
VDNS: 一种跨平台的固件漏洞关联算法
2016-11-14 02:12刘中金王猛涛石志强孙利民
计算机研究与发展 2016年10期
常 青 刘中金 王猛涛 陈 昱 石志强 孙利民
1(物联网信息安全技术北京市重点实验室(中国科学院信息工程研究所) 北京 100093)2(中国科学院信息工程研究所 北京 100093)3(中国科学院大学 北京 100049)4(国家计算机网络应急技术处理协调中心 北京 100029) (changqing@iie.ac.cn)
VDNS: 一种跨平台的固件漏洞关联算法
常 青1,2,3刘中金4王猛涛1,2,3陈 昱1,2,3石志强1,2,3孙利民1,2,3
1(物联网信息安全技术北京市重点实验室(中国科学院信息工程研究所) 北京 100093)2(中国科学院信息工程研究所 北京 100093)3(中国科学院大学 北京 100049)4(国家计算机网络应急技术处理协调中心 北京 100029) (changqing@iie.ac.cn)
当前,越来越多的物联网厂商将第三方代码库编译并部署在不同平台上.现有研究主要集中在同平台固件漏洞关联场景,不能直接用于检测其他平台上的同源漏洞,而跨平台场景的研究则刚刚起步.针对现有跨平台方法准确率低的问题,提出基于神经网络和局部调用结构匹配的2阶段跨平台固件漏洞关联方法(vulnerability detection based on neural networks and structure matching, VDNS).以函数为最小关联单元,对函数间调用图、函数内控制流图、函数基本信息进行特征选择和数值化处理,并采用神经网络计算待匹配函数对的相似程度,在此基础上采用结构化匹配方法进一步提高匹配精度.实验结果表明:该方法在二进制文件OpenSSL上性能指标Top1从32.1%提高至76.49%;采用5个漏洞函数对OpenSSL进行关联的Rank值均为1;采用4个常见的路由器漏洞函数在372个D-Link路由器固件上进行关联获得了良好的实验效果.
跨平台;漏洞关联;特征选择;神经网络;二分图匹配
固件(firmware)是嵌入在硬件设备中的软件,表现为存储于非易失存储器中的二进制程序,为上层软件有效使用硬件设备提供调用接口,是电子系统的重要组成部分,计算机系统中的BIOS和扩展ROM中的程序,以及常见的网络设备如路由器、交换机、网络摄像头的可执行程序都是典型的固件.固件方便了用户的使用,同时也为信息系统的安全留下隐患.开放式Web应用程序安全项目(open Web application security project, OWASP)的调查结果显示,2014年排名前10位的针对物联网设备系统的漏洞威胁和攻击中,对软件和嵌入式设备固件的攻击排名第9位[1].ZoomEye的统计报告指出,2013年10月发生的D-Link路由器后门事件中,受影响的路由器型号多达10多个,可在公网搜索访问到的6万多台路由器中受影响的多达23%[2].愈来愈多因恶意固件导致的安全事件的发生,让人们认识到固件安全防护的重要性.
固件漏洞关联是指利用已知固件中存在的漏洞检测出其他固件中存在的同源漏洞.由于固件源代码难以获取,一般采用二进制程序相似性检测等技术,从待检测固件的二进制文件中搜索并定位包含已知漏洞的代码片段.早期的应用场景中,包含漏洞函数的二进制文件和待检测的二进制文件是针对同平台进行编译的,具有相同的指令集.按分析对象的不同,漏洞关联方法包括比特流比对[3-4]、指令序列比对[5-12]和动态插装[13]等.比特流比对技术研究01序列的相似性,采用滑动窗口获得的01序列作为特征计算相似度;指令序列比对技术研究汇编语句的相似程度;动态插装技术则模拟程序的动态执行过程,比较同环境下程序执行带来的“副作用”的相似程度.
当前,越来越多的物联网厂商将第三方代码库编译并部署在不同的CPU平台上,如何利用1个平台(如x86)上的漏洞函数去关联其他平台(如ARM,MIPS等)上的同源漏洞变得越来越重要.然而,现有的同平台漏洞关联方法并不能直接应用到跨平台场景中来:比特流比对技术分析的对象是比特流,它与平台采用的编码方式相关;指令序列比对技术分析的对象是指令序列,它与平台采用的指令集相关;动态插装技术分析的是动态分析过程的中间结果,受限于分析工具的平台兼容性,例如动态插装工具PIN仅支持x86平台.2015年Pewny等人首次提出基于语义的跨平台漏洞关联方法[14],采用了提升中间语言表示、转语义表达式、数值采样和最小Hash加速等技术,将二进制代码相似性检测问题转化为基本块的语义信息比较问题,使用该方法对心脏流血漏洞函数进行关联获得了不错的效果.由于采用了基于可信基点的基本块扩张算法,对平台不同导致的函数内部控制流图细节异构敏感,即在图匹配的过程中不能跳过不匹配的代码块,重新找到比较的开始点,导致后面的匹配全不正确,在对二进制文件OpenSSL进行关联时其性能指标Top1仅达到32.1%.
针对当前方法准确率不高的问题,本文提出一种基于神经网络和局部调用结构匹配的2阶段跨平台固件漏洞关联方法(vulnerability detection based on neural networks and structure matching, VDNS),该方法不依赖特定的指令集,可以跨平台进行固件漏洞关联.实验证明:该方法具有良好的关联效果.
1 跨平台的固件漏洞关联框架
本文提出的固件漏洞关联框架包括2个阶段:1)基于神经网络的函数数值相似度的计算阶段;2)基于局部调用结构匹配的函数整体相似度计算阶段.
1个固件下载解压过滤后包含多个二进制文件,对固件进行漏洞关联等同于对固件包含的二进制文件进行漏洞关联.二进制文件在逆向分析后被划分为多个函数.框架输入为2个二进制文件F和G,假设F包含已知的漏洞函数f,需要对G中的所有函数进行漏洞关联,即目的是获得漏洞函数f与G中所有待检测函数g的相似程度,记f,g为待匹配函数,(f,g)为待匹配函数对.图1是VDNS整体框架.
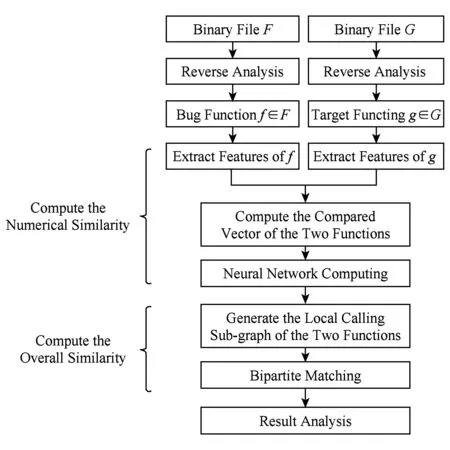
Fig. 1 The framework of VDNS.图1 VDNS整体框架
在函数数值相似度计算阶段,对二进制文件中每个函数的函数间调用关系、函数内控制流图、函数基本信息进行数值化处理和特征提取,其中特征的表现形式有数量型、集合型和序列型.针对不同的表现形式,分别采用欧氏距离、Jaccard系数和最长公共子序列占比这3种度量方法计算待匹配函数对(f,g)各维特征的相似程度得到相似度向量.基于相似度向量采用ReliefF算法进行特征选择.筛选后的相似度向量作为神经网络的输入,将神经网络的输出作为待匹配函数对(f,g)的数值相似度.在进行第2阶段之前,可以根据数值相似度结果对规模较大的待检测函数集进行初步筛选后再进行较为精确的结构化匹配.
在函数整体相似度计算阶段,分别在二进制文件F和G生成的函数调用图中截取以待匹配函数f和g为中心的局部调用结构,转化为分层赋权二分图,将其最大权匹配作为最终的整体相似度得分.
在进行关联结果分析时,可以根据数值相似度得分进行关联分析,也可以根据整体相似度得分进行关联分析.数值相似度计算是整体相似度计算过程的中间步骤,由于计算数值相似度不需要进行后期的子图匹配,因此速度较整体相似度快.但整体相似度考虑了函数调用图的结构信息,准确率高.在实际应用中,可以根据具体情况进行选择.
由于该方法在第1阶段较为全面地提取了函数在函数调用图、函数基本属性和函数控制流图3方面信息,并进行了特征选择,使得提取的特征具有一定的区分能力,同时,这些特征不依赖指令集,具有一定的跨平台能力,可以对2个不同指令集的二进制代码进行相似性度量.而在第2阶段采用的局部调用结构匹配算法结合了函数调用图层面的局部结构信息,考虑了与待匹配函数对存在调用关系的其他函数对的相似程度对待匹配函数对的影响,提高了关联准确率.在第1阶段计算出数值相似度的基础上,可以对规模较大的待检测函数集进行初步筛选,再进行较为精确的局部调用结构匹配,提高整体性能.
2 基于神经网络的函数数值相似度计算
2.1 提取函数数值特征
函数数值特征是指函数中可以进行数值化处理的特征,如指令个数、基本块数、栈大小等.函数数值特征提取的难点和思路如下:
1) 提取的特征应忽略平台不同带来的差异.既使是同一份源码针对不同平台编译得到的二进制文件反汇编后呈现的汇编程序,其指令集、寄存器、寻址方式和函数内控制流图也存在很大差异.这就要求提取的特征能忽略平台不同带来的差异.而比特流、指令集或寄存器名称等严重依赖平台,因此选择的特征不能基于这些对象.二进制文件进行反汇编和信息提取后,大部分信息表达为1个函数调用图、一系列汇编形式的函数和一系列函数控制流图.经实验观察发现,同一份源码针对不同平台编译,函数间调用关系基本保持一致;函数的某些基本属性,例如调用的字符串,也具有跨平台特性;至于函数控制流图,平台不同可能导致图的细节发生变化,但某些描述性特征,例如规模大小等不会发生巨大变化.因此,本文主要从函数调用关系、函数基本信息和函数控制流图信息3个方面入手,提取平台依赖较弱的特征.
2) 对汇编程序、图的数值化处理.由于分析的对象是汇编程序和图,无法直接输入神经网络,这就有必要对汇编程序和图进行数值化处理.汇编程序和图提供的数值特征众多,各特征的跨平台性及区分度也不尽相同.对汇编程序,可以对栈、字符串、特殊指令所占比例等方面提取;对于图,可以从点边信息、度信息和路径信息进行分析.
具体的提取过程如下:
1) 函数调用图
函数调用图是1个有向图,节点表示函数,有向边表示函数间调用关系.对函数调用图进行分析,提取该函数被其他函数调用的次数callt和该函数调用其他函数的次数callf,以及去重后次数callt2和callf2,构成调用关系特征.
2) 函数基本属性
分析函数基本信息,计算栈空间stack、代码量code、调用字符串个数str和调用的字符串集合strSet.对函数进行指令分析,统计指令个数inst、跳转指令个数jump、跳转指令占比jumpp,结合式(1)计算指令熵instEpt和跳转指令熵jumpEpt,Pk表示(跳转)指令k的占比,以上特征构成函数基本特征.
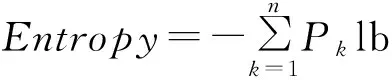
(1)
3) 函数控制流图
1个函数对应1个函数控制流图(control flow graph, CFG),图中每个节点对应函数中的1个基本块,节点间的有向边对应基本块间的跳转关系.从点边、度和路径3个方面对函数控制流图进行分析.
对函数控制流图进行点边分析.计算节点数node和边数edge;按式(2)计算图密度density,以上构成CFG图点边属性特征.
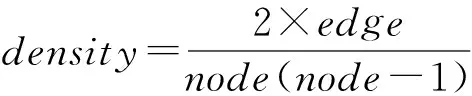
(2)
对函数控制流图进行路径分析,采用Floyd或Dijkstra算法计算入口基本块到任意基本块的最小距离,构造升序距离序列pathList,计算图的平均路径长度avePath、图直径(即最长路径)diameter,按式(3)计算图链路效率effect,以上构成CFG图路径特征.
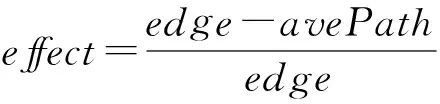
(3)
对函数控制流图进行度分析,统计每个节点的出度、入度,将CFG图转化为无向图,计算无向CFG图的每个节点的度,构成入度升序序列iList、出度升序序列oList、无向度升序序列uList.由3种度序列,分别计算3种最大度imax,omax,umax和3种平均度ieva,oeva,ueva;由式(1)计算无向图度的熵uEpt.按式(4)(5)计算图的聚类系数cluster[15],其中,c表示节点k的所有邻居节点构成的无向CFG图的子图边数,dk表示节点k的度,以上构成CFG图度特征.
(4)
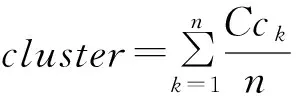
(5)
以上共计31维特征作为1个函数的数值特征.
2.2 计算待匹配函数对的相似度向量
由于本文待解决的是每个待比较的函数对(f,g)的相似性度量问题,不是分类问题,因此神经网络的输入不是1个函数的31维特征,而是待比较函数对(f,g)的每维特征的相似度构成的相似度向量.以上提取的31维特征有3种表现形式:数量型、序列型和集合型,本文采用不同的相似度度量方法:
1) 针对序列型特征:pathList,iList,oList,uList.采用式(6)计算待比较函数f和g的序列型特征L1和L2的最长公共子序列(LCS)占比作为相似度[16]:
(6)
其中,c0为0,1之间的1个常量.
2) 针对集合型特征:strSet.计算待比较函数f和g的strSet特征sf和sg的Jaccard系数[17]作为相似度:
(7)
其中,c1为0,1之间的1个常量.
3) 针对26维特征数量型特征.采用式(8)对待比较函数f和g的数量型特征Ff和Fg进行相似度计算:
(8)
其中,c2为0,1之间的1个常量.
这样便得到了31维特征的相似程度,取值范围是[0,1],构成了每个待比较的函数对(f,g)的相似度特征向量.待比较的函数对(f,g)相似程度越高,按以上方法计算得到的特征相似度越高.
2.3 特征选择
特征选择是从原始特征中选择出一些最有效的特征以降低数据集维度的过程,是提高学习算法性能的重要手段.以上31维特征是根据经验进行选取的,在对未知样本进行预测之前,应决定哪些特征应该采用、哪些特征应该忽略.本文采用ReliefF算法[18-19]进行特征选择,同时采用直观的统计方法辅证特征选择的合理性.由于神经网络输入是相似度向量,因此以相似度向量为分析对象进行特征选择.
ReliefF算法是一种特征选择算法,基于特征对近距离样本的区分能力赋予特征不同的权重.权重越大,表示该特征的分类能力越强,权重小于某个阈值的特征应被移除.本文采用ReliefF算法计算各个特征相似度的重要程度,实验数据集采用ARM×MIPS的OpenSSL.31个特征的类型和采用ReliefF算法计算31个特征的权重结果如表1和图2所示.如图2所示,“·”表示每次迭代对应编号的特征权重,“*”表示20次迭代的平均权重.权重低于0.015的特征,包括指令熵instEpt、跳转指令熵jumpEpt、度熵uEpt、平均入度ieva、平均出度oeva、最大出度omax、聚类系数cluster、链路效率effect,这8个特征对近距离样本的区分能力不高,将其移除.其中指令熵和跳转指令熵代表了函数的指令分布情况,这2个特征显著性不高说明不同函数的指令分布差异性不大.而聚类系数则代表了函数控制流图中三角结构的密度,这与函数循环结构密度和形状有关,该特征显著性不高说明不同函数的分支结构差异性不大.
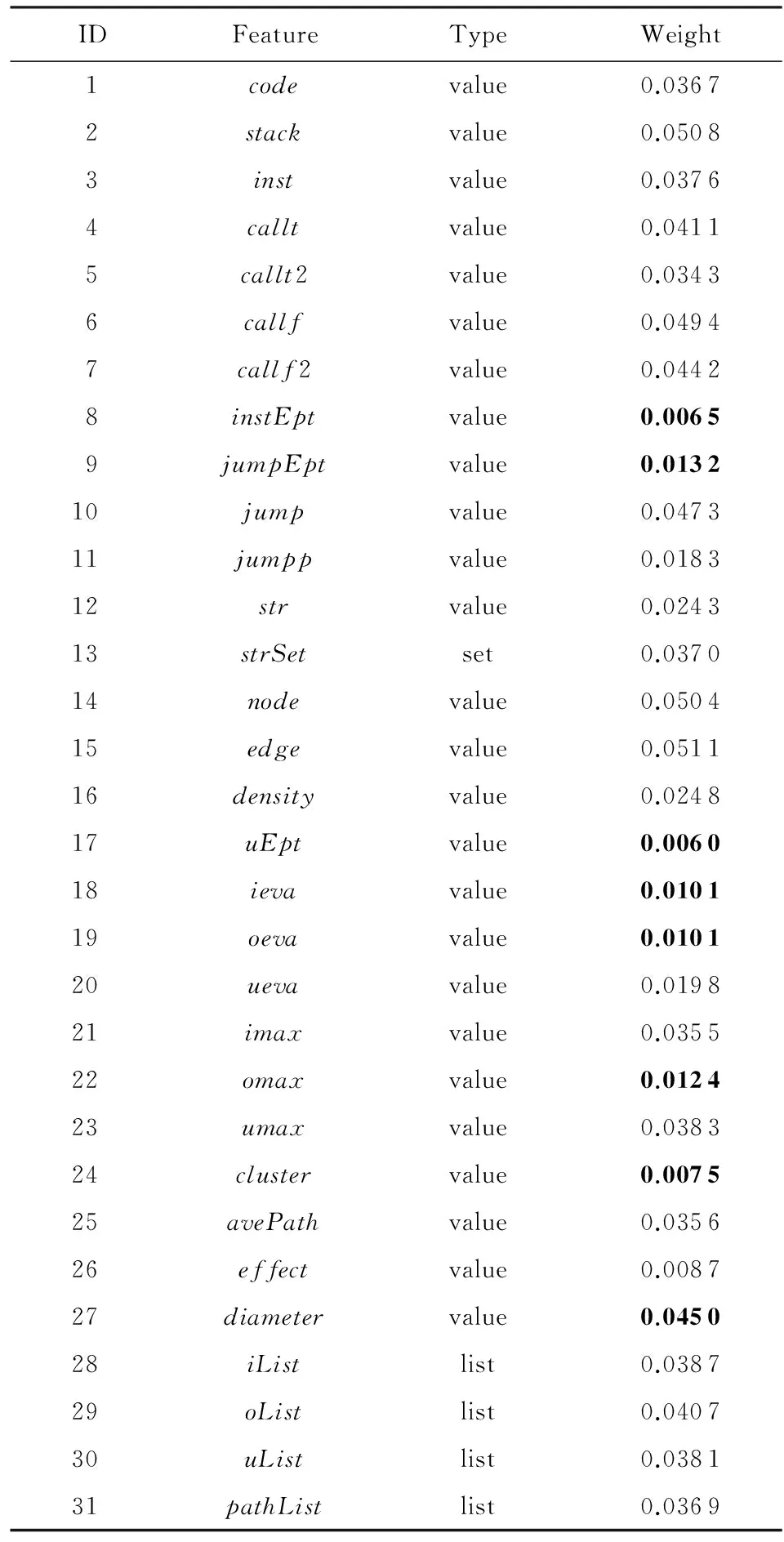
Table 1 The Table of Weight of Features Based on ReliefF
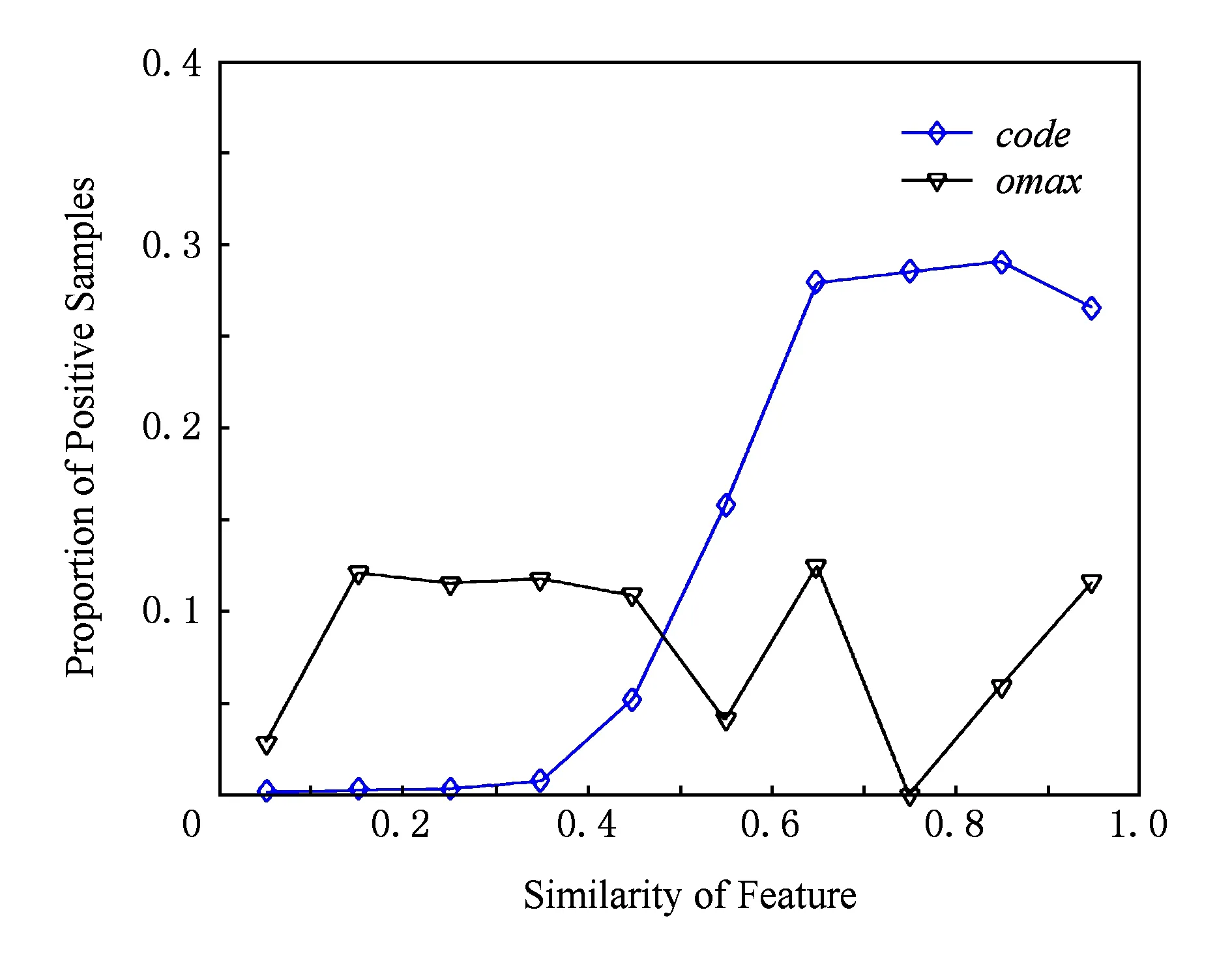
Fig. 3 Separating capacity of code and omax.图3 代码量code和最大出度omax的区分能力示意图
采用直观的统计结果辅证特征选择的合理性.相似度向量的每个元素取值区间是[0,1],值越大,代表2个待比较函数在该特征上相似程度越高.如果大量正样本特征取值很高,则认为这一特征是好的特征.本文将0~1区间均分为10个小区间,统计每个小区间正样本的比例.落入各取值区间的正样本比例应随着取值区间的变大而越大.以代码量特征code和最大出度特征omax为例,考察特征在不同取值区间包含的正样本比例.如图3所示,菱形折线表示代码量code的区分能力.随着代码量相似度取值区间的增大,落入对应区间的正样本比例呈递增趋势,说明该特征有较好的区分能力;倒三角折线表示最大出度omax的区分能力,其正样本比例与特征相似度的取值区间的递增没有正相关性,因此不具有良好的区分能力,这与ReliefF算法的结果相对应.
2.4 神经网络预测
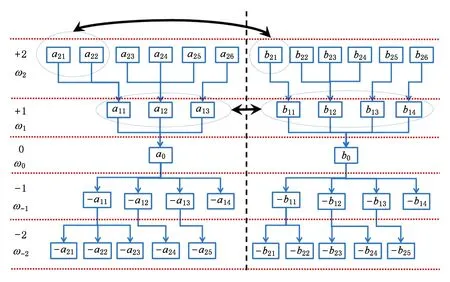
Fig. 5 The local calling structure matching.图5 局部调用结构匹配示意图
神经网络采用反向传播(back propagation, BP)神经网络[20],可以实现输入和输出间的任意非线性映射,网络由输入层、隐层和输出层的节点构成,如图4所示.将筛选得到的23维特征的相似度向量作为神经网络的输入,每维特征相似度都从不同方面反映了函数之间的相似性.通过神经网络整合这些相似度获得1个值,作为待比较函数对(f,g)的数值相似度.

Fig. 4 The structure of BP neural network.图4 BP神经网络结构
3 基于局部调用结构匹配的整体相似度计算
经实验观察发现,相比函数内部控制流图,函数调用图对平台和优化选项更具鲁棒性.文献[14]在函数控制流图层面上采用了基于可信基点的基本块扩张算法,对函数控制流图异构现象敏感,关联效果并不理想.这是由于在图匹配的过程中,算法不能跳过一小段不匹配的代码块,重新找到比较的开始点.这就意味着,一旦有局部异构,其后面的匹配结果全不正确.因此,本文在对平台和优化选项鲁棒性较好的函数调用图层级上进行结构匹配.
局部调用结构是指在函数调用图中以待匹配函数为中心,与其有调用关系的函数构成的子图,按调用关系的跳数可分为1级调用(直接调用)、2级调用等.基于局部调用结构匹配计算整体相似度是指以函数数值相似度为基础,计算待比较函数对的局部调用子图的相似程度.本文假设距离待匹配函数越近的函数对匹配的贡献越大,采用分层构造赋权二分图求最大权匹配的方法,具体流程如下:
1) 从函数调用图中截取待比较函数的局部结构信息构成2个结构子图.
2) 将截取的结构子图按离待比较函数的跳数分为+1层、+2层等和-1层、-2层等,并按距离跳数赋权重ω+1,ω+2等和ω-1,ω-2等.其中待匹配节点对为0层,权重为ω0.
3) 逆调用方向,从距离待匹配节点对最近+1层开始,将2个节点集抽象为赋权完全二分图,其中边权为数值相似度.采用Kuhn-Munkres算法[21]计算该赋权完全二分图的最大权匹配作为该图的相似度,并基于节点匹配结果对+2层的节点集构造赋权二分图,计算最大权匹配,直至到达距离中心节点最远的一层为止.
4) 顺调用方向,具体步骤同3).
5) 计算所有匹配节点的相似度加权均值作为待比较函数的整体相似度.
如图5所示,计算函数a0和b0的整体相似度.从+1层开始,将由函数a11,a12,a13构成的节点集和由函数b11,b12,b13,b14构成的节点集转化为赋权二分图,计算最大权匹配.假设函数a11与函数b11匹配,那么下一步将计算调用函数a11的函数a21,a22构成的节点集和调用函数b11的函数b21构成的节点集的最大权匹配.
理论上局部调用结构的阶数越多,附加信息越多,匹配结果应越精确.但事实上,随着阶数的增加,前一层二分图匹配的误差会传递到后一层,这将导致关联结果变差,并且阶数的增加意味着时间成本的增加.分析局部调用结构的阶数对算法时间复杂度的影响,计算第n-1层节点向第n层扩张的时间复杂度.设每层节点向外平均扩张m个节点,第n层共有mn个节点,需要进行mn-1次二分图匹配,每次匹配的时间复杂度是O(m3),总共的时间复杂度是O(mn+2),随阶数指数级增长.因此,在进行局部调用结构匹配时应同时考虑关联精度和时间成本.实验表明,2阶能够取得良好的关联效果.
4 实验与结果分析
实验主要验证VDNS的漏洞关联性能,所涉及的平台包括x86,ARM和MIPS.
4.1 实验设置
1) 实验设备和实现
实验所用台式机配置是Intel®CoreTMi7-4790 CPU @3.60 GHz 3.5 GHz,8 GB内存.在64位Window平台上采用python语言实现了VDNS.利用反汇编软件IDA Pro 6.6对二进制文件进行逆向分析,编写IDA插件进行特征提取;神经网络采用Matlab R2014b提供的神经网络工具箱完成.
2) 关联模式的定义
引入1个概念:关联模式,它描述了待匹配函数f和g所在的二进制文件F和G的平台和优化选项等信息.例如,采用针对x86平台编译的二进制文件F与针对MIPS平台编译的二进制文件G相关联构成的训练集训练神经网络,记“x86×MIPS”为训练集的关联模式.如果应用场景是将x86平台的二进制文件F中函数f作为漏洞函数,对MIPS平台的二进制文件G的函数g作漏洞关联,记“x86×MIPS”为测试集的关联模式.本文的实验数据建立在已知测试集的关联模式的假设之上,采用同关联模式的神经网络进行计算.本文将在4.6节验证即使训练集和测试集的关联模式不同,其关联结果仍可满足实际需求.
3) 训练集的构造
本文实验所用的训练集采用BusyBox v1.21.1.以x86×MIPS关联模式的训练集为例,给出具体的构造过程.将BusyBox v1.21.1源码针对x86平台和MIPS平台进行编译得到二进制文件F和G.对于F中每一函数f,其在G中同名函数f′即为f真正匹配的函数.取(f,f′)的特征相似度向量为正样本,标签为1;在G中随机取10个函数gi≠f′,i=1,2,…,10,这10个函数对(f,g)的特征相似度向量作为负样本,标签为0.正负样本比例为1∶10.
4) 神经网络的参数设置
神经网络的输入层和输出层分别含有23个节点和1个节点.隐含层50个节点为经验值,与实验的样本有关,可根据具体情况调节隐含层的节点数.
5) 动态链接的函数处理
函数调用图中某些节点是动态链接的函数,二进制文件中不包含其函数体,不能直接对其特征提取.本文实验中设定涉及动态链接函数的函数对的相似度为1个常量.
4.2 评价指标
为了和文献[14]的结果对比,我们采用文献[14]所用的评价指标:Rank和Top,定义如下:
设漏洞函数集合为F,待检测函数集合为G,对F中的某个漏洞函数f,计算f与G中所有函数的相似度.记与漏洞函数f真正匹配的G中函数f′的相似度排名为漏洞函数f的Rank值,Rank值越小表示关联效果越好,Rank值为1表示关联效果最好.
统计F中所有漏洞函数的Rank值,如果F中有y%的漏洞函数的Rank值不大于x,记F的Topx值为y%.y%取值范围为0~1,y%越大表示关联效果越好.通常用Top1,Top10和Top100描述漏洞函数集合F的整体关联情况.
4.3 时间复杂度分析
由于本文在计算数值和整体相似度时是将函数两两进行比较,时间复杂度是O(nm),其中n是漏洞函数的个数,m是待检测的固件函数的个数,这与文献[14]相同.由于实际应用中漏洞函数个数较少,所以本文方法可以应用于大规模固件函数漏洞检测.
4.4 跨平台漏洞关联实验
实验主要验证该方法能够在跨平台场景下有效地漏洞关联,分为2个部分:二进制文件OpenSSL的函数关联实验和真实漏洞函数的关联实验.
1) 二进制文件OpenSSL的函数关联实验
实验思路是采用同一份源码针对不同平台进行编译得到2个二进制文件F和G,则与F中函数f真正匹配的函数是G中f的同名函数f′.匹配F的所有函数与G的所有函数,计算F的Top1,Top10和Top100描述整体关联情况.为了与文献[14]进行结果对比,测试采用的二进制文件为OpenSSL,版本是v1.0.1f.
图6展示了关联模式为ARM×MIPS的Rank值的累计分布函数图,横轴表示x,纵轴表示Topx的值.文献[14]中的实验结果是Top1=32.1%,Top10=56.1%,Top100=80.0%.从图6中可见,在相同配置下,该方法计算得到的数值相似度是Top1=39.26%,Top10=69.11%,Top100=83.70%;该方法计算得到的整体相似度是Top1=76.49%,Top10=85.07%,Top100=88.10%.在ARM×MIPS关联模式下,无论是数值相似度还是整体相似度,本文的实验结果都优于文献[14].由于文献[14]没有给出OpenSSL在其他关联模式下的实验结果,我们仅给出本文方法的实验结果,如表2所示,可见关联效果良好.
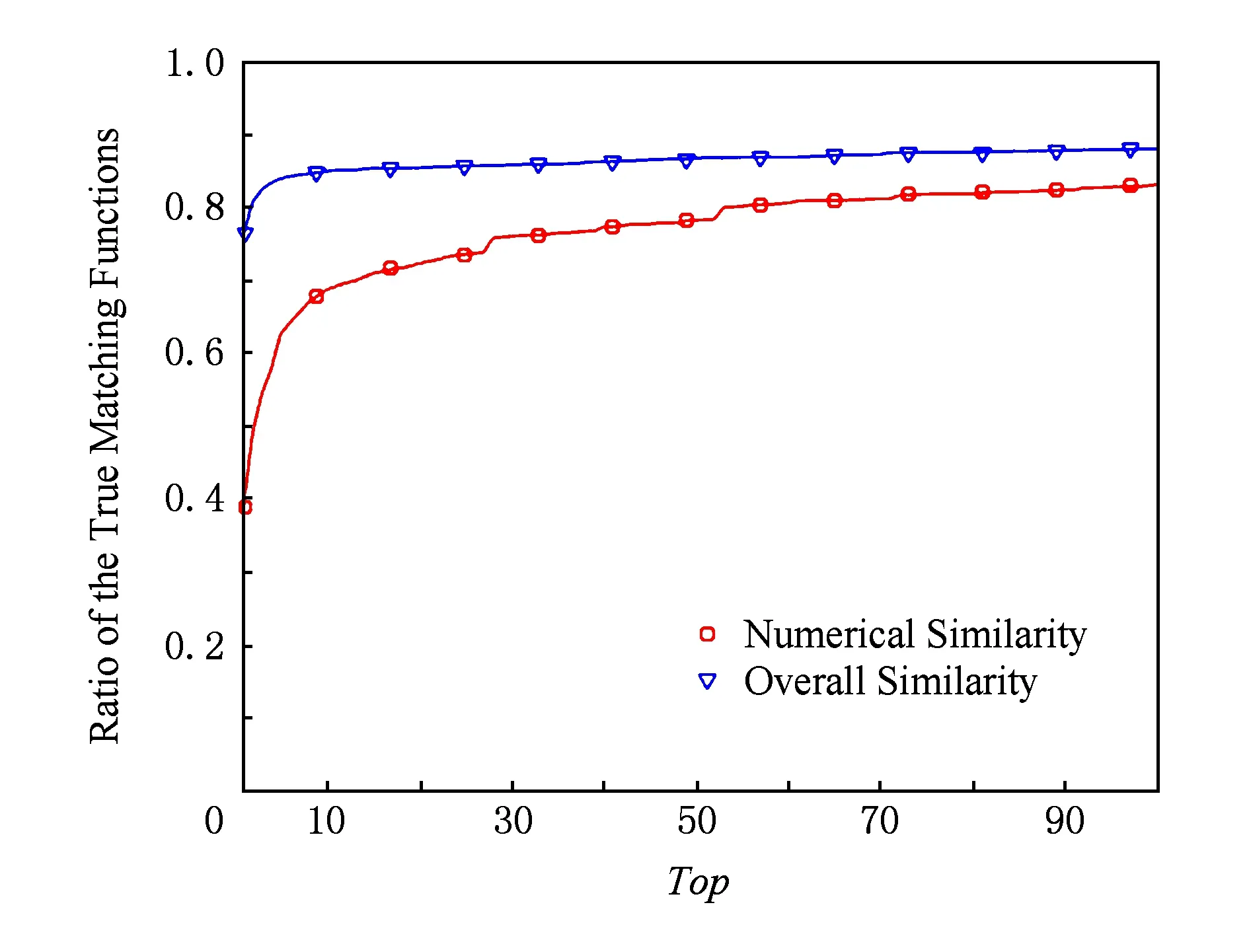
Fig. 6 Cumulative distribution function of ARM×MIPS.图6 ARM×MIPS关联模式下的累计分布图
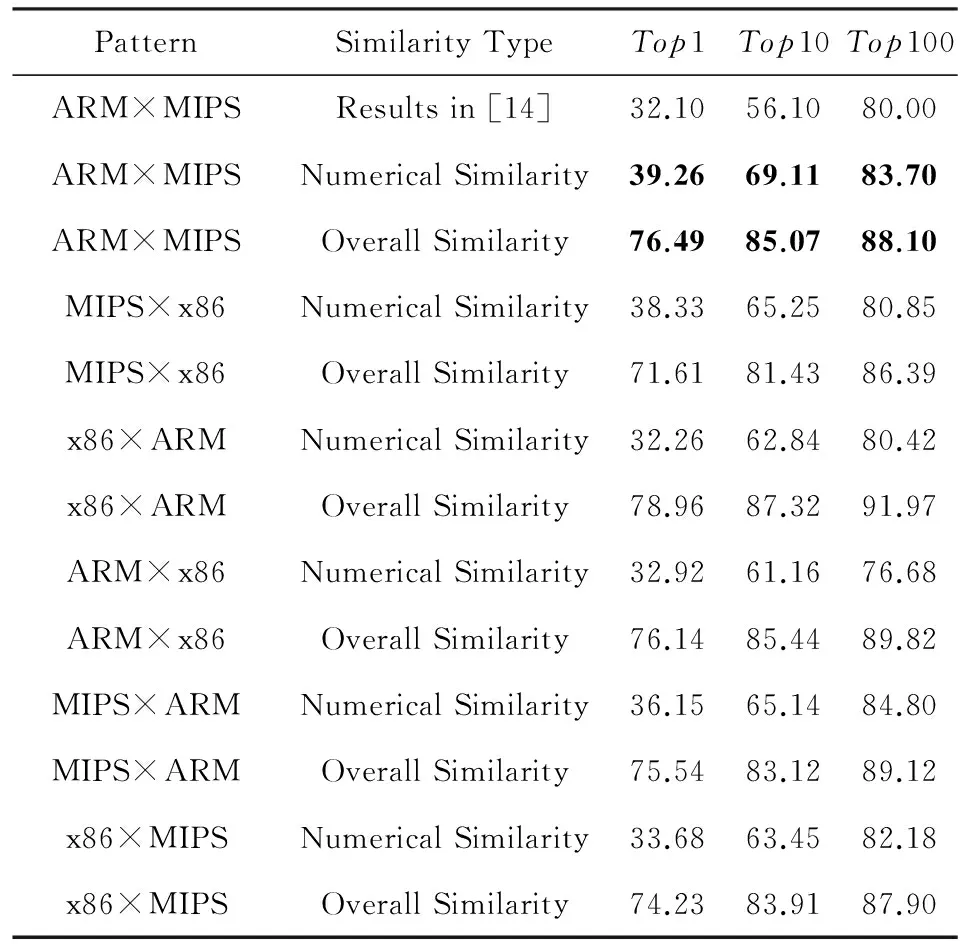
PatternSimilarityTypeTop1Top10Top100ARM×MIPSResultsin[14]32.1056.1080.00ARM×MIPSNumericalSimilarity39.2669.1183.70ARM×MIPSOverallSimilarity76.4985.0788.10MIPS×x86NumericalSimilarity38.3365.2580.85MIPS×x86OverallSimilarity71.6181.4386.39x86×ARMNumericalSimilarity32.2662.8480.42x86×ARMOverallSimilarity78.9687.3291.97ARM×x86NumericalSimilarity32.9261.1676.68ARM×x86OverallSimilarity76.1485.4489.82MIPS×ARMNumericalSimilarity36.1565.1484.80MIPS×ARMOverallSimilarity75.5483.1289.12x86×MIPSNumericalSimilarity33.6863.4582.18x86×MIPSOverallSimilarity74.2383.9187.90
2) 真实漏洞函数的关联实验
为了说明该方法对真实漏洞函数的关联能力,本文收集了二进制文件OpenSSL中5个漏洞函数,具体信息如表3所示.对二进制文件OpenSSL进行关联,计算不同跨平台关联模式下5个漏洞函数的Rank值;实验表明,除了漏洞函数X509_verify之外,其他4个漏洞函数的数值相似度Rank值保持在10以内,整体相似度的Rank值为1,关联效果良好,具体如表4所示.
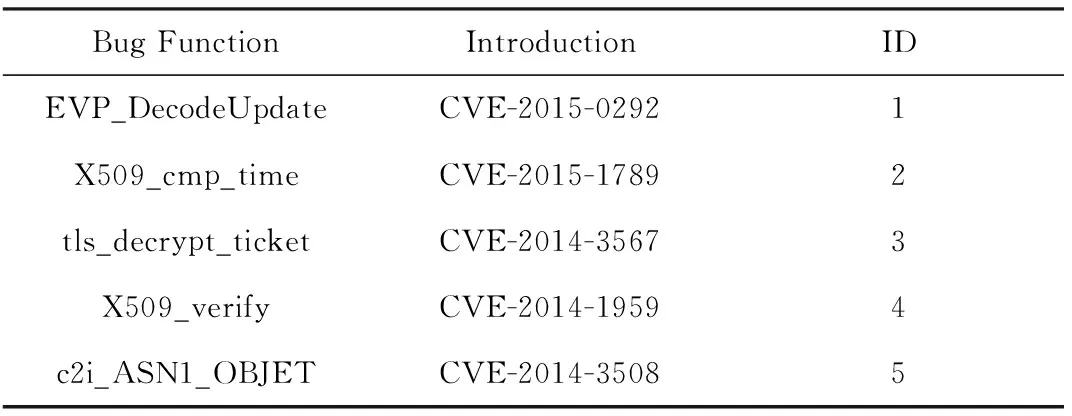
Table 3 Five Vulnerability Functions in OpenSSL
Table 4 Search Results of Five Vulnerability Functions in OpenSSL
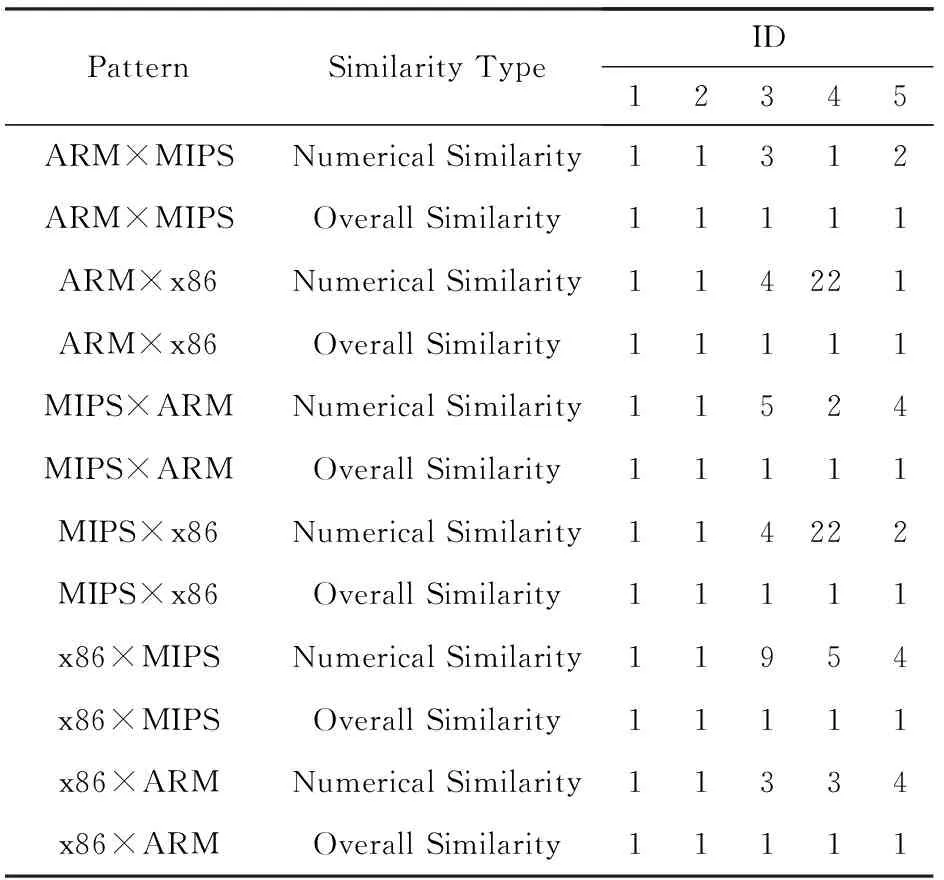
表4 OpenSSL的5个漏洞函数的Rank值列表
4.5 在真实固件中关联真实漏洞的关联实验
实验主要验证该方法在真实情况下,即采用真实漏洞函数在真实固件中进行关联,具有良好的关联效果.实验过程如下:
1) 选择D-Link路由器固件中常见的4个漏洞函数,如表5所示:
Table 5 Four Vulnerability Functions in D-Link Router Firmware
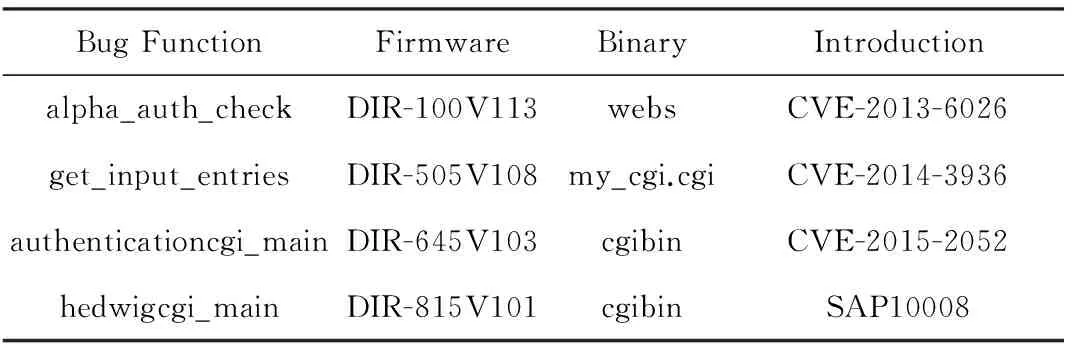
表5 D-Link路由器固件中4个漏洞函数列表
2) 从D-Link路由器固件中随机抽选372个MIPS平台的固件,筛选条件为文件名包含“cgi”和“web”子串的ELF文件,共计得到305个二进制文件共74 006个函数,其中漏洞函数同名函数个数n分别为29,28,51,58;

Fig. 7 Searching results of four vulnerability functions in routers.图7 4个漏洞函数在路由器固件中的关联结果
3) 分别计算1)中每个漏洞函数与这74 006个函数的数值相似度并进行排序.
设74 006个函数中与漏洞函数同名的函数个数为n,将得分最高的前n个函数中同名函数的个数m作为实验结果的评价指标.理想情况下,得分最高的前n个函数中同名函数的个数应该为n,即这n个同名函数的数值相似度在74 006个函数中排在了前n位.m取值在0~n之间,m越接近n说明关联效果越好.实验表明,得分最高的前n个函数中同名函数个数为29,22,37,49,如图7所示.以漏洞函数alpha_auth_check为例,其同名函数个数为29,在进行漏洞关联过程中,所有同名函数在74 006个函数中排到了前29,表明关联效果良好.
4.6 已知关联模式对关联结果的影响
4.5节的实验结果建立在已知关联模式的条件下,但在实际应用中存在未知关联模式的情况.本实验将验证训练集和测试集关联模式不同时,包括平台(ARM,MIPS,x86)不同和优化选项(-O0,-O1,-O2,-O3)不同,该方法仍能保持良好的关联效果.测试集的关联模式是ARM-O0×MIPS-O2,实验将采用不同关联模式的训练集训练好的神经网络计算表3中5个漏洞函数的数值相似度的Rank值.
表6表示优化选项的关联模式为-O0×-O2时,改变平台的关联模式的实验结果.第1列表示漏洞函数的平台,项目栏表示待关联函数的平台,表格数据表示表3中5个漏洞函数的数值相似度的Rank值.例如行1、列4的表格内容是1,1,1,1,2,这表示训练集的关联模式为ARM-O0×x86-O2,所在的二进制文件平台是ARM、优化选项是-O0的5个漏洞函数,在平台是MIPS、优化选项为-O2的二进制文件OpenSSL中的关联结果分别是1,1,1,1,2.黑体结果表示训练集与测试集关联模式相同的关联结果.
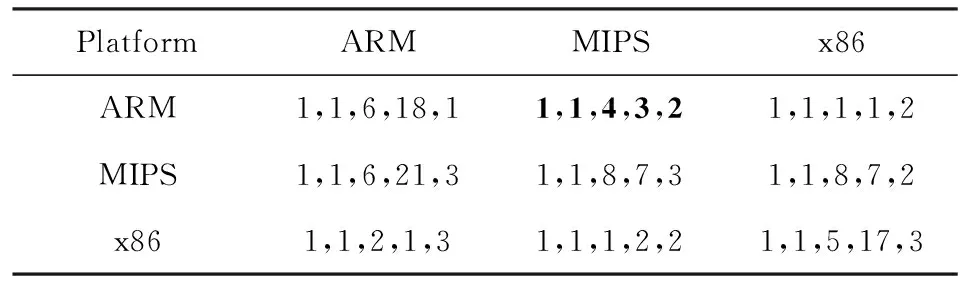
Table 6 Search Results for Different Platforms
通过观察表6可以发现,即使训练集与测试集关联模式不同,关联结果并没有发生很大变化,Rank值依然保持在21以内.这就表明即使平台关联模式未知,本文提出的算法仍能获得良好的关联效果.
表7表示平台的关联模式为-O0×-O2时改变优化选项的关联模式的实验结果.其中,第1列表示漏洞函数的优化选项,项目栏表示待关联函数的优化选项,表中数据表示表3中5个漏洞函数的数值相似度的Rank值.结果表明,即使训练集与测试集优化选项不同,关联结果并没有发生很大变化,Rank值依然保持在20以内.这就表明即使优化选项关联模式未知,本文提出的算法仍能获得良好的关联效果.

Table 7 Searching Results for Different Optimization Options
以编号为4的漏洞函数为例,相比黑体结果,采用与测试集不同关联模式的训练集训练的神经网络计算的排名略有下降.这就表明在进行关联前,如果能够识别二进制文件的平台和优化选项,将一定程度提高关联的准确率.
5 结束语
本文提出一种基于神经网络和局部调用结构匹配的固件漏洞关联方法,该方法以函数为最小关联单元,较为全面地提取了函数在函数调用图、函数基本属性和函数控制流图3方面信息,同时,这些特征的提取不依赖指令集,具有一定的跨平台能力,可以对2个不同指令集的二进制代码进行相似程度度量.局部调用结构匹配考虑了与待匹配函数有调用关系的其他函数相似程度的影响,提高了准确率.
本文在二进制文件OpenSSL上进行跨平台漏洞关联实验,相比已有方法,该方法在同一固件上性能指标Top1从32.1%提高至76.49%;采用5个真实漏洞函数对二进制文件OpenSSL进行关联时,整体相似度的Rank值均为1.最后,采用4个真实的漏洞函数在372个D-Link路由器固件上进行关联实验,结果表明该方法具有良好的关联效果.下一步工作主要集中于5个方面:
1) 将其他诸如SVM、决策树等机器学习算法应用于代码相似性检测,并分析其优缺点.
2) 识别二进制文件的平台和编译优化选项,在进行漏洞关联前确定关联模式,提高关联准确率.
3) 实际应用中,判定阈值往往根据特定的实验数据经验获取.不同关联模式下其相似度的数值分布不同,经验选取的阈值不能灵活地适应不同关联模式的需求.下一步将研究阈值的确定方法.
4) 在对动态链接库的处理上,本文在实验中设定动态链接的函数的相似度为1个常量.下一步的工作可以通过分析其函数体所在的动态链接库文件进行函数特征提取,提高关联准确率.
5) 本文方法可以应用于大规模固件函数同源性检测,时间复杂度是O(n2).为了减少时间成本,可以采用时间复杂度为O(n)的聚类算法进行提速,如LSH.
[1]Open Web Application Security Project. OWASP Internet of Things Project (Top 10 IoT Vulnerabilities (2014) Project)[EB/OL]. (2016-02-05)[2016-03-10]. https://www.owasp.org/ index.php/OWASP_Internet_of_Things_Top_Ten_Project#tab=Top_10_IoT_Vulnerabilities__282014_29
[2]Knownsec. A statistical analysis report about the back door of D-Link by ZoomEye.org[EB/OL]. (2013-10-28)[2016-09-05]. http://blog.knownsec.com/2013/10/zoomeye-org关于d-link后门的统计分析报告(知道创宇. ZoomEye.org关于D-Link后门的统计分析报告[EB/OL]. (2013-10-28)[2016-09-05]. http://blog.knownsec.com/2013/10/zoomeye-org关于d-link后门的统计分析报告)
[3]Myles G, Collberg C. K-gram based software birthmarks[C] //Proc of the 20th ACM Symp on Applied Computing. New York: ACM, 2005: 314-318
[4]Kolter J Z, Maloof M A. Learning to detect malicious executables in the wild[C] //Proc of the 10th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2004: 470-478
[5]Jin W, Chaki S, Cohen C, et al. Binary function clustering using semantic hashes[C] //Proc of Int Conf on Machine Learning & Applications. Piscataway, NJ: IEEE, 2012: 386-391
[6]David Y, Yahav E. Tracelet-based code search in executables[J]. ACM Sigplan Notices, 2014, 49(6): 349-360
[7]Gao D, Reiter M K, Song D. BinHunt: Automatically finding semantic differences in binary programs[C] //Proc of the 10th Int Conf on Information and Communications Security. Berlin: Springer, 2008: 238-255
[8]Lakhotia A, Preda M D, Giacobazzi R. Fast location of similar code fragments using semantic “juice”[C] //Proc of ACM Sigplan Program Protection and Reverse Engineering Workshop. New York: ACM, 2013: 1-6
[9]Ming J, Pan M, Gao D. iBinHunt: Binary hunting with inter-procedural control flow[C] //Proc of the 15th Information Security and Cryptology. Berlin: Springer, 2012: 92-109
[10]Ng B H, Prakash A. Expose: Discovering potential binary code re-use[C] //Proc of the 37th Annual Computer Software and Applications Conf (COMPSAC’13). Piscataway, NJ: IEEE, 2013: 492-501
[11]Xie Yuqiang, Zeng Ying, Shu Hui. Improved graph-based executable file comparison algorithm[J]. Computer Engineering and Design, 2007, 28(2): 257-260(谢余强, 曾颖, 舒辉. 改进的基于图的可执行文件比较算法[J]. 计算机工程与设计, 2007, 28(2): 257-260)
[12]Zeng Ming, Zhao Rongcai, Wang Xiaoqin, et al. A binary patch analysis technique based on the disassembly technology[J]. Computer Science, 2006, 33(10): 283-287(曾鸣, 赵荣彩, 王小芹, 等. 一种基于反汇编技术的二进制补丁分析方法[J]. 计算机科学, 2006, 33(10): 283-287)
[13]Egele M, Woo M, Chapman P, et al. Blanket execution: Dynamic similarity testing for program binaries and components[C] //Proc of the 23rd USENIX Conf on Security Symposium. Berkeley, CA: USENIX Association, 2014: 303-317
[14]Pewny J, Garmany B, Gawlik R, et al. Cross-architecture bug search in binary executables[C] //Proc of IEEE Symp on Security and Privacy. Piscataway, NJ: IEEE, 2015: 709-724
[15]Watts D J, Strogatz S H. Collective dynamics of “small-world” networks[J]. Nature, 1998, 393(6684): 440-442
[16]Bergroth L, Hakonen H, Raita T. A survey of longest common subsequence algorithms[C] //Proc of the 5th Int Symp on String Processing and Information Retrieval. Berlin: Springer, 2000: 39-48
[17]Hamers L, Hemeryck Y, Herweyers G, et al. Similarity measures in scientometric research: The Jaccard index versus Salton’s cosine formula[J]. Information Processing & Management, 1989, 25(3): 315-318
[18]Kononenko I. Estimating attributes: Analysis and extensions of RELIEF[C] //Proc of the 5th European Conf on Machine Learning. Berlin: Springer, 1994: 171-182
[19]Robnik-Sikonja M, Kononenko I. Theoretical and empirical analysis of ReliefF and RReliefF[J]. Machine Learning, 2003, 53(1/2): 23-69
[20]Hecht-Nielsen R. Theory of the back propagation neural network[J]. Neural Networks, 1989, 1(1): 593-605
[21]Bourgeois F, Lassalle J C. An extension of the Munkres algorithm for the assignment problem to rectangular matrices[J]. Communications of the ACM, 1971, 14(12): 802-804

Chang Qing, born in 1991. Master candidate. Received her BSc degree from University of Electronic and Technology of China in 2014. Her main research interests include IOT security, industrial control system security.

Liu Zhongjin, born in 1988. Received his PhD degree from Tsinghua University in 2014. Researcher in the National Computer Network Emergency Response Technical TeamCoordination Center of China. His main research interests include computer and network security, network virtualization, future Internet architecture.

Wang Mengtao, born in 1989. Master candidate. Received his BSc degree from Hainan University in 2014. His main research interests include IOT security.

Chen Yu, born in 1988. PhD candidate. Received his MSc degree from Beihang University in 2014. His main research interests include industrial control system security.

Shi Zhiqiang, born in 1970. Received his PhD degree from the Institute of Software, Chinese Academy of Sciences in 2001. Senior engineer in the Institute of Information Engineering, Chinese Academy of Sciences. His main research interests include industrial control system security, cyber security, etc.

Sun Limin, born in 1966. Received his BSc, MSc, and PhD degrees from National University of Defense Technology in 1988, 1995, and 1998 respectively. Associate professor in the Institute of Information Engineering, Chinese Academy of Sciences. His main research interests include IOT security.
VDNS: An Algorithm for Cross-Platform Vulnerability Searching in Binary Firmware
Chang Qing1,2,3, Liu Zhongjin4, Wang Mengtao1,2,3, Chen Yu1,2,3, Shi Zhiqiang1,2,3, and Sun Limin1,2,3
1(BeijingKeyLaboratoryofIOTInformationSecurity,InstituteofInformationEngineering,ChineseAcademyofSciences,Beijing100093)2(InstituteofInformationEngineering,ChineseAcademyofSciences,Beijing100093)3(UniversityofChineseAcademyofSciences,Beijing100049)4(NationalComputerNetworkEmergencyResponseTechnicalTeamCoordinationCenterofChina,Beijing100029)
Nowadays, most IOT vendors use the similar code to compile firmware for devices based on various CPU architectures. However, the prior vulnerability searching methods are limited to the same platform, which can’t be directly extended to the cross-platform case, and the cross-platform studies have just started. In this paper, we propose an algorithm to search vulnerabilities of firmware in a cross-platform model based on neural network and local calling structure matching. Firstly we extract the selected compared features from the call graphs, the basic attributes and the control flow graphs of the two compared functions as the input of the neural network, and gain the calculated results. Then we match the call sub-graphs of the compared functions with the results of the previous step as weight to improve the accuracy. The experimental results on the open source code OpenSSL demonstrate our method has better performance than the prior cross-platform vulnerability searching method with theTop1 increasing from 32.1% to 76.49% in the searching pattern from ARM to MIPS. The searching ranks of the common five vulnerabilities in OpenSSL are all No.1 rank. Moreover, we search the common four vulnerabilities in the firmware of the 372 types of D-Link routers and the results show good performance too.
cross-platform; vulnerability search; feature selection; neural network; bipartite matching
2016-06-16;
2016-08-11
中国科学院战略性先导科技专项课题(XDA06040101);国家重点研发计划(2016YFB0800202);国家自然科学基金项目(U1536107)
石志强(shizhiqiang@iie.ac.cn)
TP309.1
Chen Zhifeng, born in 1986. PhD. His main research interests include information security and trust computing.
This work was supported by the State Priority Research Program of the Chinese Academy of Sciences (XDA06040101), the National Key Technology Research and Development Program of China (2016YFB0800202), and the National Natural Science Foundation of China (U1536107).
猜你喜欢
中等数学(2021年8期)2021-11-22
商品与质量(2019年34期)2019-11-29
数学大王·低年级(2019年10期)2019-11-25
中等数学(2019年4期)2019-08-30
测控技术(2018年5期)2018-12-09
信息安全研究(2016年4期)2016-12-01
网络空间安全(2016年3期)2016-06-15
火控雷达技术(2016年2期)2016-02-06
电脑爱好者(2015年7期)2015-04-09
单片机与嵌入式系统应用(2014年9期)2014-03-11
