
基于相似度匹配的网络协议语法分析方法
2016-11-22 11:35郭亮罗森林潘丽敏
北京理工大学学报 2016年5期
郭亮, 罗森林, 潘丽敏
(北京理工大学 信息系统及安全对抗实验中心, 北京 100081)
基于相似度匹配的网络协议语法分析方法
郭亮, 罗森林, 潘丽敏
(北京理工大学 信息系统及安全对抗实验中心, 北京 100081)
为解决网络协议语法分析方法中,依赖人工干预、分析效率低下、分析范围较小等问题,提出一种基于相似度匹配的网络协议语法分析方法. 通过嗅探采集网络原始数据包,解析基础协议并对数据包进行预处理,提取9维不同角度的特征,建立了网络协议语法相似分析模型,分析网络协议细节语法特征. 通过将TCP协议作为已知协议,对UDP、DNS、QQ等3种不同类型的协议测试,结果表明这3类协议报头中,33%以上的字段能在TCP协议中找到对应的相似语法,而且平均准确率均在96%以上,该方法不需人工干预,可以提高分析效率、减少限制条件、扩大分析范围,并能较为有效地分析出网络协议语法特征.
协议语法分析;协议逆向;相似度匹配
网络协议语法分析在网络安全中地位越来越重要,涉及到入侵检测[1]、漏洞挖掘[2]、协议重用[3]等. 目前主要采用协议逆向分析的手段实现协议语法信息的提取,可分为两类,基于流量跟踪进行分析和基于指令执行进行分析. PAN-Fan等[4]对这两类方法进行了比较,后者逆向能力和准确度优于前者,而前者限制条件和分析速度由于后者.
基于流量跟踪分析的协议逆向方法,最早是Marshall Beddoe[5]启动的PI(protocol information)项目来分析未知或者未公开的网络协议的结构. CUI等[6]提出一种Discoverer方案,采用聚类的方法,比PI中基于字节的方法,更有针对性,同时还针对标志、长度、偏移、cookie等语法,分别采用了一种启发式识别规则. 但是该方法的无监督聚类方法,并不能保证聚类结果完全可靠,而其使用的识别规则,针对性太强,识别结果较固定. Antunes等[7]提出一种以偏序比对算法为基础,构建有穷自动机识别报文的方法,但该识别并不能识别具体语法,只能识别状态变化等,只满足协议识别的基本需求. 基于指令执行分析的逆向方法研究也比较多. 比如应凌云等[8]提出恶意软件网络协议的语法和行为语义分析方法,这类方法有很高的准确性和可靠性,但其复杂度依赖于分析对象软件的代码复杂度,而且分析过程长,效率低.
本文提出的基于相似度匹配的网络协议语法分析方法是属于流量跟踪的分析方法. 该方法能够提高协议分析效率,进行自动化协议分析,并且扩大了协议语法分析的范围,能够适用于更多类型的语法分析.
1 网络协议语法相似分析模型
1.1 原理框架
本文提出的网络协议语法相似分析模型,原理图如图1所示.
1.2 网络数据采集
对数据包进行主要采集依靠网络嗅探技术,捕获经过网卡的所有数据包,解析已知的基础协议,过滤掉非目标协议的所有数据包,只采集目标协议的网络数据包. 本文所采用的训练数据使用最为常见的TCP协议数据,本文实验所用到的测试数据,主要包括UDP、DNS、QQ等协议数据. 所采集数据均为原始数据包,每类数据均采集50 MB左右.
1.3 数据预处理
数据采集后,需要进行基础协议解析、数据截断等步骤. 基础协议解析主要指将原始数据流依据基础协议语法拆分成一个个独立数据包,并且去掉基础协议的报头. 而数据截断指设置一个数据截断长度N,截断所有长度大于N字节的数据包,丢弃掉所有长度小于N字节的数据包.
将输入的原始网络数据转化成c[N][M]的标准二维向量,其中N表示数据包长度,M表示参与统计特征提取的数据包个数. 对于N的选取,原则上只需要覆盖协议的报头即可,本文选取的4类协议,报头长度均在30以下,同时考虑到32位计算机中默认4字节对齐的问题,本文选取了N=32. 对于M的选取,本文采用网格法进行了多组实验,选取了实验结果最佳的M=300.
1.4 特征提取
特征提取是最核心的一步,为了选择更有效的特征,本文从取值范围、随机性、统计参数等3个角度选取了9维特征. 在预处理之后,将其输出的c[N][M]的数据包,按照单字节进行拆分,拆分成N个ci[M]序列,然后分别选取对每一组ci[M]序列进行统计特征提取,得到N组9维特征向量λi[N](i=1,2,…,9),对应的特征如表1所示.
1.5 向量分组
根据网络协议的一般特征,协议报头中相同偏移的字节语法相同,而不同偏移地址的字节也存在语法相同的情况. 本文选取的训练协议TCP协议,根据其协议语义,对20位偏移地址进行分组,最终分组结果为:[1、3] [2、4] [5、9] [6、10] [7、11] [8、12] [13] [14] [15] [16] [17、18] [19、20]等12组. 将每一组数据输入,均可得到N组特征向量λi[N](i=1,2,…,9),所有训练数据根据这12类分组,计算其每组的质心向量,作为相似匹配的模型参数.
1.6 相似匹配
提取出已知协议的特征向量质心模型之后,需要将未知协议特征向量与该模型进行相似匹配. 本文对欧几里得距离函数,Jffreys 距离,Manhattan 距离,相关系数,余弦函数等5类相似度函数从时间性能和匹配成功率两个角度进行了对比分析实验(鉴于篇幅考虑,略去该实验具体内容),选择匹配率和时间性能较好的Jffreys距离作为相似度函数,其公式为
2 实验及结果分析
2.1 实验目的
将TCP协议数据作为训练数据,UDP、DNS、QQ协议等作为测试数据,来验证算法有效性.
2.2 评价方法说明
统计每一类协议中各字段所匹配结果中,概率最大的TCP匹配类别及其匹配概率,并且人为根据其语义判定是否相似,将相似类别的平均匹配概率作为准确率进行评价.
2.3 实验过程和参数说明
本实验选取TCP协议视为已知协议,UDP、DNS、QQ协议等视为未知协议. 首先分别选取50 MB的TCP、UDP、DNS、QQ协议数据,每300个数据包为一组,并对所有数据进行预处理和特征提取. 将TCP协议数据提取出的特征向量进行分组,计算每一组的质心. 分别选取UDP、DNS、QQ协议数据提取出特征向量各100组,输入相似匹配模块,与TCP协议各组质心进行相似匹配,选取与该输入Jffreys距离最小的质心,视为该组数据的匹配结果,并选择匹配次数最多的质心,作为该类协议该字段的匹配最终结果.
2.4 实验结果及分析
其中UDP相似匹配详细结果如表2所示,从结果可以看出,UDP的字段1、3、7字段分别与TCP的1、1、11类字段相似,而从其字段含义也可以看出其语法相同,并且准确率很高,在98%以上.
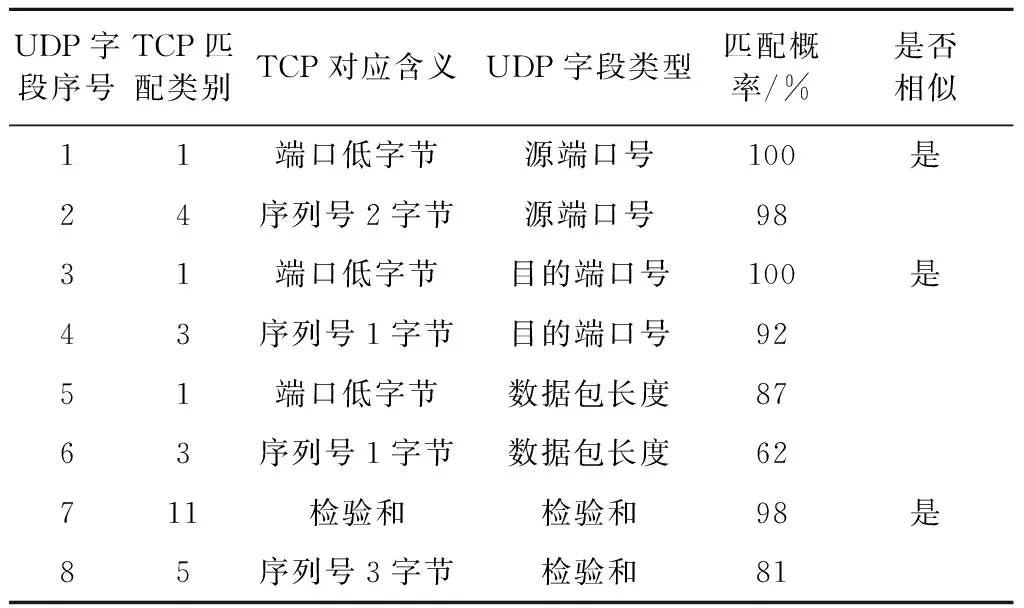
表2 UDP相似匹配结果
此外,UDP其他字段,比如两个端口号的第二字节,分别匹配到了TCP的序列号的1、2字节,虽然从字段含义中看不到其联系,但通过分析其语法,也可以得到其语法相似的结果,不过本文结果并未采用这类隐藏较深的结果.
鉴于篇幅原因,不将中间结果一一展示,实验结果如表 3所示. 经过UDP、DNS、QQ等3种不同类型的协议测试,分别有3、4、3个字段与TCP中对应字段有明显相似关系. 而在这些相似语法字段的匹配中,平均准确率均在97%以上,说明了本文方法的有效性. 此外,从结果看出,与TCP协议越相似的协议,如UDP协议,有着越高的算法准确率.

表3 UDP、DNS、QQ匹配结果
本文选取了具有代表性的3类方法进行比较,包括CUI所用的Discoverer[6]方法、Antonio Trifil[7]所用方法和应凌云所用的Prama[9]方法进行了对比分析,其比较结果如表 4所示. 与同样基于流量跟踪方法的Discoverer方法和Antonio方法比较来看,本文方法能够分析出更多的特征,并且自动分析能力和时间性能都比较优秀. 而与基于指令执行的Prama方法比较来看,可以进行实时、自动分析,并且分析范围为相似特征,与Prama方法分析的行为特征各有优劣,虽然在分析内容方面比Prama方法分析出的语义信息略有逊色,但本文方法在分析出字段语法之后,可以通过参考相似字段的语义信息,进行人工语义分析,一定程度地弥补该方法的不足.
表4 本文方法与Discoverer、Antonio及Prama方法对比分析
Tab.4 Comparison with Discoverer、 Antonio and Prama’s methods

方法分析条件分析手段分析范围分析内容分析时间本文方法流量跟踪自动相似特征语法分析实时Discoverer流量跟踪自动3类特征语法分析实时Antonio流量跟踪半自动1类特征状态分析略长Prama指令执行人工行为特征语义分析较长
综上所述,相比Discoverer方法、Antonio方法和Prama方法,网络协议语法相似分析方法不需人工干预,能提高分析效率、减少限制条件、扩大分析范围,并能较为有效的分析出网络协议语法特征.
3 结 论
本文提出了一种基于相似度匹配的网络协议语法分析方法,并建立了网络协议语法相似分析模型.
通过实验确定了各项参数指标,然后通过UDP、DNS、QQ等3种不同类型的语法分析实验,结果表明这3类协议报头中,33%以上的字段都能在TCP协议中找到对应的相似语法,而在这些相似语法字段的匹配中,平均准确率均在96%以上,说明了本文方法的有效性.
与同类方法比,该方法不需人工干预,能提高分析效率、减少限制条件、扩大分析范围,并能较为有效地分析出网络协议语法特征,有较好的实用性.
本文方法也存在一些缺点和不足. 首先该方法结果的准确率,依赖于用于训练的已知协议的选取,不同于其他协议分析方法直接对目标协议进行分析. 其次本文所采用的特征,对于TCP、UDP、DNS等固定长度的协议有较好效果,但对于HTTP、XML等采用分隔符类的协议并不合适,对该类协议需要寻找一批新的特征,做进一步的研究工作.
[1] Caballero J, Poosankam P, Kreibich C. Dispatcher: enabling active botnet infiltration using automatic protocol reverse engineering[C]∥Proceedings of the ACM Conference on Computer and Communications Security. [S.l.]: ACM, 2009:621-634.
[2] Comparetti P M, Wondracek G, Kruegel C. Prospex Protocol specification extraction[C]∥Proceedings of 2009 30th IEEE Symposium on Security and Privacy (SP). [S.l.]: IEEE, 2009:110-125.
[3] Brumley D, Caballero J, Liang Zhenkai. Towards automatic discovery of deviations in binaryimplementations with applications to error detection and fingerprint generation[C]∥16th USENIX Security Symposium.[S.l.]: USEMX Assaciation, 2007:213-228.
[4] Pan Fan, Wu Lifa, Du Youxiang, et al. Overviews on protocol reverse engineering[J]. Application Research of Computers, 2011,28(8):2801-2806.
[5] Beddoe M. Protocd information project[EB/OL]. [2004-01-02]. http://www.4tphi.net/~awalters/PI/PI.htrnl.
[6] Cui Weidong, Paxson V, Weaver N C. Discoverer: automatic protocol reverse engineering from network traces[C]∥16th USENIX Security Symposium. [S.l.]: USENIX, 2008.
[7] João Antunes, Nuno Neves, Paulo Verissimo. Reverse engineering of protocols from network traces[C]∥18th Working Conference on Reverse Engineering. [S.l.]: IEEE, 2011:169-178.
[8] 应凌云,杨轶,冯登国,等.恶意软件网络协议的语法和行为语义分析方法[J].软件学报,2011,22(7):1676-1689.
Ying Lingyun, Yang Yi, Feng Dengguo, et al. Syntax and behavior semantics analysis of network protocol of malware[J]. Journal of Software, 2011,22(7):1676-1689. (in Chinese)
(责任编辑:刘芳)
Analysis of the Network Protocol Syntax Based on Similarity Matching
GUO Liang, LUO Sen-lin, PAN Li-min
(Information System and Security & Countermeasures Experimental Center,Beijing Institute of Technology, Beijing 100081, China)
To solve the problems in analysis of the network protocol syntax, which are rely on human intervention, low efficiency and narrow scope, a method was proposed for analysis of network protocol syntax based on similarity matching. The main process of the method include collecting the raw packets by network sniffer, and then preprocessing the packets, using a variety of methods for 9 features extraction, establishing a network protocol syntax analysis model based on similarity matching method, to analyze the syntax feature of network protocol. Taking the TCP protocol as a known protocol, experiments were actualized with different types of protocols as UDP, DNS and QQ. The results show that in the three types of protocol header, more than 33% of the correct similar syntax fields can be found in TCP protocol, and the average accuracy rate was over 96%, the process needs not manual intervention, it can improve the analysis efficiency, reduce the constraints, expand the scope of the analysis, and analyze the network protocol syntax more effectively.
analysis of the network protocol syntax; protocol reverse; similarity matching
2014-03-24
北京理工大学科技创新计划重大项目(2011CX01015);国家“二四二”计划项目(2005C48)
郭亮(1986—),男,博士生,E-mail:liang4358@163.com.
潘丽敏(1968—),女,硕士,实验师,E-mail:panlimin@bit.edu.cn.
TP 391
A
1001-0645(2016)05-0520-04
10.15918/j.tbit1001-0645.2016.05.015
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
电脑爱好者(2021年23期)2021-12-08
民用飞机设计与研究(2020年4期)2021-01-21
办公室业务(2019年13期)2019-08-01
时代英语·高一(2019年1期)2019-03-13
物联网技术(2018年8期)2018-12-06
时代英语·高三(2017年1期)2017-03-01
新世纪图书馆(2014年7期)2014-09-19
新世纪图书馆(2014年7期)2014-09-19
