
web日志挖掘中会话识别方法
2016-12-14 06:45:28陈海光
上海师范大学学报·自然科学版 2016年5期
袁 艺, 陈海光
(上海师范大学 信息与机电工程学院,上海 200234)
web日志挖掘中会话识别方法
袁 艺, 陈海光
(上海师范大学 信息与机电工程学院,上海 200234)
通过对传统web会话识别方法分析和比较,改进了目前最常用的基于时间阈值会话识别方法,提出了一种基于动态阈值会话识别方法,该算法采用动态计算会话中请求记录间的平均时间间隔和动态计算会话中页面的平均大小相结合的方法,根据用户和网页的特点动态调整阈值,相对于传统单一的先验阈值,该方法可以根据不同的用户访问不同的页面生成动态的阈值,充分运用用户和网页信息.经过实验验证,该方法可以识别出更多的用户会话,且识别会话的准确率和查全率也比传统算法更高.
web挖掘; 会话识别; 时间阈值; 数据预处理
0 引 言
随着Internet 的不断发展,越来越多的组织、企业、机构通过网络与用户交流或交易.为了留住已有用户,争取潜在客户,必须使自己的网站更加实用,更加有吸引力.为了实现这个目标,一般有两种方法,第一种是通过要求用户对浏览过的页面,提交浏览体验,得到用户的喜好、兴趣.第二种是通过对用户的访问日志进行分析,从而获取用户的浏览习惯,提高和改进网站.
web日志分析,通过分析用户访问网站的日志来得到用户的访问模型,从而获取用户的个人兴趣和访问习惯,调整网站内容,优化网站结构,发展个性服务,发掘潜在用户.在web日志挖掘中web日志预处理的会话标识最重要和最耗时.会话识别的目的是将用户的多次请求划分成一个个独立的会话,每个会话代表一次访问过程,只有用户的这些原始会话被识别后,才能应用web数据的挖掘算法挖掘用户模式,从而优化网站,发展个性服务,挖掘潜在用户.
1 web日志挖掘数据预处理
web日志挖掘预处理阶段主要有以下几个步骤组成:数据清洗、用户识别、会话识别.
1.1 清洗数据
web日志数据本身的特点不能直接用于日志挖掘,因此,数据清洗的目的就是把日志数据格式化,删除不相干数据,合并能合并的数据域,生成新的格式,使其适合挖掘算法.
首先要对web数据清洗,删除不相关的数据:
1) 去掉爬虫软件和搜索代理等网络机器人访问请求;
2) 删除无效页面;
3) 删除以head为请求方式的web日志;
4) 删除框架、CSS文件、脚本等非用户请求的逻辑单位;
5) 对图片、视频进行处理,计算网页大小.
1.2 用户识别
如果一个网站必须用户登录以后才可以浏览网页,用户识别将变得非常简单,只要根据用户名就可以很好识别用户,但是现在绝大多数网站都允许访问者匿名浏览网页,在这种情况下,用户识别就很具有挑战性.如果网站使用的是通用日志格式(common log format)来记录用户请求记录,那么就只能使用IP地址来区分用户,因为common log format没有记录关于操作系统和浏览器等信息.当然也可以使用cookies来识别用户,当客户端用户启用cookies时,第一次请求访问某个网站,该网站服务器在返回所请求内容的同时会返回相应的cookie,当下一次该用户请求访问同一个网站其他页面时,如果cookie没有过期,那么用户浏览器会把cookie和请求一起发给服务器,从而服务器可以识别用户.但是因为cookies存在一些问题,一般不被用于用户识别,首先客户端可能会禁止cookies使用,或者手动清除掉存储在自己机器上的cookies,其次cookies使用可能会侵犯用户的隐私.
下面是最常使用的用户识别方法:
1) 不同的IP地址代表不同的用户;
2) 相同的IP地址,但用户代理(Agent)数据域中的操作系统或浏览器不同,则可以认为是不同用户;
3) 如果IP地址、操作系统和浏览器都相同,则判断每一个请求的页面与访问过的页面之间是否有链接,如果一个请求访问的页面与之前访问的所有页面都没有直接的链接,则假设是不同用户.
然而,以上的规则并不能保证准确识别出每一个用户,因为有时无法从web日志中获取浏览器和操作系统信息,即像Common Log Format这样的日志并不包含Agent相关信息,即使使用的是扩展日志,同一个用户也可以同时使用不同操作系统或浏览器访问web服务器,将被认为是不同用户.具有相同IP地址的多个用户使用相同操作系统和相同浏览器,并且看过的页面集合也一样会被认为是同一个用户.所以要非常准确识别出每个用户是很困难的,用户识别结果直接影响整个预处理结果.
1.3 会话识别
可以把用户在一次访问某网站期间从进入该网站到离开该网站所进行的一系列活动称为一个会话.在跨度时间较大的web服务器中,用户可能多次访问了该网站,会话识别的目的是将同一个用户的多次请求划分成一个个独立的会话,每个会话代表一次访问过程.
web会话识别方法有很多,如基于时间阈值方法、最大向前序列方法、参引长度方法、Fuzzy c-means聚类算法等,根据文献[1]基于时间阈值识别会话是最常用的.文献[2]中基于会话持续时间的方法,被许多商业产品用30 min作为默认阈值来使用.文献[3]等文献又提出了从10 min到2 h不等的更多阈值.文献[4]通过动态计算页面停留时间来调整会话阈值.文献[5]提出了时间阈值与共享模式相结合来识别会话,首先使用基于时间阈值方法来识别会话,然后对识别后的会话采用共享模式进行二次过滤识别.文献[6]认为会话阈值与参引长度有关,通过计算参引长度来确定会话时间阈值.
基于时间阈值的会话识别方法,主要研究集中在如何确定会话阈值.对于固定阈值方法,阈值一旦确定就不会改变,显然没有考虑具体用户和网站对会话的影响.最合理的时间阈值的选取显然要依赖具体的用户和网站.
2 改进的基于动态阈值会话识别方法
2.1 基本思想
每个用户存在个体差异,如用户计算机性能、网络位置、网络连接速度、阅读速度、上网习惯,以及使用计算机的熟练程度等一系列因素.不同的用户会话时间通常也是不相同的.例如,相同页面不同用户的浏览速度和兴趣也不一定相同.但是,对于同一个用户,其所属的网络环境、个人兴趣、浏览速度等因素相对不同用户来说,是比较稳定的.所以除去用户个体差异对会话阈值的影响,会话阈值还受网站的结构、页面的信息量影响.即同一个用户浏览信息量大的页面所需要的时间也应更多.所以充分考虑了用户和页面信息量对会话阈值的影响,提出动态页面平均停留时间和页面信息量相结合的算法.与以往固定的阈值及文献[4]只考虑页面间停留时间的动态阈值方法(AST)相比,可以更好地根据用户和网页来识别会话,实验证明可以识别出更多的会话.
根据上面的思想,提出动态调整阈值方法,当有新请求被加入会话时,页面间停留时间相对较大时才会重新计算动态阈值.动态页面停留时间计算公式如下:dynamicAverageStayTime=a(dynamicAverageStayTime+a(较大时间间隔)/2,其中a为平滑系数,动态阈值计算公式如下:
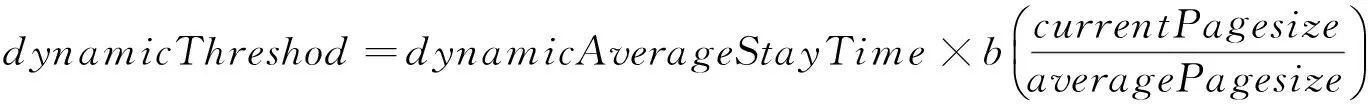
其中b为平滑系数,currentPagesize为当前请求页面大小,averagePagesize为用户会话平均页面大小.
2.2 算法描述
因为在前期清洗日志数据的同时已经把日志数据按照用户进行了排序,且相同用户默认按照访问时间递增排序,所以在会话识别算法(DPAST)中,前一个请求记录的用户名如果与后一个请求记录的用户名不同,则认为前一个请求记录是属于前一个会话且该会话结束,后一个请求记录是属于新的一个会话.对于相同用户名的两条连续请求记录,如果时间间隔小于动态阈值,表明他们属于同一个会话,重新计算会话平均页面大小(averagePagesize),如果同一个会话内前后两个请求记录的时间间隔相对较大则重新计算动态平均页面停留时间(dynamicAverageStayTime)和动态时间阈值(dynamicThreshold).该算话时间复杂度为O(n),其中n为web日志访问记录长度.流程图如图1所示.
DPAST伪代码如图2所示.

图2 DPAST伪代码
3 实验测试与分析
本节将给出优化后会话识别算法的实验结果,并与最常用的基于会话持续时间的算法(固定阈值为30 min)、基于页面停留时间的算法(固定阈值为10 min)和只考虑页面停留时间的动态调整阈值的算法(AST)进行分析比较.实验数据来源于美国航空航天局航天中心的Web服务器日志,该数据集是开源的,任何人都可以用于研究和学习,数据的真实可靠性已经被许多研究人员认可.该日志记录了1995年7月整整一个月的访问请求.由于数据量巨大,人工识别会话非常耗时,所以只选取一天数据进行分析,根据对整个7月日志的分析,12日前后访问请求数量波动不大,所以本实验只选取1995年7月12日这一天数据来测试本算法.经统计该天一共有92 536条访问请求,经过数据清洗后的日志数量为22 681(裁剪了大量不相干数据),对于清洗排序后的数据进行人工会话识别,7月12日这一天内产生的真实会话有6 270个.
分别用上面三种算法进行会话识别结果如表1所示,表1中A代表真实会话个数(A=6 270),T表示发现会话个数,R表示发现的真实会话个数.DPAST算法中initSessionTime为16 min,largerintervalTime为10 min,平滑系数a,b都为1.
从表1可以看出,作者提出的动态阈值算法(DPAST)无论是从精确度还是查全度来讲,都优于基于固定先验阈值和只考虑页面停留时间的动态调整阈值的会话识别算法.
4 结束语
通过对最常用的固定先验阈值算法进行改进,使会话阈值能够根据用户和网页动态调整,实验证明能更好地识别会话.

表1 三种会话识别算法识别结果
对于页面对会话阈值的影响,现在该算法还只考虑了页面的大小,今后会找一些信息量更多的日志,对页面进行量化,综合考虑网站结构、网页性质(内容页面还是辅助页面)、网页大小、超链接能因素对页面进行量化,得出每个页面的量化值,将量化值带入该算法进行会话识别.
[1] Pabarskaite Z,Raudys A.A process of knowledge discovery from web log data:Systematization and critical review [J].Journal of Intelligent Information Systems,2007,28(1):79-104.
[2] 蔡浩,贾宇波,黄成伟,等.Web日志挖掘中的会话识别算法 [J].计算机工程与设计,2009,30(6):1321-1323.
Cai H,Jia Y B,Huang C W,et al.In Web log mining session identification algorithm [J].Computer Engineering and Design,2009,30(6):1321-1323.
[3] Liu H,Kešelj V.Combined mining of Web server logs and web contents for classifying user navigation patterns and predicting users′ future requests [J].Data & Knowledge Engineering,2007,61(2):304-330.
[4] Spiliopoulou M,Mobasher B,Berendt B,et al.A Framework for the Evaluation of Session Reconstruction Heuristics in Web-Usage Analysis [J].Informs Journal on Computing,2003,15(2):171-190.
[5] Montgomery A L,Faloutsos C.IdentifyingWeb Browsing Trends and Patterns [J].Computer,2001,34(7):94-95.
[6] Guerbas A,Addam O,Zaarour O,et al.Effective web log mining and online navigational pattern prediction [J].Knowledge-Based Systems,2013,49:50-62.
[7] Kapusta J,Munk M,Svec P,et al.Determining the Time Window Threshold to Identify User Sessions of Stakeholders of a Commercial Bank Portal [J].Procedia Computer Science,2014,29:1779-1790.
[8] 陈子军,王鑫昱,李伟.一种Web日志会话识别的优化方法 [J].计算机工程,2007,33(1):95-97.
Chen Z J,Wang X Y,Li W.The optimization of a Web log session identification method [J].Computer Engineering,2007,33(1):95-95.
[9] 方元康,胡学钢,夏启寿.Web日志预处理中优化的会话识别方法 [J].计算机工程,2009,35(7):49-51.
Fang Y K,Hu X G,Xia Q S.Web log pretreatment session identification method of optimization in [J].Computer Engineering,2009,35(7):49-51.
[10] 周爱武,程博,李孙长,等.Web日志挖掘中的会话识别方法 [J].计算机工程与设计,2010,31(5):936-938.
Zhou A W,Chen B,Li S C,et al.In Web log mining session identification method [J].Computer Engineering and Design,2010,31(5):936-938.
(责任编辑:包震宇,冯珍珍)
Method of session identification in web log mining
YUAN Yi, CHEN Haiguang
(College of Information,Mechanical and Electrical Engineering,Shanghai Normal University,Shanghai 200234,China)
In this paper,by analyzing and comparing of the traditional web method of session identification,with the improvement on the most commonly used method of session identification based on time threshold,this paper proposed a session identification method based on dynamic threshold,in which the algorithm uses the average time interval between request records in conversation of dynamic calculation,and in combination of the average size of dynamic calculation session pages dynamically adjusts the threshold according to the characteristics of users and Webpage.Compared with the traditional single a priori threshold,this method can generate dynamic threshold according to different user access to different pages and make full use of user information and Webpage.After experimental verification,this method can identify more user sessions.The accuracy of session identification and the recall rate are higher than the traditional algorithm.
web mining; session identification; threshold; data preprocessing
2015-08-24
陈海光,中国上海市徐汇区桂林路100号,上海师范大学信息与机电工程学院,邮编:200234,E-mail:19276368@qq.com
TP 393
A
1000-5137(2016)05-0593-06
10.3969/J.ISSN.1000-5137.2016.05.013
猜你喜欢
华人时刊(2021年13期)2021-11-27 09:19:02
心声歌刊(2020年4期)2020-09-07 06:37:14
电子制作(2018年10期)2018-08-04 03:24:38
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
电子制作(2017年2期)2017-05-17 03:54:56
疯狂英语(双语世界)(2017年4期)2017-04-28 09:10:37
海外华文教育(2016年3期)2017-01-20 08:22:18
电子测试(2015年18期)2016-01-14 01:22:58
计算机与网络(2014年7期)2014-03-25 10:57:07
电子设计工程(2014年19期)2014-02-27 12:00:42
