
微博演化网络的负信息分类方法*
2017-01-18 08:15何克清黄贻望
计算机与生活 2017年1期
赵 一,何克清,李 昭,黄贻望
1.武汉大学 计算机学院 软件工程国家重点实验室,武汉 430072
2.三峡大学 计算机与信息技术学院,湖北 宜昌 443002
微博演化网络的负信息分类方法*
赵 一1,何克清1,李 昭2+,黄贻望1
1.武汉大学 计算机学院 软件工程国家重点实验室,武汉 430072
2.三峡大学 计算机与信息技术学院,湖北 宜昌 443002
ZHAO Yi,HE Keqing,LI Zhao,et al.Micro blog evolutionary network to classification method of negative information.Journal of Frontiers of Computer Science and Technology,2017,11(1):91-98.
序列最小优化(SMO);支持向量机(SVM);演化网络;UCI数据集;负信息
1 引言
随着Web2.0的兴起,不仅是电子邮件成为人们生活中不可缺少的部分,微博和微信等也成为人们彼此交流的主要工具。自从2006年Williams创建了Twitter以来,微博对整个互联网产生了巨大的影响。据美国财经杂志《商业周刊》称,Twitter已经成为世界最大同时也是信息速度传递最快的虚拟社区,拥有着超乎想象的社会和政治影响力。信息交流主要是通过关注和转帖等互动形式来进行,因此用户消息会在Twitter中呈几何级数增长,并在用户间迅速传播。而信息的多元化也将影响到未来社会和政治的发展[1]。因此微博这样一个互联网新生事物已经成为文本挖掘、网络舆情分析与垃圾信息处理等重要研究方向[2]。以SNS(social networking services)和微博为代表的Web2.0应用占整个互联网流量的比重越来越高,它们与互联网用户的联系越来越密切,网民花费大量的时间上网,主要集中在SNS网站(如人人网、开心网)和发布微博(新浪微博、腾讯微博、搜狐微博等),但是有用数据中夹杂着众多的无用信息或者是有危害的信息,从而它对互联网上人们的影响日趋增强。因此对微博进行分类在用户个性化推荐、微博社群以及垃圾信息过滤中都至关重要。而有些微博属于长文本,有些微博属于短文本,包含各式各样的信息量,传统的文本分类方式并不能很好地用在微博上。目前主流的分类垃圾信息的方法有以下几种:第一种是利用Navie Bayes[3](后验概率)计算特征所属空间的概率,取其最大者为判定结果。它通过训练数万封电子邮件内容,包含垃圾邮件/非垃圾邮件,提取邮件内单词,输入字典,过滤出现设定次数的单词,具体公式为:
式(1)中p表示概率;ϖ表示所属类别。然后定义probSPAM=probHAM=1,完成4步统计后,两个prob变量分别乘以对应类别的邮件数,然后除以所有邮件总数,即得到Prior。比较probSPAM和probHAM,如果probSPAM大就分到垃圾信息类,如果probHAM大就分到正常信息类。但是此方法对信息分类太过于考虑一个词汇的垃圾性,如果垃圾信息发送者插入通常与垃圾邮件无关的随机无害词,从而降低电子邮件的垃圾邮件分数,使得它更有可能在Prior值上更接近于正常信息。
近年来,有关短文本分类及应用的研究不断推出很多新的方法,并已经成为自然语言领域和文本挖掘的一个热点研究课题。同时,在很多知名的国内外会议和期刊上都有这方面的论文发表。其中,有使用LDA(latent Dirichlet allocation)聚类来找到同一主题的类别[4],这种使用聚类的方法缺点是无法准确定义类簇。比如文献[5]提出了两类垃圾评论的类型:(1)显式垃圾评论;(2)隐式垃圾评论。文章虽然利用LDA找出了隐藏的垃圾评论,扩大了垃圾评论的范围,但是因为作者使用一般的LDA模型,所以对topic话题个数K取值无法明确分出话题个数,它能否代表准确的垃圾评论类别是值得深入研究的。但是LDA聚类缺点是如果处理短文本,比如特征稀疏的评论处理,聚类效果就会打折扣。另外,当发现整个博客垃圾评论后,并不能及时地控制整个网络的传播路径,因此要想准确地定位垃圾评论最有效的方法还是对评论文本进行分类,日前只能利用机器学习的方法分辨出垃圾邮件以及它们的特征。
文献[6]试图通过对微博平台上广告传播的分析,发现微博广告传播的模式特征;并且收集了一些广告信息的传播数据,将每条信息的传播途径用一个传播树表示;针对每个传播树,共提取了包括传播参与者的数量、传播途径的拓扑结构和时间的传播特征3个方面共33个特征,并使用K-Means聚类算法对这些传播树进行了聚类,验证了名人效应在信息传播中的推动作用,从而证明了网络微博的传播网络不是随机网络结构。但是文章中并没有对微博拓扑结构随时间变化进行验证,也没有提出有效的控制垃圾广告软件传播的防御机制,说明微博垃圾信息处理与管理在国内大数据信息化研究中是一个亟待解决的问题。基于以上需求本文主要解决了垃圾信息分类问题和跟踪垃圾信息发送者ID,依据微博转发形成的演化网络,从源头隔离垃圾发送者。第2章主要介绍了一些相关准备工作;第3章介绍本文的核心算法——基于SMO(sequential minimal optimization)的SVM(support vector machine)垃圾信息的分类算法,并对UCI数据集构建演化网络模型,利用SVM分类算法找出垃圾信息发送者,并根据演化网络结构,在关键节点标记垃圾发送者ID,并根据转发内容是否为垃圾信息,来判定是否应该隔离它;第4章是实验流程以及结果分析和验证;最后,总结全文并计划下一步的工作。
2 UCI数据集以及分类
2.1 UCI新浪微博数据集
UCI数据库是CaliforniaIrvine大学提出的用于机器学习的数据库[7],这个数据库在2015年5月进行了更新,新增了各行各业的数据集12个,加上原来数据库的200多个数据集,基本覆盖知识领域。每个数据文件(*.data)包含以“属性-值”对形式描述的很多个体样本的记录。对应的*.info文件包含大量的文档资料。
本文数据集来源UCI官网[8],2015年3月17日更新。此数据集提供者爬取新浪微博,这些数据适合用于研究和学习,以及做一些社会网络研究。其中weibo_user.csv文件描述属性如下:user_id是新浪微博用户ID;user_name是账户昵称;account registration gender包括男和女;class是微博账户等级;message是账号注册地点或其他个人信息;post_num是到现在为止发帖数量;follower_num是此账号微博粉丝的数量;followee_num是此账号关注过的微博;follow ratio是博客A关注过微博数/A关注的微博;is_spammer是手动标注标签,1指垃圾信息发送者,0指正常信息发送者。user_post.csv文件描述属性如下:post_id是发新浪微博的用户ID;微博发送的时间;微博帖子接收者ID;repost_num是帖子通过别人的转发数。Commnet_num是别人评论的次数。followefollowee.csv文件描述属性如下:follower是粉丝(关注者)的昵称;follower_id是粉丝的ID;followee是关注的微博昵称;followee_id是关注的微博ID。
2.2 构造演化网络
通过以上分析,可以得出,如果微博用户A的帖子被用户B转发,记为eAB;或者微博用户A的帖子被用户B关注,记为eBA。最终构成无向图,记为G(V,E)。边权[9]是网络中用来衡量节点A和节点B共享的边的关联度大小的量,记A转发B的次数即出度为repost_num,B发给A的次数即入度为post_num;N=repost_num+post_num。则A和B链接的权重构建出新浪微博社交网络中具有互粉关系[10]的无向权重图G′=(V,E)。
依据UCI新浪微博数据集,得到所构建的复杂系统拥有共同的重要特性:大部分节点只有少数几个链接,而某些节点却拥有与其他节点的大量链接。这些具有大量链接的节点称为“集散节点”,从图1可知,“集散节点”所拥有的链接数可能高达数百、数千甚至数万,由此得出,这一特性似乎能说明新浪微博的演化网络是无尺度的。从而也会拥有无尺度网络具有的某些重要特性,比如它们都可以承受意外的故障,但面对协同式攻击却很脆弱。
由于篇幅所限,本文提供的新浪微博演化网络图,只是随机抽取用户昵称节点,并且使用Gephi工具画出UCI数据集中用户的帖子转发关系图。从中可以看出,演化网络中存在着一些“集散节点”,比如“新百伦商城”,“孚禾静静_”“积奇薄荷少女怀亦”,“手机用户1779439745”等。图1中也有一些离散的节点,这些用户只发过微博,出度和入度都为0,比如“IT经济学”“战刀_骑士”等孤立节点,转发关系和出度与入度可以清晰观测。
2.3 中文分词算法
对用户帖子内容的分词,本文使用的是改进的中科院中文分词算法[11]。本文举例“新百伦商城”和“孚禾静静_”,对微博帖子的分词改进效果如表1所示。
两位微博用户发帖,对帖子正文进行分词。从表1中可以得出,使用改进后的分词算法可以在几次迭代运算识别出准确的名词,并且能够识别出符号中的特有名词,如[]中的“奥汀羽酵素反馈”名词。
2.4 SMO SVM模型
本文分析博客所发帖子是否为垃圾信息的分类算法选用的是SMO优化算法[12],该算法是Platt在1998年提出,被认为是很快的二次规划优化算法,对线性SVM和数据稀疏能更好地处理。SMO SVM模型已经成功应用到文本分类、信息检索等诸多文本相关的领域[13-14]。图2为SMO SVM模型算法流程。
Fig.1 Evolving network user of forwarding relationship图1 用户转发关系的演化网络
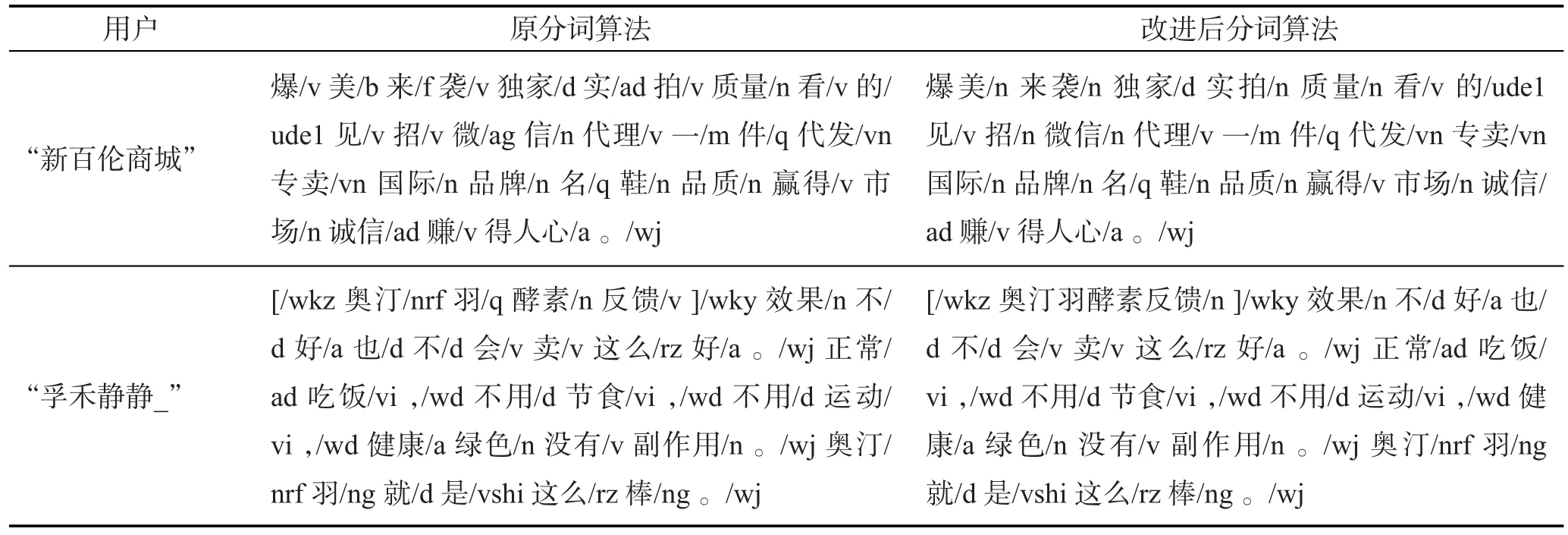
Table 1 Improved Chinese word segmentation method表1 改进中文分词法
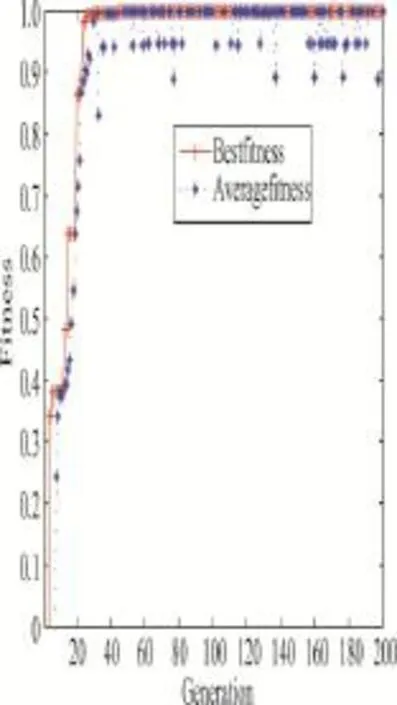
Fig.2 SMO SVM model algorithm图2 SMO SVM模型算法
SMO SVM需要把文本信息分为有用文本和负面文本,该问题是基本的线性可分。
如果用x表示数据点,用y表示类别(y取值可以为1或者-1),分解方程可以表示为:

根据文献[9]得知,
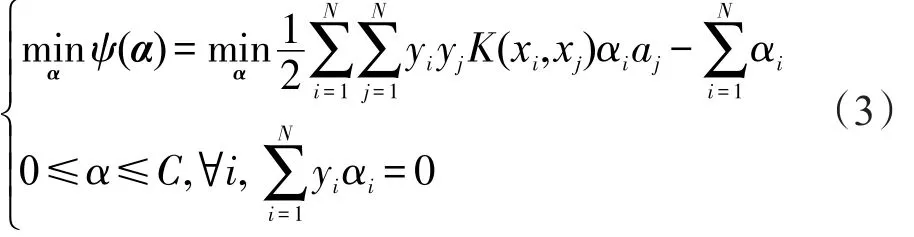
当SVM模型建立完成后,第3章将详细描述本文如何对UCI数据集文本进行分类。
3 SMO SVM模型分类
3.1 特征抽取
本文认为负面信息可以通过情感词典来辅助抽取特征项,利用情感词典HowNet[15]作为基础词表,并融入当今热点网络流行情感词汇构成的新情感词典,例如“代理产品”、“减肥产品”等,具有明显特征色彩的词汇,用于筛选出这些关键词语。
针对UCI用户发送帖子进行预处理后只留下了名词、动词、形容词,这些带有特征的词汇,设正面信息记为POS,负面信息记为NEG,再进行特征提取,其步骤如下。
(1)计算每个词特征t的观测值:
A为包含t且属于POS的文本个数。
B为包含t且属于NEG的文本个数。
C为不包含t且属于POS的文本个数。
D为不包含t且属于NEG的文本个数。
(2)对每个特征t计算它的卡方值x2:

(3)取x2排序前5个值作为t的特征项。
训练集的建立,以“新百伦商城”用户为例,他发布了一条微博,其内容包括“专卖”词汇,则“专卖”属于正面类别的文档数为2篇,包含“专卖”属于负面类别的文档数为10,不包含“专卖”,却属于正面文档数为12,既不包含“专卖”又不属于正面文档数为8。代入式(4)中可以得到卡方验证的值,然后生成SVM分类的特征数据。
3.2 用户节点屏蔽
通过上述分析,判断当前用户所发信息是否属于负面信息,如果是负面信息则屏蔽用户。从图1可以知道,“新百伦商城”用户是一个集散节点,他与另外一个集散节点“积奇薄荷少女怀亦”互粉过,从分类结果得知,“新百伦商城”是一个负面信息发送者,他所发微博基本被分到负面类中,而“积奇薄荷少女怀亦”是一个主要发送正面信息为主的用户。正是因为这种原因,他们的follower(粉丝)众多。本文引入演化网络方法,并结合SMO SVM分类算法,能够准确地分辨谁是负面信息(主要以广告信息为主)的发送者,因此屏蔽了“新百伦商城”,如图3所示。
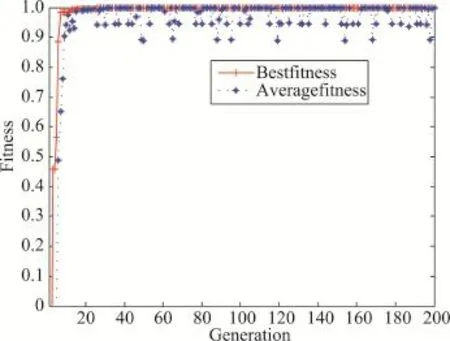
Fig.3 Evolving network after SVM classifying图3 SVM分类后生成的演化网络
从图3中可以看到“新百伦商城”和“积奇薄荷少女怀亦”节点已经过处理,屏蔽了“新百伦商城”。可以自动完成负面节点边的删除,从而实现对负面信息来源的屏蔽功能。
算法1演化网络分类算法


4 实验结果及验证
本文实验数据全部来源于“2015年UCI自然语言处理和机器学习”提供的测评数据集,它包含142 369位用户,发布近20万篇帖子。测评数据以CVS格式存储,总数据大小为27.2 MB。
本文对测试数据分别进行3种方法的实验,包括现在流行的负面信息分类法贝叶斯分类法、SVM分类法、SMO SVM分类法[16]。
在对SVM分类方法的有效性进行评估时,本文使用的评估指标是准确率(Precision)、召回率(Recall)、F值(F-measure)。对SVM分类法与SMO SVM分类法的分类情况进行人工观测。
通过图4和图5得知,针对二分类数据(微博负面信息数据集),SMO SVM分类算法比一般的SVM分类算法要更加准确。图中红色点代表微博中的负面信息,蓝色点代表微博中的正面信息,褐黄色点代表未知准确分类信息。图4使用SMO SVM分类算法,其中只有6个点的文本特征没有准确分类。图5使用SVM分类算法,可以得知,未分类的褐黄色点有8个,这比SMO算法效率要低20%左右。
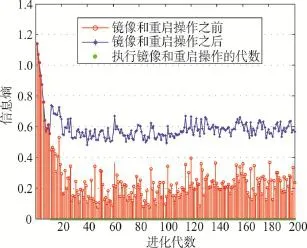
Fig.4 SMO SVM classification algorithm图4 SMO SVM分类算法
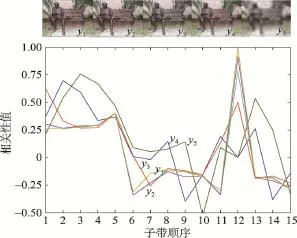
Fig.5 SVM classification algorithm图5 SVM分类算法
从图6中可以知道,对于微博短文本SMO SVM算法在倾向于负面信息的文本分词上性能有一定的提高,它较前两个方法都有较高的正确率、召回率、精度值。
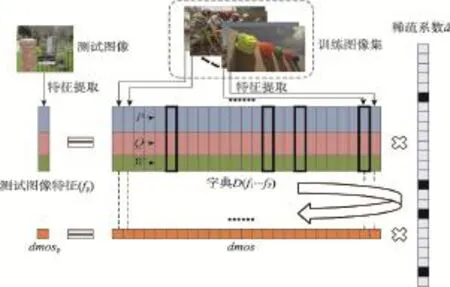
Fig.6 Distinguish results of negative information图6 负面信息识别结果
实验表明,基于UCI数据集的SMO SVM分类算法结合用户转发微博连接的演化网络分类方法,能够有效地分辨微博用户发帖子的性质,如果该用户所发帖子为正面信息,则不屏蔽该贴,若是用户发送负面信息,如广告、谣言等信息时,能立刻分辨出,并且屏蔽用户。
5 结论及展望
本文以UCI最新微博数据集为实验基础,使用卡方验证抽取特征向量,并使用SMO SVM算法与贝叶斯和SVM分类算法在处理二分类问题上进行比较。最后在正确率、召回率、F值方面对以上3种算法进行比较,得到SMO SVM检测负面信息文本有较高的准确率,并且能提供更好的微博屏蔽效果。下一步工作,将完善情感词典,改进SMO SVM算法,来提高自动识别新兴词汇,加强短语样本的学习,继续优化特征向量的选取,加强实时数据爬取,希望能做到实时监控用户发送信息等功能。
[1]Bowles C.TwitterCore data library team Hadoop optimization experience[EB/OL].Twitter Job Bole[2015-07-02].http:// blog.jobbole.com/88283/.
[2]Peng Xixian,Zhu Qinghua,Liu Xuan.Research on behavior characteristics and classification of micro-blog users-taking“Sina Micro-blog”as an example[J].Information Science, 2015,33(1):69-75.
[3]Hui Bei,Wu Yue.Anti-spam model based on semi-naïve Bayesian classification model[J].Journal of Computer Applications,2009,29(3):903-904.
[4]Wang Peng,Gao Cheng,Chen Xiaomei.Research on LDA model based on text clustering[J].Information Science, 2015,33(1):63-68.
[5]Diao Yufeng,Yang Liang,Lin Hongfei.LDA-based opinion spam discovering[J].Journal of Chinese Information Processing,2011,25(1):41-47.
[6]Chen Xiao,Huang Shuguang,Qin Li.Social network model based on micro-blog transmission[J].Journal of Computer Applications,2015,35(3):638-642.
[7]Li Dahua.Probability model and computer vision[EB/OL]. MIT Courser[2015-07-02].http://www.sigvc.org/bbs/thread-165-1-1.html.
[8]Sina mirco-blog.UCI data sites[EB/OL].(2015-03)[2015-07-02].http://www.archive.ics.uci.edu/ml.
[9]Kernighan B W,Lin S.An efficient heuristic procedure for partitioning graphs[J].Bell System Technical Journal,1970, 49(2):291-307.
[10]Zhao Yi,He Keqing,Chen Jingliang,et al.Evolution knowledge tree for services computing domain in Wikipedia[J].Journal of Wuhan University:Natural Science Edition,2015,61 (4):331-338.
[11]Plantt J C.Sequential minimal optimization:a fast algorithm for training support vector machines,MSR-TR-98-14 [R].Microsoft Research,1998.
[12]Han Zhongming,Zhang Hui,Xie Xiaomeng.Effective sentiment classification method based on SVM for microblogging text[D].Beijing:Beijing Technology and Business University,2013.
[13]Yang Chao,Feng Shi,Wang Daling,et al.Analysis on Web public opinion orientation based on extending sentiment lexicon[J].Journal of Chinese Computer Systems,2010,31 (4):44-49.
[14]Ding Jianli,Ci Xian,Huang Jianxiong.Orientation analysis of Web reviews[J].Journal of Computer Applications,2010, 30(11):2937-2940.
[15]Wang Zhenyu,Wu Zeheng,Hu Fangtao.Words sentiment polarity calculation based on HowNet and PMI[J].Computer Engineering,2012,38(15):187-193.
[16]Li Yingle,Yu Hongtao,Liu Lixiong.Predict algorithm of micro-blog retweet scale based on SVM[J].Application Research of Computers,2013,30(9):2594-2597.
附中文参考文献:
[2]彭希羡,朱庆华,刘璇.微博客用户特征分析及分类研究——以“新浪微博”为例[J].情报科学,2015,33(1):69-75.
[3]惠孛,吴跃.基于不完全朴素贝叶斯分类模型的垃圾邮件分类模型[J].计算机应用,2009,29(3):903-904.
[4]王鹏,高铖,陈晓美.基于LDA模型的文本聚类研究[J].情报科学,2015,33(1):63-68.
[5]刁宇峰,杨亮,林鸿飞.基于LDA模型的博客垃圾评论发现[J].中文信息学报,2011,25(1):41-47.
[6]陈骁,黄曙光,秦李.基于微博转发的社交网络模型[J].计算机应用,2015,35(3):638-642.
[10]赵一,何克清,陈荆亮,等.面向维基百科服务计算领域的演化知识树[J].武汉大学学报:理学版,2015,61(4):331-338.
[12]韩忠明,张慧,解筱梦.基于SVM的微博文本情感倾向性识别[D].北京:北京工商大学,2013.
[13]杨超,冯时,王大玲,等.基于情感词典扩展技术的网络舆情倾向性分析[J].小型微型计算机系统,2010,31(4):44-49.
[14]丁建立,慈祥,黄剑雄.网络评论倾向性分析[J].计算机应用,2010,30(11):2937-2940.
[15]王振宇,吴泽衡,胡方涛.基于HowNet和PMI的词语情感极性计算[J].计算机工程,2012,38(15):187-193.
[16]李英乐,于洪涛,刘力雄.基于SVM的微博转发规模预测方法[J].计算机应用研究,2013,30(9):2594-2597.

ZHAO Yi was born in 1984.He is a Ph.D.candidate at Computer School,Wuhan University,and the member of CCF.His research interests include service computing,software engineering and complex network,etc.
赵一(1984—),男,湖北荆门人,武汉大学计算机学院博士研究生,CCF会员,主要研究领域为服务计算,软件工程,复杂网络等。

HE Keqing was born in 1947.He is a professor at Wuhan University,and the member of CCF.His research interests include service computing,software engineering and complex network,etc.
何克清(1947—),男,湖北武汉人,博士,武汉大学教授,CCF会员,主要研究领域为服务计算,软件工程,复杂网络等。

LI Zhao was born in 1986.He is a lecturer at College of Computer and Information Technology,Three Gorges University.His research interests include service computing,software engineering and complex network,etc.
李昭(1986—),男,湖北宜昌人,博士,三峡大学计算机与信息技术学院讲师,主要研究领域为服务计算,软件工程,复杂网络等。

HUANG Yiwang was born in 1978.He is an associate professor at Computer School,Wuhan University,and the member of CCF.His research interests include service computing,business process management and formal method,etc.
黄贻望(1978—),男,湖南怀化人,博士,武汉大学计算机学院副教授,CCF会员,主要研究领域为服务计算,业务流程管理,形式化方法等。
Micro Blog Evolutionary Network to Classification Method of Negative Information*
ZHAO Yi1,HE Keqing1,LI Zhao2+,HUANG Yiwang1
1.State Key Laboratory of Software Engineering,Computer School,Wuhan University,Wuhan 430072,China
2.College of Computer and Information Technology,Three Gorges University,Yichang,Hubei 443002,China
+Corresponding author:E-mail:zhaoli@ctgu.edu.cn
Aiming at the relationship of the Sina micro blogging,this paper establishes the evolving network by user's transmit blog,which classifies blog by SMO SVM(sequential minimal optimization support vector machine)algorithm,and implements the classification of malicious posts,spam,trash marketing information.The method enables users to accurately block the unwanted posts and blogger.The first step,classifying the entire Sina micro blogs based on the evolving network of transmit relationship and SVM classification algorithm;The second step,annotating the bloggers of often sending malicious advertisements by using the complex network technology;When the malicious bloggers sending message,blocking them in the network;Finally,finding out the source of spam,and discerning the blogger malicious or not,on the macro to better curb the spread of spam.The results of this paper are compared with user feedback actual situation from the UCI data set,the experimental results of machine learning classification reaches 89%.
sequential minimal optimization(SMO);support vector machine(SVM);evolutionary network;UCI data set;negative information
A
:TP393.092
10.3778/j.issn.1673-9418.1509090
*The National Basic Research Program of China under Grant No.2014CB340401(国家重点基础研究发展计划(973计划)).
Received 2015-08,Accepted 2015-10.
CNKI网络优先出版:2015-10-30,http://www.cnki.net/kcms/detail/11.5602.TP.20151030.1618.004.html
摘 要:针对Sina微博博文的转发关系,建立起用户转发博文之间的演化网络,从而利用SMO SVM(sequential minimal optimization support vector machine)分类算法对博文进行分类,筛选出恶意博文、垃圾广告、垃圾营销信息,使用户能够精确地屏蔽不想要的博文和博主。第一步基于微博转发关系的演化网络和SVM分类算法对整个Sina微博进行分类;第二步利用复杂网络等技术对经常发送恶意广告的博主进行标注,从而在网络中对他们进行屏蔽;最后找出垃圾信息的来源以及分辨出博主是不是恶意转发者,在宏观上能更好地遏制垃圾信息的传播。与用户从UCI数据集中实际反馈情况进行比较,实验结果表明,机器学习分类的实验结果吻合度达到89%。
猜你喜欢
科普童话·学霸日记(2021年2期)2021-09-05
数学小灵通(1-2年级)(2021年4期)2021-06-09
当代陕西(2019年24期)2020-01-18
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
能源(2018年8期)2018-09-21
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
小太阳画报(2018年10期)2018-05-14
知识窗(2017年12期)2018-01-02
初中生世界·七年级(2017年9期)2017-10-13
中国新时代 (2011年7期)2011-02-05
