
基于神经网络与比例法的多文字识别
2016-10-17 09:05林毅斌姚剑敏郭太良
电视技术 2016年9期
林毅斌,姚剑敏,郭太良
(福州大学 物理与信息工程学院,福建 福州 350002)
基于神经网络与比例法的多文字识别
林毅斌,姚剑敏,郭太良
(福州大学 物理与信息工程学院,福建 福州 350002)
用传统方法进行文字识别时,需要花费时间分别去提取各个文字的区域。但是在讲究速度与效率的实时系统中,文字识别的速度是一个值得深思的问题。提出了一种多文字识别方法,其核心思想是将输入的文字当做一个整体进行处理,而不需要在单字区域提取上消耗过多时间,再利用ROI以及投影法进一步减少比例法特征提取算法的运算时间。在此基础上,采用BP神经网络进行样本训练与文字识别。实验结果表明,该方法能够有效地实现快速识别,识别四个字的所花费的时间为120 ms。
多文字识别;比例法;BP神经网络
伴随着计算机技术的快速发展,多媒体信息的重要传递媒介已经逐渐从文字转换为图像;同时相机从之前的胶卷相机发展到数码相机,并且其制造技术逐年成熟,大大提高了数码相机的性能,高质量的相机也出现在市场上,配合这软件技术对拍照质量的提升,高质量的数字图像已经可以较为轻松地获取。因此,作为数字图像处理中的文字识别技术也由此受到了研究人员的关注[1]。位于数字图像中的文字(如拍摄到的车牌等)是图像信息中的重点,具有非常丰富的含义,对于图像中文字信息的提取,可获取图像中包含的语义,可以运用到生活中的多个方面[2]。
文字识别是模式识别的重要应用领域之一,文字识别的方法主要有以下几种:基于统计特征字符的文字识别方法[3-4]、基于模板匹配的方法[5]、模糊识别和结构字符识别[6]。作为模式识别中的一种,文字识别的成功率在很大程度也是取决于所提取特征的正确性和稳定性。因此,能良好反映文字本质的特征在表示文字的同时,还应该具有易于实现和简洁性质[7]。
神经网络作为一门日益成熟的学科,已经在计算机视觉、语言识别、模式识别等领域广泛应用,利用神经网络来实现文字识别也因此成为研究人员的兴趣所在,受到重视[8]。其中BP神经网络算法具有算法成熟,结构简单,精确寻优等优点,故而可将BP神经网络用于文字识别。
由于在现实使用中,特别是在实时系统中,文字识别的速度是制约系统的一大因素,例如在脱机式智能显示器自动化测试时,由于图像中文字信息保持的时间长短不一,文字识别所消耗时间过长就可能导致文字信息的漏测,造成错误。因此本文提出基于神经网络和比例法的多文字识别方法,将多个文字进行统一处理,减少文字识别的时间,提升速率。
1 比例法文字特征提取
传统的文字识别技术,通常对各个文字区域采用分别提取的方式,由此为基础上再利用某种文字识别算法对各个单文字进行识别,得到各个文字的识别结果,从而得到整体文字识别的结果。
本文采取的特征提取方法为比例法提取,其关键是将输入的文字当做一个整体部分进行处理,而不需要经过单个文字的提取,从而减少文字提取的处理时间;同时在特征提取上,采用ROI与投影法[9]降维相结合的方法减少运算量,从而达到快速特征提取的效果。
1.1ROI文字区域粗提取
感兴趣区域(Region of Interest,ROI)[10-11]在进行图像处理时,可在原图像内部以矩形、圆等图形勾勒出所需要处理的区域。设置ROI后,对图像进行处理时大多数情况下只会ROI区域进行处理,从而忽略其他区域,大大减少了图像的运算量,增加了精度,因此被广泛应用于视觉处理中。在文字图像中设置ROI区域,将文字信息包含于ROI 中,并将ROI区域作为子图,在进行阈值处理、文字精提取等处理时可大大减少运算速度,从而为达到快速文字识别奠定了基础。
1.2文字区域精提取
在初步提取的文字ROI区域中,需要进一步对文字区域进行精确提取。提取的步骤如下所述:
1) 对该区域进行二值分割,使用的方法为直方图与大津法相结合的二值化算法[12],该方法的具体实施如下:求出ROI区域的直方图,直方图反映的是图像的灰度分部。再对直方图进行滤波,从而可以得到平滑的直方图,在去除掉部分噪声的同时又保留了直方图的原始信息。
(1)在滤波后的直方图中找出波峰,得到波峰集合
R0={Rl,Rl≥Rl-t&Rl≥Rl-t&h(l)>(1/L)×θ}
(1)
式中:L为灰度的等级;h(l)则是直方图的原始数值;θ是一个比例系数,用来保留在直方图中占一定比例的波峰。
(2)把直方图中相近的波峰进行处理,当距离小于某一数值时,将较小的波峰删除;同时去除波谷不明显的峰值,将其视为同一峰值合并。
(3)将筛选过后的峰值进行区域划分,若剩余的峰值为r0,r1,r2,…,rn,则区域划分为[0,r0],[r0,r1],…,[rn-1,rn]。
(4)在划分后的区域中分别利用大津法求得局部阈值。设在某一灰度区域内[1,m]中,根据大津法原理,若所求的阈值为K,前景C0与背景C1出现的概率和均值为
(2)
(3)
式中:Pi为每个灰度出现的概率。
则C0和C1类间方差为
(4)
式中:uL为整图的总体均值;K*即为最佳阈值。
2) 在进行图像分割后,作为前景的文字信息与背景分离。因为文字信息在排列上具有一定的规律性,最直观的表现为按某同一方向进行排列,且各个字符之间的空隙几乎一致,因此文字信息在投影上有这特殊的现象,即等距相隔出会出现规律性的波谷(峰)。因此在此处可用投影方法对图像文字的区域进行提取,可得到文字区域的最小外接矩形,并提出文字信息。
1.3文字特征提取
由于在脱机式智能显示器自动化测试时所涉及到的文字以4个字为主,本文讨论的多文字以4个字为例。本文的文字特征提取关键在于降维和比例法,降维有助于减少计算量,从而能够更加快速提取文字的特征,在提取文字特征时应当考虑全局与局部相考虑,如果只考虑全局部分,则提取到的文字特征就缺少对局部特征的描述,如果只考虑局部部分,就会造成提取到的文字特征缺乏全局特征,不具有全局代表性,因此只有将全局特征和局部特征相结合才能得到具有代表性且相对稳定的文字特征。
在满足本文应用的条件下,本文的文字特征提取过程如下:将4个文字平均分为16个子区域部分,每个区域部分作为一个子图存在,图1为其示意图,对每个子图分别提取2个特征值,其中一个特征值与全局相关,另一个特征与局部相关,故对“无线网络”而言,有32个特征值,组成代表文字的特征向量。

图1 子区域示意图
1)比例法全局特征提取
本文采取的比例法全局特征为各个子图中笔画占子图总面积的百分比,若假设子图像的行有W个像素,高有H个像素,则比例法全局特征有
(5)其中:c1为比例法全局特征;s为子图总面积,即s=W×H;f(i,j)表示二值图像中像素点的值,有

(6)
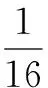
信息感知层对耗材流转进行跟踪定位、自动识别并将实时采集到的信息反馈到网络支撑层,网络支撑层同步记录数据并及时无误地向平台上层传输[7]。
2)比例法局部特征提取
本文的比例法局部特征的提取涉及到图像的投影[10]。对于任意一幅图像来说,其构成都是由像素构成的,若文字图像中的背景为白色的像素点,将文字部分所占的部分为黑色的像素点。则此时有该图像中一行像素点中黑色像素点的总和为该行的水平投影,把图像中每行的水平投影求出并统计即可得到该图像的水平投影;同理,垂直投影就是图像中每一列垂直投影的统计整合,而每列的垂直投影为该列中黑色像素的和。投影可以将二维的图像降维成两个一维的函数,维度的减少也就意味着计算量的减少。
该特征的提取方法如下,若已求出子图中的水平投影与垂直投影,则在水平投影中找到笔画(黑色点)最多的一行,记该行的笔画点数为L;在垂直投影中找到笔画最多的一列,记该列的笔画点数为V,则该局部特征值为
(7)
根据上述方法提取“无线网络”的特征向量为:
(1.264 706,0.686 250,1.041 667,0.784 583,1.075 000,0.757 500,1.041 667,0.670 000,1.025 641,0.670 000,1.041 667,0.695 417,1.242 424,0.752 500,1.041 667,0.664 583,1.041 667,0.825 417,1.041 667,0.758 750,1.351 351,0.736 667,1.041 667,0.677 500,1.136 364,0.731 250,1.041 667,0.711 250,6.250 000,0.738 750,1.041 667,0.630 833)。
2 BP神经网络
人工神经网络即神经网络,是一种模拟生物神经网络的算法[13],利用该算法可从外界中学习获取相关知识,并通过学习到的相关知识处理某些问题,是一门广泛应用的交叉性学科。
2.1人工神经元
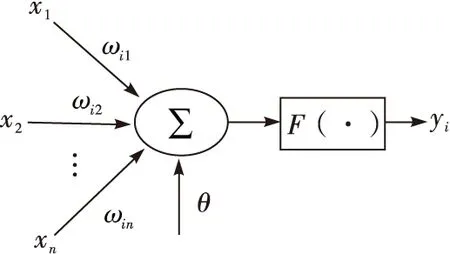
图2 人工神经元原理
图2中,x1~xn是从其他神经元传输过来的信号;ωij表示表示从神经元j到神经元i的连接权值;θ表示一个阈值,或称为偏置,用来改变神经元的活性。则神经元i的输出与输入的关系表示为
(8)
则输出yi表示为
yi=f(neti)
(9)
式中:函数f(·)为激活函数,neti为净激活,若神经元的净激活neti为正,称该神经元处于激活状态或兴奋状态,若净激活neti为负,则称神经元处于抑制状态。
2.2BP神经网络及学习过程
BP神经网络是应用最为广泛的人工神经网络模型,使用的是常见的负梯度下降算法,具有很强的非线性映射能力,通常应用中所利用的三层BP神经网络被证明可以实现任意函数的逼近,具有通用性,所说的三层BP网络即含有输入层、输出层和一个隐含层。BP网络的结构如图3所示。在算法训练过程中,输入信息由输入层正常传递,误差则是反向回馈,从而不断对权值和阈值进行调整,实现对函数的逼近[14]。
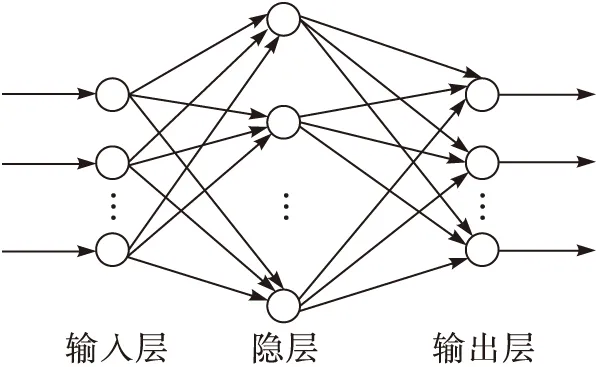
图3 BP神经网络
激活函数作为神经网络的重要环节,对BP网络训练有重要作用, 为了能实现梯度算法,BP网络要求神经元的激活函数必须是可导的,并且导函数必须连续函数。激活函数常采用S型函数和双极S型函数这两个非线性函数。其中S型函数为
(10)
双极S型函数为
(11)
假设BP网络的有P个训练样本,则有P个输入输出对(Ip,Tp),其中p=1,2,…,P,则设输入向量为Ip=(ip1,ip2,…,ipm)T,理论网络算法输出为Op=(op1,op2,…,opn)T,算法实际的输出为Tp=(tp1,tp2,…,tpn)T,通常情况下,理论值与实际输出值有误差,BP算法的学习过程就是重复不断地把Tp与Op进行比较,并根据极小原则修改权值ωij,从而使误差平方和为最小,即
(12)
若记Δωij表示一次学习过程对权值的修改量,则有
ωij+Δωij⟹ωij
(13)
(14)
其中:δpi=tpi-opi;η为学习因子,影响BP网络的学习速率,又称学习速率。
2.3网络参数选择
1)激活函数选择
根据BP网络的特性,激活函数将采用Sigmoid函数,即S形函数,Sigmoid函数可以实现对神经元较好的模拟,同时微分简单,运算方便。
2)输入层神经元的个数
输入神经元个数应与文字的特征向量的维数相对应,故在本文中输入层神经元个数为32个。
3)隐含层神经元个数
隐含层神经元个数的选取[15]需要经过反复的实验才能得出最合适的值。对与给定的样本输入值和理论输出值,不重复调整隐含层神经元个数,训练完成后必须查看网络识别结果,如此反复进行实验,选取网络结果最理想的值。对于本文来说,经过多次反复验证,神经元个数取29时BP网络有良好的效果。
4)输出层神经元个数
网络的输出层可因样本的规模大小选取不同的个数。当样本规模较小时,对于本文选取的Sigmoid函数,可将Sigmoid函数值域[0,1]平均分为若干份,分别对应于各个样本;若样本规模较大时,可适当增加神经元个数以便使用。在本文中,选取的神经元个数为6。
3 实验结果
在实验中,本文采用的硬件平台为CPU2.2 GHz,内存为4 Gbyte,软件算法使用VC编写实现,操作系统为Windows7。
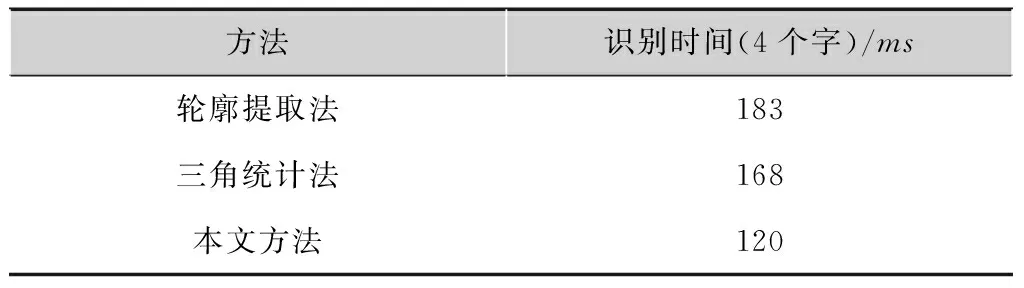
本文一共采用250个四字汉字,各20个样本,总共5 000个样本作为BP网络训练样本,与其他文字识别算法进行对比,如表1所示。
表1实验结果对比
方法识别时间(4个字)/ms轮廓提取法183三角统计法168本文方法120
由表1可得到,本文提出的算法在识别4个字的情况下,识别时间为120ms,比其他算法具有更快的速度,因此此方法可行且有效。
4 结语
本文在针对脱机式智能显示器自动化测试的应用特点,在需识别文字可预知在一定范围内的情况下,研究了一种基于神经网络与比例法的多文字识别。该方法采用将输入文字作为整体进行识别,从而减免了单个文字区域的提取,在文字特征的提取上也采用了运算速度较快的降维方法等,实现了更快的识别速度。因此本方法适用于其他实时性系统,如logo检测等。
[1]姚丽君,李浪.静态图像文字提取技术综述[J]. 电脑知识与技术,2014 (33):7991-7992.
[2]HEL,RUANWT,ZHANGM,etal.Surveyonhyperspectralimageryclassificationwithsupportvectormachine[J].Journalofnewindustrialization,2012,2(1):46-51.
[3]钱娜,侯清涛,李金屏. 基于神经网络和三角形统计特征的文字识别[J]. 济南大学学报(自然科学版),2008 (2):128-131.
[4]梁华刚,程加乐,茹锋. 基于特征空间法的旋转多字体文字识别[J]. 微电子学与计算机,2015 (4):82-85.
[5]陈玮,曹志广,李剑平. 改进的模板匹配方法在车牌识别中的应用[J].计算机工程与设计,2013,34(5):1808-1811.
[6]苏畅,胡晓冬,王斌辅,等.基于笔画相关加权的视频图像文字识别[J].计算机应用,2012 (8):2305-2308.
[7]ERLERM,KENDERJR.Semantickeywordextractionviaadaptivetextbinarizationofunstructuredunsourcedvideo[C]//Proc.the16thIEEEInternationalConferenceonImageProcessing.Piscataway:IEEE,2009:26l-264.
[8]焦微微,巴力登. 基于改进BP神经网络的脱机手写文字识别[J]. 电视技术,2014,38 (13):200-202.
[9]张娜,陈露军,王绪本. 基于水平垂直投影的考古文字修复识别方法[J]. 科技通报,2014 (6):185-187.
[10]冯竞舸. 静止图像的ROI区域自动提取与编码[D]. 南京:南京邮电大学,2013.
[11]白玛玉珍. 藏文文字特征提取方法的研究[J]. 电脑知识与技术,2013 (10):6362-6364.
[12]吴丹,蔡晓东,谢月飞,等. 基于直方图分析和OTSU算法的文字图像二值化[J]. 计算机与现代化,2013 (7):117-119.
[13]KALAICHELVIV.Applicationofneuralnetworksincharacterrecognition[J].Internationaljournalofcomputerapplications,2012,12 (52):183-192.
[14]张宇博,舒红平. 改进的BP神经网络算法及其应用[J]. 网络安全技术与应用,2015 (3):78-80.
[15]沈花玉,王兆霞,高成耀,等.BP神经网络隐含层单元数的确定[J].天津理工大学学报,2008 (5):13-15.
林毅斌(1991— ),硕士生,主研信息显示系统;
姚剑敏(1978— ),硕士生导师,副研究员,为本文通信作者,主要研究方向为视频图像处理、模式识别;
郭太良(1963— ),博士生导师,研究员,主要研究方向为场致发射阴极材料及器件研究。
责任编辑:闫雯雯
Multi-character recognition based on the neural network and projective method
LIN Yibin, YAO Jianmin,GUO Tailiang
(CollegeofPhysicsandInformationEngineering,FuzhouUniversity,Fuzhou350002,China)
It is time-consuming to use the traditional method in recognizing characters by collecting characters by every word region. However, it is worth of digging deeper into the problem of recognition speed, regarding to the efficiency in the real-time system. A multi-characters recognition method is presented. It mainly focuses on recognizing characters as a whole batch instead of spending much time in picking up every word region. In addition, it can make further improvement in reducing the computing time of characteristic parameter by using ROI and projective method. On that basis, BP neural network is applied in training samples and recognizing characters. The experimental result shows that it is an efficient method of characters recognition, which takes 120 ms in recognizing four characters.
multi-character recognition; projective method; BP neural network
TN911.73;TP391.4
A
10.16280/j.videoe.2016.09.023
国家“863”重大专项(2013AA030601);福建省科技重大专项(2014HZ0003-1);福建省资助省属高校专项课题(JK2014003)
2015-09-29
文献引用格式:林毅斌,姚剑敏,郭太良. 基于神经网络与比例法的多文字识别[J].电视技术,2016,40(9):112-116.
LIN Y B, YAO J M,GUO T L. Multi-character recognition based on the neural network and projective method[J]. Video engineering,2016,40(9):112-116
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
数学物理学报(2021年1期)2021-03-29
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
电子制作(2019年15期)2019-08-27
学生天地·小学低年级版(2019年5期)2019-06-05
学生天地(2019年15期)2019-05-05
摄影之友(影像视觉)(2018年12期)2019-01-28
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
初中生世界·八年级(2017年3期)2017-03-24
