
一种混合算法在焦炉推焦计划调度中的应用
2016-12-24 06:46:45陶文华刘洪涛
西北大学学报(自然科学版) 2016年6期
陶文华,刘洪涛
(辽宁石油化工大学 信息与控制工程学院,辽宁 抚顺 113001)
·信息科学·
一种混合算法在焦炉推焦计划调度中的应用
陶文华,刘洪涛
(辽宁石油化工大学 信息与控制工程学院,辽宁 抚顺 113001)
焦炉推焦计划安排依靠人工经验法不但缺乏智能性而且准确度低,文中建立了具有TSP(旅行商问题)性质的推焦计划调度模型。提出一种差分进化算法和蚁群算法的混合算法(HDE-ACO)。HDE-ACO的基本思想是利用差分进化算法对蚁群算法的3个主要参数进行优化,解决蚁群算法对参数变化敏感的困难,从而提高蚁群算法寻优精度。将HDE-ACO与其他几种算法对多个不同的TSP进行测试比较,结果表明HDE-ACO不仅寻优能力强而且收敛速度快。最后,将HDE-ACO应用到推焦计划调度中,对推焦计划调度的优化进行研究。
推焦计划调度;TSP;差分进化;蚁群算法
焦炉推焦在正常工况下运行时往往要受到许多因素干扰,推焦计划的合理调度能够减少生产延时,增加企业产量,提高产品质量。焦炉推焦计划调度与旅行商问题(travelling salesman problem,TSP)有很多相似之处,可以将其归为TSP。随着计算机技术的不断进步,为TSP的求解提供了很多近代智能进化和仿生算法,例如遗传算法[1]、蚁群算法[2-3]、人工蜂群算法[4]、量子启发式算法[5]、布谷鸟搜索算法[6]等等。
蚁群算法(ant colony optimization,ACO)被证明用来求解TSP有很好的实验效果。1996年M. Dorigo首先将ACO应用到TSP[7]。ACO采用正反馈机制,随着多数蚂蚁在某条路径上留下信息素浓度的不断增大,后来的蚂蚁选择该路径的概率也会增高,从而加强了该路径的信息素浓度。每个蚂蚁在独立完成路径寻优的同时,蚂蚁之间不断进行信息交流和传递,避免个体陷入局部最优,保证了全局最优性。但ACO对参数非常敏感,单纯依靠人工经验调整不仅效率低下而且缺乏智能性。为此可以采用一种有效的算法对ACO的参数进行优化处理。
差分进化算法 (differential evolution, DE)由美国Berkeley大学的Storn和Price于1955年提出[8]。DE采用实数编码,有全局搜索能力,简单易行。其特有的记忆种群最优解的能力使得算法具有较好的鲁棒性和较强的收敛性。DE在许多领域得到应用研究,如路径规划[9]、化工生产[10]、图像处理[11]等。DE非常适合解决复杂非线性优化问题,所以文中使用DE对ACO参数进行优化。
现有的推焦计划调度主要采用撵炉法和丢炉法,这两种方法都是依靠人工经验安排推焦顺序,缺乏智能性和准确性。鉴于此,本文建立推焦计划调度模型,提出一种DE和ACO的混合算法,并将其应用到推焦计划调度中,经过大量实验证明本文算法有很好的寻优效果。
1 焦炉推焦计划调度模型
TSP的数学描述:一个城市集合Q={c1,c2,…,cm},其中每两个城市之间的距离为d(ci,cj)∈R+。一个旅行商经过Q中每个城市一次的路线为R=(q1,q2,…,qi,…,qm)(qi为Q中第i个城市),使得整个路线一周的距离最小,目标函数为
(1)
推焦顺序通常表示为a-b串序,a代表相邻两次推焦间隔的炉孔数目,b代表两趟签号对应炉孔间隔的整数。目前,世界上主要包括5-2,9-2,2-1推焦串序,我国主要采用5-2式和9-2式。相比而言,5-2式机械行程较短。本文以2×42孔JN43-80型焦炉为例,采用5-2推焦串序,其编排顺序如下:
1排签:1,6,11,16,21,26,31,36,41,46,51,56,61,66,71,76,81;
3排签:3,8,13,18,23,28,33,38,43,48,53,58,63,68,73,78,83;
5排签:5,10,15,20,25,30,35,40,45,50,55,60,65,70,75,80;
2排签:2,7,12,17,22,27,32,37,42,47,52,57,62,67,72,77,82;
4排签:4,9,14,19,24,29,34,39,44,49,54,59,64,69,74,79,84。
正常情况下,推焦计划会按照以上顺序有条不紊的进行。由于炉内外存在多种干扰因素,会出现多种异常状况,例如乱笺、事故影响、病号炉等。为了保证产品的质量、产量以及减少机械损失,需要建立一个实用有效的推焦计划调度模型。
1) 推焦过程中相邻炉孔顺序错乱引起惩罚:
Pi,j=Xi,jwi,j,
(2)
(3)
式中,i,j=0,1,…n,表示相邻推焦炉孔代数,且i≠j;wi,j为惩罚权值,根据推焦编排顺序其值依次增大,例如,w1,11=3,w1,16=4,…,w1,84=84;n是炉孔总数目。
2) 没有在规定时间出焦引起的惩罚:
Ji=exp(θYi)-1,
(4)
(5)
式中,θ∈(0,1)是炉体损坏和焦炭质量影响因子;χ,γ分别表示提前出焦和延迟出焦时间影响因子,提前出焦对炉体损坏和焦炭质量影响程度要比延迟出焦大,所以χ>1,0<γ<1;ti为第i个炉孔的计划出焦时间,与标准出焦时间差值不大于15min;tmax和tmin分别为标准出焦时间的最大值和最小值。
3) 相邻炉孔顺序错乱和未按规定时间出焦引起的总惩罚:
fi,j=Pi,j+Ji+Yj。
(6)
综上所述,在一个完整的周转时间内,完成所有炉孔的推焦要保证整个推焦系统的总惩罚最小,推焦计划调度目标函数为
(7)
通过比较式(1)和式(7)发现,推焦计划调度问题和TSP非常相似。区别在于TSP计算整个路线一周距离,包含路径列表中起点和终点的距离,而推焦计划调度问题不计算推焦顺序中始、末炉孔的惩罚。每个炉孔可以比作TSP中的每个城市,两炉孔之间的惩罚比作TSP中两城市之间的距离,本文将推焦计划调度问题转换为TSP求解。
2 混合优化算法
2.1 蚁群算法(ACO)

(8)

蚂蚁在(i,j)之间会留下一定量的信息素,当所有蚂蚁遍历完所有城市时,要进行城市间信息素的更新。然而,为了减少蚁群算法被调用的次数,本文采用全局异步特性与精英策略相结合的信息素更新方式。
全局异步信息素更新是指蚁群算法每一次被调用时,信息素不清零,并且每代迭代时,当本代解优于上一代最优解时进行更新,否则不进行更新。全局异步信息素更新规则为

(9)
(10)

(11)
式中,ρ∈(0,1)表示信息素的挥发程度;T为蚁群进化迭代次数;Lk(T)表示第k只蚂蚁第T次迭代路径长度;Lbest(T-1)表示第T-1代全局最优值;Q是信息素总量,为常数。
精英策略信息素更新是指对本次迭代全局最优路线中的信息素更新,这种策略能使本代最优路线进入下一代。精英策略信息素更新规则为

(12)
综上,全局异步特性与精英策略相结合的信息素更新公式为
(13)
ACO计算步骤如下:
Step1 ACO参数初始化。确定参数α,β,ρ,m,n以及最大迭代次数Tmax。给定T=1,k=1。初始化信息素矩阵Tau和禁忌表tabuk。
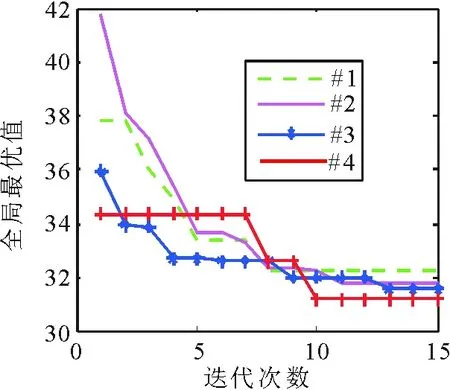
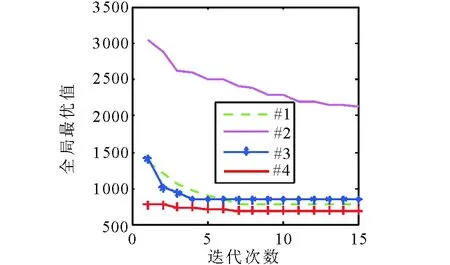
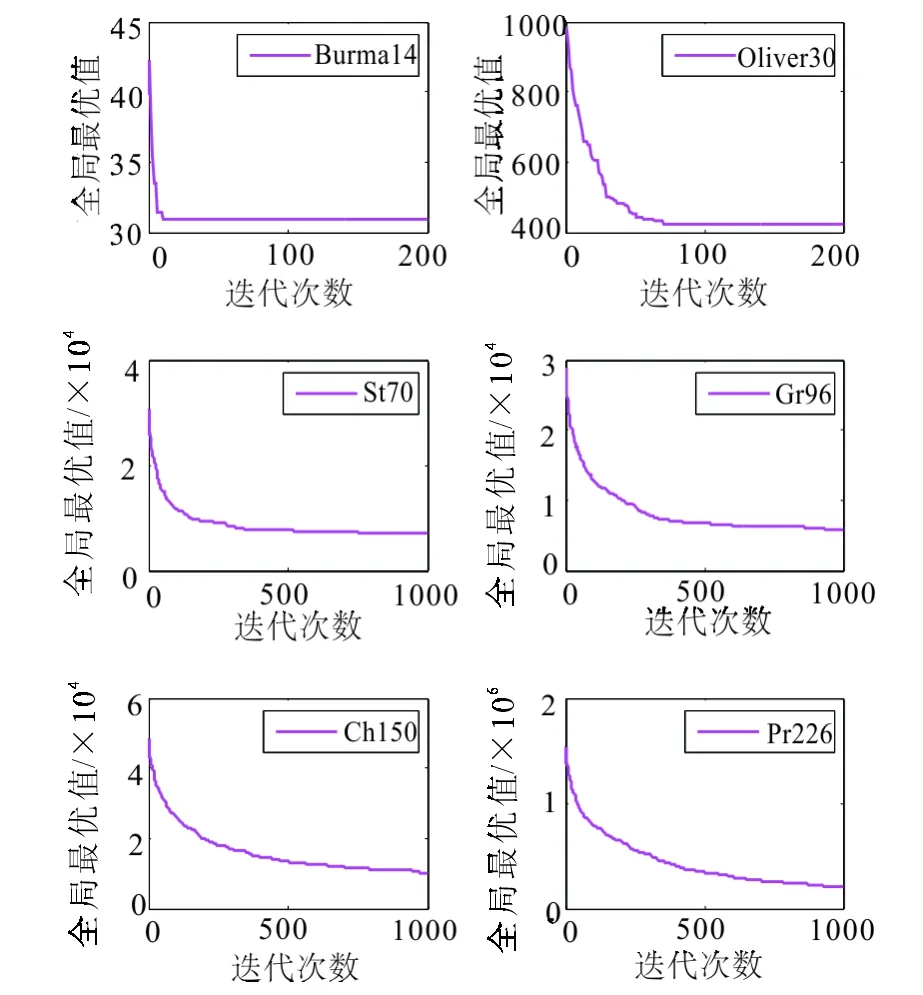
Step2 计算每两个城市之间的距离d(i,j),(0 Step3 根据当前时刻的tabuk确定第k只蚂蚁的位置,按照式(8)和当前时刻的allowedk选择下一个城市。 Step4 下一时刻更新第k只蚂蚁的禁忌表tabuk和允许访问的路径表allowedk。 Step5 如果k≤m,则k=k+1,返回到Step3。否则,执行下一步。 Step6 按照式(13)更新信息素矩阵Tau。 Step7 如果T≤Tmax,则T=T+1,返回到Step3。反之,则输出计算结果。 2.2 DE种群初始化 (14) 式中,pi,j表示第i个个体的第j维变量值;hj和lj分别为j维变量的搜索上下界,rand为0~1之间均匀分布的随机数。 本文以ACO中的α,β,ρ作为控制变量;控制向量p=[α,β,ρ];问题维数d=3;l=[0,0,0]是3个变量搜索下界;h=[5,5,1]是3个变量搜索上界。 2.3 DE变异操作 变异操作的目的就是为当代种群个体pi(G)产生一个参照体。其中,i∈(1,2,…,NP)从当代种群中任意选取3个个体pr1(G),pr2(G),pr3(G),按照以下规则取得目标个体ti(G)。 ti(G)=pr1(G)+F×[pr2(G)-pr3(G)], (15) F=F(0)×2φ, (16) (17) 其中,r1≠r2≠r3≠i;G为DE种群进化代数;Gmax是种群最大进化代数;F是自适应缩放比例因子,F(0)是F的初始值;实验已经证明F取值在0.5附近,且随进化过程逐渐减小会对算法有利。 2.4 DE交叉操作 将当代个体pi(G)与目标个体ti(G)进行变量交换,保留较优的个体变量,增强局部搜索能力。二项交叉的执行方式如下: (18) cr=0.5×(1+rand)。 (19) vi,j(g)为测试个体vi(g)的变量;ri,j(G)表示第G代第i个个体的第j个变量对应生成的均匀分布的随机数;rnd为1~d之间均匀分布的整数;rand是均匀分布的随机数;cr表示自适应交叉概率,其取值在0.5~1范围对算法有利。 2.5 DE选择操作 比较测试个体vi(G)和当代个体pi(G),选择较优者进入下一代,采用这种方式保证了下一代种群个体pi(G+1)优于当代种群个体pi(G),这是一种贪婪选择方式。即 pi(G+1)= (20) 式中,ACO[]表示以ACO作为DE的适应度函数,即DE调用ACO。 综上,HDE-ACO算法基本步骤如下: Step1 DE以ACO参数α,β,ρ作为控制变量进行初始化,求得初始种群。参数上下界上文已给出,G=1,i=1。需要确定参数Gmax,NP,Tmax,Q,F(0)。 Step2 按照式(15)和式(18)对第G代初始种群进行DE变异和交叉操作得到测试种群。 Step3 将第G代初始种群的第i个个体代入ACO求得计算结果ACO[pi(G)]。 Step4 将测试种群的第i个个体代入ACO求得计算结果ACO[vi(G)]。 Step5 按照式(20)确定初始种群的第i个个体或测试种群的第i个个体是否进入下一代。 Step6 如果i≤NP,则i=i+1,返回到Step3。如果达到终止条件,则执行下一步。 Step7 如果G≤Gmax,则G=G+1,返回到Step2。 Step8 如果满足终止条件,则输出相应的计算结果。 所有实验程序在Matlab2010环境下运行,PC机主频为2.30 GHz,内存2GB。所有实验结果以数值最小化为基准。 2.6 算法性能测试 由于TSP问题的求解难度大,一般以TSP作为平台检验优化算法的性能[12]。使用文中算法与文献[13-15]中算法分别对6个城市规模不等的基准TSP进行测试。为保证算法公平比较,所有算法迭代次数均为15。其他参数在以下算法描述中给出,为了分析方便4种算法,分别用“#1”,“#2”,“#3”,“#4”表示。 #1(文献[13]算法):蚁群算法。其采用的参数为,α=1,β=2,ρ=0.65,Q=10。 #2(文献[14]算法):改进的粒子群算法。粒子群算法依靠大规模粒子和多次迭代寻优,本文将粒子个数增加到500。 #3(文献[15]算法):蚁群和遗传混合算法。其参数为:α=1,β=5,ρ=0.7,Q=100,交叉概率pc=0.9,变异概率pm=0.9。 #4(HDE-ACO):参数设置为,Gmax=15,NP=12,Tmax=5,Q=100,F(0)=0.2。 以上算法对6个TSP各自求解5次,实验数值统计如表1~6所示;6个TSP的全局最优值的变化如图1~6所示,横坐标表示算法迭代次数,纵坐标表示每次迭代得到的全局最优值。 表1 Burma14的数值统计结果 Tab.1 Numerical statistics of Burma14 算法平均值最优值#133643222#233933178#332643157#433683123 表2 Oliver30的数值统计结果 Tab.2 Numerical statistics of Oliver30 算法平均值最优值#14899146137#27988465920#34957846820#44539644196 表3 St70的数值统计结果 Tab.3 Numerical statistics of St70 算法平均值最优值#18969979140#2242e+003212e+003#39051884956#48470074317 表4 Gr96的数值统计结果 Tab.4 Numerical statistics of Gr96 算法平均值最优值#16892559159#2240e+003215e+003#37418168067#46853755449 表5 Ch150的数值统计结果 Tab.5 Numerical statistics of Ch150 算法平均值最优值#1105e+004788e+003#2424e+004381e+004#3120e+004973e+003#4714e+003681e+003 表6 Pr226的数值统计结果 Tab.6 Numerical statistics of Pr226 算法平均值最优值#1138e+005966e+004#2138e+006128e+006#3174e+005153e+005#4807e+004783e+004 图1 Burma14的全局最优值的变化Fig.1 The global optimal value change of Burma14 图2 Oliver30的全局最优值的变化Fig.2 The global optimal value change of Oliver30 图3 St70的全局最优值的变化Fig.3 The global optimal value change of St70 图4 Gr96的全局最优值的变化Fig.4 The global optimal value change of Gr96 图5 Ch150的全局最优值的变化Fig.5 The global optimal value change of Ch150 图6 Pr226的全局最优值的变化Fig.6 The global optimal value change of Pr226 Burma14和Oliver30是小规模问题。由表1可见,#4的平均值比#1大0.04,比#3大1.04,差距都不大。#4的最优值比其他算法都小,但差距不大。由表2可见, #4的平均值比#1的小7.3%,比#2的小43.2%,比#3的小8.4%。#4的最优值比#1的小4.2%,比#2的小33%,比#3的小5.6%。 对于Burma14的求解,#4的寻优结果最好。 但是,与#1,#2,#3差别不大,对于Oliver30,#4的寻优结果最好,#1和#3能力相当,#2效果欠佳。 St70和Gr96是中等规模问题, 由表3可见, #4的平均值比#1的小5.6%,比#2的小65%,比#3的小6.4%。#4的最优值比#1的小6.1%,比#2的小65%,比#3的小19.4%。由表4可见,#4的平均值比#1的小0.6%,比#2的小71%,比#3的小7.6%。#4的最优值比#1的小6.3%,比#2的小74.2%,比#3的小18.5%。通过比较表3和表4可得:对于St70和Gr96的求解,#4的寻优结果最好,#1与#4差别不大,#2效果最差。 Ch150和Pr226是大规模问题,由表5可见,#4的平均值比#1的小32%,比#2的小83.2%,比#3的小40.5%。#4的最优值比#1的小13.6%,比#2的小82.1%,比#3的小30%。由表6可见,#4的平均值比#1的小41.5%,比#2的小94.2%,比#3的小53.6%。#4的最优值比#1的小18.9%,比#2的小93.9%,比#3的小48.8%。通过比较表5和表6可得:#4的寻优结果明显优于#1,#2,#3,其中#2效果最差。 由图1~6可知,在15次迭代过程中#4的收敛速度和寻优结果最好,说明对于不同规模的问题,#4不易陷入局部最优,具有较高的寻优精度。 通过表1~6以及图1~6可知,#2一直处于弱势,这主要是由于本文选取迭代次数过小导致。为了实验的严谨性和科学性,本文加大#2的迭代次数并求解6个TSP,#2对每个TSP求解5次。图7表示#2求解6个TSP的全局最优值过程变化,表7是#2和#4的数值统计对比表。 表7 #2和#4的数值统计 Tab.7 Numerical statistics of #2 and #4 TSP #2 #4 迭代次数平均值最优值迭代次数平均值最优值Burma14200310330881533683123Oliver302004684342374154539644196St7010008773771792158470074317Gr9610008303758232156853755449Ch1501000161e+004101e+00415714e+003681e+003Pr2261000440e+005197e+00515681e+003783e+004 图7 #2求解TSP的全局最优值变化Fig.7 The global optimal value change of TSP obtained by #2 由表7中数值比较可知,对于小规模问题,#2的平均值以及最优值与#4的差距不大,对于大规模问题,#4的平均值与最优值远小于#2的。对于St70问题,#2的最优值比#4的小,对于Gr96问题,#4的最优值比#2的小,说明对于中等规模问题#2和#4的寻优能力相当。因此可知,#2求解中小规模问题时,求解精度与#4相差不大,甚至略优于#4。但是,对于大规模问题,其求解精度远远不如#4。#2在求解大中规模问题时需要多达千次的迭代,这种方法需要较高的时间成本,所以此法不可取。 总之,对于不等规模的路径寻优问题,#4的寻优能力要优于其他算法。 焦炉推焦计划调度模型参数选取:tmax=17.917(h),tmin=18.083(h),θ=0.5,χ=2,γ=0.5。HDE-ACO选取的参数与上文中#4的相同。焦炉推焦计划调度具有随机性,文中主要从以下3种情况进行研究。优化后的推焦顺序实际按照系统总惩罚最优原则求得。表8是人工经验推焦计划安排和文中算法优化调度后系统总惩罚值比较表。以下结果基于Matlab 2010求得。 情况1 炉孔无错乱,并且按时出焦这种情况就是正常工况下的推焦调度,考虑这种情况的目的是为了验证本文算法对推焦调度优化的准确性。优化后的推焦顺序完全符合5-2推焦顺序。 优化后的推焦顺序: 1→6→11→16→21→26→31→36→41→46→51→56→61→66→71→76→81→ 3→8→13→18→23→28→33→38→43→48→53→58→63→68→73→78→83→ 5→10→15→20→25→30→35→40→45→50→55→60→65→70→75→80→ 2→7→12→17→22→27→32→37→42→47→52→57→62→67→72→77→82→ 4→9→14→19→24→29→34→39→44→49→54→59→64→69→74→79→84。 情况2 炉孔部分错乱、全部按时出焦。随机选取炉号为6,9,7,25的炉孔发生推焦顺序错乱。 优化后的推焦顺序: 1→11→16→21→6→26→31→36→41→46→51→56→61→66→71→76→81→ 3→8→13→18→23→28→33→38→43→48→53→58→63→68→73→78→83→ 5→10→15→20→30→35→40→25→45→50→55→60→65→70→75→80→ 2→12→17→22→7→27→32→37→42→47→52→57→62→67→72→77→82→ 4→14→19→24→9→29→34→39→44→49→54→59→64→69→74→79→84。 情况3 炉孔部分错乱、部分未按时出焦。错乱炉孔依然是6,9,7,25,炉孔i的计划出焦时间ti=17.75+0.5×rand。 优化后的推焦顺序: 1→11→16→21→6→26→31→36→46→51→56→61→76→81→ 8→13→18→28→33→43→48→53→63→68→73→83→ 5→10→15→30→40→25→35→55→60→65→70→75→80→ 2→12→17→22→27→37→42→47→52→57→62→67→77→ 4→19→24→29→14→39→44→54→59→64→69→74→79→84→41→71→ 3→23→38→58→78→20→45→50→7→32→72→82→29→34→49→66。 表8 系统惩罚比较 Fig.8 The comparison of system penalty 情况系统总惩罚人工经验HDE⁃ACO1002>27273≫4132541325 表8中,两种方法在情况1(正常工况)下的系统总惩罚值均为0。情况2下,HDE-ACO求得的系统总惩罚值为27,而人工经验法求解结果大于27。情况3下,HDE-ACO求得的系统总惩罚值为413.25,而人工经验法求解结果远大于27。情况2和情况3属于异常工况,通过情况2和情况3各自系统总惩罚值比较,证明HDE-ACO智能调度优化得到的惩罚效果要优于人工经验推焦计划安排,即HDE-ACO求得的推焦调度精度高。 基于NP-hard问题的求解,文中提出一种DE和ACO的混合算法。混合算法利用DE优化ACO参数,解决ACO对参数变化敏感的问题。混合算法主要特点是采用自适应DE参数,解决了DE参数的难调性的困难;全局异步特性与精英策略相结合的信息素更新策略被引进到ACO中,减少了ACO被一次调用需要多次迭代的问题。使用文中算法与文献[13-15]中的算法对多个TSP问题测试比较,实验结果证明经过少次迭代,文中算法表现出很强的寻优能力和较快的收敛速度。将文中算法应用到焦炉推焦计划调度中,其优化后的推焦顺序准确度高,能够使系统惩罚最优。 [1] MAITY S, ROY A, MAITI M. A modified genetic algorithm for solving uncertain constrained solid travelling salesman problems[J].Computers & Industrial Engineering, 2015, 83(2):273-296. [2] ESCARIO J B, JIMENEZ J F, GIRON-SIERRA J M. Ant colony extended:Experiments on the travelling salesman problem[J].Expert Systems with Applications, 2015, 42(1):390-410. [3] MAVROVOUNIOTIS M, YANG S. A memetic ant colony optimization algorithm for the dynamic travelling salesman problem[J].Soft Computing, 2011, 15(7):1405-1425. [4] KIRAN M S, ISCAN H, GÜNDÜZ M. The analysis of discrete artificial bee colony algorithm with neighborhood operator on traveling salesman problem[J].Neural Computing and Applications, 2013, 23(1):9-21. [5] BANG J, RYU J, LEE C, et al. A Quantum heuristic algorithm for the traveling salesman problem[J].Journal of the Korean Physical Society, 2012, 61(12):1944-1949. [6] OUAARAB A, AHIOD B, YANG X S. Discrete cuckoo search algorithm for the travelling salesman problem[J].Neural Computing and Applications, 2014, 24(7-8):1659-1669. [7] NARASIMHA K V, KIVELEVITCH E, SHARMA B, et al. An ant colony optimization technique for solving min-max multi-depot vehicle routing problem[J].Swarm and Evolutionary Computation, 2013, 13(5):63-73. [8] ZOU Dexuan, LIU Haikuan, GAO Liqun, et al. An improved differential evolution algorithm for the task assignment problem[J].Engineering Applications of Artificial Intelligence, 2011, 24(4):616-624. [9] LAI Mingyong, CAO Erbao. An improved differential evolution algorithm for vehicle routing problem with simultaneous pickups and deliveries and time windows[J].Engineering Applications of Artificial Intelligence, 2010, 23(2): 188-195. [10] CHEN Xu, DU Wenli, QIAN Feng. Multi-objective differential evolution with ranking-based mutation operator and its application in chemical process optimization[J].Chemometrics and Intelligent Laboratory Systems, 2014, 136(16):85-96. [11] ALI M, AHN C W, SIARRY P. Differential evolution algorithm for the selection of optimal scaling factors in image watermarking[J].Engineering Applications of Artificial Intelligence, 2014, 31:15-26. [12] WANG Yong. The hybrid genetic algorithm with two local optimization strategies for traveling salesman problem[J].Computers & Industrial Engineering, 2014, 70(2): 124-133. [13] RAGHAVENDRA B V. Solving traveling salesmen problem using ant colony optimization algorithm[J].Applied & Computational Mathematics, 2015,4(6):1-8. [14] GAO Yuxi, WANG Yanming, PEI Zhili. An improved particle swarm optimization for solving generalized travelling salesman problem[J].International Journal of Computing Science & Mathematics, 2012, 3(4):385-393. [15] WANG Chunxiang,GUO Xiaoni. A hybrid algorithm based on genetic algorithm and ant colony optimization for Traveling Salesman Problems[C]∥The 2nd International Conference on Information Science and Engineering. IEEE, 2010: 4257-4260. (编 辑 李 静) Application of a hybrid algorithm in coke pushing planning and scheduling of coke oven TAO Wenhua, LIU Hongtao (School of Information and Control Engineering, Liaoning Shihua University, Fushun 113001, China) Coke pushing plan of coke oven is arranged by artificial experiences, which is not only lack of intelligence, but also lack of accuracy. In view of this, a coke pushing plan scheduling model that has the nature of Traveling Salesman Problem is built in this paper. In order to obtain a more accurate solution for the problem, a hybrid algorithm of Differential Evolution and Ant Colony Optimization (HDE-ACO) is presented in this paper. The basic idea of HDE-ACO is that DE is used to optimize three parameters of ACO, thus overcoming the difficulty that ACO is sensitive to parameter change. Then, the optimization accuracy of ACO can be improved. HDE-ACO and several other algorithms are used to optimize multiple different TSPs. The comparison results show that HDE-ACO has not only a strong ability of searching optimal solution but also a faster convergence rate. Finally, HDE-ACO is applied to coke pushing plan scheduling and the optimization of coke pushing plan is divided into three kinds of cases to study. coke pushing planing and scheduling; TSP; differential evolution; ant colony optimization 2015-09-03 国家自然科学基金资助项目(61473140); 国家自然科学基金青年基金资助项目(61203021) 陶文华,女,浙江绍兴人,教授,从事智能算法的研究与应用。 TP18 A 10.16152/j.cnki.xdxbzr.2016-06-008










3 仿真研究

4 总 结
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
武汉工程职业技术学院学报(2022年1期)2022-04-13 06:31:30
小读者(2020年2期)2020-03-12 10:34:06
阅读(快乐英语高年级)(2019年11期)2019-09-10 07:22:44
金桥(2018年4期)2018-09-26 02:24:54
趣味(语文)(2018年1期)2018-05-25 03:09:58
学苑创造·A版(2015年6期)2015-07-01 09:00:12
中国卫生(2014年5期)2014-11-10 02:11:26
中学数学杂志(高中版)(2014年2期)2014-05-26 13:42:42
