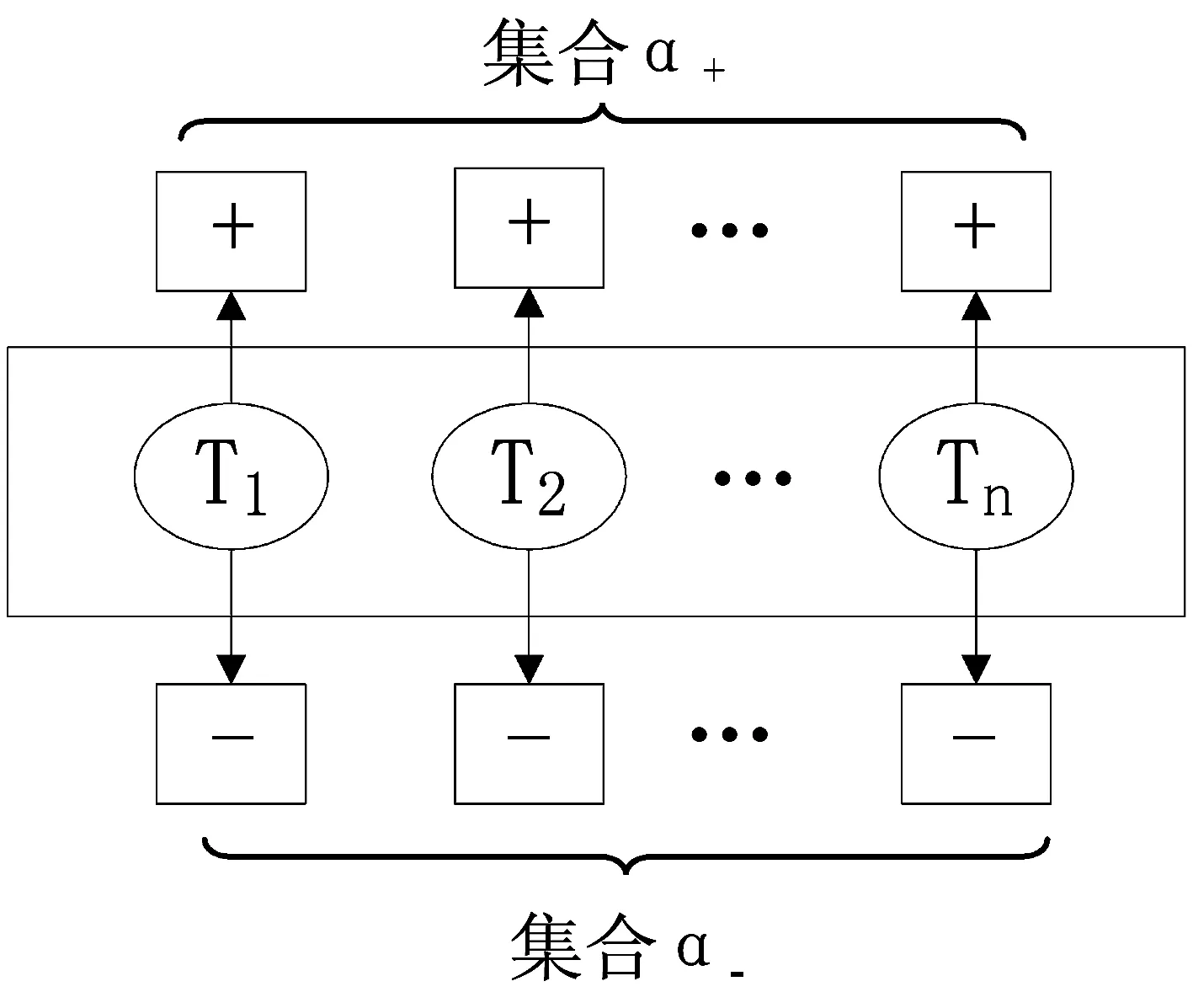
图2 主题角色生成示意图
本节采用基于语义方法的思想[3]计算主题角色在文本中的情感影响值,通过主题特征词的倾向值来计算主题角色在一篇文本中的情感值。考虑特征词在不同语境中会有不同的情感倾向,此外,副词也会影响特征词的倾向性和情感强度。例如“药效并不好”和“药效非常好”,因为否定副词和程度副词的存在,“药效”这个词在句中表现为不同的情感极性和强度。为使主题特征词的情感倾向更接近在文本中的真实情况,计算其所在句的情感倾向值,并将整句的情感值作为主题特征词的情感值。
依据文献[14]的思想,对文本按照标点符号进行分句,将文本d看作是由一系列句子组成的集合:d={s1,s2,…,sm},其中m为文本d中句子的数量,每个句子si看作是由一系列的词语组成的集合:si={wi,wi+1,…,wi+n-1},其中i代表句子中第一个词的位置,n代表句子中词语的数量。根据情感词汇本体(本文使用大连理工大学信息检索研究室的情感词汇本体[15],并将词汇本体中的词语称作情感词,词语情感值记作Sentibility(wi))中的情感词标签对文本句子中情感词的情感极性和情感强度进行初始设置。考虑词语所在句子的位置权重,在自然语言处理中文本开头和结尾两端的句子具有更高的权重,句子评分表达式定义如下:
Position(sj)=a×pos(sj)2+b×pos(si)+c
(4)
式(4)服从:
其中m表示文本d中句子的数目,pos(si)表示句子si在文本d中的位置,a、b、c为多项式系数。同时考虑否定副词和程度副词对情感词极性和情感强度的影响,收集否定副词和程度副词并为副词设定不同等级的权值如表1。计算整句的情感倾向值作为句中特征词的倾向值,计算公式如下:
Position(Si))
(5)
其中Sentibility(wi)表示情感词wi的情感值,m表示句子中情感词的数量,n表示句子中否定副词的个数,valueadv为程度副词的权值。
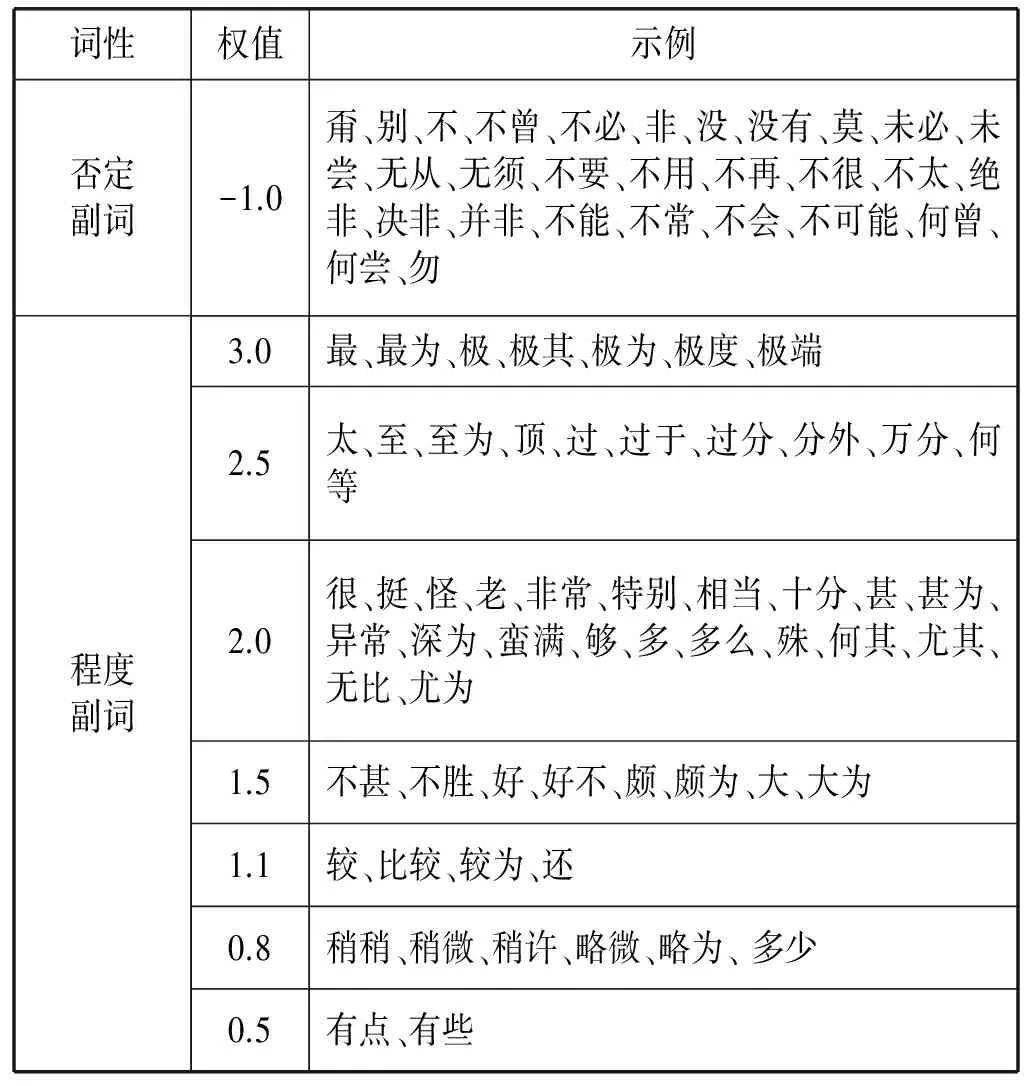
表1 副词转折词权值映射表
通过上述操作,每个主题角色的特征词在文本中的情感倾向值便可计算出,同一主题分裂生成的正、负两种主题角色在文本d中的情感值便可由式(6)和式(7)计算得出:
(6)
(7)
其中,SO(wi)为特征词wi在文本句中的情感值,由式(5)计算得出;φn,i为特征词在所属主题的概率分布;m为主题角色中的特征词数量;ϑd,n为文本d中主题Tn的概率分布。根据约束域原理[16],对表达式进行了归一化处理,使主题角色在文档中的情感值处于区间,便于量化分析。表达式如下:
(8)
1.3 主题角色模型建立和分类框架
主题角色作为保存文本情感的特征项,其特征值Fn,d由式(8)得出,最后情感角色模型建立如下:
(9)
其中,n表示正负主题角色数量,即主题数,N为语料库中的文章数。通过上述一系列处理,在正向情感的文本中,正极主题角色在文本中的特征值会明显高于负极主题角色在正向文本中的特征值;相反,在负向情感的文本中,正极主题角色在文本中的特征值会明显小于负极主题角色在正向文本中的特征值。将待测文本与训练文本作相同处理进行特征提取,从而实现主观性文本倾向性分类。
分类的整体框架如图3所示。结构A通过LDA模型提取主题及主题—词分布并建立主题角色模型,训练过程在正、负语料集中分别进行;结构B针对新文本在已生成的主题上运行LDA模型得到新文本的文本—主题分布,并进行特征表示;将结构A和结构B获得的结果送入分类器,实现基于主题角色模型的分类。
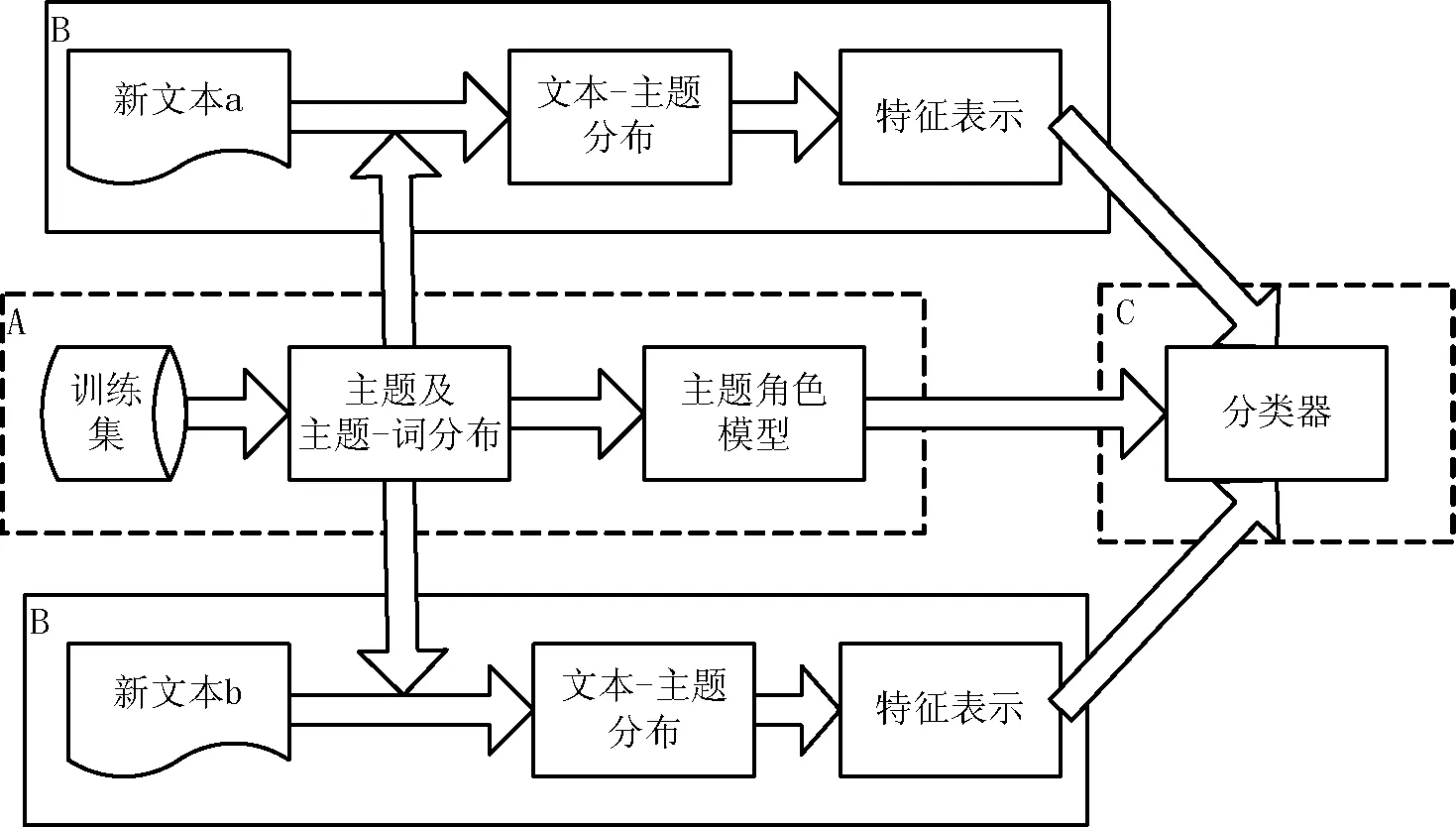
图3 分类框架图
2 实 验
2.1 实验数据与实验设置
实验选用平衡的中文情感挖掘语料集ChnSentiCorp(http://www.searchforum.org.cn/tansongbo/corpus-senti.htm)。另外,从互联网上收集赞美祖国、赞美和谐社会等主题的字数规模在500~1000字的文档2000篇,收集同等字数规模的反动暴力以及污蔑共产党等主题的文档2000篇作为实验语料。语料均经过抽取转换成统一的文本格式,从中选取正、负极性的语料各500篇作为测试集,其余语料作为训练集,本文实验均在正、负语料集中分别进行。对语料库中的文本进行预处理,包括分词和去除停用词,分词工具使用中科院的中文分词工具ICTCLAS。
2.2 实验结果分析
本文选用情感分类中常用的准确率和召回率和F-measure作为实验结果的衡量标准。统计被判定为正极性实际为正极性的文本tt,被判定为正极性实际为负极性的文本tn,被判定为负极性实际为正极性的文本nt,被判定为负极性实际为负极性的文本nn,计算式如下:
(10)
(11)
准确率和召回率是反映分类质量的两个重要指标,两者必须综合考虑。根据COAE2014的评价指标,实验采用F1测度来均衡两方面,定义如下:
(12)
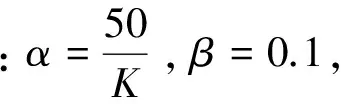
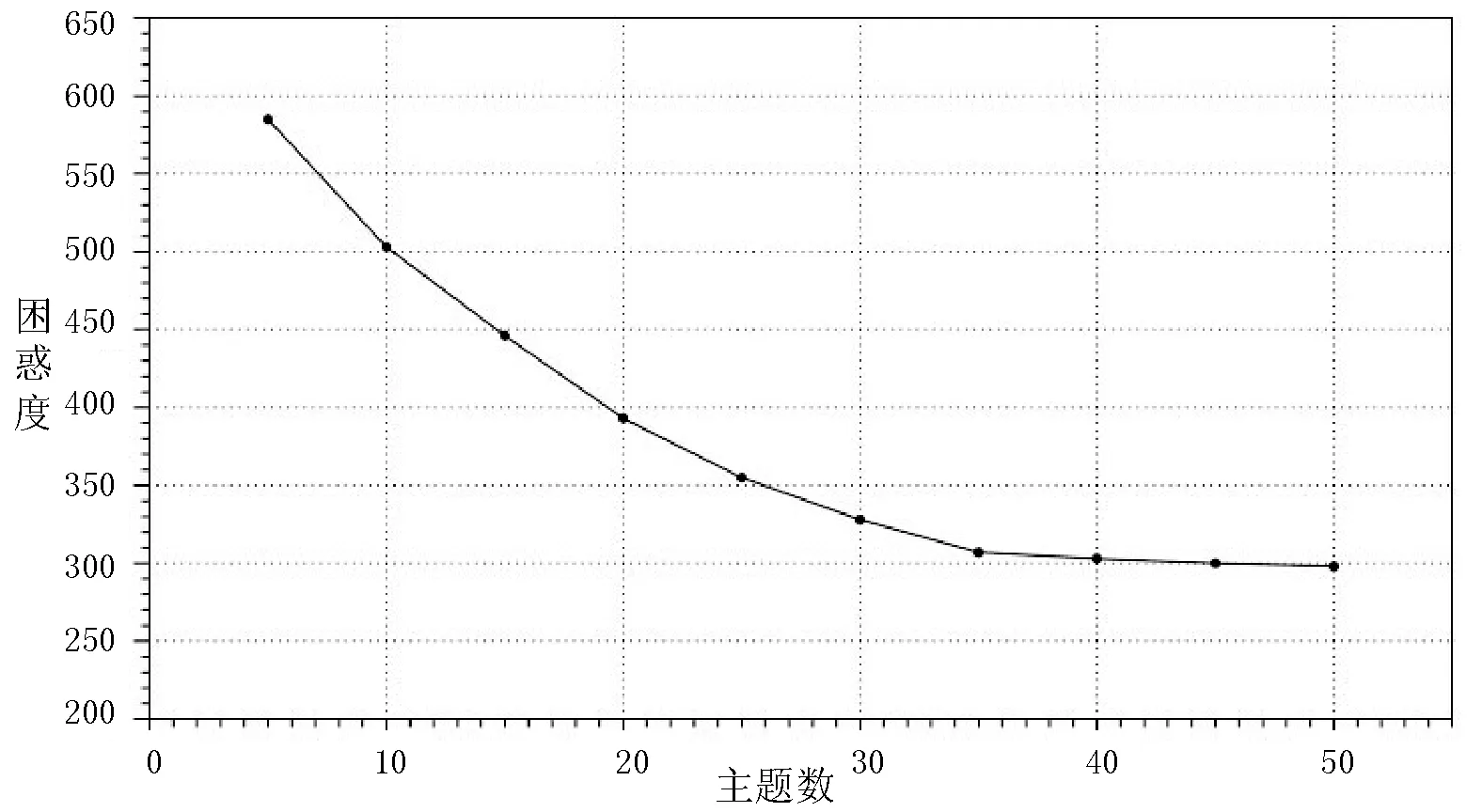
图4 不同主题数下的困惑度
从图4可以看出,随着主题数的增加,困惑度呈下降趋势,当主题数达到35时,困惑度趋于稳定,可以得出此时模型性能较佳,最优主题数目为35。因此取主题数目为K=35。
实验2 为验证式(3)中选取不同数量的主题特征词时的分类性能。本文方法是通过主题特征词的情感倾向来计算主题角色的特征值,如果主题特征词的数量选取不合适则容易造成情感特征遗漏和情感指向不明的问题。设置选取的前m个主题特征词的数量为5~50(间隔为5),暂时使用SVM分类算法进行测试。由图4可以看出,当特征词的数量选取在20附近时,分类效果较佳。设置特征词数量为16~24(间隔为1)继续进行测试,实验结果如图5所示,由图可知,当特征词数量为22时分类准确率最高,于是设置选取的前m个主题特征词数为22。
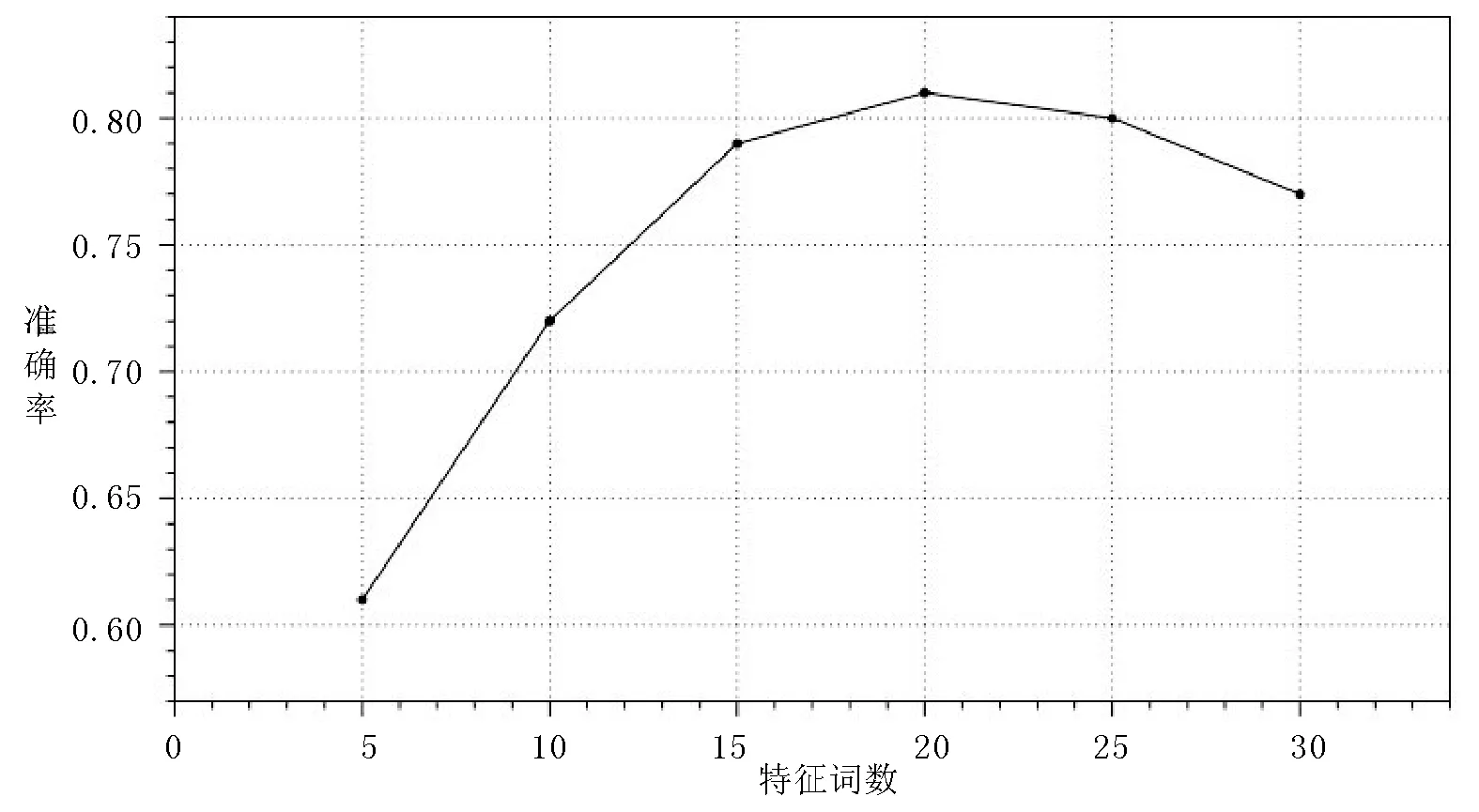
图5 不同特征词数下的准确率

图6 不同特征词数下的准确率(细化)
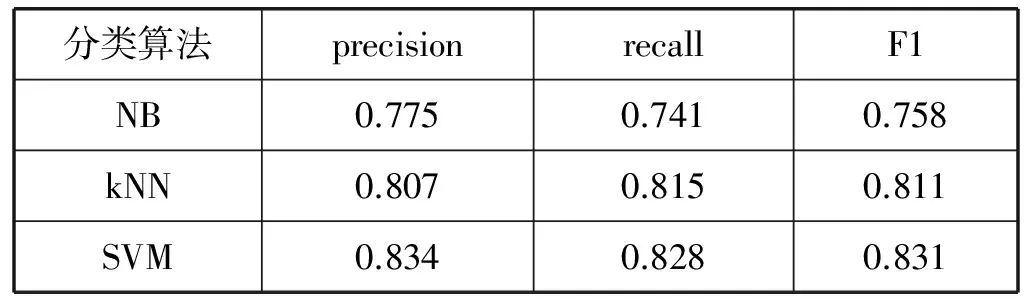
实验3 为选用不同分类器的分类性能对比。NaiveBayes(NB)方法非常简单,但在文本分类中常常取得令人满意的效果;k-近邻(kNN)分类方法是一种非常有效的归纳推理方法;支持向量机(SVM)方法在文本分类中展现出的良好性能已得到多位学者的验证,如Pang等[7]在进行对电影评论的分类任务时使用SVM算法的分类效果最佳。kNN中近邻数设置为11~25(间隔2),实验结果显示近邻数为17时实验效果最优。SVM多采用多项式核函数和径向基核函数,分别选用两种核函数进行测试,使用径向基核函数时表现出了更好地分类性能,径向基核函数的形式如式(13)。分别使用参数设置为最优的NB、kNN、SVM三种分类方法对语料集进行训练,比较三种分类方法在同一语料集下的分类性能,结果显示SVM方法的分类准确率、召回率和F1测度明显高于其他两种方法,所以本文选用SVM分类器,对于SVM算法的实现选用工具LibSVM。实验结果如表2所示。
(13)
实验4 为本文方法与传统情感分类方法的性能对比。使用本文提出的方法结合SVM(Local-SVM),使用信息增益提取情感特征结合SVM(IG-SVM),文献[10]提出的人工抽取情感角色的方法(ER-SVM)和文献[17]提出的基于主题的情感向量空间模型(BR)的方法,分别对语料集进行训练,比较4种方法在同样语料下的分类性能。实验结果如表3所示。

表3 不同分类方法的分类性能对比
由表3可得:1) 在处理同等规模的语料时,相较于使用SVM算法分类,本文所提方法在准确率上有较大提高;2) 较传统的仅使用机器学习的方法,本文所提方法在准确率和召回率上也有所提高;3) 准确率和召回率和文献[10]所提出方法相比虽然略有下降,但是考虑到本文方法不需要人工收集潜在评价对象,且应用范围更广,损失的准确率在可接受范围之内。
3 结 语
本文提出的基于主题角色的方法将文本潜在评价对象考虑到文本情感分类中来,采用的主题角色模型很好地保存了文本特征,可以有效发现文本隐藏情感信息,解决了因情感项指向不明引起的文本情感分类误判的问题,在一定程度上提高了分类的性能。今后的研究工作将继续优化所提方法的效率,并将该方法推广应用到短文本及跨领域的情况下。
[1] 赵妍妍, 秦兵, 刘挺. 文本情感分析[J]. 软件学报, 2010, 21(8): 1834-1848.
[2] 徐琳宏, 林鸿飞,赵晶. 情感语料库的构建和分析[J]. 中文信息学报, 2008, 22(1): 116-122.
[3] 徐琳宏, 林鸿飞, 杨志豪. 基于语义理解的文本倾向性识别机制[J].中文信息学报, 2007, 21(1): 96-100.
[4]TurneyPD,LittmanML.UnsupervisedLearningofSemanticOrientationfromaHundred-Billion-WordCorpus[R].NationalResearchCouncilofCanada, 2002.
[5]TurneyPD,LittmanML.Measuringpraiseandcriticism:inferenceofsemanticorientationfromassociation[J].ACMTransactionsonInformationSystems, 2003, 21(4): 315-346.
[6] 朱嫣岚, 闵锦, 周雅倩, 等.基于HowNet的词汇语义倾向计算[J].中文信息学报, 2006, 20(1): 14-20.
[7]PangB,LeeL,VaithyanathanS.Thumbsup?Sentimentclassificationusingmachinelearningtechniques[C]//ProceedingsoftheACL-02ConferenceonEmpiricalMethodsinNaturalLanguageProcessing.Stroudsburg,PA:AssociationforComputationalLinguistics, 2002: 79-86.
[8] 唐慧丰, 谭松波, 程学旗. 基于监督学习的中文情感分类技术比较研究[J]. 中文信息学报, 2007, 21(6): 88-94,108.
[9] 徐军, 丁宇新, 王晓龙.使用机器学习方法进行新闻的情感自动分类[J].中文信息学报,2007, 21(6): 95-100.
[10] 胡杨, 戴丹, 刘骊, 等. 基于情感角色模型的文本情感分类方法[J]. 计算机应用, 2015, 35(5): 1310-1313,1319.
[11] 乌达巴拉, 汪增福. 一种扩展式CRFs的短语情感倾向性分析方法研究[J]. 中文信息学报, 2015, 29(1): 155-162.
[12] 朱杰. 基于评价对象及其情感特征的中文文本倾向性分类研究[D]. 上海:上海交通大学, 2010.
[13]BleiDM,NgAY,JordanMI.Latentdirichletallocation[J].TheJournalofMachineLearningResearch, 2003, 3: 993-1022.
[14] 林政, 谭松波, 程学旗. 基于情感关键句抽取的情感分类研究[J]. 计算机研究与发展, 2012, 49(11): 2376-2382.
[15] 徐琳宏, 林鸿飞, 潘宇, 等. 情感词汇本体的构造[J]. 情报学报, 2008, 27(2): 180-185.
[16]EsuliA,SebastianiF.SentiWordNet:Apubliclyavailablelexicalresourceforopinionmining[C]//ProceedingsoftheLREC-06,the5thConferenceonLanguageResourcesandEvaluation,Genova,Italy, 2006: 417-422.
[17] 王磊, 苗夺谦, 张志飞, 等. 基于主题的文本句情感分析[J]. 计算机科学, 2014, 41(3): 32-35.
TEXT SENTIMENT CLASSIFICATION METHOD BASED ON TOPIC ROLE
Liu Chenchen1Feng Xupeng2Hu Yang1Liu Lijun1Huang Qingsong1,3*Duan Chengxiang4
1(FacultyofInformationEngineeringandAutomation,KunmingUniversityofScienceandTechnology,Kunming650500,Yunnan,China)2(EducationalTechnologyandNetworkCenter,KunmingUniversityofScienceandTechnology,Kunming650500,Yunnan,China)3(YunnanKeyLaboratoryofComputerTechnologyApplications,Kunming650500,Yunnan,China)4(KunmingDiShiTechnologyCo.Ltd,Kunming650000,Yunnan,China)
Traditional text sentiment classification methods usually use vocabulary or phrase as feature of a text vector model which may cause emotion point to unknown or hidden view missing. In order to solve these problems, a text sentiment classification method based on topic role modeling is proposed. The method firstly extracted potential evaluation objects in the text and got the evaluation collection. Then it adopted the LDA model to mining topics for the collection of evaluation objects and divides the topics into two kinds of topic roles with positive polarity and negative polarity. After that, the topic roles would be regarded as feature used to store text emotional information. Finally, it let the tendency value of topic role integrate into feature space to improve the feature weight computation method and establish the topic role model. The experimental results show that the proposed method can efficiently improve the effectiveness and accuracy for text classification compared with other traditional text sentiment classification methods.
Text sentiment classification Potential evaluation objects Latent Dirichlet Allocation (LDA) Topic mining Topic role
2015-11-06。国家自然科学基金项目(81360230)。刘晨晨,硕士生,主研领域:机器学习,文本情感分析。冯旭鹏,硕士生。胡杨,硕士生。刘利军,讲师。黄青松,教授。段成香,工程师。
TP391
A
10.3969/j.issn.1000-386x.2017.01.028
猜你喜欢
通信技术(2021年12期)2022-01-25
计算机系统应用(2021年9期)2021-10-11
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
计算机技术与发展(2018年8期)2018-08-21
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
中国机械工程(2017年22期)2017-12-02
初中生世界·七年级(2017年9期)2017-10-13
中文信息学报(2015年4期)2015-04-21
民族古籍研究(2014年0期)2014-10-27
