
面向食品安全监理话题检测方法的研究
2016-12-14 08:36:06冯振海刘宏志
食品科学技术学报 2016年5期
冯振海, 刘宏志
(北京工商大学 计算机与信息工程学院, 北京 100048)

面向食品安全监理话题检测方法的研究
冯振海, 刘宏志
(北京工商大学 计算机与信息工程学院, 北京 100048)
食品安全问题一直是国民热切关注的话题,关系到社会的多个领域。为及时知晓食品安全领域关注的热点问题,对比了食品安全热点话题与其他热点话题在检测方法上的异同,构建了食品安全监理话题检测模型,运用聚类算法对食品安全数据进行文本挖掘来实现话题检测,并对食品安全数据进行分析。通过实验说明,采用Single-Pass算法的评价优于K-Means算法的评价,能够有效地对食品安全话题进行检测。
食品安全监理; 文本挖掘; 话题检测
食品是人类生存和发展的必需物质,食品安全是重大的社会问题,涉及国民的身体健康和生命安全,关系到社会的稳定和发展。近年来,食品安全问题时有发生,每次都成为社会舆论关注的焦点,影响着民众对我国食品安全监管的信任[1-2]。为了掌握民众对食品安全的社会舆情,可以借鉴信息工程监理的机制来实现对食品安全的监督和管理。“监理”和“监管”都有监督管理的意思,但它们有所不同。第一,依据不同。前者侧重于技术规范、标准,具有自主性,有利于大众对食品安全的监督;而后者侧重法律法规、行政,具有强制性。第二,性质不同。“监理”属于企业行为,“监管”属于政府行为。通过构建食品安全监理话题检测模型,再利用K-Means算法和Single-Pass算法对食品文本数据进行聚类,从而识别出一个个重要话题。这对监管部门快速掌握社会大众舆情有很大的帮助,相关部门根据实际情况可及时采取措施降低负面影响,力争把食品安全问题降到最低。
1 食品安全监理话题检测机制及数据收集
为能够多方面对食品安全进行监督和管理,需要完善并丰富相应的监管机制。现阶段国内已经建立了食品安全监理体系[3],物联网[4]和云计算[5-6]在食品安全监理方面得到了很好的应用,从食品供应链角度构建预测模型[7],并进行了深入的研究,有较好的理论基础。Peng和Wu等[8-9]采用多种话题检测方法,对话题进行了追踪和排名;另外,还有部分学者针对特定领域进行话题的检测[10-11]。在国外还有学者提出建立食品安全模型库[12]的策略来提高食品安全的监管效率。总的来说,国内外大多数学者研究点集中在用户兴趣和用户传播影响力对话题检测的影响。在舆论导向上,郭林宇等[13]探讨了食品质量的网络舆情特点。本研究拟利用文本聚类算法[14],通过语义分析食品安全的隐含知识来进行话题检测[15-16],从而实现食品安全话题的检测。
1.1 食品安全数据的采集
食品安全数据的采集主要是对网页的采集,即把从微博、论坛、贴吧等原始网页或文本下载到本地计算机存储设备上,作为处理的数据源。
采集器是从食品安全数据种子网页开始,然后使用这些网页中的链接再去获取其他页面。从已获取到的网页再一次获取链接地址,然后根据地址去定位相应的页面并访问。重复这一过程,直到满足结束条件为止。
1.2 面向食品安全数据的获取
主题采集器是针对某一领域里的采集器,它和一般通用采集器最大的区别就是抓取的内容只针对这一领域,在制定规则时只考虑特定领域就可以。一个采集器的采集流程如图1。
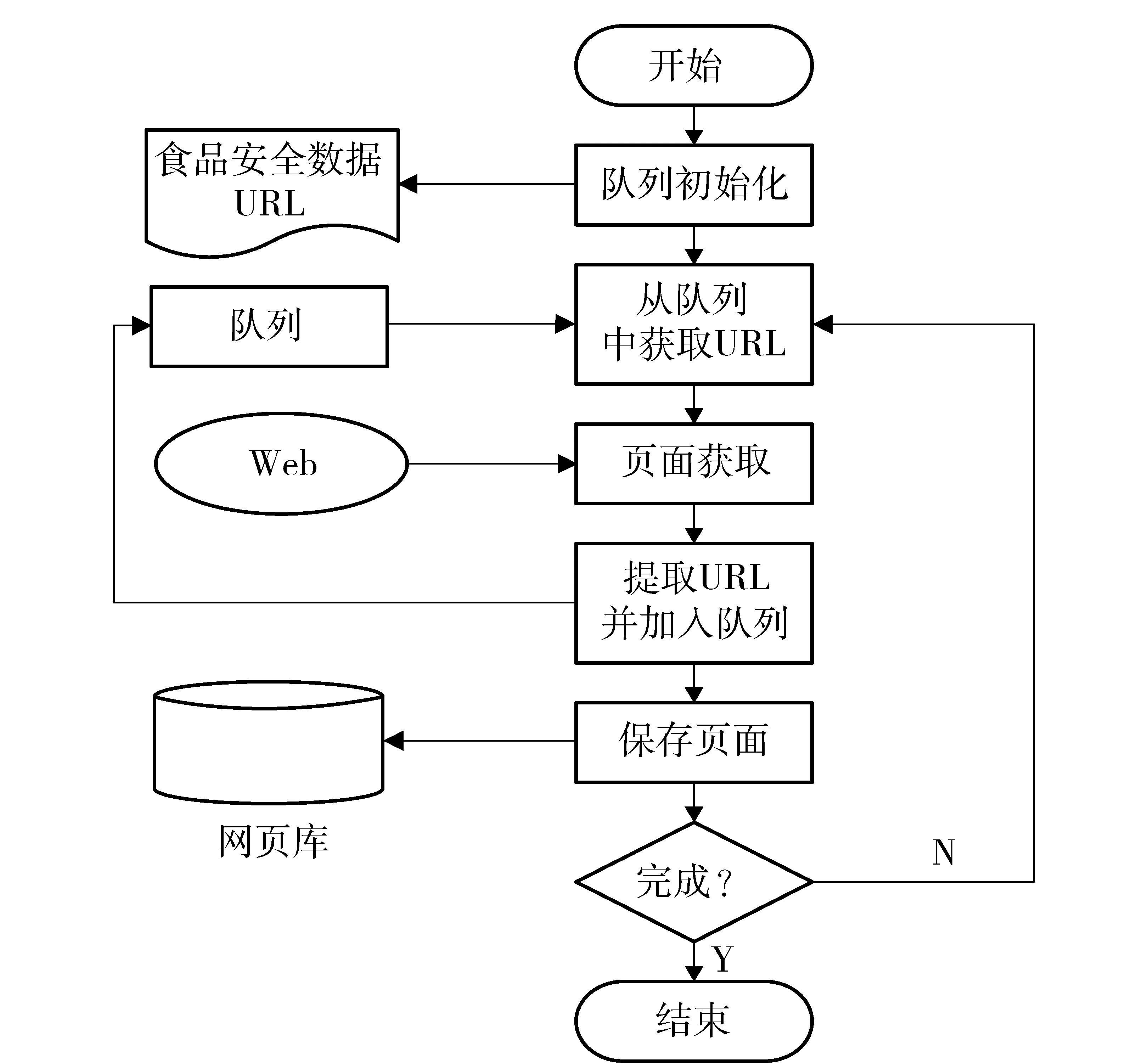
图1 采集器采集流程Fig.1 Processes of crawling for food safety data
设有一目标主题集合为T={t1,t2…tn},ti表示一个主题文档,与之对应的有相应的主题采集器。一组关键词K={k1,k2…kn},表示一个主题资源的关键特征,在用一系列样本集w来描述一个主题,其中w={
由于这些资源都是与某个主题相关的,它们必然存在共同的特征C={c1,c2…cn},ci表示提取出的共同特征,根据公共特征可以检查网页内容是否符合判定规则[17]。
实验数据采用该方法搜集,为了增加数据源的权威性,数据来源不仅包含互联网的数据,更主要是国家食品药品监督管理局定期发布的关于食品安全表格、文本、图文等不同类型的数据。这些食品安全数据表现为个体之间层次关系,并且呈现多维数据特征[18]。对数据进行整理分析后就可以对数据预处理,使数据满足模型的要求。
1.3 食品安全数据预处理
采集好数据后,有些数据通常不是实验所需要的理想数据,需要对其进行一些处理,主要包括数据清理、数据集成、数据变换和数据规约等操作[19-20]。
2 食品安全监理话题检测模型
话题检测模型采用向量空间模型,是使用最广泛的模型之一。该模型是将文档表示为词向量,是在文档集上进行搜索的一个框架,核心思想是文档与查询都是高维空间中的一个向量[21]。作为话题检测的重点之一,向量空间模型的基本思路和构建过程,可概括为5个方面。
2.1 文档向量
在向量空间模型中,首先要计算文档的词频率(TF)或者是计算逆向文档频率表(TF-IDF),然后得到一个数值的向量,该向量表示文档。该模型是将非结构化的文本内容转化为结构化的多维空间向量,这样做可以使得计算机能够识别并进行计算。
设N是准备实验的文本文档的总数,dfi为其中含有至少一次词ti的文档数目,fij为词ti出现在文档dj中的次数。那么dj中的ti的正规范化词频(定义为tfij)如式(1):

(1)
在式(1)中,分母取fij中最大的那个值,tfij=0代表ti在dj中没有出现。|V|为文档数据集的词汇表的大小。
词ti的逆向文档频率(idfi)的计算公式如式(2):

(2)
从式(2)中我们可以看出,如果很多文档中都含有文档集中的这个词,那么它的重要程度很低或者说是不重要,也可以说没有区别度。词逆向文档频率权值计算如式(3):
wij=tfij×idfi。
(3)
一个非停用词对于文档集合上的搜索而言,具有两个基本性质:
1)对于一个文档,该词出现的次数越多,则该词越重要;
2)对于多个文档构成的文档集,包含该词的文档数越少,则该词越重要。
2.2 话题相似度计算
在文本挖掘过程中,一般要进行文档与主题、文档与文档相似度计算,实现文本聚类。
常用方法之一是通过计算2个向量内积空间夹角的余弦值来度量2个文本的相似性,可以应用在任何维度的向量中,其计算公式如式(4)。

(4)
式(4)中,Wij是词频- 逆向文档频率(TF-IDF),q是查询。余弦相似度用于用户对内容的评分,用来区分兴趣的相似度和差异。
2.3 食品安全话题检测的步骤
话题检测的过程是从众多的观点中抽取所需的话题,然后根据检测指标和检测条件判断所抽取的话题是否是想要的话题内容。检测流程如图2。
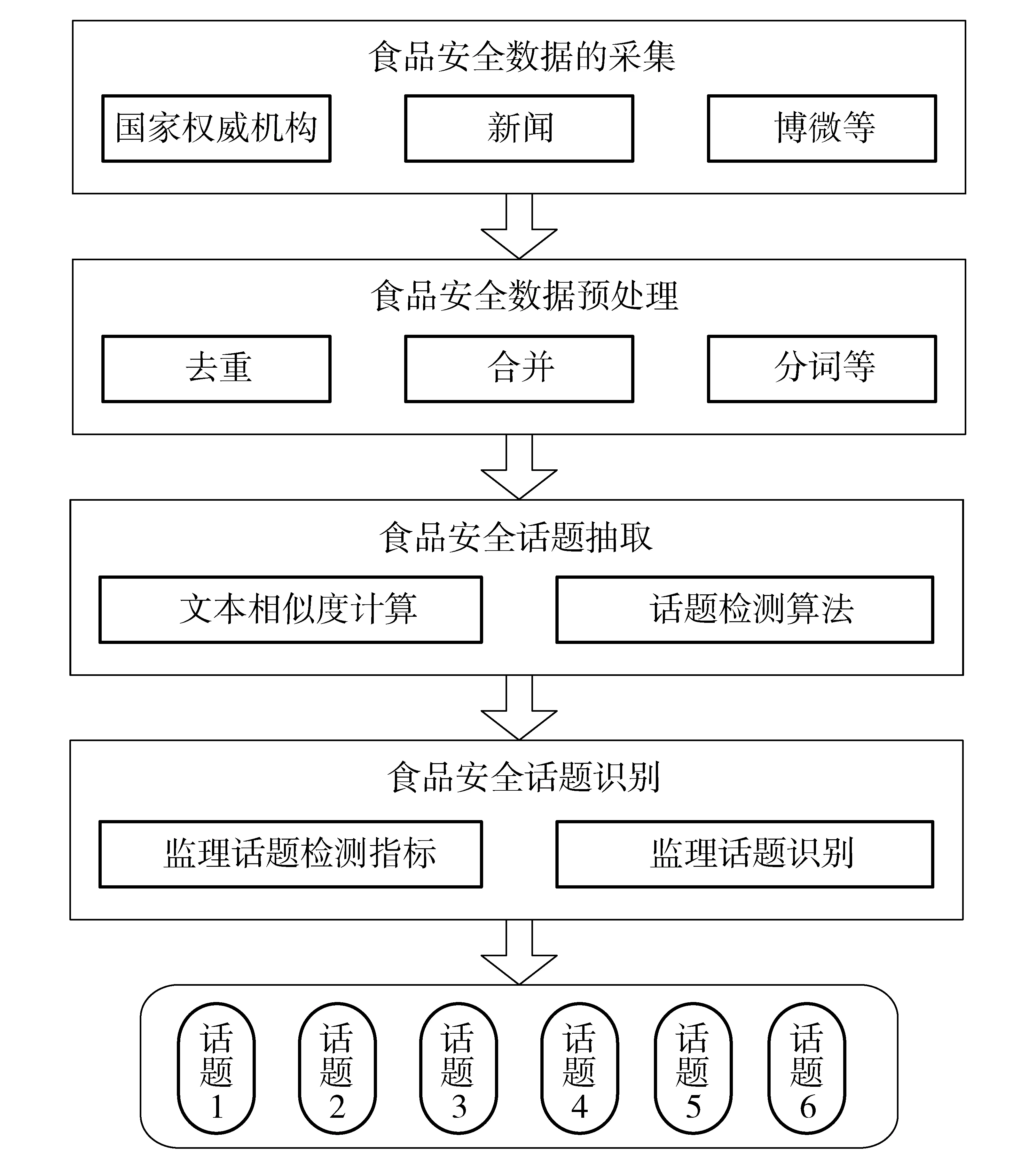
图2 话题检测流程Fig.2 Processes of topic detection
步骤1:数据准备阶段。采集官方发布的食品安全数据、各大网站食品安全的正文;把采集好的数据放入相应的数据存储介质中。
步骤2:数据预处理。主要包括对采集文本数据进行去重、合并、变换、规约等操作;如果是文本数据,还要对其进行分词操作。
步骤3:话题的抽取。首先要计算食品安全相关文本相似度,然后利用Single-Pass算法抽取相应的话题。
步骤4:热点话题识别。根据话题的检测指标,判断抽取出来的话题是否为热点话题。
2.4 食品安全话题检测与其他话题检测的区别
食品安全话题检测与互联网热点话题检测方法上有区别也有关联,整体过程大致都是收集语料库、分词操作、词频统计、特征词权重的计算以及采用不同的算法对语料库做聚类。但在实现过程中,还有许多不同于互联网话题检测的地方。
2.4.1 语料库的内容选取
食品安全话题检测所需语料库是针对食品安全数据相关的语料,该领域的语料库内容专一,数据特征鲜明。而互联网话题检测面对的是所有众多的海量数据,数据的内容广泛,结构多元复杂,数据量惊人,难以整理和处理。
2.4.2 热点词权值的计算
热点词语通常是在论坛或者网页中多次出现的词语,在同一个论坛中,会在多个文档中出现,这样的词语权重值就大。在食品安全语料库中,我们选取出现频率高的词语作为热点词,这些词语的权重值与互联网的热点词的权重是不同的,也体现了不同语料库相似度不同。
2.5 聚类算法的评价
对语料库数据处理后,使用聚类算法对话题进行识别和抽取,并对算法结果进行评价。
2.5.1 常用的评价标准
常用的评价标准包括准确率P、召回率R、模型综合指标F1-measure。
准确率P:反映检出的文档中有多高相关度,见式(5)。

(5)
式(5)中,a为相关文档数,b为不相关文档数。
召回率R:反映检出的相关文档数量,见式(6)。
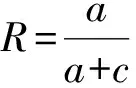
(6)
式(6)中,c为未被检出的相关文档数。
模型综合指标,见式(7)。

(7)
召回率与准确率在理论上是不相关的,但是在实际应用中,准确率高了相应的召回率就低了。同样的道理,准确率低了对应召回率就高了。在具体应用中,到底哪个评估标准更为重要取决于计算结果的特性,为了平衡两者的大小,可用模型综合指标F1-measure计算。
2.5.2 替代性指标P-R曲线
P-R曲线作为一种评价指标,可以很直观地描述出评价结果,并且可以随着某一变量的变化而变化。在实际中,召回率与准确率成负相关关系,即随着召回率的升高准确率就降低,反之,随着召回率降低准确率就升高。所以,召回率与准确率曲线更能清晰地描述评价结果。
3 食品安全话题检测算法及分析
本实验的话题检测运用K-Means算法和Single-Pass算法来实现对文本的聚类。K-Means算法是基于原型的算法,它必须先定义聚类中心,按照算法的迭代执行,其算法复杂度为O(nkt),其中n为文档数量,k为聚类的个数,t为要迭代的次数。Single-Pass算法是按照一定的次序,把第一个文档当作聚类依据,按照顺序比较相似度,如果相似度达到阈值要求,将其归入同类;否则,将选取新的聚类依据再进行上述操作,其算法复杂度为O(nk),其中n为文档数量,k为聚类的个数,其内存资源消耗小于K-Means算法的内存资源消耗。
实验所用到的食品安全数据来自国家食品药品监督管理局公布的食品安全数据以及各大网站的食品安全新闻数据,经过抓取最终获得4144条食品安全数据。对这些数据进行整理,从中检测出排名前5的话题。
采用K-Means算法聚类实验结果见表1。
采用Single-Pass算法聚类实验结果见表2。
通过比较发现,采用Single-Pass算法在漏检率和误检率方面都比K-Means算法效果更好。

表1 K-Means算法聚类实验结果
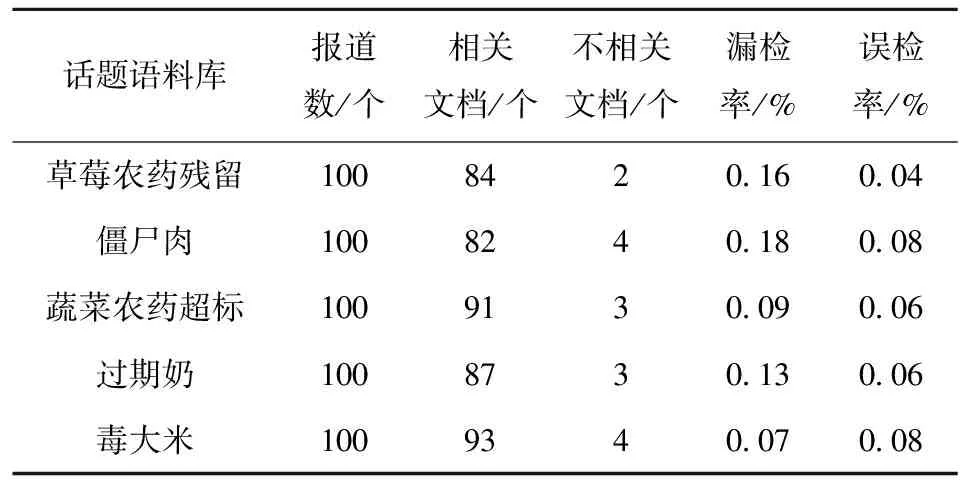
表2 Single-Pass算法聚类实验结果
然后,再采用查全率和查准率曲线来检测效果,如图3。

图3 两种算法对应的评价P-R曲线Fig.3 Comparison of two algorithms evaluations for P-R curve
图3是两种算法的P-R曲线,正方形线代表Single-Pass算法的P-R曲线,三角形线代表K-Means算法的P-R曲线,该曲线动态地反映了不同阶段准确率和召回率的表现,当召回率(recall)固定时,正方形线对应的准确率(precision)数值大于三角形线的数值。总的来说,Single-Pass算法的评价好于K-Means算法的评价。由此可见,对于食品安全的文本聚类,采用Single-Pass算法更利于该实验进行。
4 结 论
研究针对食品安全话题的发现过程和聚类算法进行了研究。通过对国内外的话题检测方法进行详细分析后,针对食品安全话题的特征构建模型,并使用数据挖掘方法解决话题检测问题。通过实验发现,采用Single-Pass算法在漏检率、误检率、准确率、召回率方面好于K-Means算法,提高了文本聚类的精度。采用该方法对食品安全话题检测具有一定的参考价值,便于对食品安全进行监督和管理,有利于降低食品安全问题发生的概率。
[1] 孙宝国, 王静, 孙金沅. 中国食品安全问题与思考[J]. 中国食品学报, 2013, 13(5):1-5. SUN Baoguo,WANG Jing,SUN Jinyuan.Perspectives on China food safety problems[J].Journal of Chinese Institute of Food Science and Technology, 2013, 13(5):1-5.
[2] 孙宝国, 周应恒, 温思美,等. 我国食品安全的监管与治理政策研究:第93期“双清论坛”学术综述[J]. 中国科学基金, 2013(5):265-270. SUN Baoguo, ZHOU Yingheng, WEN Simei,et al. Research of China’s food safety supervision and governing policy: summary of the 93th shuangqing forum of NSFC[J]. Science Foundation in China,2013(5):265-270.
[3] 张云霄, 刘宏志. 我国食品安全监理体系研究[J].食品科学技术学报,2014,32(1):77-82. ZHANG Yunxiao,LIU Hongzhi.Study on food safety surveillance system in China[J]. Journal of Food Science and Technology,2014,32(1):77-82.
[4] 邓小云, 刘宏志. 基于云计算的食品安全监理研究[J].北京工商大学学报(自然科学版),2012,30(4):75-78. DENG Xiaoyun,LIU Hongzhi.Study on food safety surveillance based on cloud computing[J]. Journal of Beijing Technology and Business University (Natural Science Edition),2012,30(4):75-78.
[5] 李梦寻, 刘宏志. 基于物联网的食品安全监理模型研究[J].北京工商大学学报(自然科学版),2011,29(2):54-58. LI Mengxun,LIU Hongzhi.Study on food safety surveillance model based on internet of things[J]. Journal of Beijing Technology and Business University (Natural Science Edition),2011,29(2):54-58.
[6] LIU Hongzhi,XIONG Jieqiong.Research on the city emergency logistics scheduling decision based on cloud theory based genetic algorithm[J].Communications in Computer and Information Science,2011,417:182-185.
[7] 韩福霞,刘宏志. 基于云服务的食品安全监理实时化研究[J]. 食品科学技术学报,2015,33(3):74-78. HAN Fuxia, LIU Hongzhi. Study on real-time analysis in food safety surveillance based on cloud service[J].Journal of Food Science and Technology,2015, 33(3):74-78.
[8] PENG Feifei,QIAO Xu,LI Gaoren. A research of hot topic detection through microblogging[C]∥2012 4th International Conference on Intelligent Human-Machine System and Cybernetics. Nanchang, China: IEEE, 2012:185-188.
[9] WU X M,IDE I,SATON S. New topic tracking and re-ranking with query expansion based on near-duplicate detection[M]. Heidelberg: Springer, 2009:755-766.
[10] 李劲,张华,吴浩雄,等. 基于特定领域的中文微博热点话题挖掘系统BTopicMiner[J]. 计算机应用,2012(8):2346-2349. LI Jin ,ZHANG Hua ,WU Haoxiong ,et al.BTopicMiner: domain-specific topic mining system for Chinese microblog[J]. Journal of Computer Applications, 2012(8):2346-2349.
[11] ZHU Mingliang,HU Weiming,WU Ou. Topic detection for discussion threads with domain knowledge [C]∥Proc of International Conference on Web Intelligence and Inteligent Agent Technology. New York:ACM Press,2010:545-548.
[12] PLAZA-RODRIGUEZ C, THOENS C, FALENSKI A, et al. A strategy to establish food safety model repositories[J].International Journal of Food Microbiology, 2015,204:81-90.
[13] 郭林宇, 戚亚梅, 李艳,等. 农产品质量安全网络舆情监控体制机制研究[J]. 食品科学, 2013, 34(3):312-316. GUO Linyu,QI Yamei,LI Yan,et al.Monitoring of internet public opinion toward agricultural products quality and safety[J].Food Science, 2013, 34(3):312-316.
[14] WANG Chunhong, NAN Lili, REN Yaopeng. Research on the text clustering algorithm based on latent semantic analysis and optimization[C]∥2011 IEEE International Conference on CSAE. Shanghai: IEEE, 2011,4:470-473.
[15] WANG Zhiming, HOU Xusheng. A topic detection method based on bicharacteristic vectors[C]. Wuhan: IEEE, 2009: 683-687.
[16] CATALDI M, BALLATORE A, TIDDI I, et al. Good location, terrible food: detecting feature sentiment in user-generated reviews[J]. Social Network Analysis & Mining, 2013, 3(4):1149-1163.
[17] ADAR E, TEEVAN J, DUMAIS S T, et al. The web changes everything: understanding the dynamics of web content[C]∥Proc 2nd ACM Int Conf on Web Search and Data Mining. Chicago ACM, 2009: 282-291.
[18] 陈为, 沈则潜, 陶煜波, 等. 数据可视化 [M]. 北京:电子工业出版社, 2013: 10-20. CHEN Wei,SHEN Zeqian,TAO Yubo,et al.Data visualization[M].Beijing: Publishing House of Electronics Industry,2013: 10-20.
[19] 聂飞霞,付敏. 数据预处理:数字图书馆的“清洗机”[J]. 图书馆界,2013(4):52-55. NIE Feixia,FU Min.Data preprocessing: digital library “washing machine”[J].Library World,2013(4):52-55.
[20] 孟巍. 数据仓库数据质量评价研究及其应用[D]. 天津: 河北工业大学,2004:48. MENG Wei.Evaluation and realization of data quality of data warehouse[D]. Tianjin: Hebei University of Technology,2004:48.
[21] 郝文宁, 穆新国, 陈刚,等. 基于军事训练本体的文档向量空间模型构建[J]. 计算机应用, 2012, 32:10-12. HAO Wenning,MU Xinguo,CHEN Gang,et al.Document vector space model construction based on ontology in military training[J].Journal of Computer Applications, 2012, 32:10-12.
Research of Topic Detection Method for Food Safety Surveillance
FENG Zhenhai, LIU Hongzhi*
(SchoolofComputerScienceandInformationEngineering,BeijingTechnologyandBusinessUniversity,Beijing100048,China)
Food safety problem has been a hot topic of national concern, which related to many areas of society. In order to know hot issues that relate to food safety in timely, food safety hot topics and other hot topics of the similarities and differences in detection methods were compared. The food safety surveillance topic detection model was constructed and the clustering algorithm was used for text mining for food safety data to achieve the topic detection. Through the experimental results, the evaluation of the Single-Pass algorithm was better than the K-Means algorithm, which could effectively detect food safety topics.
food safety surveillance; text mining; topic detection
檀彩莲)
10.3969/j.issn.2095-6002.2016.05.013
2095-6002(2016)05-0089-06
冯振海,刘宏志. 面向食品安全监理话题检测方法的研究[J]. 食品科学技术学报,2016,34(5):89-94. FENG Zhenhai,LIU Hongzhi. Research of topic detection method for food safety surveillance[J]. Journal of Food Science and Technology, 2016,34(5):89-94.
2015-07-13
北京市属高等学校科学技术与研究生教育创新工程建设项目(PXM2012_014213_000037)。
冯振海,男,硕士研究生,研究方向为信息工程与食品安全监理;
*刘宏志,男,教授,博士,主要从事信息工程监理、电子商务与电子政务等方面的研究。
。
TS201.6; R155; TP18
A
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
消费导刊(2017年24期)2018-01-31 01:28:30
中国工程咨询(2017年10期)2017-01-31 02:43:52
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
电脑迷(2012年4期)2012-04-29 06:12:13
