
高校图书馆资源发现系统中文检索性能比较分析
2017-01-04 05:33:12寇晶晶贾君枝
国家图书馆学刊 2016年6期
寇晶晶 贾君枝
高校图书馆资源发现系统中文检索性能比较分析
寇晶晶 贾君枝
对不同资源发现系统的检索性能进行比较分析,可以发现系统间的差异,为高校选择合适的资源发现系统提供一定的依据。以“985工程”高校普遍使用的五种资源发现系统Primo、Summon、EDS、Find+和指针搜索作为选择研究对象的依据,选取应用各系统的高校图书馆作为调查对象,从检索功能和检索效果角度对系统的性能进行比较分析,发现各资源发现系统之间在检索功能和检索效果上存在一定的差异,高校应根据自身需求合理选择资源发现系统。表12。参考文献9。
高校图书馆 资源发现系统 检索性能
1 引言
近年来,飞速发展的计算机和网络信息技术使得信息资源的种类日益复杂,资源量日益庞大,图书馆资源检索开始面临更多的难题和挑战。为了让用户能够以较少的时间准确地检索到符合自身需求的资源,图书馆不断地尝试实现精准的资源整合检索,从早期致力于本馆馆藏数字资源的OPAC系统、数据库导航系统到资源整合系统[1],再到现在的资源发现系统。资源发现系统的检索性能关乎用户的检索体验和满意度,本文旨在应用适宜的信息检索评价指标,设定查询主题,从检索功能和检索效果角度对不同的资源发现系统的性能进行比较分析,以对图书馆进行资源发现系统的选择与更新提供参考借鉴。
2 资源发现系统样本选择
资源发现系统是在元数据的基础上将图书馆各种数字资源整合到统一检索平台,从而为用户提供快速方便检索服务的一种跨数据库跨平台的检索系统,具有内容聚合、整合检索、结果集展示、一站式获取等特点。其资源主要来自于本地馆藏资源、电子期刊/数据库、数字资源和开放获取资源等,包括图书、期刊、电子书、期刊文章、学位论文、多媒体资源、报纸文章等多种类型。
目前,国外的资源发现系统主要有 EDS、Primo、Summon、WorldCat Local四种;国内主要有e读、读秀、超星学术发现系统、指针搜索、百链、EBSCO&南大数图Find+、CNKI学术搜索等[1]。
由于e读、CNKI学术搜索、百链等应用较普遍,较难体现出图书馆资源发现系统使用的差异性,因而本文对除上述外的其他资源发现系统进行了调研,对国内“985工程”高校图书馆资源发现系统的调查显示(截止到2016年2月6日),全国39所“985工程”高校中,拥有资源发现系统的高校数量由2013年的25所[1]上升为39所,覆盖率达到100%,具体使用情况如表1所示。
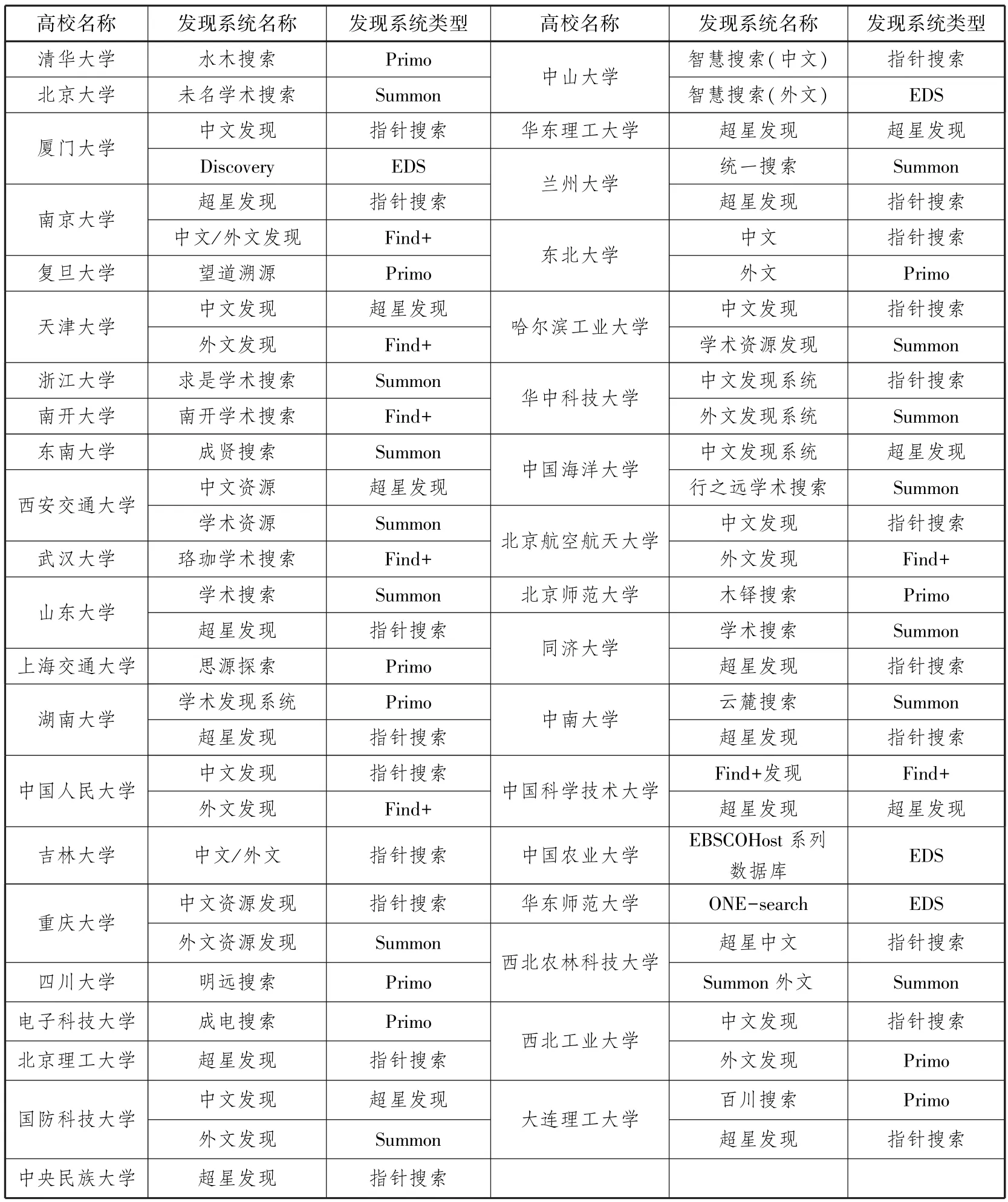
表1 国内“985工程”高校图书馆资源发现系统使用情况
根据资源发现系统的可访问程度,本文选取Primo、Summon、EDS、Find+和指针搜索五种系统分别在清华大学、北京大学、中山大学、南京大学和厦门大学五所高校的应用为比较对象。
3 图书馆资源发现系统检索功能分析
检索功能是资源发现系统的核心,决定了其能否将资源全面、准确地揭示给用户[2],主要包括:检索字段的设置,提供的检索类型、检索策略、检索限定以及检索结果的显示方式等。这些功能存在与否、其完备程度及合理性将影响系统的可用性和易用性,与检索效果密切相关,关系到系统满足用户需求的程度,是反映检索系统性能的重要依据。因此本研究从检索字段、检索类型、检索策略、检索限定以及检索结果五个方面,对高校图书馆资源发现系统的检索功能进行调查分析,详见表2。
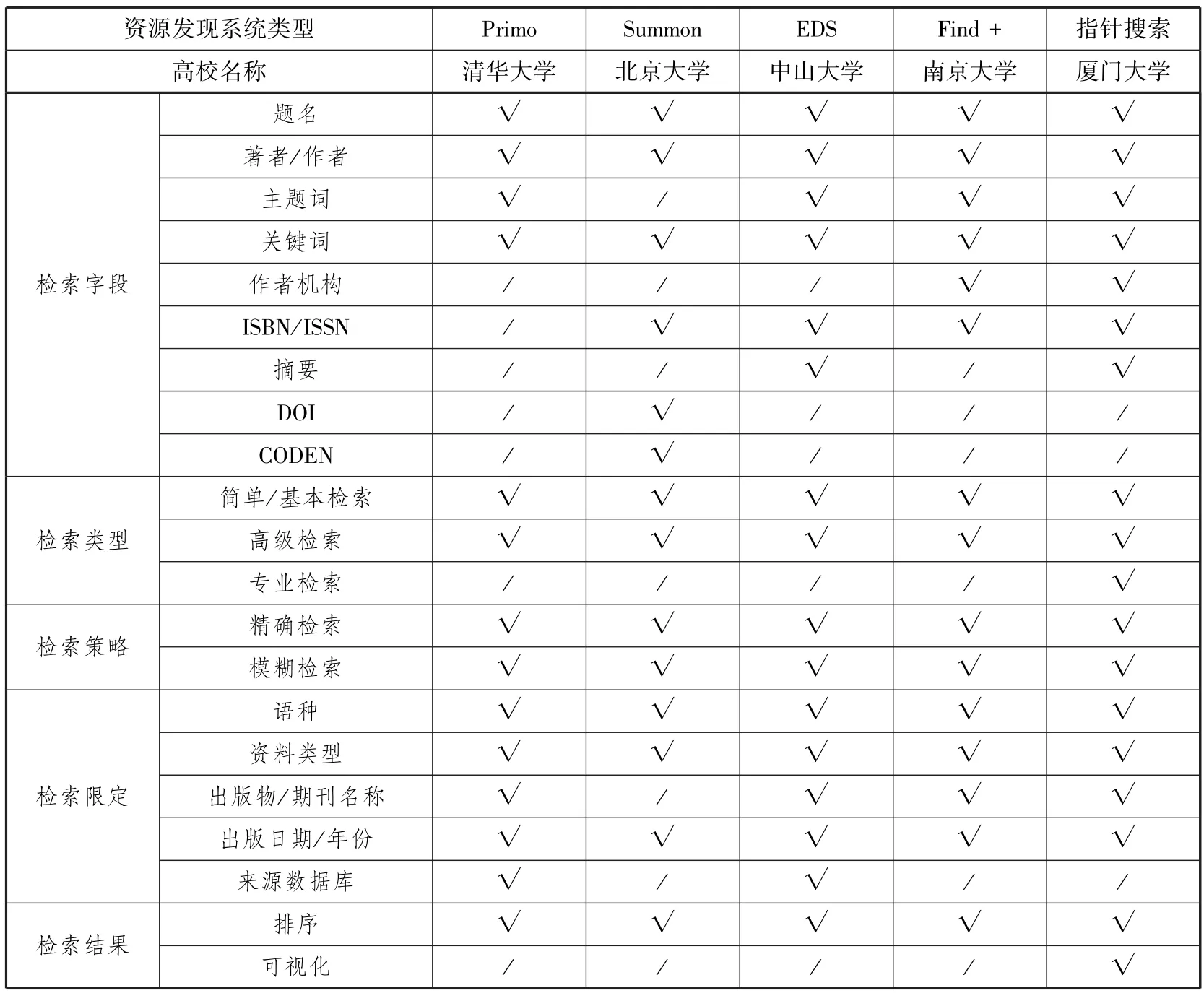
表2 五所高校图书馆资源发现系统检索功能
从表2内容可以看出:
(1)检索字段方面:五所高校的资源发现系统均具有的检索字段为题名、著者/作者和关键词。清华大学的水木搜索包含的检索字段最少;北京大学的资源发现系统不具有主题词检索字段,但却在DOI(数字对象唯一标识符)、CODEN(国际刊名代码)等字段上优于其他系统;中山大学的EDS系统和厦门大学的指针搜索还提供了摘要检索字段。此外,只有南京大学和厦门大学的系统提供了作者机构检索字段。
(2)检索类型方面:五所高校的资源发现系统均提供了简单(或基本)检索和高级检索两种,而厦门大学的指针搜索发现系统还提供了专业检索,即用户可以根据自身需要制定检索式。相较于高级检索的固定字段和固定逻辑关系检索,专业检索增加了检索的灵活性。进入各高校资源发现系统主页会发现,相对于其他资源发现系统来说,北京大学采用Summon系统而形成的“未名学术搜索”在检索界面和风格上更趋向于一站式检索,界面也更加简洁,增强了系统易用性。
(3)检索策略方面:五所高校均提供精确检索和模糊检索,但提供的方式不尽相同。例如,清华大学的水木搜索在“检索帮助”中说明:可使用半角双引号进行精确匹配;而南京大学的资源发现系统则是提供了“精确匹配”勾选框,更加方便读者进行模糊或精确检索。
(4)检索限定方面:虽然五所高校的资源发现系统均提供语种、资料类型和出版日期/年份的检索限定条件,但各限定条件下的细分项存在一定差别。例如,北京大学的资料类型提供的种类较多,分类详细,包括案例、百科、报告、报纸、报纸文章、标准、参考文献、抄本、出版物、技术报告、简讯、讲座、乐谱、图书馆馆藏、期刊文章等在内的四十多种资料类型限定;而清华大学仅提供图书、文章、期刊、图片和音像资料5种,中山大学的资料类型也只提供了期刊、图书、全文、目录、图像、同行评审6种。此外,北京大学不提供出版物/期刊名称和来源数据库限定,而南京大学、厦门大学仅不提供来源数据库限定。
(5)结果显示和筛选方面:北京大学在显示内容和精炼检索结果这两个选项前特别设置了多选框,这样读者就可以根据自己的需要更为灵活地对显示内容进行控制;“未名学术搜索”还自动提供文献的摘要部分,有助于读者更加直接地判断系统返回的结果是否为自己所需。而清华大学的“水木搜索”则具有更加自主化的页面,并没有将所有信息一并呈现在初始页面上,而是给予用户一定的选择权,用户可以根据需要在检索结果页面上点击相关链接以得到更多的详细信息。此外,厦门大学的资源发现系统还提供了可视化显示,用户可以通过指针资源发现系统得到近年来相关主题的发文趋势图、学科分类分布图、期刊分类分布图等。而在排序方式中除均包括相关性和日期排序外,清华大学的排序方法还包括作者、题名、受欢迎度等,南京大学还包括核心期刊排序。
4 图书馆资源发现系统检索效果分析
检索效果是以检索结果为立足点,通过对响应时间、查全率、查准率、重复率等指标的分析,反映检索结果能在多大程度上满足用户的需求。传统意义上的响应时间是指从用户发出检索指令,到检索系统返回检索结果所需要的时间,响应时间与用户的检索体验密切相关。一般而言,响应时间越短,用户负担越小,用户体验也相对越好。查全率和查准率由J.W.Perry和A.Kent提出[3]。查全率是用于刻画检索系统在执行某一检索指令时,检出相关文献能力的一种指标,传统的计算方法是指检索出的相关信息量与系统中所有相关信息量的比值[4];查准率是用于刻画检索系统执行某一检索指令时检索精确度的指标,计算方法为检出的相关文献量与检出的文献总量的比值[4]。对于检索系统来说,查准率和查全率越高系统的性能越好,越能将完备度高、准确率高的结果返回给用户。重复率是指检索结果中重复的结果数占全部检索结果数的百分比[5],也是反映检索系统性能的一个重要指标。较强的去重功能能够自动将相同的链接过滤掉,帮助读者提高检索效率。去重功能越强大,所得到的重复率就越低。
4.1 检索主题的确定
本文选取如下四个主题分别在这五所高校图书馆的资源发现系统中进行检索,比较各系统的检索效果。
(1)Topic1:从引文角度分析高校科研水平(检索词:高校 引文 科研水平)
(2)Topic2:高校图书馆管理系统的使用情况(检索词:高校 图书馆 管理系统 使用)
(3)Topic3:知识管理在中小企业中的应用(检索词:知识管理 中小企业 应用)
(4)Topic4:搜索引擎性能的评价体系研究(检索词:搜索引擎 性能 评价)
4.2 检索效果比较
(1)响应时间
由于响应时间会受到网络和检索工具本身反应速度的影响,因此本文将五所高校的检索实验选择在相同网络,同一计算机检索终端以及相同地点进行,以减少不必要的误差。表3为各高校图书馆资源发现系统关于各主题的响应时间和平均响应时间。
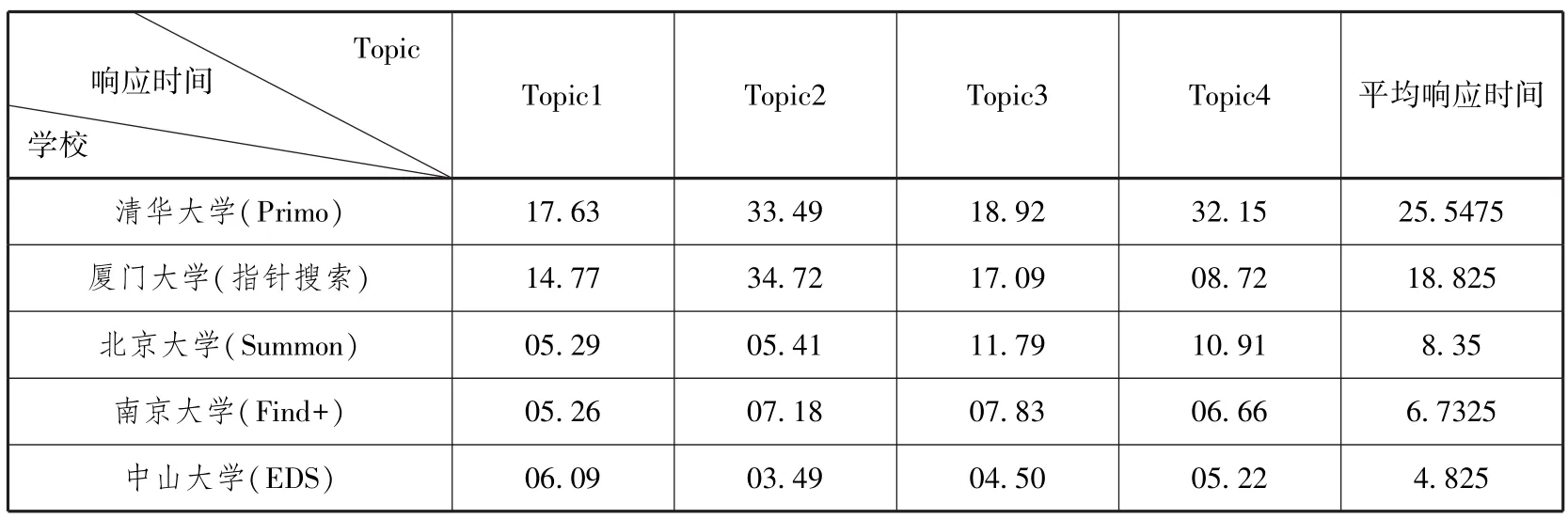
表3 五所高校图书馆资源发现系统的响应时间(单位:秒)
如表3所示,五所高校资源发现系统的平均响应时间从长到短依次为清华大学、厦门大学、北京大学、南京大学和中山大学,即清华大学的“水木搜索”和厦门大学检索系统的响应时间较长,可能会增加用户检索时的负担。而从上表中也可以看出,清华大学和厦门大学的资源发现系统在四个主题的检索响应时间上相差较多,厦门大学的检索系统最为明显,最长的响应时间为34.72秒,而最短的响应时间为8.72秒。中山大学的资源发现系统平均响应时间最短。
(2)相对查准率
1)相对查准率计算方法
大数据时代的到来,使得信息检索系统检索结果超乎想象的庞大,在这种情况下,如果用传统的方法来计算查准率,无疑是不可能的。相关调查显示,用户在进行信息检索时,仅有12.1%的用户会查看20条以上的检索结果,也就是说87.9%的用户只会查看不到20条检索结果[6],甚至更少。因此,本文参考美国研究人员H.Vernon和Jaideep Srivstava的“前X命中记录查准率”[7]计算方法来考察图书馆资源发现系统的查准率(以下称为相对查准率),即首先将前20条检索记录分为三组,1 -3为第一组,所占权重为20;4-10为第二组,所占权重为17;11-20为第三组,所占权重为10,而20以后的返回记录可以看成第四组,但是其所占的权重默认为0,则当系统返回的记录数多于20条时,查准率计算的分母为279。若检索结果返回的记录数不足20,则分母为279-(20-n)∗10[8](n为实际返回的检索记录数,本文五所高校资源发现系统返回的检索记录数均大于10)。
2)相关度判断
根据检索结果对用户的有用程度,本文将相关性范畴划分为四类,给每一类赋予不同的相关度系数,本文设定相关度系数的值域为[0,1],显然非常有用和完全没用的系数取值分别为1和0,而对较为有用和部分有用两类的系数取值则相对自由,为显示区分度,本文在完全没用(系数为0)和非常有用(系数为1)的基础上加减0.3,得到中间两类的相关度系数,则相关度系数最终设为1、0.7、0.3、0(重复链接中第二次出现的记录的相关度系数默认为0),具体见表4。

表4 相关度判断
这样在相对查准率计算方法和相关度判断方法的基础上,就得出如下计算方公式:

该公式为当检索返回记录数多于20条时相对查准率的计算公式,i=1,2,3……20,其中Wi表示第i条记录所属分组的权重,Ri表示该条记录的相关系数。而当检索返回记录数不足20条时,计算公式为:

其中,分母的取值在上文中已经提到,n表示该检索所返回的记录数,Wi和Ri的含义不变。
3)相对查准率计算
表5—9分别对应清华大学、厦门大学、北京大学、南京大学和中山大学的资源发现系统检索结果相关度判断。
根据表5—9计算各高校资源发现系统的相对查准率,结果如表10所示(计算结果保留到小数点后6位)。
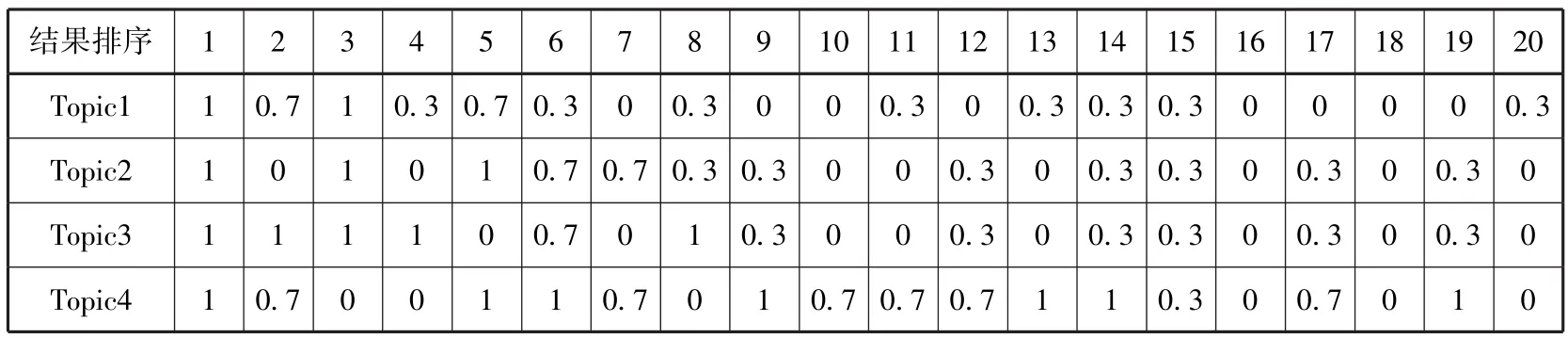
表5 清华大学资源发现系统相关度判断
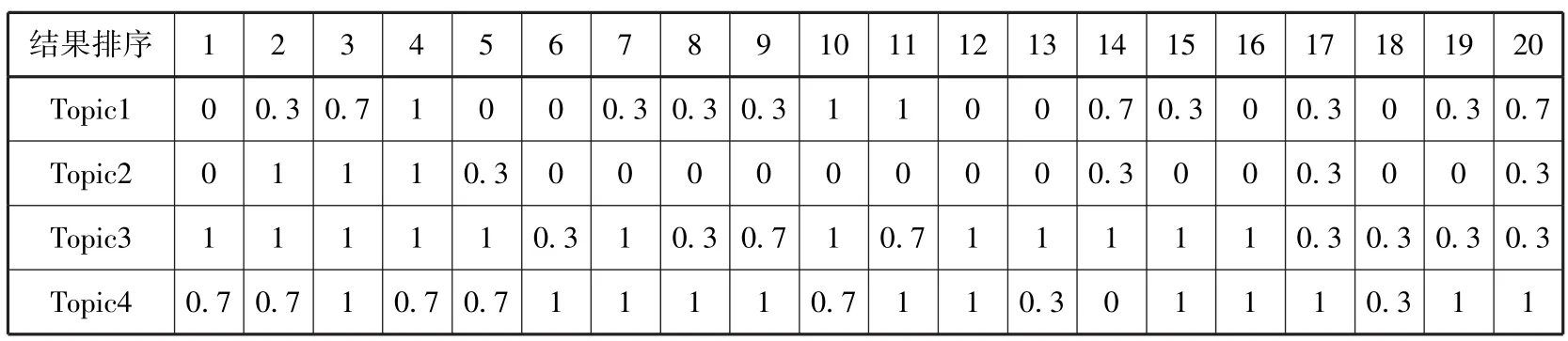
表6 厦门大学资源发现系统相关度判断

表7 北京大学资源发现系统相关度判断

表8 南京大学资源发现系统相关度判断
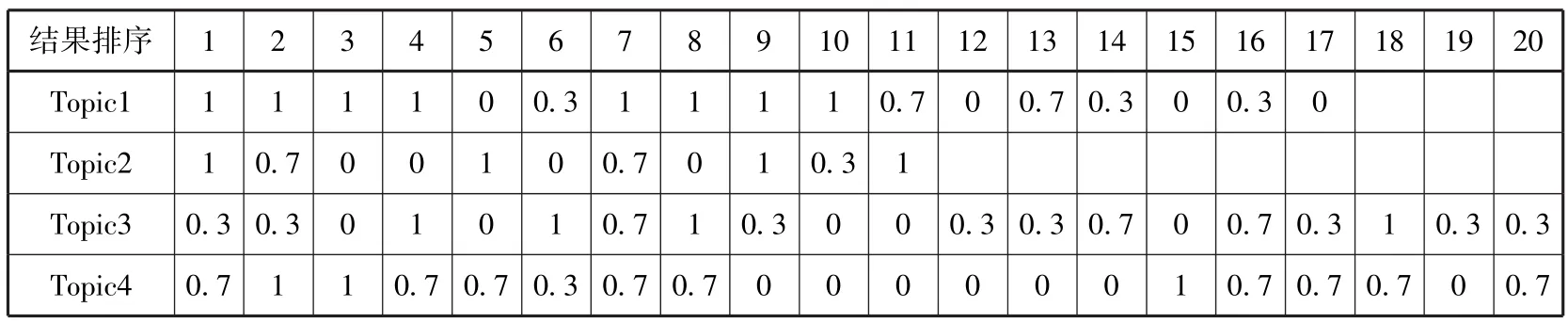
表9 中山大学资源发现系统相关度判断

表10 五所高校图书馆资源发现系统相对查准率
表10反映的是五所高校图书馆资源发现系统的相对查准率的计算结果,其平均查准率排名(从高到低)依次为厦门大学、北京大学、南京大学、中山大学和清华大学,可以看出几所高校所使用的资源发现系统的查准率还是存在一定差别的。
(3)相对查全率
1)相对查全率的计算方法[9]:设在一个相对较短的时间内,Pm(m=1,2,3,4,5)为资源发现系统m,Xn(n=1,2,3,4)为第n个主题,那么就可以形成一个矩阵Z。矩阵Z中每一个元素pmn表示第n个主题在第m个资源发现系统上所得到的返回记录数,即检索结果数。假设pn′=Max(p1n,p2n,p3n,p4n,p5n),即同一主题在五种资源发现系统中得到返回记录数最多的系统;qn′=Min(p1n,p2n,p3n,p4n,p5n),即同一主题在五种资源发现系统中得到返回记录数最少的系统。这样就会出现A和B两种理想情况,其中A表示在所有主题的检索中都能得到最多返回记录数的系统(Pbest),而B则表示在所有主题的检索中都能得到最少返回记录数的系统(Pworst)。当然这两种情况都是理想状态,从客观的角度来说,没有一个资源发现系统会那么好,也没有一个资源发现系统会那么糟糕。但是我们可以根据某一发现系统与最好和最坏两种理想系统的接近程度,来衡量它的查全率。
pm=∑(pn′-pmn)(m=1,2,3,4,5;n=1,2,3,4),得到的值表示第 m个资源发现系统与Pbest的接近程度,pm越小,说明与理想状态越接近;qm=∑(pmn-qn′)(m=1,2,3,4,5;n=1,2,3,4),表示第m个系统远离Pworst的程度,所得到的值越大,则表明所对应的系统的查全率越高。
2)相对查全率


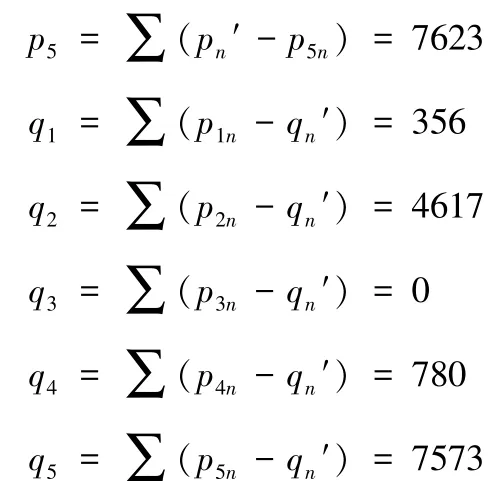
最终相对查全率的计算结果如表11所示。
从表11中可以看出,相对查全率的计算结果中出现了上文中所说的理想状态,这是由中山大学的EDS发现系统对外文发现能力较强,而对中文的发现能力较弱造成的。就本次检索而言,相对查全率的排名(从高到低)依次为北京大学、厦门大学、南京大学、清华大学和中山大学。
(4)重复率
在本次检索实验中,五所高校在四个主题检索实验中的重复情况如表12所示。其中,重复数是指同一检索主题下,同一链接出现的次数的总和。如检索主题1,得到的检索结果中A和B是相同的,C和D是相同的,那么基于这个主题的检索重复数就是4。而总重复数是指四个检索主题下总共的重复数,平均重复率是用总重复数除以四个主题总的参评记录数。假设总重复数为X,根据只查看前20条记录的方法,若每个主题返回的结果数大于20,则其重复率为X/(20∗4);若有的主题返回的记录数小于20,则分母应改成真实的记录数之和。
从表12可以看出,五所大学的资源发现系统均虽具有一定的去重功能,单就此次检索实验来说,除去中山大学外(中山大学的EDS由于是外文发现系统,因此对中文主题的检索受到一定的限制),其他高校资源发现系统的平均重复率均在5%以上。尤其是清华大学的资源发现系统,重复率在五所高校中最高,达25%,其去重功能最弱,可能会给读者检索带来较多不便。
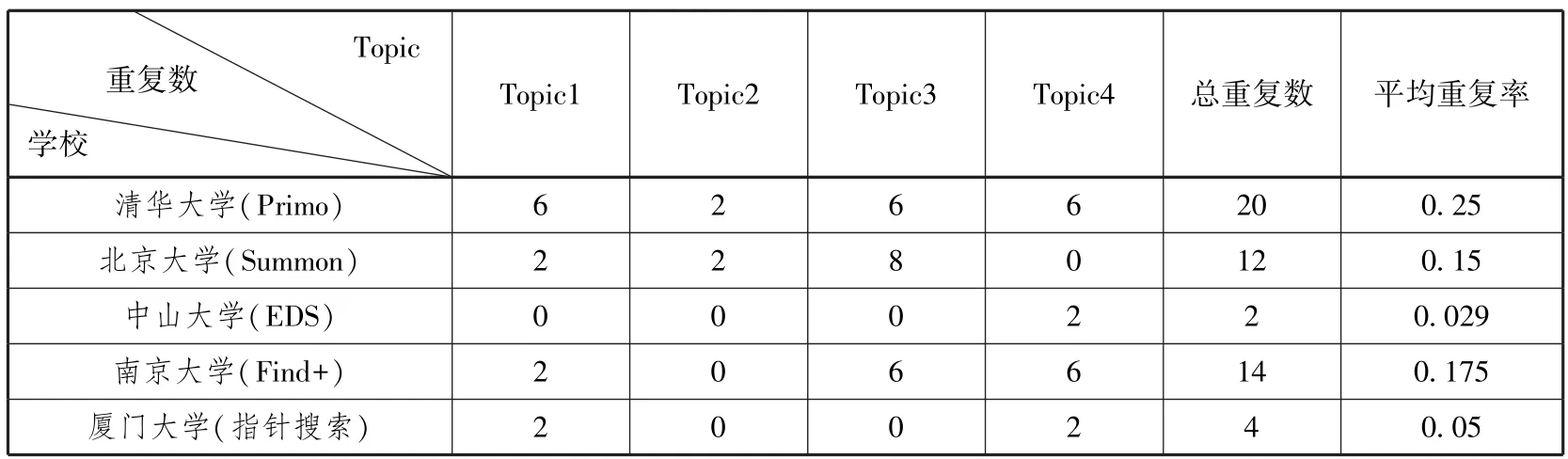
表12 五所高校图书馆资源发现系统的重复记录(单位:个)
5 结语
通过对Primo、Summon、EDS、Find+和指针搜索五种类型的图书馆资源发现系统进行实证研究得到如下结论:
(1)五种资源发现系统在检索功能上差别并不大,但是厦门大学所使用的指针搜索发现系统在可视化方面具有较大优势,在显示检索结果的同时,还提供了可视化显示,用户可以通过资源发现系统得到近年来相关主题的发文趋势图、学科分类分布图、期刊分类分布图等。
(2)在检索效果方面,虽然中山大学的EDS属于外文发现系统,但其对中文主题也有一定的发现能力。而从响应时间、查准率、查全率、重复率四个维度的计算结果可以看出,在检索效果方面,各资源发现系统之间存在一定差别。
由于受一些因素的限制,本文仍存在以下几个问题:(1)受访问权限的影响,中山大学的EDS发现系统对中文资源的检索能力不够,从而使得相对查全率和相对查准率的计算受到影响。(2)虽然文中采取了多个主题查准率结果求取平均值的计算方法,在一定程度上提高了查准率计算结果的准确性,但是由于检索实验返回结果的相关度判断受到判断者主观因素的影响,其计算结果仍存在一定的局限性。
1 胡玮.“985工程”高校图书馆资源发现系统现状分析和思考[J].图书馆学研究,2013(16).
2 秦鸿,等.三种发现服务系统的比较研究[J].大学图书馆学报,2012(5).
3 邓汉城.检全率与检准率辨异[J].情报理论与实践,1998(1).
4 黄崑.网络信息检索的检全率、检准率影响因素研究[J].图书情报工作,2002(3).
5 张文良.网络环境下的信息检索系统评价[J].科技情报开发与经济,2010(12).
6 邓小昭,等.网络用户信息行为研究[M].北京:科学出版社,2010:44.
7 H.Vernon Leighton,Jaideep Srivastava.Precision Among World Wide Web Search Services(Search Engines):Alta Vista,Excite,Hotbot,Infoseek,Lycos[EB/OL].[2016-02-20].http:∥www. winona.msus.edu/library/webind2/webind2.htm.
8 张军华,韩全会.中文五大综合搜索引擎主要性能测评[J].情报科学,2008(9).
9 于彩云.搜索引擎Yahoo的性能评价及评价指标的选择[J].现代情报,2007(2).
(寇晶晶 中国科学院文献情报中心2015级硕士研究生,贾君枝 教授 山西大学经济与管理学院)
Comparative Analysis on the Chinese Retrieval Performance of Resource Discovery Systems of Academic Libraries
Kou Jingjing Jia Junzhi
The paper aims to find differences between different systems and provides some basis for universities to help them choose appropriate resource discovery system.Taking five kinds of library resource discovery systems used by“985 Project”universities as the basis,including Primo,Summon,EDS,Find+and Super Star Found,this paper selects some academic libraries that use these systems as the research objects,and then compares and evaluates these university libraries'resource discovery systems from the point view of retrieval function and effect.There are some differences between them,and universities should choose appropriate resource discovery system according to their own needs.12 tabs.9 refs.
Academic Library;Resource Discovery System;Retrieval Performance
2016-07-18
猜你喜欢
校园英语·下旬(2019年11期)2019-11-28 02:04:21
现代电子技术(2018年20期)2018-10-24 04:39:04
现代电子技术(2018年16期)2018-08-21 02:57:42
现代情报(2018年11期)2018-01-07 09:41:14
老年教育(老年大学)(2017年12期)2017-12-26 03:58:44
现代电子技术(2017年23期)2017-12-20 13:23:31
计算机应用(2016年10期)2017-05-12 11:02:20
法语学习(2015年3期)2015-04-17 07:08:16
中医文献杂志(2015年4期)2015-03-16 09:22:46
计算机光盘软件与应用(2013年6期)2013-08-08 08:26:50
