
基于分布式流计算的路网指挥中心系统数据处理技术
2016-11-29 09:20宋真祥
城市轨道交通研究 2016年3期
梁 奕 李 立 宋真祥
(国电南瑞科技股份有限公司研发中心,210061,南京∥第一作者,高级工程师)
基于分布式流计算的路网指挥中心系统数据处理技术
梁 奕 李 立 宋真祥
(国电南瑞科技股份有限公司研发中心,210061,南京∥第一作者,高级工程师)
城市轨道交通路网指挥中心系统要求针对分布式环境、种类繁多的海量数据进行整合。根据数据ETL(Extract-Transform-Load)理论知识和路网指挥中心数据的实际特点,运用分布式流计算技术,结合Storm平台下的Spout-Bolt工作机制,设计了一个适用于业务系统数据源的分布式流计算ETL框架。介绍了模块的功能及数据处理过程。利用分布式流计算ETL框架,可充分满足多业务场景下的数据处理需求,提高了数据的实时性和系统的横向扩展能力。
城市轨道交通;路网指挥中心;数据处理技术
Author's address R&D Center,NARI Technology Co.,Ltd.,210061,Nanjing,China
城市轨道交通路网指挥中心系统要将分散的线路自动化系统联结为一个有机的整体,以提高各系统的协调配合能力。这就要求对分布式环境、种类繁多的海量数据进行整合。如何整合这些数据成为路网指挥中心系统的研究热点。数据仓库技术可以保证数据的准确性、一致性和综合性,可以为后续的联机查询、数据挖掘等工作提供可靠统一的数据源。因此,引入数据仓库技术是实现路网指挥中心系统数据集成的最优方案之一。
数据萃取、转换和加载(Extract-Transform-Load,简为ETL)是构建数据仓库的必经过程。在路网指挥中心系统方面,传统的ETL工具很难对大规模高并发的监控数据进行有效的数据整合工作,且不能保证数据仓库的实时性、数据安全性及ETL工具的可靠性。因此,为了可以快速准确整合路网指挥中心系统产生的各类数据,分布式流计算技术的使用是获取最佳性能和高扩展性的关键所在,具有较高的研究价值。
1 Storm系统框架
Storm是Twitter公司开发的分布式的、可伸缩的、容错的实时流计算系统。其并行计算及实时计算的特性,很好地满足了路网指挥中心数据ETL的实际需求。Storm流处理平台可以直接处理实时进入系统的任何数据流,具有如下优点:可横向扩展,支持动态增加集群工作节点以提高整体的并发计算能力;布置安装简单;无状态的工作节点;独有的消息追踪框架可以实时监控集群中数据的流向;可靠的事务机制可以满足不同级别的数据处理需求;支持多种编程语言进行开发。
Storm拓扑结构由Spout和Bolt组件构成(如图1所示)。Spout组件用于处理集群的数据输入,而后Spout将数据传递给名为Bolt的组件,后者将以某种方式处理这些数据。例如Bolt以某种存储方式持久化这些数据,或者将它们传递给另外的Bolt。
2 分布式流计算ETL框架的设计
2.1路网指挥中心数据分析
一般线路业务系统中通用的关系数据库模型比较简单实用。在此模型中,设备综合维度表的主键为综合数据表的外键引用(如图2所示)。

图1 Storm拓扑结构示例
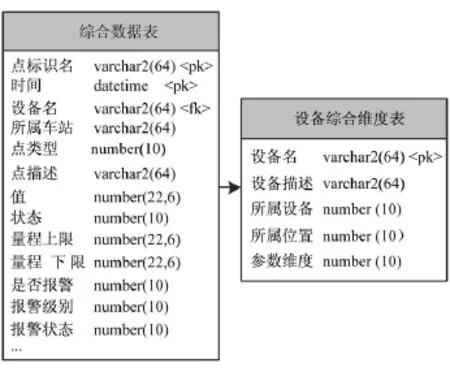
图2 业务系统数据源模型图
在数据规模大时,综合数据表会呈现出爆炸式的增长,从而导致系统查询效率极其低下,无法适应路网中心的大数据规模。而传统的索引等方式已不能解决数据库设计本身存在的缺陷。
在数据仓库建模设计时,已充分考虑上述数据特点,采用水平分表结合星型模型的方式来构建数据仓库模型。具体做法为:①将综合数据表的数据按功能进行分类,再通过分类信息维度表将数据记录分散至各类事实表。②每类事实表再根据具体特性,设计其私有的维度表。通过这种方式,不仅能快速地将事实表的数据级别从千万级降至了百万级,而且利用维度表特性和类似于垂直分表的思想解决了大量的数据冗余问题。典型的数据仓库模型如图3所示。
码位事实表是实际接收数据源增量数据的数据表,而设备类型维度表、测点位置维度表及设备参数维度表都可以看作是定义表。在第一次完全加载后,如无特殊情况则定义表的数据量不会产生明显变化。在码位事实表中,所有增量数据可通过数据源中的对应字段直接获取,而所属位置键、所属设备键及参数维度键则可通过数据源中的设备综合维度表进行获取。通过ETL转换至数据仓库后,整个设计就显得合理得多,可以更好地为后续的数据挖掘、联机分析等作数据支持。

图3 数据仓库数据模型图
2.2系统总体架构设计
本文根据路网指挥中心的需求,提出了一种分布式流计算ETL框架。该框架从线路监控实际产生数据的源头出发,利用Storm流处理平台强大的分布式及实时处理能力,将传统的ETL过程转化为通过流计算编程的方式实现并行ETL过程,从而提高了ETL过程中的转换效率及处理能力。分布式流计算ETL框架是基于Storm平台而设计的,以Storm作为执行平台,以Redis作为临时存储区,以ORACLE数据库作为数据仓库。其框架体系结构如图4所示。

图4 分布式流计算ETL框架体系结构
从图4中可以看出,分布式流计算ETL框架既可处理关系型数据,又可支持短时高并发数据流写入的业务场景。分布式流计算ETL框架由数据萃取、数据转换和数据加载三个主模块构成。其中数据萃取模块对应于传统Storm拓扑结构中的Spout组件,数据转换模块和数据加载模块对应于Bolt组件。
2.2.1数据萃取模块
(1)XML适配器:其主要功能是解决ETL数据萃取需求环节中的确认数据源需求,XML适配器采用XML配置文件的方式,在文件中对数据源及数据仓库进行了配置。
(2)增量萃取模块。处理增量数据的处理问题是ETL工具设计中的一个重点,主要使用读取数据库日志、时间戳、数据比较差异和触发器加上数据变更记录来捕获数据源变化数据。
(3)触发萃取引擎:主要针对于短时高并发的触发器数据源而设计。引擎依赖于设备触发器的数据获取接口,结合Storm分布式流计算框架处理高并发业务场景的能力,通过多Spout适配不同设备的数据源,在拓扑设计时增加节点的并行度,从而提高触发萃取的效率。
2.2.2数据转换模块
数据转换过程是连接数据抽取过程与数据加载过程的纽带,在ETL过程中起到决定性的作用,包括以下4个方面。
(1)空值处理:若在转换过程中获取到某些字段存在空值,则可按照定义将该字段的空值替换为预订数值或者不作任何处理。
(2)格式化数据:根据业务数据源中各个字段的数据类型,进行数据格式的格式化化操作。例如,统一将数值类型转化成字符串类型。
(3)数据重构:根据数据建模关系进行字段的拆分、合并等操作,是最为典型的ETL的转换过程。
(4)数据过滤:根据数据建模关系对字段进行过滤,提取数据内容,进行拆分和合并操作,满足业务规则要求。
2.2.3数据加载模块
在分布式流计算ETL框架中,数据的加载主要为最初加载和增量装载两种装载类型。最初加载主要利用批量加载引擎进行处理,增量装载则使用批量加载引擎和实时加载引擎结合的方式进行处理。实时加载引擎可在该代码基础上进行优化,即将数据流中的每个数据元组直接入库。其效率会稍低于批量加载引擎,但实时性较强。
3 基于业务系统数据源的实现
通过上述建模过程得知,可利用星形模型对路网中心系统数据源及目标数据仓库进行数据建模。本节将结合实际数据需求,给出基于分布式流计算ETL框架的对应解决方案。
业务系统ETL过程建模如图5所示。要采集的业务系统数据源中,综合数据表即事实表,用于存放监控系统业务数据;设备综合维度表即维度表,用于存放采集设备的设备参数信息。通过采集业务系统数据源,将数据变为多种类型表的形式存放至数据仓库中。实际的工作环节涉及复杂的表结构拆分、合并过程及表内字段拆分、合并过程。之后,源数据中的数据会按照预先设定的规则存储至目标数据仓库中。数据仓库同样使用星型模型进行建模。以信号设备的监测类型为例,其存储监测数据的事实表为码位事实表,而与之关联的设备类型维度表、测点位置维度表和设备参数维度表可为其提供设备的多种参数定义信息。

图5 业务系统ETL过程建模示意图
图6为分布式流计算ETL处理过程。在萃取阶段,系统使用spout组件通过时间戳字段完成对综合数据表的增量萃取工作。单spout即可支持上万组数据的并发处理需求;扩展成多spout后,可横向扩展系统的实际吞吐能力以支持不同数据规模下的实际需求。在转换阶段,使用并行的bolt对综合数据表数据同时进行拆分、合并等工作,将数据缓存至Redis存储引擎中,构建分类型数据表的数据集,并每隔一段时间将源数据转化为目标数据仓库所需的结果数据。在加载阶段,系统使用并行的bolt将Redis存储引擎中的结果数据持久化保存至数据仓库中,并批量完成数据的持久化工作。

图6 业务系统ETL分布式处理过程
整个ETL过程中,由于数据均处于内存,故避免了不必要的磁盘读写,将系统处理能力提高到最优。在Redis缓存引擎中加入了分布式流计算ETL独有的数据持久化机制。这在保证数据安全的前提下,大大提高了数据的实时性。
4 结语
本文结合数据ETL理论知识和城市轨道交通路网指挥中心数据的实际特点,运用分布式流计算技术,结合Storm平台下的Spout-Bolt工作机制,设计了一个适用于业务系统数据源的分布式流计算ETL框架,并阐述了业务系统数据源在分布式流计算ETL框架中的具体实现过程。经过分析,利用分布式流计算ETL框架,可充分满足多种业务场景下的数据ETL需求,并能在保证数据安全性的前提下,提高数据的实时性和系统的横向扩展能力。
[1] Singapore technologies electronics limited.traffic control centre(tcc)integrated information system for beijing urban railway network[R/OL].[2006-07-10][2015-08-01]http:∥www.stee.stengg.com/pdf/railway_systems/Beijing _TCC-Eng.pdf.
[2] ATHANASSOULIS M,CHEN S,AILAMAKI A,et al. MaSM:Efficient online updates in data warehouses[C]∥proc of the SIGMOD Int Conf on Management of Data.New York:ACM,2011:865.
[3] ZHAO L,SHI W.Research on optimization of application model based on storm[C]∥Software Engineering and Service Science(ICSESS),2014 5th IEEE International Conference on.IEEE,2014:248.
[4] SANFILIpp OS,NOORDHUIS p.Redis[EB/OL].[2015-01-27][2015-08-07].http:∥redis.io.
[5] ELLIOTT T.Why In-Memory Computing Is Cheaper And Changes Everything[EB/OL].(2013-04-17)[2014-06-18].http:∥timoelliott.com/blog/2013/04/201304170098. htm.
[6] 张延松.大规模可扩展数据分析技术研究[D].北京:中国人民大学信息学院,2010.
[7] 李玉建,马子彦.城市轨道交通信息化规划建设中主数据管理平台的建设契机[J].城市轨道交通研究,2014(3):11.
Data Processing Technology in Traffic Control Centre Based on Streaming Computing
Liang Yi,Li Li,Song Zenxiang
TCC for urban rail transit network is demanded to integrate large scale,various types and distributed data. Based on the data ETL(extract transformload)theory and the practical characteristics of TCC system,the streaming computing method is used and combined with Spout Bolt Scheme on the Storm platform,a distributed ETL framework for streaming computing in TCC system is proposed. Then,the modula functions and data processing are introduced.This distributed ETL framework has better performance on data processing in multi service scenario,and improves the real-time capability and scalability of TCC system.
urban rail transit;traffic control centre(TCC);data processing technology
Tp 274
10.16037/j.1007-869x.2016.03.009
(2015-07-30)
猜你喜欢
电子乐园·下旬刊(2021年3期)2021-02-08
党员生活·下(2020年3期)2020-04-20
党员生活(2020年2期)2020-04-17
自然资源信息化(2019年4期)2019-03-29
铁道通信信号(2018年10期)2018-12-06
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
山东工业技术(2016年15期)2016-12-01
中国教育信息化(2015年10期)2015-08-23
浙江大学学报(工学版)(2015年2期)2015-05-30
