
基于友好度的影响力最大化算法
2016-12-22 07:10:02胡一清
西安邮电大学学报 2016年6期
吴 旭,胡一清
(西安邮电大学 计算机学院, 陕西 西安 710121)
基于友好度的影响力最大化算法
吴 旭,胡一清
(西安邮电大学 计算机学院, 陕西 西安 710121)
提出一种基于友好度的影响力最大化算法。利用社交网络中用户行为信息计算友好度并构建友好关系网络,通过友好度调整节点的扩散概率,同时启发式地选取友好度积累值较高的节点作为启发节点以此提升算法的实现效率,最后采用CELF++算法计算影响力最大的节点集。实验结果表明,该算法与CELF++算法、TIM算法和DegreeDiscount算法相比,在获得较好的扩散效果的同时亦将执行时间有效的控制在一定范围内。
影响力最大化;友好关系;社交网络;社会计算
社会网络中的影响力最大化算法[1, 2]可以帮助发现现实生活中不易发现的社会现象或者社会问题。其目的是寻找若干个种子节点使影响力扩散最大化,得到影响力最大化的最优解决方案。
利用自然贪心算法计算影响力最大化的效果虽然明显好于基于节点度或中心性的启发式的影响力最大化算法,但其计算效率不高,特别是面对拥有海量用户节点和边社交网站,低效问题更加明显[3]。CELF(Cost-Effective Lazy Forward selection)算法[4]在自然贪心算法的基础上,利用影响力最大化的子模块特性提升了贪心算法的效率;CELF++算法[5]是对CELF算法的改进,利用堆特性进一步提升了算法效率。 NewGreedy算法[6]和CELF算法[4]融合得到的MixedGreedy算法,计算效率也有所提高,但是计算得出的种子节点个数与最佳的影响力最大化的节点集仍有差距; DegreeDiscount算法[6]利用节点度启发式选取种子节点,并没有考虑到网络中用户间的关系信息,通过牺牲扩散范围来降低时间复杂度;与DegreeDiscount 算法相似,TIM(Two-phase Influence Maximization)算法[7]虽然效率较高,但是也没有对个体间的相互关系进行分析和量化,导致扩散效果受到限制。
目前,影响最大化问题中的影响力扩散模型主要有线性阈值模型(Linear Threshold Model,LTM)和独立级联模型(Independent Cascade Model,ICM)[3]。扩散模型中个体之间的影响力权值默认是已知的常量或者提前赋予的数值,但是在现实环境中这种假设不成立,因此有必要对个体间的影响力因素及其相互关系进行分析和量化。
在信息扩散过程中,用户之间的友好关系是主要影响因素之一[8-11]。针对用户之间行为和交互信息较少所导致的度量结果与实际情况有偏差的问题,本文拟提出基于友好度的影响力最大化算法(Friendliness-based Influence Maximization Method, FIMM),并基于独立级联模型构建FIMM算法框架。利用用户间友好度调整扩散概率,可使友好度较高的用户之间的传播概率更大。同时将启发式的选取友好度积累值较高的节点作为最有潜力的影响力节点以期提升算法的实现效率。
1 基于友好度的影响力最大化算法
1.1 FIMM算法框架
FIMM算法的实现框架,如图1所示,包括两个阶段:(1)友好关系网络建立阶段。通过计算用户间的友好度得到用户间的友好关系网络。(2)FIMM算法的具体实现阶段。通过友好度调整节点的激活概率,同时启发式的选取友好度积累值较高的节点作为最有潜力的影响力节点。

图1 FIMM算法的实现框架
1.2 友好关系网络的建立
采集用户间的历史交互行为信息。通过分析这些行为的分布规律和因果关系得到社交网络中用户间的熟悉度与相似度。根据用户间的熟悉度与相似度计算用户间友好度,并利用友好度建立用户间友好关系网络。友好度计算公式为
T(a,b)=F(a,b)S(a,b),
(1)
其中T(a,b)为a与b之间的友好度,S(a,b)为a与b的相似度,F(a,b)为a与b间的熟悉度。熟悉度计算表达式为
,
其中Wa,b表示a与b相互回应的消息次数,N(a)表示a的邻居节点集合,Wa,m表示a与所有邻居m的相互回应的消息次数。用户间的交往时间对熟悉度的计算有影响,将式(1)通过时间因子tΔ进行修正,得到

(3)

(4)
其中ΔTa,b表示用户双方首次相互回应的时间点和最新交互回应的时间点的差值。ΔTuniverse为友好关系网络中所有节点间首次相互回应的时间点和最新交互回应的时间点的差值。最后将ΔTa,b进行平滑处理得到时间因子tΔ。
通过Pearson相 关 系 数(Pearson Correlation Coefficient)[12]调整得到相似度的计算公式为

(5)


(6)
其中,Ia和Ib分别表示a和b打过分的项目的数量。
计算用户对其邻居友好度的积累得到累加的友好度积累值C(a),该值被用来度量用户的潜在影响力,其表达式为

(7)
其中Ar表示第r轮影响力扩散的种子节点集。友好度积累值C(a) 较高的节点将作为最有潜力的影响力节点。
1.3 FIMM算法


(8)

FIMM算法将分为3步选取k个种子节点,并引入启发因子h(0≤h≤1),启发因子h意味着启发阶段选取启发节点个数所占比率。FIMM算法的具体实现步骤如下。
步骤1 调整激活概率。
在友好关系网络的基础上,通过式(8)调整激活概率p。
步骤2 启发式地选取种子节点。
利用式(7)计算节点在友好关系网络上的友好度积累值,友好度积累值较高的节点被选取作为启发节点。选取[hk]个节点作为启发节点。重复执行[hk]轮,每轮选取未激活的友好度累积值较高的节点作为启发节点(种子节点),然后在保留上一轮扩散的节点的基础上用启发节点经行扩散。
步骤3 利用贪心算法选取种子节点。
利用CELF++算法计算剩余的k-[hk]个种子节点。重复执行k-[hk]轮,直到得到具有k个种子节点的集合S。输出集合S。
当h=0时,算法跳过步骤2直接步骤3。其中启发因子h为经验值,因此需要确定h的值才能得到一个确定的影响最大化方法。
2 实验结果及分析
2.1 实验数据集
为验证FIMM算法在社交网络中的有效性,选取两组用户数据集作为仿真验证对象。从社交网络抽取用户节点及节点信息形成社交网络图,其中用户节点包括用户对电影、音乐、书籍的评分。评分项直接反应了用户的兴趣。通过这些节点数据信息得到节点间的熟悉度与相似度以构建友好关系网络。节点数据为:
(1) 用户信息。包括用户名ID、用户名、关注用户数和被关注用户数。
(2) 用户关注关系。包括当前用户ID、当用户关注用户的ID和被当前用户关注的用户ID。
(3) 评分信息。当前用户对电影、书籍及音乐专辑的评分。
最后通过用户关注关系中相互关注的行为形成边。数据集描述如表1所示。

表1 数据集描述
2.2 实验对比
选取种子集合个数k作为输入参数,影响范围和算法执行时间作为种子集合S在扩散模型之上的仿真效果的评价指标。其中影响范围表示算法利用种子节点S扩散一定的轮数所影响的节点个数。将CELF++算法、TIM算法和DegreeDiscount算法3种影响力最大化算法与FIMM算法进行比较,共进行两组实验。
实验1 选取种子集合个数k作为参数,用以考察在k值一定的情况下取不同启发因子h所得到的影响范围。数据集1的实验结果如图2所示。
由图2可知,排除h=1的情况,h取其它值所得到的影响范围均比h=1时要大。当k=50,h=0.5,FIMM算法所得的影响范围比h的其他取值要高出3%。当h=1时,FIMM算法变为静态选取潜在影响力最大的节点,将其作为种子节点,这种选取方式未考虑影响力的传播过程,因此所得的影响范围也最差。而当h=0时,FIMM算法退化为CELF++算法。

图2 参数k与h在数据集1中的影响范围曲线
数据集2的实验结果如图3。当h≠0且取合适的值时,所得的影响范围优于h=0情况。这说明在友好关系网络的环境下启发式的选取一部分种子节点优于直接使用CELF++算法。同时,当h=0.5时,所取得的影响范围仍高于h取其他值的情况。

图3 参数k与h在数据集2中的影响范围曲线
实验2 将CELF++算法、TIM算法、DegreeDiscount算法与FIMM算法分别在影响范围和算法执行时间上进行比较。其中FIMM算法的启发因子取h=0.5。实验结果分别如图4和图5所示。
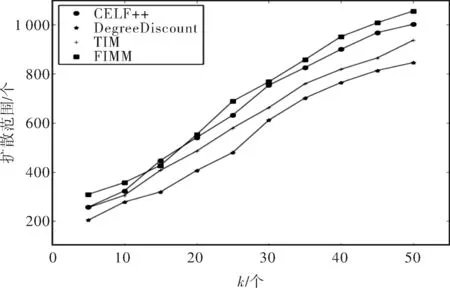
图4 不同算法在数据集1中的影响范围曲线
从图4可以看出,在k=50时,由FIMM算法得到种子节点的扩散范围(即所影响的种子节点数)比CEFL++算法得到的扩散范围高出7%。这说明FIMM算法框架通过友好关系网络有效地模拟了社交网络中影响力传播过程进而使挖掘出的最具影响力的种子节点集合的扩散效果得到提升。由于FIMM算法通过计算节点的友好度累积值,启发式的选取种子节点,因此当种子节点个数k的取值较小时会影响FIMM的扩散效果。从实验结果上看,k>25时,FIMM算法的扩散范围开始优于其他影响力最大化算法。

图5 不同算法在数据集1中所消耗的时间
从图5中可以看出,CELF++算法的执行时间高于其他算法,这是由于该算法在整个社交网络中利用蒙特卡洛模拟估算节点影响力。而 FIMM算法在构建友好关系网络后利用节点友好度的积累选取启发节点将有效减少算法执行时间,并且最终的扩散范围优于CELF++算法。 FIMM算法与其他算法相比在获得较好的扩散效果的同时亦将执行时间有效的控制在一定范围内。实验结果验证了友好度的引入和启发式的选取种子节点较好地优化了影响力最大化算法。
3 结语
FIMM算法利用独立级联模型模拟扩散过程,采集用户间的历史交互行为信息计算用户间的友好度,以此建立用户间的友好关系网络;启发式的选取友好度积累值较高的节点作为最有潜力的影响力节点,以减少寻找种子节点所消耗的时间。与CELF++算法、TIM算法和DegreeDiscount算法对比实验结果表明, FIMM算法在获得较好的扩散效果的同时亦将执行时间有效的控制在一定范围内,这表明友好度的引入和启发式的选取种子节点较好地优化了影响力最大化算法。
[1] DOMINGOS P, RICHARDSON M. Mining the Network Value of Customers[C/OL]//Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, New York, NY, USA:ACM,2001:57-66[2016-5-20]. http://dx.doi.org/10.1145/502512.502525.
[2] RICHARDSON M, DOMINGOS P. Mining Knowledge-sharing Sites for Viral Marketing[C/OL]//Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, New York, NY, USA:ACM,2002:61-70[2016-5-20]. http://dx.doi.org/10.1145/775056.775057.
[3] KEMPEL D, KLEINBERG J, TARDOS. Maximizing the Spread of Influence Through a Social Network[C/OL]//Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, New York, NY, USA: ACM, 2003: 137-146[2016-5-20].http://dx.doi.org/10.1145/956750.956769.
[4] LESKOVEC J, KRAUSE A, GUESTRIN C. Cost-effective Outbreak Detection in Networks[C/OL]//Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, New York, NY, USA: ACM, 2007: 420-429[2016-5-20].http://dx.doi.org/10.1145/1281192.1281239.
[5] GOYAL A, LU WEI, LAKSHMANAN L V S. CELF++: Optimizing the Greedy Algorithm for Influence Maximization in Social Networks[C/OL]//Proceedings of the international conference companion on World Wide Web. New York, NY, USA: ACM, 2011: 47-48[2016-5-20].http://dx.doi.org/10.1145/1963192.1963217.
[6] CHEN W, WANG Y, YANG S. Efficient Influence Maximization in Social Networks[C/OL]//Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining, New York, NY, USA: ACM, 2009: 199-208[2016-5-20].http://dx.doi.org/10.1145/1557019.1557047.
[7] TANG Y Z, XIAO X K SHI Y C. Influence Maximization: Near-Optimal Time Complexity Meets Practical Efficiency[C/OL]// Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, New York, NY, USA: ACM, 2014: 75-86[2016-5-20].http://dx.doi.org/10.1145/2588555.2593670.
[8] VACCARO A, ADARMS S K, KISLER T S, et al. The Use of Social Media for Navigating the Transitions Into and Through the First Year of College[J/OL]. Journal of the First-Year Experience & Students in Transition, 2015,27(2):29-48[2016-5-20]. http://eric.ed.gov/?q=social+AND+media+AND+school&pg=4&id=EJ1102760.
[9] LUO H, MA L. Empirical research on consumers' post-transaction general trust in B2C E-business[C/OL]// 2013 10th International Conference on Service Systems and Service Management, Hong Kong: ICSSSM, 2013:208-213[2016-5-20]. http://dx.doi.org/10.1109/ICSSSM.2013.6602639.
[10] 吴旭. 基于增强稳定组模型的移动P2P网络信任评估方[J/OL].计算机学报, 2014, 37(10) : 2118 - 2127[2016-5-20]. http://dx.chinadoi.cn/10.3724/SP.J.1016.2014.02118.
[11] ZHANG H, WANG Y, YANG J. Space Reduction for Contextual Transaction Trust Computation in E-Commerce and E-Service Environments[C/OL]// 2015 IEEE International Conference on Services Computing (SCC) , 2015: 680-687[2016-5-20].http://dx.doi.org/10.1109/SCC.2015.97.
[12] AHLGREN P, JAMEVING B, ROUSSEAU R. Requirements for a cocitation similarity measure, with special reference to Pearson’s correlation coefficient[J/OL]. Journal of the American Society for Information Science and Technology, 2003: 54(6):550-560[2016-5-20].http://dx.doi.org/10.1002/asi.10242.
[责任编辑:祝剑]
Influence maximization algorithm based on friendliness
WU Xu, HU Yiqing
(School of Computer Science and Technology, Xi’an University of Posts and Telecommunications Xi’an 710121, China)
A new influence maximization algorithm based on friendliness is proposed in this paper and named as Friendliness-based Influence Maximization Method (FIMM). FIMM uses behavior and interaction information of nodes in social network to compute friendliness and to build friendly relationship network. FIMM also adjusts the diffusion probability of nodes through the friendliness and improves the efficiency of implementation of the algorithm by selecting nodes. These nodes have higher accumulation of friendliness and have the most potential influence heuristically based on friendly relationship network. Experiment results show that FIMM can get better diffusion effect than CELF++, TIM and DegreeDiscount. FIMM can also limit implement time effectively in a smaller range, which means that using friendliness and selecting nodes heuristically can optimize influence maximization algorithm.
influence maximization, friendliness, social network, social computing
10.13682/j.issn.2095-6533.2016.06.023
2016-6-16
国家自然科学基金资助项目(71501156);中国博士后基金资助项目(2014M560796);陕西省教育厅科研计划资助项目(15JK1679);西安邮电大学创新基金资助项目(114-602080048)
吴旭 (1978- ),女,副教授,博士,从事可信计算、信任管理和云计算等研究。E-mail: xrdz2005@163.com. 胡一清 (1990- ),男,硕士研究生,研究方向为计算机网络舆情。E-mail: 172142282@qq.com.
TP393.093
A
2095-6533(2016)06-0118-05
猜你喜欢
学习周报·教与学(2021年16期)2021-10-30 09:25:22
当代陕西(2021年1期)2021-02-01 07:18:12
考试与评价·高二版(2020年3期)2020-09-10 13:04:38
教育研究与评论(课堂观察)(2020年3期)2020-07-30 07:23:46
华人时刊(2019年15期)2019-11-26 00:55:44
NBA特刊(2018年14期)2018-08-13 08:51:40
新一代(2017年4期)2017-05-13 08:28:18
人大建设(2017年11期)2017-04-20 08:22:49
中国卫生(2015年8期)2015-11-12 13:15:34
瞭望东方周刊(2015年12期)2015-04-14 23:28:02
