
数据密集型科学与大数据视域下的健康信息行为研究*
2016-12-08 10:35宋美杰
现代传播-中国传媒大学学报 2016年11期
■ 宋美杰
数据密集型科学与大数据视域下的健康信息行为研究*
■ 宋美杰
本文以健康信息行为研究这一健康传播分支领域为个案,对前沿科研项目的数据来源、研究对象、研究应用以及范式变革进行了探讨,认为传统以经验或实证的方法研究社会现象的社会行为范式将理论发现限制在人们现有的认知能力范围内。大数据时代的到来,使数据密集科学从第三范式中分离出来,放弃对因果关系的执着,转而关注相关关系,倡导数据处理先于理论假设并有可能得出之前未知的理论,为健康传播理论创新创造了条件,新媒体技术、可穿戴设备、精准医疗给健康传播带来了新的研究问题。
健康信息行为;大数据;第四范式;理论模型
“模型皆有误,或尤建奇功(All models are wrong,but some are useful)”,几乎每个统计学家和科学工作者都熟知30多年前乔治·伯克斯(George E.P.Box)提出的论断。但一直以来研究者别无选择,因果关系的构建引发了科学体系的建立,从宇宙哲学方程到人类日常行为,只有使用模型才能不完美的解释我们周围的世界(Anderson,2008)①。这一范式的隐忧就在于理论和参数决定了数据的搜集范围。理论模型的精简,要求研究者在重要与不重要的参数之间进行取舍。然而那些被排除在数据采集范围外的、非重要参数在某些条件下或许就起到了关键作用。
步入21世纪,随着信息与网络技术的迅速发展,新型传感器和基础设施可以实时获取从宏观到微观、从自然到社会的海量数据。大数据时代最大的转变,就是放弃对因果关系的执着,转而关注相关关系,与之相适应数据处理先于理论假设并有可能得出之前未知的理论。大数据也正在尝试为社会科学脱下“准科学”的外衣。与海量数据计算紧密相关的舆情分析、情感分析、社会化媒体研究都在尝试创新研究路径,发现以往研究范式无法实现的规律、知识。
在这一宏观背景下,数据密集型科学与大数据给传播学研究提供了更多的方法与可能:跨越多种媒介渠道的统合数据分析;跨时期的宏观数据与微观数据结合;计算机内容分析与传统内容分析交互验证;数据挖掘和机器学习处理社交媒体上数量庞大的关系与行为数据。传播学领域的顶级期刊《传播学刊》(Journal of Communication)出版了《传播学研究中的大数据》特刊,收录了政治传播、健康传播、新媒体研究等领域以大数据为支撑的研究成果。作为跨越自然科学医学、社会科学传播学的新研究领域,大数据与数据密集型科学对健康传播的研究范式变革最为突出。
一、健康信息行为的研究路径
健康传播研究发端于20世纪70年代,以理论关照下的实证研究为主流,通过理论模型(Conceptual model)和实测模型(Measurement model)的构建来研究具体的健康相关问题。中国健康传播研究起步迟、受美欧影响大、国际学术话语影响力极为有限②,且鲜有影响公众实际健康行为的成果。当前的健康传播研究也面临着研究领域的拓展与工具方法的创新:一方面,医学、认知科学、生物系统、医疗服务等领域的数据密集型科学研究取得了重要进展;另一方面,新媒体技术、可穿戴设备、精准医疗也给健康传播带来更广泛的研究问题。本文以健康信息行为研究(Health Information-Seeking Behavior,HISB)这一健康传播的分支领域为代表,探讨大数据对健康传播以及传播学研究中的数据来源、研究对象、研究方法乃至整体研究范式上的变革。
1.健康信息行为的模型构建
信息行为是建立在信息资源和信息渠道基础上的所有人类行为的总和,包括主动与被动的信息查询与使用行为③。信息行为研究涉及政治广告、恐怖袭击、健康风险以及环境问题等诸多领域。健康信息行为属于健康传播与信息行为研究的交叉领域,即人们通过某些渠道获取健康信息、了解健康风险以及疾病预防知识④(Brashers,Goldsmith,& Hsieh,2002)。与健康传播研究的其它领域类似,美欧主流的健康信息行为研究多采用模型构建的方式展开研究,以结构方程模型(Structural Equation Modeling)的手段处理数据。
作为对现实事件内在机制直观、简洁的描述,模型隐含了对相关性的判断,这种判断又可以抽象为某种理论。如果一个模型具有可操作性,便可以转化为实测模型、用数据来证伪。在近30年的研究历程中,健康信息行为研究者发展了诸多理论模型来解释个体主动/被动/避免寻求健康信息的原因,使用较多的模型包括:信息寻求模型(Information Seeking model,Lenz’s,1984),健康信息采集模型(Health Information Acquisition Model ,Freimuth,Stein,& Kean,1989),信息寻求综合模型(The Comprehensive Model of Information Seeking ,Johnson,1997,2003),信息寻求行为扩展模型(The Expanded Model of Health Information-seeking Behaviors,Longo,2005)。模型多以传播学、心理学、图书情报学、医学等学科中的相关理论为基础,借助相关或因果关系构造变量间的关联方式,形成可以检验的实测模型。上述模型,都指定几种个人、情境或内容因素来检验健康信息寻求的主动性(Lambert,& Loiselle,2007)⑤。
2.传统研究范式的局限与反思
本部分以Johnson(1997)的信息寻求综合模型(The Comprehensive Model of Information Seeking)为例(见图1),进一步解释健康信息行为的典型研究路径。该模型以使用满足和意义构建理论为基础,认为只有人们意识到现有的知识和需要解决的问题之间存在差距,信息寻求行为才会触发。因此,模型中涉及的核心变量包括:个体的人口统计特征、以往的媒介使用经验、问题的显著性和自我效能。以上四个因素影响了人们对各类渠道功用的看法,而这又反过来决定了具体的健康信息寻求行为。
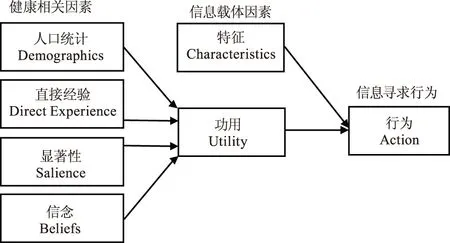
图1 信息寻求综合模型(Johnson,1997)⑥
这种基于理论与经验构建模型、操作化变量,通过抽样调查获取数据,用经典的统计方法进行检验与预测的实证研究范式,是健康信息寻求研究的主导,也是传播学量化研究的主流。但社会科学研究与自然科学的差异在于,人类行为具有不确定性,很难做到精确量化与预测。以上述的信息寻求综合模型为例,人们的个体偏好、媒介使用习惯、时空环境、情绪状况都具有极大的偶然性与特殊性。Johnson(1997,2003)以及其它研究领域多次测试过该模型,发现对于不同的任务和目标,对于某些任务/人群可能毫无影响的前提变量在另外一些任务/人群中影响却是显著的⑦。这同时也是模拟仿真范式所存在的问题,依据理论与经验的变量取舍很可能造成结果的大相径庭,同时也将理论的发现与变量间的关联限制在人们现有的认知能力范围内。
对于健康信息行为研究,乃至更大范畴的传播学量化研究而言,模型仅提取最主要的变量进行描述,排除了众多干扰因素的同时也丧失了模型的现实应用价值。作为一种旨在探索新理论的研究路径,健康信息行为中往往包含十几甚至几十个变量。问卷、量表的数据获取方式会造成数据的损失与失真,传播行为所依存的人际关系、群体背景与时空情境均被抽象化和剥离。作为一门应用科学,这一传统研究范式的缺陷也为部分质化研究者所诟病。很长一段时间以来,健康传播研究少有突破性的理论发现,大多数的研究者都在前人铺就的道路上做着精致而无用的重复劳动。是否存在更有效的数据收集与处理方式?是否有更好方法来解释和预测人们的健康信息行为?是否能开创新的范式探索前所未有的理论?研究的成果如何能更直接的应用于公众医疗与健康促进活动中?数据密集型科学范式与大数据技术提供了具有启发意义的解决方案。
二、数据密集型科学的研究范式变革
科学数据的爆炸式增长给前沿科学项目带来了巨大挑战,研究者需要不断改进科研工具和技术方法来探索变化中的自然与社会。科学研究的历史是一个逐渐趋近真实的进程:实验归纳(第一范式),实验为基础的科学研究模式,以文艺复兴时期哥白尼、伽利略、开普勒创建的实验观察模式为代表;理论推演(第二范式),理论研究为基础的科学研究模式,以牛顿微积分和经典力学的模型推演和理论精准预测为代表,这一范式在19世纪末发展到极致;计算机仿真(第三范式),20世中期冯·诺依曼提出了现代电子计算机架构,计算机仿真越来越多地取代实验⑧。利用电子计算机对科学实验进行模拟仿真成为科研的常规方法。
健康信息行为研究的传统研究路径与模拟仿真“理论提出—数据搜集—计算仿真—理论验证”的过程一致,同属于第三范式。詹姆士·格雷 (James Gray)认为大数据可以使得数据密集型科学(Data-Intensive Scientific Discovery)从第三范式中分离出来,成为一个独特的科学研究范式,即“第四范式”⑨。数据不再仅是科学研究的结果,更成为了科学研究的对象、工具乃至基础设施。传统以数学模型计算为中心的方式将转变为以海量数据处理为中心。第四范式在学术界尚存在争议,但这一方法已在商业实践中取得了丰硕的成果,梅西百货应用数据密集型科学对千万种商品进行实时调价、美国运通基于历史交易数据对消费者进行忠诚度预测。
说服公众采取健康的行为习惯和生活方式是健康传播研究的终极目的。媒体通过一系列健康传播活动与健康促进运动来提高人们对风险因素的认知。咨询医生、搜索信息、亲友讨论等积极的健康信息行为是态度转变的前提。大数据为健康传播研究中的大型社交网络的分析、自动的数据收集和数据挖掘、可视化、情感分析、意见挖掘、机器学习、自然语言处理以及计算机辅助下的内容分析提供了基础性的可能。以理论、假设、模型、检验为路径的健康信息行为研究也呈现了一种全新的研究范式。
三、大数据时代的健康信息行为研究趋势
传统研究建立在关系数据模型之上,数理统计是健康传播与健康信息行为研究的主流方法。利用SAS、STAT等软件建立模型,根据假设对收集到的数据进行各种方差分析、回归分析,通过解读分析指标发现数据间的关系和隐藏的规律,从而验证或推翻假设。随着大数据技术的普及,无论是源自自然界、生命和生物、社交媒体的数据,无论其原始数据是结构化的、半结构化、甚至是分布在网络上的异构型数据,都可以纳入到研究之中。按照之前所综述的健康信息寻求的经典研究路径,面对如此庞杂的数据,很难一开始就以一种正式的方式建立模型并描述清关系。数据类型和数据量的剧增,使得原有的经典研究路径与数据处理方法不适应于健康信息行为研究的新趋势。
1.数据来源:从问卷调查到实时数据流
前文归纳了健康信息行为研究的三类核心变量:个人、媒介、情境。当涉及特定健康问题,如癌症、慢性病、保健养生时,则需要考虑信息寻求者的健康状况及其可能获得的医疗服务资源。因此,个人特征、健康状况、社会资源、媒介使用是健康信息寻求研究中必须收集的基础性数据。健康传播研究中最普遍的数据采集方式是问卷调查,如美国每两年一次的健康信息全国趋势调查。我国卫生统计也建起了覆盖国家、省、市、县、乡、村六级、从业人员达10万人的工作网络,90余万家医疗卫生机构通过统计直报系统上报年报及月报⑩。这类调查需要集合医学、传播学、心理学等多领域专家设计包含健康素养、行为习惯、渠道依赖、社会保障等诸多变量的问卷。以理论假设为前提,包含有限问题的问卷结构导致研究角度单一且难以进行数据补充,且数据获取成本高昂、周期漫长。
在大数据时代,报刊、电视、广播、互联网产生的媒体数据,个人在社交媒体上发布的文字、图片、视频,以及人们网络搜索、浏览、点击、购买行为都在以数字化的方式记录存储下来。地理位置和空间移动信息、社会关系资料、电子健康档案、智能医疗设备信息也可以被数据化存储分析。作为一种人类信息行为的研究,直接采用行为痕迹数据能更好地还原人们寻求健康信息时所处的环境与情景。大数据所提供的多类型数据之中包含的信息更为丰富,单位数据的研究价值也更高。以生物大数据为例,Google和DNAnexus一起打造一个巨大的开放式DNA数据库,并储存于谷歌的云计算服务器,免费向医学研究者提供接入服务。大数据技术为健康信息行为研究提供数据来源方面的新路径。
智能手机、可穿戴设备可以24小时读取并传输如心率、行走步数、卡路里燃烧、血糖状况、心理压力等生物识别数据。智能可穿戴产品所展现的量化自我理念,即通过对人们生理和心理数据的采集与分析,实现了人、机、数据三元融合,获得全集数据的可能性也使健康传播学研究尤其是健康信息行为研究可以不再完全依赖于问卷量表测量以及随机抽样。随着移动互联网和可穿戴设配普及,这种实时更新的动态数据会促使健康传播延伸出新的研究领域。

2.研究对象:人口统计指标到多维标签化
健康传播与社会科学中的其他学科一样,更关注社会中小群体的行为特征。健康信息行为研究更着重于特殊年龄(如老年人的HISB、普通成年人的HISB、青少年的HISB)、少数种族(如非裔美国人、韩裔美国人)、偏远地区(如从城乡、发达国际与发展中国家等不同地域视角分析健康信息知沟情况)、重点疾病(如癌症患者、艾滋病人、慢性病患者)人群。以往研究只能以可直接观测的变量为依据,将大众细分为性别、年龄、收入、受教育水平不同的群体,寻找细分群体差异性与显著性。基于行为数据多维度人群的识别与聚类的方式在传统的传播学研究之中是很难实现的。
大数据时代数据以量级剧增,数据结构多元,每个人都可以根据其自然、社会、行为属性的区别贴上更具特色化的标签,如垃圾食品买家、每日运动量1万步以下、KEEP用户、社交媒体重度使用者、驾车……通过对行为数据的掌握可以实现多维化的人群细分,设计出更贴近现实行为的研究假设与分析视角。行为相关关系的群体划分具有较高的准确性,这一方法已经广泛应用于广告投放、个性化新闻定制、网络购买推荐。
传统医疗实践以病人的临床症状和体征为分类标准,给患同一种病的人吃同样的药,大数据时代的个性化医疗则可以按照患者的基因序列设计出最佳治疗方案。健康传播领域的人群标签算法与个性化医疗相似,根据生理、行为、环境属性将人群进行为多维分类,按照研究目的,可以自由组合多维度、同属性的子群体。根据行为特征所划分的小群体与基于人口统计指标的群体划分方式不同,其依据的是个人的实际行为而非推断行为,更符合社会科学研究的本质。
3.研究应用:从面向过去到预测未来


四、“第四范式”的变革与展望
Peter Norvig(谷歌公司的研究部主任)更新了 George Box的座右铭:“所有的模型都是错误的,没有这些模型反而增加你成功的机会(All models are wrong,and increasingly you can succeed without them)”。美国《连线》杂志主编Chris Anderson在其著名的演讲“理论的终结:数据洪流让科学方法过时(The End of Theory:The Data Deluge Makes the Scientific Method Obsolete)”的结尾提出:海量数据,以及用来处理这些数据的统计性工具,给我们提供了一个理解世界的新方法。关联关系比因果关系重要,科学甚至能在没有一致模型、统一理论,甚至完全不需要任何解释的情况下进步。
一直以来,以抽样调查为主流的传播学量化研究都在试图将数据做“大”,扩大样本量以满足置信区间。但在大数据时代,研究的目的是将数据做“小”,数据的无穷尽性需要研究者在达到心中设定的阈值后便停止采集,追求数据的质量与净化程度,把大数据变为可以利用的小数据。不忘初心,方得始终。传播学研究者应该最明白信息过载所带来的危害,不要让大数据时代过多的冗余信息迷失了研究的真正目的。
注释:
① Anderson C.TheEndofTheory:TheDataDelugeMakesScientificMethodObsolete.Wired Magazine,2008,16(7).
② 王积龙:《健康传播在国际学界研究的格局、径路、理论与趋势》,《上海交通大学学报(哲学社会科学版)》,2011年第1期。
③ 乔欢:《信息行为学》,北京师范大学出版社2010年版,第10页。
④ Brashers D E,Goldsmith D J,Hsieh E.InformationSeekingandAvoidinginHealthContexts.Human Communication Research,2002,28(2):pp.258-271.
⑤ Lambert,S.D.,& Loiselle,C.G.HealthInformation—SeekingBehavior.Qualitative Health Research,2007,17(8):pp.1006-1019.
⑥ Johnson J D,Johnson D J.Cancer-relatedInformationSeeking.Cresskill,NJ:Hampton Press,1997.
⑦ Johnson J D,Meischke H.AComprehensiveModelofCancer‐RelatedInformationSeekingAppliedtoMagazines.Human Communication Research,1993,19(3):pp.343-367.
⑧ [美]Tony Hey,Stewart Tansley,Kristin Tolle:《第四范式:数据密集型科学发现》,潘教峰、张晓林译,科学出版社2012年版,第16页。
⑨ Hey T,Tansley S,Tolle K.TheFourthParadigm:Data-IntensiveScientificDiscovery.General Collection,2009,317(8):p.1.
⑩ 周光华、辛英、张雅洁、胡婷、李岳峰:《医疗卫生领域大数据应用探讨》,《中国卫生信息管理杂志》,2013年第4期。



(作者系福建师范大学传播学院讲师)
【责任编辑:张国涛】
*本文系国家社科基金青年项目“青少年新媒体健康信息行为研究”(项目编号:15CXW025)的研究成果。
猜你喜欢
当代陕西(2022年5期)2022-04-19
新世纪智能(数学备考)(2021年9期)2021-11-24
甘肃教育(2021年10期)2021-11-02
福建江夏学院学报(2021年6期)2021-08-10
湘潮(上半月)(2021年4期)2021-07-20
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
汕头大学学报(自然科学版)(2020年4期)2020-12-14
大连民族大学学报(2020年2期)2020-06-16
英美文学研究论丛(2018年1期)2018-08-16
北方音乐(2017年4期)2017-05-04
