
改进型RFID自适应标签识别算法
2016-10-17 09:13:48王玉皞
电视技术 2016年9期
孙 宇,王玉皞,李 唯,邓 晟
(南昌大学 信息工程学院,江西 南昌 330031)
改进型RFID自适应标签识别算法
孙宇,王玉皞,李唯,邓晟
(南昌大学 信息工程学院,江西 南昌330031)
基于碰撞识别算法系列,提出改进型自适应标签识别算法(Improved Adaptive Collision Tree Algorithm,IACT)。算法通过优化查询前缀,消除了自适应碰撞标签识别算法在四叉树搜索产生的空时隙查询,从而减少了算法的时间复杂度,提高识别效率。通过理论推导和计算机仿真可知,该算法比自适应标签识别算法(Adaptive Collision Tree Algorithm,ACT)有着明显的优化。
RFID;标签识别;防碰撞
1 射频识别技术
射频识别(Radio Frequency Identification,RFID)技术是一项利用射频进行非接触式双向通信的自动识别技术[1-2]。它作为物联网的核心技术,在国家行业发展中发挥着越来越重要的战略作用,并影响社会的各领域,其发展显现出高速化、规模化、泛在化等特点。当多个标签(tags)在同一信道与阅读器通信时,就会引发标签碰撞,为实现多标签识别,就必须解决多标签信号碰撞冲突的问题。尤其在大规模的RFID标签场景下[3],RFID系统的标签防碰撞能力直接决定RFID系统的识别效率。
目前,解决RFID系统中的标签碰撞问题主要采用两大类标签防碰撞算法(anti-collision algorithm)[4],一类是基于时隙随机分配的Aloha算法[4-6](随机性防碰撞协议),主要包括纯Aloha(PA)、时隙Aloha(SA)、帧时隙Aloha(FSA)、动态帧时隙Aloha(DFSA)等,适用于数量较少的标签识别。另一类是基于树形搜索的防碰撞算法(确定性防碰撞协议),包括分裂树(BTS)[7]、二进制搜索(BS)[8]、查询树算法(QT)[9],以及各种改进算法和混合协议[10-11]。这类算法比较复杂,但是适用于RFID标签较多的场景。文献[12-14]就提出了一系列碰撞识别算法,这类算法可以利用标签之间的比特位碰撞,消除了传统树形算法中阅读器必须对接受序列进行逐比特识别的限制,尤其在标签数量较多的情况,很好的减少了RFID系统的查询时隙,由此也减少了系统通信复杂度。
文本在基于自适应标签识别算法(Adaptive Collision Tree Algorithm,ACT)[14]算法的基础上,提出了一种改进型标签识别算法(IACT),本文的算法对ACT算法中的四叉树搜索进行了前缀优化,消除了ACT算法中四叉树搜索产生的空时隙,同时也提高了算法识别效率。
2 碰撞识别算法以及相关改进
2.1曼彻斯特码
RFID系统中,标签ID为“0”和“1”的二进制。标签编码方式有多种,在二进制搜索算法(Binary Search,BS)中,采用的编码方式是曼彻斯特码。曼彻斯特码[15]是利用相位进行编码。其编码方式为数据采集的时钟信号(每个码元时间的中间位置)处必有跳变,编码值1为前半部分高电位,后半部分为低电位,即从高电平跳变到低电平(下降沿),编码值0为前半部分低电位,后半部分高电位,即从低电平跳变到高电平(上升沿)。这样的好处是可以检测到发生标签ID碰撞时,其碰撞比特的精确位置和标示。本文提出的算法就是采用曼彻斯特码,在发生碰撞时就能够准确地知道标签ID碰撞比特位。利用此特点,改善树形算法。根据每个前缀下的匹配标签比特位。可以快速更新前缀,有效减少查询时隙和通信复杂度。
2.2CT算法以及改进型ICT算法
在文献[12],提出碰撞识别算法(Collision Protocol,CT),其主要是基于查询树算法(QT),在算法中采用了曼彻斯特编码,标签在每次的最高碰撞位进行分裂和叠加前缀。所以每一次查询的查询码可能长度都不一定一样,有效的减少了在RFID标签识别过程中出现的空时隙。而ICT算法[13]是在CT算法基础上,根据标签ID编码的“二元性”,即每个标签ID编码只能是“0”或者“1”,提出了单次查询,两次响应。通过两个标示位“0”和“1”,进行不同子周期的响应,所以一次查询就可以得到两个标识位下面的不同标签。
2.3自适应标签识别算法
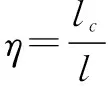
(1)
假设RFID系统中有X个待识别的标签ID,系统分配的分叉树是L,那么在深度为1的搜索深度下,标签ID的识别概率是p(1)=(1-1/L)X-1,那么在搜索深度为m时,那么其识别概率为
p(m)=p(1)[1-p(1)]m-1
(2)
搜索深度均值就为

(3)
将式(2)带入式(3)得到
(4)
因为1-p(1)必然是小于1的,最后根据等比数列算出搜索深度均值
(5)
已知时隙表达式为
(6)
式中:Tf表示系统识别均时隙。当分叉树分别是2和4时,系统识别均时隙则为
(7)
(8)
最后将式(7)公式(8)进行比较。可以计算出,当X<3时,T2用时更少。当X≥3时,T4用时更少。通过和碰撞因子的转换,可以知道η=1-(1/2)3-1=0.75是其临界。每次检测碰撞因子时,当碰撞因子η<0.75选择二叉树搜索,当η≥0.75,采用四叉树。
3 改进型自适应标签识别算法
ACT算法可以合理的在ICT算法基础上进一步减少碰撞时隙,其通过碰撞因子和待识别标签数量X之间的转换,但是还存在一些误差。因为,在标签识别的过程中,虽然可以利用曼特斯特编码知道碰撞位从而得到定义的碰撞因子,但是实际上当前节点的碰撞因子并不是每次都是能够对应准确的待识别标签ID数X。比如,碰撞比特是0011和1100这两个。那么就可以知道其碰撞位为全4位碰撞。那么可见,碰撞因子为η=1满足了之前的理论η≥0.75,应该采用四叉树搜索,这样在选择四叉树搜索下就会多产生两个空时隙。
ACT算法在处理ICT多叉树自适应问题的选择上还有改进。为了减少自适应多叉ICT算法可能产生的查询空时隙,可以通过对阅读器的前缀进行优化,也就是本文提出的改进型自适应碰撞识别算法(Improved adaptive collision tree algorithm,IACT)。在二叉树的情况下,不会产生多余空时隙。那么在碰撞因子η<7.5这个判决条件下,还是采用二叉树ICT算法。而在碰撞因子η≥0.75时,采用四叉树。但是在发送查询之前,先要对当前节点碰撞位进行一个判断处理。
就如上面的标签,若碰撞的标签ID是0011和1100。可知其碰撞比特位为XXXX,碰撞因子为4/4=1,采用四叉树。本文将4个碰撞比特位分别从高位到低位标为X3,X2,X1,X0。阅读器先发送一个最高两位碰撞位即为11,其他比特位全为0的指令给标签。标签将接收到的指令与自己标签ID相“与”,即“0”与“0”得0、“0”与“1”得0、“1”与“0”得0、“1”与“1”得1。那么得到ID码为1100,0000。所以标签ID的X3,X2位分别是11和00。为了让阅读器能够识别出高两位的实际标签ID码。将得出的高两位11和00转换10进制然后返回其对应10进制位置,即返回一个分别是X3和X0位置为1,其他位置为0的ID码,阅读器再次收到就可以根据碰撞位判断出当前存在的高两位ID码。通过在发送查询之前进行判断处理就可以有效的检测出当前标签ID的高两位,从而减少了发送无用查询的空时隙情况。图1是IACT算法的算法流程。

图1 IACT算法流程
和查询树算法一样,在初始时,前缀堆栈为空。开始时,阅读器从前缀池里取出空前缀,发送问询指令,等待标签响应。所以本文的算法步骤如下:
1)阅读器向前缀放入空串,将标签ID置空。
2)阅读器发送前缀,标签响应。标签根据自己标志位在不同响应子周期发送自己的标签ID。
3)判断前缀是否为空,为空则识别完成。否则继续。在有两个响应周期的阅读器情况,回复标签中的剩余ID的最高碰撞位作为标志位。前缀的更新为当前前缀+剩余碰撞ID位的标志位前没有发生碰撞的比特。在响应周期为S1的周期,标签发送标志位为“0”的标签。在响应周期S2,标签发送标志位为“1”的标签。来响应阅读器的请求。
4)判断是否发生碰撞,计算碰撞因子η,若η<0.75,则采用二叉树,发送前缀;若η≥0.75,则采用四叉树,根据判断处理得出高两位前缀,发送前缀。
5)将发生碰撞的最高位前的比特与前缀合并,形成新的前缀,放入堆栈。
6)再次看前缀是否为空,直到前缀为空为止。识别完成。
下面为一个识别实例,假设有7个长度为4的ID标签,分别是A:0001,B:0010,C:0011,D:0100,E:0101,F:1100,G:1110。使用本算法进行识别。识别过程如图2所示。
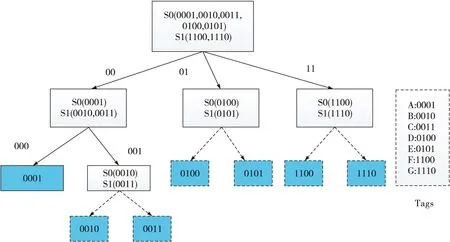
图2 IACT算法识别实例图
通过图2可知,本次识别7个标签使用6次查询。其中阴影表示识别标签,虚线表示不需要发送查询码。
4 IACT算法分析

(9)
当搜索深度大于m时,采用二叉树。因为采用子周期的结构,在搜索的过程中二叉树的查询次数需要去掉子周期的次数。那么可得采用二叉树搜索的识别时隙
(10)
式中:T子的个数根据标签碰撞的情况在0到X/2之间。本文改进了完全四叉树的查询,优化查询前缀,所以这部分的时间复杂度需要加上阅读器在检测到碰撞二次发送查询的时隙和减去空闲的时隙。二次查询的时隙正好与碰撞时隙相等。假设,在四叉树的m搜索层,X待识别标签。那么就有4m个节点,在m层n个标签响应同一节点的概率服从二项分布
(11)
那么,空时隙即为0个标签响应,识别时隙即为1个标签响应,碰撞时隙即为多个标签响应。概率表达式分别如下
(12)
(13)
P(1/X,m)
(14)
式中:n>1,p=1/4m表示为在4m节点里选择一个节点的概率,那么可知
P(0/X,m)=(1-1/4m)X
(15)
P(1/X,m)=X·4-m(1-1/4m)X-1
(16)
P(n/X,m)=1-(1-1/4m)X-X·4-m(1-1/4m)X-1
(17)
设αmi/X和δmi/X分别表示在m层第i节点被搜索的概率和在m层第i节点发生碰撞的概率,节点在同一层的搜索和碰撞的概率相同,可知δmi/X=P(k/X,m),当父节点发生碰撞时,下一节点才能被访问到,所以当深度大于1时,αmi/X=δ(m-1)i/X。平均查询总时隙为
(18)
最后得到
(19)
把δmi/X=P(k/X,m)代入得到
X·4-m(1-1/4m)X-1]
(20)
碰撞时隙为
(21)
空闲时隙为总时隙减去碰撞时隙和识别时隙得到
(22)

根据文献[16]可得大概关系为
(23)
那么,IACT算法的总时隙是
(24)
所以吞吐率为
(25)
根据文献[13]中对于ICT算法通信复杂度的计算,可以推导IACT算法的通信复杂度为只是在二次查询时增加一次查询码,但是减少了空闲时隙的查询码。所以算法的通信复杂度为
(26)
式中:Creader(X)表示为阅读器通信复杂度;Ctags(X)表示为标签通信复杂度;lq,i是在i周期发送查询前缀长;lr,i是在i识别周期发送响应的长度。标签ID长度lID=lq,i+lr,i,所以得到
(27)

5 IACT仿真以及性能分析
通过以上分析,本文主要仿真RFID标签识别最重要的两个性能对比:查询总时隙和算法吞吐率。将IACT算法与CT,ICT,ACT算法比较。仿真场景设置为标签ID长度96,标签数量从0~10 000个,假设所有标签空间分布均匀,没有丢失标签ID。通过仿真如图3所示。

图3 IACT算法与QT,CT,ICT,ACT算法的查询次数仿真对比图
从仿真结果看得出,IACT优化了ACT在四叉树时的前缀搜索。极大的减少了空时隙,进而极大的减少了总查询次数,减少了系统的识别时间复杂度。
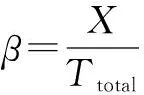
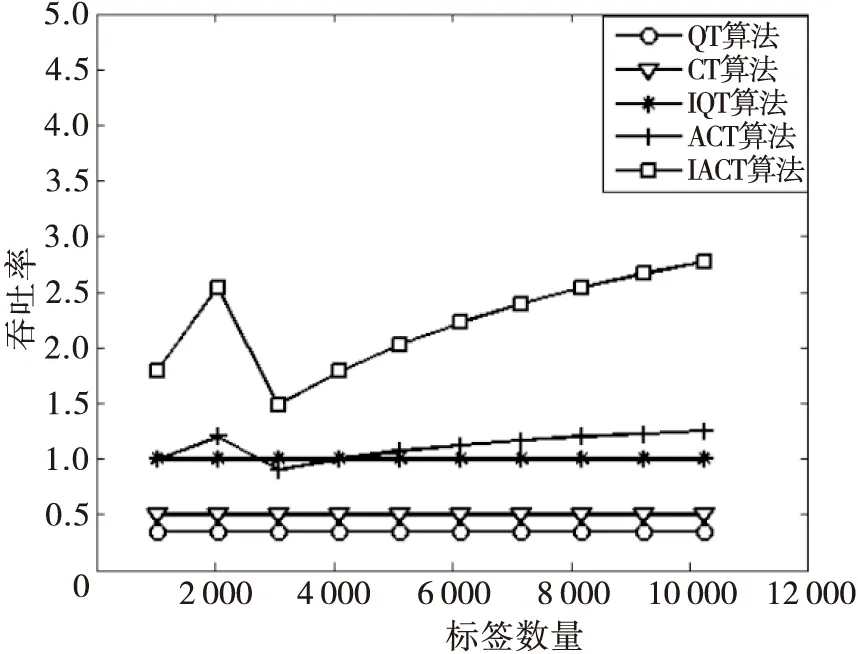
图4 IACT算法与QT,CT,ICT,ACT算法的吞吐率仿真对比图
由图4可以看出,新的改进算法吞吐率有了很大的提高。然而,采用了四叉树的算法在几个节点上会出现一些跳变,这是因为与算法的搜索深度有关,深度m=⎣log4(X/3)」表示向下取整,不是一个连续的整数会导致标签数量在到达一定数量会出现搜索深度的跳变,所以算法查询次数和吞吐率都会出现一个阶段的上升然后有一个跳变。从图中可以看出QT算法一直维持在0.4左右的吞吐率,CT和ICT分别维持在0.5和1.0的吞吐率左右。ACT的吞吐率也是高于ICT的。由于总查询时隙的极大的减少,IACT吞吐率也是极大的提高,高于其他算法。
6 结论
本文提出一种新的改进型碰撞识别算法,在自适应碰撞识别算法上有效去除在选择四叉树搜索时产生的空时隙。有效减少系统总查询时隙。在识别性能上也是极大地优化了ACT算法,通过理论和仿真验证了提出的IACT算法优于ACT,进一步提升了算法的适用性。表明IACT算法可以应用于标签识别,能高效地解决标签碰撞问题。
[1]FINKENZELLER K. RFID-handbook fundamengtals and applications in contact less smart cards and identification [M]. 2nd ed. New York:Wiley and Sons,2003.
[2]WANT R. An introduction to RFID technology[J]. Pervasive computing,2006(1):25-33.
[3]SHAO C,KIM T,YU J,et al. ProTaR: probabilistic tag retardation for missing tag identification in large-scale RFID systems[J]. IEEE transactions on industrial informatics,2015,11(2):513-522.
[4]KLAIR D K,CHIN K W,RAAD R. A survey and tutorial of RFID anti-collision protocols[J]. Communications surveys & tutorials,2010,12(3):400-421.
[5]SU W,ALCHAZIDIS N V,HA T T. Multiple RFID tags access algorithm[J]. IEEE transactions on mobile computing,2010,9(2):174-187.
[6]KAITOVIC J,IMKO M, LANGWIESER R,et al. Channel estimation in tag collision scenarios[C]// 2012 IEEE International Conference on RFID. Orlando,FL:IEEE,2012: 74-80.
[7]HUSH D R,WOOD C. Analysis of tree algorithms for RFID arbitration[C]//IEEE International Symposium on Information Theory. Cambridge, MA:IEEE,1998:107-110.
[8]YU S, ZHAN Y, WANG Z,et al. Anti-collision algorithm based on jumping and dynamic searching and its analysis[J]. Computer engineering,2005,31(9):19-20.
[9]LAW C,LEE K,SIU K Y. Efficient memoryless protocol for tag identification[C]//Proc. 4th International Workshop on Discrete Algorithms And Methods For Mobile Computing And Communications. New York:ACM,2000:75-84.
[10]BONUCCELLI M A,LONETTI F,MARTELLI F. Tree slotted ALOHA: a new protocol for tag identification in RFID networks[C]//Proc. 2006 International Symposium on World of Wireless,Mobile and Multimedia Networks. Buffalo-Niagara Falls,NY:IEEE,2006:603-608.
[11]RYU J,LEE H,SEOK Y,et al. A hybrid query tree protocol for tag collision arbitration in RFID systems[C]//IEEE International Conference on Communications,2007. Glasgow:IEEE,2007:5981-5986.
[12]JIA X,FENG Q,MA C. An efficient anti-collision protocol for RFID tag identification[J]. Communications letters,2010,14(11):1014-1016.
[13]JIA X L,FENG Q Y. An improved anti-collision protocol for radio frequency identification tag[J]. International journal of communication systems,2015,28(3):401-413.
[14]LIU X,QIAN Z,ZHAO Y,et al. An adaptive tag anti-collision protocol in RFID wireless systems[J]. Wireless communication over zigbee for automotive inclination measurement china communications,2014,11(7):117-127.
[15]FORSTER R. Manchester encoding:opposing definitions resolved[J]. Engineering science & education journal,2000,9(6):278-280.
[16]张学军,蔡文琦,王锁萍.改进型白适应多叉树防碰撞算法研究[J]. 电子学报,2012,40(1):193-198.
孙宇(1989— ),硕士生,主研通信系统、RFID防碰撞协议;
王玉皞(1977— ),博士生导师,主要研究方向为无线协作、通信系统、雷达通信一体化、RFID等;
李唯(1991— ),女,硕士生,主研RFID防碰撞协议;
邓晟(1991— ),硕士生,主研电波传播、信道参数估计、无源雷达。
责任编辑:时雯

8月24—27日,第二十五届北京国际广播电影电视展览会(BIRTV2016)在北京中国国际展览中心举行。展会以“融合媒体 智慧广电”为主题,汇聚了中外500多家参展商,展览面积超过5万平方米。展会同期举办了专业论坛超10场,全面展示了广电领域最新的技术和设备、传统主流媒体创新业务及融合发展成果,并展望了广电领域未来的发展方向。
Improved adaptive tag-reading algorithm in RFID system
SUN Yu,WANG Yuhao,LI Wei,DENG Sheng
(CollegeofInformationEngineering,NanchangUniversity,Nanchang330031,China)
A novel improved adaptive collision tree algorithm (IACT) is proposed for RFID tags-reading based on adaptive collision tree algorithm. The improved algorithm reduces idle time slots which occurs in adaptive collision tree algorithm (ACT) by optimizing the prefix-query. So, the proposed algorithm reduces the time complexity and improves the efficiency of recognition in RFID system. By mathematical analysis and simulation, it proves that the improved adaptive collision tree algorithm (IACT) has a better performance than adaptive collision tree algorithm (ACT) for RFID tags-reading.
RFID; tag-reading; anti-collision
TP39
A
10.16280/j.videoe.2016.09.028
2016-01-05
文献引用格式:孙宇,王玉皞,李唯,等.改进型RFID自适应标签识别算法 [J].电视技术,2016,40(9):137-142.
SUN Y,WANG Y H,LI W,et al.Improved adaptive tag-reading algorithm in RFID system[J].Video engineering,2016,40(9):137-142.
猜你喜欢
电脑报(2022年37期)2022-09-28 05:31:07
电子设计工程(2022年15期)2022-08-17 10:07:04
现代计算机(2021年14期)2021-07-09 17:19:40
东北师大学报(自然科学版)(2018年3期)2018-09-21 09:06:36
科技创新与应用(2017年35期)2017-12-19 08:33:36
智富时代(2017年6期)2017-07-05 16:37:15
武汉轻工大学学报(2016年4期)2017-01-16 08:53:03
现代计算机(2015年17期)2015-09-26 02:01:54
建筑材料学报(2015年3期)2015-02-28 02:36:27
物联网技术(2014年8期)2014-08-27 16:30:01
