
基于词向量的学术语义搜索研究
2016-11-05 02:15:17陈国华许玉赢贺超波肖丹阳
华南师范大学学报(自然科学版) 2016年3期
陈国华, 汤 庸, 许玉赢, 贺超波, 肖丹阳
(1.华南师范大学网络中心, 广州 510631;2.华南师范大学计算机学院,广州 510631;3. 仲恺农业工程学院信息科学与技术学院, 广州 510225)
基于词向量的学术语义搜索研究
陈国华1, 汤庸2*, 许玉赢2, 贺超波3, 肖丹阳2
(1.华南师范大学网络中心, 广州 510631;2.华南师范大学计算机学院,广州 510631;3. 仲恺农业工程学院信息科学与技术学院, 广州 510225)
基于学者网提供的计算机专业论文语料库,利用Glove语义分析工具,给出了多种词向量训练方案,比较了各自的优劣性;提出了利用随机映射的方法,在大规模的向量空间中快速定位向量;最后提出了在单个词的语义向量基础上计算整篇学术文档的语义向量的方案.通过一系列实验验证了基于词向量的学术语义搜索方案的有效性,并实际应用于学者网学术搜索中,取得良好的效果.
学术语义计算; 词向量; 随机映射; 学者网
语义搜索已经成为信息检索和自然语言处理领域的一个研究热点问题.目前,实现语义搜索的方法可分为两大流派:一类是基于统计的方法,利用词和文档的统计信息“计算”出词语的语义,在此基础上进行语义相似度的计算和语义搜索;另一类为基于逻辑的方法,首先手工标注语义资源,构建一个语义网络,然后利用逻辑分析的方法进行推理.基于统计的方法可以避免构建和维护语义网所需的巨大人力成本,因此,本文重点关注基于统计的语义搜索方法.
统计搜索技术发展的最早阶段为80年代提出的经典的文档向量空间模型,解决了全文检索中的精确匹配问题.90年代提出了潜在语义分析技术(Latent Semantic Analysis, LSA)[1-3],该方法利用特征值分解方法(Singular Value Decomposition)对词-文档矩阵进行分解、压缩,挖掘文档中隐含的“概念”,从中发现词与文档两两间的语义相似度信息.BLEI等[4-5]在此基础上提出了基于潜在Dirichlet分布的主题模型(Topic Model),该模型允许1个文档有多个主题,1篇文档是多个主题的概率分布,而1个主题是多个词语的概率分布.利用主题模型,可以计算出1篇文档包含了哪些主题,以及属于某一主题的概率.
近年来,深度机器学习技术取得了长足的进步[6-7].在此基础上,出现了新的语义计算方法,如word2vec[8-10]、GloVe等[11].Word2vec利用循环神经网络(Recurrent Neural Network)来训练语言模型,提供了2种经典的语言模型进行训练:n-gram模型和CBOW模型[12],可以很好地抓取文本的局部信息特征.而GloVe在此基础上提出了全局log-双线性回归模型,加入了全局的词汇统计信息,可以兼顾全局与局部信息,更好地挖掘词汇的语义特征.
相较于之前的语义计算方案,词向量技术在两方面做了巨大的进步:(1)相比于LSA挖掘的概念,词向量技术计算出的词的语义向量包含了线性语义特征,可以捕获词的语法及语义的线性相似度[10];(2)Topic Model模型需要计算大量的概率,模型复杂度高,无法进行大数量的计算;而词向量利用深度机器学习技术,可以在大型的语料库中进行训练,利用的数据量越大,得到的模型越精确.
从1个词到1个句子,再到一段话、整篇文档,它们之间的语义存在着很大的距离,由词的语义生成文档的语义并不像直观地看起来那样简单.这与我们经常遇到的“虽然每个词都认识,但连在一起组成1个句子,怎么也不能理解它的含义”的生活体验类似.这一问题近年来也得到了关注.1个简单的方案是采用简单的线性相加的方式,将词的向量加上一定的权重相加,求均值,即为文档的语义向量[13].该方法简单有效,但与Bag of Words模型一样,丢失了词语间的上下文信息.SOCHER等[14]提出解析句子的语法结构,在此基础上构建1个矩阵向量模型,计算句子的语义向量,但该方法无法处理段落或者文档等更为复杂的结构.文献[15]提出了Paragraph Vector的概念,除了1个词的上下文之外,还保留了段落信息,可以生成1个段落的语义.
本文提出了基于词向量的语义搜索模型.利用词向量化技术,从大量的语料库中进行训练,学习每个词的向量化表示.之后由词的向量计算出文档的向量,由此就可以计算出文档与文档之间、文档与查询词之间的语义距离,从而实现精准的语义搜索.并将本文算法应用于学术社交网站——学者网.实验表明,本文算法可以快速、准确地搜索到语义相关的学者及他们发表的论文 ,可以很好地实现语义搜索功能.
1 基于词向量的语义搜索
利用词向量方法,可以计算词汇间的语法和语义的线性相似度.所谓词汇的语法和语义的线性相似度,是指词汇的语法相似度和语义相似度可进行近似的线性计算.下面给出语义相似度的示例:
Xking-Xman≈Xqueen-Xwoman,
Xshirt-Xclothing≈Xchair-Xfurniture,
其中,Xking表示词king的语向量,其余皆同.
由此可以看出,采用词向量的方法可以很好地描述语义相似度信息,而且语义相似度可以进行近似的线性计算,为进行文档与查询词之间、文档与文档之间的相似度分析提供基础.
本文的应用背景为学者网中的学术搜索.学者网是一个面向学者的学术社区,学术搜索是其中一项重要的学术服务,收录了近8 000万条中英文论文,为学者提供丰富的学术文献资源[16].
本文基于词向量模型,提出了适用于大型学术搜索引擎中的学术论文语义搜索算法.首先给出该算法的基本处理流程:
算法1基于词向量的学术论文语义搜索
第1步:对论文数据进行清理,抽取出论文标题及关键字,形成语料库D;
第2步:将抽取出的关键字加入ansj_seg分词组件的用户自定义字典中,对语料库中的论文数据进行分词;
第3步:将分词后的数据调用GloVe进行训练,得到每个词的语义向量库V;
第4步:对用户输入的查询Q进行相关词扩展,选出相似度大于θ的最相近的词汇,组成新的查询Q’;
第5步:计算Q’的向量,在语义向量库V中查询与其最相关的文档,并返回.
算法1的第1步仅提取出论文的标题及关键字信息来计算论文文档的语义,而忽略掉论文的摘要信息.这是因为在摘要中存在着过多与论文的主题不相关的词汇,在以词汇的线性组合作为文档的语义来进行计算时,这些词汇将对文档的语义造成相当大的干扰.将在下面的实验部分进行分析.
分词效果的好坏直接决定了对于中文语料进行语义分析的效果.本文采用Ansj_seg[17]开源分词组件进行分词.Ansj_seg采用N-Gram结合条件随机域来实现,分词效率可达200万词/s,准确率达96%.算法1的第2步将关键字作为一个完整的词汇,加入到用户词典中,后面的实验证明,该方法可大幅提高语义计算的准确度.
算法1的第4步采用了查询扩展的方式,可提高语义搜索返回结果的召回率,有利于增加结果的多样性.
算法的最后一步,根据查询向量Q’,在语义向量库V中查询与其最相关的前m个文档.假设V中的向量个数为n,向量的维度为d,那么,经过简单的分析可以看到,常规的算法实现最相关文档查询的时间复杂度为O(mdn2). 在向量维度和向量库的规模很大时,常规算法的时间复杂度很高,会耗费较多的时间.
为提高相关文档的查询效率,使其适用于大规模的文档库中,我们提出了利用随机映射的方法,在大规模向量空间中快速查询最相关文档.在向量空间V中随机生成一条分隔线,将V划分成不同的2个子空间;如此进行多次随机分割,空间的划分方法就生成一颗随机树.随机树的生成过程如图1所示.
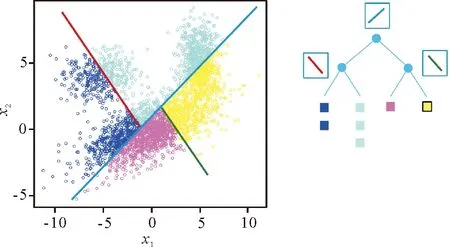
图1 随机树的划分
在随机树中定位查询目标向量所在的划分区域,然后在这些区域中查找与其最相关的文档.可见,在随机树中查找出的最相关文档,是在整个向量空间中最相关文档的一个子集.
我们提出以下观察:在向量空间V中相近的点极大可能落在随机树的同一个划分区域中.
基于以上观察,如果我们进行多次随机划分,生成多个随机树,那么,将多个随机树的查询结果结合起来,求它们的并集,将会保证覆盖到完整的最相关文档的绝大部分,甚至是命中全部最相关文档.
下面给出该算法的具体流程:
算法2随机映射法查询最相关文档
Input: 目标向量v, 随机树深度d, 随机树个数N
Output: 最相关向量集合V
Procedure:
(1)V={};
(2)foriin 1…N;
(3)生成随机树Ti;
(4)在Ti中确定v所在的划分区域Sj;
(5)在划分区域Sj中查找最相关文档Vi;
(6)V=V∪Vi;
(7)ReturnV.
2 实验结果与分析
为验证本文提出的方案,我们在学者网中抽取了计算机方向16个中文核心期刊的12 727篇论文.这些期刊为:计算机学报、软件学报、计算机研究与发展、自动化学报、计算机科学、控制理论与应用、计算机辅助设计与图形学学报、计算机工程与应用、模式识别与人工智能、控制与决策、小型微型计算机系统、计算机工程、计算机应用、中国图象图形学报、遥感学报和中文信息学报.
在实验中,我们将分别考查以下因素对语义搜索带来的影响:
•利用“题目+关键字”信息与利用“题目+关键字+摘要”信息;
•分词时是否将关键字作为一个完整的词汇;
•计算语义时是否利用TF-IDF作为词的权重;
•是否采用语义相关词汇,对查询进行扩展.
本实验分别在保证其他条件不变的情况下,改变某一项条件,检验它对语义搜索的结果会造成如何影响.检验方法为手动设定若干常见的查询条件,并判断它们的语义相关度.
2.1“题目+关键字”与“题目+关键字+摘要”
首先,我们对比在其他条件相同的情况下,是否采用摘要信息对语义带来的影响.本文给出几个常见的查询,并且比较它们的准确率.在词的权重相等(不加入TF-IDF分数作为权重)、将关键字作为单独词汇加入分词中的结果见表1.可以看出,加入摘要信息后,虽然检索时考虑的内容更加全面了,但是对检索的精度带来了明显的下降.亦即,在对语义进行线性计算的方案中,摘要中包含的多个语义上无关的词汇,会对最终生成的论文的语义向量造成干扰.这与数学中“1+ (-1) =0”的数学原理相一致.
2.2关键字作为单独词汇
分词是中文语言处理中特有的一个阶段.分词效果的好坏,对于中文语言分析系统的运行有着很大的影响.通常情况下,关键字都是一个特定的、完整的学术词汇,它们有着特定的含义,例如“机器学习”表示计算机领域一个特有的学习技术,如果将它拆分开“机器”、“学习”,将极大地影响语义的准确度.因此,我们采用将关键字作为一个单独词汇的方法,保证学术词汇的准确识别.本实验中,验证了该方法对语义搜索带来的准确率的提升.
通过表2可以看到,将关键字加入到分词组件的用户词典后,可以显著提升语义检索的准确率.
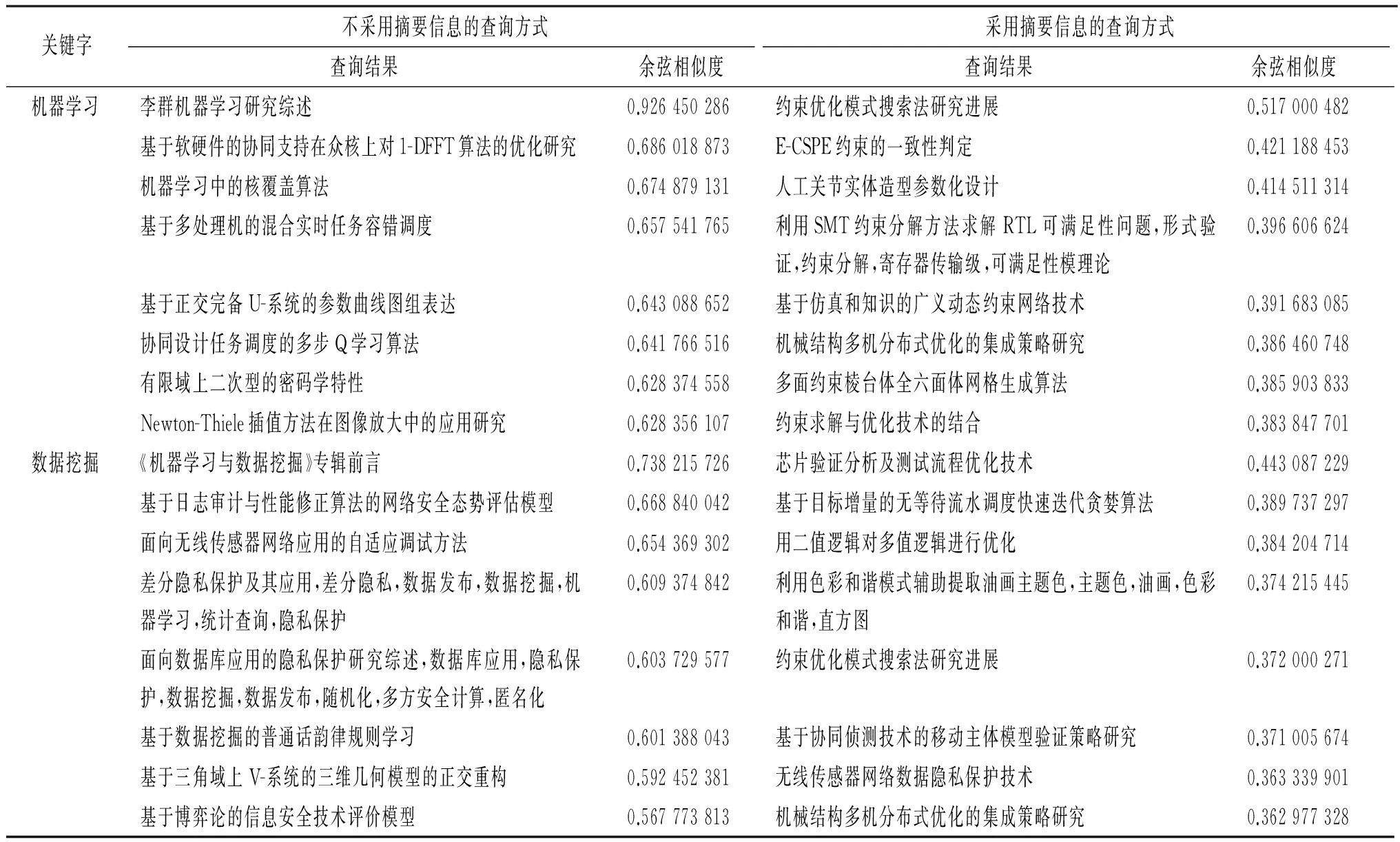
表1 是否采用摘要信息的查询结果对比
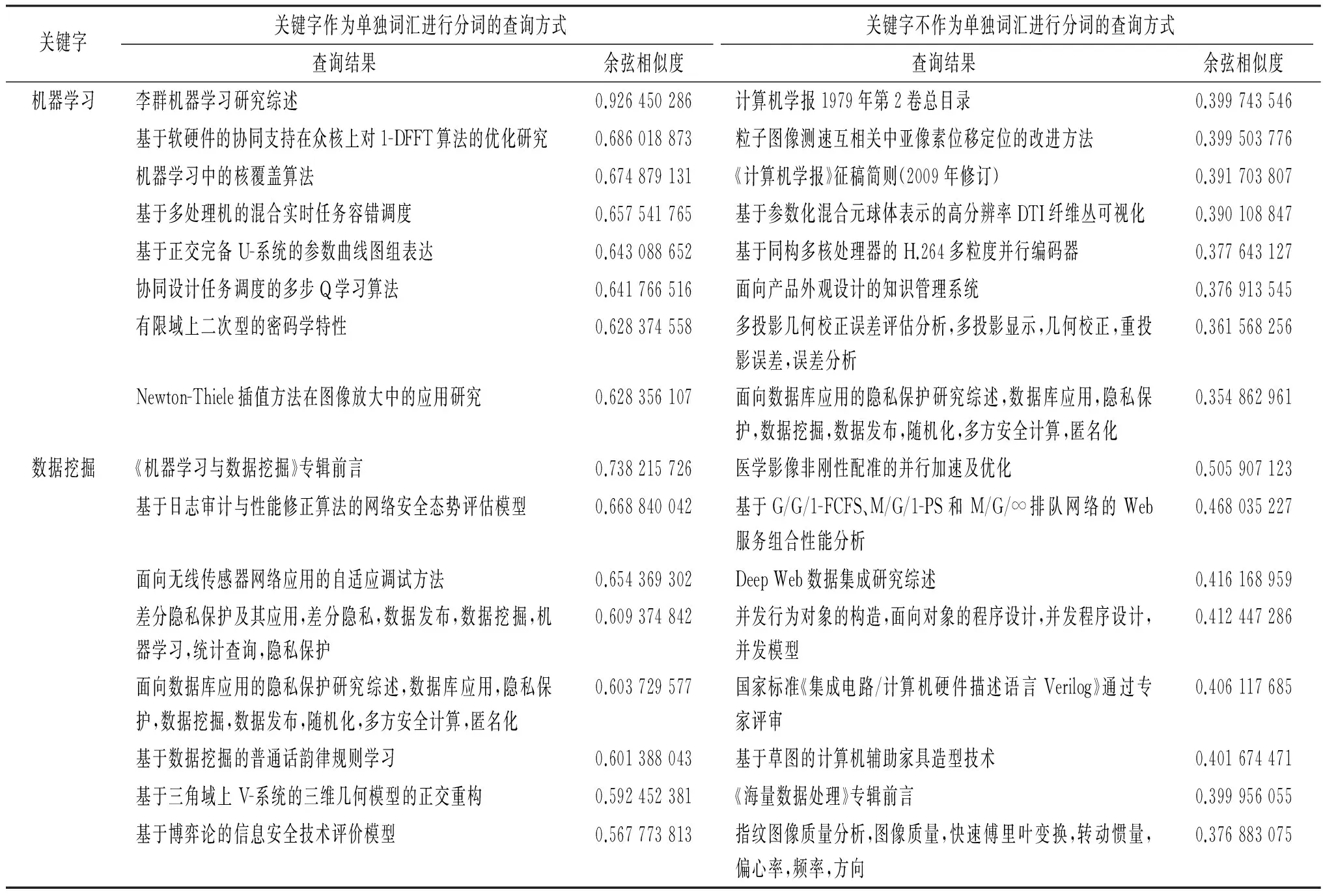
表2 是否将关键字作为单独词汇分词效果对比
2.3计算词汇权重
在普通文本处理中,词汇对于文档有着不同的区分度.例如,1个语料库中包含1个词汇的文档数越多,该词汇越通用,它对于文档的区分度就越低,反之就越高.通常用TF-IDF来描述1个词汇的重要程度.本文设置了2个方案:(1)利用TF-IDF作为词汇的权重,在计算1篇论文的语义时,将分词后的各个语义向量乘以该权重,然后相加,得到该论文的语义向量;(2)各个词的权重相同,直接相加得到论文的语义向量.表3给出了两者的结果对比.通过对比可以发现,采用TF-IDF作为权重,与同等权重基本没有差别,搜索给出的结果完全相同,仅仅在计算语义相似度的分数有很小的不同.这与本文实验所采用的语料是相关的.我们计算语义时重点考虑了文章的关键字信息,而关键字对于论文语义的权重基本上没有差别.本文的实验证明了这一观点.
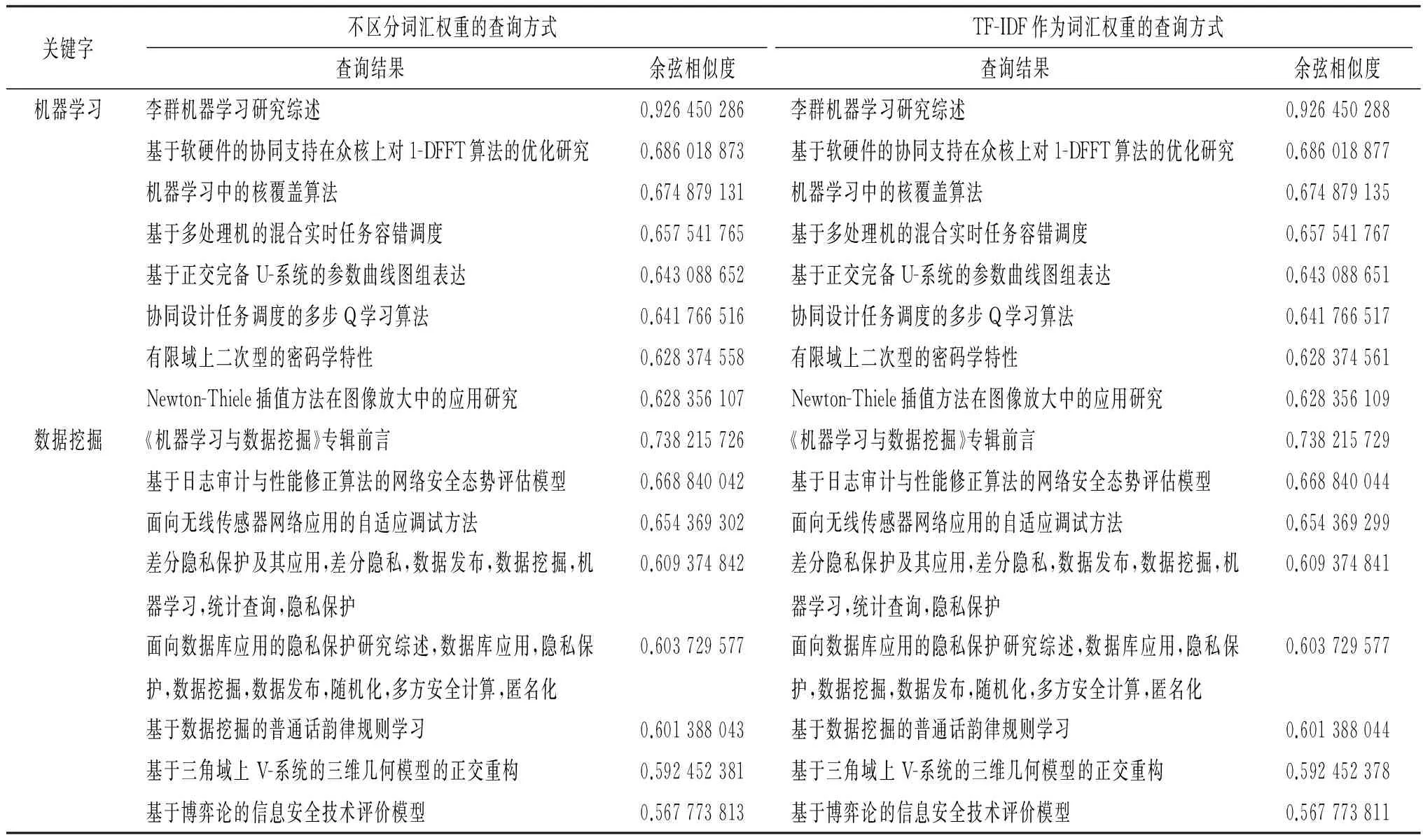
表3 是否加入权重的效果对比
2.4语义扩展
算法1的第4步对查询Q进行了相关词扩展,利用在语义上与Q最相近的词,扩展它的语义,以提高查询的召回率.例如,以“机器学习”为例,首先查询与其最相近的词,相关度阈值θ设为0.65,得到的相关词如表4所示.可以看出,利用该方法可以较准确地提取出语义上相关的词汇.利用这些相关词汇去扩展该查询,可以得到覆盖面更广的结果.
利用表4给出的语义相关词汇,将它们综合起来进行查询,并计算每篇论文与该扩展后查询的语义相关度.采用上文已证明有效的方案进行查询,即:用“标题”+“关键词”计算论文的语义、将关键字作为单独的词汇进行分词,以及将TF-IDF作为区分每个词的语义权重.从表5可知,利用语义相关词汇进行扩展后,查询到的结果更加全面,可以覆盖更多相关的主题,同时,在整体上也保持了较高的语义相关度,没有因为引入了额外的查询,而造成查询结果语义分散的情况,证明了该查询方案的有效性.
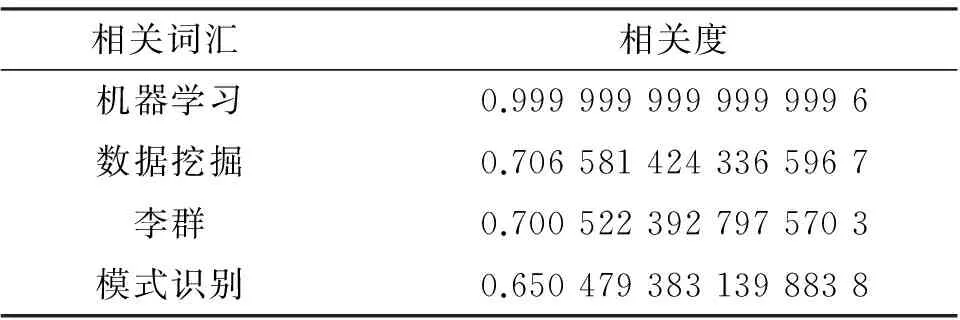
表4 “机器学习”的相关词扩展
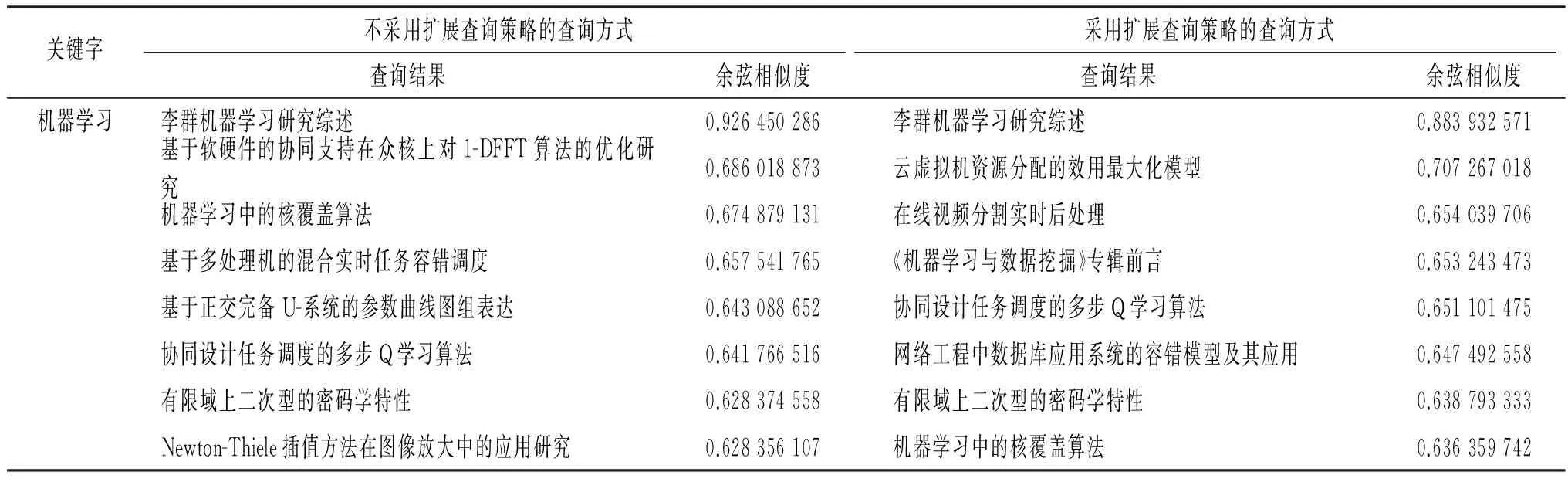
表5 是否采用扩展查询策略的效果对比
3 小结与展望
本文提出了一种利用词向量方法计算进行语义查询的搜索方案,并将其应用于学者网学术搜索中.针对学术搜索的实际情况,提出利用题目+关键词来训练语义向量,并将关键词作为完整词汇加入到分词组件的用户自定义词典中;利用随机映射的方法,提高在向量空间中查找最相关文档的效率.实验证明,该方案可以有效地计算论文的语义信息,并进行语义查询.
本文为避免摘要信息对论文的语义造成干扰,没有采用摘要信息,保证了论文语义的精确性,但同时也丢失了一部分有用的信息.在将来的工作中,可以进一步讨论如何有效的利用摘要信息,进一步丰富论文的语义.
[1]DEERWESTER S, DUMAIS S T, FURNAS G W, et al. Indexing by latent semantic analysis[J]. Journal of the American Society for Information Science, 1990, 41(6): 391.
[2]HOFMANN T. Unsupervised learning by probabilistic latent semantic analysis[J]. Machine Learning, 2001, 42(1/2):177-196.
[3]DUMAIS S T. Latent semantic analysis[J]. Annual Review of Information Science and Technology, 2004, 38(1):188-230.
[4]BLEI D M, NG A Y, JORDAN M I. Latent dirichlet allocation[J]. The Journal of Machine Learning Research, 2003, 3:993-1022.
[5]BLEI D M, LAFFERTY J D. A correlated topic model of science[J]. The Annals of Applied Statistics, 2007,1(1):17-35.
[6]SCHMIDHUBER J. Deep learning in neural networks: an overview[J]. Neural Networks, 2015, 61:85-117.
[7]WESTON J, RATLE F, MOBAHI H, et al. Deep learning via semi-supervised embedding[J]. Lecture Notes in Computer Science, 2012, 7700:1168-1175.
[8]MIKOLOV T, CHEN K, CORRADO G,et al. Efficient estimation of word representations in vector space[J/OL]. (2013-09-07)[2016-03-25].Computer Science, http:∥www.oalib.com/paper/4057741#.Vx3Rz_mEAso.[9]MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[J]. Advances in Neural Information Processing Systems, 2013,26:3111-3119.
[10]MIKOLOV T, YIH W, ZWEIG G. Linguistic regularities in continuous space word representations[C]∥Proceedings of NAACL-HLT. Atlanta:[s.n.], 2013:746-751.
[11]PENNINGTON J, SOCHER R, MANNING C D. Glove: global vectors for word representation[C]∥Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP).Doha:[s.n.], 2014:1532-1543.
[12]BENGIO Y, SCHWENK H, SENÉCAL J S, et al. Neural probabilistic language models[M]∥HOLMES D E, JAIN L C. Innovations in Machine Learning. Berlin:Springer, 2006:137-186.
[13] MITCHELL J, LAPATA M. Composition in distributional models of semantics[J]. Cognitive Science, 2010, 34(8):1388-1429.
[14]SOCHER R, LIN C C, MANNING C, et al. Parsing natural scenes and natural language with recursive neural networks[C]∥Proceedings of the 28th International Conference on Machine Learning. Bellevue:[s.n.],2011:129-136.[15]LE Q V, MIKOLOV T. Distributed representations of sentences and documents[C]∥Proceedings of the 31th International Conferences of Machine Learning. Beijing:[s.n.], 2014:1188-1196.
[16]学者网:教学科研协作平台[Z/OL].[2016-03-25].http:∥www.scholat.com.
[17]NLPChina. Ansj分词[Z/OL]. [2016-04-10]. https:∥github.com/NLPchina/ansj_seg.
【中文责编:庄晓琼英文责编:肖菁】
Research on Academic Semantic Search Using Word Vector Representations
CHEN Guohua1, TANG Yong2*, XU Yuying2, HE Chaobo3, XIAO Danyang2
(1. Network Center, South China Normal University, Guangzhou 510631, China; 2. School of Computer Science, South China University of Technology, Guangzhou 510631, China; 3. School of Information Science and Technology, Zhongkai University of Agriculture and Engineering, Guangzhou 510225, China)
Using the papers in computer science extracted from Scholat as the corpus, multiple word vector training schemes are proposed using the Glove semantic toolkit, and their performances are compared and analyzed. Then, a random projection method is proposed to quickly access vectors in the large vector space. Finally, a semantic vector computing scheme for the whole academic documents is proposed based on the word vector representations. A series of experiments are conducted, and the effectiveness of the proposed scheme “word vector based academic semantic search” is verified. This scheme is applied to the search function of Scholat and it can obtain satisfying performance.
academic semantic computing; word vectors; random projection; Scholat
2016-04-24《华南师范大学学报(自然科学版)》网址:http://journal.scnu.edu.cn/n
国家高技术研究发展计划项目(863计划)(2013AA01A212);国家自然科学基金项目(61272067,61502180);广东省科技计划项目 (2013B090800024,2015A020209178,2016A030303058);广东省自然科学基金项目(2015A030310509,2014A030310238);广州市科技计划项目(2014J4300033)
汤庸,教授,Email: ytang4@qq.com.
TP391.1
A
1000-5463(2016)03-0053-06
猜你喜欢
华人时刊(2022年1期)2022-04-26 13:39:28
中国新闻周刊(2021年26期)2021-07-27 04:02:12
动漫界·幼教365(大班)(2019年10期)2019-10-28 01:54:09
智富时代(2019年6期)2019-07-24 10:33:16
信息安全研究(2016年4期)2016-12-01 06:06:54
高中生·天天向上(2016年9期)2016-11-22 09:10:34
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
智能计算机与应用(2011年4期)2012-05-15 02:24:18
电脑迷(2012年4期)2012-04-29 06:12:13
