
基于大数据的服刑人员危险性预测
2017-01-10 06:58马国富王子贤马胜利
河北大学学报(自然科学版) 2016年6期
马国富,王子贤,马胜利
(中央司法警官学院 信息管理系,河北 保定 071000)
基于大数据的服刑人员危险性预测
马国富,王子贤,马胜利
(中央司法警官学院 信息管理系,河北 保定 071000)
在对监狱服刑人员再犯罪预测与危险性评估应用现状进行分析的基础上,提出了一种基于大数据的监狱服刑人员危险性识别与预测架构体系.在该体系的模型层,针对不同的价值密度、不同的数据类型,重点对架构中的统计模型、离群点检测模型、集成分类模型在服刑人员危险性识别与预测中的应用算法进行了描述,尤其是使用R软件包实验了服刑人员危险性集成分类识别与预测,并给出了分类预测误差.基于大数据的服刑人员危险性识别与预测体系可实现对服刑人员危险性的个性化、精准化预警,为大数据时代监狱的监管安全提供了可靠保障.
危险性评估;识别;预测;大数据;算法
监狱作为国家的刑罚执行机关,监管安全是监狱工作的首要任务,也是构建和谐社会的重要基石.目前,监狱为了确保监管安全,提出了各种管理方法,制定了各种管理制度,来规范监管.近年来,按照国家、司法部和各省的有关部署,经过各级司法行政机关的共同努力,监狱信息化建设工作已取得了很大的进展,但与公安等政法系统相比,各地监狱信息化建设发展不均衡、水平不一、缺乏信息化评估体系;各系统重复数据录入,各系统之间没有实现数据整合与共享,形成很多“信息孤岛”;重防控、轻整合,重建设、轻应用的现象比较普遍,信息化应用的总体水平仍然相对较低,信息技术在监管安全中的应用有待进一步提升.随着云计算、物联网、智能化视频监控等新型IT技术在监狱中的深入应用,监狱网络、信息资源库、应用软件、应用服务器、视频监控系统、无线传感器网络、基于无线定位的电子腕带和RFID等组成的物联网智能安防监控等系统所产生的数据呈爆炸性增长,并且数据量从线性级到指数级增长,数据已经成为一种新的资产,而大数据将产生新的价值,监狱系统正面临着“大数据”、“大系统”的管理和维护问题.利用数据挖掘、模式识别和机器学习等大数据技术从监狱信息化资源库、安防监控等系统及服刑人员的日常行为中收集服刑人员的相关数据并整合成数据集,然后进行聚类、关联、分类和深度分析,提炼信息规律,获取知识建立数据模型来对监狱服刑人员的危险性进行模式识别和预测,服刑人员危险性的识别与预测将日益基于数据分析做出,而不是像过去更多凭借经验和直觉.
1 监狱监管安全的现状
惩罚和改造服刑人员,预防和减少犯罪,确保监管安全稳定,维护执法公平正义是《监狱法》赋予监狱的职能,而这其中监管安全更是重中之重.当前,监狱各类业务信息管理系统和安全防范系统在监狱的应用大大提高了监狱的监管改造管理水平和工作能力,然而监狱突发事件仍时有发生.在百度搜索引擎里输入“越狱案件统计”,百度找到相关结果约1 280 000个,排在前几个的统计信息有:2011年9月15日财新网公开报道10起重大越狱案件,报道最后总结这些越狱案件多与监狱管理漏洞有关[1];2014年9月4日中商情报网报道近年来的7大越狱案件[2],2014年11月3日中华网公开报道了近7年来的12起越狱案件[3],2015年环球军事网报道了中国最严重的监狱越狱案件分析[4],报道中广东省监狱管理局副局长说:”这说明监狱在内部管理上、在隐患整治上存在漏洞.”.上述只是公开报道的监狱越狱事件,监狱安全监管事件除了服刑人员越狱脱逃外,还包括集体暴乱、自杀、罪犯斗殴、传染病、生产安全事故及自然灾害类等安全突发事件.然而,在现有制度下,大部分省份的监狱将劳动改造、生活卫生等形成的计分作为减刑、假释的重要依据,证明服刑人员却有悔改不致危害社会,这显然会导致监狱执法的科学性受到质疑.服刑人员出于减刑、假释的需要,会有针对性地根据监狱制定的计分方式和计分细则进行最大努力获取分数,这必然会造成服刑人员改造思想的不端正和诱发功利改造思想.在实践中,普遍存在罪犯减刑前后两个样,前后反差很大的现象,并且一旦服刑人员脱离了监狱环境回归社会,监狱监管的丧失,服刑人员的危险性将很难预料.从长远意义上来说,计分考核制度在一定程度上给监狱监管改造工作带来不良影响,因此有必要对服刑人员的监管改造模式进行革新,探索新的监管安全手段和方法.
2 服刑人员再犯罪预测与安全性评估
2.1 服刑人员再犯罪预测
Beck&Bemand(1989)通过档案分析发现,5%的犯罪人要对45%案件的发生负责;Farrington(1996)的研究也显示,在所有案件中,有将近一半是由6%的犯罪人完成的.这一现象表明,通过对高危险性服刑人员的行为识别和预测是可以实现预防的.各国学者开始了相关问题的探讨,研究个体特别是特定服刑人员是否具有人身危险性、危险性程度如何等问题,并且形成了一系列评估手段、方法.阿根廷的拉普拉特在2011年实施了“风险评估试点项目”,在当地法院的申请下,通过HCR-20、PCL-R和VARG,对65名有假释资格的罪犯进行了评估;日本成立了“专门监督官特别队”,对缓刑、假释者进行再犯风险评估;英国研发出了“犯罪人需要评价量表”,根据量表得分划分风险程度,并将不同风险的犯罪人划分为高、中、低3种监管等级[5].在中国,为提高监管改造的科学性和执法的公正性,为预防狱内突发事件的发生,为减刑、假释的需要,为服刑人员在社区矫正中再犯罪预测,全国很多监狱都开展了针对服刑人员的危险性评估.司法部预防犯罪研究所于1992年出版的《中国重新犯罪研究》,定性地分析了影响刑释人员再犯的可能性因素及其动机,但由于缺少实证数据和科学手段的支持,也没有提出如何对再犯可能性进行评估.上海市监狱管理局(2003)[6]制定了《违法犯罪可能性量表(修订版)》对减刑、假释、监外执行的服刑人员的危险性进行预测,但没有提出具体预测关系函数;黄兴瑞等[7]采用判断抽样方法对浙江省715名(初犯345,再犯370)犯人进行了问卷调查,运用数理统计方法,提取出12项与再犯显著相关的特征,并分别制成判刑前、入狱前、服刑中、释放前4种再犯罪预测量表,但由于用初犯代替未重新犯罪者,对不同特征没有赋予不同的权重,导致“弃真”错误率超过50%.邬庆祥[8]对15 000名刑释人员进行问卷调查,选择14个再犯特征,利用多元线性回归函数对其再犯罪进行预测.章恩友[9]提出通过在押人员自评量表、他评量表和实验模拟3个主要手段建立再犯预测评估体系,通过对在押人员的掩饰倾向、个性特质的变化、社会适应水平、改造质量等方面来确定再犯罪概率;曾赟[10]对浙江省不同类型监狱1 238名随机在押犯样本进行调查与统计,采用多因素方差分析与二元Logistic回归分析,提出了11项罪犯出监前重新犯罪预测因子,但没有给出预测因子与应变量(再犯罪)的函数关系;孔一等[11]选择浙江省监狱313名重新犯罪人员和288未重新犯罪的刑释人员分别作为实验组和对照组,利用SPSS17.0通过统计方法求得E2系数来选择初始预测特征,再通过合并预测特征,实现降维,但同样也没有给出预测特征和应变量的函数关系.
2.2 服刑人员危险性评估
在西方国家,根据罪犯危险等级分配司法资源,既可以降低司法成本,也可以提高司法效能,其中的司法实践就是“危险管理”,而对罪犯进行危险性评估是危险管理的重要依据,其准确程度将直接影响危险控制的效果.段晓东[12]将危险性评估定义为通过摸底排队,了解全部罪犯的有关动态,从而对监狱内所监管的罪犯危险性进行分析;翟中东[13]将危险性评估定义为通过一定技术对罪犯重新犯罪或者实施其他犯罪的可能进行预测,从而为控制这些危险提供依据;学术界,很多专家也从罪犯的人身危险性、社会危险性、心理危险性和再犯罪等多个角度对其危险性进行评估.浙江师范大学曹建路[14]利用SPSS13.0和LISEL8.70统计工具对江苏省某重型犯监狱的352名罪犯将静态因素量表和自建动态因素量表想结合,但没有通过实验测量法进行权重赋值;上海师范大学徐英兰[15]以1 830名新收监罪犯为研究对象编制了罪犯狱内危险评估自评量表和他评量表,应用统计方法对量表进行信度和效度检验,相关拟合指数大于0.8,模型拟合较好,通过量表测定给出危险等级和危险类型,但其特征因素的权重主要是依据经验设定;孙岳芳等[16]对假释罪犯制定了人身危险性量表,主要包括罪前人身、犯罪行为、生理状况、心理状况和罪后表现,但没有对这些量表中特征进行统计学意义上信度和效度检验.目前,对于社区矫正危险性评估就是对其再犯罪的预测,张学霏[17]将社区矫正中人身危险性评估分为入矫前、矫正中、解矫前3个阶段,并根据不同阶段设定不同量表,但只是进行定性叙述.由此,可以看出服刑人员危险性评估按照时空的转换可分为狱前危险性评估、狱内危险性评估、罪犯假释危险性评估、社区矫正人员危险性评估.
综上所述,可以看出,早期对罪犯的再犯罪的预测或危险性评估主要是通过定性分析,最近几年主要是通过随机抽样选择样本,然后利用统计学方法提取特征,制定量表进行再犯罪预测或危险性评估.一方面,量表测评本身具有其局限性,如果量表没有进行信度和效度的检验,其准确性很难保证,即使进行了效度和信度检验,一套量表一旦制定出来就相对固定了,变成通用的了,然而和犯罪行为相关的因素会随着社会环境、地理区域、犯罪类型等的变化而变化,因此量表的信、效度会随着时空的转换而变得越来越低.另一方面,抽样调查本身具有登记性误差和代表性误差,登记性误差是指由犯人人为因素造成的误差;代表性误差是指不论随机抽样多么科学,总是不能代替所有目标对象,因此从样本空间提取出来的特征总是和实际有一定的误差.在大数据时代,首先收集全部服刑人员的结构化、半结构化、非结构化数据,也即静态属性和动态行为数据;然后利用统计方法、数据挖掘等相关技术提取罪犯危险性特征,建立服刑人员危险性识别与动态预测模型;再然后利用机器学习等技术根据后期测试结果不断训练模型,提高精度,使其成为一个循环反馈环路,从而建立一套服刑人员危险性识别与动态预测体系.该体系一方面针对的是所有服刑人员,避免了抽样调查本身带来的误差;另一方面该体系收集的是每个服刑人员的静态属性和动态行为数据,可提供个性化、精细化的危险性识别和预测,避免了模型随时空的转换而信、效度降低的可能.
3 监狱大数据分享中的隐私保护
20世纪90年代中叶,美国马萨诸塞州团体保险委员会发布州政府雇员的“经过匿名化处理的”医疗数据供公共医学研究,删除了数据中所有的敏感信息,例如姓名、住址和社会安全号码.然而1997年,麻省理工学院博士生拉坦娅·斯威尼利用数据集中的出生日期、性别和邮编三元组信息成功破解了这份匿名数据,并找到了时任州长威廉·威尔德的医疗记录,还将该记录直接寄给了州长本人.2006年8月4日,美国在线公司在互联网上发布了超过65万用户在过去3个月的搜索关键字,以供公众对搜索技术进行研究.该公司用一个随机号码来替代用户的账号实现匿名化处理,随后,《纽约时报》成功破解该数据集,这起隐私泄漏事件导致美国在线在北加州地方法院被起诉.目前,相比较于其他领域,学者对服刑人员的危险性研究之所以较少,一个很大的原因就是因为服刑人员数据的敏感性.然而在大数据时代,对监狱服刑人员的数据进行研究同样也是必要的,这有利于监狱对服刑人员危险性的识别和预测,但是数据分享会带来被泄露的风险,因此对监狱服刑人员的数据进行隐私保护成为监狱大数据研究中的必要条件.隐私保护的目标在于既要保证修改后的数据不会遭受去匿名化攻击,又要在保护隐私的同时,保留原数据的有用信息.监狱服刑人员数据属性可以分为4类属性[18]:1)个体标识属性,可以显式表明个体身份的属性,比如姓名、身份证号码和手机号码[19].2)准标识属性,攻击者可以通过与外部数据表进行链接从而获得个体隐私信息,比如性别、年龄和邮政编码.3)敏感属性,描述个体隐私的细节信息,比如疾病和收入.4)与上述无关的其他属性.
对于服刑人员个体标识信息一般可通过删除、随机数替换、哈希码替换等方法来实现数据保护.因为某些准标识属性组的取值是唯一的,为了防止攻击者通过链接攻击的方法获得个体隐私信息,对于服刑人员准标识属性可通过数据概化方法和有损连接来处理[19].最早被广泛认同的隐私保护机制为k-匿名[20],它要求发布表中的每个元组都至少与其他(k_1)个元组在准标识属性上完全相同,使得其不再与任何人一一对应,然而k-匿名存在严重一致性攻击漏洞;微软研究院的德沃柯(Dwork)等人[21]于2006年提出了差分隐私模型及差分隐私的通用随机算法:拉普拉斯机制,但该机制主要针对实数值的场合;为此,麦克雪莉(McSherry)和图沃(Tulwar)提出适用于离散值域的指数机制,也是差分隐私的经典通用算法[22].差分隐私假定攻击者及时知晓了原数据中的除了某一条记录之外的所有信息,仍然能提供保护,但如此高强度的保护必然带来大量的噪声,影响数据的可用性.所以在实际应用中,也出现了一些改进差分隐私的尝试[23].在利用服刑人员的静态属性和动态行为数据进行危险性识别与预测时,可根据数据的类型、安全级别、数据的精确度和隐私度的值来进行不同泛化的算法选择.数据隐私保护力度可通过平均泄露概率比(average probability rate,简称APR)来衡量,数据精确度(泛化后数据的可用程度)可通过加权属性熵(weighted attributes entropy,简称WAE)来衡量[24].
(1)
(2)
其中,N表示数据集T*中的元组数,pi=1/ei(ei为第i个分组中的元组数)表示第i条元组对应个体信息的被泄露率,k为数据泛化处理中每个分组中的元组数,emin表示等价组中的最小元组数.
(3)
(4)
其中,WAE(T*)定义为所有元组加权信息量的平均值,I(Gi)为等价组G个属性的加权信息总量,gcnt为T*包含的等价组总数;|G|表示等价组G的元组数,D表示属性Aj的最大数,wj是各个属性分配的不同权重,有∑wj=1,vcntj是属性Aj(1≤j≤D)在等价组G上的值Vj所代表的精确值个数.实验结果[24]发现数据的隐私度和精确度在总体上呈现相反的变化趋势,但在整个区间并不都是单调递减关系,段与段之间是逐渐增长或消减的,因此在选择较优的泛化隐私保护模型及算法时,可根据实际需要选择那些隐私度和精确度都优的点,也可选择那些隐私度或精确度单个优的点.
4 基于大数据的服刑人员危险性识别与预测
4.1 基于大数据的服刑人员危险性识别与预测架构
目前,全国大部分监狱都已建立各类业务信息管理系统,内部历史数据量越来越大,然而在建设过程中由于主要从业务部门考虑,导致数据分散存储、数据冗余、数据不完整、数据字段标准不一等现象,使得数据难以集成为统一的大数据平台.面对有结构化数据(例如各业务管理系统中的数据)、半结构化数据(例如服刑人员病例)和非结构化数据(例如服刑人员和家属会见及电话记录、视频监控)组成的海量多源数据,不仅需要有效组织存储,而且需要筛选过滤,经深度挖掘后提取出更为有效的知识,为服刑人员的危险性识别和预测服务.20世纪90年代以来,数据仓库作为一种支持数据挖掘、联机分析处理、传统查询及报表功能并解决数据整合、数据展现及数据分析的系统架构受到学术界和产业界的广泛关注,逐渐成为信息化建设的主流技术,为决策支持提供了重要帮助[25].一个典型的数据仓库架构见图1所示,它分为4个层次,首先使用ETL工具对数据源中的数据进行数据抽取(extract)、清洗(cleaning)、转换(transform)、装载(load)到数据仓库集中存储,然后按照某种模型(星型或雪花型)组织数据;然后OLAP(on-line analytical processing)工具从数据仓库中读取数据,生成数据立方体,供前段用户查询、分析和挖掘等应用.
大数据时代图1的模型存在2个问题:首先由于在数据源层和分析层之间引入一个存储管理层,在提升数据质量的同时也付出了较大的数据迁移代价和执行时的连接代价;其次传统的数据仓库假设主题是较少变化的,因此很难适应基于主题的大数据需求变化.面对数据量大、数据类型多、处理速度快、价值密度低、异构(结构化、半结构化、非结构化)等大数据下的各种挑战,监狱需要新的大数据分析与预测架构.文献[26]提出视频监控大数据应用框架和监狱大数据应用架构,但架构没有分层,更没有针对业务逻辑进行建模和大数据处理.
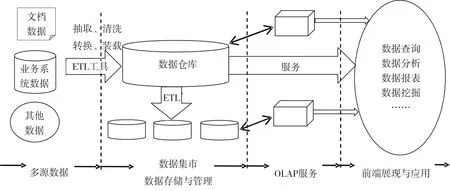
图1 数据仓库典型架构Fig.1 A typical data warehouse architecture
基于大数据的服刑人员危险性识别与预测架构见图2所示,在多维数据源层的结构化数据中,罪犯信息库包括:罪犯服刑数据、罪犯家属数据、罪犯社会关系数据;警察职工信息库包括:警察职工数据、警察职工人事管理数据、警务督察数据.监管改造信息库包括:狱政管理数据、劳动改造数据、教育改造数据、刑法执行数据、狱内侦查数据、生活卫生数据、罪犯医疗健康数据等.物联信息库包括:罪犯定位数据、车辆定位数据、劳动工具定位数据、安防设备物联数据;半结构化数据中的日志数据主要包括:各信息系统的日志,社会数据主要包括:监狱门户网站及互联网中有关服刑人员的数据;非结构化数据中的文本数据主要包括:监狱日常开会的记录数据、监狱警察每月对服刑人员的谈话数据、服刑人员可穿戴设备产生的数据、监狱警察在服刑人员和家属会见时的记录数据等一切由监狱日常工作所产生的所有文本数据,音频数据主要包括:监狱会见系统及远程电话等系统中的所有录音数据,视频数据主要包括:监狱所有视频监控产生的数据.对多源数据进行数据预处理后可存放到分布式数据库中,然后分别建立基于不同的危险等级和危险分类主题的数据集市,并通过数据仓库来实现,利用图计算系统对服刑人员的社会关系、劳动关系、饭友关系等网络进行分析;逻辑模型层通过统一的数据总线接口进行数据分析挖掘和机器学习.
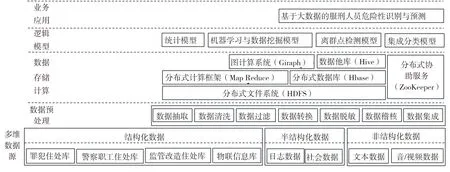
图2 基于大数据的服刑人员危险性识别与预测架构Fig.2 A architecture of risk identification and prediction for prisoners based on big data
4.2 基于大数据的服刑人员危险性识别与预测逻辑模型
基于大数据的服刑人员危险性识别与预测逻辑模型主要包括统计模型、机器学习与数据挖掘模型、离群点检测模型、集成分类模型等,这些模型针对不同的数据结构类型、不同的业务领域通过相关算法从不同维度、不同的时空变化来实现对服刑人员危险性的识别与预测.
4.2.1 服刑人员危险性统计模型
大数据时代的到来暴露了传统统计学已有方法的缺陷,从抽样调查、数据管理和存储、统计分析和计算,海量数据分析的需求对统计学带来了严峻的挑战.针对大数据时代的高维数据降维分析,Jiangqing Fan教授提出了优于传统主成分分析的投影主成分分析(projected principal component analysis),是大数据背景下统计学的重构和创新.而要想从高维数据中找到起作用的特征,有效的变量选择通过剔除多余的变量能够给出最优的预测变量,从而得到最简洁的模型,同时,有效的变量选择能够提高模型的预测精度.确定独立筛选方法(sure independence screening,SIS)大大提高了超高维变量选择的计算速度及统计性质[27].
然而在大数据时代下,统计学模型仍然具有重要的有意义,比如可利用回归分析进行变量选择.对服刑人员所犯案件及其同伙服刑人员(不一定要在一个监狱关押)的犯罪网络图谱进行分析,可建立服刑人员危险性逻辑模型,实现对服刑人员的犯罪网络维度上的统计分析、危险性识别与预测.服刑人员的危险性可通过服刑人员网络中心度Cp来识别,它是用来表示服刑人员在整个服刑人员网络(监狱或监区)里的影响力,则
(5)
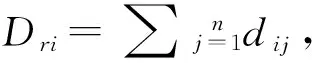
4.2.2 机器学习与数据挖掘模型
机器学习是指利用经验来改善计算机系统自身的性能,最本质的问题是要最小化预测误差的某种度量.数据挖掘是指从大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的过程.大体上看,数据挖掘可以视为机器学习和数据库的交叉,它主要利用机器学习提供的技术来分析海量数据,利用数据库提供的技术来管理海量数据.利用数据挖掘进行数据分析常用的方法主要有分类、回归分析、聚类、关联规则、特征分析、变化和偏差分析等.利用回归分析,可对服刑人员危险性建立函数关系,发现变量或属性间的依赖关系,可通过散点图进行特征选择;对未标记危险性类别的服刑人员进行聚类分析,可用于发现服刑人员的异常行为,可用于离群点检测;特征分析用于确定服刑人员危险性的属性特征;变化和偏差分析用于识别服刑人员的日常反常行为.在监狱这个独特的环境中,可利用时空数据挖掘实现对服刑人员危险性的识别与预测,时空数据挖掘主要分为:时空模式挖掘、时空聚类、时空异常检测[28].服刑人员危险性时空异常检测在于识别某个服刑人员和他在空间上相邻并在一段连续时间内出现的邻居有着显著差异的服刑人员,常用基于距离、密度和聚类的方法.
4.2.3 服刑人员危险性离群点检测模型
离群点是数据集中偏离大部分数据的数据,被用来发现稀有模式或者数据集中异常于其他数据的对象.离群点检测可以分成3类:全局离群点、情景(或条件)离群点和集体离群点,全局离群点是指一个数据对象显著偏离数据集中的其他所有对象;情景离群点是指在某个特定情景下,一个数据对象显著偏离该情景中的其他对象;集体离群点是指数据集的一个子集偏离整个数据集[29].通过对服刑人员危险性数据集中的离群点分析,可以迅速、准确地甄别发生在监狱中的时间、空间中的异常事件,从而识别与预测出服刑人员的危险性行为.服刑人员危险性的全局离群点检测主要是指某个服刑人员相比较于其他所有犯人的危险性行为.情景离群点检测在服刑人员危险性识别与预测中,主要是指在监狱的特定区域或特定时间段内发生的异常行为事件.特定区域是指监狱食堂、监舍、工作场地等服刑人员活动的场所和监狱周界围墙等高危险性场所;特定时间段是指服刑人员早课、就餐、工作、就寝、学习、休闲等时间段.服刑人员危险性集体离群点检测主要是指一小部分服刑人员的集体异常危险性行为,一般可用于服刑人员的网络图谱(犯罪网络、饭友网络等)离群点检测.服刑人员危险性识别与预测主要通过情景离群点检测来实现,具体算法如下:
1) 对于给定的数据集D,确定该数据集的情景属性sai(i≤m,m为情景属性的最大维度)和行为属性bpj(j≤n,n为行为属性的最大维数);
2) 使用训练数据,在情景属性sai上学习数据的一个混合模型U,在行为属性bpj上学习数据的一个混合模型V;
3) 在U和V的基础上,学习一个映射p(Vj|Ui),然后捕获属于情景属性Ui上的簇的对象o被行为属性Vj上的簇产生的概率;
4) 用公式(6)计算离群点得分,如果该值显著偏离正常值,确定最终离群点,预测出服刑人员的危险性行为.
S(o)=∑UiP(o∈Ui)∑VjP(o∈Vj)P(Vj|Ui).
(6)
4.2.4 服刑人员危险性集成分类模型
分类是数据挖掘、模式识别和机器学习领域中一种重要的技术,是根据数据集的特点构造一个分类模型(分类函数,或称为分类器),能把未知类别的数据映射到给定类别中的一种技术.常用的分类算法主要有决策树、Bayes、神经网络、支持向量机、马尔可夫等分类算法,分类算法的评价标准是预测的准确率、速度、强壮性、可伸缩性、可解释性.文献[30-31]基于马尔可夫模型对软件故障、软件漏洞进行分类预测,但是马尔可夫链所反映的最本质的属性是马尔可夫性(称为无后效性),即系统的状况与过去的状况无关.而服刑人员危险性前后是非常紧密相关的,比如一个想自杀的犯人可能会多次自杀,越狱的犯人会多次想越狱等,显然马尔可夫模型不适合用于服刑人员危险性分类预测.经典的神经网络分类模型计算量大,用户很难辨别输入条件对分类结果的影响,而集成分类器通过构建一组基分类器(包括决策树、Bayes、神经网络、支持向量机等分类器),最后通过投票来实现分类,从而提高分类准确率和模型的稳定性.随机森林就是一个经典的集成分类器,它的每一颗树的子分类器相互独立,最后汇总各分类子树的结果,用户可以对分类器进行在线改进,通过条件的不同组合进行训练,可随时根据数据和危险性特征的更新而对新的输入条件进行运算,得到预测结果[32].随机森林的运算速度很快,在处理大数据时表现优异,给出了所有变量的重要,并可以体现变量间的交互作用,对离群值不敏感[33],因此,基于多个决策树集成的随机森林可用在对服刑人员的危险性进行识别和预测中.假定服刑人员数据集为D,然后随机抽取K个bootsrap样本集,记为Di(i=1,2,…,k);其次,对每个Di分别建立服刑人员危险性决策树模型{h(x,θi),i=1,2,…,k},其中x是服刑人员危险性特征变量,参数集θi是独立同分布的随机向量;最后,经过k轮训练,得到分类模型序列{h1(x),h2(x),…,hk(x)},再用它们构成一个多分类模型,通过投票方式得到最终分类结果,最终的分类决策可用如下公式表示:
(7)
其中,H(x)表示集成分类模型,hi(x)是单个决策树分类模型,Y表示输出变量(脱逃、自杀、暴力等危险类型),I(.)为示性函数.可用R语言中的软件包randomForest运行随机森林算法对服刑人员危险性进行分类预测,R中代码执行如下:
Install.packages("randomForest")
//安装随机森林程序包
Library(randomForest)
//调用随机森林程序包
Offender<-read.csv("c:/data/offenders.csv",header=TRUE)
//从硬盘读入数据集
RF3<-randomForest(offender[,c('L1','L2','L3','L4')],offender[,'category'],importance=TRUE,ntr ee=10000)
//调用随机森林模型
RF3
//显示模型结果
其中,offender[,c('L1','L2','L3','L4')]表示服刑人员危险性量度,offender[,'category']表示服刑人员危险性类别.表1是服刑人员危险性分类混淆矩阵,表2显示模型对A类的判别错误为21.6%,对B和C类的判别错误率为0.

表1 随机森林的混淆矩阵
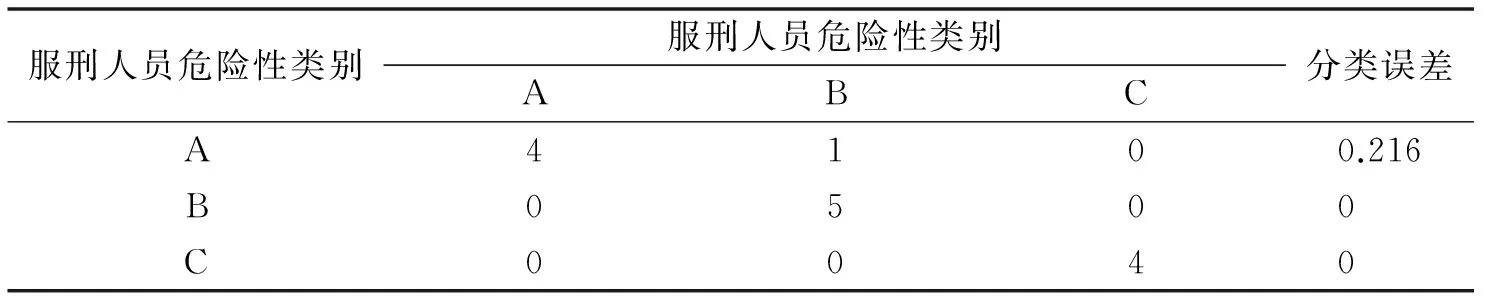
表2 随机森林的混淆矩阵的危险性分类误差
5 结论
本文在对服刑人员再犯罪预测与危险性评估现状分析的基础上,提出了一种基于大数据的服刑人员危险性识别与预测架构,并重点对架构中的统计模型、离群点检测模型、集成分类模型4个逻辑模型在服刑人员危险性识别与预测中的应用算法进行了描述,尤其是使用R软件包实验了服刑人员危险性集成分类识别与预测,并给出了分类预测误差.
下一步的主要工作是针对监狱大数据,丰富基于大数据的服刑人员危险性识别与预测架构,例如流计算框架(spark)、图处理并行框架(graphlab)、实时流计算框架(storm)等;另外还研究针对监狱不同数据类型、不同价值密度的开源实现架构和数据分析工具;最核心的内容是进一步研究将更多的机器学习算法应用到服刑人员的危险性识别与预测领域中,通过不断的训练,找出越来越精准的服刑人员危险性识别与预测模型,实现对服刑人员的危险性识别与预测.
[1] 黄晨.近年10起重大越狱案件一览[EB/OL].http://www.caing.com/2011-09-15/100302744.html,2011-09-15/2015-12-16.
[2] 中商情报网.黑龙江嫌犯杀警越狱盘点:近年国内越狱大案件[EB/OL].http://mil.askci.com/military/2014/09/04/93322wofp.shtml,2014-09-14/2015-12-16.
[3] 王婷婷,张莹.媒体盘点近7年12起越狱案[EB/OL].http://news.china.com/domestic/945/20141103/18922977-all.html,2014-11-03/2015-12-16.
[4] 环球军事网.中国最严重的监狱越狱案件分析[EB/OL].http://www.huanqiumil.com/a/40936-2.html,2015-06-10/2015-12-17.
[5] 何川,马皑.罪犯危险性评估研究综述[J].河北北方学院学报:社会科学版,2014,30(2):67-73.
HE C,MA A.Research overview on criminal risk assessment[J].Journal of Hebei North University:Social Science Edition,2014,30(2):67-73.
[6] 胡庆生.行刑方式的文明进步-上海市积极拓展社区矫治新空间[N].法制日报,2003-08-04(8).
[7] 黄兴瑞,孔一,曾贇.再犯预测研究-对浙江罪犯再犯可能性的实证分析[J].犯罪与改造研究,2004(8):8-13.
HUANG X R,KONG Y,ZENG Y.Prediction of recidivism-empirical analysis of the possibility of recidi-vism in Zhejiang[J].Research on crime and transformation,2004(8):8-13.
[8] 邬庆祥.刑释人员人身危险性的测评研究[J].心理科学,2005,28(1):222-224.DOI:10.16719/j.cnki.1671-6981.2005.01.063.
WU Q X.A research on the appraisal of the personal dangerousness of persons released after completion of a sentence[J].Psychological Science,2005,28(1):222-224.DOI:10.16719/j.cnki.1671-6981.2005.01.063.
[9] 章恩友.罪犯心理矫治[M].北京:中国民主法制出版社,2007.
[10] 曾赟.服刑人员刑满释放前重新犯罪风险预测研究[J].法学评论,2011(6):131-137.DOI:10.13415/j.cnki.fxpl.2011.06.003.
ZENG Y.Prediction of risk of redivism before the offenders released from prison[J].Law Review,2011(6):131-137.DOI:10.13415/j.cnki.fxpl.2011.06.003.
[11] 孔一,黄兴瑞.刑释人员再犯风险评估量表(RRAI)研究[J].中国刑事法杂志,2011(10):91-106.
KONG Y,HUANG X R.Study of recidivism risk assessment list for released offenders[J].Journal of Chinese criminal law,2011(10):91-106.
[12] 段晓东.科学分析狱情之管见[J].中国监狱学刊,2005(1):67-70.
DUAN X D.The scientific analysis on the situation of prison[J].Journal of Chinese Prison,2005,(1):67-70.
[13] 翟中东.国际视域下的重新犯罪防治政策[M].北京:北京大学出版社.2009.
[14] 曹建路.成年服刑人员人身危险性评估体系的建构[D].金华:浙江师范大学,2013.
CAO J L.Construction of personal danger evaluation system on adult prisoners[D].Jinhua:Zhejiang Normal University,2013.
[15] 徐英兰.罪犯狱内危险度评估量表的研制[D].上海:上海师范大学,2015.
XU Y L.The risk assessment scale of criminals in prison[D].Shanghai:Shanghai Normal University,2015.
[16] 孙岳芳,俞凯.假释罪犯人身危险性评估机制研究[J].法制与社会,2013(5):216-217.
SUN Y F,YU K.Research on the mechanism of the personal risk assessment of offenders on parole[J].Legal and Social,2013(5):216-217.
[17] 张雪霏.社区矫正中人身危险性评估的三阶段划分及应用[J].开封教育学院学报,2015,35(10):259-260.DOI:10.3969/j.issn.1008.9640.2015.10.123.
ZHANG X F.Three stage division and application of personal risk assessment in community correction[J].Journal of Kaifeng Institute of Education,2015,35(10):259-260.DOI:10.3969/j.issn.1008.9640.2015.10.123.
[18] 王茜,张刚景.实现单敏感属性多样性的微聚集算法[J].计算机工程与应用,2015,51(11):72-75.DOI:10.3778/j.issn.1002-8331.1306-0317.
WANG Q,ZHANG G J.Microaggregation algorithm for single sensitive attribute diversely[J].Computer Engineering and Applications,2015,51(11):72-75.DOI:10.3778/j.issn.1002-8331.1306-0317.
[19] 童云海,陶有东,唐世渭,等.隐私保护数据发布中身份保持的匿名方法[J].软件学报,2010,21(4):771-781.DOI:10.3724/SP.J.1001.2010.03466.
TONG Y H,TAO Y D,TANG S W,et al.Identity-reserved anonymity in privacy preserving data publishing[J].Journal of Software,2010,21(4):771-781.DOI:10.3724/SP.J.1001.2010.03466.
[20] SWEENEY L.k-anonymity:A model for protecting privacy[J].International Journal of Uncertainty,Fuzziness and Knowledge-Based Systems,2002,10(5) (2002):557-570.
[21] DWORK C,MCSHERRY F,NISSIM K,et al.Calibrating noise to sensitivity in private data analysis[J].Theory of Cryptography,2006,3876:265-284.DOI:10.1007/11681878-14.
[22] MCSHERRY F,TALWAR K.Mechanism design via differential privacy[Z].48th Annual IEEE Symposium on Foundations of Computer Science,Washington,2007.
[23] HE X,MACHANAVAJJHALA A,DING B.Blowfish privacy:tuning privacy-utility trade-offs using policies[Z].Proceedings of the 2014 ACM SIGMOD international conference on Management of data,New York,2014.DOI:10.1145/2588555.2588581.
[24] 黄灿.数据发布中隐私保护关键技术的研究[D].南京:南京航空航天大学,2010.
HUANG C.Research on key technologies of privacy protection in data publishing[D].Nanjing:Nanjing Uni-versity of Aeronautics and Astronautics,2010.
[25] 唐世渭,童云海.数据仓库技术在金融行业的深度应用和发展趋势[J].中国金融电脑,2010(7):22-25.
TANG S W,TONG Y H.Advanced application and development trend of data warehouse technology in financial industry[J].China Financial Computer,2010(7):22-25.
[26] 孙培梁.智慧监狱[M].北京:清华大学出版社,2014.
[27] 赵彦云,田茂再,吴延科,等.大数据时代统计学的重构与创新[J].统计研究,2015,32(2):3-9.
ZHAO Y Y,TIAN M Z,WU Y K et al.Reconstruction and innovation of statistics in the era of big data[J].Statistical Research,2015,32(2):3-9.
[28] 吉根林,赵斌.面向大数据的时空数据挖掘综述[J].南京师大学报(自然科学版),2014,37(1):-1-7.
JI G L,ZHAO B.A Survey of spatiotemporal data mining for big data[J].Journal of Nanjing Normal University(Natural Science Edition),2014,37(1):1-7.
[29] HAN J W,KAMBER M,PEI J.数据挖掘概念与技术[M].北京:机械工业出版社,2015.
[30] 易锦,罗峋,凹建勋,等.基于马尔科夫链的软件故障分类预测模型[J].中国科学院大学学报,2013,30(4):562-567.DOI:10.7523/j.issn.2095-6134.2013.04.019.
YI J,LUO X,AO J X,et al.Software fault classification prediction model based on Markov chain[J]Journal of University of Chinese Academy of Sciences,2013,30(4):562-567.DOI:10.7523/j.issn.2095-6134.2013.04.019.
[31] 高志伟,姚尧,饶飞,等.基于漏洞严重程度分类的漏洞预测模型[J].电子学报,2014,41(9):1784-1787.DOI:10.3969/j.issn.0372-2112.2013.09.018.
GAO Z W,YAO Y,RAO F,et al.Predicting model of vulnerabilities based on the type of vulnerability severity[J].Chinese Journal of Electronics,2014,41(9):1784-1787.DOI:10.3969/j.issn.0372-2112.2013.09.018.
[32] 孙菲菲,曹卓,肖晓雷.基于随机森林的分类器在犯罪预测中的应用研究[J].情报杂志,2014,33(10):148-152.DOI:10.3969/j.issn.1002-1965.2014.10.025.
SUN F F,CAO Z,XIAO X L.Application of an improved random forest based classifier in crime prediction domain[J].Journal of Intelligence,2014,33(10):148-152.DOI:10.3969/j.issn.1002-1965.2014.10.025.
[33] 李欣海.随机森林模型在分类与回归分析中的应用[J].应用昆虫学报,2013,50(4):1190-1197.DOI:10.7679/j.issn.2095-1353.2013.163.
LI X H.Using random forest for classification and regression[J].Chinese Journal of Applied Entomology,2013,50(4):1190-1197.DOI:10.7679/j.issn.2095-1353.2013.163.
(责任编辑:孟素兰)
Prediction of the risk of offenders based on big data
MA Guofu,WANG Zixian,MA Shengli
(Department of Information Management,The Central Institute for Correctional Police,Baoding 071000,China)
Based on the analysis of current status of offenders recidivism prediction and risk assessment,we proposed an architecture system of identification and prediction of the risk of offenders based on big data.Aiming at different value density and different data types,in the model layer of the system,we described application algorithm of identification and prediction of offenders risk for the statistical model,outlier detection model,integrated classification model of architecture system.In particular,using R software package,we conducted integrated classification identification and prediction experiments,and gives the classification prediction error.The architecture system of identification and prediction of the risk of offenders is based on big data,can realize personalized and accurate early warning for offenders risk,and provide a reliable guarantee for the safety of offenders supervision in the big data era.
risk assessment;identification;prediction;big data;algorithm
10.3969/j.issn.1000-1565.2016.06.014
2016-01-03
教育部人文社会科学研究规划基金项目(14YJAZH055);中央司法警官学院青年教师学术创新团队资助项目
马国富(1974—),男,河北保定人,中央司法警官学院副教授,主要从事信息安全、机器学习方向研究.E-mail:magf2003@126.com
TP393.08
A
1000-1565(2016)06-0657-10
猜你喜欢
计算机与现代化(2022年10期)2022-10-18
化学工业与工程(2022年1期)2022-03-29
小资CHIC!ELEGANCE(2021年36期)2021-10-15
有色设备(2021年4期)2021-03-16
中国特种设备安全(2019年10期)2020-01-04
社会生活探索(2019年0期)2019-05-21
小型微型计算机系统(2018年8期)2018-09-07
环球时报(2017-02-23)2017-02-23
方圆(2016年5期)2016-03-16
中国房地产业(2016年9期)2016-03-01
