
适用于彩色图像人脸识别的字典学习算法*
2016-11-01 03:27施静兰张智勇覃团发
电讯技术 2016年4期
施静兰,常 侃**,2,3,张智勇,覃团发,2,3
(1.广西大学计算机与电子信息学院,南宁 530004;2.广西高校多媒体通信与信息处理重点实验室(广西大学),南宁 530004;3.广西多媒体通信与网络技术重点实验室培育基地(广西大学),南宁 530004)
适用于彩色图像人脸识别的字典学习算法*
施静兰1,常 侃**1,2,3,张智勇1,覃团发1,2,3
(1.广西大学计算机与电子信息学院,南宁530004;2.广西高校多媒体通信与信息处理重点实验室(广西大学),南宁530004;3.广西多媒体通信与网络技术重点实验室培育基地(广西大学),南宁530004)
现有的基于稀疏表示的人脸识别算法在识别前需要将彩色人脸图像转换成灰度人脸图像,这样虽然提高了运算速度,但忽视了不同色彩通道数据本身所包含的信息及它们之间的相关性。为了利用不同通道间相关性,基于标签一致的K奇异值分解(LC-KSVD)字典学习算法,提出了一种适用于彩色图像人脸识别的字典学习算法。该算法将RGB通道数据顺序排列成列向量,并在稀疏编码的环节中,对正交匹配追踪(OMP)算法的内积计算准则进行修正,以此提高字典原子的色彩表达能力。在彩色人脸数据库上进行实验,结果表明:所提出的字典学习算法能够有效地提高识别率。
彩色图像;人脸识别;稀疏表示;字典学习;稀疏编码
1 引言
人脸识别的研究始于20世纪60年代,是一项具有挑战性的任务[1]。随着图像处理、计算机视觉和模式识别等领域理论与技术的成熟,与之相关的人脸识别技术经过半个多世纪的发展,也得到了广泛应用。
近年来,稀疏编码已经成功地应用于计算机视觉、机器学习和图像分析领域,包括图像去噪[2]、图像修复[3]、图像压缩[4]和图像分类[5]等。文献[6]中提出了基于稀疏表示的分类算法(Sparse Representation-based Classification,SRC),并应用于人脸识别。该方法直接使用整个训练图像集来构成字典,对于一张测试人脸图像,通过计算其在该字典上的稀疏编码系数来对其进行分类。与传统的人脸识别方法不同的是,SRC人脸识别方法不需要像Eigenface[7]和Fisherface[8]方法一样进行明确的特征提取,而且对光照变化、表情变化和局部遮挡等问题鲁棒性高,这些优点使其成为了一个新兴的研究热点。
虽然基于SRC的人脸识别算法取得了一定成功,但是,文献[6]利用整个训练样本集作为字典进行稀疏编码,字典的维度高且不能有效表征训练样本,因此进行分类时复杂度高且识别率也有待进一步提升。直接有效的改进方法是采用精简的、由自适应学习得到的字典。著名的字典学习算法包括最优方向字典学习算法[9]和K奇异值分解(K-Singular Value Decomposition,K-SVD)字典学习算法[10]等,其中,K-SVD算法循环进行稀疏编码和字典更新,字典学习的效率很高。但是,K-SVD算法本身并没有考虑字典的区分能力,因此由该算法学习而得的字典不能直接应用于人脸分类。文献[11]通过根据输出的线性预测分类器进一步迭代更新由K -SVD算法训练出的字典,由此获得一个除了具有表示能力外还同时有利于分类的字典。文献[12]提出了区分性的K-SVD(Discriminative K-SVD,DKSVD)算法,通过在原始K-SVD算法的目标函数上加入区分项,保证学习出的冗余字典同时具有表示能力和区分能力,使字典和分类器的学习过程统一起来。文献[13]提出一种监督性算法——标签一致的K-SVD(Label Consistent K-SVD,LC-KSVD)算法来学习出一个精简的和具有区分性的字典用于稀疏编码,通过在目标函数中加入“区分性”稀疏编码误差准则和“最佳”分类性能准则,并利用K -SVD算法进行优化求解,同时学习出具有区分性的字典和线性分类器。除了以D-KSVD和LC-KSVD为代表的改进的K-SVD算法外,还涌现了一些其他的字典学习算法,例如:香港理工大学的Yang和Zhang等人陆续提出了Metaface字典学习(Metaface Learning,MFL)算法[14]、Fisher判别准则字典学习算法[15]等适用于人脸识别的字典学习算法。
虽然上述基于K-SVD的各类人脸识别算法均取得了较好的识别效果,但是现有的基于字典学习的人脸识别方法均是直接将彩色人脸图像转成灰度人脸图像后再进行人脸识别,这样在识别的过程中就仅应用了灰度图像的纹理信息。较少文献对彩色人脸图像进行处理的主要原因在于:首先,相比于灰度人脸图像,单纯通过增高数据维度带来的识别率提升有限;其次,数据维度增高会引入过高的复杂度,不利于算法的实际应用。但是,一方面,随着处理器计算能力的不断增强,高维度数据的处理难度在不断降低;另一方面,可以通过引入并行计算技术,例如图像处理单元(Graphics Processing Unit,GPU)等,进一步降低所需的计算时间。因此,与其他文献不同,本文讨论高维度的彩色人脸图像识别问题,希望通过探索不同色彩通道之间的相关性达到理想的识别率。
最为直接的彩色图像人脸识别方法是将每张彩色人脸图像的R、G、B 3个通道数据按顺序排列为一个列向量代替灰度图像向量进行人脸识别。以LC-KSVD算法[13]为例,可以应用此思想进行直接扩展,对应的方法在本文中称为CE1-LC-KSVD(Color-Extension 1 of LC-KSVD)。但是,此方法是简单地直接增高数据维度,各色彩通道之间的相关性是完全被忽略的。为了合理利用色彩通道之间的相关性,从而进一步提升算法识别率,本文提出一种适用于彩色图像人脸识别的字典学习算法——CE2 -LC-KSVD(Color-Extension 2 of LC-KSVD)。与CE1-LC-KSVD算法不同,在稀疏编码阶段,CE2-LC-KSVD算法通过修正正交匹配追踪(Orthogonal Matching Pursuit,OMP)算法中的内积计算准则,对各个通道之间的相关性加以利用。这样使得学习出的字典能够体现通道间相关性,从而减少重构图像和原始图像之间的误差,最终提高识别率。
2 LC-KSVD字典学习算法[13]
LC-KSVD是一种监督字典学习算法,它旨在利用输入信号的监督信息(例如标签)来学习出一个具有重建能力和区分性的字典。为了利用训练样本的类别标签信息,将标签信息与每一个字典原子关联起来,加入一种新的标签一致的约束,并且结合重建误差和分类误差以构建最优化问题。文献[13]提出了两类LC-KSVD算法,分别记为LC-KSVD1和LC-KSVD2。
2.1LC-KSVD1
令Y表示一组维度为n的N个输入信号,即Y=[y1,y2,…,yN]∈Rn×N,D=[d1,d2,…,dK]∈Rn×K为学习字典(其中,K>n以保证字典为冗余字典),X=[x1,x2,…,xN]∈RK×N为输入信号Y的稀疏编码。线性分类器的性能决定于输入的稀疏编码X的区分性。为了利用学习得到的字典D获得具有区分性的稀疏编码X,定义如下字典构造的目标函数:

式中:α是权重参数;T为稀疏度;xi为第i个测试样本yi在字典D上的稀疏编码系数;‖Y-DX‖22为重建误差;Q=[q1,q2,…,qN]∈RK×N为输入信号Y的具有区分性的稀疏编码,如果qi中的非零值位于输入信号yi和字典原子dk具有相同类别标签的地方,那么称qi=[q1i,q2i,…,qKi]T=[0…1,1,…0]T∈RK为与输入信号yi相应的“区分性”稀疏编码;A是一个线性变换矩阵,定义一个线性变换g(x,A)=Ax,它将原始的稀疏编码x转换成在稀疏特征空间RK中最具区分性;‖Q-AX‖22项表示具有区分性的稀疏编码误差,它强制了稀疏编码X近似为具有区分性的稀疏编码Q,使得来自同一个类别的信号具有非常相似的稀疏表示(例如:令稀疏编码结果中标签一致),这样一来,即使使用一个简单的线性分类器也能获得好的分类结果。
2.2LC-KSVD2
为了使得在分类中字典最优化,在字典学习的目标函数中加入分类误差项。在LC-KSVD2中,使用一个线性预测分类器f(x,W)=Wx。一个同时具有重建能力和区分能力的字典D的学习目标函数定义如下:

式中:‖H-WX‖22项表示分类误差;W为分类器参数;H=[h1,h2,…,hN]∈Rm×N为输入信号Y的类别标签;hi=[0,0,…,1,…,0,0]T∈Rm为与输入信号yi相对应的标签向量,其中非零值的位置表明yi的类别;α和β为权重参数。
假设具有区分性的稀疏编码X'=AX和A∈RK×K是可逆的,则D'=D A-1,W'=W A-1。式(2)的目标函数可以重新写为

式中:第一项表示重建误差;第二项表示具有区分性的稀疏编误差能够使各个类别之间的稀疏编码具有区分性;第三项表示分类误差,通过‖H-W'X'‖22使学习得到的分类器最优。
3 彩色图像的稀疏表示人脸识别
3.1彩色图像LC-KSVD字典学习算法
在人脸识别中,可获取的样本数量通常远小于人脸图像样本的维数,因此由训练样本组成的字典原子色彩表示能力不高。已有的LC-KSVD字典学习算法[13]仅应用于灰色图像,而忽略了原始彩色图像中的大量信息。本文希望在LC-KSVD算法的基础上,有效地利用不同色彩通道数据之间的相关性(而不仅是简单地通过数据维度的增加),提高字典原子色彩表示能力,从而最终提高识别率。
传统的K-SVD算法包括稀疏编码和字典更新两个步骤。因为OMP算法高速有效,所以其被应用于K-SVD算法的稀疏编码阶段。文献[3]指出,将灰度图像的K-SVD字典训练扩展到彩色图像的一个简单方法是将RGB色彩空间3个通道的值顺序连接成一个列向量后再进行训练。但是,由于原始的OMP算法在重构过程中缺少一定的约束,并不能保证重建图像会包含原始图像的平均色,因此训练过程会产生伪色彩和假象,这是彩色图像处理中会遇到的典型问题。为了利用不同色彩通道数据之间的相关性提高字典原子的色彩表达能力,可以对OMP的内积计算准则进行适当的修正,使其适应于彩色图像的稀疏编码。
假设x和y是两张不同的彩色人脸图像,表示为x=[xTR,xTG,xTB]T,y=[yTR,yTG,yTB]T,其中xR、xG、xB和yR、yG、yB分别为图像x和图像y的R、G、B通道值列向量,维度为n。定义一种新的OMP内积形式如下:

式中:γ是权重参数;
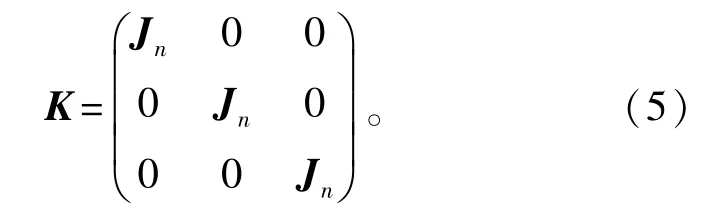
式中:Jn是一个n×n的矩阵,其元素全部为1。等式第一项为原始的Euclidean内积,它能够保证获得当前最好的结果。包含矩阵K的第二项计算每一个通道中的E(y)和E(x)的估计量并将它们相乘,因此强制选择的原子考虑平均色。为了方便求解,令γ=2a+a2,则
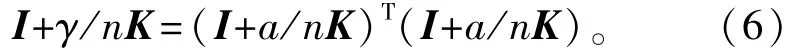
因此,一个简单的实现方法是,将每一张人脸图像和字典中的每一个原子都乘以I+a/nK,并将其进行归一化,这样便可以实现新的内积准则。
由于只有训练图像和字典原子中存在3个色彩通道之间的相关性,因此,在彩色图像LC-KSVD字典学习算法中,采用OMP算法时,将训练图像和字典原子的RGB通道值顺序联结成一个列向量,然后分别乘以I+a/nK,并采用新的OMP内积准则求解稀疏编码系数。

由此可见,彩色图像的LC-KSVD算法与原始LC-KSVD算法形式相同,仅在OMP步骤采用新的内积计算准则来处理伪色彩和假象问题。
3.2彩色图像LC-KSVD字典学习算法的优化
本文同时考虑LC-KSVD1算法与LC-KSVD2算法的彩色图像扩展算法。由于两者的优化过程相同,接下来仅以彩色图像的LC-KSVD2算法为例描述优化过程。
为了求解式(8),将其重新写为

引入两个新的变量如下:

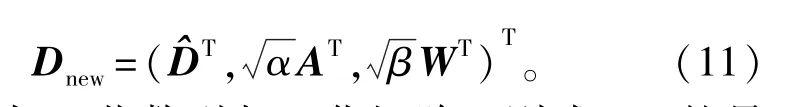
式中:Dnew为l2范数列归一化矩阵。则式(9)的最优化等价于求解如下问题:
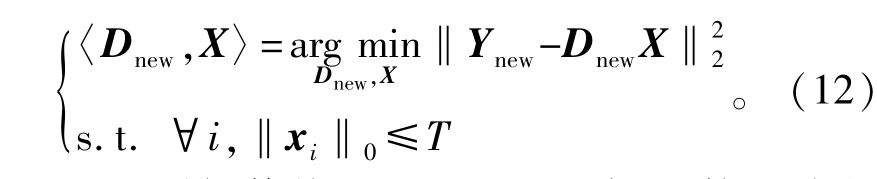
上述问题与传统K-SVD的目标函数形式相同,因此可以直接通过K-SVD算法求解。
3.3分类方法
通过上述学习过程最终得到字典Dnew后,便可利用其对待测人脸图像进行分类。从Dnew中获得wK}。由于、A和W共同进行过l2范数归一化,因此还不能直接使用它们进行分类。分类操作所需的、变换参量和分类器参量计算方法如下:

对于测试图像yi,首先通过求解以下优化问题计算它的稀疏表示系数xi:

然后简单地使用线性预测分类器~W来判断图像yi的标签j:

式中:l∈Rm为类别标签向量。
4 实验结果与分析
在实验部分,将提出的彩色图像LC-KSVD字典学习算法称为CE2-LC-KSVD。为了全面分析算法性能,与灰度图下的LC-KSVD算法[13]进行比较(需注意,灰度图下有LC-KSVD1和LC-KSVD2,因此在彩色人脸图像下对应的改进算法分别为CE2-LC-KSVD1和CE2-LC-KSVD2)。此外,将R、G、B通道数据排列成列向量,直接代替原有灰度图像进行字典学习的方法称为CE1-LC-KSVD。
由于许多主流的人脸图像库为灰度图像,本文仅选择AR和CMU_PIE两个彩色人脸图像库进行实验。其中,AR人脸库下包含与人脸色彩差距鲜明的遮挡物,CMU_PIE包含更为复杂的光照情况。
实验中,α和β与文献[13]中取相同值,分别为16和4,OMP新内积计算准则中的a取0.001。实验中使用的是台式计算机,Intel(R)Core(TM)2 Duo CPU,主频3 GHz,4 GB内存。
4.1AR人脸库实验结果
AR人脸库[16]包含来自126个人超过4 000张的正面人脸图像,每张图像尺寸为120 pixel×165 pixel。每类有26张图像,选取两个不同时期,分别在不同光照、表情以及面部遮挡条件下拍摄。遮挡包括墨镜遮挡和围巾遮挡。AR人脸库中部分人脸图像如图1所示。实验中,我们选择一组包含50个男性对象和50个女性对象的人脸子集,并将人脸图像缩小为40 pixel×55 pixel。实验分以下两部分进行:
(1)对于每个对象,随机选择N1张人脸图像作为训练样本,其余作为测试样本,字典维度为500;
(2)对于每个对象,选择第一时期和第二时期拍摄的只有表情变化和光照变化无遮挡的14张人脸图像,从中随机选择N2张作为训练样本,其余作为测试样本,字典维度为100。

图1 AR人脸库部分人脸图像Fig.1 Part of AR Database
实验1的结果列于表1。从表1可以观察到:与LC-KSVD算法相比,CE1-LC-KSVD算法的识别率有大幅提升,说明通过增加数据维度,能够获得更高的识别率;与CE1-LC-KSVD算法的识别率相比,CE2-LC-KSVD有1.7%~2.8%的提升,说明新的OMP内积计算准则能够有效地利用不同色彩通道数据之间的相关性信息来提高字典原子的色彩表达能力。此外,还可以观察到:与CE1-LC-KSVD算法相比,CE2-LC-KSVD的字典学习时间并没有明显增加,也进一步说明了本文算法的优势。

表1 AR人脸库中各算法识别率与字典学习时间(实验1)Tab.1 Recognition rates and associated dictionary learning times by different methods on the AR Database(Experiment 1)
实验2的结果列于表2。与表1的结果类似,CE1-LC-KSVD算法和CE2-LC-KSVD算法均能够取得比LC-KSVD算法更高的识别率,但是识别率提升幅度低于表1的结果。原因在于AR人脸库中的部分人脸图像具有遮挡,而遮挡物与人脸肤色差距较大,这些色彩信息在字典学习中发挥了重要的作用。实验1的样本中包含具有遮挡物的人脸图像,而实验2的样本中去除了此类图像,因此可利用的色彩信息较少。另外,从字典学习时间上看,CE2 -LC-KSVD算法的速度明显快于CE1-LC-KSVD算法,说明在训练样本色彩接近的情况下,本文修正的OMP内积方法有利于字典学习过程的快速收敛。

表2 AR人脸库中各算法识别率与字典学习时间(实验2)Tab.2 Recognition rates and associated dictionary learning times by different methods on the AR Database(Experiment 2)
4.2CMU_PIE人脸库实验结果
CMU_PIE人脸库[17]包含68个人的超过4 000张人脸图像,每张图像尺寸为140 pixel×200 pixel。每个人有13种姿势、43种不同的光照条件和4种不同表情,包括“illumination”和“light”两个子集:“illumination”子集背景光关闭,仅有不同方向的闪光灯照亮,每个类有21幅图像;“light”子集同时包含背景光和闪光灯,每个类有22幅图像,其中第一张图像只有背景光。“illumination”子集部分人脸图像如图2所示,“light”子集部分人脸图像如图3所示。

图2 CMU_PIE人脸库“illumination”子集部分人脸图像Fig.2 Part of CMU-PIE Database“illumination”subset

图3 CMU_PIE人脸库“light”子集部分人脸图像Fig.3 Part of CMU-PIE Database“light”subset
实验选择CMU_PIE人脸库中的“illumination”子集和“light”子集,将每张图像缩小为35 pixel×50 pixel。对于每个对象,随机选择N3张人脸图像作为训练样本,其余作为测试样本,字典维度为340。
CMU_PIE的实验结果列于表3。从表3中可以看出:与表1和表2中的结果类似,CE2-LC-KSVD算法的识别率最高,CE1-LC-KSVD算法次之,LCKSVD算法最低,从而验证了彩色图像人脸识别的有效性。需要注意的是:首先,彩色图像下识别率的提升幅度低于AR人脸库实验1(详见表1),原因在于CMU_PIE两个子集中的人脸图像没有出现色差很大的遮挡物,因此色彩信息少于AR人脸库实验1;其次,彩色图像下识别率的提升幅度高于AR人脸库实验2(详见表2),原因在于CMU_PIE两个子集中的光照情况较为复杂,因此色彩信息相对AR人脸库实验2而言更丰富。

表3 CMU_PIE人脸库中各算法识别率与字典学习时间Tab.3 Recognition rates and associated dictionary learning times by different methods on the CMU_PIE Database
4.3综合讨论与分析
CE1-LC-KSVD算法同时利用了R、G、B 3个色彩通道的数据值,导致数据维度大大增加,所以其识别效果会比灰度图像的LC-KSVD算法更好。但是,CE1-LC-KSVD算法仅通过单纯的数据维度的增加来获取更高的识别率,并没有考虑不同色彩通道之间的相关性。因此,这种高维度数据的应用方法效率不高,算法识别率也还有进一步提升的空间。而CE2-LC-KSVD算法采用了新的OMP内积计算准则,在稀疏编码中考虑原子的平均色,有效地解决了训练过程中产生的伪色彩和假象等问题,所以提高了字典原子的色彩多样性。因此,CE2-LC-KSVD算法能够有效地利用3个色彩通道之间的相关性,进一步提高识别率。
另一方面,因为两种彩色图像下的字典学习算法CE1-LC-KSVD和CE2-LC-KSVD将3个色彩通道的数据排列成列向量处理,所以每个训练样本以及字典原子的维度是灰度图像情况下的3倍,导致字典学习时间明显增加。为了解决此问题,一种较为有效的方法是应用并行计算技术,例如GPU等降低运算时间。需要注意的是,CE2-LC-KSVD算法在稀疏编码步骤中采用了新的内积计算准则,仅通过将每一张人脸图像和字典中的每一个原子同时乘以I+a/nK来实现。因此,在大部分情况下,CE2-LC-KSVD算法学习时间仅比CE1-LC-KSVD算法略长。根据AR人脸库实验2的结果可知,在训练样本间色彩接近的情况下,所采用的修正的OMP内积方法有利于字典学习过程的快速收敛,因此该情况下所提出的CE2-LC-KSVD算法优势更为明显。
最后需要提出的是,在实际应用中,不可避免地会存在人脸图像颜色不正的问题。为了解决上述问题,可以增大训练集,让训练集涵盖尽可能多的光照、遮挡等情况,从而最大程度地保证彩色图像字典的鲁棒性。
5 结束语
为了利用R、G、B色彩通道的信息及不同通道之间的相关性,以提高字典原子的色彩表示能力,本文将3个色彩通道的数据排列成列向量,并在OMP
稀疏编码中采用新的内积计算准则。在AR和CMU _PIE两个彩色人脸库上进行实验,并与灰度图像下的LC-KSVD算法以及直接将其扩展到彩色图像下的CE1-LC-KSVD算法进行比较。实验结果表明本文算法能有效提高识别率。但是本文算法同时应用了3个色彩通道的数据,提高了算法对内存的需求,
字典训练时间也有明显增加。在未来的工作中,研究重点之一是通过并行化技术,例如GPU等降低字典学习时间,以提高算法的实用性。此外,也将探索
Lab色彩空间下的人脸识别算法性能。与RGB色彩空间不同,Lab色彩模型是均匀的。可以尝试将彩色图像转换到Lab空间,再根据需要采用灰度图像(仅L通道)或彩色图像(L、a、b通道)的字典学习方法。
[1]ZHAO W,CHELLAPPA R,PHILLIPS P J,et al.Face recognition:a literature survey[J].ACM Computing Surveys,2003,35(4):399-458.
[2]ELAD M,AHARON M.Image denoising via sparse and redundant representations over learned dictionaries[J]. IEEE Transactions on Image Processing,2006,15(12):3736-3745.
[3]MARIAL J,ELAD M,SAPIRO G,et al.Sparse represen-tation for color image restoration[J].IEEE Transactions on Image Processing,2008,17(1):53-69.
[4]BRYT O,ELAD M.Compression of facial images using the K-SVD algorithm[J].Journal of Visual Communication and Image Representation,2008,19(4):270-282.
[5]YANG J C,YU K,GONG Y H,et al.Linear spatial pyramid matching using sparse coding for image classification[C]//Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Miami,FL:IEEE,2009:1794-1801.
[6]WRIGHT J,YANG A Y,GANESH A,et al.Robust face recognition via sparse representation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(2):210-227.
[7]TURK M,PENTLAND A.Eigenfaces for recognition[J]. Journal of Cognitive Neuroscience,1991,3(1):71-86.
[8]BELHUMEUR P N,HESPANHA J P,KRIEGMAN D J. Eigenfaces vs.Fisherfaces:recognition using class specific linear projection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1997,19(7):711-720.
[9]ENGAN K,AASE S O,HUSOY J H.Frame based signal compression using method of optimal directions(MOD)[C]//Proceedings of the IEEE International Symposium on Circuits and Systems(ISCAS).Orlando,FL:IEEE,1999:1-4.
[10]AHARON M,ELAD M,BRUCKSTEIN A.K-SVD:an algorithm for designing overcomplete dictionaries for sparse representation[J].IEEE Transactions on Signal Processing,2006,54(11):4311-4322.
[11]PHAM D S,VENKATESH S.Joint learning and dictionary construction for pattern recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Anchorage,AK:IEEE,2008:1-8.
[12]ZHANG Q,LI B X.Discriminative K-SVD for dictionary learning in face recognition[C]//Proceedings of 2010 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).San Francisco,CA:IEEE,2010:2691-2698.
[13]JIANG Z L,LIN Z,DAVIS L S.Label consistent KSVD:learning a discriminative dictionary for recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(11):2651-2664.
[14]YANG M,ZHANG L,YANG J,et al.Metaface learning for sparse representation based face recognition[C]// Proceedings of 2010 IEEE International Conference on Image Processing(ICIP).Hong Kong:IEEE,2010:1601-1604.
[15]YANG M,ZHANG L,FENG X C,et al.Fisher discriminationdictionarylearningforsparserepresentation[C]//Proceedings of 2011 IEEE International Conference on Computer Vision(ICCV).Barcelona:IEEE,2011:543-550.
[16]MARTINEZ A,BENAVENTE R.The AR face database[R]//CVC Technical Report#24.Barcelona:Centre de Visióper Computador,1998.
[17]SIM T,BAKER S,BSAT M.The CMU pose,illumination,and expression(PIE)database[C]//Proceedings of the 5th IEEE International Conference on Automatic Face and Gesture Recognition.Washington,DC:IEEE,2002:46-51.

施静兰(1990—),女,广西南宁人,2013年于广西大学获工学学士学位,现为硕士研究生,主要研究方向为人脸识别、稀疏表示、图像处理;
SHI Jinglan was born in Nanning,Guangxi Zhuangzu Autonomous Region,in 1990.She received the B.S.degree from Guangxi University in 2013.She is now a graduate student.Her research concerns face recognition,sparse representation and image processing.
Email:shijinglan@mail.gxu.cn
常 侃(1983—)男,广西南宁人,2010年于北京邮电大学获博士学位,现为广西大学计算机与电子信息学院副教授,主要研究方向为压缩感知、稀疏表示、图像处理;
CHANG Kan was born in Nanning,Guangxi Zhuangzu Autonomous Region,in 1983.He received the Ph.D.degree from Beijing University of Posts and Telecommunications in 2010.He is now an associate professor.His research interests include compressed sensing,sparse representation and image processing.
Email:pandack0619@163.com.
张智勇(1991—),男,广西扶绥人,2014年于广西大学获工学学士学位,现为硕士研究生,主要研究方向为稀疏表示、低秩矩阵及应用;
ZHANG Zhiyong was born in Fusui,Guangxi Zhuangzu Autonomous Region,in 1991.He received the B.S.degree from Guangxi University in 2014.He is now a graduate student.His research concerns sparse representation,low rank matrix and its application.
Email:zhangzhiyong1160@163.com
覃团发(1966—),男,广西宾阳人,1997年于南京大学获博士学位,现为广西大学教授、计算机与电子信息学院副院长、中国电子学会高级会员、中国通信学会高级会员,主要研究方向为无线多媒体通信、网络编码。
QIN Tuanfa was born in Binyang,Guangxi Zhuangzu Autonomous Region,in 1966.He received the Ph.D.degree from Nanjing University in 1997.He is now a professor and the Vice Dean of School of Computer and Electronic Information,Guangxi University,and also a senior member of China Institute of Electronics and senior member of China Communications Institute. His research interests include wireless multimedia communications,network coding.
Email:tfqin@gxu.edu.cn
A Dictionary Learning Algorithm for Color Face Recognition
SHI Jinglan1,CHANG Kan1,2,3,ZHANG Zhiyong1,QIN Tuanfa1,2,3(1.School of Computer and Electronic Information,Guangxi University,Nanning 530004,China;2.Guangxi Colleges and Universities Key Laboratory of Multimedia Communications and Information Processing,Guangxi University,Nanning 530004,China;3.Guangxi Key Laboratory of Multimedia Communications and Network Technology(Cultivating Base),Guangxi University,Nanning 530004,China)
The existing sparse-representation-based face recognition algorithms usually transform the color face images into gray images.Although this procedure increases the recognition speed,it ignores the information of the different color channels and the correlation among them.In order to utilize the correlation among different channels,based on the label consistent K-Singular Value Decomposition(LC-KSVD)algorithm,a new dictionary learning method for color face recognition is proposed.To improve the representing ability of each atom for color images,this algorithm concatenates R,G and B values into a single vector,and then introduces a new inner product into orthogonal matching pursuit(OMP)during sparse coding procedure.Experiments on different color face images datasets demonstrate that the proposed algorithm can achieve a higher recognition rate.
color images;face recognition;sparse representation;dictionary learning;sparse coding
The National Natural Science Foundation of China(No.61401108,61261023);The Natural Science Foundation of Guangxi(2013GXNSFBA019272)
TP391.4
A
1001-893X(2016)04-0365-07
10.3969/j.issn.1001-893x.2016.04.003
施静兰,常侃,张智勇,等.适用于彩色图像人脸识别的字典学习算法[J].电讯技术,2016,56(4):365-371.[SHI Jinglan,CHANG Kan,ZHANG Zhiyong,et al.A dictionary learning algorithm for color face recognition[J].Telecommunication Engineering,2016,56(4):365-371.]
2015-10-28;
2016-03-11 Received date:2015-10-28;Revised date:2016-03-11
国家自然科学基金资助项目(61401108,61261023);广西自然科学基金资助项目(2013GXNSFBA019272)
**通信作者:pandack0619@163.com Corresponding author:pandack0619@163.com
猜你喜欢
计算机工程(2020年3期)2020-03-19
电子制作(2019年16期)2019-09-27
小学阅读指南·低年级版(2019年11期)2019-07-01
中国听力语言康复科学杂志(2019年3期)2019-06-24
智能城市(2018年7期)2018-07-10
中国交通信息化(2018年3期)2018-06-13
小天使·一年级语数英综合(2017年11期)2017-12-05
自动化学报(2017年5期)2017-05-14
读者(2016年14期)2016-06-29
中国交通信息化(2016年2期)2016-06-06
