
伪特权信息和SVM+
2016-12-20 06:23孙广玲
西安电子科技大学学报 2016年6期
孙广玲,董 勇,刘 志
(上海大学 通信与信息工程学院,上海 200072)
伪特权信息和SVM+
孙广玲,董 勇,刘 志
(上海大学 通信与信息工程学院,上海 200072)
针对只有部分训练样本拥有特权信息的特权学习,提出了伪特权信息及相应的SVM+.一方面,对于无特权信息的样本额外构造伪特权信息,使得这部分样本的松弛变量可在修正空间中预测,从而有效地提高了模型泛化能力.可用信息和随机特征都是有效的伪特权信息.另一方面,将真正特权信息用伪特权信息取代,使得全部训练样本的松弛变量都在惟一的修正空间中预测.在实践中发现,至少对于某些真正的特权信息和二分类问题来说,使用一个修正空间可获得更优的泛化能力.在手写数字和人脸表情识别问题上进行的实验结果显示,采用伪特权信息的SVM+具备一定的优势.
特权学习;伪特权信息;SVM+
利用特权信息的学习(Learning Using Privileged Information, LUPI)是近年来机器学习领域发展较快的一个方向[1-2].其意图在于模仿人类“教”与“学”中的一个重要现象:在学生的学习阶段,一个好的教师除了提供实例,还要提供相关的其他信息,而这些信息是在非学习阶段(学生利用学习得来的知识独立解决问题而不再依赖于教师)不可获得的,因此称为特权信息.在学习阶段提供特权信息的意义是: 相对于只提供实例,可以使学生获得更好的知识,从而提高其未来独立解决问题的能力.自然地,人们可以构建体现类似思想的机器学习模型,以使学习得来的模型拥有更强的泛化能力.相对于特权信息,称训练样本和测试样本都可获得的信息为可用信息.
最早的属于利用特权信息的学习模型是SVM+[2].自SVM+提出之后,无论是模型、算法还是应用方面,在利用特权信息的学习领域研究者们已发表了很多研究成果.对比属于有监督学习的SVM+,文献[3]中研究了利用特权信息的无监督聚类问题,并将其用于金融领域的预测模型[4].文献[5]中给出了特权经验风险最小化相对于常规经验风险最小化可获得更快收敛速度的理论分析.文献[6]中提出了Information-Theoretic Metric Learning+(ITML+),试图用特权信息修正可用信息空间中每一对训练样本的损失,并用于RGBD中的人脸认证和身份重认证.文献[7]中提出了Gaussian Process Classification+(GPC+),特权信息被看做GPC隐函数中的噪声,从而可以被用于较好地评价可用信息空间中训练样本的可利用程度.文献[8]中分析出SVM+的主要作用等效于在支持向量机(Support Vector Machine,SVM)的目标函数中,利用特权信息给出每个训练样本的权重.文献[9]中提出基于Structural SVM+(SSVM+)的目标定位方法,扩展了之前基于特权学习的模型仅用于分类的应用场景.类似地,文献[10]中研究了利用特权信息的结构化输出条件回归森林算法,用于定位人脸的特征点.文献[11]中强调有相对排序关系的属性作为特权信息或是文献[12]中利用特权信息学习属性排序对于提升分类器性能的作用,而这相对排序关系是基于一定的学习模型得到的,恰好可与SVM+的模型一致地形成一个整体.
上述研究无一不在强调特权信息的作用,但更多的研究目的是比较训练样本有无特权信息时,分类器性能的差异.然而存在另一方面的问题是,由于获取方法的特殊性,或者获取的成本较高,或者其他原因,在很多现实应用中,仅部分的训练样本才拥有特权信息.对于此种情况,Vapnik提出了Partial SVM+(PSVM+),对于有特权信息样本的松弛变量,利用修正函数预测.对于无特权信息样本的松弛变量,仍然利用决策函数预测[2].这是自然和直观的方法.但是在小样本的学习问题中,决策函数较高的VC(Vapnik-Chervonenkis)维使得无特权信息部分的样本易产生过学习.固然可以只利用有特权信息的样本,但在小样本问题中,样本本身是“最宝贵”的资源,不可丢弃.因此,在保证利用所有样本的前提下,笔者提出了对于无特权信息的样本额外构造一种特权信息,称为伪特权信息,使得这部分无特权信息的样本也可以在修正空间中利用修正函数预测松弛变量,以有效地降低过学习的概率.笔者构造了两种伪特权信息,即训练样本的可用信息和随机特征.另外,也是在利用所有样本的同时,还可以使得全部的训练样本都采用伪特权信息而预测松弛变量.实验结果说明,至少对于某些真正的特权信息和二分类问题来说,该策略可以获得更强的泛化能力.
1 采用伪特权信息的SVM+
由前分析可知,PSVM+分别用修正函数和决策函数预测有无特权信息这两个样本集的松弛变量.然而一个显然的问题是: 在小样本的学习问题中,用VC(Vapnik-Chervonenkis)维较高的决策函数直接预测无特权信息样本的松弛变量易导致模型过学习.因此,对于无特权信息的样本,可设想构造伪特权信息,用于在修正空间和利用修正函数预测无特权信息样本的松弛变量.依据文献[2]中的分析,伪特权信息及修正空间的引入可提高无特权信息样本学习的收敛速度,从而提高了整个模型的泛化能力.实践中也证明了该策略的确可使在相同的数据集下,模型的泛化能力得到提升(见实验相关部分).该模型在下文中称为形式Ⅰ.另一方面,在引入伪特权信息之后,模型中必然要考虑两个修正函数的复杂度问题,从而增加了整个模型的风险.笔者试图从只保留一个修正空间的角度提出另一种模型.这时无非有两种选择:一种是只利用那部分有真正特权信息的样本;另一种选择是丢弃真正的特权信息,代之以伪特权信息.由于前者样本数目直接决定了风险的界,而且在小样本的问题中,样本是更加“宝贵”的资源,不可丢弃.因此,选择后者并生成新的模型,称为形式II.此时所有训练样本的特权信息皆为伪特权信息,且模型中只保留一个修正空间.下面给出这两种形式模型的定义及求解.
1.1 形式Ⅰ
为部分样本引入伪特权信息之后,与真正特权信息联合预测样本松弛变量并考虑两个修正函数复杂度的,在原空间中的SVM+的目标泛函及约束为
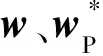
将其转换至对偶空间中求解:
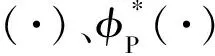
1.2 形式Ⅱ
将伪特权信息样本扩展至全部样本,式(1)可变化为如下的形式:
同样,将其转换至对偶空间中求解:
上式中所有符号含义与形式Ⅰ中的相同.不难发现,该模型与SVM+的定义一致,只是有关特权信息的表示或计算用相应的伪特权信息取代,因此也可视为SVM+的特例.
为了更显明地表示上面两种形式,下文中将形式Ⅰ简记为P3SVM+(Pseudo-Privileged information based Partial SVM+),将形式Ⅱ简记为P2SVM+(Pseudo-Privileged information based SVM+).至于这伪特权信息如何构造,其一是选择训练样本的可用信息用作伪特权信息.在此种情况下,特权信息可视为与可用信息相同.其二是将服从一定分布的随机变量用作伪特权信息,具体方法参见实验部分.两种形式的模型都转换至对偶空间并采用标准的二次规划算法求解.
2 实验和分析
2.1 实验数据库介绍
(1) 手写数字识别和MNIST数据库.MNIST数据库拥有大量手写数字图片,且分辨率为28×28[13].为了使分类问题更具难度,Vapnik和Vashist将这些图片大小统一转换成 10×10 的分辨率,并且只关注数字5和8之间的分类问题.用http://ml.nec-labs.com/download/data/svm+/mnist.priviledged中提供的转换后的数据进行实验,可用信息是100维的像素信息,特权信息是21维的属性描述特征,例如某个数字具有对称性,可以给它定义一个实数来表征对称性的强度等.
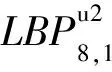
2.2 MNIST5-8分类数据集
选取训练集、验证集、测试集的样本个数分别为70,4 002 和 1 866 个.其中70个训练样本是从全部100个有属性特权信息的样本中随机地抽取20次,学习各模型,然后在固定的 1 866 个测试样本上测试.而各模型参数的最优参数由获得最高识别率的验证集确定.表1为各模型参数的取值情况.

表1 MNIST5-8分类数据集实验各模型参数设置
表1中的P3SVM+A和P3SVM+R分别表示将可用信息和随机特征用作伪特权信息的P3SVM+.类似地,P2SVM+A和P2SVM+R分别表示将可用信息和随机特征用作伪特权信息的P2SVM+.
随机特征生成和维数选择如下所述.

图1 带有属性特权信息的MNIST5⁃8分类数据集,不同数量特权信息样本和不同模型识别率随随机特征维数的变化曲线图2 带有属性特权信息的MNIST5⁃8分类测试结果(所有模型的学习样本总数都为70个)
P3SVM+和P2SVM+涉及到伪特权信息中的随机特征如何生成的问题.笔者选择的随机分布是0-1均匀分布.为了进一步地确定维数,进行了以下测试: 当有属性特权信息训练样本的个数分别为20,35,50,且维数分别为1,25,50,75,100时,测试了P3SVM+R及P2SVM+R的识别率,而其他参数分别与P3SVM+A及P2SVM+A相同.结果如图1所示.依据这个结果,选择随机特征的维数是25.图2显示了不同模型的识别性能.其中,SVM+表示学习样本只包含有属性特权信息的样本,SVM表示利用全部70个样本但只是可用信息学习.从实验结果中可以看出,在只有20和35个属性特权信息样本的学习中,SVM+的表现是最差的;而当样本数增加到50时,其表现与PSVM+接近.另外一方面,对于PSVM+和P3SVM+A(R)来说,不同数量的特权样本对识别率的影响并不大.这个结果充分说明,学习样本的总量相对属性特权信息样本的数量而言,对提升分类器的性能起更重要的作用.在3种不同特权信息样本数的情况下,P3SVM+A(R)的表现优于PSVM+的,P2SVM+A(R)的表现也优于SVM的.值得关注的是,P3SVM+A(R)甚至低于SVM,与P2SVM+A(R)高于SVM的结果联合分析,可以认为真正特权信息和伪特权信息引入的修正空间并存,至少在该例当中,的确增加了学习模型的风险.
2.3 Bosphorus人脸表情识别
从数据库中随机抽取65个人作为实验数据,身份无交叠地划分为训练集、验证集、测试集,其中30个人是训练集,20个人是验证集,15个人是测试集.同样地,实验中所有涉及识别率的结果都为交叉验证20次的平均数据.各模型最优参数仍依据验证集确定.

表2 Bosphorus数据库实验各模型参数设置
对于PSVM+,当灰度特权信息样本的比例变化时,相应的最优参数也有所区别,具体见表2.
随机特征生成和维数选择如下所述.
同样生成服从0-1均匀分布的随机特征.对于维数的选择,进行了类似的实验,得到的结果如图3所示.从曲线的变化趋势可以看出,900维是比较合适的选择.
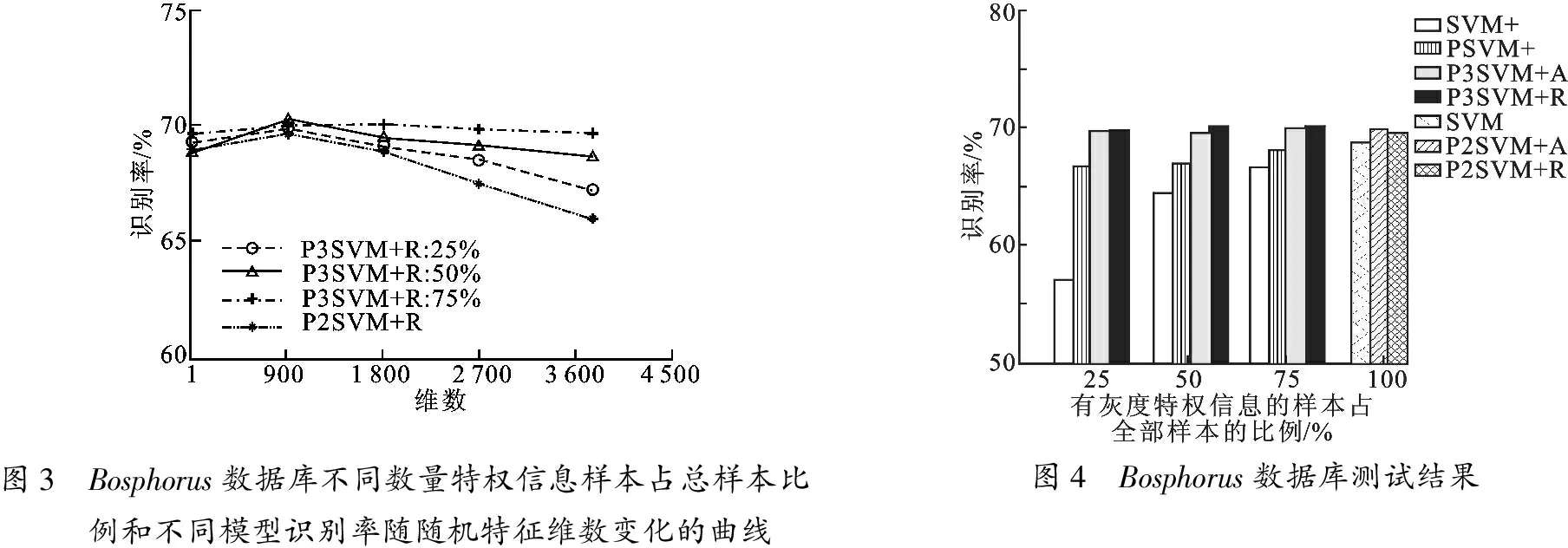
图3 Bosphorus数据库不同数量特权信息样本占总样本比例和不同模型识别率随随机特征维数变化的曲线图4 Bosphorus数据库测试结果
图4呈现的各模型整体的识别率,再次反映了P3SVM+A(R)相对于PSVM+以及P2SVM+A(R)相对于SVM的优势.至于该实验中体现出的其他问题及相应的分析,都与2.2节类似,此处不再赘述.但是与2.2节结果不同的是,P3SVM+A(R)的识别率高于SVM的,也与P2SVM+A(R)的识别率基本一致.这说明真正特权信息的具体选择也在相当程度上影响了模型学习的收敛速度,而不仅仅是模型的结构.
3 总 结
笔者提出了将可用信息和随机特征用作伪特权信息的P3SVM+模型和P2SVM+模型.P3SVM+模型的特点是伪特权信息与真正特权信息并存,P2SVM+模型的特点是全部样本的特权信息都是伪特权信息.在MNIST5-8分类数据集和Bosphorus人脸表情识别数据库上的实验结果,说明了笔者所提模型具备一定的优势.今后的工作将着重于研究如何生成更有效的伪特权信息.
[1] VAPNIK V, VASHIST A, PAVLOVITCH N. Learning Using Hidden Information(Larning with Teacher)[C]//Proceedings of the International Joint Conference on Neural Networks. Piscataway: IEEE, 2009: 3188-3195.
[2]VAPNIK V, VASHIST A. A New Learning Paradigm: Learning Using Privileged Information[J]. Neural Networks, 2009, 22(5/6): 544-557.
[3]FEYEREISL J, AICKELIN U. Privileged Information for Data Clustering[J]. Information Sciences, 2012, 194: 4-23.
[4]RIBEIRO B, SILVA C, VIEIRA A, et al. Financial Distress Model Prediction Using SVM+[C]//Proceedings of the International Joint Conference on Neural Networks. Piscataway: IEEE, 2010: 5596729.
[5]PECHYONY D, VAPNIK V. On the Theory of Learnining with Privileged Information[C]//Advances in Neural Information Processing Systems 23: 24th Annual Conference on Neural Information Processing Systems. Vancouver: Neural Information Processing Systems Foundation, 2010: 1894-1902.
[6]XU X X, LI W, XU D. Distance Metric Learning Using Privileged Information for Face Verification and Person Re-identification[J]. IEEE Transactions on Neural Networks and Learning Systems, 2015, 26(12): 3150-3162.
[8]LAPIN M, HEIN M, SCHIELE B. Learning Using Privileged Information: SVM+and Weighted SVM[J]. Neural Networks, 2014, 53: 95-108.
[9]FEYEREISL J, KWAK S, SON J, et al. Object Localization Based on Structural SVM Using Privileged Information[C]//Advances in Neural Information Processing Systems27: 28th Annual Conference on Neural Information Processing Systems. Vancouver: Neural Information Processing Systems Foundation, 2014: 208-216.
[10]YANG H, PATRAS I. Privileged Information Based Conditional Structured Output Regression Forest for Facial Point Detection[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2015, 25(9): 1507-1520.
[11]SHARMANSKA V, QUADRIANTO N, LAMPERT C H. Learning to Rank Using Privileged Information[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE, 2013: 825-832.
[12]WANG S Z, TAO D C, YANG J. Relative Attribute SVM+learning for Age Estimation[J]. IEEE Transactions on Cybernetics, 2016, 46(3): 827-839.
[13]LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based Learning Applied to Document Recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[14]SAVRAN A, ALYÜZ N, DIBEKLIOLU H, et al. Bosphorus Database for 3D Face Analysis[M]. Lecture Notes in Computer Science:5372. Heidelberg: Springer Verlag, 2008: 47-56.
[15]AHONEN T, HADID A, PIETIKAINEN M. Face Description with Local Binary Patterns: Application to Face Recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28(12): 2037-2041.
(编辑:郭 华)
Pseudo-privileged information and SVM+
SUNGuangling,DONGYong,LIUZhi
(School of Communication and Information Engineering, Shanghai Univ., Shanghai 200072, China)
In machine learning, learning using privileged information(LUPI) tries to improve the generalization of the classifier by leveraging information only available during learning. In the scenario of privileged information(PI) possessed by partial training samples, pseudo-privileged information(PPI) and SVM+are investigated. The proposed models depend on two formulations. One is to construct PPI for the samples without PI alone. The formulation enables slacks of such samples predicted in the correcting space with an ultimate goal of improving the generalization of the classifier. Available information and random features are proved to be effective options for PPI. The other is to replace the genuine PI with PPI so as to predict the slacks of all training samples in the unique correcting space. It is confirmed that at least for certain genuine PI and two categories classification task, the latter one is capable of obtaining better generalization performance. Experiments are performed on written digits and facial expression recognition. The results have validated advantages of SVM+using PPI.
learning using privileged information; pseudo-privileged information; SVM+
2015-10-26
时间:2016-04-01
教育部科学技术研究重点资助项目(212053);上海市自然科学基金资助项目(16ZR1411100)
孙广玲(1975-),女,副教授,E-mail: sunguangling@shu.edu.cn.
http://www.cnki.net/kcms/detail/61.1076.tn.20160401.1622.036.html
10.3969/j.issn.1001-2400.2016.06.018
TP391.41
A
1001-2400(2016)06-0103-06
猜你喜欢
数学物理学报(2022年4期)2022-08-22
好日子(2022年3期)2022-06-01
湘潮(上半月)(2021年12期)2022-01-18
数学物理学报(2020年3期)2020-07-27
科技创新与应用(2020年6期)2020-02-29
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
浙江人大(2014年6期)2014-03-20
郑州大学学报(理学版)(2012年4期)2012-03-25
燃气涡轮试验与研究(2010年4期)2010-04-16
