
基于Hadoop的海量小文件合并的研究与设计
2017-01-10 04:08彭建烽魏文国郑东炜
广东技术师范大学学报 2016年11期
彭建烽,魏文国,郑东炜
(广东技术师范学院电子与信息学院,广东广州 510665)
基于Hadoop的海量小文件合并的研究与设计
彭建烽,魏文国,郑东炜
(广东技术师范学院电子与信息学院,广东广州 510665)
基于Hadoop海量小文件合并的策略研究,一方面为了减轻NameNode的元数据量,利用Eclipse开发工具实现了Har、HBase、SequenceFile三种主流合并方案对海量小文件的合并;另一方面分析这三种主流合并方案在不同场景下性能以及应用方面的优劣,进而为海量小文件在Hadoop上的存储提供一些有价值的参考.
Hadoop;HDFS;小文件;元数据;Har;HBase;SequenceFile
1 引言
Hadoop分布式数据存储和处理框架凭借其高效、可靠、高容错等优点,渐渐成为了炙手可热的大数据存储和处理工具.Hadoop分布式文件系统(HDFS)是Hadoop的核心部分,它所具有的两类节点以管理者-工作者的模式运行,即单一NameNode(管理者)和若干个DataNode(工作者).NameNode负责管理文件系统的命名空间,DataNode作为系统的工作节点,它们根据需要存储并检索数据块(受客户端或NameNode调度),并且定期向NameNode发送它们所存储的块列表[1].
但HDFS并不适合存储海量小文件,主要因为NameNode将文件系统的元数据放在内存中,整个系统的文件数目受到NameNode内存大小的限制.根据经验,每个文件、目录和数据块的存储信息大约占150字节.举例来说,如果有一百万个文件,且每个文件占一个数据块,那至少需要300MB的内存.尽管存储上百万个文件是可行的,但是存储数十亿个文件就超出了当前硬件的能力[1].如今,Hadoop存储海量小文件已成为了大数据领域的热点问题.
2 相关研究
解决Hadoop上海量小文件的存储问题可以归结为两类:HDFS自身提供的解决方案和针对不同的应用场景采取特定的优化方案.
文献[2-4]是HDFS自身提供的解决方案. Har方案执行MapReduce任务将HDFS中的大量小文件合并成大文件,以此减少元数据量,不足之处在于归并的过程耗时较长,且随机读取小文件需要额外访问一层索引,导致访问速度可能更慢[2].SequenceFile方案工作原理是采取keyvalue键值对存储合并后的小文件,key是小文件名,value是对应的内容.但该方案不适合低延时的随机访问,因为每次读取小文件都需要遍历整个大的文件[3].MapFile方案是在SequenceFile方案基础上进行优化的,增添按key排序、有索引的功能,读取小文件的性能优于后者[4].
文献[5-7]根据不同应用场景采取特定解决方案.文献[5]在WebGIS系统中,将保存在相邻地理位置具有相关性的小文件合并成一个大文件,进而优化NameNode的内存开销,同时为合并后的小文件建立索引,进一步提高小文件的访问速度.文献[6]认为Bluesky系统缺乏考虑ppt之间的相关性和预存取机制,一方面将同属于一个课件的ppt文件合并成一个大文件;另一方面建立索引文件和数据文件的预取机制,提高文件的访问速度.文献[7]将NameNode中的元数据迁移到集群的数据库中,发挥关系型数据库的读写性能快的优势,实现对元数据快速读取;同时将块校验工作转交到元数据存储集群中,进一步减轻NameNode的负载压力.
针对当前众多小文件合并方案虽能在一定程度上解决文件合并所带来的性能问题,但都不具备很好的通用性,缺乏对几种不同合并方案的综合性分析和总结.因此,本文对当前三种流行的Har、HBase、SequenceFile合并方案进行综合性的研究,分析这三种解决方案在不同场景下的性能以及应用方面的优劣,为解决小文件问题提供一些有价值的参考.
3 文件合并方案比较分析
Har是一种特殊的档案格式,它在HDFS上再建立一层文件系统,通过在HDFS文件索引的基础上再添加一个索引,即主索引记录了这些Har索引,而Har索引则记录了文件数据的信息和内容,从而实现归档合并文件.Har方式通过减少NameNode元数据的条数,将海量的小文件归档为少量或者一个大文件,有效地提高了网络吞吐量,使得元数据减少了对内存的占用和消耗,从而缓解了NameNode压力.但这种方式不足之处在于不仅要读取HDFS上的索引,还要读取Har的索引,从而对数据文件进行加载,效率比原来的直接存放低.
HBase是一个分布式、面向列的开源数据库,HBase表的数据被分割成多个Region,是分布式存储的最小单元,分别由HBase集群中的RegionServer所管理,主节点NameNode有一个HMaster,负责管理集群中DataNode节点的HRegionServer,每一个HRegionServer存放客户端提交的数据,即分布式存储的最小单元Region,它是由一个或多个HSTORE组成的,而一个HSTORE保存一个列族,每个HSTORE又由一个MEMSTORE和多个Hfile组成.HFile是只读的,一旦创建就不可修改.当出现多个HFile的时候,就会进行HFile合并,而如果HFile大小到达一定阈值之后就会触发split操作,这个由HRigionServer检测是否达到阈值,将当前Region分割成两个Region,再由HMaster分配给其他server,从而保证了I/O读取的高性能.但不足之处在于HBase只是适合大量稀疏数据.
SequenceFile是一种存储大量二进制键值对数据文件格式,用来作为小文件的容器,从而提高MapReduce处理数据的效率.SequenceFile将小文件合并成一个格式为SEQ的序列大文件,作为MapReudce的输入输出.此外,SequenceFile提供三种基于None、RECORD、BLOCK键值对压缩方式,SequenceFile不仅从源头解决了小文件过多导致元数据消耗大量内存的问题,而且提高了MapReduce任务处理速度,压缩还能减少空间的占用,但是不足在于SequenceFile不支持追加,不能往里面添加数据.
4 测试与分析
4.1 实验环境
实验环境搭建了5个节点的Hadoop集群,每个节点的配置为:四核Intel Core CPU,主频3.6GHz,内存4GB,1TB硬盘空间,其中一台机器作为NameNode,其余四台作为DataNode.每台节点安装的操作系统为Ubuntu 12.04,Hadoop版本为Hadoop-2.6.3,JDK版本为1.8.0_73.实验用到的数据类型为txt格式文档、jpg格式图片、mp3音频文件,jpg格式图片的大小分布在0~200KB,大小2MB到10MB的txt文档和mp3音频文件分别占各自数据总量的80.3%、93.7%.
4.2 实验分析
实验1通过上传2000、4000、6000、8000、10000个小文件,对原始HDFS、Har的NameNode的内存使用情况进行了测试.结果如图1所示.

图1 NameNode的内存使用大小对比
图1的实验结果表明,Har能显著降低NameNode的内存开销,而且随着小文件数量的增多,Har的优势更加地明显.这是因为Har将多个小文件合并成大文件能有效地减少NameNode元数据量,使得客户端在NameNode检索元数据时变得更快,从而提高访问速度.
实验2采用10000个小文件,测试原始HDFS和HBase合并后小文件4次顺序读取的耗时开销,实验结果如图2所示.
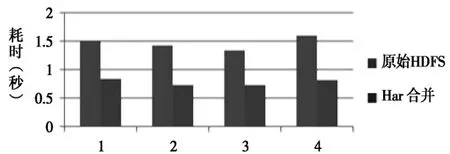
图2 原始HDFS、HBase合并顺序读取时间对比
通过计算,最终HBase顺序读取平均时间是原始HDFS的1/1.61,HBase合并后顺序读取性能优于原始HDFS.这是因为HBase合并会提高I/O性能,检索速度变快.在实际应用环境中数据量更大,差异也会更加明显,但是这种方式的合并并不能随意使用,否则会引起阻塞,应该在HBase集群空闲时间调用.
实验3通过对1000个txt格式文档分别采用直接读取文件方式、SequenceFile合并再读取然后进行词频统计,实验共进行4次,每次采用不同内容的txt文档.测试原始HDFS和SequenceFile合并后读取全部txt文档的耗时开销.
实验发现进行词频统计需要读取文件时,SequeceFile合并后产生的单个序列文件再进行一次读取平均只用了约12秒,而普通文本的全部读取约12000秒,SequeceFile合并后的全部读取时间是原始HDFS读取耗时的1/1000左右.显然对于txt文档而言,先将其采取SequeceFile合并再一次读取进行词频统计的效率要远远高于普通文本的多次读取.
5 结语
本文基于Hadoop海量小文件的存储问题,测试并总结三种合并方案在不同场景下的性能以及应用方面的优劣.Har合并能显著减少NameNode节点上的元数据量,减轻NameNode内存开销,且Har合并最为常用,适用于众多的文件格式.HBase主要对序列化到磁盘的文件进行合并,以此达到提高小文件检索速度;而且能提高复杂环境下数据检索的速度,但是需要根据实际生产情况进行配置才能达到很好的效果.SequenceFile针对的是数据文件的合并,从而快速提高MapReuce作业对数据的读取,适用于用于数据分析的应用,例如天气预测、用户手机流量统计、词频统计等应用.
[1]tom white.Hadoop权威指南(第三版)[M]北京:清华大学出版社,2015.2.
[2]HadoopArchives[OL].http://hadoop.apache.org/docs/ r-1.2.1/hadoop_archives.html.
[3]SequenceFileWiki[OL].http://wiki.apache.org/hadoop/ SequenceFile.
[4]Mapfiles[OL].http://hadoop.apache.org/common/docs /current/api/org/apache/hadoop/io/MapFile.html.
[5]Liu,Xuhui,et al.Implementing WebGIS on Hadoop: A case study of improving small file I/O performance on HDFS[C].2009IEEE International Conference on Cluster ComputingandWorkshops.IEEE,2009.
[6]Dong B,et al.A novel approach to improving the efficiency of storing and accessing small files on hadoop: a case study by powerpoint files[C].Services Computing(SCC),2010IEEEInternationalConferenceon. IEEE,2010.
[7]马志强,杨双涛,闫瑞,张泽广.SQL-DFS:一种基于HDFS的海量小文件存储系统[J].北京工业大学学报,2016.01.
[责任编辑:王晓军]
Research and Design of Massive Small File Merging Based on Hadoop
PENG Jianfeng,WEI Weiguo,ZHENG Dongwei
(Guangdong Polytechnic Normal University,Guangzhou Guangdong 510665)
The research is based on consolidation of the massive small files storage on Hadoop.On the one hand,in order to reduce the metadata footprint in memory,the different solutions of Har,HBase and sequence were combined by using Eclipse development tools.On the other hand,we analysed the advantages and disadvantages of the performance and application of the three massive file merging solutions,and provided some valuable reference for the storage of massive small files on Hadoop.
Hadoop;HDFS;Small files;Metadata;Har;HBase;SequenceFile
TP 391
A
1672-402X(2016)11-0040-03
2016-05-20
广东省公益研究与能力建设专项资金(2014A010103032)和广东省科技型中小企业技术创新专项资金项目(2016A010120010、2014A010101109、2014A010101092)资助.
彭建烽(1991-),男,广东湛江人,2015级硕士研究生.研究方向:网络信息技术.
魏文国(1968-),男,湖北公安人,博士,广东技术师范学院教授,研究方向:计算机网络及其应用.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
电脑报(2019年31期)2019-09-10
当代陕西(2019年14期)2019-08-26
当代陕西(2019年13期)2019-08-20
中学数学杂志(初中版)(2016年5期)2016-11-01
电脑爱好者(2015年21期)2015-09-10
导航定位学报(2015年2期)2015-06-05
