
面向问题导向的学术文献搜索引擎研究
2016-12-26 02:26:39万连城
电子科技 2016年12期
万连城
(西安电子科技大学 期刊中心,陕西 西安 710071)
面向问题导向的学术文献搜索引擎研究
万连城
(西安电子科技大学 期刊中心,陕西 西安 710071)
针对学术搜索引擎的使用、查询和检索模型尚待深入研究的问题,研究了由学术搜索引擎接收的查询的分布,并且提出了一种查询识别方法。文中分析了学术搜索查询,并将其分为导航查询和信息查询。将导航查询限定为用户寻找特定学术文档的查询,在此条件下,通过引入一组新特征的机器学习方法来识别此类的查询,采用梯度提高树(GBT)来训练识别导航查询的分类器,结果显示在召回率为0.68的条件下,准确率为0.68,并且获得了0.677的F评分。
学术搜索; 导航; 查询; 机器学习
学术搜索引擎已成为许多研究人员起草研究手稿或着手研究提案时的起点。通常,有两类主要的检索系统供学者使用。第一类是引用数据库,例如,Web of Science和Pubmed;另一类是典型的网络搜索,例如,Google学术搜索和百度学术搜索。统计数据可以反映用户对每种类型系统的偏好。在调查统计中,2012年30%的博士研究人员依靠Google学术搜索作为查找信息的主要来源,根据来自加利福尼亚大学的统计数据,Santa Cruz表示Google 学术在2010年被用作次要信息来源[1]。在科学领域检索相关信息的需求导致了在信息检索方面的许多进展[2-6]。Kang和Kim使用了分布差异、相互信息、使用率作为锚文本、以及POS信息用于分类[7];Jansen等人提出了一种基于启发式算法的方法[8];Lee等人研究了用户点击行为和锚链接分布[9]。最接近的工作是Kan和Poo[10],他们专注于检测在线公共访问目录中的已知项目搜索。
本文中专注于使用基于关键字搜索的学术搜索系统,使用3年的查询日志来研究学术搜索引擎的用户行为。通过观察用户的查询模式,将学术搜索查询分类为导航和信息查询来研究用户查询意图。搜索引擎查询通常被分为3类[11]:(1)信息,用户正在网上寻找一些信息;(2)导航,用户试图访问特定网站;(3)事务性,用户试图执行某种类型的事务。查询意图分类是所有搜索引擎的重要部分,这是因为查询类型会影响查询的处理方式。如果已知查询是导航,则搜索引擎可以选择通过显示单个结果或少数结果来不同地呈现结果页面。在本文工作中,引入学术导航查询的概念。
1 学术查询日志
本文工作动机来自检查CiteSeerX的学术用户的使用行为,其中CiteSeerX是计算机科学和工程、物理学和经济学的出版物的索引。搜索引擎提供多种搜索类型,最典型的是文档搜索和作者搜索。将搜索引擎在2009年9月~2013年3月期间收到的搜索过程用于本研究。搜索类型的比例在表1中给出,从表1中可以看出,大多数的搜索过程(92.73%)属于文档搜索。此外,6.9%的搜索过程属于作者姓名搜索。推测两个可能的原因在于:(1)当用户记住论文的作者之一但不记得标题时,用户对通过作者姓名搜索论文感兴趣;(2)个别作者搜索自己追踪他们的论文被引用数量,以及被搜索引擎索引的文档数量。查询的一个重要特征是查询长度,其在某种程度上可以指示用户查询意图。例如,发出较长查询的用户更有可能搜索更具体的信息。通过检查类型文档搜索的查询,发现查询的平均长度为4.76项。

表1 文档和作者搜索类型百分比
2 查询类型分类
大多数查询意图识别集中在通用搜索引擎[9]。当前学术搜索引擎的易用性,以及它们与大多数人熟悉的传统Web搜索的相似性给研究用户的查询意图创造了机会。在学术搜索中,可以将查询至少分为导航和信息两种类型。在学术环境中定义事务性查询并不简单,在学术搜索中提供查询意图的完整分类超出了本研究的范围。相反,本文专注于识别导航查询。将导航查询限定为用户寻找特定学术文档的查询,特定学术文档可以是报纸、书、论文等。正确识别导航查询是重要的,因为排名者受引用的严重影响,这可能导致高引用论文排名高于新论文低引用论文。此外,标题包含一般术语的论文更容易受到影响,这是因为存在大量的匹配。在学术搜索中存在导航查询的多个方面,例如,用户可以通过以下方式查找给定文档:
文档对象标识符(DOI):10.1038/science15102
完整标题查询:百度文件系统
作者和标题信息的组合:zhang and LED
作者和年份/场地信息:Green 2009
知名工作的作者姓名:Cormen Leiserson
作者姓名与论文区别术语的结合:dic brin motwani
在第一种情况下,当用户通过DOI搜索时,检查查询是否与DOI数据库匹配就足够了。然而,标题查询不容易检测。首先,从论文中提取标题并不总是准确的。此外,虽然可以针对标题列表来检查查询,但是可能存在多个标题位置处匹配的许多短的和不明确的查询。除此之外,没有搜索引擎包含所有学术文档[12],因此识别搜索引擎没有结果的标题导航查询可以用作定位丢失文档的信号。在学术搜索引擎的日志中发现以下查询并不明显:在查询Green 2009中,存在一个作者姓名和年份用于识别工作。找到这些查询的正确匹配可能需要比简单规则更复杂的方法。

表2 导航查询特性
2.1 查询方法
将查询建模为二进制分类问题。给定查询q,希望将其分类为导航和信息两类之一。每个查询q被表示为表2中描述的特征的向量。这些特征用于捕获表示导航查询的多个方面。例如,在注意到许多导航查询具有比信息查询更多的术语之后,选择#_tokens。is_title_match通常是好的信号,但如果查询术语是普通的,则查询导航不一定匹配。其他语法特征(例如,has_stop_word和has_punctuation)用于识别标题查询。如示例所示,提及作者姓名是导航查询的一个方面。例如,在学术搜索引擎的日志中发现的以下查询不被视为导航:mccallum nigam,因为这两个作者在多篇论文中共同署名,并且该查询不能被解释为指向单篇论文。然而,作者姓名是导航查询的指示符之一。因此,创建一个特征来表示被识别为作者姓名的查询符号的数量。识别符号是否指向作者姓名并不像检查所有可能的姓名的字典那么简单。最初,使用DBLP的作者列表作为姓名字典,然而,假阳性识别很高。因此,采用了一种语言模型方法来识别作者姓名。对于每个符号t估计3个概率:P(t|author)、P(t|title)和P(t|abstract),其中作者、标题和摘要分别指示论文的作者、标题或摘要中出现的符号。在如下情况下,符号t被认为是作者
P(t|author)>P(t|abstract)∧P(t|author)>P(t|title)
梯度提高树(GBT)用于训练识别导航查询的分类器。分别在范围[10,400]和[10-4, 10-1]上使用网格搜索来选择树的数目和学习速率参数。Smote过采样用于在数据集不平衡时对导航查询进行过采样。
2.2 数据集
为了构建数据集,首先从用户搜索日志中随机抽取1 000个查询,然后仅保留文档搜索类型中的查询,这将导致总共553个查询。然而,注意该小数目的样本可能不能给出所有可能的阳性样本(导航查询)的合理覆盖,进行多轮采样并使用上述启发法来匹配可能的阳性候选。然后,通过可能在随机采样的数据集中没有足够存在的阳性实例(例如,具有作者姓名的实例)来增强数据集。还增加了可比数量的阴性实例来抵消这种影响。最后,数据集包含579个查询。每个查询由两个判定者检查,并标记为导航或信息。当判定者具有不匹配的标签时,他们授予相同的标签。在手动标记的查询中,发现12.5%是导航。
2.3 实验
分类器的性能如表3所示。针对5层交叉验证,训练层随机分为90:10,其中10%用于验证网格搜索参数。使用Smote的过采样仅在训练层上进行,试验层保持不变。将提高的树分类器的性能与具有RBF内核的SVM的性能以及随机森林的性能进行比较。类似于GBT,两个基准分类器的所有参数都使用网格搜索进行配置。最高准确率和总体F评分通过GBT获得,如表3所示。表中的数字指通过5层交叉验证获得的平均准确率、召回率和F评分,括号内指出了标准偏差。每个特征的重要性如图1所示。查询中的符号数量是最重要的特征,这可以通过倾向于具有较高数量的符号的标题查询来解释。类似地,与查询中的符号的数量密切相关的标题匹配特征在重要性方面次之,随后是作者比率特征。值得注意的是,对导航查询进行分类在网络领域是一项艰巨的任务,至少在学术领域如此。例如,Jansen等人[8]只获得74%的整体网络查询意图分类,这不仅限于导航。在高召回率的信息查询下,其他人能够获得70%的准确率。许多关于网络搜索引擎的导航查询分类的研究依赖于点击率[13-15]。虽然这些方法总体上有效,但它们仍然是被动的,并且取决于日志中查询和点击的存在,以便能够准确地对它们进行分类。当在没有见到新查询到达时,或者当用户使用新的关键字组合来引用学术论文时,这提出了挑战。表3中括号内的数表示5层交叉验证中的标准偏差。
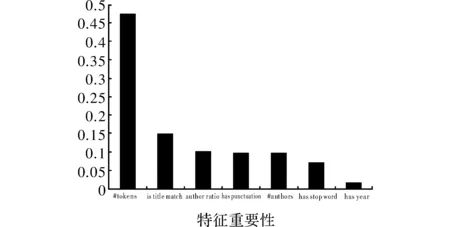
图1 导航查询分类特征重要性
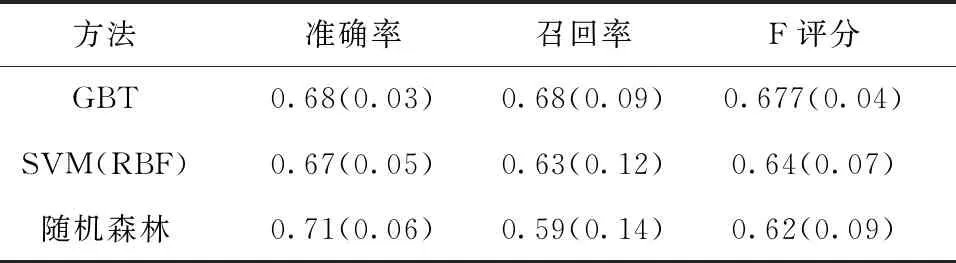
方法准确率召回率F评分GBT0.68(0.03)0.68(0.09)0.677(0.04)SVM(RBF)0.67(0.05)0.63(0.12)0.64(0.07)随机森林0.71(0.06)0.59(0.14)0.62(0.09)
3 结束语
基于用户查询日志分析了学术搜索,介绍了学术导航查询的概念,探讨了新的数据集与人判断的学术查询类型分类的问题,提出了一组特征来学习分类器。结果证明了所提出特征的有效性并且展示了该问题所带来的挑战。利用导航查询分类和学术文献排名函数来实现新的学术排名方法,可以将导航查询分类结果添加作为排序器的新特征或者对于不同类型的查询分别训练排序器。
[1] Hightower C,Caldwell C.Shifting sands: science researchers on google scholar, web of science, and pubmed, with implications for library collections budgets[J].Issues in Science and Technology Librarianship,2010(63):4-12.
[2] Sanderson M,Croft W B.The history of information retrieval research[C].CA,USA:Proceedings of the IEEE,100 Special Centennial Issue,2012.
[3] Berry M W,Dumais S T,Brien G W O.Using linear algebra for intelligent information retrieval[J].Siam Review,2012,37(4):573-595.
[4] Müller H M,Kenny E E,PW Sternberg. Textpresso: an ontology-based information retrieval and extraction system for biological literature[J].Plos Biology,2013,2(11):309-315.
[5] Charikar M,Chekuri C,Feder T,et al.Incremental clustering and dynamic information retrieval[J].Siam Journal on Computing,2015,33(6):626-635.
[6] Jensen L J,Saric J,Bork P.Literature mining for the biologist:from information retrieval to biological discovery[J].Nature Reviews Genetics,2006,7(2):119-129.
[7] Kang I H,Kim G.Query type classification for web document retrieval[C].Mrcao:In Proceedings of the 26th Annual International ACM SIGIR,2003.
[8] Jansen B J,Booth D L, Spink A.Determining the user intent of web search engine queries[C].Germany:In Proceedings of the 16th International Conference on World Wide Web, ACM,2007.
[9] Lee U,Liu Z,Cho J.Automatic identification of user goals in web search[C].France:In Proceedings of the 14th International Conference on World Wide Web,ACM,2005.
[10] Kan M Y,Poo D C.Detecting and supporting known item queries in online public access catalogs[C].Korea:Proceedings of the 5th ACM/IEEE-CS Joint Conference on Digital Libraries, IEEE,2005.
[11] Baeza Yates R,Calder′on Benavides L,Gonz′alez Caro C.The intention behind web queries[J]. String Processing and Information Retrieval,2006(3):98-109.
[12] Khabsa M,Giles C L.The number of scholarly documents on the public web[J].PLOS One, 2014,9(5): 93-94.
[13] Lu Y, Peng F, Li X,et al.Coupling feature selection and machine learning methods for navigational query identification[C].Lanzhou:In Proceedings of the 15th ACM International Conference on Information and Knowledge Management,2006.
[14] Li X,Wang Y Y,Acero A.Learning query intent from regularized click graphs[C].Hangzhou:In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,2008.
[15] Sun Y, Li H,Councill I G,et al.Personalized ranking for digital libraries based on log analysis[C].Hongkong:In Proceedings of the 10th ACM Workshop on Web Information and Data Management,2008.
Research on Problem-oriented Academic Search Engine
WAN Liancheng
(Center of Journal Publication,Xidian University,Xi’an 710071,China)
This paper investigates the distribution of queries received by academic search engines and presents a method of query recognition for the problem that academic search engine usage, query and retrieval models are not well studied. This paper studies the academic search queries and divides them into navigation queries and information queries. In this paper, the navigation query is defined as a query to find a specific academic document. Under this condition, a new set of machine learning methods is introduced to identify the query. The Gradient Boosted Trees (GBT) is used to train the classifiers , The results showed that the recall was 0.68, the precision was 0.68, and the F score of 0.677 was obtained.
academic search;navigation;query;machine learning
10.16180/j.cnki.issn1007-7820.2016.12.039
2016- 11- 07
万连城(1983-),男,硕士。研究方向:学术出版与传播。
TP305
A
1007-7820(2016)12-142-04
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
电子测试(2018年1期)2018-04-18 11:52:35
信息安全研究(2016年4期)2016-12-01 06:06:54
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
中国卫生(2015年12期)2015-11-10 05:13:38
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06 07:49:12
电测与仪表(2014年15期)2014-04-04 12:05:20
技术经济与管理研究(2014年11期)2014-03-11 17:02:44
