
图像检索中的特征表示方法研究
2017-02-23 06:49:46赵俊杰郑兴
现代计算机 2017年2期
赵俊杰,郑兴
(四川大学计算机学院,成都 610065)
图像检索中的特征表示方法研究
赵俊杰,郑兴
(四川大学计算机学院,成都 610065)
研究用于检索的单幅图像的两种特征表示方法,第一种是基于SIFT等传统手工特征点的表示方法;第二种是基于卷积神经网络的特征表示方法。采用CaffeNet和VGG-M两个预训练模型,分别提取它们全连接层和卷积层的输出作为图像的特征。实验表明,对于预训练的模型,最后一层卷积的特征对于检索的效果要好于全连接层的特征。
特征提取;图像检索;卷积神经网络
0 引言
近年来,随着移动互联网的发展,每个人都可以用手机或者平板电脑接入互联网。而手机所具有的拍摄功能使得互联网上每天都会产生巨量的图像和视频数据,如何组织和利用这些海量的图像和视频数据成为了多媒体领域研究的热点问题。CBIR[1](基于内容的图像检索技术)作为一种重要的信息获取方式也越来越受到研究人员的重视。CBIR一般的流程是先将图片转化成某种特征表示形式,然后选取合适的距离度量方式,计算两张图片的相似度,最后排序得到结果。这其中,对于图像的特征表示方法是最为关键的一个环节,直接影响图片检索的准确度。本文主要研究了用于检索目的的特征表示方法,采用传统手工设计的方法和近年来比较流行的深度卷积神经网络技术,并在百万级的商品图片数据集上做了实验分析。
1 传统手工特征表示方法
在传统的特征表示方法中,对于图像特征的提取一般是采用局部特征点,然后再根据所使用的场景来把这些局部特征点组合成特征向量。本文采用的传统的特征表示由词袋模型演变而来,基于SIFT[2]和Color Moment(颜色特征矩)特征,其流程如下:
①对查询集的所有图片依次提取特征点。
②对所有的特征点,采用K-Means方法进行聚类,所有的聚类中心形成一个约10000维的词典。
再对每一幅图像中的特征点,在②中形成的词典上面进行直方图投票,形成该张图片的特征向量。
在上面的流程中,对于每张图片特征点的直方图投票方式解释如下:
①计算该张图片中所有特征点和词典中聚类中心的距离。
②对①中的结果进行排序,选取距离最相近的前4个特征点,并在直方图相应的位置进行累加。形成特征向量。
在上面的流程中,关于向量相似度的距离度量方法,在本文的实验部分讨论。在深度学习技术出现以前,基于内容的图像检索通常都是采用上述特征表示方法,或者词袋模型结合倒排索引的技术来实现。传统方法的优势在于对计算资源的需求较小,模型简单,易于实现和应用,但在检索效果上远不如现在基于卷积神经网络的特征表示方法,本文会在第二小节详细讨论后者。
2 基于卷积神经网络的特征表示方法
2.1 卷积神经网络概述
从2012年AlexNet[3]赢得ImageNet[4]比赛过后,卷积神经网络获得大量研究人员的关注和投入。卷积神经网络是深度神经网络的一种,它和普通神经网络的区别是,它通过局部连接、权值共享等方法来避免传统神经网络采用全连接方式造成参数量巨大的问题。卷积神经网络其特点决定了它非常适合图像处理类问题,使得神经网络的参数在一个可控的范围,能够在现代GPU的计算机能力下高效地训练。
卷积神经网络一般由卷积层、Pooling(池化)层、全连接层等基本结构构成。本文采用了CaffeNet(AlexNet的复制[5])、VGG-M[6]两种模型在深度学习框架Caffe[7]上进行了实验,它们的结构如图1所示。
VGG-M和CaffeNet都是五层卷积再加上三层全连接的结构,图中96x11x11表示卷积核的数量为96,卷积核大小为11x11,St和pad分别表示参数stride(间隔)和padding(填充)。max-pooling和avg-pooling是两种pooling方式,前者的含义是取pooling窗口中的最大值,后者则是计算pooling窗口的平均值。
2.2 CNN特征提取方法
本文所使用的两种模型都是在ImageNet数据集上的预训练好的模型。特征提取方式是直接把每一层的输出当作该张图片的特征向量,分别提取了fc7,fc6, conv5,conv4的特征并做了相应的实验。其中fc6,fc7两层的特征维数不高为4096,可以直接使用。而卷积层的输出维数过高,本地的实验环境无法存储和计算,因此在卷积层后面添加了pooling层来进行降维处理。
pooling层使用了上文介绍的两种方式,max和avg。以Caffe的配置形式表示为:

上面两层的含义是在pool5层后面再接上了两层分别为3×3和4×4的max-pooling,stride都为1,最后pool6_4×4层输出的维度为2304。本文还讨论了pooling的大小,以及两种pooling方式得到的特征向量对检索精度的影响。
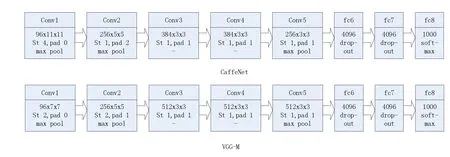
图1
3 实验部分
3.1 实验数据和评测标准
本文使用了淘宝的商品数据集,训练集为200W,验证集为300W,并给定了1500张查询图片和对应的ground truth。训练集中的图片都具有两级标签,和多种属性,但是这些标签和属性极度不均衡,对于检索问题的参考意义不大。曾使用这些标签和属性对CaffeNet进行fine-tune,然后提取特征再检索,效果反而下降。
对于检索结果,使用MAP值来决定。MAP(Mean Average Precision)是反映图像检索系统在全部相关query上的准确度指标。MAP的值由两个因素决定:检索结果中同款图的数量和同款图片在检索结果中的位置。同款图的数量越多且位置越靠前,MAP的值就越搞。如果检索结果中没有任何一个同款图,则值为0。平均准确率AP(Average Precision)定义为:

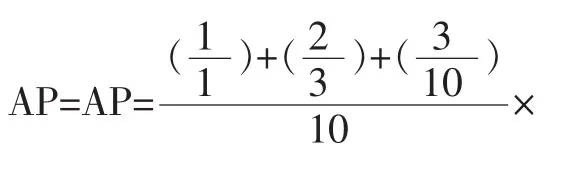
整个检索框架的基本流程是,先计算每一张的图片的特征向量,然后计算特征向量之间的距离,然后排序。本文使用Cosine Similarity(余弦距离)[8]来衡量相似度,实验表明余弦距离在衡量图像相似度方面,要优于欧氏距离。
3.2 手工特征实验
本文尝试了SIFT特征、color moment特征以及它们的融合特征。实验的结果均不及基于卷积神经网络的特征,所得到的最好MAP值大约为0.11左右。尝试过如下的方案:1.纯SIFT特征;2.纯color moment特征;3.SIFT和CNN特征的融合。
从实验的结果来看,SIFT特征对于带有文字等这类棱角分明的图片的检索效果十分显著,color moment特征对于颜色的敏感度非常高,结果图片在颜色上与查询图片保持高度的一致。手工特征方法的检索效果很大程度上依赖于选取特征的性质,而这些性质大多都是局部性的,很难体现出一张图片整体的语义。本文还尝试了CNN的特征与SIFT特征的融合实验,在这种实验方案下,MAP值有轻微的提升,不明显。从结果来看,SIFT的加入,使部分检索图像的细节点上更加准确,符合预期。由于手工特征方法的效果远不如基于CNN的特征,本文没有再继续尝试其他局部特征方法。
3.3 卷积神经网络特征实验
如前文所述,基于CNN的特征实验采用了CaffeNet和VGG-M这两种预训练模型,所得到的全部结果实验结果由表1和表2所示:

表1
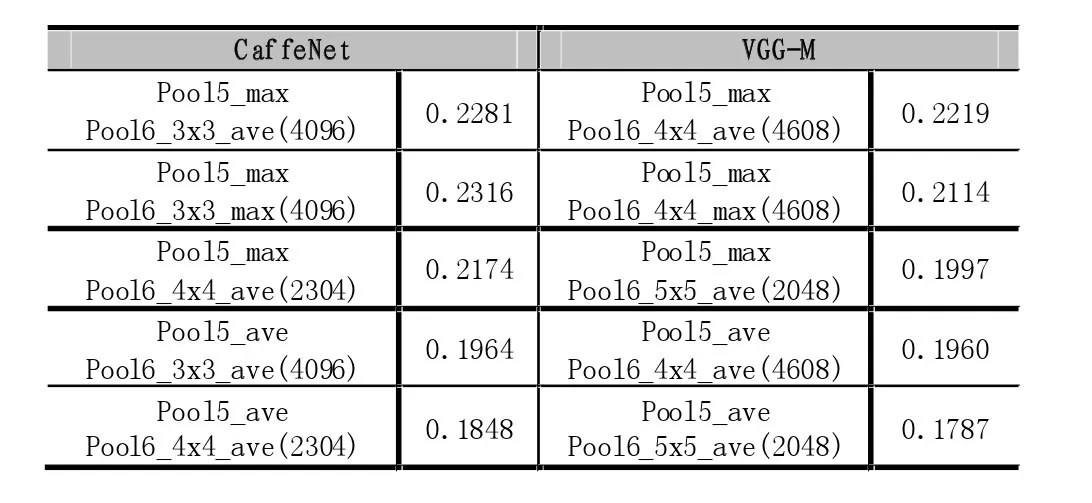
表2
表1中,pool5_max表示在pool5之后再加一个max-pooling来,pool5_ave同理是在pool5之后再加一个ave-pooling。单独从这两项的结果来看,两种方式对于检索的效果,max要优于average。这可能是由于数据中存在噪声,max在pooling窗口中取最大值一定程度上起到了去除噪声的作用,使得特征向量的判别性得到增强,从而提升了MAP值。同时,我们也试验了conv4的特征,由于pool4层的特征维数过高,我们使用两层pooling来降维,即Pool4_ave_ave,它在pool4后面接了两层ave-pooling,所得到MAP值低于conv5的特征。从表1的实验数据中,我们可以得出结论:从全连接层开始,越往前面的特征对于检索问题的效果越好,一直到最后一层卷积。
在表2中,又进一步试验了将conv5分别降维到4000和2000进行了实验。Pool6_3×3_max表示在pool5_max之后再加了一层3×3的pooling层,其他的同理。从实验的数据来看,降维到4000左右的结果最好,再进一步pooling,由于信息的损失较大,结果反而会降低。
从前面的数据中,我们可以得出下面两个基本的结论,在预训练的模型下,对于检索问题:
最后一层卷积输出的特征对于检索的效果最好。
pooling的方式对最终结果的影响很大,max-pooling要优于ave-pooling。
对于第一点,本质上,由于预训练的模型的目标是分类,而并不是检索的排序,因此造成了卷积层的特征还要优于全连接层的特征。同时,由于卷积层的特征一定程度上还包含了图像的空间位置信息[9],而全连接层则损失了这一信息。对于第二点,本文仅仅采用了简单的pooling作为降维方式,结果就有了显著的提升,说明在降维的方法上面,还有很大的提升空间。可以进一步采用更复杂的pooling方式,或者采用主成分分析等成熟的方法去提升检索效果。
4 结语
本文主要讨论了基于内容的图像检索框架中,单张图像的特征表示的两种方法。基于手工特征的表示方法受限于原有局部特征点的性质,难以提升效果。基于卷积神经网络的特征表示方法效果远胜于前者,而且有较大的提升潜力。在未来的工作中,我们还可以从以下方面进行改进和优化:第一,本文使用两种预训练模型,优化目标是分类,我们可以进一步使用learning to rank[10]的技术对模型进行fine-tune;第二,如前文所述,我们可以采用更复杂pooling方式配合PCA、LDA等方法进行各层特征的降维处理。第三,对于图像检索问题而言,查询图像往往包含了很多不相关的信息,我们还可以采用一些目标检测技术来突出重要内容,这样可以进一步提升检索效果。
[1]基于内容的图像检索.https://zh.wikipedia.org/wiki/.
[2]Lowe,David G.Distinctive Image Features from Scale-Invariant Keypoints.International Journal of Computer Vision 60.2(2004):91-110.
[3]Krizhevsky,Alex,Ilya Sutskever,Geoffrey E.Hinton.Imagenet Classification with Deep Convolutional Neural Networks.Advances in Neural Information Processing Systems,2012.
[4]Russakovsky,Olga,et al.Imagenet Large Scale Visual Recognition Challenge.International Journal of Computer Vision 115.3(2015): 211-252.
[5]https://github.com/BVLC/caffe/tree/master/models/bvlc_reference_caffenet.
[6]Chatfield,Ken,et al.Return of the Devil in the Details:Delving Deep into Convolutional Nets.arXiv Preprint arXiv:1405.3531(2014).
[7]Jia,Yang-qing,et al.Caffe:Convolutional Architecture for Fast Feature Embedding.Proceedings of the 22nd ACM International Conference on Multimedia.ACM,2014.
[8]https://en.wikipedia.org/wiki/Cosine_similarity.
[9]Zeiler,Matthew D.,Rob Fergus.Visualizing and Understanding Convolutional Networks.European Conference on Computer Vision. Springer International Publishing,2014.
[10]Faria,Fabio F.,et al.Learning to Rank for Content-Based Image Retrieval.Proceedings of the International Conference on Multimedia Information Retrieval.ACM,2010.
Research on Feature Representation in Content-based Image Retrieval
ZHAO Jun-jie,ZHENG Xing
(College of Computer Science,Sichuan University,Chengdu 610065)
Studies two kinds of feature descriptors for content based image retrieval.The first one uses hand craft features like SIFT feature,the second is based on Convolutional Neural Network.Uses two pre-trained model,CaffeNet and VGG-M,extracts feature descriptors from the fully connection layers and convolution layers.Experiments show that the last convolution layer can achieve better results than other layer including fully connection layer.
Feature Extraction;Image Retrieval;Convolutional Neural Network
1007-1423(2017)02-0067-05
10.3969/j.issn.1007-1423.2017.02.017
赵俊杰(1994-),男,四川广元人,硕士研究生,研究方向为机器学习、多媒体计算
2016-11-01
2016-12-30
郑兴(1991-),男,重庆潼南人,硕士研究生,研究方向为数据挖掘
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
电子制作(2019年11期)2019-07-04 00:34:38
许昌学院学报(2018年4期)2018-05-02 12:27:37
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中华建设(2017年1期)2017-06-07 02:56:14
专利代理(2016年1期)2016-05-17 06:14:36
电视技术(2014年19期)2014-03-11 15:38:20
