
基于多敏感值的个性化隐私保护算法*
2016-10-26 05:30黄玉蕾戴慧珺
计算机与数字工程 2016年9期
黄玉蕾 林 青 戴慧珺
(1.西安培华学院 西安 710125)(2.西安交通大学 西安 710049)
基于多敏感值的个性化隐私保护算法*
黄玉蕾1林青1戴慧珺2
(1.西安培华学院西安710125)(2.西安交通大学西安710049)
移动网络的兴以及智能终端产生了大量的数据,研究与分析这样的数据有利于科学研究、商业发展等。然而,如果攻击者能够识别或窃取数据中的用户隐私信息,特别是敏感信息,给用户个人隐私信息带了严重的威胁。现有隐私保护技术从整体角度考虑敏感属性及取值,却较少考虑到不同用户对某个敏感属性的敏感程度以及相应的隐私保护需求的综合影响。论文提出一种基于K-匿名模型的改进算法,同时考虑不同敏感属性的整体敏感度以及用户对具体敏感属性的不同需求,实现基于多敏感值的个性化隐私保护算法。最后通过信息熵评价算法的匿名程度。
隐私保护; K-匿名; 个性化匿名; 多敏感值
Class NumberTP309.2
1 引言
数据挖掘技术使得通过从大数据中提取数据特征、规律性,从而进行判决预测、决策指导等。然而大量数据公布的同时,数据拥有者的隐私信息容易遭到窃取和攻击。因此,数据挖掘不仅要考虑挖掘结果的可用性和有效性,还要对数据包含的隐私信息进行保护,以防被窃取或者攻击,造成不必要的损失。针对这些问题,从不同视角提出了众多隐私保护方法,并取得非常好的应用效果。其中,数据匿名技术就是一种应用广泛的方法,其基本思路是通过对数据表中的多条相同或者相似的数据泛化为完全相同的数据从而使避免针对具体个人的隐私攻击。其中Samarati和Sweeney提出K-匿名模型[1~3],要求数据表中的任何一个元组至少和与其相似的(K-1)个元组组成一个不可区分的(即准标识符完全相同的)K元的集合,目的是保护单个用户免于定向攻击。K-匿名模型实现简单,然而单纯通过K匿名的缺点是无法抵御同质性攻击和链接推理攻击,为了解决这些问题,Machanavajjhal等提出L-多样化模型[4~5],要求K-匿名模型的每个K元集合中都至少包含L个不同的敏感值,从而扩展了K-匿名模型。Machanavajjhal列举了关于L-多样化模型的例子,其中相异L-多样化模型可以有效地抵御敏感值的同质性攻击,然而由于该模型只考虑敏感值的种类而对各个种类所占的比例没有要求,因此无法预防概率推导攻击,使得攻击者能够以较高的概率命中所要攻击的目标成为可能;而信息熵L-多样化模型对各种类敏感值的比例做出了限定,从而减小了概率推导的成功率,匿名更为有效。Wong提出了(α,k)-匿名模型[6~7],使每个敏感值在等价集合中的出现概率都不超过α。其后,一种基于粒计算的面向用户的个性化算法被提出,实现了基于用户对敏感值的敏感程度的个性化隐私保护[8~9]。为了防止敏感属性取值以较高的概率推断出,Blum等提出了分布式隐私保护模型,适用于非交互查询模型。由于现有的个性化匿名算法只能针对单一敏感值的用户个性化需求进行匿名,因此本文综合考虑将不同敏感属性本身的敏感程度以及不同用户对敏感值的要求不同的影响,通过改进K-匿名模型,提出一种基于多敏感值的个性化隐私保护算法,最后通过信息熵对算法的匿名度进行评价。
2 基于多敏感值个性化隐私保护算法
2.1相关概念
作为数据挖掘资源或隐私攻击对象的已发布数据集的属性可以大致分为三个部分: 1) 显式标示符:即攻击者能直接获取的信息,如姓名、身份证号等。 2) 准标识符:这些属性虽然未直接显示出攻击者所需要的信息,可以通过背景知识等外部资源可以推断出的用户信息,如通过相关性、交互性等。 3) 敏感属性:数据的属性包含了用户更敏感的隐私信息,所需的保护强度更大,如健康状况。 4) 非敏感属性,除上述三种属性之外的其他属性[10]。
定义1(K-匿名)记数据表为T(A1,A2,A3…),其中A1为表中的用户数据条目。QI为准标识符,若在表中出现的QI都至少出现K次以上,则称该数据表满足K-匿名[11]。
定义2(完全(α,k)-匿名)给定数据表T,准标识符为QI,敏感属性为S,s为S的取值,若为每个s设置约束频率αs,若数据表满足K匿名,而对于S中的每个s都满足在所有等价类中出现的频率小于αs,则称该匿名表为完全(α,k)-匿名的[12]。

定义4(敏感空间)对于数据表中的所有用户,每个用户都具有一个个性化的敏感向量,这些向量的集合可以看作n维空间中的点集,每个敏感向量即从原点指向所对应点的向量,n维空间中每一维取值范围是(0,1)。称此n维空间为该数据表的敏感空间。
定义5(属性权重)由于算法针对多敏感属性(如收入、健康状况、住址等),考虑到不同属性对于隐私攻击者或数据利用者带来的效益及影响不同,对各属性赋予整体的权重,即属性权重。如在收入和健康状况两种属性中,可能健康状况隐私泄露和收入隐私泄露相比所带来的影响或损失更大,因此对健康状况的属性权重应大于收入的属性权重。具体权重的取值应根据实际情况由发布者调查和分析决定。
定义6(敏感值权重)对于n个敏感属性,若第i个敏感属性的敏感值为qi,在不考虑用户敏感程度的情况下,该qi对于数据发布者来说隐私保护的需求程度也是不同的。因此有必要对每个属性的各个取值设置权重,即敏感值权重,从而在整体范围内对隐私保护进行面向多敏感属性和多敏感值的个性化匿名。对于标称属性值,可以每种标称值设置一权重;对于数值属性值,可将数值属性分段,每段设置一权重。
定义7(等价类)在匿名表中,将所有准标识符QI相同的数据条目归为同一组,由此产生了若干个所含元素准标识符完全相同的组,这样的组称为等价类。
定义8(泛化)对于准标识符的部分信息隐匿,可以采用泛化的方法。即若标识符为标称属性,则寻找逻辑意义上更大分类的标称值。若标识符为数值属性,可以通过去数值中的最大值和最小值,将数值泛化为数值范围。由此可见,若需要泛化的属性值的数量越多,属性值之间相关性越差,则泛化结果的集合外延越大,使得数据在应用于挖掘特征值和交互关系时的可用性降低。因此,为了兼顾泛化后的数据表的可用性,应尽量寻找属性较为类似的用户群进行泛化。
2.2算法实现
在匿名过程中,需要考虑到不同用户对各敏感属性的个性化的敏感程度需求,同时还要考虑到同种敏感属性不同的取值也会影响到隐私保护的强度,因此需要将敏感向量与敏感值权重综合考虑,作为最终匿名强度决策的标准。通过对敏感向量中同一分量代表的不同属性值进行加权,得到最终供决策用的决策值。较为符合实际需求,既做到敏感值权重高的信息保护强度高,又保证了同一敏感值权重的内容保护强度高低由用户给出的敏感向量决定,实现了面向用户的个性化。另外,对于不同属性,进行属性加权,使决策值更符合实际。
对于每一用户的敏感向量,根据其各敏感属性的具体值进行敏感值加权及属性加权,所得的向量作为决策向量。决策向量具有如下特性:
1) 对于同一属性,决策向量在该属性的投影大小由敏感向量及敏感值权重共同决定。
2) 对于敏感程度相同的,敏感值权重高的投影大;对于同一敏感值权重的取值,用户敏感程度越高投影越大。
3) 对于不同属性,若某用户给出的敏感程度相同,则在决策向量中,该分量值与属性权重成比例。

在算法的执行中应注意,由于在聚类分析对用户分类的过程中,为保证聚类划分质量,需对数据表做去噪处理,去除离群点,然而在匿名保护问题中,对每个用户的要求都应考虑到,需要考虑一下问题:
1) 尤其当敏感值的权重较高且用户要求的匿名程度也较高的情况很可能成为离群点,而此类用户反而需要更强的保护措施,因此应在聚类划分之后对离群点做单独处理,归入相近聚类或高度泛化保证其隐私保护程度。
2) 对于不同的聚类,同一属性上的投影越大的要求匿名程度越高,故αs越小。
算法对需要匿名的数据表通过五个阶段的处理,获取最终满足隐私保护需求的匿名表,具体实现如下五个阶段所示:
输出:满足用户对多敏感值隐私保护强度需求的匿名表T′。
阶段1:获取敏感向量。确定敏感属性、标识符、敏感权重以及属性权重,获取每个用户的敏感向量。
阶段2:获取决策向量。通过对敏感向量进行敏感值加权和属性加权,得到各用户的决策向量。
阶段3:求取决策向量均值。对决策向量进行去噪处理,然后将匿名要求相近的进行聚类分析,求出决策向量均值。
阶段4:分配频率约束。根据各聚类的均值决策向量分配频率约束αi。
阶段5:分配(α,k)-匿名。对各聚类进行(α,k)聚类,若某聚类泛化后仍无法满足(α,k)(α,k)-匿名,将其与最近邻聚类合并,转至上一步。
算法实现的具体流程图如图1所示。
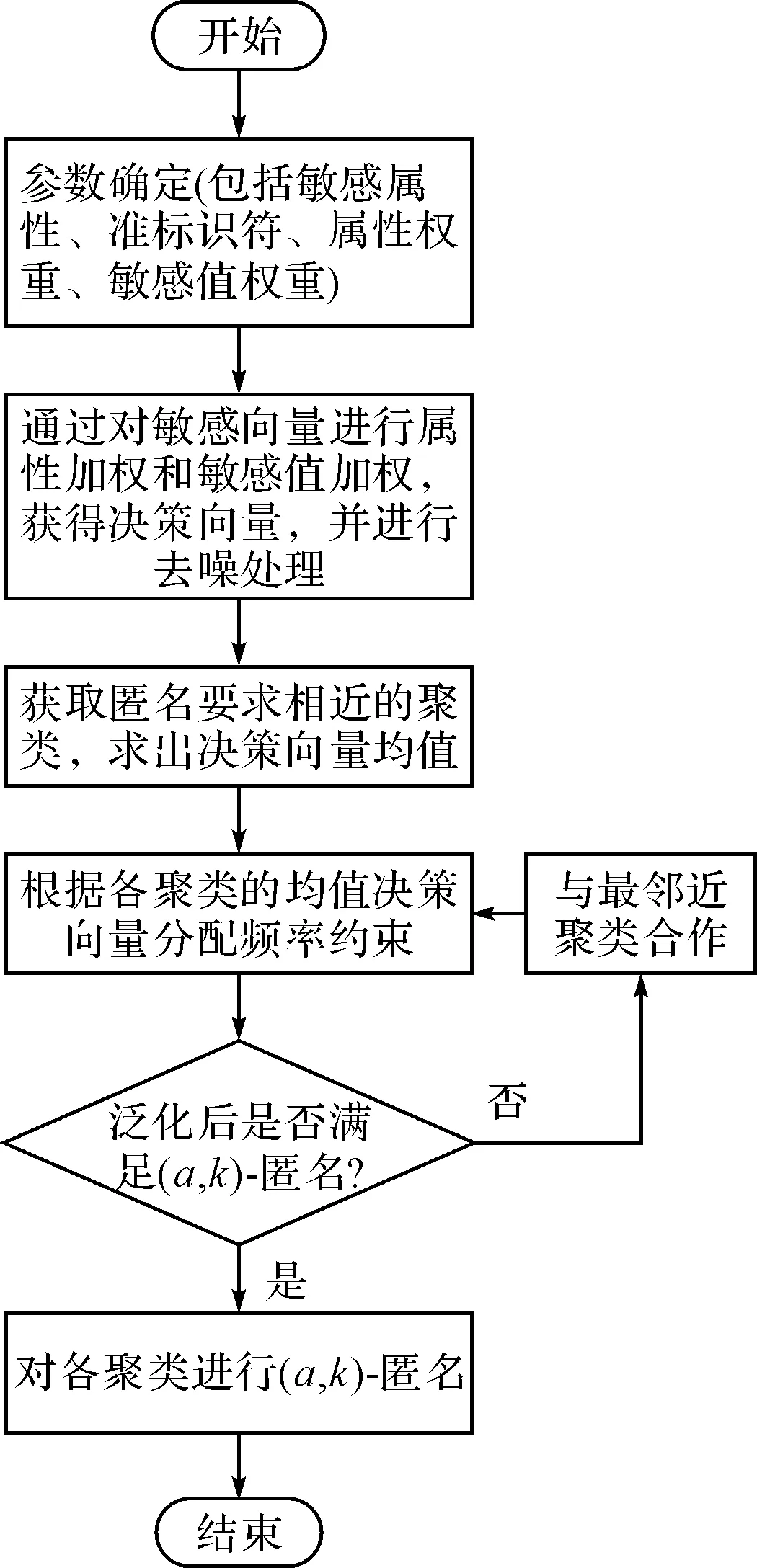
图1 算法流程图
2.3实例分析
为验证算法的有效性和可用性,通过表1所示实例对算法进行具体操作予以简要说明。
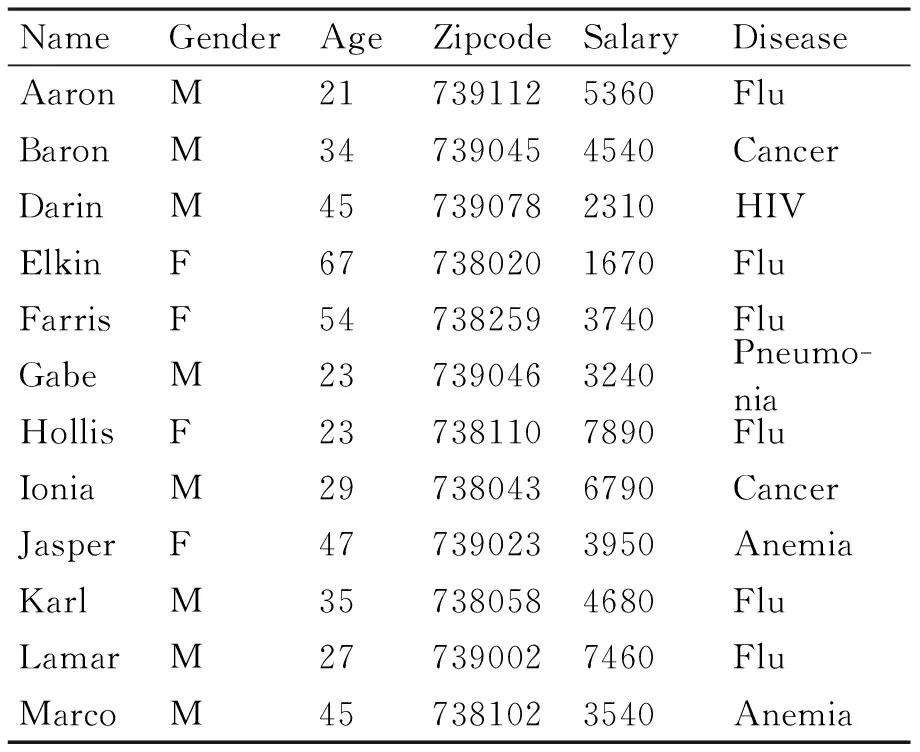
表1 原始数据表

表2 敏感值权重
首先确定敏感属性,准标识符。在此例中,可以认为“Zipcode”、“Salary”、“Disease”三项为敏感属性,则“Gender”、“Age”可以作为链接推理或概率攻击的准标识符。因此应对敏感属性“Zipcode”、“Salary”、“Disease”进行匿名。另外,需由数据发布者确定三项敏感属性的属性权重以及各属性中取值的敏感值权重。考虑实际情况,这里假设三项的属性权重分别为0.4、0.7、0.9;“Zipcode”、“Salary”各敏感值权重相同,取为1;“Disease”中按照疾病的隐私程度,敏感值权重如表2所示。
然后获取各用户的个性化敏感偏好,由各用户敏感向量组成的敏感矩阵(Sensitivity Matrix,SM)(已归一化)设为

通过敏感值加权和属性加权后,得到决策向量形成的矩阵(Decision Matrix,DM)为
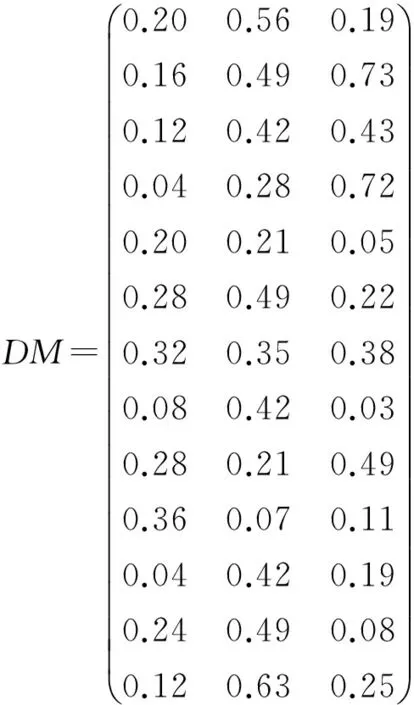

图2 敏感向量可视化
NameclusterDistanceAaron10.096Baron20.183Carlos10.222Darin20.148Elkin30.110Farris10.106Gabe10.247Hollis10.220Ionia20.229Jasper30.110Karl10.148Lamar10.156Marco10.169
由于敏感向量为三维向量,可在三维坐标中描点显示,其中每个点各分量代表每个用户对不同敏感属性的隐私保护要求,如图2所示。
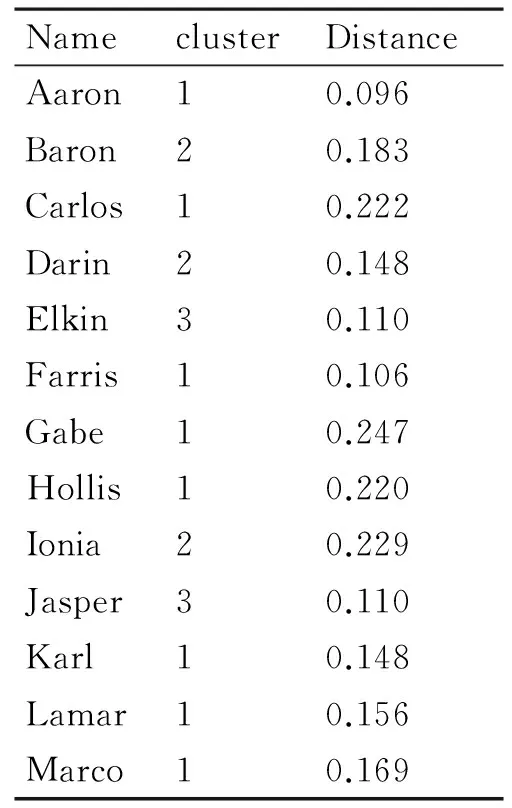
对决策向量进行聚类分析,这里采用K-means聚类分析方法,聚类中心点个数取为3,得到如表3所示各用户的所属聚类,聚类效果二维展示如图3所示。
然后为不同的簇分配合适的αi值,进行(α,k)-匿名,即可获得匿名表。具体(α,k)-匿名过程从略。

图3 聚类二维效果
2.4算法评价
隐私保护的目的不仅是保护用户隐私信息被攻击或者窃取,而且尽可能减小因匿名造成的信息损失。由香农信息论可知,对于一个随机变量,它的信息熵是由各可能值的频率决定的,而与具体值无关。即:
其中lb为以2为底求对数,所得信息熵单位为bit。

通过计算加权信息熵损失可以评价匿名对数据的利用造成损失。
3 结语
本文确定用户敏感属性,构建用户敏感向量,通过敏感值加权和属性加权,获取决策向量,综合考虑不同用户的敏感属性的敏感程度以及敏感属性的不同敏感值,通过聚类分析对不同需求的用户需求进行不同程度的匿名,实现面向用户的不同隐私保护需求的个性化隐私保护。为了评价加权处理以及匿名造成的总损失,采用信息熵衡量匿名的质量。
[1] SAMARATI P, SWEENEY L. Generalizing Data to Provide Anonymity When Disclosing Information (abstract)[C]//Proceedings of the 17th ACM SIGMOD-SIGACT-SIGART Symposium on the Principles of Database Systems. Seattle, WA, USA,1998:188.
[2] CAI S L, ZHANG Z P, SONG L, et al. A K-Anonymity Model for Protecting Privacy[J]. Journal of Yanshan University,2002,10(5):557-570.
[3] 杨晓春,刘向宇,王斌,等.支持多约束的K-匿名化方法[J].软件学报,2006,17(5):1222-1231.
YANG Xiaochun, LIU Xiangyu, WANG Bin, et al. K-Anonymization Approaches for Supporting Multiple Constraints[J]. Journal of Software,2006,17(5):1222-1231.
[4] MACHANAVAJJHALA A, GEHRKE J, KIFER D. L-Diversity: Privacy Beyond K-Anonymity[J]. ACM Transactions on Knowledge Discovery from Data,2007,1(1):3.
[5] XIAO X, TAO Y. Personalized privacy preservation[C]//Proceedings of the 17th ACM SIGMOD International Conference on Management of Data,2006:229-240.
[6] WONG C R, LI J, FU A, et a1. (α,k)-anonymity: An enhanced k-anonymity model for privacy preserving data publishing[C]//Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Philadelphia,2006:754-759.
[7] 刘丽杰,李盼池,李守威.粒化(a,k)-匿名方法研究[J].计算机工程与应用,2014,50(2):75-80.
LIU Lijie, LI Panchi, LI Shouwei. Research of Granulating (α,K)-Anonymous Method[J]. Computer Engineering and Applications,2014,50(2):75-80.
[8] BLUM A, LIGETT K, ROTH A. A Learning Theory Approach to Non-interactive Database Privacy[C]//Proceedings of the 40th Annual ACM Symposium on Theory of Computing,2008:609-618.
[9] 兰丽辉,鞠时光,金华,等.数据发布中的隐私保护研究综述[J].计算机应用研究,2010,27(8):2822-2827.
LAN Lihui, JU Shiguang, JIN Hua, et al. Survey of Study on Privacy-Preserving Data Publishing[J]. Application Research of Computers,2010,27(8):2822-2827.
[10] 韩建民,岑婷婷,虞慧群.数据表k-匿名化的微聚集算法研究[J].电子学报,2008,36(10):2021-2029.
HAN Jianmin, CEN Tinging, YU Huiqun. Research in Microaggregation Algorithms for k-Anonymization[J]. Journal of Electronics,2008,36(10):2021-2029.
[11] 霍峥,孟小峰.轨迹隐私保护技术研究[J].计算机学报,2011,34(10):1820-1830.
HUO Zheng, MENG Xiaofeng. A Survey of Trajectory Privacy-Preserving Techniques[J]. Chinese Journal of Computers,2011,34(10):1820-1830.
[12] 潘晓,郝兴,孟小峰.基于位置服务中的连续查询隐私保护研究[J].计算机研究与发展,2010,47(1):121-129.
PAN Xiao, HAO Xing, MENG Xiaofeng. Privacy Preserving Towards Continuous Query in Location-Based Services[J]. Journal of Computer Research and Development,2010,47(1):121-129.
Individuation Privacy Protection Algorithm Based on Multiple Sensitive Values
HUANG Yulei1LIN Qing1DAI Huijun2
(1. Xi’an Peihua University, Xi’an710125)(2. Xi’an Jiaotong University, Xi’an710049)
The rise of mobile networks as well as intelligent terminal has generated a lot of data, studying and analyzing such data is essential for scientific researcher and business development. However, it will be a serious threat to the user’s privacy, especially the sensitive information, if adversary is able to identify and steal user’s privacy. The existing privacy protection methods usually consider sensitive attributes and corresponding values from an overall perspective, but the sensitivity of different sensitive attributes and different requirements for user’s specific sensitive attributes are paid less attention to. In this paper, an improved algorithm based on K-anonymity model is proposed. In addition, based on information entropy, the degree of anonymity of this algorithm is evaluated.
privacy protection, K-anonymity, individuation anonymity, multiple sensitive values
2016年3月7日,
2016年4月19日
2015陕西省教育厅科学研究基金项目(编号:15JK2091)资助。
黄玉蕾,女,硕士,讲师,研究方向:数据挖掘与大数据。林青,女,硕士,讲师,研究方向:数据挖掘与信息安全。戴慧珺,女,博士,讲师,研究方向:数据挖掘与云计算。
TP309.2DOI:10.3969/j.issn.1672-9722.2016.09.029
猜你喜欢
计算机应用(2022年8期)2022-08-24
党员生活·下(2020年3期)2020-04-20
党员生活(2020年2期)2020-04-17
计算机系统应用(2020年8期)2020-03-22
铁道通信信号(2019年6期)2019-10-08
铁道通信信号(2018年10期)2018-12-06
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
图书馆建设(2015年11期)2015-08-24
电子设计工程(2015年6期)2015-02-27
