
基于Spark的Apriori并行算法优化实现
2017-01-04 05:32杨显华
郑州大学学报(理学版) 2016年4期
王 青, 谭 良,2, 杨显华
(1.四川师范大学 计算机科学学院 四川 成都 610101; 2.中国科学院 计算技术研究所 北京 100190;3.四川省计算机研究院 四川 成都 610041)
基于Spark的Apriori并行算法优化实现
王 青1, 谭 良1,2, 杨显华3
(1.四川师范大学 计算机科学学院 四川 成都 610101; 2.中国科学院 计算技术研究所 北京 100190;3.四川省计算机研究院 四川 成都 610041)
针对传统Apriori算法处理速度和计算资源的瓶颈,以及Hadoop平台上Map-Reduce计算框架不能处理节点失效、不能友好支持迭代计算以及不能基于内存计算等问题,提出了Spark下并行关联规则优化算法.该算法只需两次扫描事务数据库,并充分利用Spark内存计算的RDD存储项集.与传统Apriori算法相比,该算法扫描事务数据库的次数大大降低;与Hadoop下Apriori算法相比,该算法不仅简化计算,支持迭代,而且通过在内存中缓存中间结果减少I/O花销.实验结果表明,该算法可以提高关联规则算法在大数据规模下的挖掘效率.
Spark; 并行化; 数据挖掘; 关联规则; Apriori
0 引言
关联规则挖掘是用来描述事物之间的联系和挖掘事物之间的相关性,它是在数据库中搜索两个项目之间存在的显示或者隐式关系,有助于管理和决策.Apriori算法是最为经典的关联规则挖掘算法,该算法的核心是生成最大项目集,通过迭代方式逐层搜索频繁项集,直至没有更大项目集生成,但每次搜索都需要完整地扫描一次数据库,这种传统串行方式效率非常低.随着云计算技术的发展,Hadoop在分布式集群环境下对离线批处理作业表现出优势,但由于其处理数据必须先存储后运算,不能同时进行并行化操作,影响数据处理的实时性.而Spark拥有Map-Reduce框架所有的优点,且所有计算结果都可以保存在内存中,它的快速数据处理能力可以有效减轻海量数据下发现挖掘任务的压力,提高迭代运算的效率.基于Spark下的并行Apriori算法可以解决传统关联规则算法遇到的难题、单一并行化计算模式的瓶颈以及Hadoop平台不能很好支持迭代计算的缺陷.因此,本文结合Spark计算平台,提出了基于Spark的Apriori并行优化算法,提高了关联规则算法在大数据规模下的挖掘效率.
1 相关工作
为了提高Apriori算法的性能,文献[1]在最大项集和闭项集的基础上,提出了元项集挖掘算法,减少频繁项集结果的冗余;文献[2]构建了基于领域知识的项相关性模型,简约划分数据库并映射至一种压缩树形结构中,缩小事务规模;文献[3]利用缓存数据库提高Apriori算法的效率.这些算法在事务集小且事务维度不高的情况下,能发挥较好的作用.但随着事务集越来越大、事务维度越来越高,上述算法性能明显降低.
随着云计算技术和大数据分析处理技术的兴起,为了提高挖掘效率,Apriori算法优化主要围绕并行化进行研究[4],包括MPI并行化以及基于Hadoop平台的并行化研究.文献[5-6]把云计算技术的两个重要步骤Map和Reduce,分别引入到Apriori算法的连接和剪枝步骤中,并对优化算法进行Map-Reduce模型并行化,达到了Apriori算法并行化的目的.但Apriori算法需要多次迭代才能发现频繁项集,当采用Hadoop并行化的Apriori算法时,需要为每次迭代产生一个新的Map-Reduce去读取HDFS上的中间结果,产生额外负载.文献[7]提出了将Apriori 基于Spark 进行并行化实现的YAFIM算法,解决了基于Hadoop并行化存在的编程模式问题,性能明显提高,但YAFIM算法也存在经典Apriori算法本身的一些问题.文献[8]提出了Spark 平台上并行化的R-Apriori算法,但R-Apriori算法仅通过优化YAFIM算法的第二次迭代过程提高YAFIM的效率,仍然存在额外的I/O负载.因此,进行基于Spark的Apriori算法并行化优化具有研究意义.
2 基于Spark的Apriori算法优化(SP-Apriori)
2.1 Apriori算法简介
Apriori算法的主要思想是通过迭代的方法逐层搜索,用(K-1)项集去搜索大于最小支持度的K项集,直到没有满足条件的(K+1)项集生成.对于事物A、B,规则是否有效是由支持度ssupport(A→B)=P(A∪B)决定.Apriori算法具体步骤如下:
输入:数据集Datasets;最小支持度阈值mmin_support.
输出:K-项频繁集LK;
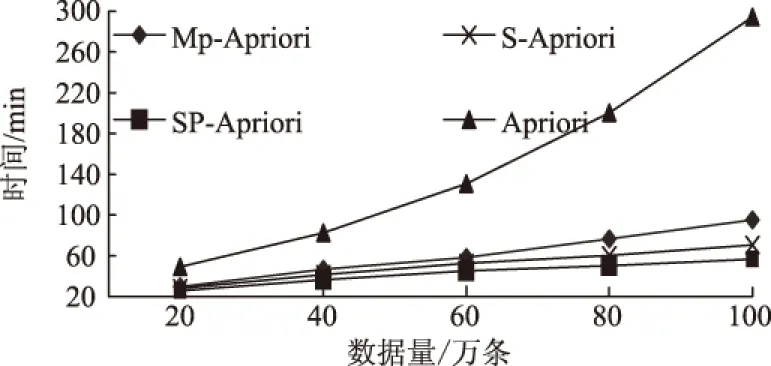
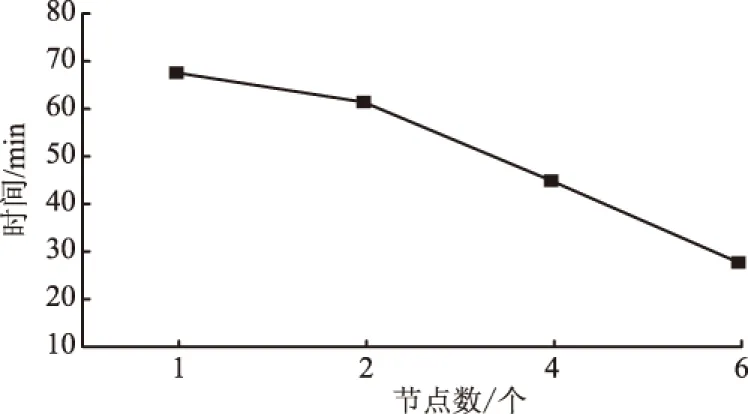
1) 首次扫描Datasets生成候选集C1,通过逐层扫描统计候选集中每个项集X的支持度ssupport,删除X.ssupport 2) 频繁集L1再进行自身连接生成候选集C2,再次通过逐层扫描Datasets,删除X.ssupport 3) 对K>2的每个候选集CK,重复2),最终得出最大频繁项集LK. 可以看出,算法效率非常低下,主要存在以下问题:① 资源消耗大.算法每次搜索都需要完整扫描一次数据库,挖掘海量数据时,CPU时间和内存消耗问题更加突出;② 规则挖掘模型较复杂.单一方式搜索候选集,挖掘海量数据时,候选集数量巨大,产生候选集模型无法适应大数据环境. 2.2 基于Spark的Apriori算法优化过程 2.2.1 Apriori算法的改进 对Apriori算法进行了如下改进:在挖掘过程中,利用频数表示支持度,易于比较并减少频繁计算支持度概率;利用组合策略得到总的规则类别,便于获得各项集kkey;利用此算法的两个重要性质(① 若X是频繁项集,则X的所有子集是频繁项集;② 若X是非频繁项集,则X的所有超集都是非频繁项集)去掉多余项集kkey来压缩搜索空间.改进Apriori算法的步骤描述如下: 1) 扫描事物数据库得到所有1-item项集K个,以及事物总数nnums. 2) 对各个1-item进行计数,记录频数最大的iitem并去除产生1项候选集C1. 3) 根据业务需求和经验设置关联规则阈值:mmin_support(最小支持度),即最小支持频数为mmin_sup=nnums*mmin_support. 4) 令i=1,i作为搜索第i项集的迭代控制变量,满足i 6) 所有候选集Ci频数nnum_Li满足规则(nnum_Li>mmin_sup)=>1项频繁项集Li. 7) 如果nnum_Li 8) 去掉频繁集Li中频数最小的i-item,产生有趣第i项频繁集Fi,令Li=Fi. 9) 对Li进行趋势(平稳、下降、上升、随机)分析=>Li,更新项集并存储,i++. 10) 逐次迭代5)~9)直到产生K项候选集CK,如果存在K+1项候选集,则继续迭代执行,如果不存在,则最终得到有趣K项频繁集LK,产生关联规则. 表1 K-项集与二进制对应关系Tab.1 The correspondence between K-item and binary 对于步骤5)~9),把传统算法抽象成循环迭代算法,每次搜索项集候选项集确定,迭代次数确定并小于K,它不仅减少了运行复杂度,且可以把每次搜索任务分摊到多个处理器上同时运行,便于并行化计算. 2.2.2 基于Spark的Apriori算法并行化设计 Spark引入弹性分布式数据集RDD数据模型,并整合了内存计算基元,支持节点集群将数据集缓存在内存中,缩短了访问延迟.除了能够提供交互式查询外,还可以优化迭代工作负载,当需要反复操作的次数越多、读取的数据量越大时,相对于Hadoop,Spark在性能方面更适用于需要多次操作特定数据集的应用场合.Spark是Map-Reduce的扩展,它提供两类操作:transformation(得到新的RDD)和action(得到结果)多种API,不再需要使用Hadoop唯一DataShuffle模式,编写程序更具灵活性,使上层应用开发效率提升数倍.Spark大数据编程模型如图1所示. 图1 Spark大数据编程模型 结合Spark特性,基于“分而治之”的思想,本文算法的并行化设计是把事物数据库均衡分发给多个子节点,以局部查找频繁项集、剪枝代替全局操作,避免全局查找出现内存无法容纳的问题,并且可以实时实现数据集计数、过滤支持度低的项集以及排序等,实现对整个挖掘频繁项集和生成规则以及评价规则等各个处理过程的并行化.并行化设计步骤如下: 1) Master利用Spark提供的算子ttextFile()扫描存储在HDFS上的事务数据库,即为一个RDD. 2) Worker利用CCount(rrdd,nnum)操作求1项集的集合L1和候选1项集C1. 3) RDD被平分成n个数据块,且这些数据块被分配到m个worker节点进行处理. 4) 根据worker节点上1-项Item, 采用优化算法步骤7)的方式生成所有局部K-项集Part_LK. 5) 通过函数f(iiter)=>iiter.ffilter(_>=MMax_ L1)对wworker中的所有数据进行过滤. 6) 设置关联规则标准的阈值最小支持度mmin_sup. 7) 根据Part_LK生成局部支持度频数,利用局部剪枝性质,删除局部支持度频数小于局部支持度阈值的项. 8) 利用mmap(wworker,CK)、rreduceByKey(wworker,CK)、ffilter(wworker,CK>mmin_sup)组合操作进行每一轮局部剪枝操作. 9) 针对剪枝触发提交job进行fforeachRDD(iiter.步骤8)=>aadd(wworker,CK)=>PPart_ LK局部连接,然后uunion(worker,PPart_ LK)=>CK进行全局连接. 10) 结合频繁项集时序性规则挖掘趋势进行filter(-,-)产生有趣频繁项集. 11) 全局ffilter(CK>mmin_sup)触发SparkContext产生有趣规则LK. 以上ttextFile,CCount,ffilter,mmap,rreduceByKey算子都是Spark为用户编程提供的接口API,其中f(iiter)函数是自定义迭代函数,去除小于支持度的项集. 2.2.3 基于Spark的Apriori算法的实现 迭代式Apriori算法并行化实现的核心是迭代调用transformation和action操作,每次迭代中利用上一次迭代结果来进行求解,算法并行化实现步骤如下: 输入:数据源路径iinpath;最小支持度阈值mmin_sup. 输出:K-项频繁集;K-项频繁集输出路径K-outpath. 1) 获取总事务集iitems=AApriori(iinpath)//构造函数,对数据源进行预处理. 2) 获取总事务数nnums=ggetNums(iitems)//计算1项集总类别数. 3) 获取1到K-项集K-items集,去掉mmaxCount(iitems)的1项集合//计算得到最大1项集. 4)K=1. 5)ooutpath=ggetFirstFreq(iinpath,K,nnums,mmin_sup)//从iinpath获得所有1项集L1,并将产生的L1=>C2输出到新的K-outpath中. 6) while(1){K-outpath=ggetKFreq(iinpath,ooutpath,nnums,mmin_sup) //通过数据源iinpath以及L1获得2-K项集L2-LK结果集 如果K-outpath为空,则退出 否则:K=K+1; 比对K-items集,去掉小于mmin_sup项集;ooutpath=K-outpath//作为下一次剪枝依据 }. 7) 各计算节点将频繁模式CK增加趋势:CK=CK->ttrend(C1,C2,…,CK) =>LK. 8) 通过uunion(K-outpath,mmin_sup)汇集到mmaster节点,得出全局关联规则集合. //子节点得到关联规则结果=>全局关联规则结果. 3.1 实验环境 采用两台PC电脑,其中1台为mmaster节点,同时也作为wworker节点,另外1台为wworker节点,共4个节点,通过交换机组成一个局域网.所用软件为Intellij+Hadoop+Spark,分别实现了传统Apriori算法,Hadoop Map-Reduce模式下Apriori改进算法(Mp-Apriori算法),Spark RDD模式下Apriori算法(S-Apriori算法),Spark RDD模式下Apriori改进算法(SP-Apriori算法).本实验数据由IBM数据生成器生成,由于实验硬件条件限制,数据量大小为1.12 G,事务平均长度为42 MB,共100个iitem项集,包括约100万条事务数据记录. 3.2 实验结果 对3.1节数据进行随机采样,在支持度 0.75下统计运行时间,采用子节点运行内存的50%来缓存RDD,在此基础上开展两组实验.实验一:采用传统Apriori算法以及保持4个节点不变的集群环境下的并行化Mp-Apriori算法、S-Apriori算法和SP-Apriori算法,在挖掘数据集大小不同的情况下,计算各个算法的运行时间,结果如图2所示.实验二:采用100万条数据集,增加一台机器,新增两个wworker节点,改变集群节点数目,测量节点可扩展性,分别测量节点数为 1, 2, 4, 6 时的SP-Apriori算法进行规则挖掘的执行时间,结果如图3所示. 图2 不同算法的运行时间Fig.2 The running time of different algorithms 图3 不同节点数的运行时间Fig.3 The running time of different workers 由图2可知,并行化算法比传统串行Apriori算法的效率更高,随着数据量的增加,并行化算法时间开销平稳增加,而传统串行Apriori算法时间开销成倍增加,说明相对于传统串行方式,并行化更适合大数据环境;当事务数据量不大时,基于Spark和Hadoop的算法运行时间差距不大,但随着事务数据量的增加,基于内存计算的SP-Apriori算法直接从内存中读取迭代时所需中间结果,大大减少了Hadoop计算时所需I/O读取时间,Spark的优势越来越明显,改进的算法效果最好.由图3可知,随着数据节点数增多,算法执行时间不断缩短.数据节点也是影响算法效率的一个重要因素.因此,本文提出的优化对算法的性能有一定提高,同时随着节点数的增加、各节点内存容量变大以及对数据源进行预处理,算法的执行时间在理论上将大幅度减少. 结合Spark计算平台,实现了一种基于Spark的并行Apriori优化算法,提高了处理海量数据的效率,适用于生产环境中对实时性要求较高的应用.由于没有事先对数据集进行预处理,无效数据过多,使得内存利用率降低;没有改变数据的存储结构,在实验过程中发现仍然有数据集本身数十倍甚至上百倍大小的中间结果需要保存在内存中.在接下来的研究中,将对算法的预处理和改变事务存储结构进行深入研究,并对并行过程进行严谨证明和理论推导,同时也会探讨Spark平台对实际应用场景的适用性,以期获得理想效果. [1] 宋威, 李晋宏, 徐章艳, 等. 一种新的频繁项集精简表示方法及其挖掘算法的研究[J]. 计算机研究与发展, 2010, 47(2): 277-285. [2] 毛宇星, 陈彤兵, 施伯乐. 一种高效的多层和概化关联规则挖掘方法[J]. 软件学报,2011,22(12):2965-2980. [3] ASTHANA P, SINGH D. Improving efficiency of Apriori algorithm using cache database[J]. International journal of computer applications, 2013, 75(13):15-20. [4] 陈玉哲,赵明华,李军,等.基于移动agent和数据挖掘标准的分布式数据挖掘系统[J].郑州大学学报(理学版),2011,43(1):90-94. [5] 伊瑶瑶, 茅苏. Hadoop下的关联规则分析研究[J]. 计算机技术与发展,2015,25(9):84-88. [6] 刘木林, 朱庆华. 基于Hadoop的关联规则挖掘算法研究:以Apriori算法为例[J]. 计算机技术与发展,2016,26(7):1-11. [7] QIU H, GU R, YUAN C, et al. YAFIM: a parallel frequent itemset mining algorithm with Spark[C]// IEEE International on Parallel & Distributed Processing Symposium Workshops (IPDPSW). Phoenix, 2014: 1664-1671. [8] YANG S, XU G, WANG Z, et al. The parallel improved Apriori algorithm research based on Spark[C]//9th International Conference on Frontier of Computer Science and Technology. Dalian, 2015:354-359. (责任编辑:孔 薇) Optimization of Apriori Parallel Algorithm Based on Spark WANG Qing1, TAN Liang1,2, YANG Xianhua3 (1.CollegeofComputerScience,SichuanNormalUniversity,Chengdu610101,China; 2.InstituteofComputingTechnology,ChineseAcademyofSciences,Beijing100190,China; 3.SichuanInstituteofComputerSciences,Chengdu610041,China) In view of the bottleneck of traditional Apriori algorithm in processing speed and computing resources, and that Map-Reduce on Hadoop could not handle node failures, friendly support iterative calculation, and calculate based on memory issues ,a parallel association rule optimization algorithm based on Spark was proposed. The optimization algorithm only needed to scan the transaction database twice and it took advantage of Spark’s RDD storage structure. By comparing with the traditional Apriori and Apriori based on Hadoop, analysis showed that Apriori based on Spark more greatly reduced the number of scan database than that of traditional Apriori, and it used less I/O overhead than Apriori based on Hadoop, because it supported storing temporary results in memory and iterative calculation. Experimental results showed that Apriori based on Spark performed effectively on big data for mining association rules. Spark; parallel processing; data mining; association rule; Apriori 2016-07-23 国家自然科学基金资助项目(61373162);四川省科技支撑项目(2014GZ007). 王青(1992—),女,湖南衡阳人,硕士研究生,主要从事大数据处理与分析、数据挖掘以及机器学习研究;通讯作者:谭良(1972—),男,四川成都人,教授,主要从事可信计算、网络安全以及云计算和大数据处理研究,E-mail: tanliang2008cn@126.com. 王青,谭良,杨显华.基于Spark的Apriori并行算法优化实现[J].郑州大学学报(理学版),2016,48(4):60-64. TP301.6 A 1671-6841(2016)04-0060-05 10.13705/j.issn.1671-6841.2016667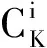


Fig.1 Big data programming model of Spark3 实验和结果分析
4 小结
猜你喜欢
节能与环保(2022年7期)2022-11-09辽宁大学学报(自然科学版)(2022年1期)2022-04-26河南水利年鉴(2020年0期)2020-06-09计算机技术与发展(2019年11期)2019-11-18电脑报(2019年31期)2019-09-10当代陕西(2019年13期)2019-08-20计算机与数字工程(2018年10期)2018-10-23计算机与数字工程(2017年2期)2017-03-02电脑爱好者(2015年21期)2015-09-10中南民族大学学报(自然科学版)(2014年1期)2014-08-06
