
基于EVD变换的鲁棒音频水印算法
2016-10-20 03:31童人婷程航张新鹏
上海大学学报(自然科学版) 2016年4期
童人婷,程航,2,张新鹏
(1.上海大学通信与信息工程学院,上海 200444;
2.福州大学数学与计算机科学学院,福州 350108)
基于EVD变换的鲁棒音频水印算法
童人婷1,程航1,2,张新鹏1
(1.上海大学通信与信息工程学院,上海 200444;
2.福州大学数学与计算机科学学院,福州 350108)
常见的数字信号处理往往会改变音频信号的高频分量并引入随机噪声,并且易造成数字水印信息的位置改变.提出了一种新的数字音频水印算法.在该算法中,原始音频被分为两部分:①运用量化索引调制来嵌入伪随机序列生成的二值同步码;②利用特征值分解(eigenvalue decomposition,EVD)方法先对离散小波变换(discrete wavelet transform,DWT)低频系数进行变换,然后在生成的对角阵中用量化索引调制嵌入水印信息.实验结果表明,在确保不可感知性和较强鲁棒性的前提下,可大幅度提高水印嵌入容量,达到172 bit/s.
音频水印;特征值分解;鲁棒;高容量
随着计算机网络和多媒体信息处理技术的发展,方便快捷地制作、编辑、复制和传输各种无失真的数字化产品成为可能,如数字化的图像、视频、音频、软件、图形、动画和文本等.这给人们带来便利的同时也带来了许多需重视的安全问题,如数字媒体产品的版权保护、软件产品的盗版、数字文档的非法拷贝和各种数字信息的篡改等.
针对上述问题,能够有效实现版权保护的数字水印(digital watermarking)技术应运而生.音频水印是一种嵌入到强背景上的特殊的弱信号,是通过检测装置或水印解码器来进行提取的.通常要求音频水印是不可察觉的,而不可察觉性是建立在人类听觉系统之上的.由于人耳非常敏感,因此设计一个满意的音频水印系统需要满足一些特定的要求,其中鲁棒性、不可察觉性和嵌入容量是数字音频水印中的3个基本要求,这些要求相互矛盾,也相辅相成[1].
除了将音频水印算法归类为时域算法、变换域算法、压缩域算法外[2],根据嵌入方案的不同,可以把近年来数字音频水印的研究成果分为5类:扩频水印方案[3]、利用样本或系数之间的关系来嵌入的集合关系水印方案[4]、自我复制水印方案[5]、不变水印方案[6]、量化水印方案[7]等.Kirovski等[3]提出的扩频水印是在原始音频中嵌入伪随机序列,通过计算含水印音频与伪随机序列之间的相关性来检测水印,扩频水印要求一个耗时的心理声学模型整形过程来减少可感知噪声,且对时间轴缩放攻击十分敏感;集合关系水印通过两个或多个样本集或变换系数集之间的相互关系来嵌入信息[4];自我复制水印的基本思想是通过利用原始音频自己来构成水印,典型的方法有回声隐藏,由于其通常是时域算法,鲁棒性较弱;而不变水印则利用对特定攻击的一些不变特征来嵌入,这种算法嵌入容量不大[5];由Chen等[7]提出的基于量化音频水印方案是通过量化器量化音频样本或变换域系数来嵌入信息,不需要原始音频即能成功提取水印,完全实现了水印的盲提取.
本研究为了实现盲提取,选取了量化水印方案作为水印的嵌入方法,并引入了特征值分解(eigen-value decomposition,EVD)变换以达到更好的鲁棒性,在离散小波变换域实施水印的嵌入与提取,这种灵活的水印方案不仅使水印在鲁棒性和容量上达到了平衡,同时也兼顾了不可感知性.实验结果表明,在兼顾鲁棒性和不可感知性的前提下,其嵌入容量可达172 bit/s.
1 高容量音频水印算法
一个有效的音频数字水印系统必须满足不可感知性和鲁棒性.为了提高水印的鲁棒性,本研究中将同步码嵌在时域里,通过量化索引调制(quantization index modulation,QIM)修改原始音频信号时域的幅值以形成同步段(见图1).而水印嵌在离散小波变换(discrete wavelet transform,DWT)低频系数中,以提高算法的鲁棒性.嵌入时先把原始音频分为两部分:①嵌入同步码作为提取水印的依据;②在频域中嵌入水印信息.提取时先逐点查找同步段,再根据同步段的定位分段进行DWT以提取水印(见图2).

图1 原始音频分段Fig.1 Segmentation of original audio

图2 水印置乱前后Fig.2 Binary and scrambled watermark image
1.1 EVD变换
任意方阵的EVD可用于数字音频水印,从而增强其鲁棒性.如任意一个n阶方阵X可以分解为
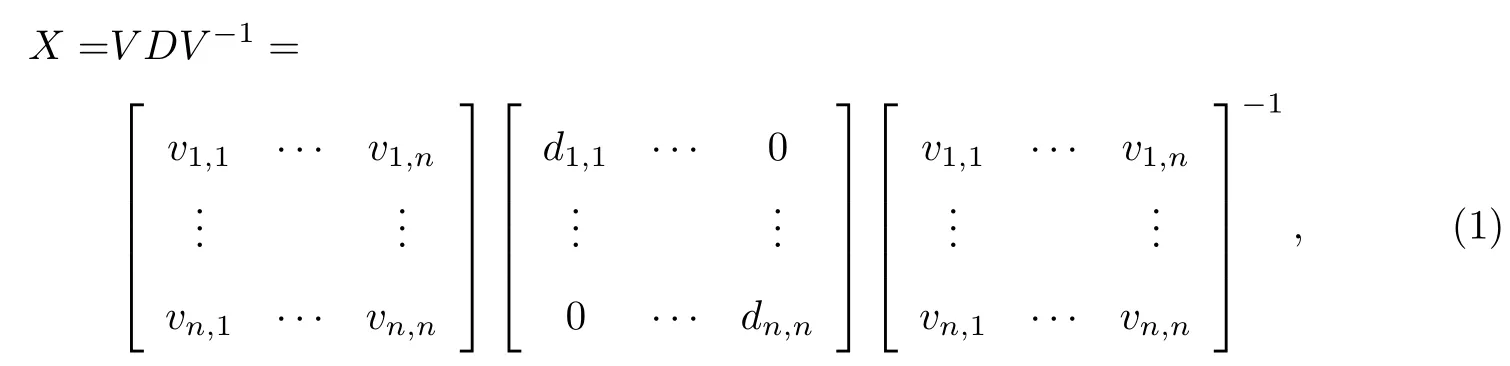
式中,D为X的特征值对角阵,di,j为其元素;V为X的特征向量矩阵,vi,j为其元素.
对于基于EVD的数字音频水印,一段音频被视为一个方阵通过EVD变换分解为3个方阵,通过修改对角阵中元素达到水印嵌入的目的,较一般方法更能提高其鲁棒性.
1.2 水印预处理
Arnold变换是俄罗斯数学家Arnold提出的一种变换.基于Arnold变换的简便和周期性,本研究选取它完成对水印图像的预处理,以达到消除图像像素空间的相关性,并加密水印图像提高安全性的目的.假设水印二值图像大小为M×M,Arnold变换为
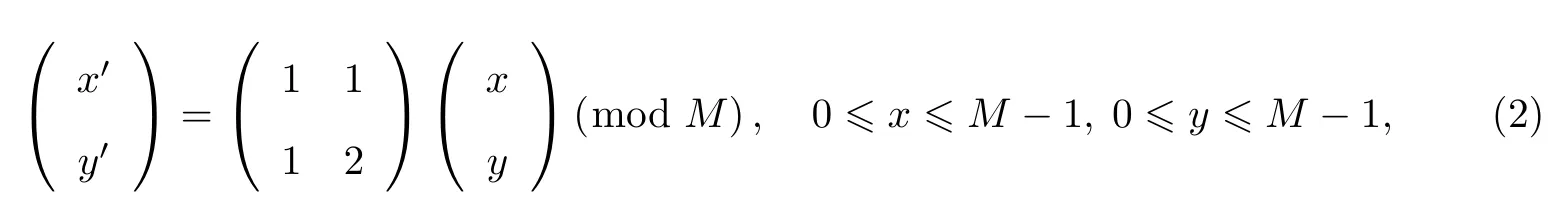
式中,x和y分别表示变换前像素的行与列的位置.二值水印图像经过Arnold变换后,图像像素的位置重新排列,完成了对图像的置乱加密,然后将置乱后的像素矩阵转换成一维二进制数组.
Arnold变换只是改变图像像素点的位置并对总像素变更.每一次Arnold变换都使得图像混沌,如果持续变换一定周期就又能得到原始图像.
1.3 同步码的生成
同步码的使用是为了找到隐藏的信息位的位置,从而避免随机剪裁,抵抗移位攻击.本研究将混沌序列作为同步码[8],在时域中嵌入.
生成长为Lsyn的混沌序列y:
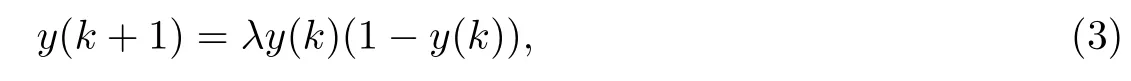
式中,3.57<λ 6 4,k为任意正整数.
利用混沌序列y生成长为Lsyn的二值同步码{Syn(k)}:
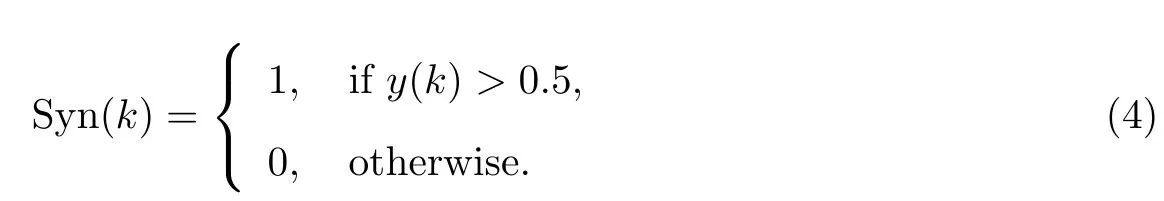
假设{Seq(k)}是与同步码{Syn(k)}等长的未知序列,对{Seq(k)}与{Syn(k)}逐一进行比特比较,当二者的汉明距离小于等于设定阈值t时,即认为{Seq(k)}是同步码.
1.4 同步码嵌入
在时域中嵌入同步码的优点是查找的时间较少,计算成本较低,因此用长为Lsyn二值同步码y修改原始音频并作为同步段的时域样点,以达到同步码的嵌入.嵌入遵循如下形式进行:
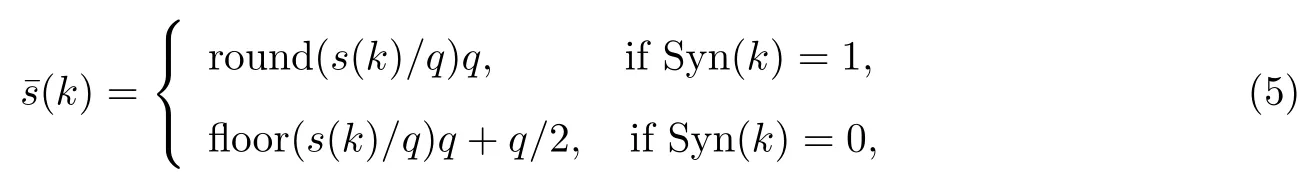
式中,q为同步码对应的量化强度.
1.5 水印嵌入
进行水印嵌入的步骤如下(见图3).
(1)把原始音频s(长为Ls)分为n大段,每大段分为两部分.
(2)第一部分长为Lsyn作为嵌同步码的时域部分,第二部分作为嵌水印的频域部分.
(3)对每大段的第二部分进行分为4 096个(采样频率为44.1 kHz,每帧约93 ms)样点的帧,对每帧进行二层DWT,选取每帧DWT低频系数(1 024个样点)分为若干小段(实验中小段为64或者256个样点),每小段形成方阵(8×8方阵或者16×16方阵).
(4)对步骤(3)形成的方阵S进行EVD变换.
(5)对变换所得的对角阵的第一个值即最大值x=Λ(1,1)进行修改:
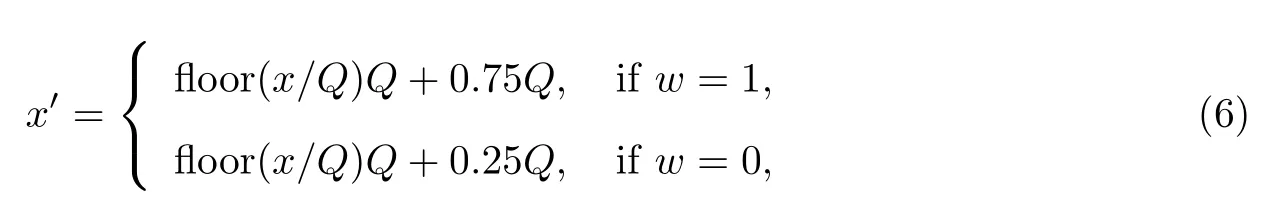
式中,Q为水印对应的量化步长,Q值越大则音质损伤越大而鲁棒性越好,Q值越小则音质损伤越小而鲁棒性越差.因此,通过调整嵌入强度Q的大小来保持音质的损失不被察觉并兼顾鲁棒性,实验表明Q=0.3时最佳.用修改后的值替换在原来的D(1,1)位置,并进行EVD逆变换,其中每个方阵嵌1 bit秘密信息.
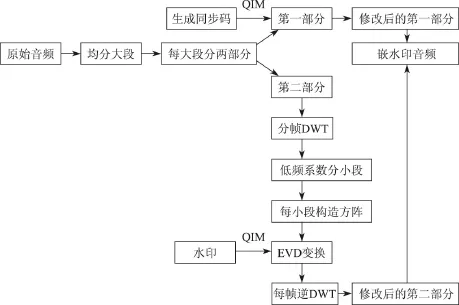
图3 水印的嵌入Fig.3 Watermark embedding
(6)对修改后的方阵生成的一维向量进行离散小波逆变换(inverse discrete wavelet transform,IDWT),再把生成的小段合并,合成大段后与同步段合并最终生成嵌水印音频.
1.6 同步码提取
(2)以长为Lsyn的窗口对进行逐点滑动计算与同步码 es的相似度,若相似度大于设定的相似阈值t,则认为该段与同步码相匹配,即为同步段;否则继续滑动直至匹配.
同步码的提取如下述形式进行:
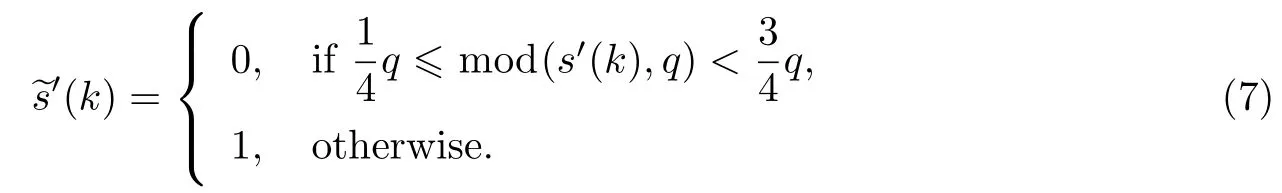
1.7 水印提取
水印提取遵循如下步骤进行(见图4).
(2)对每大段的第二部分进行分为4 096个(采样频率为44.1 kHz,每帧约93 ms[9])样点的帧,对每帧进行二层DWT,将选取的每帧DWT低频系数(1 024个样点)分为若干小段,每小段形成方阵式中为特征向量矩阵.

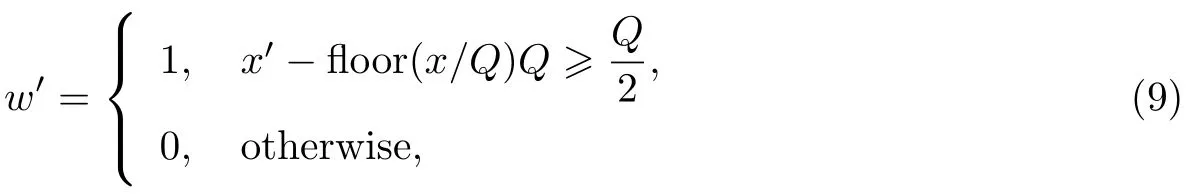
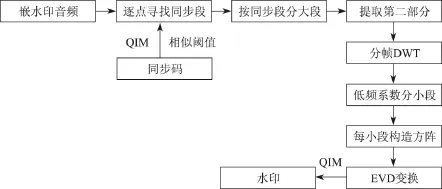
图4 水印的提取Fig.4 Watermark extracting
2 实验结果分析讨论
本实验平台采用Windows7下的Matlab2014a,并将单声道、16位量化、采样率为44.1 kHz的6组不同类型的WAV音频片段作为原始的数字音频信号;一幅M×M= 64×64=4 096的二值图像“Min.bmp”(见图2)和二值向量作为两种待嵌水印.
2.1 不可感知性
常用的语音质量评价方法分为主观评价和客观评价.1996年国际ITU组织在ITUTP.800和P.830建议书中开始制订相关的评测标准:MOS(mean opinion score)测试.MOS具体分值对照如表1所示.本研究用到的P.862-PESQ(perceptual evaluation of speech quality,主观语音质量评估)算法是ITU组织在2001年2月发布的目前最新的语音传输质量测量标准.
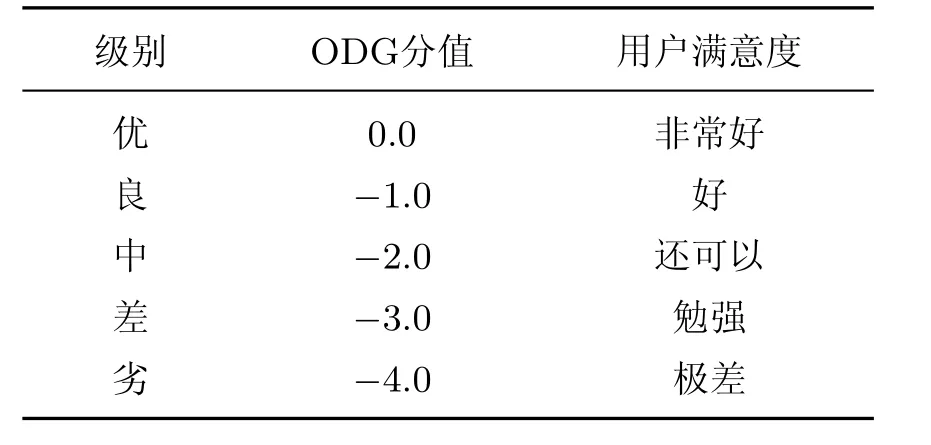
表1 ODG分值对照Table 1 ODG score
PESQ算法是模仿人耳的听觉系统,对参考信号和测试信号进行对比分析得出对应于音频质量的客观差异等级(objective difference grade,ODG)(见表1),范围为[-4,0],分数越接近于0表示音频可察觉的损伤越小[10].
信噪比(signal noise ratio,SNR)是评估音频质量的一种通用的客观测量方法[11],建立在度量均方误差的基础上:
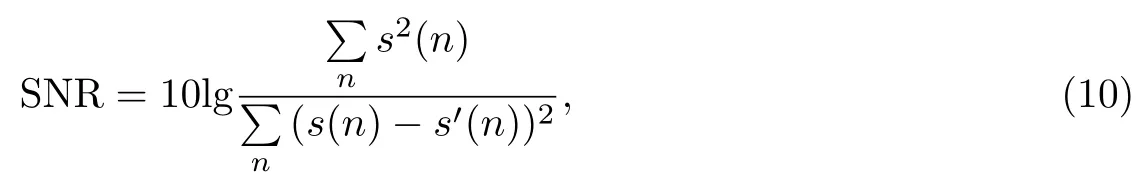
式中,s为音频信号,n为正整数.
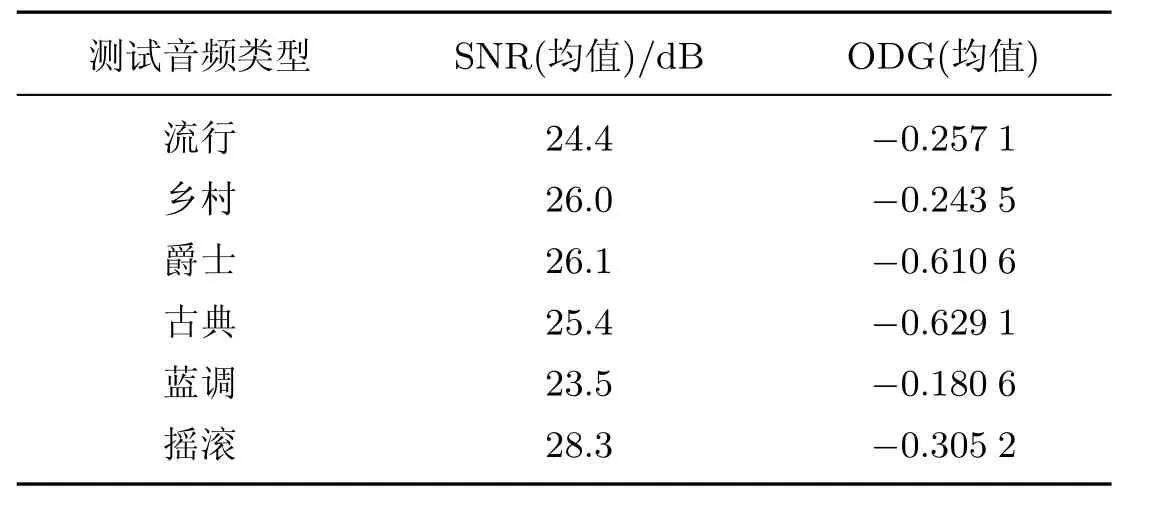
表2 ODG和SNRTable 2 ODG and SNR
近十年来的研究成果表明,SNR在20 dB以上被认为音质良好.由表2可知,本实验中6组测试音频的SNR值都在20 dB以上的良好范围内(见图2).ODG值也都处于[-1,0]的良好等级,含水印的音频信号与原始音频信号的音质非常接近.而由图5和6可知,嵌水印前后音频在时域和频域都改变不大.因此,本研究提出的音频水印算法具有良好的不可感知性.
2.2 鲁棒性
评测音频水印算法是否鲁棒,本研究用归一化互相关系数(normalized cross-correlation,NCC)和误码率(bit error rate,BER)来判定.
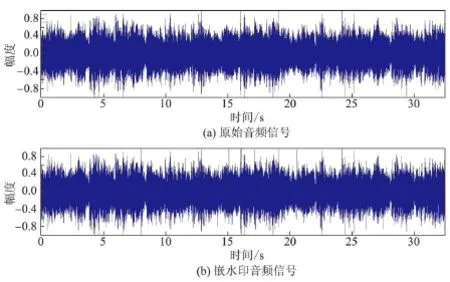
图5 原始音频与嵌水印音频Fig.5 Original audio and watermarked audio
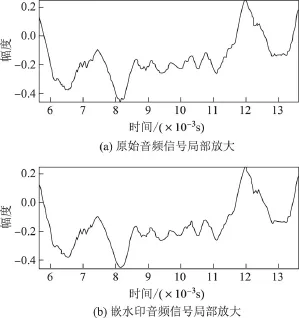
图6 原始音频与嵌水印音频的局部比较Fig.6 Local comparison of original audio and watermarked audio
归一化互相关系数是评测原始信号与嵌水印信号相似度的指标,其值越接近于1则原始信号与嵌水印信号越相似,其定义如下:
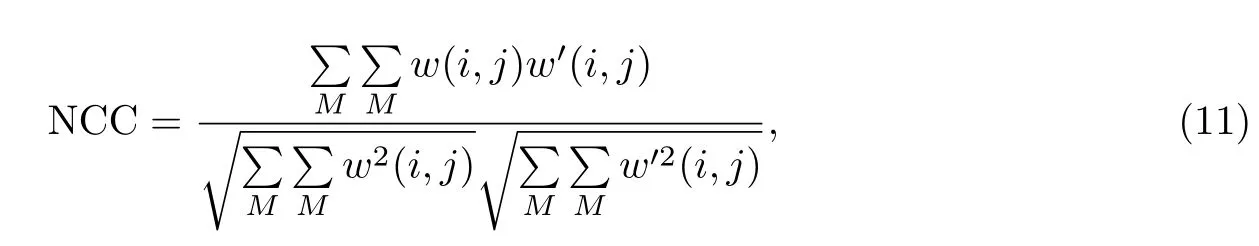
误码率是评测水印检测精度的指标,其值越接近于0说明该算法的水印检测精度越高,定义如下:
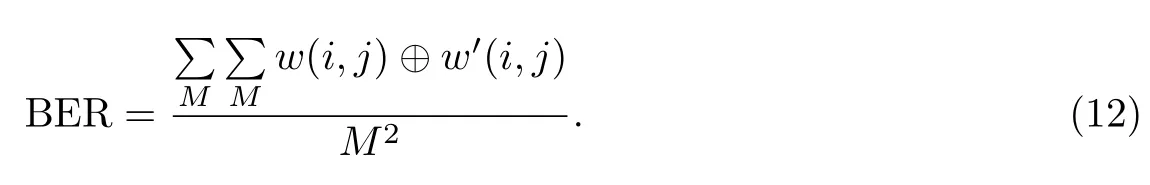
本实验用如下攻击来评测水印算法的鲁棒性:①噪声干扰.对嵌水印音频加SNR为55 dB的高斯白噪声,其均值为0.②低通滤波.对嵌水印音频用截止频率为4 kHz的低通滤波器滤波.③重采样.将嵌水印音频采样频率下降为22.05 kHz,再利用插值将采样频率还原为44.1 kHz.④重量化.将嵌水印音频量化位由16 bit变为8 bit,再恢复16 bit量化.⑤MP3压缩.对嵌水印音频以320 kbit/s的压缩率压缩.实验结果如表3(Q=0.3)、图7和8所示.
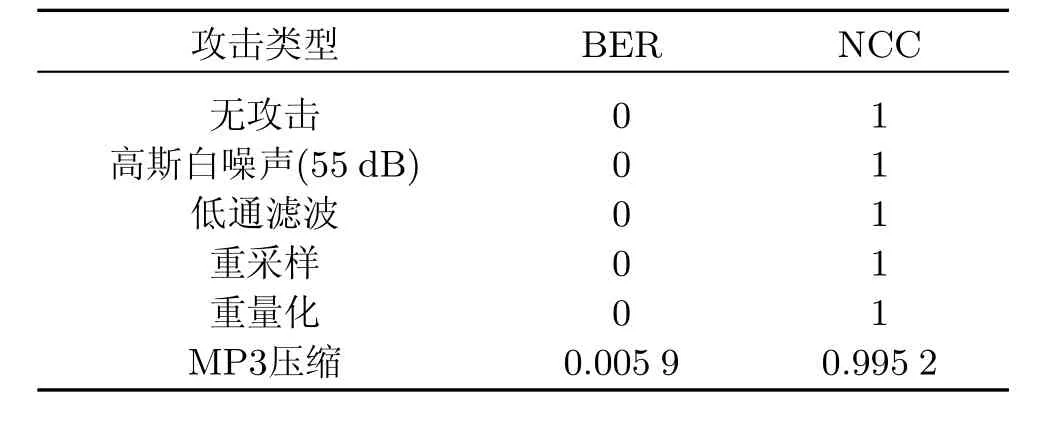
表3 鲁棒性评测结果Table 3 Robustness results

图7 重采样前后提取的水印Fig.7 Extracted watermark before and after resampling

图8 MP3压缩前后提取的水印Fig.8 Extracted watermark before and after MP3 compression
从上述实验结果可以看出,本研究中提出的算法对噪声攻击、低通滤波攻击、重采样、重量化、MP3压缩等操作具有很强的鲁棒性.
2.3 水印容量
未攻击时确保误码率为0和归一化互相关系数为1的状态下,嵌入容量均值可高达172 bit/s(见表4).
另外,实验结果就不可感知性、水印容量两个方面与近期的两个方法比较(见表5).
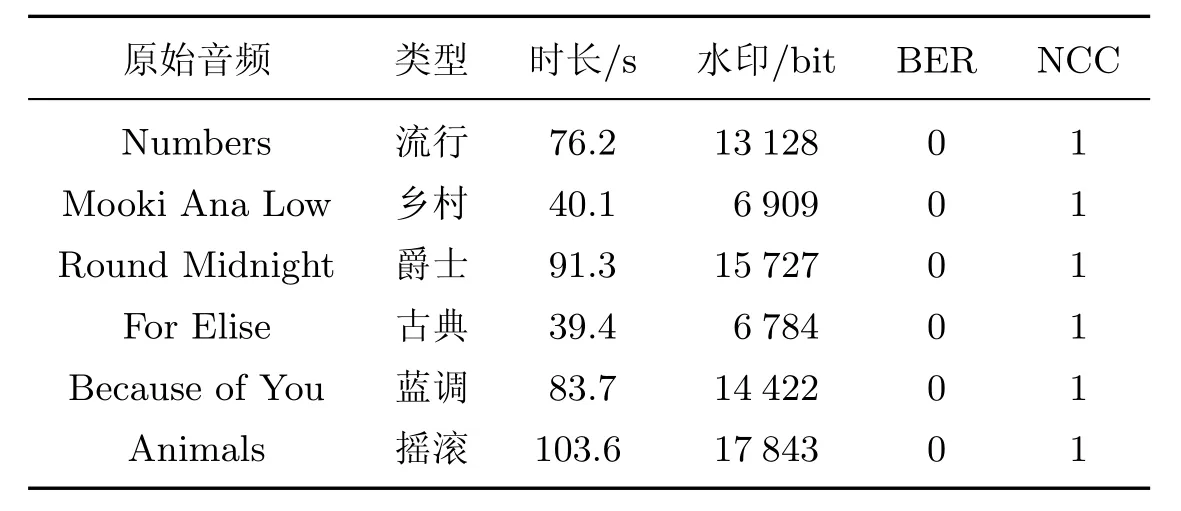
表4 不同音频的嵌入容量Table 4 Capacity of different audio
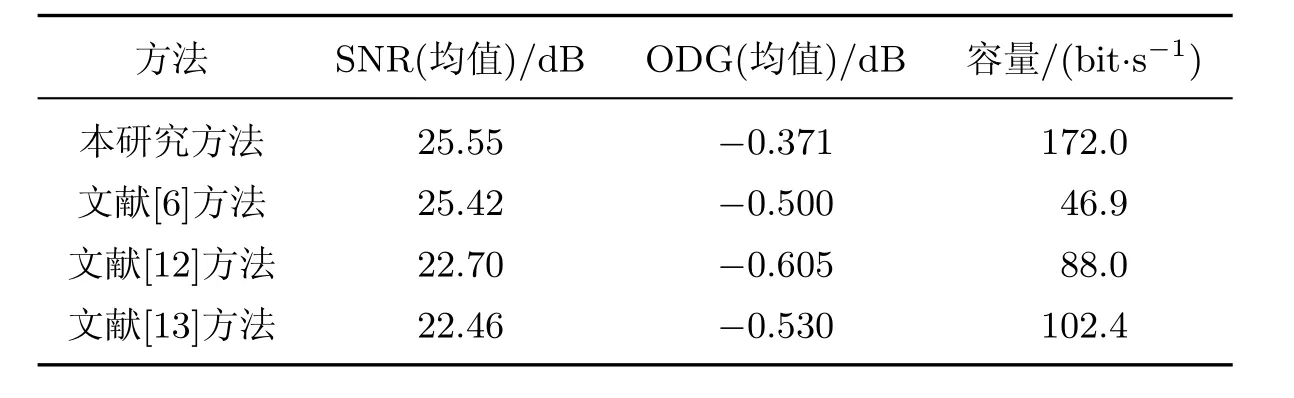
表5 不同算法的比较Table 5 Comparison of different methods
由表5可得出,在相似的SNR条件下,同样使用近两年提出的盲音频水印算法,在ODG均值最低时可得本研究提出的算法不可感知性更低,且嵌入容量可达172 bit/s,而文献[6]中的嵌入容量只有46.9 bit/s,文献[12]中的嵌入容量只有88 bit/s,文献[13]中的嵌入容量只有102.4 bit/s.
3 结束语
本研究就一种新颖的基于EVD的高容量音频水印算法进行了详细阐述.本算法引入了EVD变换,为音频水印嵌入过程中不可感知性和鲁棒性的平衡提供了一种解决方法.实验结果表明,与已有的算法相比,在确保不可感知性和鲁棒性的基础上本算法可达到平均嵌入容量172 bit/s.
[1]孙圣和.数字水印技术及应用[M].北京:科学出版社,2004:388-452.
[2]李伟,袁一群.数字音频水印技术综述[J].通信学报,2005,26(2):100-111.
[3]KIROVSKI D,MALVAR H S.Spread spectrum watermarking of audio signals[J].IEEE Transactions on Signal Processing,2003,51(4):1020-1033.
[4]BHAT V,SENGUPTA I.An adaptive audio watermarking based on the singular value decomposition in the wavelet domain[J].Digital Signal Processing,2010,20(6):1547-1558.
[5]KO B S,NISHIMURA R.Time-spread echo method for digital audio watermarking[J].IEEE Transactions on Multimedia,2005,7(2):212-221.
[6]KHALDI K,BOUDRAA A O.Audio watermarking via EMD[J].IEEE Transactions on Audio, Speech,and Language Processing,2013,21(3):675-680.
[7]CHEN B,WORNELL G W.Quantization index modulation:a class of provably good methods for digital watermarking and information embedding[J].IEEE Transactions on Information Theory, 2001,47(4):1423-1443.
[8]LEI B Y,SOON I Y.Blind and robust audio watermarking scheme based on SVD—DCT[J]. Signal Processing,2011,91(8):1973-1984.
[9]HWAI T H,LING Y H.Variable-dimensional vector modulation for perceptual-based DWT blind audio watermarking with adjust able payload capacity[J].Digital Signal Processing,2014,31:115-123.
[10]ERFANI Y,SIAHPOUSH S.Robust audio watermarking using improved TS echo hiding[J].Digital Signal Processing,2009,19(5):809-814.
[11]POHLMANN K C.数字音频原理与应用[M].4版.北京:电子工业出版社,2002:213-218.
[12]ZHANG J Q,WANG H X.Audio watermarking scheme resistant to both random cropping and lowpass filtering,communications[C]//2013 International Conference on Communication,Circuits and Systems.2013:292-295.
[13]WANG X K,WANG P J.A norm-space,adaptive,and blind audio watermarking algorithm by discrete wavelet transform[J].Signal Processing,2013,93(4):913-922.
本文彩色版可登陆本刊网站查询:http://www.journal.shu.edu.cn
Robust audio watermarking based on eigen-value decomposition
TONG Renting1,CHENG Hang1,2,ZHANG Xinpeng1
(1.School of Communication and Information Engineering,Shanghai University,Shanghai 200444,China;
2.College of Mathematics and Computer Science,Fuzhou University,Fuzhou 350108,China)
Common digital signal processing often introduces noise into audio signals and cause high-frequency distort.Meanwhile,both signal processing operations and malicious attacks may change location of watermark information.By making use of robustness of eigen-value decomposition(EVD),a blind audio watermarking algorithm is proposed.The original audio signal is divided into two parts.Binary codes for synchronization are embedded into the first part using quantization index modulation(QIM).The approximation components of discrete wavelet transform(DWT)of the second part is transformed using EVD to generate a diagonal matrix,and the watermark information is embedded into the matrix entries with QIM.Experimental results show that embedding capacity of the proposed method is as high as 172 bit/s,and it still maintains good audio quality and can tolerate a wide range of common attacks.
audio watermarking;eigen-value decomposition(EVD);robust;high capacity
TP 391
A
1007-2861(2016)04-0388-10
10.3969/j.issn.1007-2861.2014.05.017
2014-11-26
国家自然科学基金资助项目(61472235)
张新鹏(1975—),男,教授,博士生导师,博士,研究方向为多媒体信息安全.E-mail:xzhang@shu.edu.cn
猜你喜欢
作文小学高年级(2022年6期)2022-07-01
学生导报·东方少年(2019年24期)2019-12-30
测控技术(2018年10期)2018-11-25
电子产品世界(2018年1期)2018-09-21
计算机技术与发展(2017年12期)2017-12-20
计算机应用(2016年10期)2017-05-12
电子制作(2017年10期)2017-04-18
散文诗世界(2016年5期)2016-06-18
现代商贸工业(2016年35期)2016-04-09
西部广播电视(2015年10期)2016-01-18
