
基于自动提取特征点的三维人脸表情识别
2016-11-22 11:29岳雷沈庭芝
北京理工大学学报 2016年5期
岳雷, 沈庭芝
(北京理工大学 信息与电子学院, 北京 100081)
基于自动提取特征点的三维人脸表情识别
岳雷, 沈庭芝
(北京理工大学 信息与电子学院, 北京 100081)
为实现完全自动的人脸表情识别,提出一种基于自动提取三维及二维特征点的三维人脸表情识别算法. 该算法采用在三维点云、深度图像以及三维点云对应的二维特征图像上分别自动获得特定特征点,并将非点云上获得的特征点映射回三维点云以获得全部需用特征点的方法. 基于这些自动获取的特征点得到三维欧氏距离组成25维特征向量以待分类. 通过运用支持向量机作为分类器,取得了平均87.1%的6种基本表情的分类结果,其中惊讶、开心表情的分类结果分别达到了92.3%和91.7%.
三维表情识别;三维特征点;三维欧氏距离;支持向量机
人脸表情所传递的信息在人与人的日常交流中占据着异常重要的地位. Mehrabian[1]提到,表情在人们的日常沟通中扮演着最重要的角色:大约55%有效的沟通需要借助于表情,38%通过语调表达,而只有7%才是所说的语言. 同时,人脸表情识别亦是人工智能的一个重要分支和应用,是实现很多应用的基础,例如人机交互和对于人类行为的社会学分析.
对于人类表情的研究可以追溯到1872年达尔文发表的文章:人类和动物情感的表达[2]. 在该文中达尔文指出任何国籍和种族的人类都使用相同的表情来表达同样的情感. 基于此,Paul Ekman[3]提出了6种基本表情,即:气愤、厌恶、恐惧、高兴、沮丧和吃惊. 此后,Ekman又和Friesen[4]共同提出了被广泛运用的人脸运动单元编码系统(facial action unit coding system, FACS). 现今,FACS已经成为了系统的分析和表征人脸表情的标准,并广泛运用于心理学分析和动画制作领域. FACS共定义了46个不同的运动单元(AU).
通过运用不同运动单元(AU)的组合,编码员可以手动编辑几乎所有人类可以做出的表情. 虽然FACS在表征人类表情上非常有效,但是在视频或者连续三维点云序列中逐帧手动标注AU组合却是既费时又费力的工作,而且无法做到自动的对于表情的识别.
从20世纪80年代开始,很多学者发表文章致力于自动人脸表情识别的研究. 但是绝大部分的工作都是基于二维图像或者图像序列(视频)的研究, 直到3D-BUFE[5]数据库的公开发布. 基于此数据库,学者们已经发表了大量的文章,其中一些也取得了十分理想的表情分类结果,例如Hao Tang等[6]在文章中提到的结果. 但是,Tang等使用了数据库中手动标注的83个特征点中的23个来提取特征,无法做到自动的表情分类.
故本文提出了基于自动提取人脸特征点的表情分类识别算法,其中12个特征点从三维点云及其对应的深度图像上自动获得;由于数据库点云分辨率和特征提取难度等原因,另外8个特征点由数据库中对应于点云的二维特征图像获得并映射回三维点云.
1 特征点自动提取
人脸表情识别是人工智能的一个重要分支和应用,需实现完全自动识别. 而目前一些用于表情识别的特征点却难于在三维点云上自动获取. 故采用在三维点云、深度图像以及三维点云对应的二维特征图像上分别自动获得20个特征点,并将非点云上获得的特征点映射回三维点云以获得全部需用特征点的方法,并基于这些自动获取的特征点得到25维欧氏距离作为特征向量使用支持向量机(SVM)进行分类. 算法流程图如图1所示.
需要提取的20个特征点如图2所示,其中鼻尖、鼻翼端点、嘴角、上下嘴唇、下巴、左右眼角等12个特征点由三维点云及其对应的深度图像获得;眉毛端点和上下眼皮中点等8个点由二维特征图像中获得.
1.1 三维特征点的提取
1.1.1 鼻尖点
通过一个连续的过程来获得三维点云上的12个特征点. 首先是鼻尖,由于3D-BUFE数据库中的人脸三维点云都有严格的坐标限定,即采集实验者人脸点云时人脸与正对的三维摄像机连线并指向摄像机方向为Z轴正方向,与其垂直平面为X轴、Y轴所在二维平面,并且水平方向为X轴,向右为X轴正方向,竖直向上为Y轴正方向. 坐标轴定义如图3所示(点云上的坐标原点并不一定在图示处). 故由人脸解剖学可知,人脸正面最高点,即Z轴数值最大点即为大体鼻尖坐标. 出于准确性考虑,提取Z轴坐标最大点及其邻接各点的三维坐标,取平均以获取更加准确的鼻尖三维坐标.
1.1.2 鼻翼端点
提取鼻翼两侧定义鼻子宽度的两个点. 这两个点是在一个以鼻尖为中心的42 mm×50 mm的矩形内搜索得来. 选择这个大小的搜索区域是基于Farkas[7]在著作中提到的关于成年男性鼻子高度和宽度的均值和标准差而确定的. 成年男性的鼻子宽度(μ=35 mm,σ=2.5 mm)和高度(μ=53mm,σ=3.4 mm)比成年女性都要大,故选取了以上数值为搜索区域. 在这个搜索区域中使用Laplacian of Gaussian边缘检测算法在点云对应的深度图像(range image)上提取鼻子边缘. 由于鼻子相对人脸曲面比较突兀,故可以非常准确地在深度上提取鼻子边缘. 并由鼻尖点坐标向左右水平方向搜索鼻子边缘最远点即为左右鼻翼点,如图4所示.
1.1.3 内眼角点和外眼角点
对于内眼角点和外眼角点,通过定位Peak of Gaussian Curvature来确定. 首先确定内眼角点的搜索区域. 使用已经取得的鼻尖、鼻翼点以及头部最高点(此点即为每个人脸三维点云Y值最大点,也是直立人脸最上方点),借助这些特征点以及Farkas[8]关于普通成年人面部比例的理论:对于一个普通成年人,其内眼角到鼻尖的竖直距离大约是头顶到鼻尖竖直距离的0.380 3倍,而两个内眼角之间的距离与两个鼻翼点之间的距离大约相同. 基于以上特征点和理论确定搜索区域如下:搜索区域上边界为(prny+0.380 3×1.5×|prny-vy|),下边界为(prny+0.380 3×0.33×|prny-vy|),其中prny为鼻尖的Y坐标,vy为三维点云最高点的Y坐标. 两个内眼角的水平搜索边界分别是鼻尖X轴坐标prnx以及(alx,left+0.5×|alx,left-alx,right|)和(alx,left-0.5×|alx,left-alx,right|),其中alx,left为左鼻翼点X轴坐标,alx,right为右鼻翼点X轴坐标. 两内眼角点的搜索区域及Gaussian Curvature幅度如图5(a)5(b)所示. 在此区域内的Peak of Gaussian Curvature点坐标即为内眼角点坐标. 外眼角点的提取类似于内眼角点,搜索区域上下边界与内眼角点相同,左外眼角点搜索右边界与左内眼角点搜索左边界相同,左边界为左内眼角点搜索左边界左移两内眼角点之间水平距离. 右外眼角点搜索边界与左外眼角点搜索边界类似,此处不再赘述.
1.1.4 上下嘴唇边缘中点及下巴点
由3D-BUFE数据库中各三维点云坐标系定义及人体解剖学可知,自鼻尖以下人脸侧面轮廓线坐标的Z轴高度将先降低,后升高至最高区域极值点,即上嘴唇中心点;再降低后升高至区域极值点,即下嘴唇中心点;之后第3次下降并第3次升高至区域极值点,即为下巴点. 故经过数据库中每个点云上自动获取的鼻尖点做平行于(y,z)平面的面,并取其与人脸曲面相交线鼻尖点下面一段作为搜索曲线. 首先对此曲线进行平滑处理,去除小范围内曲线升降所引起的噪声污染,并依上文提到的选取3个Z轴坐标区域极值点作为上下唇边缘中点以及下巴点,如图6所示.
1.1.5 嘴角点
通过对鼻子以下人脸Curvature(曲率)的测量,嘴角点具有高幅度的正Mean Curvature(平均曲率),如图7所示,故选取此区域平均曲率的正极值点作为嘴角点. 左右嘴角点的搜索区域如下:搜索区域上边界为鼻尖点与上唇中点连线中点坐标,下边界为下唇中点与下巴点连线中点坐标. 左嘴角点搜索区域为左鼻翼点横坐标alx,left与(alx,left+0.7×|alx,left-alx,right|)之间,右嘴角点搜索区域为右鼻翼点横坐标alx,right与(alx,left-0.7|alx,left-alx,right|)之间.
1.2 二维特征图像上特征点的提取
由于3D-BUFE数据库中点云的分辨率以及特征点提取难度等问题,选择在每个人脸点云所对应的二维特征图像(2D feature image)上自动检测左右眼上下眼皮中心点以及左右眉毛内外边界点等8个特征点. 由于三维点云及其对应的二维特征图像是由同一套立体摄影系统同时采集,有非常精确的坐标对应关系,故可以将二维图像上自动获取的特征点映射回三维点云,并将其与上一节提到的自动获取的其他12个特征点一起提取三维欧氏距离向量作为特征进行分类.
1.2.1 左右眼上下眼皮中心点
运用严超等[9]提到的水平和竖直方向投影直方图以确定眼睛区域以及使用链表来定位眼皮曲线的方法,首先确定出眼睛在二维图像上的大体方位即眼睛区域. 然后,使用二次微分算子计算眼睛区域的灰度梯度,此过程中包括平滑去噪、计算梯度以及二值化再次去噪,如此得到眼睛区域的二值图像. 之后由二次微分后的图像搜索出上眼皮曲线. 步骤如下:确定起始点与终点,以右眼为例,选取由三维点云映射过来的右眼外眼角点为起始点,右眼内眼角点为终点;使用文献[7]中所提出的链表的方法从起始点开始搜索上眼皮边缘并终止与右眼外眼角点,选取曲线上横坐标为起始点与终点横轴坐标中点处的点作为上眼皮点,如图8所示. 其余右眼下眼皮点与左眼上下眼皮点以相似方法取得.
1.2.2 左右眉毛内外边界点
最后是左右眉毛的内边缘点以及外边缘点的检测. 首先确定搜索区域,左右眉毛的搜索下边界分别为上一步中检测到的左右上眼皮点的纵坐标上移10像素;上边界为下边界向上搜索1.5倍眼睛内角点和眼睛外角点横坐标差值(1.5(|exx-enx|),其中exx为外眼角点横坐标;enx为内眼角点横坐标),即眼睛宽度. 左边眉毛的右边界点为左右两眼内角点横坐标的中点,此边界亦为右边眉毛的左边界点. 而左边眉毛的左边界点为其右边界点向左搜索2倍的眼睛宽度(2(|exx-enx|));同理,右边眉毛的右边界点为其左边界点向右搜索2倍的眼睛宽度(2(|exx-enx|)). 确定搜索区域后,分别对左右眉毛区域进行边缘检测,并取检测到的眉毛边缘的左右边界点为所需眉毛内外边界点,如图9所示.
2 特征向量
由上一节自动获取的20个特征点,选取25个点与点之间的三维欧氏距离组成25维向量作为特征,如表1所示.

表1 25个三维欧氏特征距离
之所以选择距离向量作为特征,是因其具有FACS的类似特性,如FACS中的一号Action Unit(AU):Inner Brow Raiser,就可以表征为眉毛内边界点和内眼角点之间距离的变化(表1中特征5,6);第12号AU∶Lip Corner Puller,可以表征为嘴角点与鼻翼点和外眼角点之间距离的变化(表1中特征17,18等). 类似做不同表情时,上下嘴唇终点之间距离,嘴唇中点以及鼻尖、下巴点之间的距离也会做出相应改变. 此外,为了精确起见,把从每个不同实验对象的6个不同表情点云上所提取的特征向量对该实验对象中性表情所提取特征向量做归一化,得到最终用于分类的25维特征向量.
3 实验结果及对比
使用纽约州立大学宾汉姆顿分校的3D-BUFE数据库[5]进行实验. 该数据库涵盖了100个实验对象的脸部扫描点云,包括宾汉姆顿大学和美国州立大学各院系的本科生、研究生和教职员工(比如心理学、艺术专业、计算机科学、电子工程和机械工程),但大部分的实验对象是心理学专业的本科生. 此数据库中包含了60%的女性和40%的男性,他们分别来自不同的人种,包括白种人、非洲裔、东亚裔、中东裔和南美拉丁裔等. 每个实验对象都在三维扫描系统前表现出7种不同表情:气愤、厌恶、恐惧、高兴、沮丧、吃惊以及中性表情(即什么表情都不做),如图10所示. 除了中性表情,其他表情都有4个三维扫描,依次表征表情从起始到最高点. 因此,每个实验对象对应着25个三维点云,该数据库一共包括2 500个三维表情扫描数据和各个点云对应的二维特征图像. 随机选取80个实验对象作为训练集,另外的20个对象作为验证集,如此重复10次,以10次结果的平均值为最终的分类实验结果.
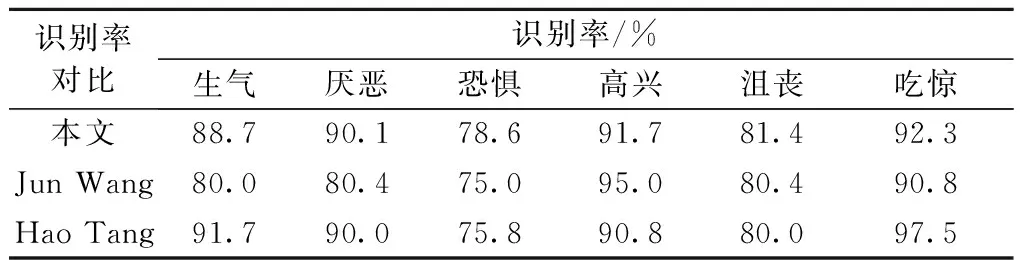
获得数据库中每个三维点云所对应的25维特征向量后,使用支持向量机(SVM)[10]作为分类器,并使用台湾大学林智仁对支持向量机的实现LIBSVM[11]进行实验. 实验结果及与Hao Tang[6]和Jun Wang等[12]的实验结果对比如表2所示. Hao Tang等在文章中使用了数据库提供的83个手动标注特征点中的23个特征点提取24个三维欧氏距离作为特征向量,并使用了Nearest Neighbor,Naïve Bayes与LDA等3个分类器分别进行分类,其中Naïve Bayes的平均分类结果最优,也选择這个分类器的分类结果作为比较. Jun Wang等使用了基于基础曲率(peak, ridge, saddle, hill, flat, ravine, pit)为特征的特征提取算法. hill可以进一步被分为convex hill, concave hill, saddle hill 和 slope hill;saddle hill又可以进一步被分解为concave saddle hill和convex saddle hill;而saddle可被分解为ridge saddle和ravine saddle,因此一共12种基础曲率. 他们根据人脸不同区域这些基础曲率的分布规律作为特征实行分类. 这两篇文章中,Hao Tang等的文章需要手动标注的特征点,故不是完全自动的识别算法,而Jun Wang等文章中使用的基础曲率是自动计算得来.
由表2的对比结果可看出自动人脸表情识别算法几乎在每一种表情的分类结果上都比Jun Wang等的自动分类结果优异;而对比Hao Tang等的非自动分类结果,实验结果也在厌恶、恐惧、高兴以及沮丧等表情的分类结果占优.
表2 本文实验结果与Hao Tang等和Jun Wang等实验结果的比较
Tab.2 Our experiments results and comparison with Jun Wang and Hao Tang’s proposal
识别率对比识别率/%生气厌恶恐惧高兴沮丧吃惊本文88.790.178.691.781.492.3JunWang80.080.475.095.080.490.8HaoTang91.790.075.890.880.097.5
4 结 论
提出了一种自动检测3D+2D特征点,并根据这些特征点获得三维欧氏距离向量作为特征向量的人脸表情识别算法,并获得了优异的表情分类识别结果. 但是仍有不尽如人意的地方,比如由于表情点云分辨率以及相关的技术限制,尚无法在点云中自动获取全部特征点,而需要借助于每个点云所对应的深度图像及二维特征图像. 下一步将尝试其他不同算法以求在三维点云上获得所有需要特征点,以摆脱二维图像的束缚. 其次,FACS的AU组合是现今普遍认为最准确的表情描述,但是由于AU数量众多,重要的就有46个之多. 而各个表情又是由这些AU中的某个或某几个组合而来,所以检测难度巨大. 一个受过专业训练的人员需要花费大量的时间才能人工标注各个表情的AU组合. 故计算机自动识别各个AU组合的难度可想而知. 虽然有难度,但由于此6种表情所需要的AU数量不多,并且可以由一些自动检测特征点的移动向量来表征,所以下一步的工作将集中在AU检测上,希望得到更加精确的自动表情分类结果.
[1] Mehrabian A. Communication without words[J]. Psychology Today, 1968,2(4):53-56.
[2] Darwin C. The expression of the emotions in man and animals[M]. New York: Philosophical Library, 1872.
[3] Ekman P. Universals and cultural differences in facial expressions of emotion[J]. Nebraska Symposium on Motivation, 1971,19:207-282.
[4] Ekman P, Friesen W. Facial action coding system: a technique for the measurement of facial movement[M]. Palo Alto: Consulting Psychologists Press, 1978.
[5] Yin L, Wei X, Sun Y, et al. A 3D facial expression database for facial behavior research[C]∥Proceedings of International Conference on Automatic Face and Gesture Recognition. Southampton, UK: [s.n.], 2006:211-216.
[6] Hao T, Huang T. 3D facial expression recognition based on automatically selected features[C]∥Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, Alaska, USA: [s.n.], 2008:1-8.
[7] Farkas L.Anthropometry of the head and face[M]. New York: Raven Press, 1994.
[8] Farkas L.Anthropometric facial proportions in medicine[M]. [S.l.]: Thomas Books, 1987.
[9] 严超,苏广大.人脸特征的定位与提取[J].中国图像图形学报,1998,3(5):375-380.
Yan Chao, Su Guangda. Facial feature location and extraction from front-view images[J]. Journal of Image and Graphics, 1998,3(5):375-380. (in Chinese)
[10] Cortes C, Vapnik V. Support-vector networks[J]. Machine Learning, 1995,20:273-297.
[11] Chang C, Lin C. LIBSVM: a library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology, 2011,27(2):1-27.
[12] Wang J, Yin L, Wei X. 3D facial expression recognition based on primitive surface feature distribution[C]∥Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. New York: [s.n.], 2006:1399-1406.
(责任编辑:刘芳)
3D Expression Recognition Based on Automatically Detected Facial Points
YUE Lei, SHEN Ting-zhi
(School of Information and Electronics, Beijing Institute of Technology, Beijing 100081, China)
In order to deal with automatic facial expression recognition task, a 3D facial expression recognition algorithm was proposed based on automatically detected fiducial points from 3D mesh models, range images and the corresponding 2D feature images. First, the fiducial points were automatically detected on the 3D mesh models, range images and the corresponding 2D feature images. And some fiducial points got from non-mesh models were mapped back to 3D mesh models to get full fiducial points. Then, Euclidian distances between these fiducial points were extracted as feature to feed the SVM classifier. Compared with two state-of-the-art algorithms, the classification results show that the fully automatic algorithm can achieve highly competitive classification rate. The average recognition rate was 87.1%, especially the recognition rate for surprise and happiness expression were 92.3% and 91.7% respectively.
3D expression recognition; 3D fiducial point; 3D Euclidian distance; support vector machine
2014-03-05
国家自然科学基金资助项目(60772066)
岳雷(1983—),男,博士,E-mail:napoylei@163.com.
TP 37
A
1001-0645(2016)05-0508-06
10.15918/j.tbit1001-0645.2016.05.013
猜你喜欢
中国医疗美容(2022年3期)2022-05-20
少儿美术·书法版(2021年9期)2021-10-20
快乐作文(5.6年级)(2021年8期)2021-09-03
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
中外文摘(2019年3期)2019-11-12
中国美容医学(2019年1期)2019-03-01
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
