
一种基于多阶邻居的网络环境下多标签分类算法
2016-12-08 05:44王浩,张赞,李磊,汪萌
电子学报 2016年10期
王 浩,张 赞,李 磊,汪 萌
(合肥工业大学计算机与信息学院,安徽合肥 230009)
一种基于多阶邻居的网络环境下多标签分类算法
王 浩,张 赞,李 磊,汪 萌
(合肥工业大学计算机与信息学院,安徽合肥 230009)
随着标签分类应用的增长,社交网络环境下多标签分类已成为一个重要的数据挖掘研究领域.关系分类模型基于一阶邻居做标签分类,其性能优于传统的多标签分类器.但现有的关系分类模型也存在问题:第一,仅利用一阶邻居做分类,未能充分使用邻居信息.第二,网络数据通常包含大量不连通的孤立部分,其标签无法利用现有的关系分类模型分类.考虑基于共引规则为非孤立节点挖掘二阶邻居和基于节点特征向量相似度为孤立节点挖掘高阶邻居,本文提出一种新的基于多阶邻居的网络数据多标签分类算法,称为MORN算法.在多个真实数据集上将MORN与现有的关系分类模型作对比,实验表明,MORN算法能够学习到更多节点的标签且精度优于传统关系分类方法.
社交网络;关系学习;多标签分类
1 引言
近年来,随着社交网络(social networks)的发展和相关领域应用的不断深入,网络数据分类(networked data classification)已成为数据挖掘(data mining)的一个重要研究方向.区别于传统数据,网络数据包含相互联系的实体,不遵循实例独立性假设.实例和实例之间可以被多种多样的方式连接到一起.本文研究基于网络数据的多标签分类问题.
传统的关系分类模型[1]基于社交网络同质性及一阶马尔科夫假设,通过群体分类(collective classification)[2],可以分类网络数据的标签.其基本假设是:一个节点的标签依赖于网络中与它直接相连的邻居的标签[3].因此关系分类模型处理网络数据优于传统标签分类模型[4~6].但传统关系分类模型也存在两个问题:
(1)传统关系分类模型仅依赖与待分类节点直接相连的邻居节点,往往因为邻居中训练节点占比较少,影响分类精度.
(2)关系网络通常包含大量的孤立部分.其节点的标签无法利用现有的关系分类模型分类[7].
2 相关工作
2.1 传统多标签分类方法
解决传统多标签分类问题,通常基于两大类方法:第一类是将多标签分类问题拆解成多个单标签分类问题,例如Hullermeier等[8]提出的基于标签对比的方法.第二类是将单标签分类方法转化为多标签分类方法.Zhang等[9]提出的MLKNN算法就属此类.郑等[10]将随机游走模型引入多标签学习,提出了基于随机游走模型的多标签分类方法.
传统的多标签分类算法处理网络数据存在问题:第一,数据不满足独立同分布的假设;第二,无法有效利用实例之间连接关系;第三,通常需要使用实例的特征向量作为算法输入.综上三点,传统多标签分类方法不适合网络环境多标签分类.
2.2 网络数据多标签分类方法
Tang[11]等提出了基于社会特征提取的EdgeCluster算法,以解决当网络数据缺少特征向量时,难以使用传统多标签分类方法的问题.该算法的整体架构属于传统多标签分类方法.
关系分类模型基于网络中的连接,充分发掘实例之间和标签之间的依赖关系,再通过群体分类,估计所有未知标签节点的标签,经过重复迭代,最终获得一个稳定状态以最小化邻居节点间标签的不一致[12].关系分类模型代表算法有wvRN[13]和SCRN[3].
3 MORN算法
3.1 二阶邻居发现

共引性(citation regularity)是社会科学研究的重要现象[ 14,15],相似的实体倾向于连接到相同的事物.基于共引性,如果两个节点有较多的共同邻居,我们认为这两个节点存在相似性.在多标签分类计算中,我们引入了二阶邻居.
发掘二阶邻居的方法是:

(3)设定阈值T,当Numui-vi≥T时,我们认为ui是vi的二阶邻居.
下面我们用DBLP数据集中一个例子来说明引入二阶邻居的必要性,该数据集的详细介绍在4.1节.以图1为例,假设7344号节点是待分类节点.这5个节点的实际标签在表1中.

表1 7344号、2926号、3440号、7342和7775号节点的实际标签
接下来,我们给出wvRN算法的模型:
wvRN统计邻居节点具有标签λ的平均值P(Yi=λ|vi)作为节点vi具有标签λ的概率:
(1)
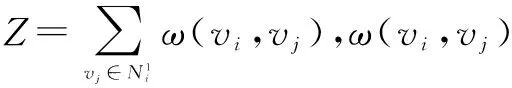
7344号节点的一阶邻居的权重都为1.根据式(1),7344号节点具有各标签的概率为:
wvRN默认已知7344号标签数目为2.依据各标签概率(在概率相等情况下,wvRN算法默认按标签顺序),7344号节点的标签分类结果是:Y7344={λ9,λ13},与实际情况不相符.
我们为7344号节点发掘到二阶邻居即7343号节点.其实际标签是Y7343={λ13,λ14}.
此时为7344号节点和7343号节点建立新连接(图中虚线).使用wvRN算法,7344号节点具有各标签的概率为:
此时,7344号节点的标签分类结果是:Y7344={λ13,λ14},与实际情况相符.此例说明引入二阶邻居可以更充分地利用邻居信息以利分类.
3.2 高阶邻居发现
基于社会特征相似度,从已知标签节点集中寻找与孤立节点相似的节点集,该集合中的节点即为该孤立节点的高阶邻居节点.相似度越大,说明孤立节点与该高阶邻居的标签集相似度越高,会被分配越高的权重.
挖掘高阶邻居的具体步骤如下:
(1)依据已知标签节点集的分布,识别出孤立节点集合Visolated,具体使用的工具在4.3节介绍.
(2)删除孤立节点vi∈Visolated与各一阶邻居的边,因为vi的一阶邻居都是孤立节点,对标签分类不起作用.
(3)我们用Tang等提出的边聚类算法[11]提取所有节点的社会特征向量SF(Social Features).该算法在网络结构上使用聚类刻画节点的特征向量,可以在无连接的情况下使度量节点间的关系成为可能.
(4)计算孤立节点vi与每一个已知标签节点vj∈Vm的社会特征向量的相似度Sim(SFvi,SFvj).
(5)我们选取与目标节点vi相似度数值大于0的已知标签的节点作为vi的高阶邻居.
(6)在网络G中,为每个目标节点vi与其高阶邻居建立新的边连接,边的权重为归一化后的相似度值.
下面我们举例说明高阶邻居挖掘.如图2所示,图中左半部分显示网络G由左右两个子网络G1和G2构成.假设已知标签节点集Vm=(v3440,v7342,v7344).我们想预测G2中包含的节点的标签.因G2中不含已知标签节点,我们得出G2是孤立部分,在图2中以灰色点表示.
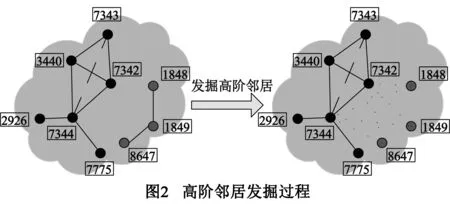
在确认v1848是孤立节点后,删除它与v1849的连接.计算v1848与Vm中每一个节点的社会特征向量相似度.选取相似度大于0的节点作为v1848的高阶邻居.假设发掘到的v1848的高阶邻居是v7342和v7344.我们分别为节点对(v1848,v7342)和(v1848,v7344)建立连接边.孤立节点v1849和v8647发掘高阶邻居的过程与v1848的发掘过程一致.
综合二阶邻居发现方法和高阶邻居发现方法,重新构建网络结构和邻居关系,调用SCRN算法作为基础分类器给出MORN算法,如下所示.
算法1 基于多阶邻居的多标签分类算法MORN
输入:网络G,标签集Y,训练集Vm,测试集Vtest,最大迭代次数Max-Iter
输出:Vtest中所有节点的标签
1. 使用文献[6]中的方法为G中每一个节点提取社会特征向量SF(vi)
2. 基于Vm的分布,计算得到孤立节点集合Visolated
3. for eachvi∈Vtestdo
4. ifvi∉Visolated
5. 发掘vi的二阶邻居 //3.1节
6. ifvi∈Visolated
7. 发掘vi的高阶邻居 //3.2节
8. 跟据上述3~7步,重新构建网络,得到G′
9. while iterations≤Max-Iterand predictions have not converged to stable values
10. 基于G′,调用SCRN算法作为底层分类器
11. endwhile
12. 得到Vu中节点的标签,从中提取出Vtest中节点的标签,即为测试集节点分类结果
4 实验
4.1 数据集
本文采用的DBLP数据集[3],提取自DBLP网站.IMDb数据集[3]提取自在线视频数据库IMDb,我们从中选取了10000个节点.DBLP数据集和IMDb数据集统计信息如表2所示.

表2 数据集统计信息
4.2 度量标准
本文使用2个经典的标签分类度量标准Macro-F1值和Micro-F1值[3,8,16]度量分类精度.
本文在度量各算法分类精度的基础上,提出预测比例PR(Prediction Ratio)指标来度量最终测试集内有多少比例的节点获得了分类标签.
(2)
4.3 实验结果与分析
我们基于Matlab实现MORN算法.采用的对比算法是SCRN、wvRN和EdgeCluster.
本文使用边聚类方法提取节点的社会特征向量.我们采用GHI[3]来计算特征向量相似度.我们基于Matlab BGL工具包识别孤立节点.依据文献[3]和文献[11],DBLP数据集的社会特征向量维度设置为1000,IMDb数据集的社会特征向量维度设置为10000,其它均采用默认参数.
对比实验使用网络交叉验证(Network Cross-Validation,NCV)[16]对结果进行验证,以减小测试集的重叠.
4.3.1 二阶邻居发现中阈值T对实验结果的影响
在DBLP上做实验,比较T取不同值,Micro-F1的变化.训练集规模设定为10%,实验结果如图3所示.通过实验发现,T值取1时,Micro-F1值最大,为57.02%.当T值增大到2,Micro-F1值降低到56.59%,降幅非常明显.随着T值进一步扩大,Micro-F1值变化极小.因此,在后续实验中,我们设定T值为1.

4.3.2 MORN算法和SCRN算法运算时间对比分析
我们对比两个算法在标签预测上开销的时间.MORN算法和SCRN算法在标签预测阶段,迭代次数Max_Iter都设为10.由表3的实验结果可知,虽然MORN需要挖掘新的邻居,运算时间多于SCRN,但在可接受范围之内.

表3 MORN算法和SCRN算法在DBLP数据集上的运算时间
4.3.3 标签分类结果与分析
从表4和表5可知,MORN、SCRN和wvRN的精度高于EdgeCluster.MORN在DBLP上的精度高于SCRN和wvRN.在IMDb上,MORN的精度高于wvRN,但在训练集占1%—2%时,MORN的精度低于SCRN.原因是训练集过少,发掘到的二阶邻居和多阶邻居数量都非常少.随着训练集增大到3%以上,MORN在IMDb上精度好于SCRN和wvRN.对比实验说明MORN的精度比SCRN和wvRN更高.

表4 各算法在DBLP数据集上的分类精度
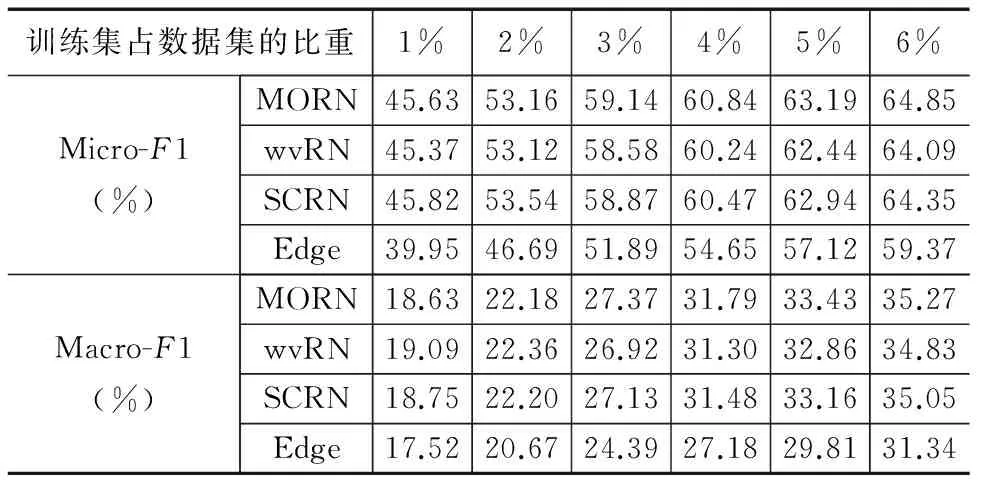
表5 各算法在IMDb数据集上的分类精度
从表6和表7可知,MORN在PR值上好于SCRN和wvRN,在DBLP上领先13%-15%;在IMDb上领先8%-15%.实验结果说明,MORN可以有效地学习到孤立节点的标签.随着训练集规模扩大,MORN在PR值上接近100%,但没有达到100%.原因是少数孤立节点与所有的训练集节点的特征向量相似度都为0,无法为其找到相似的节点.
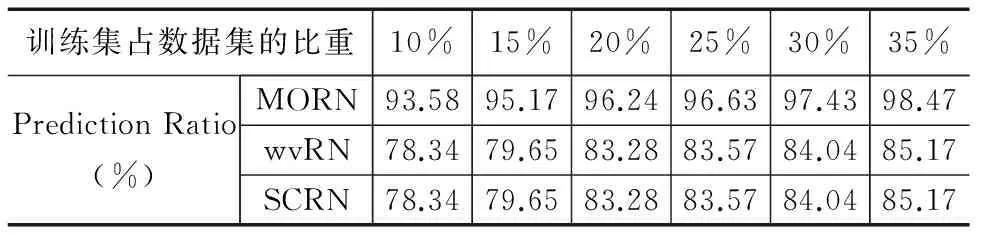
表6 关系分类方法在DBLP数据集上的预测比例
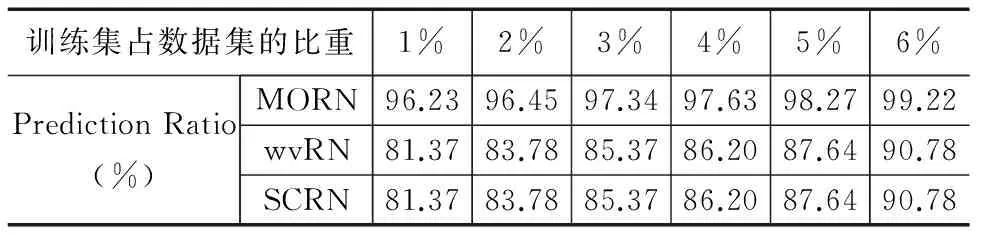
表7 关系分类方法在IMDb数据集上的预测比例
5 结论
本文分析了现有关系分类模型在处理网络环境下多标签分类存在的问题.针对现有关系分类模型仅利用一阶邻居做分类并且无法学习孤立节点标签的不足,提出了一种基于多阶邻居的网络数据多标签分类MORN算法.理论分析和实验都证明了MORN算法能够有效解决网络环境下多标签分类问题.
[1]S Macskassy,F Provost.A simple relational classifier[A].Proceedings of the Second Workshop on Multi-Relational Data Mining at ACM SIGKDD[C].Washington DC,USA:ACM,2003.64-76.
[2]P SEN,G Namata,M Bilgic,L Getoor,B Gallagher,T Eliassi-Rad.Collective classification in network data[J].AI Magazine,2008,29(3):93-106.
[3]X Wang,G Sukthankar.Multi-label relational neighbor classification using social context features[A].Proceedings of the ACM SIGKDD[C].Chicago,USA:ACM,2013.464-472.
[4]J Neville,D Jensen,L Friedland,M Hay.Learning relational probability trees[A].Proceedings of the ACM SIGKDD[C].Washington DC,USA:ACM,2003.625-630.
[5]B Taskar,P Abbeel,D Koller.Discriminative probabilistic models for relational data[A].Proceedings of the UAI[C].Edmonton,Canada:Morgan Kaufmann,2002.485-492.
[6]M Zhang,K Zhang.Multi-label learning by exploiting label dependency[A].Proceedings of the ACM SIGKDD[C].Washington DC,USA:ACM,2010.999-1007.
[7]C Aggarwal.Social Network Data Analytics[M].Berlin:Springer,2011.115-148.
[8]E Hullermeier,J Furnkranz,W Cheng,K Brinker .Label ranking by learning pairwise preferences[J].Artificial Intelligence,2008,172(16):1897-1916.
[9]M Zhang,Z Zhou.A k-nearest neighbor based algorithm for multi-label classification[A].Proceedings of the IEEE International Conference on Granular Computing[C].Beijing,China:IEEE,2005.718-721.
[10]郑伟,王朝坤,刘璋,王建民.一种基于随机游走模型的多标签分类算法[J].计算机学报,2010,33(8):1418-1426.
W Zheng,C Wang ,Z Liu,J Wang.A multi-label classification algorithm based on random walk model[J].Chinese Journal of Computers,2010,33(8):1418-1426.(in Chinese)
[11]L Tang,H Liu.Scalable learning of collective behavior based on sparse social dimensions[A].Proceedings of the ACM CIKM[C].Hong Kong,China:ACM,2009.1107-1116.
[12]J Neville,D Jensen.Iterative classification in relational data[A].Proceedings of the AAAI Workshop on Learning Statistical Models from Relational Data[C].Austin,USA:AAAI,2000.42-49.
[13]S Macskassy,F Provost.Classification in networked data:a toolkit and a univariate case study[J].Journal of Machine Learning,2007,8(5):935-983.
[14]M Newman.Networks:An Introduction[M].Oxford:Oxford University Press,2010.
[15]M McPherson,L Smith-lovin,J Cook.Birds of a feather:Homophily in social networks[J].Annual Review of Sociology,2001,27(1):415-444.
[16]J Neville,B Gallagher,T Eliassi-Rad,T Wang,Correcting evaluation bias of relational classifiers with network cross validation[J].Knowledge and Information Systems,2012,30(1):31-55.

王 浩 男,1962年生,江苏泰州人.合肥工业大学计算机与信息学院教授,博士生导师.1984年于上海交通大学获工学学士学位,1989年和1997年于合肥工业大学获工学硕士和工学博士学位.主要研究方向为智能计算理论与软件、分布式智能系统、复杂系统理论与建模等.

张 赞 男,1987年生,安徽马鞍山人.2009年于东北电力大学获管理学学士学位,2013年于合肥工业大学获工学硕士学位.现为合肥工业大学博士研究生.主要研究方向为社交网络行为的预测和分类研究.
E-mail:zhangzan99@163.com
A Multi-Order Neighbor Based Multi-Label Classification Algorithm in Network Environments
WANG Hao,ZHANG Zan,LI Lei,WANG Meng
(SchoolofComputerandInformation,HefeiUniversityofTechnology,Hefei,Anhui230009,China)
Multi-label classification in network environments is becoming a key area of data mining research as its applications are increasing dramatically.Relational classification models,which predict class labels of linked neighbors according to the ones of the given nodes,have been shown to outperform traditional multi-label classifiers.However,existing relational classification models neither make full use of neighbor information,nor predict the isolated nodes’ labels,which are popularly existing in relational networks.In this paper,we present a multi-label relational classifier (MORN) that mines both second-order neighbors for non-isolated nodes and high-order neighbors for isolated nodes.MORN has been conducted on real datasets and it demonstrates that our proposed classifier outperforms existing relational classification models.
social networks;relational learning;multi-label classification
2015-01-31;
2015-07-31;责任编辑:李勇锋
国家973重点基础研究发展计划(No.2013CB329604);国家自然科学基金(No.61070131,No.61175051);安徽省自然科学基金(No.1408085QF130);中央高校基本科研业务费专项(No.2015HGCH0012)
TP311
A
0372-2112 (2016)10-2330-05
��学报URL:http://www.ejournal.org.cn
10.3969/j.issn.0372-2112.2016.10.007
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
数学物理学报(2021年1期)2021-03-29
数学物理学报(2020年6期)2021-01-14
哈尔滨轴承(2020年1期)2020-11-03
应用数学(2020年2期)2020-06-24
数学物理学报(2020年1期)2020-04-21
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
许昌学院学报(2018年4期)2018-05-02
