
大数据环境下基于模糊匹配的审计方法
2016-12-02 02:32陈伟
中国注册会计师 2016年11期
陈 伟
大数据环境下基于模糊匹配的审计方法
陈伟
随着大数据时代的到来,电子数据审计的研究与应用成为审计领域的热点问题。本文首先分析了大数据环境下开展电子数据审计的重要性以及电子数据审计的原理。在此基础上,针对大数据环境下电子数据审计的需要,提出了一种基于模糊匹配的审计方法,并分析了该方法的原理。最后,借助于自主研发的电子数据审计模拟实验室软件,以某税收数据审计为例,分析了该方法的应用。
大数据电子数据审计模糊匹配审计风险审计软件
一、引言
随着信息技术的发展,大数据(Big data)时代的到来为电子数据审计提供了机遇和挑战。2015年8月31日,国务院印发《促进大数据发展行动纲要》。2015年12月8日,中共中央办公厅、国务院办公厅印发了《关于实行审计全覆盖的实施意见》等文件,该文件指出,对公共资金、国有资产、国有资源和领导干部履行经济责任情况实行审计全覆盖,是党中央、国务院对审计工作提出的明确要求。其中,创新审计技术方法是实现审计全覆盖的一个重要手段,要求构建大数据审计工作模式,提高审计能力、质量和效率,扩大审计监督的广度和深度。国际审计机关也高度关注大数据环境下的审计方法创新,2016年6月24日,金砖国家最高审计机关领导人会议在北京召开,会上指出:金砖国家最高审计机关应适应国家治理发展变化需要,加强顶层设计和战略规划,以审计方式方法创新,提升审计效能,更好发挥审计作用。在审计技术方法上,加强大数据技术运用,积极应用“云计算”、数据挖掘、智能分析等新兴技术,提高审计效率和质量。
国内外学术界也高度关注大数据在审计中的应用,AICPA(2014)初步分析了大数据环境对审计工作的影响;Earley(2015)分析了大数据技术给审计工作带来的机遇和挑战。笔者分析了大数据环境下电子数据审计的机遇、挑战与方法(陈伟,2016)。
综上所述,研究大数据环境下的电子数据审计问题具有重要的理论意义和应用价值。本文结合目前大数据的研究与应用现状,研究了大数据环境下基于模糊匹配的电子数据审计方法。
二、大数据环境下基于模糊匹配的审计方法的原理分析
(一)大数据概述
目前,大数据的研究与应用已经成为国内外的热点(Science,2011)。Gartner把大数据定义为:大数据是具有大容量、快速、和(或)多样性等特点的信息资产,为了能提高决策、洞察发现和流程优化,这种信息资产需要新形式的处理方法(Gartner,2012)。2015年国务院印发的《促进大数据发展行动纲要》文件中指出:大数据是以容量大、类型多、存取速度快、应用价值高为主要特征的数据集合,正快速发展为对数量巨大、来源分散、格式多样的数据进行采集、存储和关联分析,从中发现新知识、创造新价值、提升新能力的新一代信息技术和服务业态。因此,为了充分从大数据中挖掘有用的信息,需要研究不同种类的大数据技术。目前,一些大数据技术以及用于分析大数据的工具正在被研究(Chen,2014;Melnik,2010;Gulisano,2012)。
(二)现有的电子数据审计方法
电子数据审计一般可以理解为“对被审计单位的电子数据进行采集、预处理以及分析,从而发现审计线索,获得审计证据的过程”,其原理如图1所示(陈伟,2012;陈伟,2016)。在实际的审计工作中,为了避免影响被审计单位信息系统的正常运行,并保持审计的独立性,规避审计风险,审计人员在开展电子数据审计时,一般不直接使用被审计单位的信息系统进行查询分析和检查,而是将所需的被审计单位的电子数据采集到审计人员的计算机中,利用相关软件进行分析。
由图1可知: 审计数据采集和审计数据预处理的目的是为审计数据分析做准备,通过审计数据分析,发现审计线索,获得审计证据,形成审计结论才是审计的最终目的。因此,审计数据分析是电子数据审计的关键。一般来说,常用的审计数据分析方法主要包括:账表分析、数据查询、审计抽样、统计分析、数值分析等,其中,数据查询的应用最为普遍。通过采用这些方法对被审计数据进行分析,可以发现审计线索,获得审计证据。
(三)基于模糊匹配的审计方法原理
大数据环境下从不同地方采集来的被审计数据中可能含有相似重复的数据,这些相似重复数据可能就是审计过程中要查找的可疑数据,如何对这些相似数据进行关联分析是大数据分析过程中的一个重要问题。目前常用的电子数据审计方法,如SQL数据查询、数值分析(重号分析)等,只能查找完全符合查询条件的数据(陈伟,2016)。为了查找被审计数据中的相似重复数据,解决SQL数据查询计的不足,本文提出了一种基于模糊匹配的审计方法,该方法的原理描述如下:
1.选取模糊匹配字段
根据对被审计数据的分析,选取要比较的字段。
2.进行模糊匹配
选用合适的字段相似检测算法,根据所选取的比较字段,执行数据表中各字段之间的比较,在此基础上,综合所有比较字段的相似检测结果,计算整条数据记录的相似度,并根据预定义的字段和记录的阈值,检测出相似重复数据,即为可疑数据。其中,字段相似检测算法如下:
(1)字符型字段相似度计算方法。对于字符型字段,一个字段可以看成是一个字符串,字符串的相似检测也称字符串匹配,一般通过采用编辑距离算法,可以计算出两个字段间的编辑距离。由于编辑距离值为整数,为了把字段间的编辑距离转换成字段间的相似度,提出转换方法如表1所示。表1中的对应关系也可以由审计人员根据对被审计数据的分析进行调整,从而更准确地检测相似重复数据。
(2)布尔型字段相似度计算方法。对于布尔型字段,如果两字段相等,则相似度取0,如果不同,则相似度取1。
(3)数值型字段相似度计算方法。对于数值型字段,可以采用计算数字的相对差异算法:
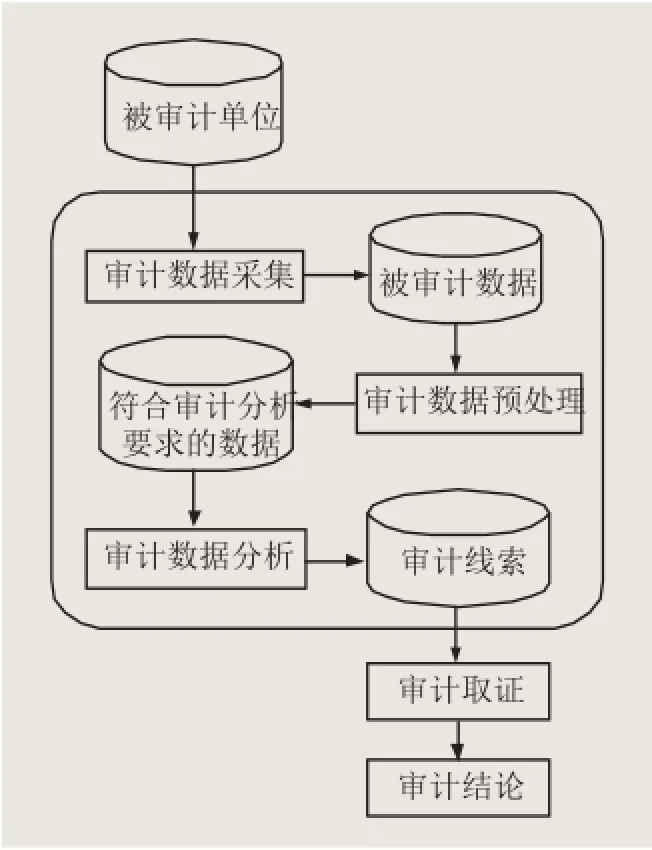
图1 电子数据审计的原理
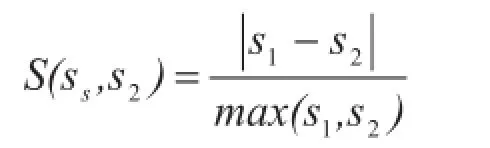
3.确认模糊匹配结果
对检测出的每一组相似重复数据(可疑数据),由审计人员通过对可疑数据的调查和分析,最终获得审计证据。
由以上分析可以看出:当该方法分析字符型字段时,无论该字段中字符的位置怎样,只要出现该字符即可。同样,当该方法分析数值型字段时,也不要求待比较的数值型字段的值完全一样,只要相近即可。所以,本文所提出的方法称之为模糊匹配。相对于模糊匹配,精确匹配指只有所比较的字符型字段中整个字段相同,或者所比较的数值型字段的值完全一样时才匹配。
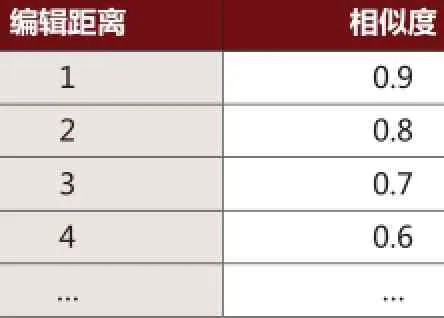
表1 编辑距离和相似度的对应关系定义
三、大数据环境下基于模糊匹配的审计方法的实现
根据前文对基于模糊匹配的审计方法的分析,笔者在电子数据审计模拟实验室软件中设计并实现了这种审计数据分析方法,其界面如图2所示。主要功能介绍如下:
1.功能菜单区
功能菜单区主要提供电子数据审计模拟实验室软件的功能菜单,包括分析结果导出、审计日志导出、数据采集、审计数据分析(数据查询、数值分析、统计分析、审计抽样、数据匹配、相似数据查询)、关于本系统等。其中,相似数据查询和数据匹配功能菜单即为基于模糊匹配的审计方法。
2.状态区
状态区用来显示当前数据预览及结果显示区中数据记录的数量,以及用来选择和显示采集来的待分析数据表,用户可以在状态区选择要分析的数据。
3.相似查询参数设置区
相似查询参数设置区主要用来选择待分析的字段、设置相应字段的权重,以及选择每个相似查询字段的相似检测算法。
4.阈值参数设置区
阈值参数设置区主要用来设置字段间阈值和记录阈值。字段间阈值表示每个字段之间的相似度,记录阈值表示整个数据记录之间的相似度。
5.相似度与编辑距离对应关系设置区
相似度与编辑距离对应关系设置区用来设置相似度与编辑距离之间的对应关系。相似度与编辑距离对应关系可以由审计人员根据对被审计数据源的分析进行调整,从而更准确地检测相似重复数据。
6.数据预览及结果显示区
数据预览及结果显示区用来显示当前待分析数据表中的数据,用户可以通过该区预览当前待分析数据表中的数据。同时,一般相似查询功能的数据分析结果也在该区中显示,用户可以通过单击菜单“文件”→“分析结果导出”完成分析结果的导出和保存。
四、大数据环境下基于模糊匹配的审计方法的审计风险评价
由于模糊匹配方法的不精准性,如何评价该方法的审计风险非常重要。国际审计与鉴证准则委员会(International Audit and Assurance Standards Board,IAASB)把审计风险的模型定义为:
审计风险 = 重大错报风险 × 检查风险
在审计风险模型中,审计人员所能控制的只有检查风险,重大错报风险与被审计单位有关,审计人员对其无能为力,只能对其水平进行评估,以便确定可接受的检查风险水平。根据以上审计风险模型,不难发现:可以通过采用合适的审计方法来降低检查风险。
目前,国内对信息化环境下计算机辅助审计风险的研究多是从理论层面分析计算机辅助审计风险的成因与规避,在审计风险控制这方面的研究也多是从定性的角度进行分析,没有从定量的角度对其进行深入的研究。为了从定量的角度分析审计数据分析方法的审计风险,笔者定义相应的查全率R(Recall)和查准率P(Precision),分别为:
1.查全率R
查全率是指可疑数据被正确识别的百分率,即:
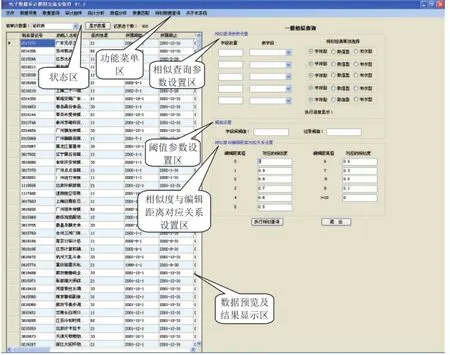
图2 电子数据审计模拟实验室软件中的相似查询功能界面
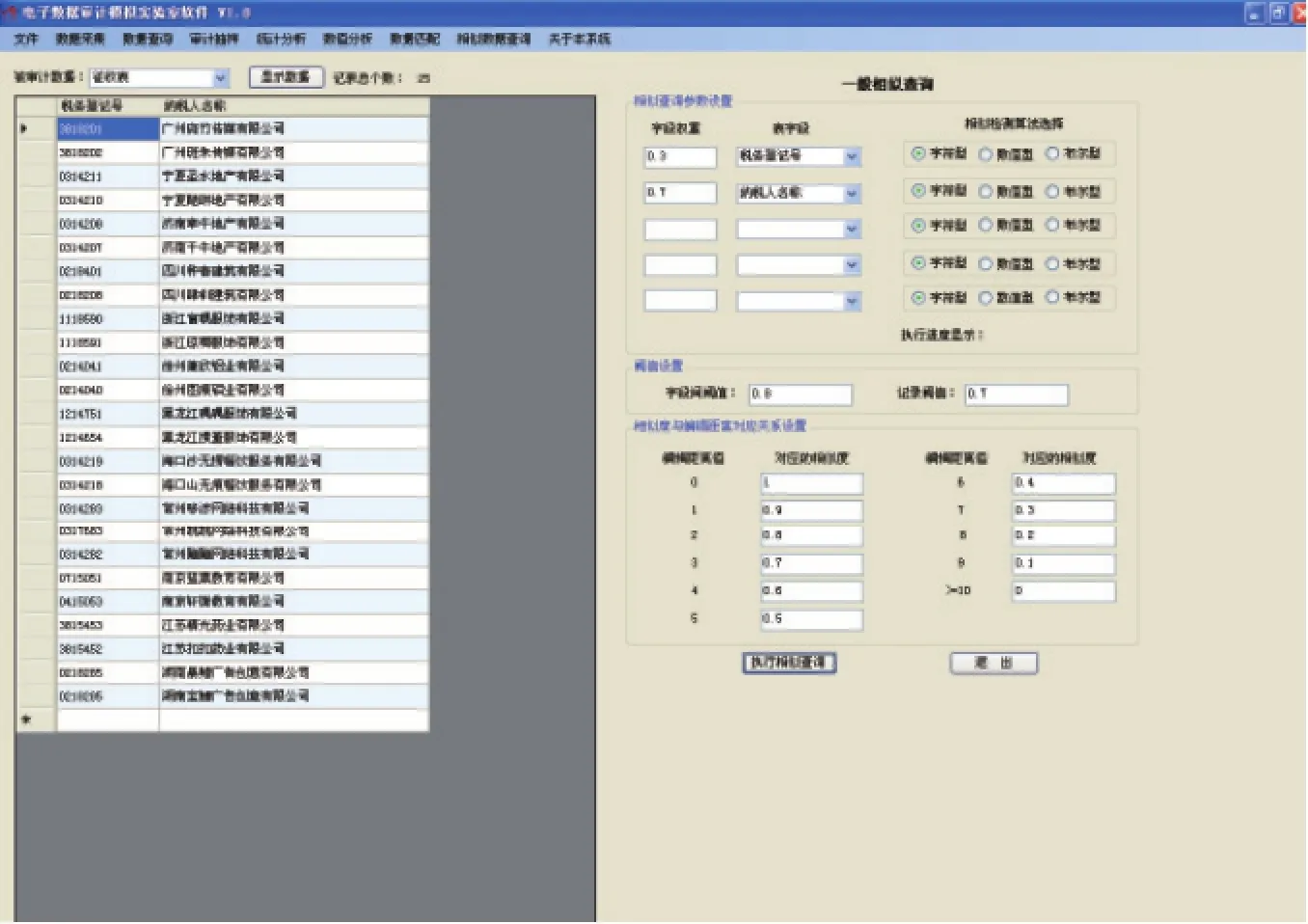
图3 字段阈值为0.8和记录阈值为0.7时的模糊匹配分析结果示例

2.查准率P
查准率是指审计方法识别可疑数据的正确率,即:

通过以上两个指标,可以定量地评价基于模糊匹配的审计方法的审计检查风险。比如,通过灵活地设置字段和数据的阈值,以及字段的权重,可以改变系统的查全率和查准率,从而控制基于模糊匹配的审计方法的检查风险。
五、大数据环境下基于模糊匹配的审计方法的应用及分析
(一)案例介绍
以给定的某税收征收电子数据(文件名为“税收征收.mdb”,数据表名为“征收表”)为例,查找该数据中“纳税人名称”和“税务登记号”两字段相似的数据,要求从查全率和查准率的角度考虑审计检查风险。
(二)案例操作
要检查某税收征收电子数据中“纳税人名称”和“税务登记号”两字段相似的数据,可采用电子数据审计模拟实验室软件中的“相似数据查询”功能,根据“纳税人名称”和“税务登记号”这两个字段对该数据中相似的数据进行分析。对于审计检查风险,可以通过设置字段阈值和记录阈值来控制。
假设该税收征收电子数据已被采集到电子数据审计模拟实验室软件中,打开电子数据审计模拟实验室软件的相似查询功能,如图2所示。然后,在图2中相似查询的字段分别为“纳税人名称”和“税务登记号”,考虑到“纳税人名称”字段较为重要,“纳税人名称”的权重设为0.7,“税务登记号”的权重设为0.3;“纳税人名称”和“税务登记号”的相似查询算法都选择字符型;相似度与编辑距离的对应关系保持系统默认值不变。主要分析结果如下:
1.当选择字段阈值为0.8,记录阈值为0.7时。单击“执行相似查询”按钮,其相似查询结果如图3所示。
2.当选择字段阈值为0.9,记录阈值为0.8时。单击“执行相似查询”按钮,其相似查询结果如图4所示。
3.当选择字段阈值为0.8,记录阈值为0.8时。单击“执行相似查询”按钮,其相似查询结果如图5所示。
4.当选择字段阈值为0.9,记录阈值为0.9时。单击“执行相似查询”按钮,其相似查询结果如图6所示。
以上分析的结果可以另存为数据文件,然后做进一步的分析。
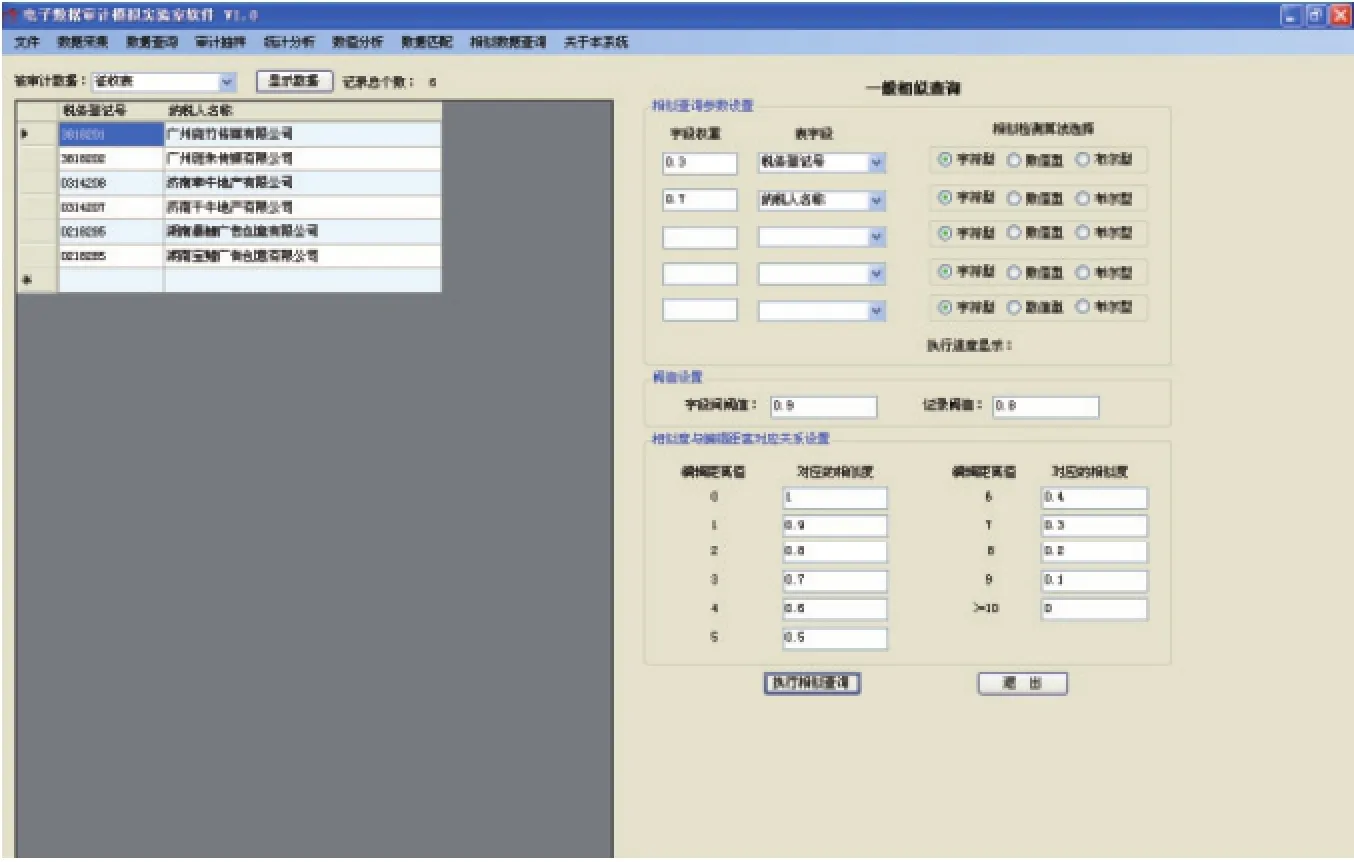
图4 字段阈值为0.9和记录阈值为0.8时的模糊匹配分析结果示例
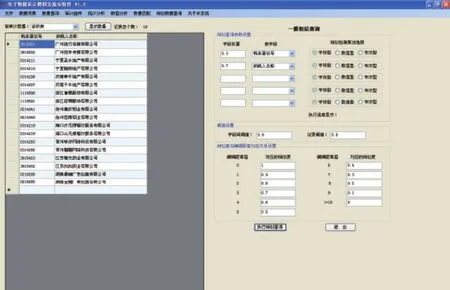
图5 字段阈值为0.8和记录阈值为0.8时的模糊匹配分析结果示例
(三)案例分析
由以上案例可以看出:
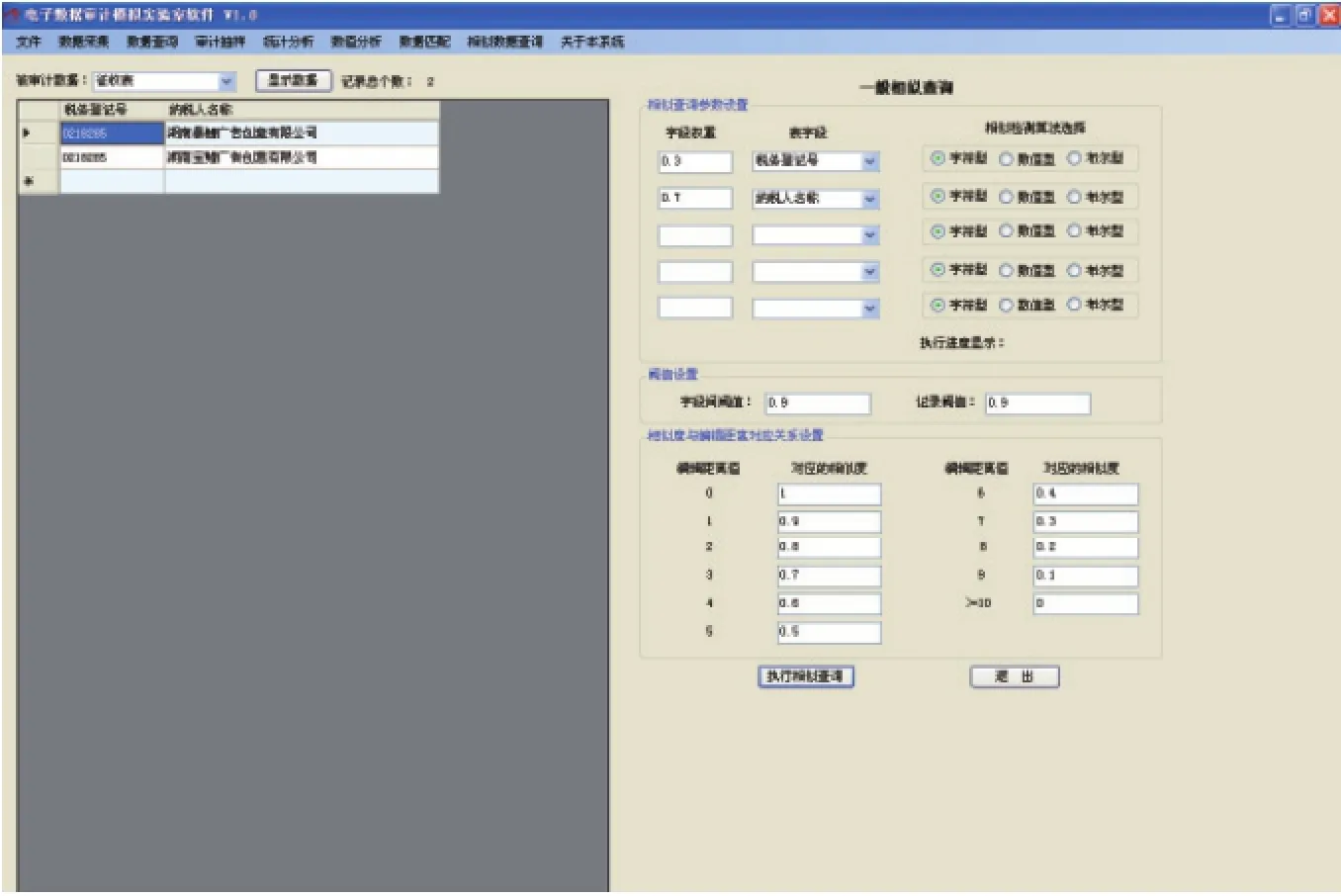
图6 字段阈值为0.9和记录阈值为0.9时的模糊匹配分析结果示例
1.通过设置不同的字段阈值和记录阈值,相似数据查询结果会有所不同。当设置的字段阈值和记录阈值较低时,查出的相似数据较全,但准确率较低;当设置的字段阈值和记录阈值较高时,查出的相似数据会有遗漏,但准确率较高。
2.当查全率高时,分析出的结果较多,查出的相似数据较全,审计检查风险减少,但审计人员需要更多的时间去确认这些相似重复数据,从而降低审计效率;当查准率高时,分析出的结果较少,分析结果较准确,审计人员不需要更多的时间去确认这些相似重复数据,从而提高审计效率,但查出的相似数据会有遗漏,审计检查风险增加。
3.审计人员可以根据所需要控制的审计风险水平,来确定合适的查全率和查准率,然后确定合适的字段阈值和记录阈值,从而可以控制审计检查风险。
4.基于模糊匹配的审计方法可以有效地对被审计数据进行分析,查找出被审计数据中的相似重复数据,满足大数据环境下审计数据分析的需要。
六、总 结
本文根据目前大数据环境下开展电子数据审计的需要,提出了一种基于模糊匹配的审计方法,并在自主研发的电子数据审计模拟实验室软件中实现了这种方法。在此基础上,以某税收数据审计为例,分析了该方法的应用。本文研究认为,审计人员借助电子数据审计模拟实验室软件,可以方便地使用基于模糊匹配的审计方法,并能通过在系统中设置合适的字段阈值和记录阈值,以及相似度与编辑距离的对应关系,有效地控制该方法的审计风险。总之,基于模糊匹配的审计方法能有效地满足大数据环境下电子数据审计的需要。
作者单位:南京审计大学审计科学研究院
主要参考文献
1.陈伟.电子数据审计模拟实验. 清华大学出版社.2016
2.陈伟.计算机辅助审计原理及应用(第三版).清华大学出版社.2016
3.陈伟, Wally Smieliauskas. 大数据环境下的电子数据审计:机遇、挑战与方法.计算机科学.2016 (1)
4.陈伟.电子数据审计模拟实验室研究.中国注册会计师.2015(7)
5.陈伟, Smieliauskas W.云计算环境下的联网审计实现方法探析.审计研究.2012(3)
6.AICPA. 2014. Reimagining Auditing in a Wired World[EB/OL]. http://www. aicpa.org
7.Chen C L P, Zhang C Y. 2014. Data-intensive applications, challenges, techniques and technologies A survey on Big Data[J]. Information Sciences, 275:314-347
8.Chen W, Liu S F, Smieliauskas W, etc. 2012. Influence factors analysis of online auditing performance assessment: a combined use between AHP and GIA[J]. Kybernetes, 41(5/6): 587-598
9.Earley C E. 2015. Data analytics in auditing: Opportunities and challenges [J]. Business Horizons, 58(5): 493-500
10.Gartner E S. 2012. 10 Critical Tech Trends for the Next Five Years [EB/OL]. http://www. forbes.com/ sites/ericsavitz/ 2012/10/22/gartner-10-critical-tech-trends-for-the-nextfive-years/
11.Gulisano V, Ricardo J P, Marta P M, etc. 2012. Streamcloud: an elastic and scalable data streaming system[J]. IEEE Transactions on Parallel and Distributed Systems, 23 (12) :2351-2365
12.Lambrechts A J, Lourens J E, Millar P B,etc. 2011. Global technology audit guide (GTAG):Data analysis technologies[M]. The Institute of Internal Auditors
13.Melnik S, Gubarev A, Long J J, etc. 2010. Dremel: interactive analysis of webscale datasets[C].Proceeding of the 36th International Conference on Very Large Data Bases. 3(1):330-339
14.Science.2011. Dealing with data [J]. Science, 331(6018): 639-806
国家自然科学基金(71572080);教育部人文社会科学研究规划基金(14YJAZH006);江苏省社会科学基金(13GLC016);江苏省“六大人才高峰”高层次人才项目(2014-XXRJ-015)
猜你喜欢
Plasma Science and Technology(2022年2期)2022-03-10
电脑爱好者(2021年23期)2021-12-08
建材发展导向(2021年19期)2021-12-06
疯狂英语·读写版(2021年5期)2021-06-15
临床骨科杂志(2020年1期)2020-12-12
武汉科技大学学报(社会科学版)(2020年2期)2020-04-28
杰出人物(2020年2期)2020-04-01
办公室业务(2019年13期)2019-08-01
新世纪图书馆(2014年7期)2014-09-19
