
一种基于交叉特征学习的复杂事件检测算法
2016-12-06 10:25武俊芳
实验室研究与探索 2016年5期
武俊芳, 郭 英
(1. 河南理工大学 万方科技学院, 河南 郑州 451400; 2. 南阳广播电视大学, 河南 南阳 473036)
一种基于交叉特征学习的复杂事件检测算法
武俊芳1, 郭 英2
(1. 河南理工大学 万方科技学院, 河南 郑州 451400; 2. 南阳广播电视大学, 河南 南阳 473036)

提出一种改进的事件检测算法,通过交叉特征学习实现相关样本的自适应利用。首先将相关性水平看成是有序标签,利用标签候选集中相邻两个相关性标签的最大容限准则进行模型学习。然后采用多核学习理论来定义标签加权问题,通过交叉特征预测来更新标签候选集合。重复上述步骤直到算法收敛为止,将最终获得的统一检测器用于事件检测。利用大规模TRECVID 2011数据集来测试本文算法,实验结果表明,就平均精度和Pmiss值而言,本文算法的检测性能优于当前其他算法。
复杂事件检测; 相关样本; 交叉特征学习; 标签候选集; 平均精度
0 引 言
复杂事件是对较长视频片断更高层次的语义抽象,其语义抽象层次要高于运动、场景或对象[1]。例如,“生日聚会”事件可能包含人物、生日蛋糕、唱歌、欢呼、吹蜡烛等多种概念。此外,描述同一事件的视频往往发生强烈的事件内部变化。“生日聚会”可能在室内(比如餐厅)或室外(比如公园),而且人们可用唱歌,聚餐,或者玩游戏来欢庆生日,与只持续数秒钟的运动或用一幅图片即可检测出来的对象不同,复杂事件的持续时间从数分钟至数小时不等。
虽然复杂事件检测的难度很大,但在近几年仍然受到人们的大量关注[2-3]。持续时间较长且类内变化较大的视频,包含的信息丰富复杂,而且单个特征无法有效刻画视频的整个信息。当前研究认为将多个特征进行综合是实现事件检测的有效方法[4-6]。然而这些研究对特征进行综合的方式过于简单,没有考虑事件检测时不同特征间的相关性。如果设法发掘出不同特征间的共享信息,便可更为有效地对多个特征加以利用。鉴于此,提出一种面向复杂事件检测的多特征学习算法。该算法可有效挖掘不同特征间的相关性,然后联合处理多个特征,最终提高事件检测的稳健性。
1 相关工作
复杂事件检测是目前计算机视觉领域的研究热点,人们已经从特征或分类角度提出多种策略来提升检测精度。文献[7]提出一种基于多通道形态-流核描述符的事件检测算法。Yang等[8]提出一种算法从多模态(multi-modality)信号中检测出日期驱动概念,然后进行稀疏视频表示学习,进而实现事件检测。Natarajan等[5]提出通过综合多模态的不同特征来提升多媒体事件检测的性能。Tamrakar等[6]评估了多种主流特征对复杂事件检测的性能。文献[9]利用Fisher向量来融合低层描述符来表示视频,然后实现复杂事件检测。另一方面,Ma等[10]提出当正性样本数量较少时利用迁移学习实现复杂事件检测。Liu等[11]提出一种局部专家森林模型来融合多个分类器的得分,然后实现复杂事件检测。上述研究取得的进展虽然振奋人心,但是大多没有利用到事件特征的相关性,因此还有进一步提升检测性能的空间。
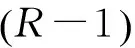
2 本文算法
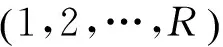
2.1 多相关性水平学习
假设从视频中提取了P个不同特征,本文将基于不确定性标签的多特征学习问题表述如下:
(1)

(2)

(3)
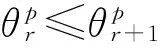
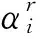
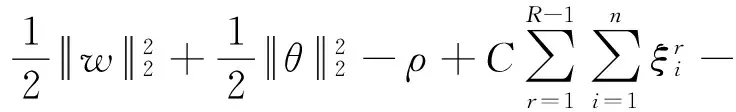
(4)
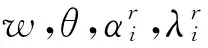
(5)
其中,
于是式(5)可简化为:
(6)
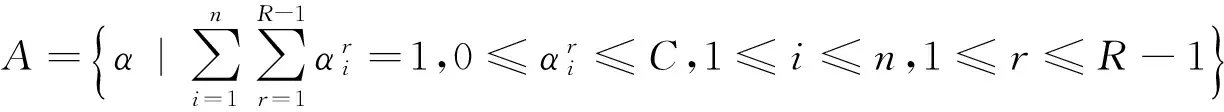
(7)


(8)
对式(8)不等式约束引入拉格朗日变量dm≥0,上述问题可放松为:
(9)
其中,D表示d的可行集,且
调换maxα∈A和mind∈D等价于:
(10)
2.2 基于交叉特征选举的标签候选更新
由于数据条件不够平衡,所以无法获得用于判定预测值的标识为+1或-1的准确阈值。为了将预测值离散化为标签集,本文并没有只设置一个阈值(阈值一般为0),而是利用其他特征的预测值来融合它们的信息,然后对预测值设置不同阈值来获得标签候选集合。之所以设置不同阈值,是因为在数据不平衡条件下,预测值存在严重偏差。因此,需要设置不同阈值,然后生成更大规模的标签候选集。本文模型可选择质量较高的标签候选。
对于预测数据源,可以只利用上次迭代训练好的分类器所提供的预测值。然而,之前迭代时质量较差的标签候选可能传播到后续的标签候选中,进而降低预测性能。尤其是在前几次迭代时,标签候选的精度可能较低。因此,除了最后一次迭代生成的标签候选外,保留各次迭代时的标签候选。在整个迭代过程中利用标签候选来提高所生成的标签候选的稳健性。
我们提出一种交叉特征选举方法来更新标签候选,其中第p个特征的标签候选由其他特征选举。本文方法可表述如下:
(11)
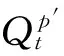
算法1:基于多特征的多相关性水平学习。
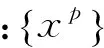
输出:αp,dp,Yp
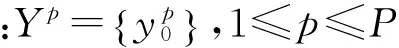
m←1;
m←1;
forp←1 toPdo
根据式(10)和Yp求解dp和dp;
获得数据点xp的预测值zp;
设置zp的不同阈值,获得满足约束的标签候选集Qp;
end
forp←1 toPdo
Yp←Yp∪Qp′;
end
m←m+1
until终止条件;
2.3 中止准则和收敛
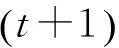
2.4 时间复杂度
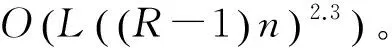
3 实 验
3.1 数据集
为了验证本文方法的性能,采用NIST从Youtube等互联网主机网站上收集的大量视频数据集(TRECVID MED)进行了仿真实验,它包含32 000多个测试视频。总持续时间为1 200 h,体积约800 GB。TRECVID MED测试集中的事件包括“生日聚会(BP)”“更换车辆轮胎(CaVT)”“民众集会(FMG)”“拆解汽车(GaVU)”“饲养动物(GaA)”“制作三明治(MaS)”“游行(PR)”“跑酷(PK)”“修理设备(RaA)”“缝纫(WaSP)”。NIST为每个事件提供的正性样本数量从100~200个不等,相关性样本数量约为150个。
我们在实验中使用3种视频特征[17]:密集轨迹、MoSIFT和彩色SIFT (CSIFT),经证明这些特征是TRECVID MED竞赛中的最优视觉特征。我们从视频中提取这3种特征,然后为每个描述符生成尺寸为4 096的视觉词表。视频被映射到4 096维词包中(BoWs)。我们采用1×1, 2×2和3×1空间网格来生成空间BoW。因此,每个特征有32 768维空间表示。根据文献[4]可知,c2-核是视频分析最为有效的内核。因此,在本文算法的预处理阶段对c2-核采用KPCA策略。
3.2 比较算法
根据TRECVID竞赛中排名靠前队伍的报告及事件检测领域的近期研究[4-5,7],支持向量机和核回归(KR)是最为可靠的事件检测算法。为了阐述相关性样本的利用方式不同将会产生不同的结果,进行如下实验。首先,将所有相关样本看成是正性标签,然后训练事件检测器,并给出结果。我们分别将实验表示为SVMNEG和KRNEG。与文献[4]一致,我们对SVM和KR应用c2-核。对于多特征融合算法,对这些特征进行早期融合及晚期融合。对早期融合算法,采用平均早期融合策略。对晚期融合算法,采用平均晚期融合及LP-Boost融合策略[18]。
在本文算法中将参数C设置为1,对相关性水平设置R=4,然后要求高相关性视频数量不得超过相关性视频总量的20%。在比较时使用两种评估指标。一种是平均精度(AP),另一种是TRECVID MED官方评估时采用的Pmiss。
3.3 单特征实验结果
本文模型可获得每个特征的预测值,下面给出了利用单特征时的检测结果。为了表示利用相关性标签信息的有效性,我们与基于单特征的SVM、SVMPOS、SVMPOS、KR、KRPOS和KRNEG算法做比较。表1给出了不同算法在密集轨迹、MoSIFT和CSIFT指标方面的检测性能(取10个事件的平均精度)。从表1中可以看出,3个特征中无论采用哪种特征,本文算法的性能均显著优于其他算法。

表1 基于单特征的检测性能比较(10个事件的平均AP)
10个事件的完整名称见3.1节,Pmiss值越小表明性能越好,AP值越高表明性能越好。
图1给出了不同算法对密集轨迹这一最优特征的性能比较情况。可以发现,本文算法对不同事件的性能仍然始终优于其他最新算法。具体来说,就Pmiss和AP指标而言,除了事件MaS和RaA外,本文算法在10个事件中的8个事件显示出来的性能均优于其他所有算法。从以上的仿真结果还可以看出,如果对相关性样本利用不当,则有可能降低性能。例如,考虑3种特征时SVMPOS的性能低于SVM。对KR同样如此:KRPOS的性能低于KR。这些结果表明,相关性样本不得直接看成是正性样本。从人类语义层面上定义的相关性未必一定接近于正性样本。因此,为相关性样本赋予正性标签或高置信度,对检测性能不利。另一方面,我们可以发现SVMNEG的性能与SVM类似,KRNEG的性能与KR类似。这一现象可做如下解释:扩大阴性样本的空间不会对性能产生重大影响。
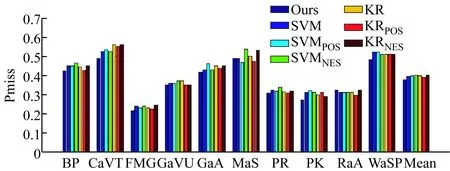
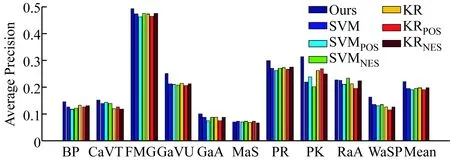
图1 不同算法采用密集轨迹单特征时的性能比较
3.4 多特征实验结果
在上述的单特征比较实验中,将相关性样本作为正性或阴性样本使用并不会提升SVM和KR的性能。在本小节实验中,将本文基于多特征组合的事件检测方法的仿真结果与平均晚期融合SVM(SVMlate)、平均晚期融合KR(KRlate)、平均早期融合SVM(SVMearly)、LPBoost融合SVM(SVMLP)和LPBoost融合KR(KRLP)算法进行了比较。利用10个事件的平均Pmiss和平均精度值来衡量检测性能,表2给出了检测性能结果。从中可以看出,本文算法的性能优于其他当前最新多特征组合算法。为了与近期发表文献中的结果做性能比较,我们给出了与采用文献[19]中具有完全实验配置的实验结果。文献[19]在MED数据集中组合了13种类型的图像特征,及2种类型的视频特征,其特征数量是本文的数倍之多。但是文献[19]中10个事件的平均AP值为0.2178,而本文为0.2507。表2基于3个特征的检测性能比较。给出10个事件的平均Pmiss值和平均AP值。Pmiss值越小表明性能越好,AP值越高表明性能越好。

表2 检测性能结果
10个事件的完整名称见3.1节,Pmiss值越小表明性能越好,AP值越高表明性能越好。
最后,图2分别给出了各个事件的性能比较结果。可以看出,本文算法对各个事件的性能最优,在10个事件中的7个事件具有最小Pmiss值和最高AP值。仔细分析其原因可知,这主要是因为本文算法中的有序标签使事件检测器能够区分“高相关性”和“低相关性”,因此提高了事件检测的灵活性和稳健性。另外,它遵守相邻有序标签间的最大容限准则,并为预测值设置不同阈值来更新标签候选,利用了多个特征的信息,因此取得了更好的检测结果。
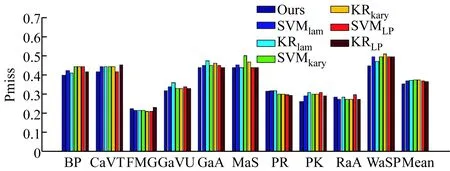
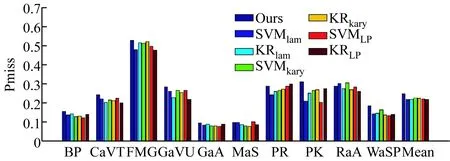
图2 不同算法基于3个特征时的性能比较
4 结 语
本文研究了多特征场景下的复杂事件检测这一棘手问题。采取自适应策略来学习每个相关视频的相关性水平,并将相关性水平看成是有序标签,利用最大容限准则来区分高相关性和低相关性视频。然后将问题描述为标签候选选择问题,生成大量标签候选后在学习阶段选择最为合适的标签。从多特征预测值中选择标签候选,在迭代期间融合新生成的候选,并在标签预测时设置不同阈值。本文方法将相关性水平学习问题嵌入多特征条件中,有效利用了相关性样本包含的信息。利用TRECVID MED 11数据集进行了全面的仿真实验,结果表明本文算法的性能远优于其他当前最新算法,证明了本文算法的有效性。
[1] 李劲菊, 朱 青, 王耀南. 一种复杂背景下运动目标检测与跟踪方法[J]. 仪器仪表学报, 2010 (10): 2242-2247.
[2] Jiang L, Hauptmann A G, Xiang G. Leveraging high-level and low-level features for multimedia event detection[C]//Proceedings of the 20th ACM international conference on Multimedia. Nara, Japan: ACM Press, 2012: 449-458.[3] Ma Z, Yang Y, Sebe N,etal. Multimedia event detection using a classifier-specific intermediate representation[J]. IEEE Transactions on Multimedia, 2013, 15(7): 1628-1637.
[4] Tang K, Fei-Fei L, Koller D. Learning latent temporal structure for complex event detection[C]// 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). RI, USA: IEEE Press, 2012: 1250-1257.
[5] Natarajan P, Wu S, Vitaladevuni S,etal. Multimodal feature fusion for robust event detection in web videos[C]// 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). RI, USA: IEEE Press, 2012: 1298-1305.
[6] Tamrakar A, Ali S, Yu Q,etal. Evaluation of low-level features and their combinations for complex event detection in open source videos[C]// 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). RI, USA : IEEE Press, 2012: 3681-3688.
[7] Natarajan P, Wu S, Vitaladevuni S,etal. Multi-channel shape-flow kernel descriptors for robust video event detection and retrieval[C]// 12th European Conference on Computer Vision(ECCV). Florence, Italy: IEEE Press, 2012: 301-314.
[8] Yang Y, Shah M. Complex events detection using data-driven concepts [C]// 12th European Conference on Computer Vision(ECCV). Florence, Italy: IEEE Press, 2012: 722-735.
[9] Oneata D, Verbeek J, Schmid C. Action and event recognition with Fisher vectors on a compact feature set[C]// 2013 IEEE International Conference on Computer Vision (ICCV). Sydney, Australia: IEEE Press, 2013: 1817-1824.
[10] Ma Z, Yang Y, Cai Y,etal. Knowledge adaptation for ad hoc multimedia event detection with few exemplars[C]//Proceedings of the 20th ACM international conference on Multimedia. Nara, Japan: ACM, 2012: 469-478.
[11] Liu J, McCloskey S, Liu Y. Local expert forest of score fusion for video event classification[M]// 12th European Conference on Computer Vision(ECCV). Florence, Italy: IEEE Press, 2012: 397-410.
[12] Tzelepis C, Gkalelis N, Mezaris V,etal. Improving event detection using related videos and relevance degree support vector machines[C]//Proceedings of the 21st ACM international conference on Multimedia. Barcelona, Spain: ACM Press, 2013: 673-676.
[13] Yang Y, Ma Z, Xu Z,etal. How related exemplars help complex event detection in web videos?[C]// 2013 IEEE International Conference on Computer Vision (ICCV). Sydney, Australia: IEEE Press, 2013: 2104-2111.
[14] Kim M. Accelerated max-margin multiple kernel learning[J]. Applied intelligence, 2013, 38(1): 45-57.
[15] Sun B Y, Li J, Wu D D,etal. Kernel discriminant learning for ordinal regression[J]. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(6): 906-910.
[16] Kim S J, Boyd S. A minimax theorem with applications to machine learning, signal processing, and finance[J]. SIAM Journal on Optimization, 2008, 19(3): 1344-1367.
[17] Wang H, Kläser A, Schmid C,etal. Action recognition by dense trajectories[C]// 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). CO, USA, IEEE Press, 2011: 3169-3176.
[18] Gehler P, Nowozin S. On feature combination for multiclass object classification[C]// 2009 IEEE 12th International Conference on Computer Vision. Kyoto, Japan: IEEE Press, 2009: 221-228.
[19] Tang K, Yao B, Fei-Fei L,etal. Combining the right features for complex event recognition[C]// 2013 IEEE International Conference on Computer Vision (ICCV). Sydney, Australia: IEEE Press, 2013: 2696-2703.
A Complex Event Detection Algorithm Based on Cross-feature Learning
WUJun-fang1,GUOYing2
(1. Wanfang College of Science & Technology, Henan Polytechnic University, Zhengzhou 451400, China; 2. Nanyang Radio and TV University, Nanyang 473036, China)
It is difficult to realize the complex event detection using the relevant samples while multiple features are available. Relevant samples share certain positive elements of the event, but have no uniform pattern due to the huge variance of relevance levels among different relevant samples. The existing detection schemes lack consideration of the correlation between the event features, and weaken the accuracy of event detection. In this paper, an improved algorithm is proposed which adaptively utilizes the relevant samples by cross-feature learning. Firstly, the relevance levels are treated as ordinal labels, and we learn the model with the maximum margin criterion between the consecutive relevance labels from a label candidates set. Then the label weighting problem is formulated based on the multiple kernel learning theory, we update the label candidate set from the prediction of cross-feature. The procedure is repeated until convergence and the final unified detector is used for event detection. We test our algorithm using the large scale TRECVID 2011 dataset, experimental results show that the detection performance of the proposed algorithm is superior to other current algorithms in terms of average accuracy and Pmiss value.
complex event detection; relevant samples; cross-feature learning; label candidates set; average accuracy
2015-11-12
武俊芳(1979-),女,河南西平人,硕士,讲师,主要研究方向:图像处理、云计算。Tel.:13949021815; E-mail:2459325@qq.com
TP 391
A
1006-7167(2016)05-0141-05
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
制造技术与机床(2019年9期)2019-09-10
西南交通大学学报(2018年6期)2018-12-18
车迷(2018年11期)2018-08-30
知识经济·中国直销(2018年8期)2018-08-23
海峡姐妹(2018年3期)2018-05-09
河北遥感(2017年2期)2017-08-07
数学学习与研究(2017年3期)2017-03-09
衡阳师范学院学报(2016年3期)2016-07-10
公民与法治(2016年10期)2016-05-17
