
基于Web的主题内容提取与存储系统研究
2016-12-15 02:47朱林
软件 2016年11期
朱 林
(东南大学成贤学院,江苏 南京 210088)
基于Web的主题内容提取与存储系统研究
朱 林
(东南大学成贤学院,江苏 南京 210088)
为了快速提取网页中的主题内容,本文对基于Web的主题内容提取与存储系统进行了较为深入的研究,从系统总的设计思想、架构设计、各个组件的关键实现技术等方面进行了分析,使人们可以基于WEB准确且迅速的提取到相应的主题内容,大大提高人们的工作效率。
Web;主题内容提取;存储系统
本文著录格式:朱 林. 基于Web的主题内容提取与存储系统研究[J]. 软件,2016,37(11):30-32
0 引言
互联网上存在大量的Web网页,每一个网页通常都会有某个主题,基于Web的主题内容提取与存储系统可以帮助人们实现对自己所关注主题的网页内容的快速提取,并且可以存储起来以方便人们查看那些提取到的内容。可以节省寻找目标网页与内容的时间,让人们在茫茫的信息海洋里准确且迅速地提取到有关某个主题的信息,对于人们的工作效率而言具有重大意义。
1 系统总体思想
在设计基于Web的主题内容提取与存储系统时,可以事先设定一个搜索范围,即设定搜索的网站,可以按照人们所需要的主题去搜索并显示出搜索的结果,最后存储到数据库中去,而且这个系统可启可停,在需要的时候启动它,不需要的时候停止它,不会去无限占用存储空间[1]。具体设计思想如下:
1.1 多个部分,一个整体
将系统重要的部分分成一个个独立的小部分,这样设计起来思路清晰,效率高。就像汽车组装的流水线一样,将汽车分为各个部分,最后进行组装形成最终的成品。这样的设计使得整个系统的布局很规则,哪个部分负责什么,一看就能知道。而且当程序员进行修改或者查错时也很节约时间,很方便。最后将每个独立的小部分连接起来。
1.2 简单,易操作
功能不要太眼花缭乱,注重实际需求,抓住用户最需要的功能。用户可以通过简单的操作达到提取与存储的目的,方便的提取到自己所需主题内容并且一眼就能看到结果。用户不需要清楚系统是如何实现的,只在乎如何用最少的时间来完成操作并获得结果。这样的设计对于用户来说是绝对正确和实用的[2]。
1.3 完全开放,人性化
系统是完全开放的,用户不仅可以使用现有的
功能而且还能在代码里编写设置自己所需要的其它功能,可以使此系统更为强大,十分人性化。
2 系统架构设计
可以使用模块化的设计方法来设计该基于Web的主题内容提取与存储系统的架构[3],系统程序模块化的设计对于某些规模较小的程序来说并不一定能够带来什么方便之处,但是对于规模较大或者说后期可以加以拓展的系统程序来说进行模块化设计还是很有利的。首先,模块化设计之后各个模块之间是相对独立的,其次各个模块的功能也是相对固定单一的,最后最大的好处就是结构十分清晰,处理问题相当方便。
本系统可以分为网页下载,页面解析,URL抓取,提取结果处理和系统数据库这几大部分,以及一个简约的可视化界面,这个界面设计方便了用户的操作。系统总体的架构图如图1所示:
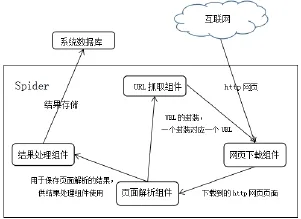
图1 基于Web的主题内容提取与存储系统架构
整个系统的结构十分清晰,每个部分具体负责什么工作内容也十分明显。Spider可以看成一个大容器,系统的各个部分在这个容器里面彼此联系。从互联网下载的网页会传递给页面解析组件进行解析,提取出的主题内容再传递给结果处理组件,持久化到系统数据库。页面解析时获取后续URL并传递给URL抓取组件存入队列,通过URL网页下载得以继续。
系统的总体功能也是按照各大模块部分来设计。网页下载部分的功能是实现从互联网上下载所需要的网页,将这些下载好的网页传递给页面解析组件,页面解析组件的功能主要有两个:一是对页面主题元素的提取,二是获取系统的后续URL以供网页下载组件下载网页。URL抓取组件的功能也是分为两个,第一个是对于URL待抓取队列的管理,第二个是URL去重的工作,主要是去除那些相同的URL,以免重复下载相同的网页,耗费内存。提取结果处理组件的功能也可以分为两部分来设计:一是对于提取结果的处理,可以使用户自行选择结果存储路径,此系统只提供存储到数据库这个一个存储路径,其他的路径用户可自行开发。二是提取内容结果持久化到数据库。将整个系统的数据存储到系统数据库中。
3 系统实现关键技术
系统实现时主要考虑以下四个方面的关键技术:
3.1 网页下载组件实现
网页下载组件是基于Web的主题内容提取与存储系统运行的起点,可以利用开源爬虫工具来编写,基于HttpClient下载网页的URL,获取网页的源代码和其他重要属性信息,下载之后交付给页面解析组件进行解析。
一般情况下不希望相同的网页被重复下载多次,这样就会耗费计算机资源,所以要进行URL的去重处理。URL去重方式很多,主要有基于内存去重、基于数据库去重、基于磁盘路径去重和基于布隆过滤器去重等方法。基于Web的主题内容提取与存储系统可以选用基于内存的去重方式,它是在每次网页开始下载时,将URL全部存入内存中的哈希表,然后在哈希表中进行查找、匹配等操作。例如当系统需要检测某个URL是否已经存在时,只需要将这个URL做一次哈希映射,映射之后得到的地址如果重复,就放弃下载,否则,就将这个URL及其对应的哈希地址作为关键码存放进哈希表中。
3.2 网页解析组件实现
网页解析组件主要由两个子模块组成,一是对网页页面元素的提取模块,二是页面元素提取完之后的后续链接的发现模块[4]。
主题内容的提取归根结底是页面元素的提取,是整个系统的核心部分。用户需要什么样的主题内容,系统就去提取页面中什么样的主题元素。可以使用正则表达式regex和XML路径语言XPath这两种页面元素提取技术来实现。
系统在运行是不可能一下子保存某个网站所有页面的URL,所以在页面解析的基础上发现后续的新的链接对于系统来说也是尤为重要的。例如对于网站的URL特征是"http://www. xxx.com/xxx/ xxx/..../"格式的网页而言,后续链接的选择在规则上
可以利用了正则表达regex跟踪和实现。代码如下:

代码可以分为两个部分来看,首先后续链接必须符合"(https://www\.com/\w+/\w+)"这个正则表达式,然后通过page.addTargetRequests将符合要求的URL加入到URL待抓取队列中去。此时就完成了系统中后续链接的发现工作。
3.3 URL抓取组件实现
基于Web的主题内容提取与存储系统使用的是内存队列来保存和管理待抓取的URL队列。可以利用了深度优先遍历策略来实现URL的抓取。所谓深度优先遍历抓取策略简单的说就是:系统从给定的第一个URL开始,当系统解析完这个页面的元素之后,就会转入下一个网页,一个链接一个链接抓取下去[5]。因为页面解析部分提供了新链接的发现功能,所以不需要担心没有下一个链接来抓取。
3.4 结果处理组件实现
结果处理组件可以对页面解析组件中提取主题内容元素结束时的结果进行处理,这有利于模块之间的分离,分离开来之后代码编写的结构会十分清晰。另外,对于抽取结果的后期处理可以定制不同的功能,比如结果的保存方式,可以选择将其保存到文件还是保存到数据库,如果用户自己定制了多种保存方式,但只想用里面的一种方式就需要使用如下代码:

如果说想用两种方式结合起来的话也很简单,代码如下:

如果将提取出的主题内容存储到数据库,就可能涉及到数据持久化的问题。数据持久化需要将内存中的数据模型转变为存储模型,或者将存储模型转变成数据模型。在实现的时候,系统中提取出的主题内容结果都在HashMap对象resultItems中[6],通过以下代码分别调出主题内容结果:


因为resultItems是一个HashMap形式,即
在将结果持久化到数据库时需要使用sql插入语句将得到的结果存入数据库中,其中的sql语句如下:

为了防止注入攻击,可以使用预编译的状态集对象 preparedstatement,参数用setXXX方法进行填装。完成结果存储。
4 总结
本论文从对WEB主题内容准确而快速的提取和存储出发,首先阐述了系统设计的总体思想,然后基于此设计系统的总体架构,并提出了详细的系统实现关键技术,大大提高系统的性能和人们的工作效率。
[1] 陈立玮, 冯岩松, 赵东岩. 基于弱监督学习的海量网络数据关系抽取[J]. 计算机研究与发展. 2013(09).
[2] 王元卓, 靳小龙, 程学旗. 网络大数据: 现状与展望[J].计算机学报. 2013(06).
[3] 高乐, 张健, 田贤忠. 基于视觉的Web页面分块算法的改进与实现[J]. 计算机系统应用. 2009(04).
[4] 郑津杨, 樊雨婷. 基于匹配树方法的RFID 标签信息归类方法设计[J]. 软件, 2015, 36(12): 154-157.
[5] 潘昊,鄂海红,宋美娜. 布隆过滤器在网页消重中的应用[J]. 软件, 2015, 36(12): 166-170.
[6] 杨淙钧, 艾中良, 刘忠麟, 等. 基于多级列式索引的海量数据高效查询设计[J]. 软件, 2016, 37(3): 79-83.
Research on Topic Content Extraction and Storage System Based on Web
ZHU Lin
(Southeast University chengxian College, Nanjing jiangsu Province, 210088, China)
In order to extract web page theme, this paper studied topic extraction and storage system based on Web, analyzes the key system design, architecture design, component technique, so that people can be based on an accurate and rapid extraction of WEB to the corresponding theme and improve the work efficiency of people.
Web; Topic content extraction; Storage system
TP393.092
A
10.3969/j.issn.1003-6970.2016.11.007
2014年江苏省现代教育技术研究“面向软件工程课程群的网络教学支撑系统研究”(2014-R-31607);东南大学成贤学院“青年教师科研发展基金”项目(y380001)。
朱林(1981-),男,硕士,讲师,研究方向:软件工程,电子商务。
猜你喜欢
保健医苑(2022年1期)2022-08-30
哈尔滨轴承(2020年2期)2020-11-06
发明与创新·大科技(2019年12期)2019-03-17
电子制作(2018年10期)2018-08-04
电子制作(2017年2期)2017-05-17
电子测试(2015年18期)2016-01-14
中国教育信息化(2015年12期)2015-08-24
电测与仪表(2015年10期)2015-04-09
计算机与网络(2014年7期)2014-03-25
网络安全技术与应用(2011年3期)2011-03-14
