
基于KNN?SVM的垃圾邮件过滤模型
2017-01-12 09:28林荫
现代电子技术 2016年23期
林荫

摘 要: 垃圾邮件具有特征维数高、样本不平衡等特点,针对近邻算法(KNN)或支持向量机(SVM)存在虚警率高等难题,基于组合优化理论,提出基于KNN?SVM的垃圾邮件过滤组合模型。首先提取垃圾邮件的特征项,并构建垃圾邮件过滤模型的输入向量,然后采用KNN对垃圾邮件训练样本进行选择,将训练样本缩减到k个,并采用支持向量机对[k]个样本训练和建模进行垃圾邮件过滤,最后采用中文邮件集对KNN?SVM的性能进行分析。结果表明,KNN?SVM提高了垃圾邮件过滤的准确率,大幅度降低了虚警率,而且垃圾邮件的过滤速度可以满足邮件处理的在线需求。
关键词: 垃圾邮件; 模式识别提取; K近邻算法; 特征提取
中图分类号: TN915.08?34; TP393 文献标识码: A 文章编号: 1004?373X(2016)23?0090?03
Spam mail filtering model based on K nearest neighbor algorithm
and support vector machine
LIN Yin
(Changzhou University Huaide College, Changzhou 213016, China)
Abstract: The spam mail has the characteristics of high feature dimension, unbalance sample, etc. To overcome the high false alarm rate existing in K nearest neighbor (KNN) algorithm or support vector machine (SVM), a spam mail filtering combination model based on KNN?SVM is proposed according to the combinatorial optimization theory. The feature items of spam mail are extracted to construct the input vector of the spam mail filtering model. And then the KNN algorithm is used to select the training samples of spam mail, so as to reduce the quantity training samples to k. The support vector machine is used to train and model the k samples for spam mail filtering. The Chinese mail set is used to analyze the performance of KNN?SVM. The results show that the KNN?SVM based model improved the accuracy of spam mail filtering, reduced the false alarm rate greatly, and the filtering speed of spam mail can meet the online demand of mail processing.
Keywords: spam mail; pattern recognition and extraction; K nearest neighbor algorithm; feature extraction
0 引 言
电子邮件(Email)是包含文字、图像、视频的特殊文本,已经成为网络上交流、沟通的工具[1]。大量统计与研究报告表明,垃圾邮件占了全世界邮件的50%以上,对人们生活、工作带来了干扰,而且浪费了大量的网络带宽[2]。提高垃圾邮件过滤的准确率,保证信息安全,引起了人们的广泛关注[3]。
垃圾邮件过滤的实质是对邮件进行分类,将其识别为合法邮件或者垃圾邮件,若为垃圾邮件则过滤掉,否则让其通过[4]。垃圾邮件过滤是一种分类问题,分类器的构建直接影响过滤效果,当前常采用K近邻算法(K Nearest Neighbor Algorithm,KNN)和支持向量机(Support Vector Machine,SVM)[5?7]建立垃圾邮件过滤的分类器,对于英文邮件,它们获得了理想的过滤效果,垃圾邮件过滤的虚警率低[8]。对于中文邮件,过滤效果却很差,这是因为中文垃圾邮件是一种超文本,不仅具有一般文本的特征,而且样本极不平均、特征维数高,采用KNN进行处理,易出现“维数灾”难题,过滤速度慢;SVM虽然不存在“维数灾”难题,但是对于大规模垃圾邮件,训练时间长,无法满足垃圾邮件在线过滤要求[9?11]。
为了提高垃圾邮件过滤的准确率,加快垃圾邮件的过滤速度,提出了KNN?SVM的垃圾邮件过滤组合模型,并采用中文邮件数据集对KNN?SVM的性能进行测试,以验证其有效性,同时与当前经典垃圾邮件过滤模型进行对比分析,验证其优越性。
1 提取邮件特征
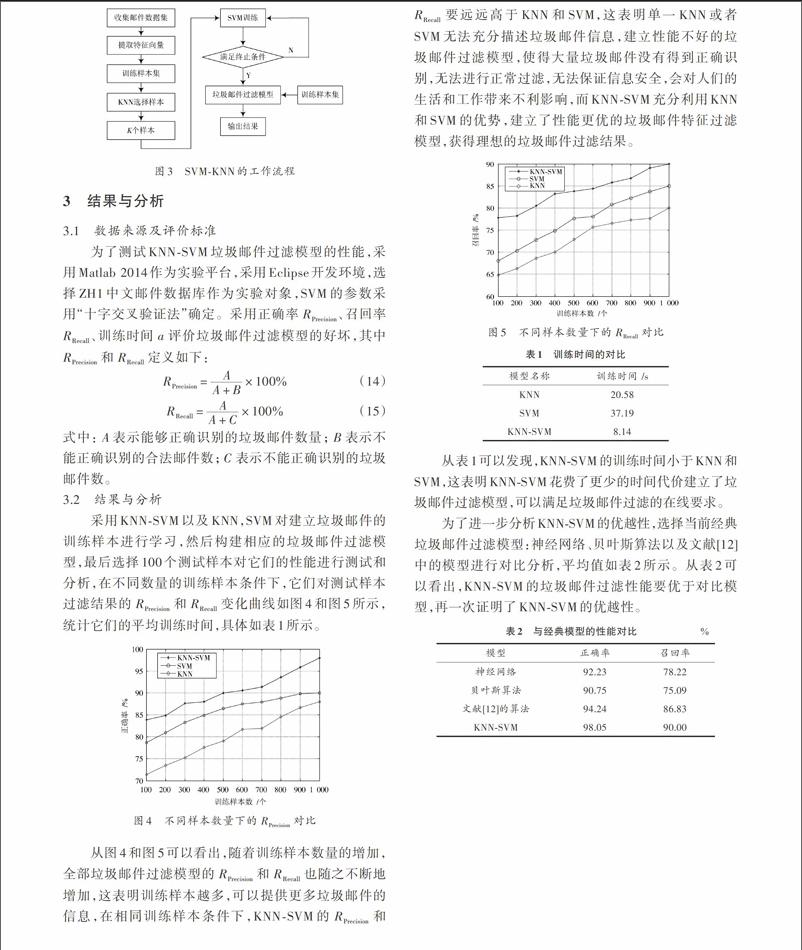
垃圾邮件的建模与过滤过程中,无法直接对垃圾邮件进行过滤操作,首先需要对邮件内容进行分析,找出一些关键元素,如词、字或短词等,从而提取邮件特征。通常采用有向图描述邮件内容,结构见图1,S表示邮件中的句子,NP表示邮件中的名词,VP表示邮件中的动词,PP表示邮件的介词短语。
4 结 语
在垃圾邮件过滤过程中,分类器的设计直接影响过滤效果,针对当前单一KNN和SVM的缺陷,提出了基于KNN?SVM的垃圾邮件过滤模型,结果表明,KNN?SVM能够改善垃圾邮件的过滤效率,而且可以获得较高的过滤准确率,具有良好的实际应用价值。
在未来的工作中将引入更优的SVM参数优化方法,对SVM分类能力进行改善以获得更好的垃圾邮件过滤结果。
参考文献
[1] 王斌,潘文锋.基于内容的垃圾邮件过滤技术综述[J].中文信息学报,2005,19(5):4?5.
[2] 李国明,汤文亮.反垃圾邮件技术及其最新展望[J].网络通讯与安全,2007(16):959.
[3] 梁志文,杨金民,李元旗.基于多项式模型和低风险的贝叶斯垃圾邮件过滤算法[J].中南大学学报(自然科学版),2013,44(7):2787?2792.
[4] 李潇,罗军勇,尹美娟.基于结构特征分析与文本分类的邮件筛选[J].计算机工程与设计,2010,31(21):4555?4558.
[5] 郑炜,沈文,张英鹏.基于改进朴素贝叶斯算法的垃圾邮件过滤器的研究[J].西北工业大学学报,2010,28(4):622?627.
[6] 李雯,刘培玉.基于贝叶斯的垃圾邮件过滤算法的研究[J].计算机工程与应用,2007,43(23):174?177.
[7] 陈琴,梁家荣.基于遗传算法和发送行为的垃圾邮件检测模型[J].广西大学学报(自然科学版),2010,35(6):1007?1010.
[8] 张俊丽,张帆.改进KNN算法在垃圾邮件过滤中的应用[J].现代图书情报技术,2007(4):75?78.
[9] 邹汉斌,雷红艳,邓卫红.支持向量机在反垃圾邮件过滤中的应用[J].计算机工程与设计,2007,28(9):2015?2017.
[10] 强永妍,杨庚.中文垃圾邮件的索引分词法的研究与设计[J].计算机应用,2007,27(9):2234?2236.
[11] 雷剑刚,孙细斌.一种智能垃圾邮件过滤模型的仿真研究[J].计算机仿真,2013,30(5):370?373.
[12] 闫鹏,郑雪峰,朱建勇,等.一种基于嵌入式特征选择的垃圾邮件过滤模型[J].小型微型计算机系统,2009,30(8):1616?1620.
猜你喜欢
英语文摘(2021年10期)2021-11-22
潍坊学院学报(2020年2期)2021-01-18
计算机与网络(2020年4期)2020-04-20
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
中国生物医学工程学报(2017年6期)2017-02-10
广西科技大学学报(2016年1期)2016-06-22
现代计算机(2016年11期)2016-02-28
噪声与振动控制(2015年4期)2015-01-01
上海电机学院学报(2013年4期)2013-03-11
