
超分辨率重建算法综述
2016-10-17 09:12崔子冠朱秀昌
电视技术 2016年9期
李 欣,崔子冠,朱秀昌
(南京邮电大学 图像处理与图像通信实验室,江苏 南京 210003)
超分辨率重建算法综述
李欣,崔子冠,朱秀昌
(南京邮电大学 图像处理与图像通信实验室,江苏 南京 210003)
随着高分辨率移动设备和超高清电视的发展,对已有的低分辨率视频进行超分辨率上采样成为最近的一个研究热点。对已有的超分辨率重建算法根据输入输出方式的不同,分为多图像超分辨率重建、单图像超分辨率重建、视频超分辨率重建三大类,综述了其中每类算法的发展情况及常用算法,并对不同算法的特点分析比较。随后讨论了多图像超分辨率重建和单图像超分辨率重建方法对视频超分辨率重建方法的影响,最后展望了超分辨率重建算法的进一步发展。
超分辨率;超高清电视;配准;稀疏表示
人类获取信息的主要途径是视觉,大部分基于视觉的应用效果都依赖于图像的质量。高分辨率(High Resolution,HR)图像有助于在一个监控录像中更好地识别犯罪嫌疑人的脸,在医学X射线照片中更准确定位肿瘤,在高清晰度电视中产生更优质的视频,在工业检查时产生更清晰的图像,获得一个更好的遥感图像等。超分辨率(Super Resolution,SR)技术是一种图像处理程序。将退化的图像或图像序列作为输入,生成更高质量的图像或图像序列。退化图像的定义是主观的,取决于应用程序。低分辨率(Low Resolution,LR)退化图像可能是监控视频,或者在很低辐射量下获得的医学X射线照片,或者压缩比很高的压缩图像。图像质量的概念也可以通过不同的方式定义,例如,在摄影照片中,图像质量取决于人类观察者的鉴赏感知力,而在目标检测任务中图像质量可能是指良好的边缘定位。
超分辨率技术已经被应用于各种领域,如视频监控、医学成像、高清晰度电视、遥感、手机与数码相机等。在视频监控系统中,摄像头监控的兴趣点的位置用于检测异常,视频通常保存到视频片段中,系统可以触发各种警报,如发送电子邮件、引发警报,甚至让用户通过网络来观看视频。由于数据量的庞大和带宽的限制,视频帧通常是在非常低的比特率下捕获的。相机通常设置为广角模式以期能捕捉尽可能多的场景,故而感兴趣的对象分辨率往往都比较低。为了安全目的如个人身份识别和身份验证,不论是时间上(速度)还是空间上(图像分辨率)都需要超分辨率重建技术。
1 超分辨率重建的分类
单图像输入和多图像输入是超分辨率重建面临的两种不同情况。多图像输入意味着输入的是一系列图像(或视频的一部分),这些图像间有着不同的亚像素平移,每幅图像都包含着高度相关信息的信息(即相对场景运动)可以用于超分辨率重建一幅图像[1]。实际中,很多情况下没有足够的相关输入图像来源,这就需要开发基于单图像输入的算法,即输入源仅是一幅图像。根据输入图像的多少可以将超分辨率重建问题分为三类:多图像、单图像和视频。它们具有相同的核心任务即产生更多的图像像素,但它们的定义各有不同:多图像超分辨率(Multiple-Image Super-Resolution)重建指的是根据同一场景得到的多幅低分辨率图像重建出一幅高分辨率图像;而视频超分辨率(Video Super-Resolution)除了在空域寻找重建方法外,还可以在时域通过增加图像帧的方法提高整个视频的质量;单图像超分辨率(Single-Image Super-Resolution,SISR)重建可以看作为前两种情况中的基本情况,如单图像超分辨率可以直接用于视频超分辨率的每一帧中来增加空间细节,此外,单图像超分辨率也可以用于多种其他问题,如视频监控中的检测、分类和识别问题,超分辨率重建可以帮助其获得更好的性能,医学影像系统中超分辨率重建可以提高医学检查的准确度等。以下章节将分别对这三类超分辨率重建算法的发展情况分类讨论。
超分辨率重建从重建的角度通常分为频域的方法和空域的方法[2]。第一种超分辨率重建的方法就是频域方法[3],其主要是消除LR图像中的混叠来重建HR图像,这类技术主要是基于连续和离散傅里叶变换间的平移和混叠特性。这种方法的主要优点是理论简单及并行实现的能力,但观测模型仅局限于全局平移运动和线性空间不变(Linear Space Invariant,LSI)模糊,由于在频域缺少数据相关性,目前该类方法已经不是研究热点。空域的方法利用观测模型中的全局和局部运动、空间可变点扩散函数、光学模糊、运动模糊等内容,空域的方法可以将空域的先验约束用于正则化病态的超分辨率重建问题。本论文综述的超分辨率重建方法主要是基于空域的方法。
2 多图像超分辨率重建
多图像超分辨率重建方法旨在整合多个LR图像到一个HR图像,其图像观测模型为
Yi=DBiWiX+ni,i=1,2,…,I
(1)
式中:X为待重建的高分辨率图像;Yi为第i个观察到的低分辨率图像;D为下采样算子;Bi为模糊算子;Wi为变形算子;ni为处理过程中的加性噪声。
这类方法用了一个假设,即多个类似的图像可以从一个成像设备中反复得到。该类方法一般包含3个步骤:图像配准、插值和图像恢复。考虑输入的多个LR图像间存在运动位移,对这种位移关系进行精确估计,将多个LR图像配准到一个公共坐标下,通过非均匀插值(Non-uniformInterpolation)得到估计的高分辨率图像,再根据式(1)的观测模型对图像超分辨率问题转化为最优化问题求解。多图像与单图像超分辨率重建方法最主要的区别就在于运动估计和图像配准过程,后续的最优化方法也常常用在单图像超分辨率重建中。本节主要讨论图像配准及非均匀插值。
为了保证输入的多个LR图像中包含增加空间分辨率的足够信息,通常要求各个LR图像间存在亚像素平移。如图1所示,LR图像的像素首先根据其运动信息投影到HR图像平面,然后通过插值对齐到统一的HR图像网格上。这种方法的优点是其相对较低的计算量,可实时实现,然而,在这个方法受限于退化模型,即模糊和噪声特征被假定为所有LR图像是相同的。Zhou等[4]提出一种coarse-to-fine的框架通过估计变形参数用独立视角运动来准确配准图像的局部感兴趣区域(RegionsofInterest,ROI)。Milchevski等[5]给出基于机器学习的SR算法,对配准误差具有鲁棒性。Vrigkas等[6]提出了一种最大后验概率(MaximumaPosteriori,MAP)模型下的图像超分辨率方法,其中图像配准的部分由两个步骤完成:首先,低分辨率图像通过对应SIFT特征来配准;其次,在迭代过程中通过最大化互信息准则估计配准参数来精确地估计高分辨率图像。
3 单图像超分辨率重建
单图像超分辨率重建(SISR)是架起输入低分辨率图像和输出高分辨率图像之间桥梁的重要技术,近年来获得了更多的关注,由于仅仅只有一幅输入图像,式(1)的图像观测模型变为
Y=DBX+n
(2)
式中:X为待重建的高分辨率图像;Y为输入低分辨率图像;D为下采样算子;B为模糊算子;n为加性噪声。
因此,单图像超分辨率重建是欠定问题而不是多图像超分辨率重建的超定问题。因为问题是不适定的,可用的图像数量有限,在重建过程中往往需要利用图像的先验信息。单图像超分辨率重建就是要利用一幅图像中包含的丰富信息以及从样本图像中得到的视觉先验,因此,单图像超分辨率重建的挑战主要包括:识别重要的视觉线索,填充细节,并尽可能忠实和美观地呈现。目前单图像的超分辨率重建一般可分为两类:基于重建的方法(Reconstruction-Based)和基于样本学习的方法(ExampleLearning-Based)。
3.1基于重建的方法
基于重建的方法旨在重建降质过程中丢失的高频信号。Irani和Peleg[7]观察到插值得到的HR图像通过式(2)的下采样过程生成的LR图像与输入的LR图像是不同的。为了保证式(2)成立,用2范数约束表示超分辨率重建问题的解为
(3)
用反向投影在LR上的差值来完善HR图像的方法求解式(3),由于这个问题是病态的,有无穷多个解,因而采用迭代的方法,称为迭代反向投影(Iterative Back-Projection, IBP)算法。因此,IBP重建出的HR图像,若再次通过下采样得到的LR图像会随着迭代次数的增加与输入LR图像更相似。IBP重建增强了HR图像中的高频分量,如边缘两边的对比度,但该方法只是简单地反向投影任何差值,HR图像中的梯度可能会被过度放大而导致振铃效应。由于该方法简单有效,IBP算法在很多图像超分辨率重建算法中作为一个后处理过程。
IBP算法求出的解仍不唯一,为了找到式(3)更优的解,通常需要考虑图像的先验信息来正则化SR问题,式(3)则可改写为
(4)
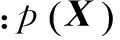
Dai等[8]利用图像边缘处两边的对比度大而边缘的一边具有连续性的先验知识,设计了中心像素和相邻像素的差值加权和的正则化项。即求解式(4)的最优化问题得到高分辨率图像能产生尖锐和光滑的边缘,但该方法对于纹理区域总是生成模糊的结果,由于纹理处的图像特征并不满足先验假设。另外,生成的高分辨率图像质量与其中的参数设置有关,但又很难找到一个可用于大多数图像的共同设置,必须手动调整,故实用性不强。
Zhang等[9]提出一种两步超分辨率方法:首先,双立方插值得到初始化高分辨率图像,用非局部核回归来减少图像中的锯状效应,重建出的高分辨率图像中边缘是直且光滑的,但不尖锐;第二步再用反卷积,应用全变差(Total Variation ,TV)作为正则化先验模型来增强边缘的对比度。这种方法能够重建尖锐和清晰的边缘,但它对于细线和纹理仍然无法得到好的效果,这是因为细线在双立方插值处理后变宽,但余下的流程却无法再收窄,纹理经非局部核回归处理后变得平滑,虽然在第二步中对比度有所增强,但结果与原始真实图像还是会有很大不同。
Singh等[10]利用图像边缘处像素值通常满足坡道(ramp)先验,即是由一组强度不断增加或减少的相邻像素组成,该算法在边缘方向上外推得到高分辨率图像,较前两种方法相比的优势在于坡道除了在边缘还可以在拐角(corner)和交叉(fork)处找到。但坡道需要多个像素才能确定,对于窄边缘或复杂的纹理坡道仍然不能确定。
基于重建的超分辨率方法只是用了一些先验知识来正则化重建过程,而没有使用样本图像通过训练得到训练先验。这类方法的优点是简单、计算量低,但无法处理自然图像中的复杂图像结构。
3.2基于样本学习的方法
与基于重建的超分辨率重建方法相比,由于加入了外部样本图像,基于样本学习的方法有两个优点:首先,通过对样本图像中多种图像块训练学习可以得到各种复杂图像结构而不仅仅是边缘的先验知识;其次,利用包含在样本中的高频分量在重建过程中可以生成高频信息丰富的高分辨率图像。因而,基于样本学习的方法目前成为单图像超分辨率重建的主流研究方向,前两种算法一般作为基于样本学习方法的辅助处理过程。
自然图像内容千变万化,基于样本学习的方法都是针对图像块学习先验知识,因此,重建约束变为
(5)
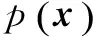
根据如何使用样本图像块,基于样本学习的方法可分为基于样本(Example-Based)的方法和字典学习(Dictionary Learning)方法,前者直接从样本图像块中寻找类似的实例(Instance),而后者则是对样本图像中的大量实例通过学习的方法得到图像的先验信息。
3.2.1基于样本的方法
由于样本图像中含有丰富的高频信息,这些信息可用于重建超分辨率图像中的高频分量。基于样本的方法没有训练阶段,在重建过程中对样本集搜索足够的实例来完成重建,因此需要较高的计算量。
1)基于样本
Freedman[11]观察发现,两个图像块如果在LR中相似,则它们对应的HR块更可能是相似的,另外,两个相邻的HR块中的重叠像素的值应该是相似的,基于这两个观察,选用马尔科夫随机场(Markov Random Field,MRF)来确定样本图像集中的最优候选。低分辨率图像的降质过程是一个多对一的映射过程,对于输入的LR图像块,在样本集中找到多个与其最相近的样本LR块,将与之对应的HR样本块作为候选,应用马尔科夫网络在选择最佳候选的同时最小化输入LR块与样本LR块的差值,并重叠HR像素的差值。与插值得到的高分辨率图像相比,Freedman的结果含有丰富的高频细节,但马尔可夫网络不能防止异常的候选存在,而人眼的视觉特性对异常高频信号会很敏感,因此重建的图像主观感觉常常是含有噪声的。Wang等[12]通过用条件随机场(Conditional Random Field,CRF)取代MRF来改进Freedman的方法,MRF只计算了局部块间的关系,CRF则计算任何块对,缺点是模型会更加复杂、计算量更高。
2)邻域嵌入
Chang等[13]提出一种邻域嵌入(Neighbor Embedding,NE)算法,通过加权平均多个高分辨率候选块而不是只选择其中之一对Freedman的方法作改进。用局部线性嵌入计算一组最近邻的样本块的权重来表示输入LR块,再用这些权值来平均相应的HR样本块生成输出的HR块。这种方法生成的图像不会有明显的噪声存在,因为加权平均的方法就能抑制异常样本的效果。针对Chang的方法中权重无限制导致的重建失真,Bevilacqua[14]等基于非负邻域嵌入和最小二乘(Least Square,LS)近似LR块,证明了非负权重选取的有效性。Yang等[15]提出双几何邻域嵌入方法,利用多视角特征和图像块局部空间邻域来找到特征-空间流型嵌入。
3)基于自相似块
Glasner等[16]观察到在超分辨率重建图像中利用外部样本图像不容易出现重建锐利的边缘,因为相似的图像块在不相关的图片中并不多,相比之下,由于边缘方向和对比度在下采样过程中保持不变,类似的边缘块在输入图像的图像金字塔中很容易找到。因而提出利用多尺度LR/HR块对来重建图像,重建的图像边缘锐利清晰,但由于多尺度图像遍历搜索,计算时间较长。给定LR块在图像金字塔的边缘上找到最相似的块,由于边缘方向和对比度不变,因此在大多数情况下最相似的块都是位于同一位置上。Freedman等[17]利用这个性质来加速Glasner的方法,用局部搜索代替全局块搜索,并在GPU上实现搜索算法。为了找到有效的多尺度自相似块,这两种方法都使用一个小尺度因子生成图像金字塔,并用小尺度因子迭代地放大输入图像直到生成图像的大小达到所需高分辨率图像的大小,因此LR输入图像中的小梯度块可能被放大为输出HR图像中的短边缘,如果输入图像包含不规则梯度纹理,将可能产生一些与高分辨率图像内容不相关的局部块。在Glasner方法基础上,Cui等[18]利用深度学习的方法,提出一种深度网络级联来逐层上采样LR图像,由于在每一层级联的自相似搜索过程的优化和自动编码器是独立的,因此该方法无法得到一个端到端的解决。
4)纹理重建
Tai[19]提出一种用统计先验来重建边缘而从样本图像中合成纹理的方法,首先需要高度相似的样本图像,并要创建一个模板来分段样本图像中的有效区域。虽然这种方法可以产生高质量的纹理,但高度相似的样本图像却并不是总能找到的。HaCohen等[20]通过自动匹配测试和样本段来弱化Tai的假设,并用多个段代替单一段,首先准备一个涵盖多种纹理类的小图像集,每个类中包含一些样本纹理图像,重建时与样本图像完全一致的纹理就不需要模板,其次通过训练的每个纹理类的典型来对测试图像分段,并从样本图像合成重建图像中的纹理。该方法也能产生高质量的纹理,但仍然需要人工准备有效的样本纹理图像,因而适用面还是不广。Sun等[21]提出一种全自动重建图像中纹理的方法,先收集包含各种纹理类的大量自然图像,通过Berkeley分段机制自动生成分段,再提取多尺度多方向梯度分布作为分段特征,并广泛应用纹理描述符。对于给定的输入LR图像,将其分段与具有最近特征的LR样本分段匹配,并用对应的HR样本块分段作为正则化项来产生HR图像中丰富的高频细节。如果分段和匹配步骤都工作正常,该方法能产生丰富的高质量纹理,然而,自然图像的纹理是难以分段和匹配的,如果出现无效分割或匹配的,生成的结果将会包含不一致或不正确的纹理。
3.2.2字典学习的方法
由图像降质模型可以看到,这是一个多对一的映射过程,也就是说很多不同的HR图像会产生一幅相同的LR图像,在基于样本学习的方法中,由于图像都是被划为许多小的图像块,那这种映射关系就完全可能出现在样本图像块集中,为了更有效地整合样本图像块集中包含的信息,字典学习的方法通过对大量的样本块训练来学习最可能的HR特征映射到LR图像块上。一旦学到先验知识,则不再需要样本图像,这样在重建阶段也就不需要大的内存空间及搜索时间,与基于样本的方法相比,字典学习的方法计算效率更高。
1)边缘优先
相比较学习全局特性的先验,Fattal[22]和Sun等[23]分别提出两个类似的方法学习局部边缘统计先验,两种方法都是在边缘处重建梯度,不同主要在于特征提取部分和从LR到HR特性训练映射函数部分。Fattal提取边缘锐度作为3个力矩,Sun则将边缘轮廓建模为广义高斯分布模型;Fattal学习一个查找表来预测HR梯度,Sun为广义高斯分布的锐度和形状学习分段映射函数。由于使用的图像结构和方法基本相同,因此两种方法产生的图像是相似的,边缘清晰但纹理是模糊的。这两种方法所使用的先验对纹理都不起作用,因为纹理的高频细节不能由边缘轮廓建模。
2)基于稀疏表示
Yang等[24]为了覆盖各种图像结构提出从图像块而不是边缘学习先验。首先利用样本图像产生LR/HR训练图像对,提取一阶、二阶梯度作为LR块特征,因为大梯度代表重要的视觉信息,提取训练HR图像和LR图像双立方插值图像的差值作为HR块特征。从大量的LR/HR特性块对训练集中,优化出一对共享相同系数并能产生最小重建误差的稀疏字典,因此训练字典对的过程实际上就是找到从LR特征到HR特征的复杂的非线性映射函数。重建时,为每LR块用LR字典计算稀疏系数,再通过相同的系数在HR字典上生成HR特征,将估计的HR特征叠加到输入图像的双立方插值图像上就能得到最终的输出图像。因为字典训练用于代表任何块,故边缘和纹理的高频细节都可以重建。Zeyde等[25]改进了Yang的方法,引入投影矩阵训练,通过主成分分析(Principle Component Analysis,PCA)选定特征,LR字典可以更准确地表示图像块。另外,经过PCA处理后特征维数降低,稀疏系数的计算量也随之降低。Wang等[26]弱化了Yang的方法中对LR和HR字典稀疏系数相同的假设条件,引入稀疏域变换增加LR和HR字典系数之间的灵活性。与边缘优先的方法相比,直接对样本块学习先验对于重建HR图像更通用且更有效。
3)基于回归模型
基于字典学习的方法虽然在重建图像的质量上有着优势,但计算量仍然较高。为了解决这个问题,Kim和Kwon[27]通过训练回归函数来预测HR特征,Timofte等[28]和Yang[29]提出使用多个线性回归函数代替一对字典对表示的单一映射函数,这3种方法的区别在于回归函数的数量和类型。Kim和Kwon只训练一个回归函数,主要关注强边缘周围块的重建,通过复杂的核脊回归函数来生成准确的结果,通过使用一些回归参考来减少计算复杂度,为了抑制不准确回归引起的噪声,他们用自然图像的先验来改善边缘的对比度和连续性。相比之下,Timofte等和Yang的方法则是采取了各个击破的策略,在划分步骤中,把LR特征空间分割成许多子空间,为单独的子空间收集实例,对每个子空间训练特定的线性回归函数,给定测试图像块时,找到覆盖其特征的子空间,用子空间训练的回归函数估计HR的特征;在综合步骤中,只需平均重叠像素值生成输出图像而无需任何后处理。由于每个子空间小且紧,通过线性回归函数的准确预测类似于非线性回归函数如支持向量回归,但计算量会大大降低。Timofte[30]又合并了Yang的使用原始块特征的方式进一步提出一种改进的方法,增加了回归函数的有效性和重建图像的质量。Dai等[31]又通过优化块与回归函数间的关联改进了Timofte[30]的方法,提出直接训练LR/HR块对来优化整个回归函数集,通过反复训练回归函数并重组训练样本进一步减少重建误差;训练回归函数后,记录每个块对于每个回归函数的重建误差,重建是根据给定的LR块,首先检索类似的训练块,根据重建误差记录,他们确定最可能的回归函数以产生最小的重建误差。Zhang[32]等考虑到这些算法中锚点数量过高的问题,提出一种混合专家(Mixture of Experts,MoE)模型方法,可以通过期望最大(Expectation-Maximization,EM)算法求解空间部分和局部回归的联合学习。
4)基于深度学习
Dong等[33]提出在卷积神经网络(Convolutional Neural Networks,CNN)的框架下训练LR和HR映射函数,同时优化映射函数和卷积核来减少重建错差,该方法在训练阶段计算量非常大,但在重建阶段计算量很小,由于惩罚项是为了优化减小亮度差值而不是梯度,其生成的图像在尖锐的边缘可能包含鬼影。相较于训练阶段有高计算量的Dong方法,Schulter[34]提出利用随机簇来减少训练成本。随机选择的训练块用于产生多个二叉树,基于块相似性递归地将训练样本集分割成两个子集,包含在每一个叶子节点的LR/HR块对是用来训练线性回归函数,且Schulter方法中由不同的树分割的子空间是重叠的,因此密集的和重叠的回归函数可以产生高质量的图像而且训练阶段的计算量低。Huang等[35]也是运用判决树和分层判决树进一步加速了Schulter的方法。
4 视频超分辨率重建
视频超分辨率重建不是多图像超分辨率重建的直接扩展,多图像超分辨率假设输入图像为同一场景,是统一的输入,而视频可以使用异构输入,如视频中通常包括I,B,P帧,也就是输入的图像可能是高分辨率图像,也可能是降质的图像,因而LR视频可以有HR静态图像用于增加图像大小[36-37]或减少量化噪声[38]。另外,视频超分辨率重建处理的移动对象,因此除了空域的重建方法,还可以在时域增加图像帧的方法实现超分辨率重建,多图像超分辨率重建则仅是空域的重建。空域的视频超分辨率重建算法如果忽略帧间相关性[39],则可看成是单图像超分辨率重建的直接扩展,但这类方法的重建质量一般会比利用时间相关性如计算目标的运动信息的算法效果差[40-41]。根据目前视频超分辨率的应用,可大致分为两类:
取满足上面等式的a0、b0作为回归函数的参数估计,以作为回归函数的估计,称为Y关于x的一元经验线性回归方程,简称为一元线性回归方程,其图象称为回归直线.
1)基于传统视频超分辨率
近年来,电视技术以指数级的速度在快速发展,同时也面临着显示上的前所未有的挑战,高清晰度电视(High Definition Television,HDTV)和超高清电视[42](Ultra-High-Definition Television,UHDTV)都对视频分辨率提出了越来越高的要求,传统视频处理领域,SR通常是在一个混合分辨率视频框架下,即视频中包含LR或HR帧,如视频编码的相关应用。由于在视频场景中的LR和HR帧间的相似是固有的特性,基于样本的SR展示了良好的效果。在这种背景下,Song等[43]提出了使用低分辨率序列中已有的稀疏的高分辨率关键帧做重叠块运动估计(Overlapped-Block Motion Compensation,OBMC)和字典训练来完成重建。同时,Hung等[44]提出了通过使用码本(codebook)来完成SR,同样也是源于关键帧和OBMC,得到比Song更好的效果。Jeong等[45]提出一种多帧基于样本块选择算法,结合基于低分辨率图像退化模型的自相似性,提出的SR算法可显著提高LR图像的视觉质量,保留高频图像细节。Ruangsang[46]通过奇异值分解结合K均值聚类分析算法(分析K-SVD)和自适应追踪弹性网(Elastic-Net)算法,分析K-SVD算法提高了学习过程,得到更好的字典生成系数,低分辨率和高分辨率块之间的最优路径的数据集;自适应弹性网算法用于解决稀疏表示问题估计高分辨率块。
2)基于3D视频的深度视频超分辨率
三维电视(3DTV)和自由视点电视(Free-viewpoint,FTV)已经吸引了很多的关注。3DTV从不同的观点用多个视角为观众提供真实场景的感知,FTV在一定范围内可以由观众自由选择场景中的任何视角。通过3D视频提供的现实场景的互动和生动体验依赖于大量的纹理和深度图数据,因此,其在采集、存储和传输过程提出新的要求,尤其是对有限的带宽应用。对于这样问题的一个有效的解决方案是使用混合分辨率(Mixed Resolution,MR)视频,其中至少一个视图捕捉的低分辨率,而其他视图则捕获全分辨率(Full Resolution,FR)。MR视频与FR视频相比显著减少了捕获的数量、数据传输、存储和处理时间这些实时应用程序的瓶颈,然而,为了满足高清晰度的要求,减少视觉不适感,使视频格式更适合于FTV,在解码器端LR视频通常需要使用超分辨率技术恢复到FR尺度。
Garcia等[47]提出用邻近FR的视点的高频信息和相应的深度信息恢复LR视点中的高频信息。Zhang等[48]融合了从FR视图到LR视图的映射,利用非局部块加权和完成3D视频SR。不同于以前只关注利用空间信息的方法,Jain等[49]提出一种3D MRF模型,在空域和时域从HR图像库中优化块来重建LR帧。Jin等[50]提出一个新的虚拟视图辅助SR的增强算法,开发虚拟视图信息和内插帧有两个好处:首先,FR视图中包含的高频信息可以正确用于重建LR视图;其次,视图间冗余将用于在超分辨率视图中提高原始LR像素,并补偿视图间亮度都差异。Ismaeil等[51]提出一种动态多帧深度SR,但这个算法受限于横向运动,在径向变形情况下会失败,另外在内存中缓存一定数量帧来累积运动估计过程也是不太现实的。之后,又提出一种用多个卡尔曼滤波器递归深度SR算法[52],该算法把视频看作一组一维信号,当达到一个近似的流量范围,考虑径向变形估计,由于充分保护了深度表面的平滑特性,并去除噪声,使用一个多层次的迭代双边全变差正则化,取得了很好的深度预测。
5 小结
目前,超分辨率重建技术广泛用于多个场合,稀疏表示思想的提出对单图像超分辨率重建算法的飞速发展起到了重要作用,随着单图像超分辨率重建技术的快速进步,以及高分辨率移动设备和超高清电视的发展,视频超分辨率重建技术也逐步成为研究的热点。结合目前的发展情况,未来的超分辨率还可以在以下方面进一步提高:
2)基于字典学习的快速超分辨率重建也是近期的研究重点,该类算法的最主要缺点是运行速度慢,很难直接使用,近年来随着计算机性能的提升,有一些算法中使用GPUs实现,可以在很短的时间完成超分辨率重建,但快速算法通常需要弱化重建约束中的部分条件,因此重建质量又可能下降。技术研究的目的最终是实用,快速算法必然是后续研究的重点。
3)视频帧间运动信息的利用,是视频超分辨率重建与单图像超分辨率重建间最大的差别,在视频超分辨率重建的后续发展中,利用亚像素运动估计可以明显提高运动估计的准确性,但是随之而来增加的运算量也是需要解决的问题。
[1]PARK S C,PARK M K,KANG M G. Super-resolution image reconstruction:a technical overview[J]. IEEE signal processing magazine,special issue of super-resolution image reconstruction,2003,20(3):21-36.
[2]苏衡,周杰,张志浩.超分辨率图像重建方法综述[J]. 自动化学报,2013,39(8):1202-1213.
[3]TSAI R Y,HUANG T S,TSAI R Y,et al. Multiframe image restoration and registration[C]// Advances in Computer Vision and Image Processing.[S.l.]:IEEE,1984:317-339.
[4]ZHOU F,YANG W,LIAO Q. A coarse-to-fine subpixel registration method to recover local perspective deformation in the application of image super-resolution[J]. IEEE transactions on image processing, 2012, 21(1):53-66.
[5]MILCHEVSKI A, IVANOVSKI Z, MUSTAFA B. Machine learning based supper-resolution algorithm robust to registration errors[C]// Digital Signal Processing Workshop and IEEE Signal Processing Education Workshop (DSP/SPE).[S.l.]:IEEE,2011:326-331.
[6]VRIGKAS M, NIKOU C, KONDI L P. On the improvement of image registration for high accuracy super-resolution[C]//IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP) .[S.l.]:IEEE,2011:981-984.
[7]IRANI M,PELEG S. Improving resolution by image registration[J]. CVGIP:graphical models & image processing, 1991, 53(3):231-239.
[8]DAI S,HAN M,XU W,et al. Soft edge smoothness prior for alpha channel super resolution[C]//IEEE Conference on Computer Vision & Pattern Recognition.[S.l.]:IEEE,2007:1-8.
[9]ZHANG H,YANG J,ZHANG Y,et al. Non-local kernel regression for image and video restoration[J]. Lecture notes in computer science,2010(3):566-579.
[10]SINGHA,AHUJAN.Singleimagesuper-resolutionusingadaptivedomaintransformation[C]//IEEEInternationalConferenceonImageProcessing.[S.l.]:IEEE,2013:356-364.
[11]FREEMANWT,JONESTR,PASZTOREC.Example-basedsuper-resolution[J].IEEEcomputergraphics&applications,2002,22(2):56-65.
[12]WANGQ,TANGX,SHUMH.Patchbasedblindimagesuperresolution[C]//IEEEInternationalConferenceonComputerVision.[S.l.]:IEEE,2005:709-716.
[13]CHANGH,YEUNGDY,XIONGY.Super-resolutionthroughneighborembedding[C]//IEEEConferenceonComputerVisionandPatternRecognition.[S.l.]:IEEE,2004:275-282.
[14]BEVILACQUAM,ROUMYA,GUILLEMOTC,etal.Low-complexitysingle-imagesuper-resolutionbasedonnonnegativeneighborembedding[J].BMVC,2012(2):13-18.
[15]YANGS,WANGZ,ZONGL,etal.Dual-geometricneighborembeddingforimagesuperresolutionwithsparsetensor[J].IEEEtransactionsonimageprocessing,2014, 23(7):2793-2803.
[16]GLASNERD,BAGONS,IRANIM.Super-resolutionfromasingleimage[C]//IEEEInternationalConferenceonComputerVision.[S.l.]:IEEE,2009:349-356.
[17]FREEDMANG,FATTALR.Imageandvideoupscalingfromlocalself-examples[J].ACMtransactionsongraphics,2011,30(2):474-484.
[18]CUIZ,CHANGH,SHANS,etal.Deepnetworkcascadeforimagesuper-resolution[C]//ComputerVision-ECCV2014.[S.l.]:IEEE,2014:49-64.
[19]TAIYW,LIUS,BROWNMS,etal.Superresolutionusingedgepriorandsingleimagedetailsynthesis[C]//IEEEConferenceonComputerVisionandPatternRecognition.[S.l.]:IEEE,2010:2400-2407.
[20]HACOHENY,FATTALR,LISCHINSKID.Imageupsamplingviatexturehallucination[C]//IEEEInternationalConferenceonComputationalPhotography(ICCP).[S.l.]:IEEE,2010:1-8.
[21]SUNJ,ZHUJ,TAPPENMF.Context-constrainedhallucinationforimagesuper-resolution[C]//IEEEConferenceonComputerVisionandPatternRecognition(CVPR).[S.l.]:IEEE,2010:231-238.
[22]FATTALR.Imageupsamplingviaimposededgestatistics[J].ACMtransactionsongraphics,2007,26(3):95.
[23]SUNJ,SUNJ,XUZ,etal.Gradientprofileprioranditsapplicationsinimagesuper-resolutionandenhancement[J].IEEEtransactionsonimageprocessing,2010,20(6):1529-1542.
[24]YANGJC,WRIGHTJ,HUANGT,etal.Imagesuper-resolutionviasparserepresentation[J].IEEEtransactionsonimageprocessing,2010,19(11):2861-2873.
[25]ZEYDER,ELADM,PROTTERM.Onsingleimagescale-upusingsparse-representations[M].Berlin:Springer,2010.
[26]WANGS,ZHANGL,LIANGY,etal.Semi-coupleddictionarylearningwithapplicationstoimagesuper-resolutionandphoto-sketchsynthesis[C]//IEEEConferenceonComputerVisionandPatternRecognition(CVPR) .[S.l.]:IEEE,2012:2216-2223.
[27]WANGK,YOUNGHEEK.Single-imagesuper-resolutionusingsparseregressionandnaturalimageprior[J].IEEEtransactionsonpatternanalysis&machineintelligence, 2010, 32(6):1127-1133.
[28]TIMOFTER,DEV,GOOLLV.Anchoredneighborhoodregressionforfastexample-basedsuper-resolution[C]//IEEEInternationalConferenceonComputerVision(ICCV).[S.l.]:IEEE,2013:1920-1927.
[29]YANGCY,YANGMH.FastDirectsuper-resolutionbysimplefunctions[C]//IEEEInternationalConferenceonComputerVision(ICCV) .[S.l.]:IEEE,2013:561-568.
[30]TIMOFTER,SMETVD,GOOLLV.A+:adjustedanchoredneighborhoodregressionforfastsuper-resolution[M]. [S.l.]:SpringerInternationalPublishing,2014.
[31]DAID,TIMOFTER,GOOLLV.Jointlyoptimizedregressorsforimagesuper-resolution[C]//ComputerGraphicsForum.[S.l.]:IEEE,2015:95-104.
[32]ZHANGK,WANGB,ZUOW,etal.Jointlearningofmultipleregressorsforsingleimagesuper-resolution[J].IEEEsignalprocessingletters, 2016, 23(1):102-106.
[33]DONGC,CHENCL,HEK,etal.Learningadeepconvolutionalnetworkforimagesuper-resolution[C]//ComputerVision-ECCV.[S.l.]:SpringerInternationalPublishing,2014:184-199.
[34]SCHULTERS,LEISTNERC,BISCHOFH.Fastandaccurateimageupscalingwithsuper-resolutionforests[C]//IEEEConferenceonComputerVisionandPatternRecognition.[S.l.]:IEEE,2015:3791-3799.
[35]HUANGJJ,SIUWC.Learninghierarchicaldecisiontreesforsingleimagesuper-resolution[J].IEEEtransactionsoncircuits&systemsforvideotechnology, 2015(7):1-14.
[36]BHATP,ZITNICKCL,SNAVELYN,etal.Usingphotographstoenhancevideosofastaticscene[J].Eurographicssymposiumonrenderingjankautz&sumantapattanaik,2007(6):327-338.
[37]WATANABEK,IWAIY,HAGAT,etal.Afastalgorithmofvideosuper-resolutionusingdimensionalityreductionbydctandexampleselection[C]//19thInternationalConferenceonPatternRecognition.[S.l.]:IEEE,2008:1-5.
[38]LIUF,WANGJ,ZHUS,etal.Noisyvideosuper-resolution[C]//ACMInternationalConferenceonMultimedia.[S.l.]:IEEE,2008:713-716.
[39]SHANQ,LIZ,JIAJ,etal.Fastimage/videoupsampling[J].ACMtransactionsongraphics,2008,27(5):32-39.
[40]SHIMANOM,OKABET,SATOI,etal.Videotemporalsuper-resolutionbasedonself-similarity[J].Ieicetransactionsoninformation&systems,2010,94(8):93-106.
[41]LIUC,SUND.Abayesianapproachtoadaptivevideosuperresolution[C]//IEEEConferenceonComputerVisionandPatternRecognition.[S.l.]:IEEE,2011:209-216.
[42]吴蔚华,阮卫泓,谢于迪. 超高清晰度电视技术概述[J]. 电视技术,2014,38(8):69-71.
[43]SONGB,JEONGSC,CHOIY.Videosuper-resolutionalgorithmusingbi-directionaloverlappedblockmotioncompensationandon-the-flydictionarytraining[J].IEEEtransactionsoncircuitssystemvideotechnology,2011,21(3):274-285.
[44]HUNGE,QUEIROZR,BRANDIF,etal.Videosuper-resolutionusingcodebooksderivedfromkeyframes[J].IEEEtransactionsoncircuitssystemvideotechnology,2012,22(9):1321-1331.
[45]JEONGS,YOONI,PAIKJ.Multi-frameexample-basedsuper-resolutionusinglocallydirectionalself-similarity[J].IEEEtransactionsonconsumerelectronics,2015,61(3):353-358.
[46]RUANGSANGW,ARAMVITHS.Super-resolutionforHDto4KusingAnalysisK-SVDdictionaryandadaptiveelastic-net[C]//IEEEInternationalConferenceonDigitalSignalProcessing(DSP).[S.l.]:IEEE,2015,1076-1080.
[47]GARCIADC,DOREAC,QUEIROZRL.Superresolutionformultiviewimagesusingdepthinformation[J].IEEEtransactionsoncircuitssystemvideotechnology,2012,22(9):1249-1256.
[48]ZHANGJ,CAOY,WANGZ.Asimultaneousmethodfor3dvideosuper-resolutionandhigh-qualitydepthestimation[C]//20thIEEEInternationalConferenceonImageProcessing(ICIP).[S.l.]:IEEE,2013:1346-1350.
[49]JAINAK,NGUYENTQ.Videosuper-resolutionformixedresolutionstereo[C]//20thIEEEInternationalConferenceonImageProcessing(ICIP).[S.l.]:IEEE,2013:962-966.
[50]JINZ,TILLOT,YAOC,etal.Virtualviewassistedvideosuper-resolutionandenhancement[J].IEEEtransactionsoncircuits&systemsforvideotechnology, 2015, 25(2):1-12.
[51]ISMAEILKA,AOUADAD,MIRBACHB,etal.Dynamicsuperresolutionofdepthsequenceswithnon-rigidmotions[C]//20thIEEEInternationalConferenceonImageProcessing(ICIP) .[S.l.]:IEEE,2013:660-664.
[52]ISMAEILKA,AOUADAD,SOLIGNACT,etal.Real-timenon-rigidmulti-framedepthvideosuper-resolution[C]//IEEEConferenceonComputerVisionandPatternRecognitionWorkshops(CVPRW).[S.l.]:IEEE,2015:8-16.
李欣(1981— ),女,讲师,主要研究图像处理与多媒体通信、数字电视处理与传输等;
崔子冠(1982— ),副教授,主要研究方向为视频编码与传输、图像处理等;
朱秀昌(1947— ),教授,博士生导师,主要研究方向包括多媒体信息、图像和视频的采集、处理、传输和显示。
责任编辑:时雯
Survey of super-resolution algorithms
LI Xin,CUI Ziguan,ZHU Xiuchang
(ImageProcessingandImageCommunicationLab.,NanjingUniversityofPostsandTelecommunications,Nanjing210003,China)
With the development of high-resolution mobile devices and ultra-high-definition televisions, applying super-resolution up-sampling to the existing low-resolution video has become a hot research topic recently. In this paper, according to the different way of input and output, the existing super-resolution reconstruction algorithms are divided into three categories:multiple-image super-resolution reconstruction, single-image super-resolution reconstruction, and video super-resolution reconstruction. The development and common usage of each category are reviewed, and the characteristics of different algorithms are compared. In the following, the impact of multi-image super-resolution reconstruction and single-image super-resolution reconstruction on video super-resolution reconstruction is discussed. Finally, the development prospect of super-resolution reconstruction algorithm is analyzed.
super-resolution; ultra-high-definition televisions; registration; sparse representation
TN911.73; TP391.4
A
10.16280/j.videoe.2016.09.001
国家自然科学基金青年基金项目(61501260);江苏省自然科学基金项目(BK20130867;BK20140891);江苏省普通高校研究生科研创新计划项目(CXLX12_0474)
2016-01-25
文献引用格式:李欣,崔子冠,朱秀昌.超分辨率重建算法综述[J].电视技术,2016,40(9):1-9.
LI X,CUI Z G,ZHU X C.Survey of super-resolution algorithms[J].Video engineering,2016,40(9):1-9.
猜你喜欢
雷达学报(2020年3期)2020-07-13
软件(2020年3期)2020-04-20
成都信息工程大学学报(2019年3期)2019-09-25
摄影之友(影像视觉)(2018年12期)2019-01-28
Coco薇(2017年8期)2017-08-03
自动化学报(2017年5期)2017-05-14
中国诠释学(2016年0期)2016-05-17
Coco薇(2015年5期)2016-03-29
探测与控制学报(2015年4期)2015-12-15
太空探索(2015年8期)2015-07-18
