
基于云计算平台的知识库构建方案
2016-12-06 12:54刘利
电脑与电信 2016年8期
刘利
(泸州职业技术学院信息工程系,四川 泸州 646005)
基于云计算平台的知识库构建方案
刘利
(泸州职业技术学院信息工程系,四川 泸州 646005)
当今互联网已成为一个巨大的开放式知识库,其中包含着许多有价值的信息。互联网信息呈现形式多样性的特点,如何初步筛选出有价值的网页,是信息抽取的第一要务,也是构建知识库的基础。本文在建立互联网模型基础上,利用Hadoop平台下的Pagerank算法,旨在研究如何在节省时间和空间基础上筛选出有价值的网页,为从互联网抽取有价值信息构建知识库提供解决方案。
Hadoop;Pagerank;知识库;信息抽取
1 引言
互联网像是一个巨大的知识库,具有信息规模庞大、信息资源多样、信息分散等特点。网页被视为知识库中的单位信息,但这些信息有很强的独立性和自治性。搜索引擎好比是在这个知识库中建立索引,方便用户搜索。用户用主流的搜索引擎比如google和百度搜索某个关键字时,会反馈许多已排序好的网址,排序过程是根据复杂的文本匹配算法和链接分析算法相结合的技术实现的。在用户搜索之前,网页间的等级划分就已通过链接分析算法初步确定,链接分析算法成为评判网页等级和重要性的标准之一。
2 链接分析算法
由互联网信息所具有的特征可知,在扩展网页和超链接规模时,需判断它们的重要性,选取质量和信誉度好的网页。本文采用链接分析方法作为网页重要性的评判标准。
影响搜索引擎的链接排名的一个很重要的因素是链接分析算法。常见的链接分析算法主要有PageRank、HITS、 SALSA、Hilltop等等,这些算法的核心是PageRank[1]和HITS[2],而后面的其他算法都是以它们为基础延伸的。
HITS算法对待排序的网页数量规模要求较小,网页数量规模要求一般为1000至5000个,但由于需要从文本的搜索引擎中获得中心类网页集并以此扩充权威类网页集,这个过程消耗时间较长,而PageRank算法处理的数据数量规模上远远超过了HITS算法。据Google官方介绍[3],目前已经收录了1万亿以上的网页并且规模还在不断扩大,而且PageR-ank算法是在用户查询前就已经在服务器端独立完成的,不会占用用户查询时间,因此从用户体验时间来说其远比HITS要短。
3 PageRank算法
PageRank算法有单机模式和并行运算模式。单机模式运算规模较小,对内存空间要求较大,而本文面向的是上亿的URL链接,鉴于此,选择并行运算模式。通过PageRank算法算出每个网页的等级,等级越高说明网页质量和可信度就越高。决定网页等级的主要因素有:链入数量、链入网页的等级、链出数量。
计算网页的等级就等价于计算网页的PR值。网页的PR值定义为:链入网页(比如A网页)的所有页面的PR值除以各自页面里面链出数量之和。算法如公式1所示:
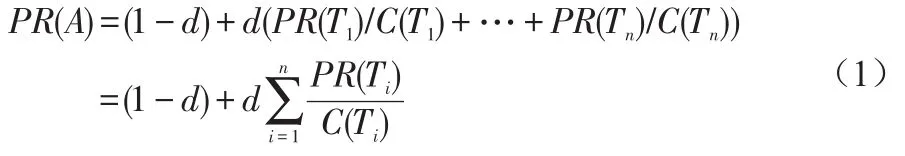
其中,PR(A)表示A页面的等级,PR(Ti)表示Ti页面的等级,Ti页面指向A页面(即Ti链出到A),C(Ti)表示Ti页面的链出总数,d是0到1间的常数,称为阻尼系数。根据Lawrence Page等人给出的值,应用中一般设置为0.85。PR(Ti)/C(Ti)表示页面Ti链到A页面的概率,随着i值的变化,即可算出模型中达到A页面的总概率。根据上述公式进行迭代计算,当算出相邻两次页面的PR值收敛时计算结束,得到的PR值为每个页面最终的PR值。
本文以网页质量好、可信度高为原则对网页为基础,采用网络爬虫的思想,最终收集并整理8亿多的URL,这对整个互联网来说是很小的,若利用现有的方式计算各个URL对
应网页的PR值将导致两级分化,究其原因在于计算过程中,有的网页只有链接入没有链出,这将导致有的PR值将特别大,而有的PR值将特别小,也会导致计算结果的不准确,这有悖于互联网闭环的特点。因此,在计算之前建立互联网模型很有必要,将没有链出的网页,让它的链出指向包括自身在内的每一个网页。
PageRank迭代计算并致收敛后,有些网页的PR值大于1,就可认为该网页等级比平均网页等级高,可视为质量好的网页。
4 实验过程和结果分析
4.1 相关准备
以戴尔PowerEdge R8201的硬件服务器搭建的Hadoop平台,1台master和2台slave。软件安装:JDK版本为jdk-6u31-linux-i586.bin[5];Hadoop版本是hadoop-1.2.1.tar.gz[6]。集群信息如表1所示。

表1 集群信息
4.2 Hadoop配置和运行步骤
(1)将每个服务器都安装JDK、解压Hadoop,并保存和安装在各服务器上的路径相同;
(2)配置各服务器的缓存大小、接口、通信等,需要设置各个服务器上的四个配置文件:core-site.xml、hadoop-env.sh、hdfs-site.xml和mapred-site.xml;
(3)用命令启动Hadoop平台,配置成功后,HDFS的存储能力达到460多个G。
(4)编写Hadoop要求的程序并提交。
4.3 网页和超链的收集整理
为减少在计算时所要求的空间性能,在计算之前先将URL转化为对应的checksum编码[7]。转化URL的保存格式是:URL##checksum,如图1所示。

图1 URL和checksum存储格式
在计算网页PageRank时,输出格式是:checksum PR1 PR2,如图2所示:
图2 PageRank计算结果
在PageRank收敛后,选取PR值大于1的网页,最终整理出网页5000多万的URL,并以此为基础下载网页数据构建知识库。
5 结语
本文描述了一种以互联网为基础的构建知识库的方案,在大规模URL基础上建立互联网模型,通过Hadoop平台的Pagerank算法筛选出有价值的URL,并下载对应网页,方便后续构建知识库的研究提供解决方案。
[1]Page L,Brin S,Motwani R,Windograd T.The Pagerank citation ranking:Bring order to the web.1998.
[2]Kleinberg J.Authoritative sources in a hyperlinked environment.Proceedings of the 9th ACM-SIAM symposium on Discrete Algorithms.New Orleans:ACM Press,1997:668-677.
[3]google官方微博[EB/OL].http://readwrite.com/2008/07/25/ google_hits_one_trillion_pages.
[4]周傲英,曾大聃.Hadoop权威指南(中文版)[M].北京:清华大学出版社.2010.
[5]jdk下载[EB/OL].http://www.oracle.com/technetwork/java/ javase/index.html.
[6]hadoop下载及配置[EB/OL].http://www.apache.org/dist/hadoop/core/.
[7]checksum编码讲解[EB/OL].http://baike.baidu.com/view/ 93743.htm.Knowledge Base Constructing Scheme Based on Cloud Computing Platform
Liu Li
(Luzhou Vocational and Technical College,Luzhou 646005,Sichuan)
The network has become the biggest knowledge base and contains a lot of valuable information.The presentation form of Internet information is diversified.How to discover valuable page is top priority of information extraction and the foundation of building knowledge base.Based on the Internet model,this article researches how to discover valuable pages using Pagerank algorithm in Hadoop platform saving time and space,to provide solutions for knowledge base construction.
Hadoop;Pagerank;knowledge base;information extraction
TP391.1
A
1008-6609(2016)08-0077-02
刘利,男,四川泸州人,硕士,讲师,研究方向:人工智能、数据挖掘。
猜你喜欢
廉政瞭望(2022年19期)2022-11-16
成都信息工程大学学报(2021年6期)2021-02-12
制造技术与机床(2019年6期)2019-06-25
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2017年2期)2017-05-17
中国交通信息化(2016年9期)2016-06-06
图书馆研究(2015年5期)2015-12-07
西南医科大学学报(2014年6期)2014-03-20
读写算·高年级(2009年3期)2009-11-16
