
利用子空间改进的K-SVD语音增强算法
2016-12-20 06:24:01贾海蓉
西安电子科技大学学报 2016年6期
郭 欣,贾海蓉,王 栋
(太原理工大学 信息工程学院,山西 太原 030024)
利用子空间改进的K-SVD语音增强算法
郭 欣,贾海蓉,王 栋
(太原理工大学 信息工程学院,山西 太原 030024)
在低信噪比的情况下,稀疏表示无法将纯净语音完全从带噪语音中分离出来,针对此问题提出了一种利用子空间改进的K奇异值分解语音增强算法.首先,利用子空间最优估计器跟踪噪声; 其次,通过K奇异值分解算法对噪声进行训练,构建出噪声字典; 最后,用K奇异值分解算法训练语音字典.在训练过程中,如果某个原子对应的稀疏系数低于设定的阈值,并且该原子可在训练得到的噪声字典中找到,就把该原子对应的稀疏系数设为零,即可达到去噪的目的.仿真结果表明,改进算法去除白噪声和babble噪声的效果显著,有效提高信噪比和减少语音失真,同时,该算法也可以很好地应用于消除随机噪声.
语音增强;K奇异值分解;稀疏表示;信号子空间
在实际的语音通信系统中,语音信号不可避免地受到噪声的干扰.语音增强[1]的目的就是尽可能地从噪声中提取出纯净的语音信号,达到改善语音信号的质量和提高可懂度.目前平稳噪声及高信噪比(Signal-to-Noise Ratio,SNR)下的语音增强方法都能取得较好的增强效果,但低SNR下的语音增强效果不佳,严重影响了通信效果.因此,低SNR下的语音增强仍然是目前研究的热点和难点.
近年来,稀疏表示或稀疏编码在信号处理领域受到了极大的关注.文献[2]首次提出了过完备稀疏表示思想,构造过完备字典主要分为两类算法,一种是利用传统基构造字典,比如离散余弦变换(Discrete Cosine Transform,DCT)字典[3]; 另一种就是K奇异值分解(K-Singular Value Decomposition,K-SVD)算法构造字典,其中K-SVD算法是最具代表性的一种算法[4].文献[5]提出了基于数据驱动字典和稀疏表示的语音增强,说明了K-SVD构造的字典可以有效去除加性噪声,改善语音质量.但是运用稀疏表示语音增强的前提是,在K-SVD构造的字典中语音是稀疏的、噪声是密集的.然而实际情况中噪声也可能是稀疏的[6-7],那么,在低SNR下噪声原子就可能掩盖信号原子.笔者针对以上问题提出了一种利用子空间改进的K-SVD语音增强算法,先通过改进算法构造噪声字典; 然后在K-SVD训练语音字典过程中,如果同时满足两个条件: 某个原子对应的稀疏系数低于设定的阈值和该原子可在得到的噪声字典中找到,就把该原子对应的稀疏系数设为零,达到去除噪声的目的.虽然信号子空间算法具有计算量大、实时性较差的问题,但是文中只是利用子空间算法的最优估计器估计噪声,大大减少了计算量,实时性增强.并且子空间算法也可以弥补K-SVD算法误判几率大、SNR提高不明显的问题.
1 基于K-SVD算法训练过完备字典
K-SVD算法需要K次迭代,在迭代过程中先根据当前的字典更新稀疏表示系数,然后再利用此系数更新字典中的原子.它的过程也就是稀疏编码与字典更新的不断反复交替.
K-SVD算法构造的过完备字典目标函数为[4]
算法的具体步骤如下:
(1) 初始化字典,假设字典是固定的,赋予字典初始值.
(2) 稀疏分解,基于字典D对Y进行稀疏分解得到X.利用正交匹配追踪(Orthogonal Matching Pursuit,OMP)算法计算每个输入信号的稀疏表示,即
(3)

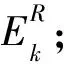
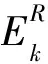
接下来进入下一次迭代,稀疏编码与更新字典交替完成,直到满足迭代条件为止.
2 利用子空间改进的K-SVD语音增强算法
在高SNR的情况下,噪声原子的能量明显小于语音信号的原子,K-SVD稀疏表示的语音增强效果明显; 在低SNR的情况下,由于信号和噪声的稀疏表示区别不明显,此算法的增强效果不佳.最典型的例子就是白噪声,它与清音部分非常相似[6],如果可以用字典表示清音,那么同样可以表示白噪声; babble噪声本身是一种语音,可以在训练的纯净语音字典中稀疏表示.为了验证噪声也具有稀疏性,对语音库中一段随机噪声的 5 000 点进行稀疏性分析,此信号采样频率为 8 kHz,帧长取128个样点.某帧噪声的稀疏表示如图1所示,可以清晰地看出,噪声在过完备K-SVD字典下是稀疏的,这将很可能导致增强性能的下降,造成严重的失真.为了解决这些问题,提出了利用子空间改进的K-SVD语音增强算法.
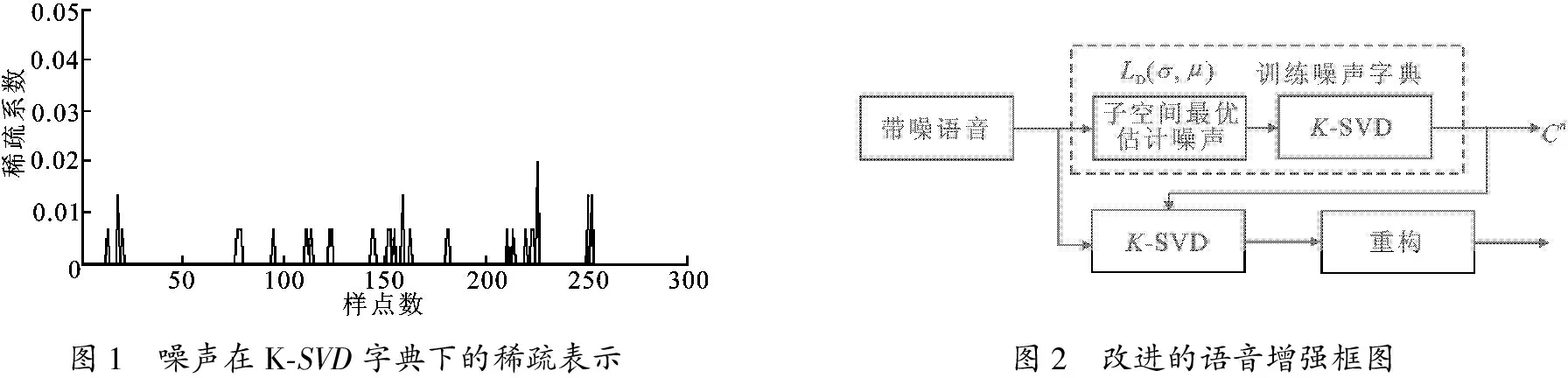
图1 噪声在K⁃SVD字典下的稀疏表示图2 改进的语音增强框图
2.1 利用子空间改进的K-SVD语音增强算法的基本框架
综上所述,整个算法的基本构架如图2所示,字典学习(Dictionary Learning,DL)用LD表示,该系统可以训练出噪声字典和噪声的非零稀疏系数,μ和σ分别表示字典语音增强阶段的相干阈值.
算法具体步骤如下:
(1) 通过子空间算法计算带噪语音的协方差矩阵Ry,对前 3 000 点进行采样计算噪声的协方差矩阵Rn.利用子空间最优估计器进行多次估计,找到噪声部分.为保证信号不发生较大的失真,在使用信号子空间算法时选择小的拉格朗日乘子,文中选择 μ= 0.3.

图3 语音增强后的SNR随μ变化的曲线图
参数μ对于信号最终的增强程度影响很大,图3显示了SNR为 -5 dB 的带噪语音利用子空间改进的K-SVD语音增强算法增强后SNR随参数μ的变化曲线图.由图可知,选取 μ= 0.3,可以最大提高SNR.
(2) 找到的噪声部分,在K-SVD过完备字典训练下,得到常用噪声的噪声字典同时得到所有非零的稀疏系数.
(3) 运用K-SVD算法对带噪语音进行训练得到语音字典,初始字典采用过完备DCT字典.
在K-SVD更新字典和稀疏编码中,可以通过匹配追逐原理(Matching Pursuit,MP)、OMP等匹配追踪算法和基追踪算法求取近似值,OMP算法是在MP算法基础上的一种改进算法,将所选原子正交化,再将信号投影到这些正交基上,得到语音分量和噪声分量,最后用相同方法迭代循环.由于OMP算法收敛速度比MP算法更快,文中使用OMP算法基于K-SVD进行追踪匹配.
(4) 使噪声部分在语音字典重新训练,同时可以在字典中找到频繁使用的k个原子.如果这些原子对应的稀疏系数低于某一阈值,并且也可以在得到的常用噪声的噪声字典中找到,那么就把这些原子对应的稀疏系数设为零,以达到去除噪声的目的.
2.2 子空间构造噪声字典
信号子空间[9]可通过选取适当的拉格朗日乘子,在抑制噪声和减少信号失真上做出较为折中的选择.帯噪语音信号的向量空间可以分成一个信号加噪声子空间和一个噪声子空间.子空间语音增强方法的基本思想就是将带噪语音信号投影到信号子空间(包含语音信号和噪声,其中语音信号占主要部分)和噪声子空间,然后尽可能地滤除噪声子空间,并保留信号子空间的信号部分,进而恢复出近似纯净的语音信号.
定义一个纯净信号x的模型,设x是一个k维零均值随机向量
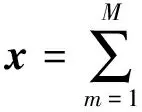
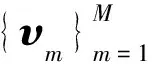
假设n为加性噪声信号,那么带噪语音y就可以表示为
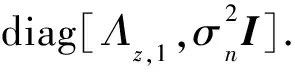
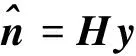
H=Rn(Rx+μ Rn)-1.
其中,μ是拉格朗日乘子.利用特征值分解,式(8)可以重新写为

假定一个过完备K-SVD字典Φ={d1,d2,…,dN}(k=1,2,…,N),则
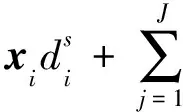
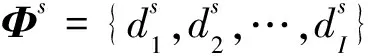
如果Φs∩Φn=Ø,那么将已得噪声字典中的噪声原子稀疏系数设置为零,然后通过式(11)重构,即
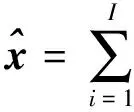
但是,轻易地把一个原子的稀疏系数设为零会有什么样的结果?如果 Φs∩ Φn=Ø,很可能造成语音信号严重失真.
(a) 若原子属于Φs而不属于Φn,则语音能量丢失,失真严重;
(b) 若原子同时属于Φn和Φs,强行设置原子系数为零,则去噪是以语音能量的损耗为代价的;
(c) 若原子属于Φn不属于Φs,则可以把噪声很好地消除.
在这里,希望找到所有的原子在(c)情况下,然后将其稀疏系数设置为零.所以为了避免(a)、(b)的情况,这里需要通过子空间算法多次估计噪声,再通过K-SVD训练找到合适的阈值,以至于可以找到频繁表示噪声和不频繁表示噪声的原子,使其达到良好地抑制噪声和减少失真的作用.
3 实验仿真
为了验证利用子空间改进的K-SVD语音增强算法,设计了两组实验.实验采用的是863语音库,采样频率为 8 kHz,初始字典是过完备DCT字典,其中字典的大小设为 1 024 个原子.使用SNR和SPSS[10-11]系统来验证并评价重构语音的质量.
实验1 考察白噪声和babble噪声环境下的算法效果.
在上一节中,提到噪声也可以稀疏表示,最典型的就是白噪声和babble噪声.实验采用noise-92语音库中的白噪声和babble噪声得到所需的带噪语音,并且在带噪语音SNR分别为 -10 dB、-5 dB、0 dB、5 dB、10 dB 和 20 dB 的情况下进行测试,如图4~5所示.
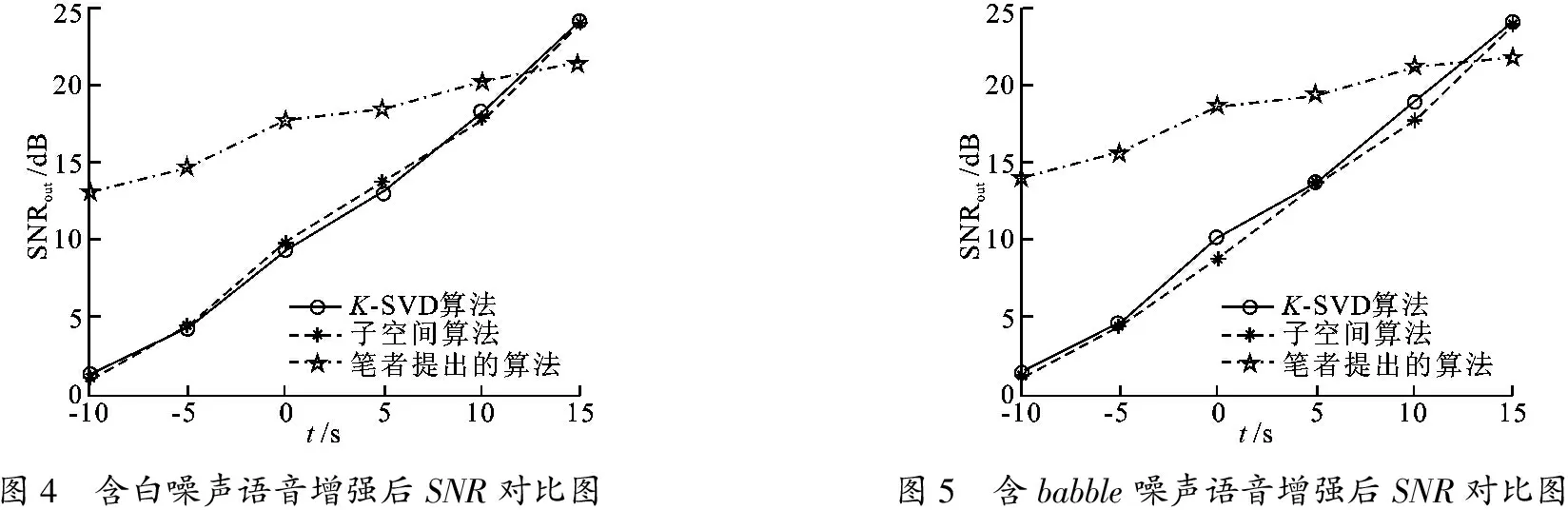
图4 含白噪声语音增强后SNR对比图图5 含babble噪声语音增强后SNR对比图
图4和图5分别表示了在白噪声和babble噪声环境下,3种算法增强后SNR的对比图.从图4可以看出,单独运用K-SVD和子空间算法的去噪结果是非常接近的; 图5显示在babble噪声中,K-SVD字典去噪效果是略胜过子空间算法的,因为babble噪声是时变噪声,对于子空间算法噪声谱估计比较困难.而文中提出的去噪方法在大部分SNR下是优于其他两种算法的,尤其是在低SNR情况下.
实验2 考察随机噪声环境下的算法性能.
实验条件同实验1,主要考察语音加随机噪声时,3种增强算法的性能比较.使用语音库中的一段男声信号和一段女声信号,加入SNR分别为 -10 dB、-5 dB、0 dB 和 10 dB 的随机噪声,分别用基于K-SVD字典、子空间及K-SVD与子空间的改进算法去噪.时域波形图如图6~7所示,不同输入SNR的结果如表1所示.

图6 男声-5dB不同算法去噪效果图7 女声-5dB不同算法去噪效果
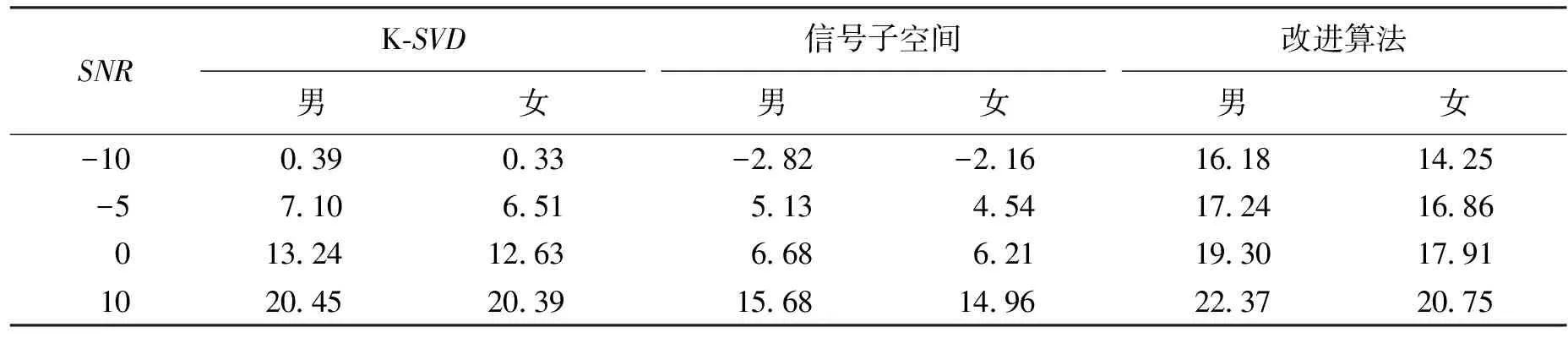
表1 各种算法去噪后的SNR结果 dB
图6~7分别表示男声、女声信号在-5 dB情况下的波形图,从波形可以看出,单独使用K-SVD、子空间方法虽在一定程度上降低了噪声干扰,但在非语音段仍有大量噪声; 而两者联合的方法仿真波形失真少,很好的刻画了局部信息.表1列出了SNR为 -10 dB、-5 dB、0 dB 和 10 dB 时的去噪结果,由此看出,文中方法在低SNR时大大优于单独使用K-SVD、子空间方法.
采用SPSS19.0数据统计软件分析不同SNR情况下,不同算法对语音增强是否存在显著性影响.SPSS数据统计中的指标(p表示显著性差异,其中低于0.5就为显著)统计分析中,原始数据为在SNR分别为 -10 dB、-5 dB、0 dB 和 10 dB 这4种情况下,3种算法对20句不同语音进行语音增强后得到的SNR,因此共得到 4×20 个数据.统计方法选用重复度量方差分析方法.统计分析结果如表2和表3所示.
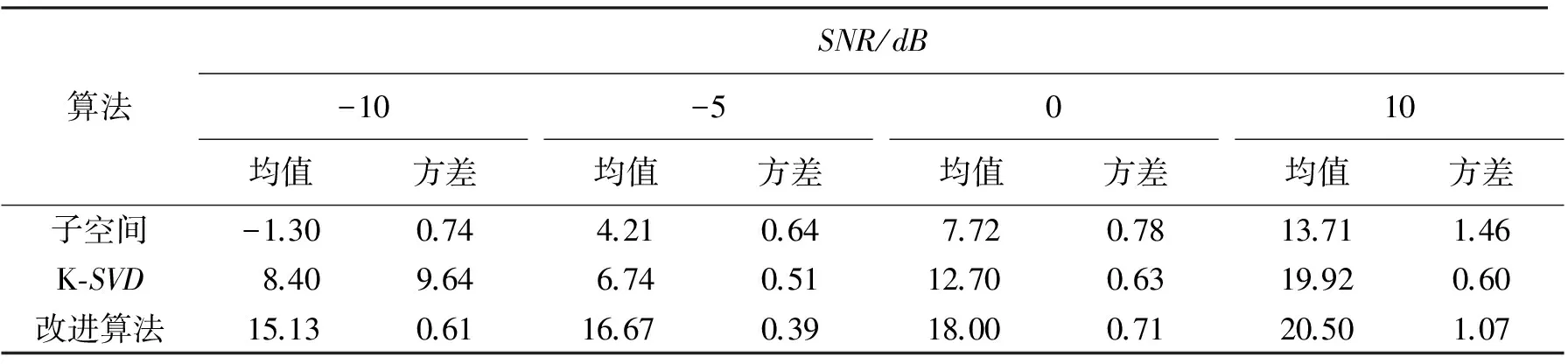
表2 3种算法增强后的性能对比

表3 相同SNR下的不同算法的对比
从表2可以看出,在同一SNR下,改进算法在3种算法中均值最大.K-SVD算法和子空间算法方差明显大于改进算法,此差距说明K-SVD算法和子空间算法语音增强效果不稳定、两极分化严重.所以,验证了3种算法中利用子空间改进的K-SVD语音增强算法性能最优.表3表明利用子空间改进的K-SVD语音增强算法的性能存在显著性差异,(F(2,125)= 312.95,P< 0.01).在SNR分别为 -10 dB、-5 dB、0 dB 情况下,文中提出的改进算法明显优于子空间算法和K-SVD算法 (P< 0.01); 在SNR为 10 dB 情况下,改进算法的性能仍然优于子空间算法,但与K-SVD算法性能没有明显的差异.由此可以说明,改进算法在低SNR的情况下性能最为突出,论证了前文的结论.
4 结 束 语
为了解决噪声(尤其是白噪声和babble噪声)在过完备K-SVD字典上稀疏的问题,结合子空间构造噪声字典,笔者提出了利用子空间改进的K-SVD语音增强算法.从仿真结果可以看出,在低SNR下,利用改进算法明显比子空间算法和K-SVD算法去除白噪声和babble噪声效果好,并且也改善了信号子空间计算量大、实时性差的问题.同时,通过大量实验验证了,利用子空间改进的算法对白噪声和babble噪声的良好效果也可以很好地应用于消除随机噪声.并且通过采用SPSS19.0软件评价了改进算法在低SNR的情况下,与K-SVD算法、子空间算法相比,其误判率大大降低,SNR有所提高,且减少了失真.
[1] 杨立春, 叶敏超, 钱沄涛. 基于多任务稀疏表达的二元麦克风小阵列话音增强算法[J]. 通信学报, 2014, 35(2): 87-94.
YANG Lichun, YE Minchao, QIAN, Yuntao. Speech Enhancement Based on Multi-task Sparse Representation for Dual Small Microphone Arrays[J]. Journal on Communications, 2014, 35(2): 87-94.
[2]MALLAT S G, ZHANG Z. Matching Pursuits with Time-frequency Dictionaries[J]. IEEE Transactions on Signal Processing, 1993, 41(12): 3397-3415.
[3]张君昌, 刘海鹏, 樊养余. 一种自适应时移与阈值的DCT语音增强方法[J]. 西安电子科技大学学报, 2014, 41(6):177-182.
ZHANG Junchang, LIU Haipeng, FAN Yangyu. Speech Enhancement Method Using Self-adaptive Time-shift and Threshold Discrete Cosine Transform[J]. Journal of Xidian University, 2014, 41(6): 177-182.
[4]DONOHO D L. Compress Sensing [J]. IEEE Transactions on Information Theory, 2006, 52(4): 1289-1306.
[5]孙林慧, 杨震. 基于数据驱动字典和稀疏表示的语音增强[J]. 信号处理, 2011, 27(12): 1793-1800.
SUN Linhui, YANG Zhen. Speech Enhancement Based on Data-driven Dictionary and Sparse Representation[J]. Signal Processing, 2011, 27(12): 1793-1800.
[6]HE Y J, HAN J Q, DENG S W, et al. A Solution to Residual Noise in Speech Denoising with Sparse Representation [C]//Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2012: 4653-4656.
[7]赵彦平. 基于稀疏表示的语音增强方法研究[D]. 长春: 吉林大学, 2014.
[8]AHARON M, ELAD M, BRUCKSTEIN A.K-SVD: an Algorithm for Designing Overcomplete Dictionaries for Sparse Representation [J]. IEEE Transactions on Signal Processing, 2006, 54(11): 4311-4322.
[9]BOROWICZ A. A Signal Subspace Approach to Spatio-temporal Prediction for Multichannel Speech Enhancement [J]. EURASIP Journal on Audio, Speech, and Music Processing, 2015, 2015(1): 1-12.
[10]ZHANG S J. An Analysis of English Majors Speech Perception Problems[J]. Journal of Chemical and Pharmaceutical Research, 2014, 6(6): 2472-2483.
[11]BALCIUNIENE I. Linguistic Disfluency in Narrative Speech: Evidence from Story-telling in 6-year Olds[C]//Proceedings of the Annual Conference of the International Speech Communication Association. Baixas: International Speech and Communication Association, 2013: 2143-2146.
(编辑:王 瑞)
Speech enhancement using the improvedK-SVD algorithm by subspace
GUOXin,JIAHairong,WANGDong
(College of Information Engineering, Taiyuan Univ. of Technology, Taiyuan 030024, China)
In the case of a low SNR, it is difficult that the clean speech is separated completely by sparse representation from the noisy speech. To solve the above problem, a speech enhancement method using the improvedK-SVD algorithm by subspace is proposed. First, the noise is tracked by the optimal estimator of the subspace, and a noise dictionary is trained by using theK-SVD. Then, the speech dictionary is trained by theK-SVD algorithm. In the process of training, if an atom whose sparse coefficient is lower than the set threshold and could also be found in the noise dictionary, the sparse coefficient is set to zero, which achieves the goal of de-noising. Simulation results show that the algorithm can remove white noise and babble noise obviously, so that the SNR is improved and distortion is reduced greatly. Simultaneously, this improved algorithm can also be applied to eliminate the random noise very well. And the improved algorithm verified by SPSS19.0 software is superior to theK-SVD algorithm and subspace algorithm under a low SNR.Key Words: speech enhancement;K-SVD; sparse representation; subspace
2015-08-28
时间:2016-04-01
国家自然科学基金资助项目(61370093);山西省青年科技研究基金资助项目(2013021016-1);山西省自然科学基金资助项目(2013011016-1);校基金团队资助项目(2014TD028,2014TD029)
郭 欣(1990-),女,太原理工大学硕士研究生,E-mail:Gxin189@126.com.
贾海蓉(1977-),女,副教授,博士,E-mail:helenjia722@163.com.
http://www.cnki.net/kcms/detail/61.1076.tn.20160401.1622.038.html
10.3969/j.issn.1001-2400.2016.06.019
TN912.35
A
1001-2400(2016)06-0109-07
猜你喜欢
家教世界(2023年28期)2023-11-14 10:13:50
家教世界(2023年25期)2023-10-09 02:11:56
少儿科学周刊·儿童版(2021年22期)2021-12-11 21:27:59
少儿科学周刊·儿童版(2021年22期)2021-12-11 21:27:59
少儿科学周刊·儿童版(2021年22期)2021-12-11 06:42:32
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
创新作文(小学版)(2016年19期)2016-08-22 05:54:08
