
BW-RAID系统的分布式异步版本识别机制①
2016-12-05 03:13郭明阳董欢庆
高技术通讯 2016年3期
王 慧 郭明阳 董欢庆 许 鲁
(*中国科学院计算技术研究所 北京 100190)(**中国科学院大学 北京 100049)
BW-RAID系统的分布式异步版本识别机制①
王 慧②***郭明阳*董欢庆*许 鲁*
(*中国科学院计算技术研究所 北京 100190)(**中国科学院大学 北京 100049)
为解决BW-RAID系统中数据冗余模式从镜像向RAID4转换时的节点间缓存数据版本识别问题,提出了一种分布式异步版本识别机制。该版本识别机制在镜像卷中的一个逻辑块被更新时,为其生成一个新版本;在冗余模式转换时,通过比较镜像节点间的版本判定某一逻辑块在两个镜像节点缓存的数据是否一致,如果数据一致将其迁移到数据存储卷,否则暂存入镜像节点各自的磁盘缓存以保证系统的冗余一致性。实验表明,该机制在系统正常、降级、故障恢复状态下均能准确、有效识别一致数据;顺序写评测中存储负载小于1%,平均带宽提升最高达25.43%;Open-mail负载重播评测中存储负载低于40%,应用重播结束时写更新数据均完成冗余模式转换,实现了提高空间利用率的目标。
网络RAID, 数据一致性, 分布式异步版本, 泛化时间戳, 版本识别
0 引 言
RAID是廉价磁盘冗余阵列(redundant array of inexpensive disk),是存储系统的基础和关键部件。RAID技术大大提高了存储系统的存储容量、可靠性和性价比。蓝鲸分布式集群BW-RAID(Blue Whale network RAID)[1]采用镜像与纠删码协作的系统架构,其优势在于既能发挥较高的读写性能又节省存储空间。在工业界类似的混合冗余架构被广泛应用,比如,EMC-Isilon[1,2]、Panasas[3]均实现了对小文件使用副本冗余,对大文件使用parity保证可靠性;HDFS-DiskReduce[4]则实现了应用写三副本,异步转为纠删码冗余方式保存。上述系统中混合冗余机制均是文件系统级的实现,BW-RAID则是在通用块层实现了混合冗余。
BW-RAID采用Mirror与RAID4混合的冗余方式容忍单点故障。集群中的存储资源划分为若干冗余组(RAID-set),每个RAID-set实现对数据的冗余存储。一个RAID-set覆盖多个数据卷和一个校验卷,其中包括两类功能节点,即数据存储节点(data node, DN)和校验存储节点(parity node, PN);一个数据卷的写更新数据首先存储在由DN和PN的缓存组成的镜像中,PN的后台线程异步地对冷数据进行集中RAID4计算,并将完成冗余计算的数据存储到DN的数据卷,将校验码更新到PN的校验卷,实现数据冗余模式转换。针对冗余模式转换过程中如何解决镜像中的缓存数据一致性问题,本文提出了一种分布式异步版本识别机制,以保证冗余组一致。
1 背 景
RAID-set的最小宽度为2,包括两个数据卷和一个校验卷,覆盖两个DN节点和一个PN节点,布局见图 1(a)。为减少不必要的网络数据传输和磁盘IO,RAID-set在进行冗余模式转换时PN冗余计算和DN数据迁移均引用各自缓存中的数据副本,但此时正在进行转换的逻辑块在DN与PN缓存中的数据对象若不一致将导致RAID4的数据与校验不一致,即影响RAID-set的冗余一致性。然而在分布式环境中由于存在网络延迟、节点间独立请求调度等因素,互为镜像的缓存中数据不一致的现象难以避免。比如图1(b)所示情形,DV1中的逻辑块B在DN1缓存中已更新为[B:V2],然而远程写被阻塞,PN缓存中仍为[B:V1],此时若对逻辑块B进行冗余模式转换导致RAID4不一致。因此缓存数据一致性感知(或数据对象一致性识别)是保证冗余一致性的关键。解决数据对象一致性识别问题的常用方法有以下几种:
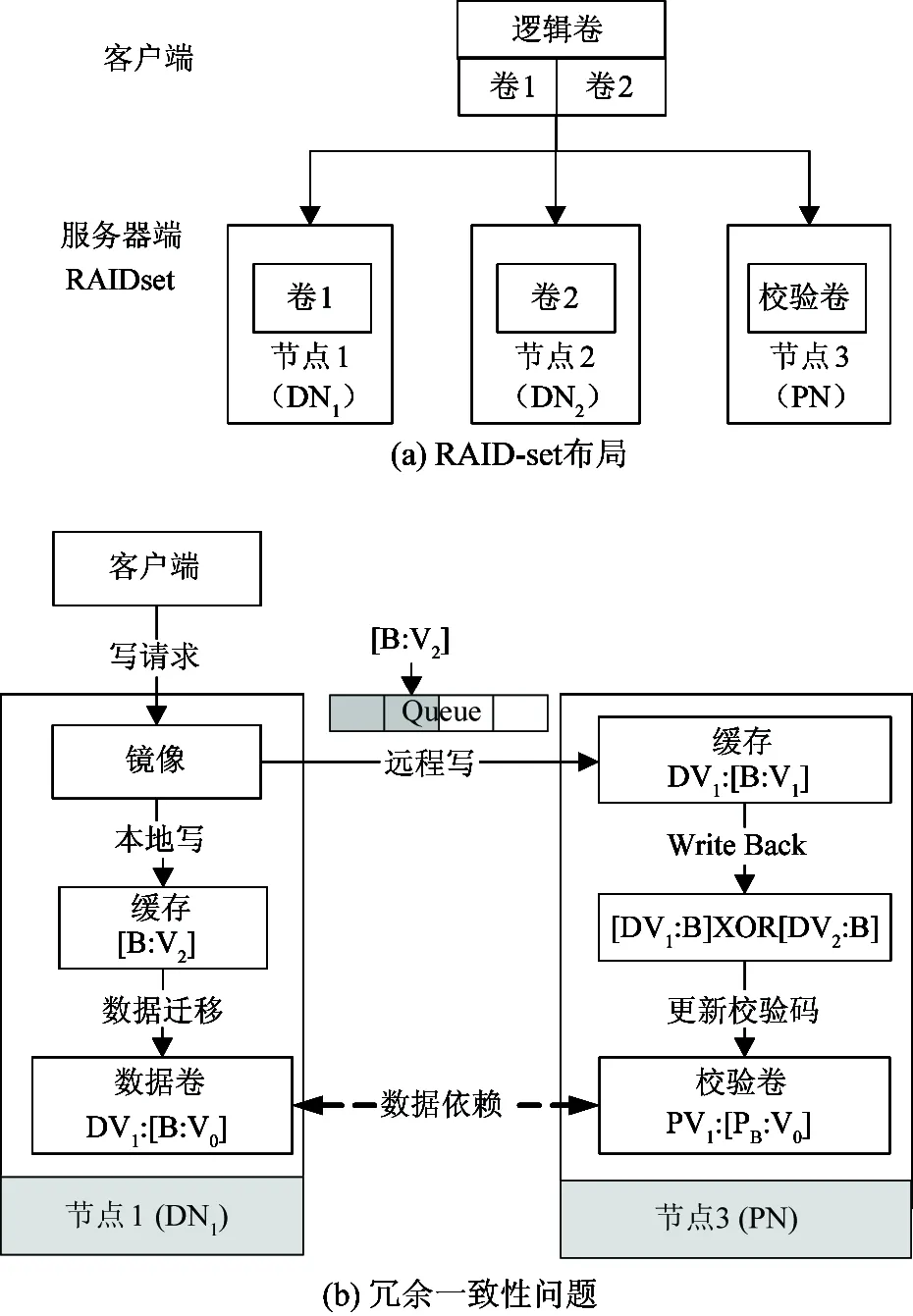
图1 RAID-set结构及冗余一致性问题
(1) 内存字符比较: Linux系统中的cmp工具、CMSD系统[5]等使用此方法比较数据一致性,该方法的不足是,将数据加载到内存增加了磁盘IO,在分布式环境中需要将数据传输到执行比较的节点又有网络开销。
(2) 数据指纹比较:采用SHA-1、MD-5等算法计算数据对象的数据指纹,使用数据指纹索引数据内容,可以实现一致性确定,比如文件系统中的冗余数据识别[6-14]、内存寻址系统[15]、版本管理系统GIT[16]等均使用该方法,其优点是精确度高,但是数据指纹计算的时间开销、维护的空间开销都较高。
(3) 数据版本识别:(a)物理时间戳,通过比较数据对象产生的物理时间戳识别其一致性,其优点是时间由操作系统维护的,无需单独的模块支持,该方法在理论上可行,然而在分布式环境中要求各节点的时间须完全同步,难以实现;(b)逻辑时间版本,其本质是请求序列号,通过比较版本判断数据更新发生的序列关系确定一致性,该方法可以不依赖于物理时间。比如版本管理系统SVN[17],使用自增量作为其版本,Lamport timestamp[18]通过记录更新操作发生的偏序关系判断节点间的数据更新一致性,Dynamo[19]采用了该类算法解决并发访问中的数据一致性问题。逻辑时间版本方式易于实现,其最显著的特点是节点间数据同步时需要同时同步其版本号,目前通用块层成熟的传输协议(如Iscsi)不支持该功能。(c)物理时间与逻辑时间结合的版本,每隔固定时间更新并同步节点间的全局逻辑时间,各节点在全局逻辑版本为基础独立更新本地逻辑时间,该方法允许节点间存在合理的时钟偏移,这可以降低时钟同步开销,并且逻辑时间同步及更新与数据同步可以解耦,WACE[20]使用了该方法解决缓存集群中的缓存一致性问题。
上述方法难以满足BW-RAID对数据对象一致性识别的要求,为此,本文提出了一种分布式异步版本识别机制解决该问题,该版本机制支持物理时间与逻辑时间结合的实现方式。
2 分布式异步版本识别
2.1 概念
主节点(master serving node, MSN):缓存镜像中接收客户端请求的存储节点,正常情况下默认是数据节点(DN)。
从节点(slave serving node, SSN):缓存镜像中接收镜像写请求的存储节点,正常状态下默认是校验节点(PN)。
关联请求:主节点写请求和从节点与之对应的镜像写请求为一对关联请求。
2.2 基于精确时间的版本识别
2.2.1 精确时间版本定义
假设系统开始运行时主、从节点时间同步,主节点串行的接收对一个数据卷中同一逻辑块地址的写更新。我们对同一逻辑地址的写请求按发生次序使用自然数编号,主、从节点的请求分别表示为Qi(i=1,2,3,…), qj(j=1,2,3,…)。
根据同步镜像特点则有:
推论1:主节点写请求Qi与从节点访问相同地址的写请求qj为关联请求的充要条件是i=j。
识别关联请求的关键是探寻i=j的充分条件。由数理逻辑可知:
i=j⟺i+1>j&&j+1>i
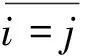
(1)
只需要探寻i+1≤j‖j+1≤i的必要条件。由此结合访问某逻辑地址的当前写请求与其后继写请求的时间属性,我们给出了写请求版本定义,该版本同样是写请求所包含数据对象的版本。
定义1:存储节点上一个逻辑数据卷中的任意逻辑块B,在当前节点对其数据进行更新的写请求Qi的版本表示为
(1) Ai:Qi在当前节点发生的精确系统时间;
(2) Ci:Qi在当前节点完成的精确系统时间;
(3) Ai+1:写请求Qi+1在当前节点发生的精确系统时间。
2.2.2 精确时间版本识别
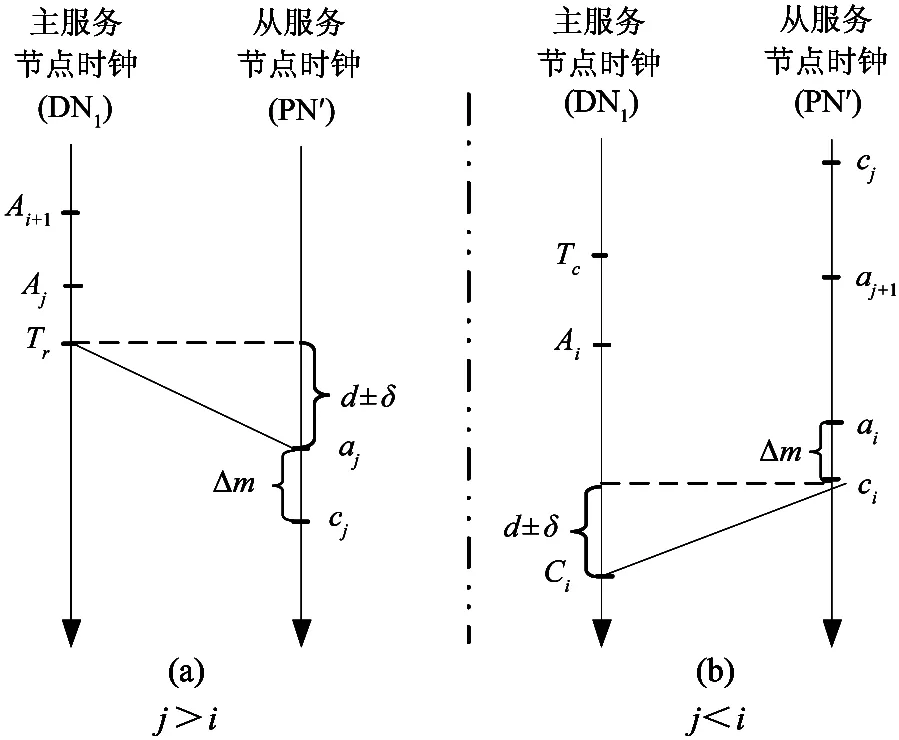
假设主、从节点访问相同逻辑块B的任意两个写请求,Qi:<(Ai,Ci,Ai+1>, qj:< aj,cj,aj+1>,我们以Qi与qj为参照论证关联请求版本识别方法。论证分为三步:论证i+1≤j的必要条件;论证j+1≤i的必要条件;论证i=j的充分条件。
(1) i+1≤j的必要条件:
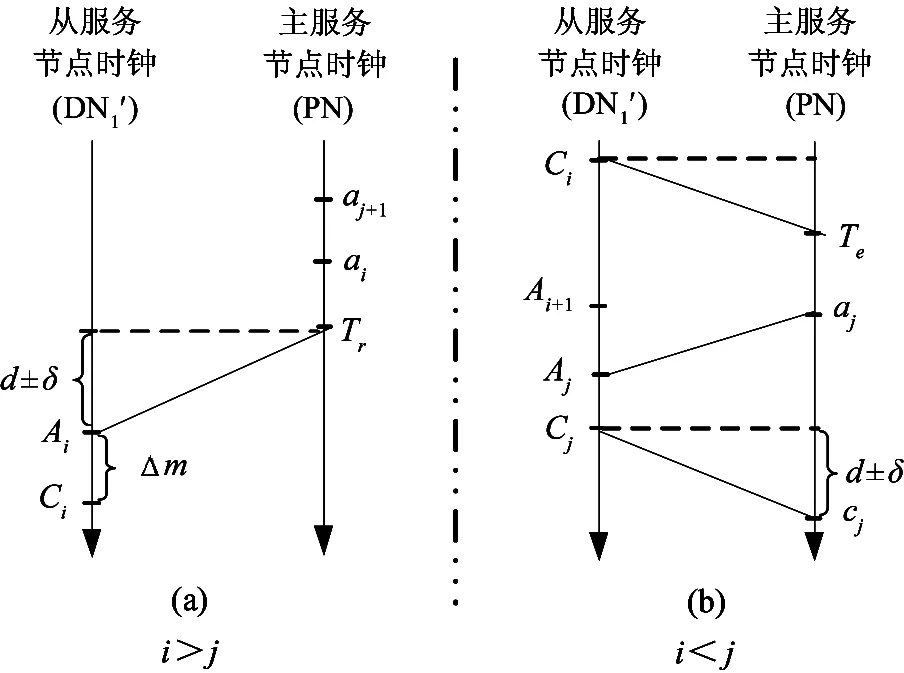
i+1≤j时,Qi+1,Qj,qj在主、从节点的逻辑时序如图 2(a)。参数说明:[d]为网络传输延迟;[δ]为DN与PN当前时钟误差;[Δm]为写缓存时间。
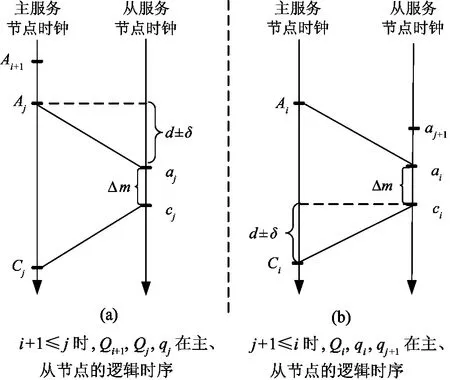
图2 关联请求逻辑时序
由时序图可得推导式:
(2)
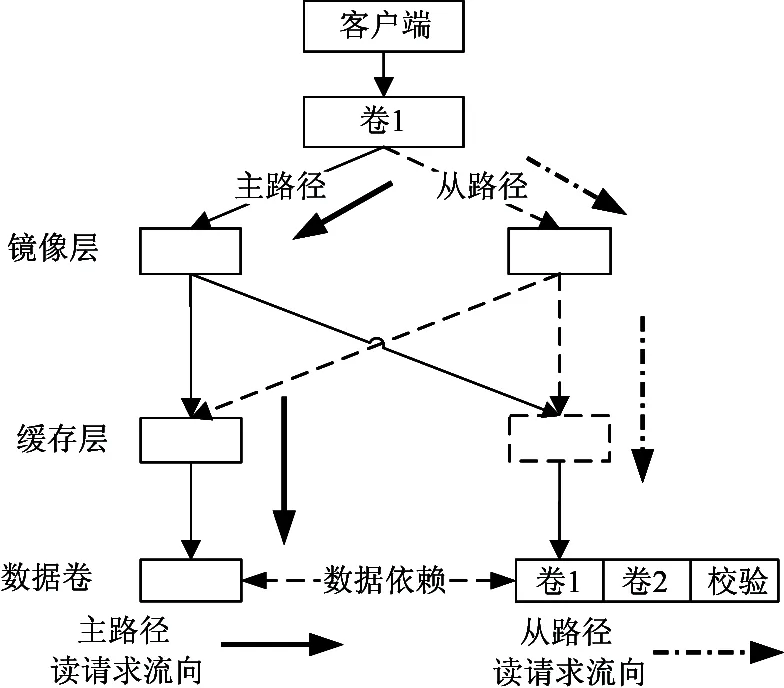
即 Ai+1 (2) j+1≤i的必要条件: j+1≤i时,Qi,qi,qj+1在主、从节点的逻辑时序如图 2(b),则有推导式: (3) 即aj+1 由式(1)、(2)得推导式: (i+1≤j)‖(j+1≤i)⟹(Ai+1 (aj+1 (4) 即(Ai+1 (3) i=j的充分条件: 式(4)的逆否命题成立,即有 (j+1)>i⟺i=j (5) 由此得:定理1:(Ai+1≥cj+δ)&&(aj+1≥Ci+δ)⟹i=j □ 证毕。 2.2.3 节点故障恢复 首先,定理1的前提是一个数据卷中同一逻辑地址的写请求串行地进入存储节点,通过调研dm-raid1、md-raid1等常用的镜像实现方式,我们发现在镜像恢复过程中会阻塞对正在恢复的逻辑地址的应用写更新,直到该逻辑地址恢复完成,即对于同一逻辑地址数据恢复请求与应用写请求是串行的。其次,镜像恢复时将恢复窗口内地址的最新版本数据同步到接替节点。最后,新节点接入后集群恢复以RAID-set为单元并发执行。我们以一个RAID-set中的数据节点恢复和校验节点恢复为例分别论证。 (1) 数据节点恢复 证明: (6) 上述推导式结合时序图可得: (7) 2) DN′1的恢复数据不会误判为PN的任意新版本数据(即i i (8) 3) 结论:综合DN恢复时的两种情况则有i≠j⟺i 证毕。□ 图3 DN′恢复的请求时序图 (2) 校验节点恢复 假设RAID-set中PN故障(见图 1),接替节点为PN′,恢复开始是PN′与两个DN时钟均同步;DV1卷中的任意逻辑块B,在DN1有写请求Qi: 证明: 1) PN′的恢复数据不会误判为DN1的任意旧版本数据(即j>i)。 假设DN1在Tr时刻恢复逻辑块B数据到PN′,PN′的恢复请求qj: Ai+1≤Aj ⟹Ai+1 ⟹Ai+1 (9) 即有j>i⟹Ai+1 2) PN′的恢复数据不会误判为DN1的任意新版本数据(即j 根据镜像恢复逻辑在逻辑块B恢复时刻DN1的最新更新对应Qj,而Qi为恢复完成后到达的某一应用写请求,逻辑时序见图4(b),有推导式: aj+1≤ai(∵j ⟹aj+1≤ci-Δm(∵ai=ci-Δm) ⟹aj+1≤Ci-Δm-d∓δ(∵ci=Ci-d∓δ) ⟹aj+1 (10) 图4 PN节点恢复请求时序图 即有j 3) 结论:综合PN恢复时的两种情景则有i≠j⟺i 证毕。□ (3) 结论 综合集群故障恢复时RAID-set中DN恢复与PN恢复两种情况,对于任意两个数据对象不一致的恢复写请求与应用写请求均满足推导式: i≠j⟺i (11) 由此证明集群恢复过程中新节点的镜像恢复请求不会误判为正常服务节点的任一不相关联的写请求。进而根据数理逻辑则可知集群恢复状态下定理1同样成立。 2.3 应用局限性 定理1表明通过比较镜像节点间请求的精确物理时间戳来识别关联请求的方法理论上可行,实际应用中仍存在以下局限性: 局限1:保证数据与版本一致须将数据更新与版本更新绑定,当缓存数据合并时,精确物理时间版本合并违背定义1语义。 局限2:定义1与定理1依赖于后继应用写请求到达的精确物理时间,因而版本识别须在后继写请求发生之后进行,否则请求版本不完整。 针对上述两方面局限性,本文提出了泛化时间戳版本理论。 2.4 基于泛化时间戳的版本机制 2.4.1 泛化时间戳版本定义 2.4.2 泛化时间戳版本识别 证明: 假设Qi, qj的精确物理时间属性分别为(Ai, Ci, Ai+1),(aj, cj, aj+1),由定义2,则有 因此有 证毕。□ 2.5 应用局限性解决 2.5.1 版本合并方法 基于定义2提出了版本合并方法解决局限1,使得存储层数据合并时,新旧版本同时合并。版本合并须保证定理2适用,须满足两个条件: (1) 合并后版本是新数据的合法泛化时间版本,即符合定义2语义。 (2) Ai对应同一逻辑块写请求Qi-1的后继写请求的泛化发生时间。 版本合并方法:假设任意逻辑块B当前版本为 证明: 假设两个待合并的泛化时间版本对应的精确时间版本分别为 版本合并前,Ai是Qi-1后继写请求的泛化发生时间,每次版本合并均保留Ai,即新版本可以保证当前版本中请求到达时间为Qi-1的后继写请求的泛化到达时间。 因此新版本符合定理2适用的两个条件。 证毕。□ 2.5.2 后继写请求时间扩展 推理1:假设任意逻辑块B的某一版本 证明: 假设Qi+1发生的精确时间为Anext(Anext或趋于∞),则有Ai+1≤Anext,因此Ai+1时间符合定义2语义,即该版本合法且定理2适用。 证毕。□ 2.6 小 结 论证结果表明,利用物理时间戳版本解决BW-RAID中镜像节点间的数据版本识别问题是理论可行的,通过对物理时间戳做泛化扩展可以满足实际系统的需求,基于此形成了基于泛化时间戳的分布式异步版本识别机制。该版本机制优点是:(1)易于实现,不需要冗余组内的节点时间保持完全同步,允许节点间存在合理的时间误差,时间同步难度和开销降低。(2)时间复杂度低,其实现的时间复杂度主要是版本生成及更新时检索版本项的时间消耗,本文的原型系统中将使用基树(Radix tree)管理版本项,查找操作的时间复杂度为O(h),h为基树高度,在64位x86平台的Linux操作系统中基树最大高度仅为16。 3.1 原型系统实现 本文以BW-RAID原型系统为基础,实现了版本子系统,该系统包括四个功能模块:(1)组内全局版本管理模块,定时更新全局逻辑版本号,并向组内各成员同步全局版本;(2)本地系统版本更新模块,接收并更新全局逻辑版本号,定时更新本地版本序列号,将全局版本与逻辑版本组合产生节点当前系统版本;(3)请求版本生成及更新模块,写请求到达节点时为其生成版本,对于已存在旧版本的逻辑块,执行版本合并;(4)版本识别模块,锁定待比较逻辑块版本,并执行版本比较;该模块包含inline和offline两个版本识别线程;inline线程在校验节点执行冗余计算时与数据卷对应的数据节点交换版本,并进行对应逻辑块的版本识别;offline线程对冗余计算时写入PN暂存的逻辑块进行后台识别。 BW-RAID系统中引入分布式异步版本识别机制使得RAID-set冗余模式转换可以与应用数据更新异步。冗余模式转换过程是先更新校验码,然后同时对即将转换的逻辑块进行版本比较,若版本一致则将DN缓存中的数据迁移到数据存储卷;若版本不一致PN的数据暂存入本节点磁盘缓存中,监测到一致版本后DN再进行数据迁移,并释放在PN占用的磁盘缓存资源。 本文对配置分布式异步版本识别机制的BW-RAID原型系统进行了评测。测试环境包括一个客户端和三个存储节点,节点物理配置见表 1。本文在三个存储节点上搭建了只有一个RAID-set的简易集群,在客户端为每个数据卷配置主、从访问路径,可以分别通过DN和PN读写数据,默认主路径为活跃路径;客户端节点作为组内时钟服务器。 表1 硬件环境配置 3.2 数据可用性验证 数据正确性是指BW-RAID系统中配置分布式异步版本识别机制后,客户端写入逻辑卷的数据与从该卷读出的数据须一致,即可用性。综合RAID-set的状态,可用性包括三方面:(1)客户端写入到存储端的数据可用;(2)数据节点故障时数据可用;(3)节点故障恢复完成后,恢复到新节点的数据可用。 测试方法:客户端将逻辑卷格式化为ext3文件系统并挂载,复制2GB大小的文件和1.5GB大小的目录(包含3个子目录)到挂载目录;分别通过主路径(master path)和从路径(slave path)访问存储节点,计算复制文件与源文件的md5校验值,对比一致性,执行diff操作对比复制目录与源目录的一致性。通过主、从路径读RAID-set中数据卷的请求流向见图 5。 图5 读请求流向 综合数据可用性所涉及的三方面,进行以下测试: (1) 冗余组正常状态下,从DV1、DV2各自主路径读取数据,比较一致性; (2) DN1故障,由DV1卷从路径读取数据,比较一致性; (3) DN1故障恢复完成后,由DV1主路径读取数据,比较一致性; (4) PN故障恢复完成后,将DV2或者DV1的访问路径切换到从路径读取数据,比较一致性。 对于上述4种测试,复制文件、目录与源文件、目录均一致,说明异步版本机制可以保证数据可用性,进而达到保证冗余组一致性的目标。 3.3 有效性验证 有效性评价测试使用基准测试工具FIO进行存储压力测试和应用负载重播。存储系统参数配置见表2。 表2 系统参数 本节评测中以sync模式的BW-RAID作为对比基准,其特点是冗余模式时阻塞写IO保证节点间缓存同步以解决一致性问题,具体过程是:首先阻塞客户端对逻辑块B所在条带的写更新,并等待该条带上所有写更新完成;然后计算、更新RAID4校验码,并进行数据迁移。 3.3.1 存储压力评测 存储压力评测,在逻辑卷上执行指定请求粒度的顺序写测试。测试分别在sync和async两种模式的BW-RAID中进行,评价指标为校验节点的IO负载开销和系统吞吐量。 (1) 测试方法:在客户端以direct方式向逻辑卷顺序写入128GB数据,每5秒记录一次带宽作为实时带宽。分别对4kB、64kB、1024kB三种请求粒度进行测试对比。sync模式在校验存储节点不产生IO开销,只记录带宽;对async模式,同时记录校验节点冗余模式转换时写本地磁盘缓存的IO数量,及版本比较时锁定版本导致阻塞的IO数量。 校验节点IO负载(图6)的结果表明:(1)三种粒度的顺序写测试中版本识别率均高于99%,最高达99.69%;(2)由于inline线程中版本比较不一致在PN产生的IO开销为0.31%~0.85%;async模式下4kB粒度用例中不一致版本比例最高,原因在于缓存资源管理粒度是64kB,同一缓存块被多次更新,多次被回写,导致DN与PN缓存的数据在某些时刻存在不一致的情况。其它两个用例中每个缓存块被写一次,即只有一个版本,此时不一致版本属于漏判。冗余计算过程中inline线程不能识别的版本转入后台识别模式,三个用例的结果显示不一致数据对象均完成版本识别,迁移到了共享数据卷,在PN所占用的磁盘缓存资源也释放。由此可以得出分布式异步版本识别机制在顺序写应用中可以通过版本识别实现识别一致数据对象的目标。 图6 校验节点IO负载 (2)结果分析: (1)4kB粒度用例,两种模式实时带宽接近, async模式平均带宽比sync模式下降2.70%,其原因是资源管理粒度为64kB,async模式下存储节点最多16个请求竞争同一逻辑块版本执行版本合并操作,因此带宽略有降低(图7)。 图7 4kB实时带宽 (2)64kB粒度用例,async实时带宽明显优于sync模式,平均带宽提升25.43%,校验存储节点IO负载仅增加0.31%(图8)。 图8 64kB实时带宽 (3)1024kB粒度用例,async模式实时带宽抖动明显,峰值带宽高于sync模式,通过分析我们发现此时因版本比较而阻塞的请求数量明显上升,分别是4kB和64kB的14倍和17倍,阻塞请求增加导致系统吞吐量不稳定(图9)。 图9 1024kB实时带宽 顺序写平均带宽对比见表3 表3 顺序写对比 3.3.2 应用负载重播评测 应用负载重播,在async模式下重播应用trace验证版本识别机制的有效性,评测指标:(1)inline线程与offline线程结合是否可以识别所有版本;(2)inline线程识别的版本比例及校验存储节点数据小盘IO负载。 测试方法:在async模式下重播open-mail应用中写请求比例高于50%的1#-3#trace,三个trace中小于8kB的写请求均比例均高于90%,故在本小节中选取了4kB的资源管理粒度。 结果表明三个trace重播完成后,所有数据均完成冗余模式转换,即随着测试的进行版本均可以识别。上述三个应用中inline线程不能识别的版本接近40%,那么相对于sync模式PN平均约增加了40%的IO负载(图10)。 图10 校验节点IO负载 根据本文版本识别理论,同一逻辑块重复被写,并且每次写间隔小于系统设置的最小可识别间隔是导致版本不可识别的主要原因。对此我们也分别分析了三个trace的覆盖写请求比例及对同一逻辑块覆盖写时间间隔(见表 4)。 表4 覆盖写比例 三个trace中均有55%以上的逻辑块被重复写,并且覆盖写请求比例均高于80%。然而重复写请求间隔小于配置的可识别间隔(5ms)的比例仅在10%左右,评测结果与应用特点不完全相符。原因在于本文使用了基准测试工具FIO重播,其特点是仅按照请求原有序列模拟IO,并不考虑原有请求实际到达的相对时间,即忽略了应用原有请求时间属性。应用重复写比例高,请求间隔被忽略导致不可识别的版本比例升高。 本文针对BW-RAID异步冗余计算面临的冗余一致性问题,以WACE为研究基础提出了一种分布式节点数据版本识别方法,该方法以泛化分布式时间戳思想为基础实现了分布式镜像节点中同一逻辑块的数据对象一致性比较,其主要特点是:(1)可以转换为物理时间与逻辑时间结合的版本实现方式;(2)组内每个节点可以独立维护本节点系统版本且系统版本更新与IO解耦合,组内节点间版本传递开销降低,适用于Iscsi等通用块层传输协议;(3)可以通过比较版本确定逻辑块(或请求)所包含数据是否相同,满足BW-RAID冗余模式转换对数据一致性识别的要求。实验表明,该方法可以有效识别镜像关联请求,降低组内网络开销。 然而应用负载评测表明在覆盖写密集的应用中校验节点IO开销明显增大,同时随着系统数据容量增大维护版本产生的资源开销也随之增加,对于提高版本识别比例、降低版本维护资源开销等问题需要做进一步的研究及验证。 [1] 那文武, 柯剑, 朱旭东等. BW-netRAID: 一种后端集中冗余管理的网络RAID系统. 计算机学报, 2011, 34(5): 912-923 [2] Noble M. EMC Isilon OneFS-A Technical Overview . http://www.emc.com/collateral/hardware/white-papers/: EMC Corporation. 2012 [3] Welch B, Unangst M, Abbasi Z, et al. Scalable performance of the Panasas parallel file system. In: Proceedings of the 6th USENIX Conference on File and Storage Technologies, Berkeley, USA, 2008. 17-33 [4] Fan, B, Tantisiriroj W, Lin X, et al. DiskReduce: RAID for data-intensive scalable computing. In: Proceedings of the 4th Annual Workshop on Petascale Data Storage, New York, USA, 2009. 6-10 [5] 李玮玮.BW-RAID系统中数据版本管理的研究: [硕士学位论文].北京:中国科学院计算技术研究所,2011. 9-40 [6] Kulkarni P, Douglis F, LaVoie J, et al. Tracey. Redundancy elimination within large collections of files. In: Proceedings of the General Track:2004 USENIX Annual Technical Conference, Boston, USA, 2004. 59-72 [7] Policroniades C, Pratt I. Alternatives for detecting redundancy in storage systems data. In: Proceedings of the General Track:2004 USENIX Annual Technical Conference, Boston, USA, 2004. 73-86 [8] Jain N, Dahlin M, Tewari R. TAPER: Tiered approach for eliminating redundancy in replica synchronization. In: Proceedings of the 4th USENIX Conference on File and Storage Technologies, San Francisco, USA, 2005. 281-294 [9] Zhu B, Li K, Patterson H. Avoiding the disk bottleneck in the data domain deduplication file system. In: Proceedings of the 6th USENIX FAST, San Jose, USA, 2008. 69-282 [10] Koller R, Rangaswami R. I/O deduplication: utilizing content similarity to improve I/O performance. In: Proceedings of the 8th USENIX Conference on File and Storage Technologies, San Jose, USA, 2010. 211-224 [11] Ungureanu C, Atkin B, Aranya A, et al. HydraFS: a high-throughput file system for the HYDRAstor content-addressable storage system. In: Proceedings of the 8th USENIX Conference on File and Storage Technologies, San Jose, USA, 2010. 225-238 [12] Kruus E, Ungureanu C, Dubnicki C. Bimodal content defined chunking for backup streams. In: Proceedings of the 8th USENIX Conference on File and Storage Technologies, San Jose, USA, 2010. 239-252 [13] Srinivasan K, Bisson T, Goodson G, et al. iDedup: latency-aware, inline data deduplication for primary storage. In: Proceedings of the 10th USENIX Conference on File and Storage Technologies, San Jose, USA, 2012. 299-312 [14] Lillibridge M, Eshghi K, Bhagwat D. Improving restore speed for backup systems that use inline chunk-based deduplication. In: Proceedings of the 11th USENIX Conference on File and Storage Technologies, San Jose, USA, 2013.183-198 [15] Strzelczak P, Adamczyk E, Herman-Izycka U, et al. Concurrent deletion in a distributed content-addressable storage system with global deduplication. In: Proceedings of the 11th USENIX Conference on File and Storage Technologies, San Jose, USA, 2013. 161-174 [16] Scott C, Liu H. Sgit community book. http: //gitbook. liuhui998.com: Git Community. 2011 [17] Ben C S, Brian W, Fitzpatrick C. Michael Pilato. Svn-book. http://svnbook. red-bean.com:Creative Commons, 2008 [18] Lamport L. Time, clocks, and the ordering of events in a distributed system.CommunicationsoftheACM, 1978,21(7): 558-565 [19] DeCandia G, Hastorun D, Jampani M, et al. Dynamo: amazon’s highly available key-value Store. In: Proceedings of the 21st ACM Symposium on Operating Systems Principles, Stevenson, USA, 2007. 205-220 [20] 司承祥.集中共享存储环境中缓存集群的关键技术研究:[博士学位论文]. 北京:中国科学院计算技术所,2011. 25-28 Distributed and asynchronous version identification mechanism for BW-RAID system Wang Hui***, Guo Mingyang*, Dong Huanqing*, Xu Lu* (*Institute of Computing Technology, Chinese Academy of Science, Beijing 100190)(**University of Chinese Academy of Sciences, Beijing 100049) To solve the BW-RAID system’s problem of cache data version identification during its data redundant mode conversion from mirror to RAID4, a distributed and asynchronous version identification mechanism is presented. This version identification mechanism generates a new version for a logical block in a mirrored volume when its data are updated, and during the redundant mode conversion, checks whether this logic block’s data cached in two mirroring notes are consistent by comparing the versions between mirroring nodes, and if consistent, makes the data move to the data volume, otherwise stores them to disk caches temporarily to guarantee system redundant consistency. It was proved by experiments that the mechanism can identify consistent data for all blocks in any state, including normal, degraded, and recovery states. The sequential writing tests showed it improved the average bandwidth up to 25.43% with the storage overhead less than 1% compared to cache synchronization mode. The open-mail workloads replay tests showed, the storage loads were less than 40%, and the blocks updated finished redundant conversion as each workload replay ended. The proposed mechanism is essential to guaranteeing redundant consistency while improving storage space utilization in BW-RAID. network RAID, data consistency, distributed and asynchronous version, time-interval-based timestamp, version identification 10.3772/j.issn.1002-0470.2016.03.003 ①863计划(2013AA013205)和中国科学院重点部署课题(KGZD-EW-103-5(7))资助项目。 2015-10-20) ②女,1981年生,博士生;研究方向:网络存储和分布式系统冗余一致性;联系人,E-mail: wanghui@nrchpc.ac.cn(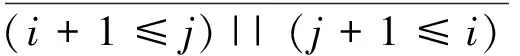
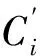
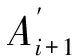
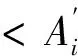
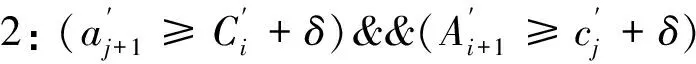
3 原型实现及评测


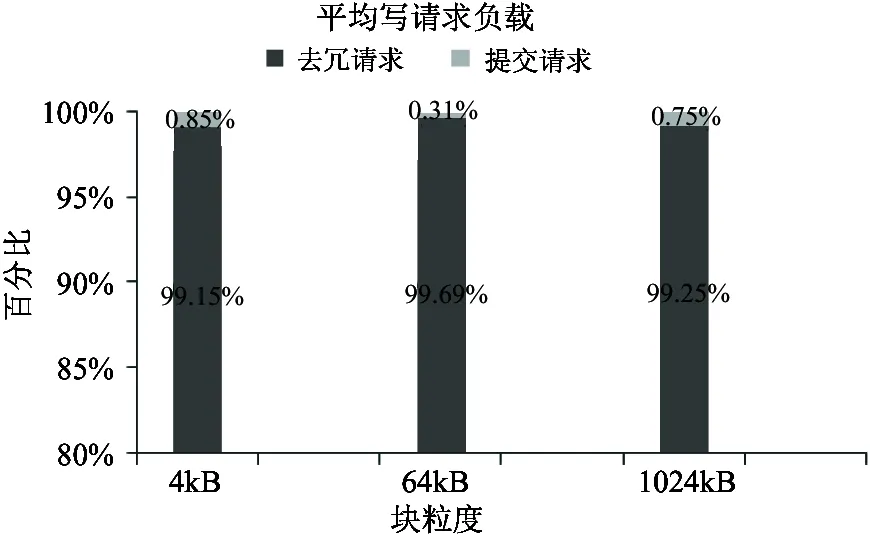
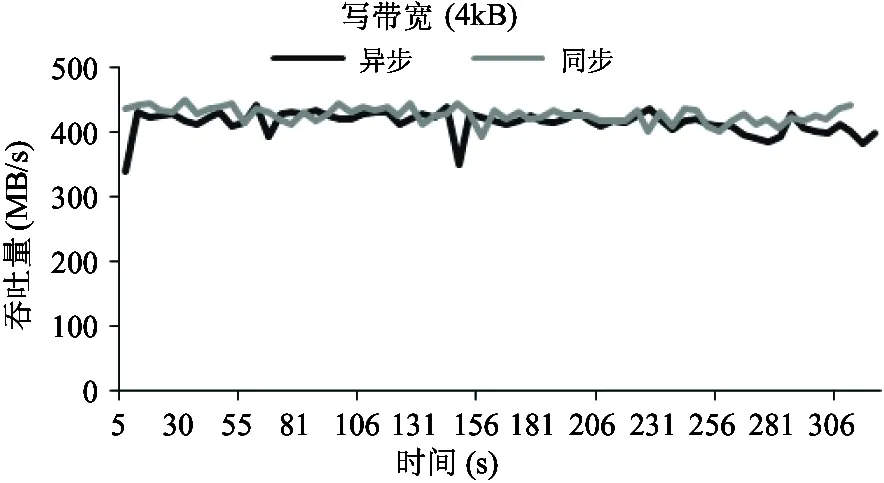
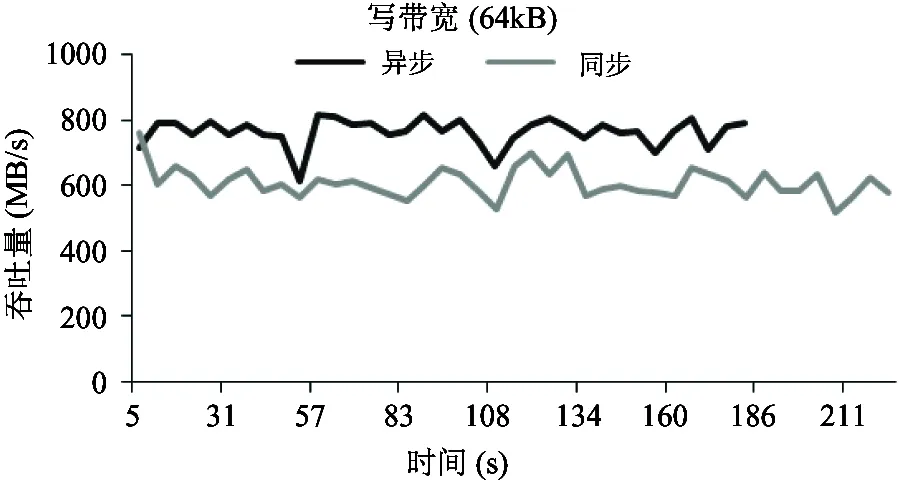
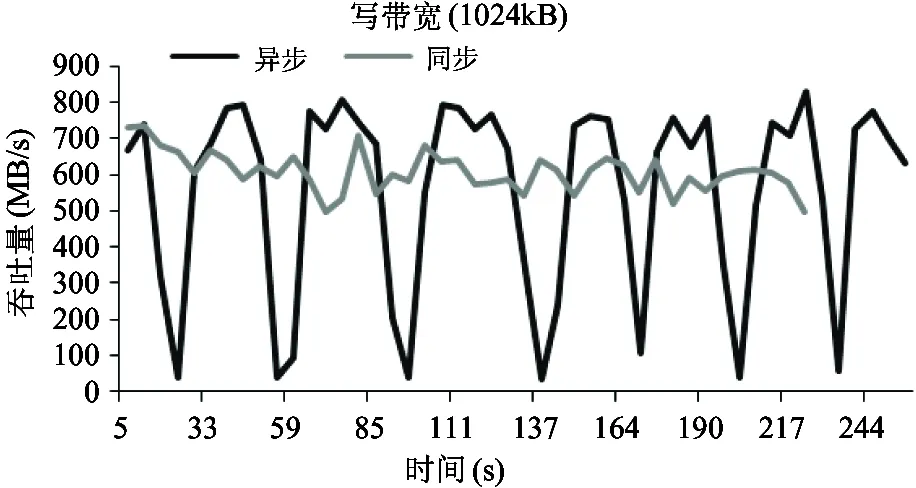
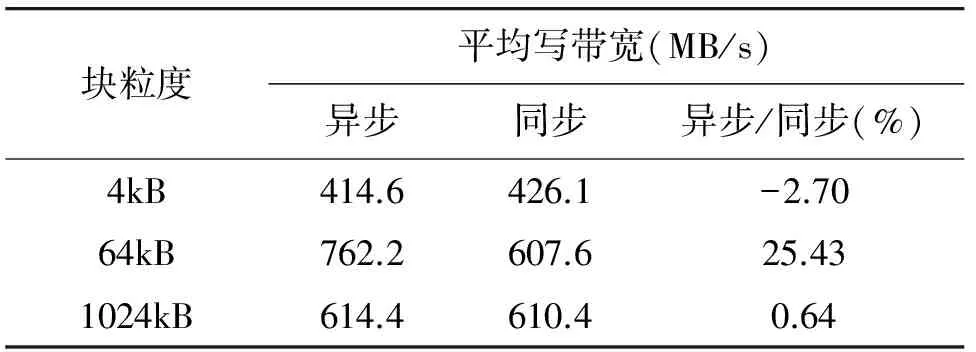
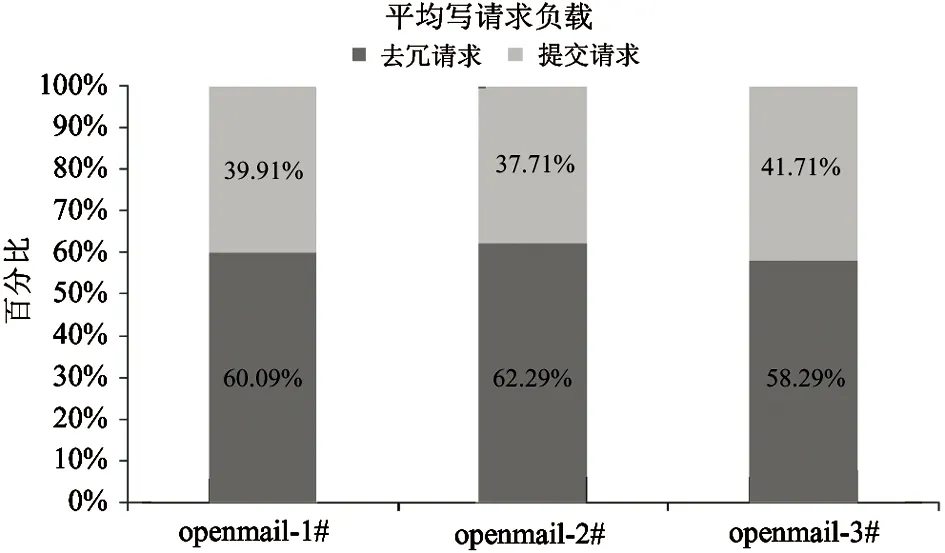
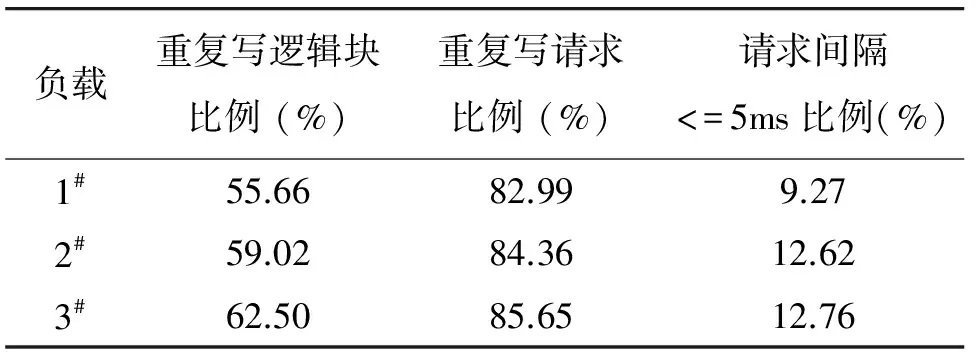
4 结 论
猜你喜欢
公民与法治(2022年5期)2022-07-29教学考试(高考物理)(2021年5期)2021-11-08中医眼耳鼻喉杂志(2021年1期)2021-07-22当代党员(2020年20期)2020-11-06小康(2018年23期)2018-08-23中国铸造装备与技术(2017年6期)2018-01-22网络安全和信息化(2016年9期)2016-11-26网络安全和信息化(2016年11期)2016-11-26燕山大学学报(2015年4期)2015-12-25小康(2015年4期)2015-03-31
