
风电短期发电功率预测方法探讨
2016-12-26 23:26梁耀光刘德泉
现代商贸工业 2016年27期
梁耀光 刘德泉
摘要:风力发电是人们利用无污染、可再生风能的一种主要形式。由于风电场受到风的随机性等特点的影响使其并网受到了限制,所以其必须有较高精度的短期风电功率预测系统。以风电场短期功率预测模型为研究对象,将历史单位置和多位置数值天气预报数据、多种智能优化算法与预测模型相结合,在Matlab仿真实验平台上开展研究和实验验证工作。
关键词:风电;短期发电功率;预测方法
中图分类号:TB
文献标识码:A
doi:10.19311/j.cnki.16723198.2016.27.100
1背景
面对日益严峻的能源及环境问题,世界各国都在找寻解决的方法,风能作为环境友好型新能源的代表,兼具蕴藏量大、可再生、无污染等特点,使得风力发电成为了解决环境问题、能源问题的重要途径。
一方面,风能在全球范围内储量巨大,人们利用风能的历史由来已久,截至到2104年年底,全世界风电新装机容量达到了51.47GW,累计装机容量达到了369.55GW,相较去年增长了15.99%,这其中中国继续领跑世界风电装机容量,达到了114.76GW。
另一方面,传统的电力系统稳定是通过发电功率追踪负荷功率来实现的。现今,电网接入大量风电后,电力系统的运行调度体系并未发生根本性的变化,传统电力系统的发电功率跟踪负荷功率的模式还在沿用。当风电功率波动超过电力系统的平衡能力时,可能导致电力系统频率越限,威胁电网安全运行。所以,高精度的风电功率预测变得越来越重要。
在风电大规模并网的大背景下,深入研究风电功率预测模型智能优化方法不仅能够为风电功率短期预测研究提供理论参考,还能为进一步消除风电对电网的不利影响打下坚实的基础。
2国内研究现状
国内对于风电功率预测的研究开始于二十世纪末,相对国外起步较晚,但研究和发展速度都比较快,目前已经很多学者将目光投入到了这一领域中。我国对于风电功率预测的研究可以分为两个阶段:
第一阶段为从2000年到2010年的这十年中,由于缺少风电功率预测专用的NWP数据,各单位和学者的主要研究工作集中在超短期预测上,且主要是理论探索。在建模过程中主要采用的方法有:时间序列法、神经网络法和支持向量机等方法。随着研究的深入,越来越多的学者发现单一简单的预测模型精度太低,很难满足实际需要。为了提高超短期预测的精确度,目前的研究主要集中在对模型输入量的优化上以及对模型自身的优化两个方面,但是超短期预测工作都是基于统计方法和简单的学习方法,预测时间较短,不能满足电力系统运行调度的需要。
第二阶段是数值天气预报数据加入模型后的预测研究。以电科院为代表,国内高校、科研机构、新能源公司通过购买NWP数据来改进风电功率模型,延长预报时间尺度,提高预测精度。中国电力科学研究院新能源研究所与德国太阳能研究所、丹麦里索国家实验室、挪威WindSim公司合作开发了我国首个风电功率预测系统(Wind Power Forecasting System-WPFS)。该研究项目于2008年4月正式启动,2008年12月10日投入试运行,2009年3月19日通过专家验收。截至到目前为止,该系统已经在全国11个省区50个风电场实施应用。随后华北理工大学和中国气象局有分别推出了服务于电网调度与发电端的风电场输出功率预测系统与中国气象局风力发电功率预测预报系统。这些预测系统也都应用在了实际风电场中。其共同点都是运用了NWP数据,当气象预报准确时,精度都较高,能满足实际需求。
3研究对象以及预测模型验证
以风电场短期功率预测模型为研究对象,将历史单位置和多位置数值天气预报数据、多种智能优化算法与预测模型相结合,在Matlab仿真实验平台上开展以下研究和实验验证工作。
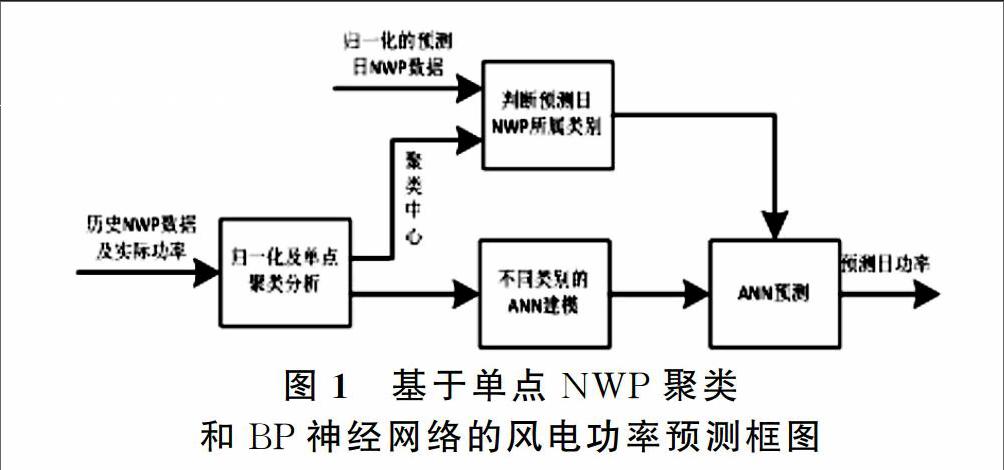
(1)对于风电功率预测常用的BP神经网络预测方法和支持向量机预测方法进行了概述,并分析了它们的优缺点。以BP神经网络理论为基础,建立了基于单位置数值天气预报的BP神经网络短期风电功率模型,并对未来一天的风电场功率进行了预测。在建立模型前,需要对训练数据进行归一化处理和聚类预处理。采用模糊c均值聚类时,需要知道分类数,考虑对于数据的分类数没有先验信息,所以采用模糊减法聚类来确定相应的分类数。
风电功率预测对NWP原始样本数据具有敏感依赖性,要提高预测精度就应选取合适的样本作为模型的输入数据。历史NWP数据数据量很大,为了获得对预测准确度影响最大的数据,首先对历史数据进行聚类分析,得到各类的聚类中心,运用欧氏距离法查找与预测日各点数据最相似的点作为训练样本;再利用各类中的数据点训练对应的BP神经网络,并保存各个权值阈值。以上节内容为基础,本文设计的聚类分析方法主要应用在3层的BP神经网络结构实现风电场功率预测。算法运算流程如图1所示。
(2)针对风电场预测模型训练用的历史数值天气预报数据和风电场历史实际功率缺失的问题,采用了一种基于数值天气预报单点聚类的方法对其进行处理,将处理后的数据运用在了BP神经网络模型训练中,并用算例进行了功率预测仿真实验。
(3)针对BP神经网络预测模型初始权值阈值难以确定的问题,运用遗传算法对其进行优化,建立了基于遗传算法优化的BP神经网络模型,解决了其初值难以确定的问题;对于支持向量模型参数优化问题进行了研究,分别运用粒子群算法、粒子群改进算法和人工鱼群算法对模型参数进行优化,建立了基于粒子群算法优化的支持向量机模型、基于改进粒子群算法优化的支持向量机模型和基于人工鱼群算法优化的支持向量机模型,并在仿真实验中进行了优化算法实验验证和各种算法的对比分析。
(4)针对大型风电场中多位置、多高度的历史数值天气预报数据,利用主成分分析对其进行降维处理,得到的数据作为BP神经网络的训练数据,得到基于多位置、多高度数值天气预报的BP神经网络模型,实现了多维输入数据的利用。
4结论
风电功率预测研究的关键是预测模型的搭建与准确的历史数据及天气预报数据的输入。模型搭建时常采用数值天气预报数据作为模型输入,采用风电功率预测值作为模型输出。本文针对风电功率预测模型特点,研究了BP神经网络与支持向量机的基本建模原理与建模方法,两种建模方法的非线性、自学习性与容错性都很好的契合了风电功率预测建模特点,但是常规的BP神经网络与支持向量机建模过程中都存在参数范围选取、初值难以确定等问题。
参考文献
[1]戴慧珠,王伟胜,迟永宁.风电场介入电力系统研究的新进展[J].电网技术,2007,31(20):1623.
[2]王继强.中国风能现状分析及发展探索[J].甘肃科技,2014,30(13):12.
[3]全球风能理事会GWEC.2014年全球风电装机容量统计[J].风能,2015,(2).
[4]刘江平,汪洪波.电网运行备用容量分析和控制策略的研究[J].华中电力,2005,18(6):2226.
[5]Santos J,Jones L.High Penetration Of Wind Power In Power Systems: An ISO Perspective[C].IEEE Power Engineering Society Summer Meeting,2002.
