
F-Seeker:基于重匿名的粒度化好友搜索架构
2016-12-08 05:45周志刚张宏莉余翔湛
电子学报 2016年10期
周志刚,张宏莉,叶 麟,余翔湛
(哈尔滨工业大学计算机科学与技术学院,黑龙江哈尔滨 150001)
F-Seeker:基于重匿名的粒度化好友搜索架构
周志刚,张宏莉,叶 麟,余翔湛
(哈尔滨工业大学计算机科学与技术学院,黑龙江哈尔滨 150001)
针对社交网络中好友检索服务的隐私保护问题,本文提出一种基于重匿名技术的粒度化好友搜索架构F-Seeker.对用户发布的位置信息采用增强的k匿名策略—(k,m,e)-匿名,用以防止“好奇”的搜索服务提供方对用户隐私的推测.在处理好友搜索服务过程中,由服务提供方根据粒度化的可视策略对数据实施重匿名,实现了对用户位置信息粒度化的访问控制.此外,文中对发布数据采用Z序编码并在搜索过程中通过运用剪枝策略提高搜索效率.实验结果表明,文中提出的匿名策略在保护用户隐私的同时并没有大幅度地增加计算开销.
重匿名;粒度化检索;基于位置的服务;泰森多边形;Z序空间填充曲线
1 引言
隐私保护的“好友”搜索是社交网络领域研究的热点问题.它可以看成是数据隐私保护、海量数据检索以及基于地理位置的服务(Location Based Service,LBS)三种技术的有机融合;即在不泄露用户隐私的前提下,由服务提供商从海量的数据中搜索符合条件的目标用户的位置信息.近年来随着智能手机的普及,基于地理位置的社交网络应用服务层出不穷(如Gowalla、Brightkit、陌陌等).“好友”搜索服务为生活在都市快节奏的人群构建了一座无形的沟通桥梁,拉近了人与人之间的距离,因此一经推出就自然吸引了大量用户.然而在用户享受这些社交服务所带来便捷的同时,其对隐私信息泄露风险的顾虑已经成为阻碍这类应用服务发展的首要问题.其次,在如何实现对用户上传的社交数据实施粒度化的访问控制以及高效的海量数据检索方面也面临极大挑战.
针对社交网络好友搜索应用中所存在的隐私保护及海量多维数据搜索问题,本文提出一个基于重匿名策略的粒度化好友搜索架构.在用户将位置信息上传至社交网络服务器前,首先由位置匿名服务器使用(k,m,e)-匿名算法对其进行匿名化操作,并将匿名后的数据发给LBS服务器.LBS端使用Z序编码技术对高维用户信息进行编码,在处理好友搜索服务过程中,采用基于Z序编码的剪枝策略对候选集进行筛选,从而极大地提高搜索效率.同时为实现粒度化的访问控制,LBS服务器根据粒度化的可视策略对数据实施重匿名.
2 相关工作
针对社交数据的隐私保护问题,相关研究人员提出了许多用户位置隐私保护方案.根据匿名原理的不同,这些方案大体可分为两类:基于位置模糊化的匿名策略[1~3]和基于k-匿名的空间位置匿名策略[4~8].基于位置模糊化的匿名模型是通过发布虚假位置信息或位置坐标区域化等策略对用户位置隐私实施保护.文献[1,2]提出基于“插入假人”的位置隐私保护策略,即用户在提交自身真实位置信息的同时,还发送若干伪造的虚假位置给LBS服务器,使得攻击者无法辨别出用户的真实位置.但由于用户的精确位置会混在虚假的信息中,所以该策略依然会造成一定的安全隐患.文献[3]提出位置相似度的概念:将服务区域细化为网格,位置服务器根据每个网格的兴趣点查询结果的相似度,计算出服务区域的相似地图,并传递给移动设备;用户再依据相似地图构造出一个服务轮廓,用于替代自身位置向LBS服务器请求服务,从而实现位置保护.Gruteser M等人[4]首次将k-匿名方法应用到用户位置隐私保护中.该策略为每个用户构造一个匿名化的空间区域(Anonymous Spatial Region,ASR),其中ASR内至少含有k个不可区分的用户(含目标用户),使得攻击者无法以高于1/k的概率识别出目标用户.Gedik B等人[5]提出了一种带有区域约束的匿名策略,该策略增加了一个最小匿名区域Amin的隐私保护约束,从而防止因这k个用户的匿名区域过小而造成的位置泄露问题.然而由这类策略生成的匿名区域可能落在某个敏感位置(Point Of Interest,POI)附近,攻击者能够据此推测出目标用户身份、职业、健康状况等隐私信息.一个自然的解决思路是在满足k-匿名的基础上实现对ASR位置多样化的需求[6],即在生成的ASR中至少包含m个POIs,同时为了防止匿名退化攻击*匿名退化攻击:攻击者可以根据用户在POIs间分布的不均衡性,在概率上缩小ASR的范围,使得能以高于1/k的概率推测出目标用户的精确位置.,要保证ASR中用户在各个POIs间分布的均衡性;从服务效用看,用户希望构造的ASR是最小的.然而,构造符合以上需求的ASR是一个NP-complete问题.
在海量数据的高效检索方面,目前大多数研究集中在通过构造高效的索引结构检索数据,如基于R-tree[9]的索引(RUM-tree[10],TPR-tree[11]),基于B+-tree的索引(Bx-tree[12]),基于quad-tree的索引(STRIPES[13]),然而这些技术仅仅根据移动用户空间地理位置的邻近关系存储数据,难以满足现实的社交网络应用中用户对好友多维度立体式的搜索需求,且在海量多维数据下,这些技术在处理范围查询(如经典的最近邻查询)时,需要扫描待搜索区域内所有的实体,产生极大的计算及存储开销,无法适用于对实时性要求较高的社交网络应用场景.
3 系统设计架构
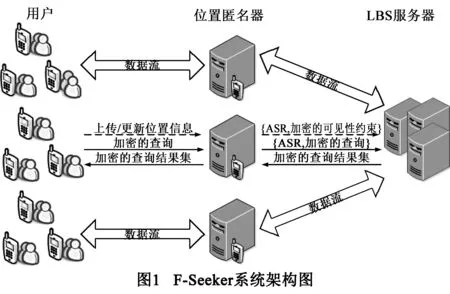
在现行的“用户-LBS服务器”二元社交网络模型中,所有用户的社交数据(如Check-In、兴趣、社交关系)都置于LBS服务器上,LBS服务器宛然成为与用户群构成星形拓扑中的核节点.一旦LBS服务器被外部攻击者入侵或内部员工恶意泄露其上数据,则用户个人隐私及其社交关系隐私都将泄露.为此,本文提出一种基于“用户-位置匿名器-LBS服务器”的三元社交网络架构如图1所示,其中,位置匿名器作为可信第三方被引入系统,采用(k,m,e)-匿名算法对用户的位置信息进行匿名,并将匿名后的区域ASR发送给LBS服务器.为防止位置匿名器成为第二个超级节点,这里位置匿名器仅用来处理用户的位置信息,而无法获知用户间的社交关系;同理,LBS服务器仅处理好友搜索业务逻辑而无法获知用户精确的位置信息.
4 位置匿名算法
k-匿名算法要求每一个实体所对应的记录在数据集中存在其它k-1条与其不可区分的记录,由于其符合人们对数据安全的共识,且易于实现,已经成为数据安全评价指标并广泛应用于和数据隐私保护相关的各个领域.针对移动用户的位置发布场景,位置匿名器通过构造一个ASR使得其中包含至少k个移动用户(含目标用户),从而保护用户的位置隐私.然而使用传统k匿名算法构造的ASR并没有对其中包含的POI的数量进行限制,当ASR中仅包含一个敏感POI(如肿瘤医院)时,用户的个人隐私将可能因此而被泄露.本文提出一个k-匿名的增强策略(k,m,e)-匿名并将其作为安全评价指标.(k,m,e)-匿名策略在k-匿名算法的基础上还限定了匿名区域中POI的数量以及用户在期间的分布.

位置匿名器对用户位置的匿名化处理包含两个阶段:(1)预处理阶段,位置匿名器离线地对其管理范围的POI集合进行划分;(2)匿名阶段,采用(k,m,e)-匿名策略生成ASR.
4.1 预处理阶段
在预处理阶段,根据Voronoi规则[14,15],位置匿名器使用其管理范围内所覆盖的POI集合对区域进行划分,使得
(1)每一个划分区域Voronoi cell(Vcell)中包含且仅包含一个POI.
(2)给定一个Vcelli及其覆盖的POI(Pi),则其上任意一点q到Pi的距离小于等于其到其它POI的距离,当且仅当q位于区域边界点时,等号成立.
基于Voronoi规则的区域划分建立了子区域与POI集合元素的一一映射关系,其目的在于当给定目标用户的位置信息能够快速检索到其邻近的POI,从而提高位置匿名的效率.图2展示了一个区域划分实例,其中四个POI(P1,P2,P3,P4)基于Voronoi规则分别被划分到V1,V2,V3,V4四个Vcells中.给定目标用户q位于Vcell(V1),能够得出P1为与之最近的POI.
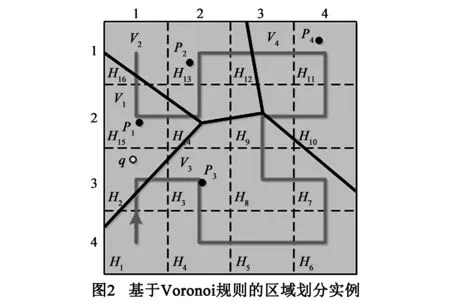
虽然基于Voronoi规则的区域划分能够精确地表述POI间及目标用户与POI间的近邻位置关系,然而仅使用Voronoi规则划分的区域存在以下几方面问题:(1)划分的子区域形状不规则,难以坐标化表示;(2)子区域的大小不均一,难以量化评估据此生成ASR中用户分布与POI分布的映射关系;(3)子区域的划分个数等于POI集合元素的个数,无法进一步对其进行加细划分,以致难以细粒度地构造ASR.为此,在以Voronoi规则对区域进行划分的基础上,本文使用Hilbert空间填充曲线[16,17]对空间区域进行迭代划分.给定待划分区域:(1)首先将划分为N×N个大小均一的格状子区域(Grid cell,Gcell),其中N∈2n(n=1,2,…);(2)使用Hilbert线序对本层的Gcells进行编号排序;(3)返回到步骤(1)对每一个Gcell迭代地进行加细划分.显然,使用Hilbert空间填充曲线划分的区域解决了上文提出的三方面问题,此外,Hilbert线序相近的区域其地理位置也具有近邻性.结合Voronoi规则及Hilbert空间填充曲线的对区域划分的优点,本文构造基于网格的B+-tree(grid-based B+-tree,gB+-tree)存储各个子区域Gcells中POI和用户的位置及分布信息.
定义2(gB+-tree) 给定待划分区域,并将其设定为gB+-tree的根节点(root),根据Hilbert空间填充曲线迭代地对其进行加细划分,其中每一个节点被划分为2n×2n(n=1,2,…)个Gcells,称最细层划分的Gcells为叶节点,其它节点为中间节点.对于每一个中间节点,使用二元组(|P|,|Q|)统计其覆盖区域中POI及用户的数量;对于叶节点,使用三元组(P,Q,H)记录其内POI及用户的信息,其中P记录其上的POI集合,Q记录其上用户集合,H是属性P的扩展属性,当P=∅时,H记录在Voronoi规则空间划分下该叶节点所属Vcells中POI所在的Gcell节点的Hilbert序ID;否则H记录在Voronoi规则空间划分下P属性值所对应Vcell覆盖的所有格状区域的Hilbert序ID.
例如,图3展示了针对图2区域实例的两层gB+-tree存储结构.所有的中间节点被划分为2×2子格区域,并使用Hilbert线序将其标记为H1~H16.其中root节点H1~16:(4,7)表示整个区域内包含4个POIs及7名移动用户,类似地,H1~4:(1,2) 表示子区域{H1,H2,H3,H4}内包含1个POIs及2名移动用户;叶节点H7:{∅,{q3,q4},{H3,H11}}表示区域H7内不含POI(P=∅),仅包含2名移动用户(Q={q3,q4}),且根据Voronoi规则对空间区域的划分,H7分属于Vcell{V3,V4},因此与其对应的POI(p3,p4)是距H7最近的POI集合,如图2所示,p3,p4分别位于H3,H11;H11:{{p4},{q5},{H7,H9,H10,H11,H12}}表示区域H11内覆盖POI(P={p4}),仅包含1名移动用户(Q={q5}),且根据Voronoi规则对空间区域的划分,p4属于Vcell(V4),且V4覆盖{H7,H9,H10,H11,H12}.

4.2 基于(k,m,e)-匿名的位置匿名策略
在现实的应用需求中,用户要求ASR在满足隐私需求(即ASR对隐私保护的安全度越高越好)的同时满足可用性(utility)需求(即ASR应该尽可能的小).一个自然的解决方案是设定一个隐私泄露的上限而求最小化的ASR.这里首先定义一个效用函数U(ASR)用于描述ASR所覆盖的区域面积,

(1)




U(ASR)≤A
(2)

subject toE(ASR)≥e,
U(ASR)≤A
(3)
其中,λ是权重参数,

然而对式(2)及式(3)的求解是NP-complete.本文提出一个基于贪心策略的启发式算法(算法1)近似地解决式(2)及式(3)中的优化问题.算法1的基本思想是迭代地扫描gB+-tree:
(1)逐层加细地定位目标用户所在的区域,直到其子节点覆盖的POI数量少于用户设定的阈值m.
(2)检测目标用户所在子区域内用户的数量及用户分布熵:(a)若用户的数量小于k,则根据Hilbert序对子区域进行扩张;(b)若用户分布熵小于e,则根据Voronoi规则对用户分布熵贡献最小的格状区域进行扩张.直到满足用户的隐私需求或打破可用性需求,算法终止.
算法1 基于贪心策略的ASR构造算法(GenASR)
输入:匿名参数k,m,e;
目标用户的精确位置qloc;
gB+-tree*b
GenASR(k,m,e,qloc,b)
1: for each entryiinbdo
2: if 2D to L(qloc)≤entryi.ID then
//2D to L() transforms 2D region to Hilbert ID
3: if entryi.|P|≥mthen
4: GenASR(k,m,e,qloc,entryi→child);
5: else
7:k=k-entryi.|Q|;
8:m=m-||;
9: ifm>0 then
10: GenASR(k,m,e,qloc,entryi→next);
11: ifk>0 then
12: GenASR(k,m,e,qloc,entryi→next);
15:foreachGiindo
16: ifGi.P=pxthen
inGi.HandGj∩=∅);
18: break;
// Procedure FindPOI
FindPOI(*b,p)
1:for each entryiinbdo
2: if entryi→child≠∅ then
3: FindPOI(entryi→child,p);
4: ifp≠0 then
6:p=p-|entryi.H|;
7: else
5 细粒度的好友搜索算法
5.1 基于Z序的数据编码
除了位置信息外,在社交网络系统中,用户会发布一些可公开的个人基本信息(如年龄、性别、爱好等)以便于“好友”对其的搜索.本文提出一种基于Z序的编码方案对用户社交数据进行编码.


性质1(聚簇性) 在Z序编码下,两条数据拥有的公共Z序编码越长,其数据各个属性的相似度也越高.
定义4(支配操作)[18]称一个点qi在M维空间上支配另一个点qj,当且仅当∀ar∈A,有qi.ar≤qj.ar,并且∃at∈A使得qi.at 性质2(单调性) 在基于Z序编码的M维空间上,若qi支配qj,则在Z序空间填充曲线上qi的位置先于qj. 5.2 查询剪枝策略 为了便于描述,文中以对2维社交网络数据集的最近邻(Nearest Neighborhood,NN)查询为例介绍剪枝策略. 根据Z序编码的性质1,Z序编码可以以组为单位迭代细分.每一条记录的Z序编码可以看作是「log2d⎤层(组)2-bit子编码构成的树形结构,其中第i(0 当接收到好友检索请求,LBS服务器首先对其进行Z序编码,并以此为目标点,搜索其在空间中的支配最近邻对象.为了减少候选记录的数量,本文提出以下逐层剪枝规则: (1)当目标点位于区域Ⅰ,则剪切同层的区域Ⅱ,Ⅲ,Ⅳ. (2)当目标点位于区域Ⅱ,则剪切同层的区域Ⅲ,Ⅳ. (3)当目标点位于区域Ⅲ,则剪切同层的区域Ⅱ,Ⅳ. (4)当目标点位于叶节点所在区域,则剪切由Z序曲线填充的该区域中位于目标点之后的对象. 5.3 基于粒度化可视约束的重匿名策略 为了对不同角色的搜索用户提供不同粒度的视图,用户在发布个人的社交网络数据前需向LBS服务器提交其对不同角色用户设定的数据访问控制条件,即粒度化可视约束. 定义5(粒度化可视约束) 给定目标用户q及其好友列表描述(Q,R,f,h),其中Q={q1,…,qn}表示用户q的好友列表,目标用户q将Q划分为l个角色R={r1,…,rl}(l≤n),(f,h)是一对对偶操作:f:Q→R表示由好友ID到角色的映射,h:R→Q表示由角色到其相应的好友ID的映射且∀ri,rj,h(ri)∩h(rj)=∅.用户q对角色ri的可视化约束可以表示为一个五元组Sq→ri=(sri,tri,mri,kri,eri),sri和tri分别表示对角色ri可搜索q的空间及时间约束,(mri,kri,eri)是设定角色ri对q定位的重匿名化约束且mri≥m,kri≥k,eri≥e((m,k,e)是对其位置信息设定的初次匿名参数). 这里,用户好友列表Q可以包含一个默认好友,与之对应的角色被设定为“游客”,即开辟一个与陌生人交互的接口. LBS服务器将用户的可视化约束内嵌到其相应的个人信息之中,并将(sri,tri)作为查询筛选条件,即当用户qi满足搜索用户q的查询请求时,LBS服务器检测qi对q设定的搜索时空约束,若满足,则使用匿名参数(mri,kri,eri)对ASRqi实施重匿名,并将结果返回用户.重匿名算法类似于算法1,由于篇幅有限,此处省略详细的算法描述. 实验配置为服务器采用Intel Xeon E3处理器,内存32GB.位置匿名器和LBS服务器分别采用3个基于Map-Reduce的计算节点分布式计算平台.本实验将从匿名算法性能以及好友搜索实时性方面进行实验验证. 6.1 匿名性能 本文使用仿真数据模拟现实社交网络中用户Check-In的位置信息,为模拟用户在空间区域内的均匀分布,数据产生器在1000×1000的空间区域内随机地生成用户的位置及POI的坐标,生成的数据库包含100K个用户位置及10K个POIs.实验中设置匿名请求提交窗口分别为100、300、500、700、900,其中位置匿名请求的提交用户是随机选择的,匿名参数为k=10,m=3,e=1.3(参数m和e仅适用于(k,m,e)-匿名算法).图5~7分别展示了在上述设置中,(k,m,e)-匿名算法在执行效率、隐私保护程度及匿名区域可用性三个方面与经典的k-匿名算法及离线最优算法的比较.图5说明,在同等条件下,随着请求数量的增加,本文提出的匿名算法执行时间呈线性增长,由于k-匿名算法没有考虑对参数m和e的限制,因此执行时间开销总是比本文所提匿名算法要小,然而正如图6中所展示的,(k,m,e)-匿名算法在隐私保护的程度上远高于同等条件下k-匿名算法对隐私的保护程度(这里使用用户在POI间的分布熵来描述ASR中用户位置隐私的保护程度,其中熵越高,说明用户在POI间的分布越均衡).图7展示了匿名区域可用性(即ASR的面积),为了便于比较,这里对实验结果进行归一化处理.结果表明,虽然从统计的角度文中所提算法所生成ASR总是大于k-匿名算法所产生的ASR,但两者的相差并不大,可以推知其依然满足现实社交网络中对位置可用性的需求. 6.2 搜索实时性 图8展示了基于Z序编码的执行效率,在上述实验环境下,用户数量设置为10K、20K、30K、40K、50K,其中,每一个用户包含5个属性且属性的取值范围[1,50].结果表明,对50K用户的一次Z序编码的压力测试大约需要10s,基本满足现实场景中对编码效率的需求. 图9展示了好友搜索执行效率,实验中设置搜索请求提交窗口分别为100、300、500、700、900,为了便于比较,我们引入了经典的位置存储结构(基于B+-tree的索引(Bx-tree[12]),基于quad-tree的索引(STRIPES[13]))作为参照,实验结果表明本文使用的基于Z序编码的搜索算法及剪枝策略在搜索效率方面明显优于经典的搜索算法且具有良好的实时性. 本文采用重匿名技术,在保证用户位置信息可用性的前提下实现对用户位置信息进行粒度化的隐私保护.与k-匿名相比,基于(k,m,e)-匿名技术的隐私保护策略防止攻击者通过用户分布对用户位置信息进行推理攻击,仅附加较低的性能惩罚.在好友搜索阶段,采用基于Z序的数据编码及相应的剪枝策略,大幅降低了对高维多值社交网络数据进行最近邻搜索时的时空开销. [1]Kido H,Yanagisawa Y,Satoh T.An anonymous communication technique using dummies for location-based services[A].Proceedings of International Conference on Pervasive Services (ICPS'05)[C].USA:IEEE Press,2005.88-97. [2]刘华玲,郑建国,孙辞海.基于贪心扰动的社交网络隐私保护研究[J].电子学报,2013,41(8):1586-1591. Liu Hua-ling,Zheng Jian-guo,Sun Ci-hai.Privacy preserving in social networks based on greedy perturbation[J].Acta Electronica Sinica,2013,41(8):1586-1591.(in Chinese) [3]Rinku Dewri.Exploiting service similarity for privacy in location based search queries[J].IEEE Transactions on Parallel and Distributed Systems,2013,25(2):374-383. [4]Gruteser M,Grunwal D.Anonymous usage of location-based services through spatial and temporal cloaking[A].Proceedings of the International Conference on Mobile Systems Applications and Services[C].USA:IEEE Press,2013.163-168. [5]Mokbel M F,Chow C Y,Aref W G.The new casper:Query processing for location services without compromising privacy[A].Proceedings of the International Conference on Very Large Data Bases[C].USA:VLDB Press,2006.763-774. [6]Bhuvan B,Ling L,et al.Supporting anonymous location queries in mobile environments with privacy grid[A].Proceedings of the 17th International Conference on World Wide Web[C].USA:ACM Press,2008.237-246. [7]王丽娜,彭瑞卿,等.个人移动数据收集中的多维轨迹匿名方法[J].电子学报,2013,41(8):1653-1659. Wang Li-na,Peng Rui-qing,et al.Multi-dimensional trajectory anonymity in collecting personal mobility data[J].Acta Electronica Sinica,2013,41(8):1653-1659.(in Chinese) [8]叶阿勇,林少聪,马建峰,许力.一种主动扩散式的位置隐私保护方法[J].电子学报,2014,43(7):1362-1368. Ye A-yong,Lin Shao-cong,Ma Jian-feng,Xu Li.An active diffusion based location privacy protection method[J].Acta Electronica Sinica,2014,43(7):1362-1368.(in Chinese) [9]Chen Q,Hu H,Xu J.Authenticating top-k queries in location-based services with confidentiality[A].Proceedings of the International Conference on Very Large Data Bases[C].USA:VLDB Press,2014.49-60. [10]Xiong X,Aref W G.R-trees with update memos[A].Proceedings of the 22nd International Conference on Data Engineering (ICDE'06)[C].USA:IEEE Press,2006.22. [11]Saltenis S,Jensen C S,Leutenegger S T,Lopez M A.Indexing the positions of continuously moving objects[A].Proceedings of ACM SIGMOD[C].USA:ACM Press,2000.331-342. [13]Patel J M,Chen Y,Chakka V P.Stripes:An efficient index for predicted trajectories[A].Proceedings of ACM SIGMOD[C].USA:ACM Press,2004.637-646. [14]Berg M de,Kreveld M van,Overmars M,Schwarzkopf O.Computational Geometry:Algorithms and Applications (2nd edition)[M].Berlin:Springer-Verlag,2000. [15]Hu L,Ku W-S,Bakiras S,Shahabi C.Spatial query integrity with voronoi neighbors[J].IEEE Transactions on Knowledge and Data Engineering,2013,25(4):863-876. [16]Kalins P,Ghinita G,Mouratidis K,Papadias D.Preventing location-based identity inference in anonymous spatial queries[J].IEEE Transactions on Knowledge and Data Engineering,2007,19(12):1719-1733. [17]Ghinita G,Kalnis P,Khoshgozaran A,Shahabi C,Tan K-L.Private queries in location based services:Anonymizers are not necessary[A].Proceedings of the ACM SIGMOD International Conference on Management of Data[C].New York:ACM,2008.121-132. [18]Lee K,Lee W,Zheng B,Li H,Tian Y.Z-sky:an efficient skyline query processing framework based on z-order[J].The VLDB Journal,2010,19(3):333-362. [19]William Feller.An Introduction to Probability Theory and Its Applications (Vol.1,3rd Edition)[M].USA:Wiley,1968. 周志刚 男,1986年2月出生,山西太原人,博士生,现就读于哈尔滨工业大学计算机系,主要研究方向为网络与信息安全、位置隐私保护、云安全等. E-mail:zzgisgod@sina.com 张宏莉 女,1973年出生,吉林榆树人,博士、教授、博士生导师,国家计算机信息内容安全重点实验室副主任,计算机网络与信息安全技术研究中心副主任,信息产业部十一五科技规划组专家.主要研究方向为网络信息安全、网络测量、并行处理. F-Seeker:Privacy-Aware Granular Moving-Object Query FrameworkBased on Over-Anonymity ZHOU Zhi-gang,ZHANG Hong-li,YE Lin,YU Xiang-zhan (SchoolofComputerScienceandEngineering,HarbinInstituteofTechnology,Harbin,Heilongjiang150001,China) Aiming to the privacy-preserving problem for moving-object retrieval services in social network,we propose a granular friend retrieval framework based on over-anonymity,called F-Seeker.Before outsourcing data,we adopt an enhanced anonymity strategy--(k,m,e)-anonymity,which preserving user privacy from the curious retrieval service provider.In the processing of providing services,the service provider employs over-anonymity strategy based on visibility requirements to realize granular data access control.In addition,we encode data using Z-order address and the retrieval efficiency can be improved by pruning.Experimental results show that the proposed strategy can protect user privacy while the computation overhead does not increase greatly. over-anonymity;granular search;location-based service (LBS);Voronoi diagram;Z-order space filling curve 2015-01-30; 2015-10-31;责任编辑:孙瑶 国家973重点基础研究发展计划(No.2011CB302605,No.2013CB329602);国家自然科学基金(No.61202457,No.61173144,No.61402137,No.61402149) TP393 A 0372-2112 (2016)10-2477-08 ��学报URL:http://www.ejournal.org.cn 10.3969/j.issn.0372-2112.2016.10.028


6 实验结果及分析


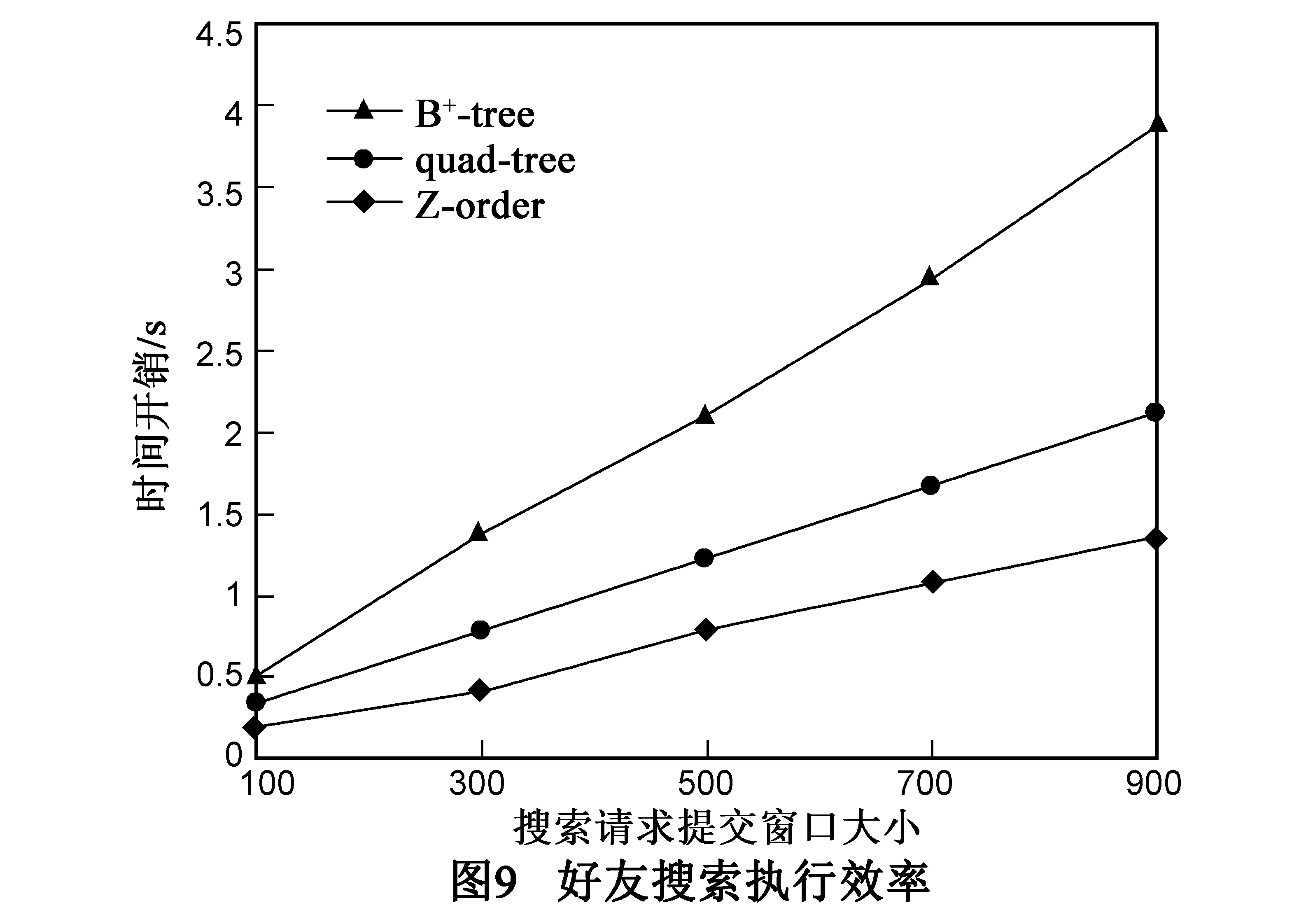
7 结束语


 猜你喜欢
粉末冶金技术(2021年3期)2021-07-28四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09汉字汉语研究(2020年2期)2020-08-13电子制作(2019年22期)2020-01-14小雪花·初中高分作文(2019年10期)2019-02-12疯狂英语·新读写(2018年3期)2018-11-29杂文月刊(2017年20期)2017-11-13系统工程与电子技术(2016年12期)2016-12-24浙江大学学报(工学版)(2016年11期)2016-06-05应用海洋学学报(2015年3期)2015-11-22
猜你喜欢
粉末冶金技术(2021年3期)2021-07-28四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09汉字汉语研究(2020年2期)2020-08-13电子制作(2019年22期)2020-01-14小雪花·初中高分作文(2019年10期)2019-02-12疯狂英语·新读写(2018年3期)2018-11-29杂文月刊(2017年20期)2017-11-13系统工程与电子技术(2016年12期)2016-12-24浙江大学学报(工学版)(2016年11期)2016-06-05应用海洋学学报(2015年3期)2015-11-22
